吃透 Golang 基础:函数
文章目录
- 函数
- 函数声明
- 递归
- 递归案例分析: LeetCode 124. 二叉树的最大路径
- 多返回值
- 错误
- 错误传播
- 出错时重试
- 输出错误信息并结束程序
- 仅输出错误信息
- 直接忽略
- 文件结尾错误(EOF)
- 函数值
- 匿名函数
- 可变参数
- Deferred 函数
- Panic 异常
- Recover 捕获异常
函数
今天我们开始系统地复习与 Golang 函数相关的知识。

函数声明
与任何语言当中的函数一样,Go 的函数声明包括函数名、形式参数列表、返回值列表(可省略)以及函数体。
func name(parameter-list) (result-list) {body
}
形参列表描述了函数的参数名及参数类型。这些参数作为局部变量,值由调用者提供。同理,返回值列表定义了返回值的名字(需要注意的是,Go 函数的返回值可以在函数定义时给出一个名字,可以在函数体当中使用这个名字)和类型。如果函数返回无名变量或没有返回值,那么返回值列表的括号可以省略。在这种情况下,每一个返回值被声明为一个局部变量,并根据该返回值的类型初始化这些局部变量为该类型的零值。
需要注意的是,如果在函数定义时给出了函数的返回值列表,那么函数必须显式地使用return作为函数体的结尾。
如果一组形参或返回值有相同的类型,那么就不需要为每个形参都写出函数类型,可以省略:
func f(i, j, k int, s, t string) {/* ... ... ... */}
func f(i int, j int, k int, s string, t string) {/* ... ... ... */} // 等价的写法
函数的类型被称为函数的签名。如果两个函数的形参列表和返回值列表中的变量类型一一对应,那么这两个函数被认为有相同的签名(类型)。在 Golang 当中,函数是一等公民,它可以被视为一个对象,因此我们甚至可以定义一个类型为“某个函数签名”的变量,然后定义一个签名相同的函数并赋值给它。
每次函数调用都必须按照声明顺序为所有参数提供实参,Go 当中没有默认的参数值(在 C++ 和 Python 当中,可以从右向左位函数的形参指定默认值),也没有任何方法可以通过参数名指定形参「这一点要尤为注意:在通过{}创建一个结构体变量时,我们可以通过指定名字的方式为该变量的成员赋值,没有指定到的成员赋零值,但是这仅限于变量的声明。Go 的函数不能通过指定参数名字来传递实参,而是必须按照顺序传递所有参数」。因此,形参和返回值的变量名对于函数的调用者而言没有任何意义。
在函数体中,函数的形参作为局部变量,被初始化为调用者提供的实参值。需要注意的是,每一个函数在创建时,都会分配一个自己的栈空间,初始的局部变量全部分配在栈空间上(除非传递进来的变量值非常的大,超过了栈的上限,才会被分配到堆上),后续创建的局部变量一般都会分配到栈上(除非占用的内存超过了栈空间的上限)。如果在函数当中,使用全局变量引用了一个函数内部的局部变量,或者函数返回了一个局部变量的指针,会导致函数的内存逃逸,即局部变量的内存从函数的栈空间逃逸到了运行时的堆上。函数的栈空间会随着函数调用的结束而销毁,局部变量占用的内存空间也随之释放,但逃逸到堆上的内存依赖于 Golang 的 GC 机制进行垃圾回收,因此如果在函数体当中产生了全局变量的引用,或是返回一个局部变量的地址,会导致性能开销的提升。这一部分内容对应于 Golang 的内存逃逸分析,有兴趣的同学可以查看我之前的文章。
需要强调的是,**Golang 只有传值调用,**实参仅通过传值的方式进行调用,因此函数的形参是实参的值拷贝。对形参进行修改不会影响实参。但是,如果实参包括引用类型,比如指针、切片、map、function、channel 等类型,实参会由于函数的间接引用而被修改。
这里可以深挖一下,我们以传递 slice 为例。slice 的底层实现是一个包含三部分成员的结构体,分别是 Pointer、len 和 cap。Pointer 即指向 slice 底层数组的指针,len 和 cap 是 slice 当前的长度以及当前最大的容量。如果我们将一个 slice 作为实参传递给函数,并在函数当中对 slice 当中的值进行修改,那么函数所做的修改对外部是可见的,原因是函数当中对 slice 的修改实际上修改的是 slice 引用的底层数组,而函数调用方与函数内部的 slice 引用的是同一个数组。但是,如果我们试图在函数当中使用 append 为 slice 追加元素,并且认为由于 slice 是引用类型,我们在函数当中的追加操作对外部可见,那就是大错特错了。原因在于在函数内部的 append 可能会导致 slice 底层扩容,从而使得 Pointer 引用的数组发生变化,然而,由于 Golang 只有传值调用,函数调用方传递进来的是 slice 的指针,函数内部指针值的修改对外部是不可见的,因此函数返回后,如果 append 导致 slice 扩容,那么外部是不会感知到 slice 的扩容的。正确的做法应该和 append 本身的用法一样,即:slice = append(slice, value),让函数本身返回修改的 slice,并让函数调用方接收这个 slice。
