详解deeplabv3+改进思路
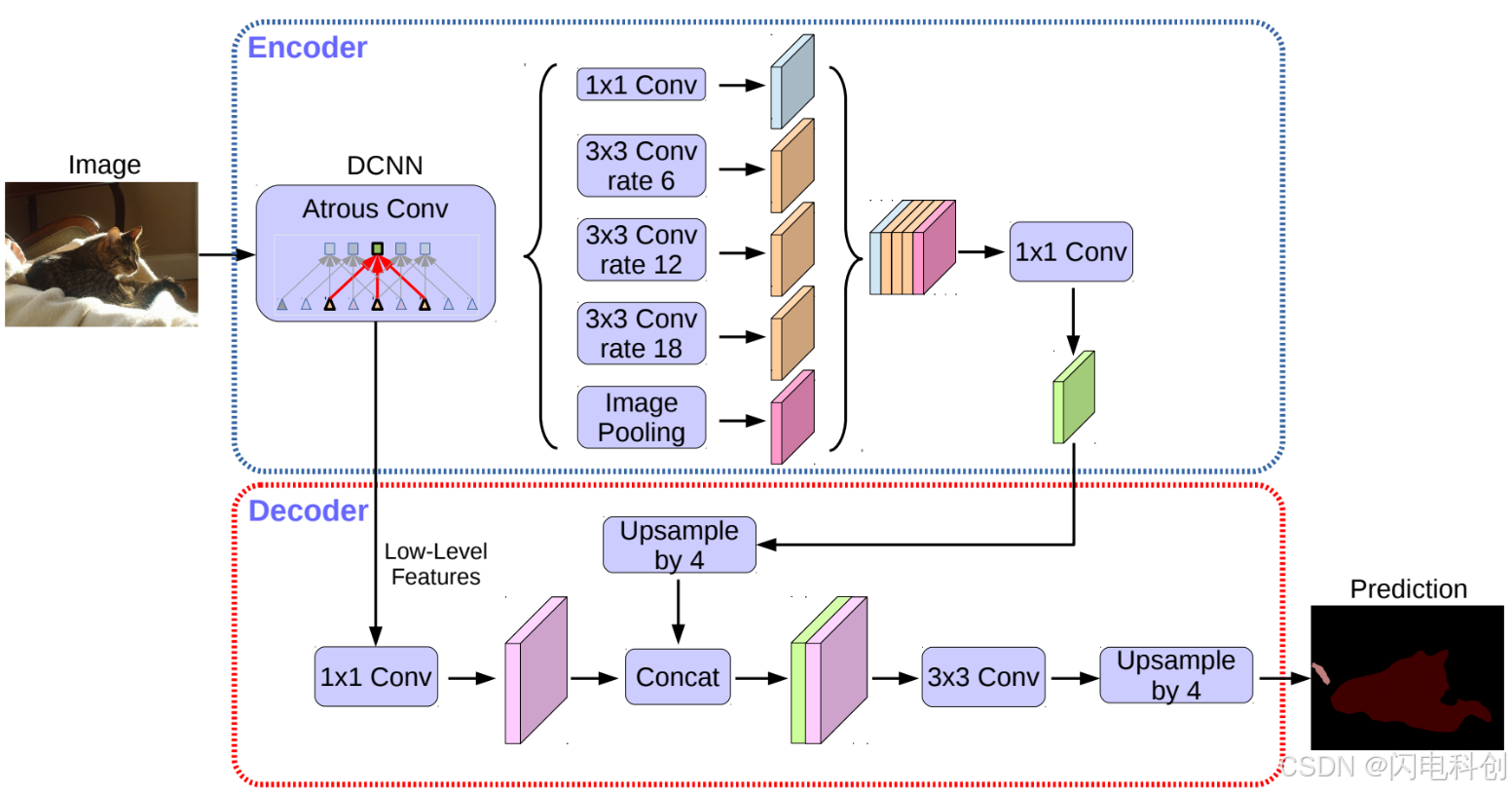
DeepLabV3+ 分割算法的改进思路
DeepLabV3+ 是一款基于深度学习的语义图像分割算法,是 DeepLab 系列的最新版本。该算法由 Google Research 提出,主要用于解决图像中的像素级别的分类问题,如人脸、物体、场景等的分割。相较于以前的版本,DeepLabV3+ 在多个方面进行了创新和改进,尤其在处理高分辨率图像和复杂场景时,取得了显著的效果提升。以下将从多个方面详细介绍 DeepLabV3+ 的改进思路和核心思想。
1. 引入空洞卷积(Dilated Convolution)
空洞卷积是 DeepLab 系列算法中的核心组件,尤其在 DeepLabV3 和 DeepLabV3+ 中得到了进一步的优化。空洞卷积(也叫扩张卷积)通过在卷积核中插入空洞(即不连接的像素点)来增加感受野,而不增加计算量。这一机制对于提升卷积神经网络的空间感知能力非常重要,尤其在图像分割中,空洞卷积能够让模型更好地捕捉到图像中的长距离上下文信息。
在传统卷积中,卷积核是连续的,感受野受到卷积核大小的限制。而在空洞卷积中,通过空洞的引入,感受野可以显著扩大,这使得网络能够处理更大范围的图像信息,从而获得更多的上下文信息,这对于图像分割任务至关重要,因为分割任务通常需要根据较大的区域来推测每个像素的类别。
DeepLabV3+ 在此基础上使用了 空洞空间金字塔池化(ASPP),这种技术结合了不同大小的空洞卷积来增强不同尺度的特征提取能力。ASPP 使用了多种不同的空洞率,这使得网络能够有效地处理不同尺寸的物体,提升了模型对复杂场景和物体的分割能力。
2. 引入编码器-解码器结构
DeepLabV3+ 的另一个显著改进是引入了 编码器-解码器结构,这一结构大大改善了语义分割中的边界精度问题。传统的 DeepLabV3 采用了全卷积网络(FCN)架构,在推断过程中,由于没有解码器部分,导致输出的分割结果在边缘区域表现不佳。DeepLabV3+ 在此基础上做了进一步的优化,引入了一个解码器模块,以增强分割精度。
解码器部分的作用是通过对低级特征进行逐步恢复,弥补了编码器部分对空间细节的损失。在图像分割过程中,编码器通过多层卷积提取图像的高层语义特征,而解码器则将这些高层特征进行上采样,以恢复图像的空间分辨率,从而提高边缘和细节部分的分割效果。通过这种设计,DeepLabV3+ 可以更好地处理细节和边缘信息,提高了图像分割的精度,尤其在复杂的物体边缘和细节上表现突出。
