【Elasticsearch】分词机制详解(含实战案例)
分词机制详解
- 1.什么是分词 ?
- 2.为什么需要分词 ?
- 3.分词发生的阶段
- 4.分词器的组成
- 5.分词器的分类
- 5.1 内置分词器
- 5.2 中文分词器(需要插件)
- 5.3 自定义分词器
- 6.电商平台商品搜索 - 自定义分词器案例
- 6.1 场景需求
- 6.2 自定义分词器设计
- 6.3 分词器组件解析
- 6.4 实际效果示例
- 6.5 搜索场景优势
- 6.6 实际应用
- 索引文档
- 搜索示例 1:同义词搜索
- 搜索示例 2:型号搜索
1.什么是分词 ?
分词(Tokenization)是指将文本拆分成一个个独立的 词项(token)的过程。在 Elasticsearch 中,分词是将原始文本分解为可被索引和搜索的基本单元的处理步骤。
例如:“Elasticsearch是一个强大的搜索引擎” → [“elasticsearch”, “是”, “一个”, “强大”, “的”, “搜索”, “引擎”]
2.为什么需要分词 ?
- 提高搜索效率:将文本分解为词项可以建立倒排索引,快速定位文档。
- 提升搜索准确性:通过分词可以匹配更精确的词项而非整个文本。
- 支持语言特性:不同语言有不同的分词需求(如中文需要分词,英文按空格分)。
- 实现高级搜索功能:如模糊搜索、同义词搜索等都依赖分词结果。
3.分词发生的阶段
分词主要发生在两个阶段:
- 索引阶段(
Indexing Time):当文档被索引时,对文本字段内容进行分词处理。 - 搜索阶段(
Search Time):对查询字符串进行分词处理(可使用与索引不同的分词器)。
4.分词器的组成
一个完整的分词器(Analyzer)由三部分组成:
- 字符过滤器(
Character Filters):原始文本预处理- 如去除 HTML 标签、替换特殊字符等。
- 一个分词器可有 0 个或多个字符过滤器。