递归
递归指的就是在函数 A 当中再次调用函数 A,基于递归可以用于处理与“层级”相关的问题,比如处理“递归”类型的数据结构(堆/树等)。
大部分编程语言使用固定大小的函数调用栈,常见的大小从 64KB 到 2MB 不等。固定大小栈会限制递归的深度,当你用递归处理大量数据时,需要避免栈溢出。
与之不同的是,Golang 使用可变栈,栈的大小可以按需增加,这使得我们在 Golang 当中使用递归时不必考虑栈溢出和安全问题。
我们以「LeetCode 124. 二叉树中的最大路径」为例,了解一下在 Golang 当中如何使用递归。
递归案例分析: LeetCode 124. 二叉树的最大路径
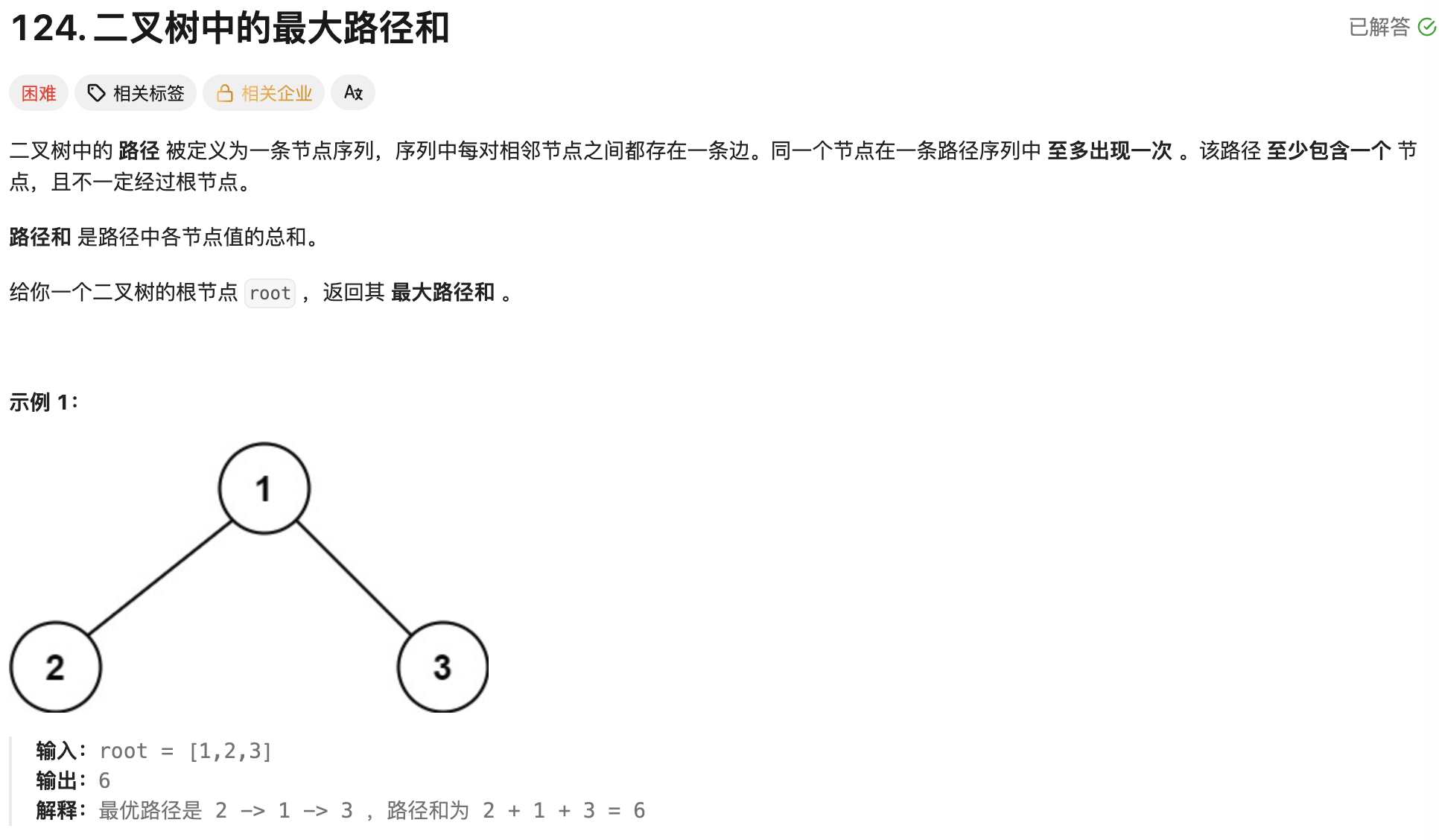
解决这道题的思路就是递归地遍历每一个二叉树的节点,并统计以该节点为路径当中的一个点,局部的最大路径和是多少,使用一个全局变量来记录局部的最大路径和,以统计全局的最大路径和。
这里的“遍历二叉树节点”就需要运用到递归。
使用 Golang 解决这个问题的代码是:
/*** Definition for a binary tree node.* type TreeNode struct {* Val int* Left *TreeNode* Right *TreeNode* }*/
func maxPathSum(root *TreeNode) int {ans := math.MinIntvar findMaxPath func(*TreeNode)(int)findMaxPath = func(node *TreeNode) int {if node == nil {return 0}left := max(0, findMaxPath(node.Left))right := max(0, findMaxPath(node.Right))ans = max(ans, node.Val + left + right)return node.Val + max(left, right)}findMaxPath(root)return ans
}
不难看出,我们定义了一个名为 findMaxPath 的函数,并递归地调用它以获取局部的结果。
多返回值
和 Python 类似,在 Go 当中,一个函数可以返回多个值。我们已经看到,许多标准库的函数会返回两个值,一个是期望得到的返回值,一个是函数出错时的错误信息。
定义一个多返回值的例子如下:
// findLinks performs an HTTP GET request for url, parses the
// response as HTML, and extracts and returns the links.
func findLinks(url string) ([]string, error) {resp, err := http.Get(url)if err != nil {return nil, err}if resp.StatusCode != http.StatusOK {resp.Body.Close()return nil, fmt.Errorf("getting %s: %s", url, resp.Status)}doc, err := html.Parse(resp.Body)resp.Body.Close()if err != nil {return nil, fmt.Errorf("parsing %s as HTML: %v", url, err)}return visit(nil, doc), nil
}
调用多返回值函数时,返回给调用者的是一组值,调用者必须显式地将这些值分配给变量或 blank identifier:
links, err := findLinks(url)
// or
links, _ := findLinks(url) // 忽略错误处理
一个函数内部可以将另一个有多返回值的函数调用作为返回值,一个例子如下:
func findLinksLog(url string) ([]string, error) {log.Printf("findLinks %s", url)return findLinks(url)