3. 深度可分离卷积的使用
另一项显著的改进是 深度可分离卷积(Depthwise Separable Convolutions)。这种卷积方法最早由 MobileNet 引入,用于减少卷积神经网络的计算量。在标准卷积中,卷积核的每一个通道都会与每一个输入通道进行全连接,从而产生大量的参数和计算。而深度可分离卷积则将这一过程分解为两个阶段:首先进行深度卷积(每个输入通道独立卷积),然后进行逐点卷积(1x1 卷积)。这一分解不仅减少了计算量,而且还保持了卷积神经网络的表现力。
在 DeepLabV3+ 中,深度可分离卷积被用于编码器部分,这显著降低了计算复杂度,提高了模型的效率,同时保持了较高的分割精度。这使得 DeepLabV3+ 在进行大规模图像分割时,可以更加高效地进行处理,特别适合在资源受限的环境中运行。
4. 空间金字塔池化(Spatial Pyramid Pooling, SPP)
为了进一步提高对不同尺度物体的分割能力,DeepLabV3+ 引入了空间金字塔池化(SPP)模块。SPP 模块能够在多尺度的层次上对图像进行池化操作,从而获取不同尺度的上下文信息。通过这种方式,网络能够在不同的尺度上提取信息,从而提升对大物体、小物体以及中等尺寸物体的分割效果。
在 DeepLabV3+ 中,SPP 不仅可以提高特征的表达能力,还能够避免由于不同尺度物体导致的性能下降。通过使用不同的池化窗口大小,SPP 能够捕捉到多层次、多尺度的信息,为模型提供了强大的上下文感知能力。
5. 全局平均池化与特征融合
DeepLabV3+ 在采用空洞卷积和编码器-解码器结构的同时,利用了 全局平均池化(Global Average Pooling, GAP)技术。GAP 是一种常用于图像分类网络中的池化操作,它将整个图像区域的特征通过池化汇聚成一个数值,通常用于提取全局信息。在 DeepLabV3+ 中,GAP 被用于提取全局上下文信息,并将其与局部特征进行融合,从而增强了模型对复杂场景的适应能力。
通过全局特征和局部特征的融合,DeepLabV3+ 在细节和整体信息的平衡方面表现得更为优越。这种特征融合的方式不仅能够提升分割的精度,还使得模型能够更加稳定地处理各种复杂的图像内容。