- 分词器(
Tokenizer):将文本拆分为词项- 必须且只有一个分词器。
- 如标准分词器、中文分词器等。
- 词项过滤器(
Token Filters):对词项进行进一步处理- 如小写转换、去除停用词、添加同义词等。
- 一个分词器可有 0 个或多个词项过滤器。
5.分词器的分类
5.1 内置分词器
| 分词器名称 | |
|---|---|
Standard Analyzer | 默认分词器,按词切分,小写处理 |
Simple Analyzer | 按非字母字符切分,小写处理 |
Whitespace Analyzer | 按空白字符切分,不转小写 |
Keyword Analyzer | 不分词,将整个输入作为一个词项 |
Pattern Analyzer | 使用正则表达式分词 |
Language Analyzers | 针对特定语言的分词器(如 english、french 等) |
5.2 中文分词器(需要插件)
| 分词器名称 | |
|---|---|
IK Analyzer | 支持中文细粒度和智能分词两种模式 |
Jieba Analyzer | 结巴中文分词 |
HanLP Analyzer | 功能丰富的中文分词器 |
THULAC | 清华大学中文分词器 |
5.3 自定义分词器
可以通过组合不同的字符过滤器、分词器和词项过滤器来创建自定义分词器:
PUT /my_index
{"settings": {"analysis": {"analyzer": {"my_custom_analyzer": {"type": "custom","char_filter": ["html_strip"],"tokenizer": "standard","filter": ["lowercase", "stop"]}}}}
}
选择合适的分词器对搜索质量至关重要,需要根据实际业务需求和数据特点来选择或定制分词方案。