}
准确的变量名可以用于传达函数返回值的含义:
func Size(rect image.Rectangle) (width, height int)
func Split(path string) (dir, file string)
func HourMinSec(t time.Time) (hour, minute, second int)
如果一个函数所有的返回值都有显式的变量名,那么该函数的 return 语句中,可以省略这些变量名,称为 bare return:
func CountWordsAndImages(url string) (words, images int, err error) {resp, err := http.Get(url)if err != nil {return}doc, err := html.Parse(resp.Body)resp.Body.Close()if err != nil {err = fmt.Errorf("parsing HTML: %s", err)return}words, images = countWordsAndImages(doc)return
}
func countWordsAndImages(n *html.Node) (words, images int) { /* ... */ }
上面的 return 语句等价为:
return words, images, err
需要注意的是,返回值的变量名要么全部命名,要么全部不命名,以保持代码清晰和逻辑一致。
错误
Go 使用控制流机制(if和return)处理错误,使得编码人员能够更多地关注错误处理。在编写 Go 的过程中我们可以大量地看到:
_, err := randomFunc(/* ... ... ... */)
if err != nil {/* ... ... ... */
}
形如这类的错误处理可以让我们根据错误的类型来采取不同的策略对错误进行处理。以下汇总了几个常见的错误处理策略。
错误传播
该策略认为,函数中某个子程序的失败是函数的失败,函数应该将错误信息err进行封装,然后返回给调用者。
resp, err := http.Get(url)
if err != nil {return nil, err
}
一个封装错误的例子是:
doc, err := html.Parse(resp.Body)
resp.Body.Close()
if err != nil {return nil, fmt.Errorf("parsing %s as HTML: %v", url, err)
}
fmt.Errorf()将格式化错误信息,并通过return返回。这使得在较长的函数调用链中,错误信息以链式的方式进行组合,所以错误信息应该避免大写和换行符。
出错时重试
第二种错误处理的策略通常在错误是由“偶然状况”(比如网络抖动)产生时使用,此时选择重试失败的操作。在重试时,我们需要限制重试的时间或重试的次数,防止无限制重试。
下面这个《Go 语言圣经》当中的例子给出了在 Golang 当中实现错误重试机制的实践,采用了指数退避(Exponential Back-off)的策略,我认为非常值得学习,予以记录:
func WaitForServer(url string) error {const timeout = 1 * time.Minute // 设置超时重试时间的上限deadline := time.Now().Add(timeout)for tries := 0; time.Now().Before(deadline); tries ++ {_, err := http.Head(url)if err == nil {return nil // success}log.Printf("server not responding (%s); retrying ...", err)time.Sleep(time.Second << uint(tries)) // Exponential Back-off}return fmt.Errorf("server %s failed to respond after %s", url, timeout)
}
输出错误信息并结束程序
该策略通常只在 main 函数体当中执行,对于库函数而言,应该仅向上传播错误:
if err := WaitForServer(url); err != nil {fmt.Fprintf(os.Stderr, "Site is down: %v\n", err)os.Exit(1)
}
仅输出错误信息