6.电商平台商品搜索 - 自定义分词器案例
6.1 场景需求
假设我们正在为一个跨境电商平台构建商品搜索系统,该平台主要销售电子产品,有以下特点:
- 商品标题包含多种语言(英文、中文、品牌特有名词)
- 商品型号规格复杂(如 “
iPhone 15 Pro Max 256GB”) - 需要支持同义词搜索(如 “
手机” 和 “智能手机” 应匹配相同结果) - 需要忽略特殊字符但保留重要符号(如 “
Wi-Fi” 中的横线应保留)
6.2 自定义分词器设计
PUT /ecommerce_products
{"settings": {"analysis": {"char_filter": {"special_chars_filter": {"type": "mapping","mappings": ["& => and","® => ","™ => ","【 => [","】 => ]"]}},"filter": {"english_stop": {"type": "stop","stopwords": "_english_"},"tech_synonyms": {"type": "synonym","synonyms": ["手机, 智能手机, cellphone, mobile phone","笔记本, 笔记本电脑, notebook, laptop","平板, 平板电脑, tablet"]},"product_type_filter": {"type": "word_delimiter","preserve_original": true,"split_on_numerics": false,"split_on_case_change": false}},"analyzer": {"product_analyzer": {"type": "custom","char_filter": ["html_strip","special