有时候在发生错误时,我们只需要输出错误信息就可以了,不需要中断程序的运行,可以通过log包提供的函数:
if err := Ping(); err != nil {log.Printf("ping failed: %v; networking disabled", err)
}
直接忽略
仅在特定情况下使用。
最佳实践是每次函数调用后,都养成错误处理的习惯,当我们决定忽略某个错误的时候,应该在注释当中清晰地解释忽略错误的原因。
文件结尾错误(EOF)
io包保证任何由文件结束引起的读取失败都返回同一个错误io.EOF。调用者仅需要简单的比较,就可以检测出这个错误,下例展示如何从标准输入读取自负,以及判断文件结束:
in := bufio.NewReader(os.Stdin)
for {r, _, err := in.ReadRune()if err == io.EOF {break // finished reading}if err != nil {return fmt.Errorf("read failed: %v", err)}
}
函数值
在 Golang 当中,函数被视为一等公民,函数与值一样,拥有类型,可以被赋值给该函数类型的变量,将函数传递给函数,以及作为返回值被返回。一个例子如下:
func square(n int) int { return n * n }
func negative(n int) int { return -n }
func product(m, n int) int { return m * n }f := square
fmt.Println(f(3)) // "9"f = negative
fmt.Println(f(3)) // "-3"
函数类型的零值是nil,调用零值函数会引发 panic:
var f func(int) int
f(3) // panic
同理,函数值可以与nil比较。
但需要注意的是,函数类型的值之间是不能比较的,因此函数值不能用作 map 的 key,但是可以作为 map 的 value。
在 Golang 的网络库当中,我们可以大量地看到实验函数作为值的例子,以及在 Gin 框架当中,当我们想要注册一个 Router 时,Router 对应的处理逻辑大概率是一个参数为*gin.Context的函数。在一个之前的仿 Gin 项目 Gee 当中,我们通过如下方式定义一个保存着 Engine 的 Router 的结构:
type HandlerFunc func(*Context)type router struct {roots map[string]*nodehandlers map[string]HandlerFunc
}
其中 handlers 就是一个 key 为 string(即 url),value 为 HandlerFunc 的 map。HandlerFunc 的类型就是一个函数值。
匿名函数
通过函数字面值(function literal),我们可以定义匿名函数,使用时,在 func 关键字后面,我们不需要定义函数名。函数字面值是一种表达式,其值被称为“匿名函数”(anonymous function)。
下例定义了一个函数闭包,其返回值是一个函数,此时就可以使用匿名函数来构造返回值:
func squares() func() int {var x intreturn func() {x ++return x * x}
}
在嵌套的函数当中,需要注意“内存逃逸”问题,因为我们在squares函数中声明了变量x,它在匿名函数中被使用,这就会导致x的值从squares的栈上逃逸到 Golang 的堆上,为 GC 带来压力。
可变参数
参数数量可变的函数称为可变参数函数,我们使用过的fmt.Println以及append都是可变参数函数,Golang 中的min和max函数也是可变参数函数。
可变参数函数通常用于格式化字符串,下例的errorf构造了一个以行号靠头,经过格式化的错误信息:
func errorf(linenum int, format string, args ...interface{}) {fmt.Fprintf(os.Stderr, "Line %d: ", linenum)fmt.Fprintf(os.Stderr, format, args...) // 传入时也需要加上...fmt.Fprintln(os.Stderr)
}
声明可变参数函数时,需要在参数列表的最后一个参数类型之前加上省略号...,表示函数会接收任意数量的该类型参数。下例对传入的若干个整型变量求和:
func sum(vals ...int) int {total := 0for _, val := range vals {total += val}return total