_chars_filter"],"tokenizer": "standard","filter": ["lowercase","english_stop","tech_synonyms","product_type_filter","asciifolding"]}}}},"mappings": {"properties": {"title": {"type": "text","analyzer": "product_analyzer","search_analyzer": "product_analyzer"},"model_number": {"type": "keyword"}}}
}
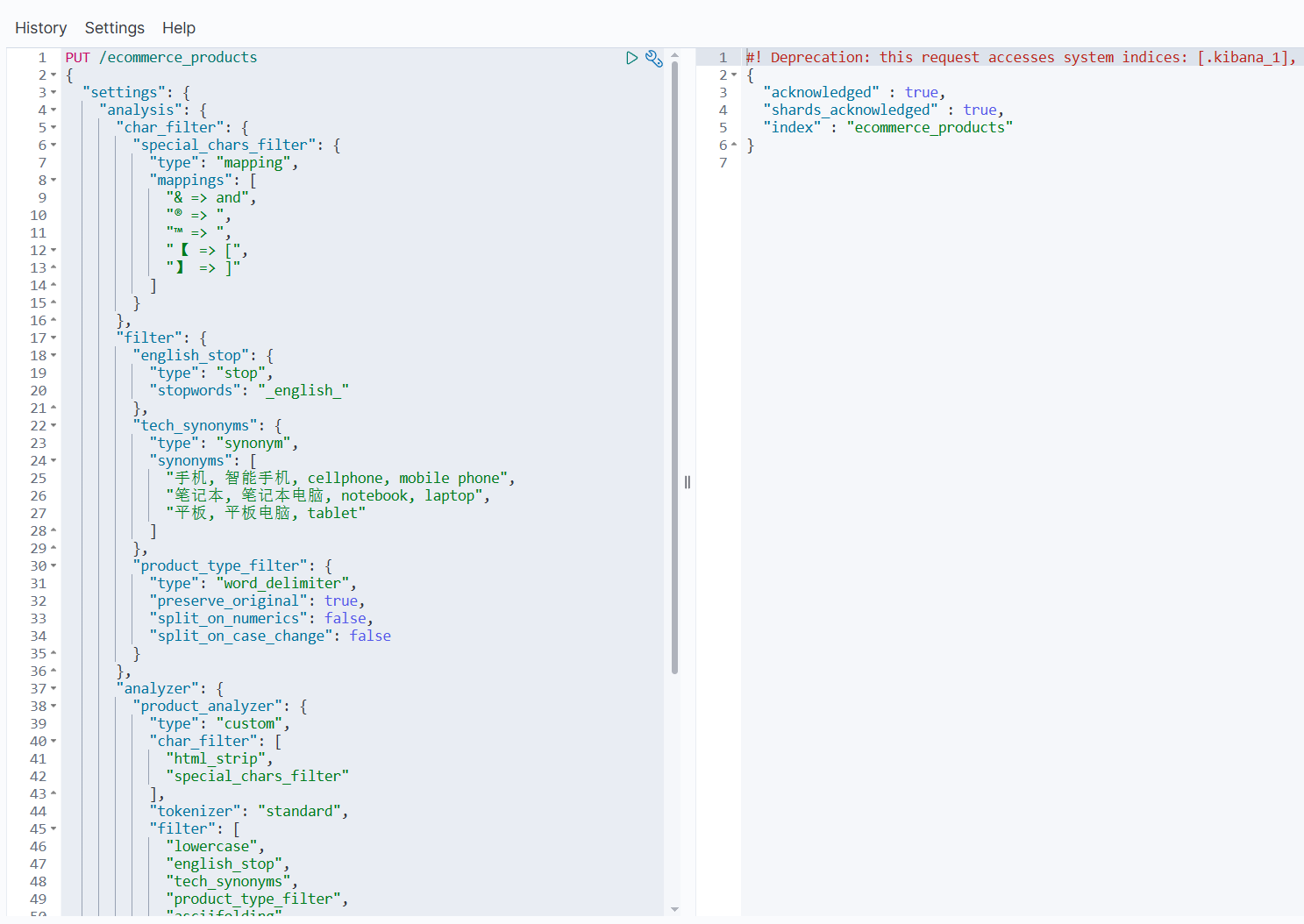
6.3 分词器组件解析
- 字符过滤器(Char Filters):
html_strip:去除 HTML 标签。special_chars_filter:处理特殊字符和商标符号。
- 分词器(Tokenizer):
- 使用
standard分词器作为基础。
- 使用
- 词项过滤器(Token Filters):
lowercase:转为小写。english_stop:去除英文停用词。tech_synonyms:添加电子产品同义词。product_type_filter:特殊处理产品型号(保留原始形式)。asciifolding:将非 ASCII 字符转换。
6.4 实际效果示例
- 输入文本:“
Apple iPhone® 15 Pro Max 256GB【旗舰手机】支持Wi-Fi 6E” - 分词结果:[“
apple”, “iphone”, “15”, “pro”, “max”, “256gb”, “旗舰”, “手机”, “智能手机”, “cellphone”, “mobile phone”, “wi-fi”, “6e”]
6.5 搜索场景优势
- 多语言支持
- 搜索 “
手机” 也能找到标题含 “智能手机” 或 “cellphone” 的商品。
- 搜索 “
- 型号规格处理
- 搜索 “
iphone 15 pro” 能匹配完整型号 “iPhone 15 Pro Max 256GB”。 - 但不会错误拆分 “
256GB” 为 “256” 和 “gb”。
- 搜索 “
- 特殊符号处理
- “
wi-fi” 和 “wifi” 会被视为等价搜索词。 - 但保留重要连接符确保技术术语准确性。
- “
- 品牌保护
- 商标符号
®被去除,但品牌名称保留。
- 商标符号
6.6 实际应用
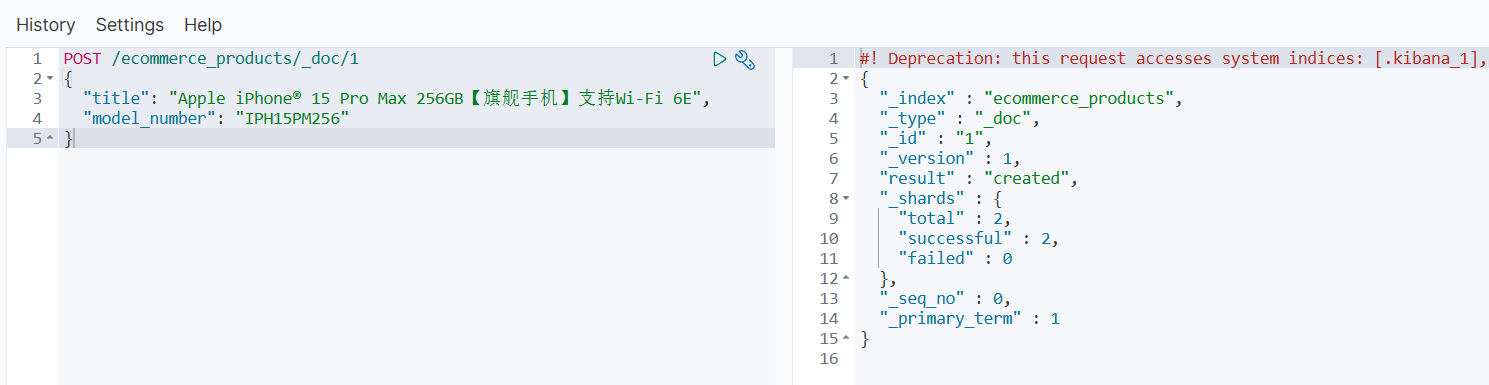
索引文档
POST /ecommerce_products/_doc/1
{"title": "Apple iPhone® 15 Pro Max 256GB【旗舰手机】支持Wi-Fi 6E","model_number": "IPH15PM256"
}
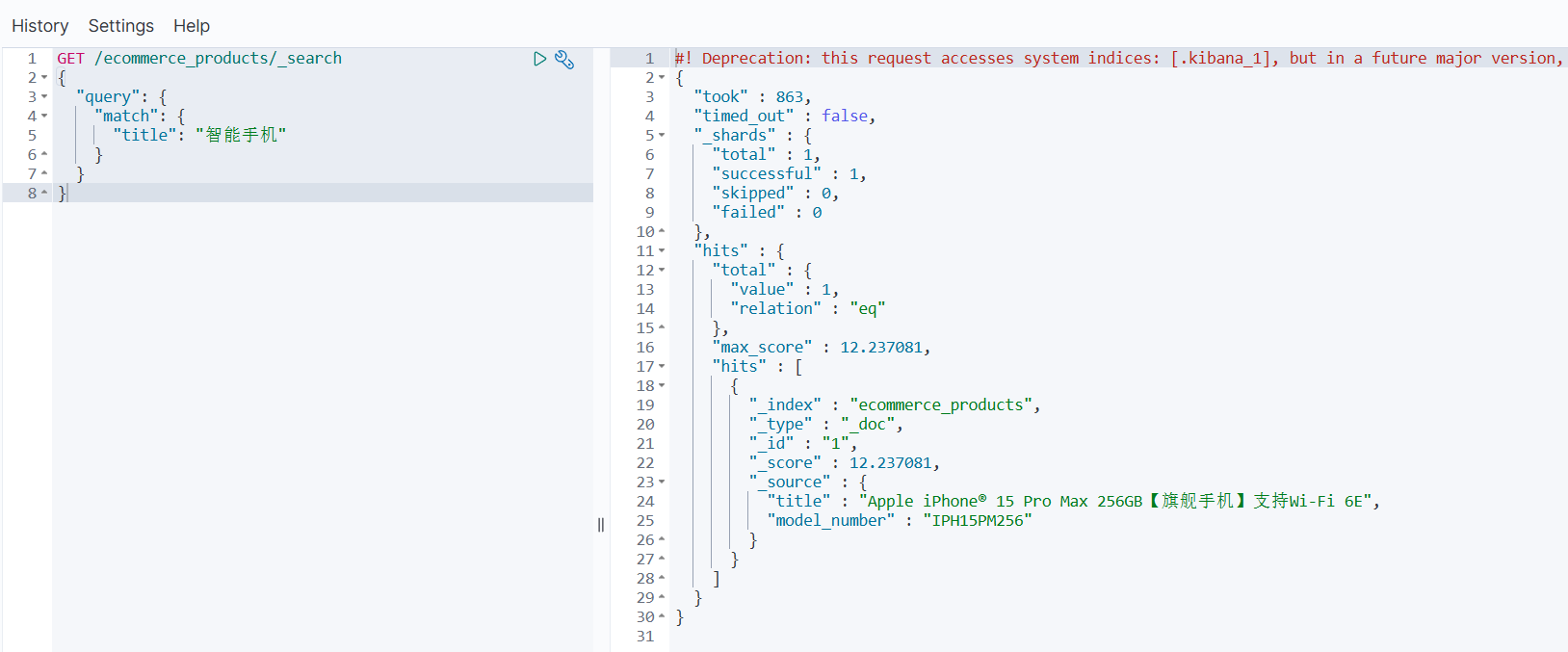
搜索示例 1:同义词搜索
GET /ecommerce_products/_search
{"query": {"match": {"title": "智能手机"}}
}
能匹配到包含 “手机” 或 “cellphone” 的文档。
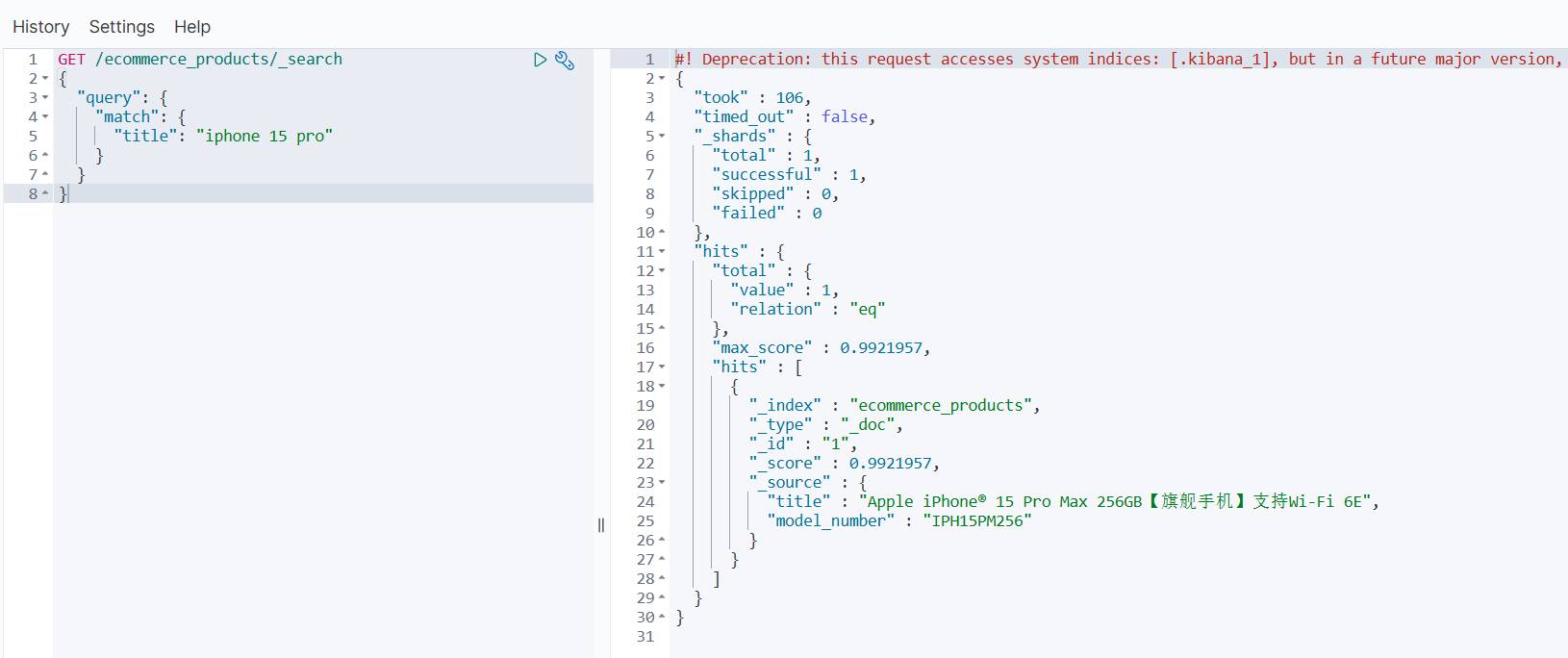
搜索示例 2:型号搜索
GET /ecommerce_products/_search
{"query": {"match": {"title": "iphone 15 pro"}}
}
能匹配完整型号 “iPhone 15 Pro Max 256GB”。
这个自定义分词器设计有效解决了电商产品搜索中的多语言处理、同义词扩展、特殊符号处理等典型问题,显著提升了搜索准确性和用户体验。