}
vals会被看作一个类型为[]int的切片。
Deferred 函数
通过defer关键字,可以首先完成待执行语句的计算,直到包含该defer语句的函数(可以是 main 函数)执行完毕,defer的函数才会被执行。可以在一个函数当中多次使用defer语句,函数执行完毕时,defer的语句会按照调用的顺序逆序执行。
defer常用于处理成对的操作,如打开/关闭网络连接、打开/关闭文件读写、加/释放锁。以下是一个处理文件资源时使用defer的例子:
func ReadFile(filename string) ([]byte, error) {f, err := os.Open(filename)if err != nil {return nil, err}defer f.Close() // 需要在错误处理之后执行, 否则如果连文件都没成功打开, 就无从关闭, 会触发 panicreturn ReadAll(f)
}
需要特别强调的是,defer和return谁先执行。正确的答案是:
- 设置返回值;
- 执行
deferred链表(按照defer的顺序逆序执行); - 执行 return。
Panic 异常
Go 的类型系统会在编译时捕获很多异常,但有些错误只能在运行时检查,比如数组访问越界、空指针引用等。这些错误会引发 panic。
一般而言,panic 时,程序会中断,并立即执行该 goroutine 中defer的函数。随后,程序崩溃并输出日志信息。日志信息包括 panic value 和函数调用的堆栈跟踪信息,供开发者追踪错误。
不是所有 panic 都来自运行时,直接调用内置的 panic 函数也会引发 panic 异常,panic 接受任何值作为参数。Go 的 panic 类似于其他语言的异常机制,但 panic 的应用场景有所不同。由于 panic 会引起程序崩溃,因此 panic 一般用于严重错误,如程序内部的逻辑不一致。对于大部分漏洞,我们都应该使用 Go 的错误机制,而不是 panic,以尽可能避免程序崩溃。
需要注意的是,由 Panic 导致的程序崩溃仍然可以通过 Recover 来恢复。
Recover 捕获异常
一般来说,不应该对 panic 异常做任何处理,但有时我们仍然希望可以从 panic 异常恢复。例如,web 服务器应该在崩溃前关闭所有连接,否则客户端会一直处于等待状态。在开发阶段,服务器甚至可以将异常信息反馈到客户端协助调试。
如果 deferred 函数中调用了 recover,且定义该 defer 的语句发生了 panic,recover 会使程序从 panic 恢复,并返回 panic value。导致 panic 异常的函数不会继续运行,但能正常返回。在未发生 panic 时调用 recover,recover 会返回 nil。
下例是使用 recover 来恢复 panic 的较好实践,例子来自于《Go 语言圣经》,它有选择地根据 panic 的类型来对 panic 进行恢复:
// soleTitle returns the text of the first non-empty title element
// in doc, and an error if there was not exactly one.
func soleTitle(doc *html.Node) (title string, err error) {type bailout struct{}defer func() {switch p := recover(); p {case nil: // no paniccase bailout{}: // "expected" panicerr = fmt.Errorf("multiple title elements")default:panic(p) // unexpected panic; carry on panicking}}()// Bail out of recursion if we find more than one nonempty title.forEachNode(doc, func(n *html.Node) {if n.Type == html.ElementNode && n.Data == "title" &&n.FirstChild != nil {if title != "" {panic(bailout{}) // multiple titleelements}title = n.FirstChild.Data}}, nil)if title == "" {return "", fmt.Errorf("no title element")}return title, nil
}