【机器学习】PCA
一、PCA概述
定义
主成分分析(Principal Component Analysis,PCA)是一种经典的无监督降维方法,其核心思想是通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量,这些新的变量被称为"主成分"。
二、PCA原理
通过投影的方式,将高维的数据映射到低维的空间中,并且保证在所投影的维度上原数据的信息量最大,从而使用较少的数据维度保留住较多的原始数据特性。那么为了达成这个目的,PCA可以基于两种思路进行优化:
- 最大可分性:样本投影到低维的超平面之后能够尽量地分开。
例如:将图中的点分别映射到M轴和N轴上,映射到M轴上的样本数据明显比投影到N的样本数据更加分散。
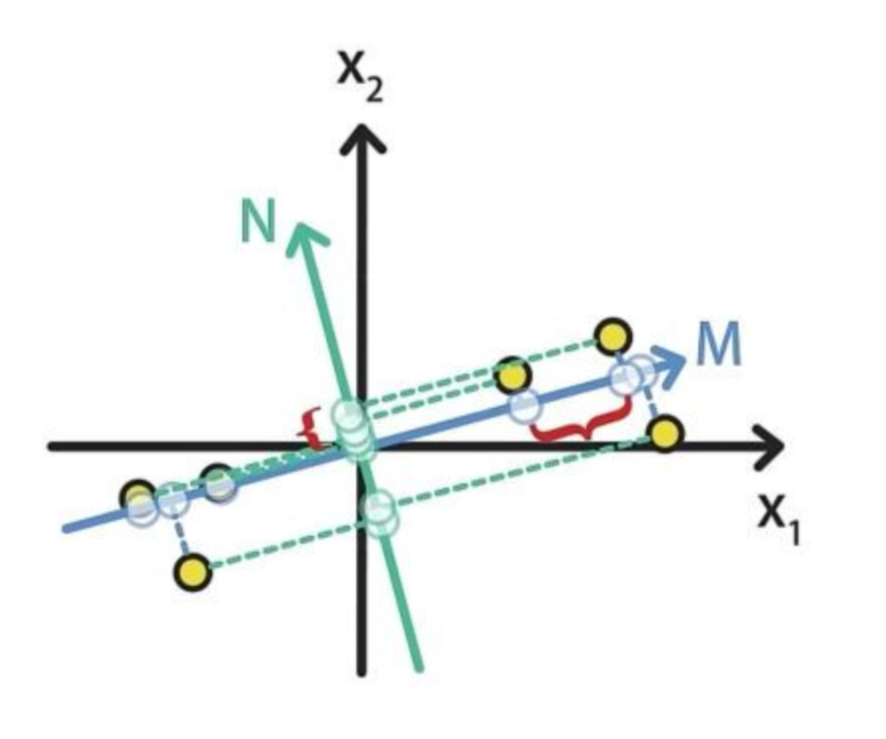
- 最近重构性:样本到待投影的低维超平面的距离要尽量的小
例如:平面上的样本到M的距离是蓝色线段,到N的距离是绿色线段
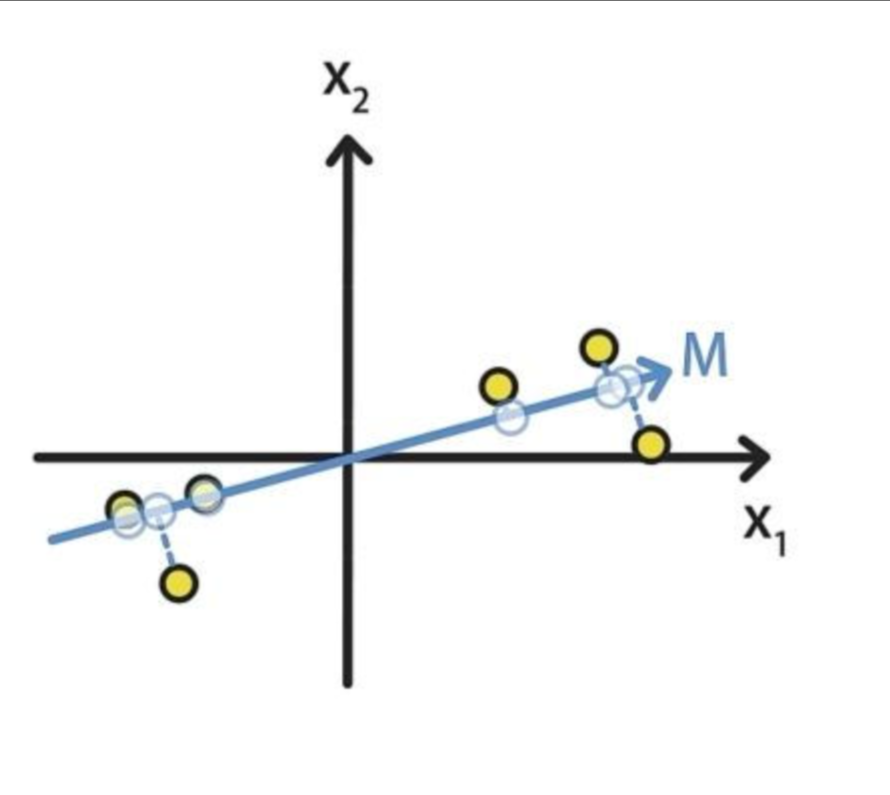
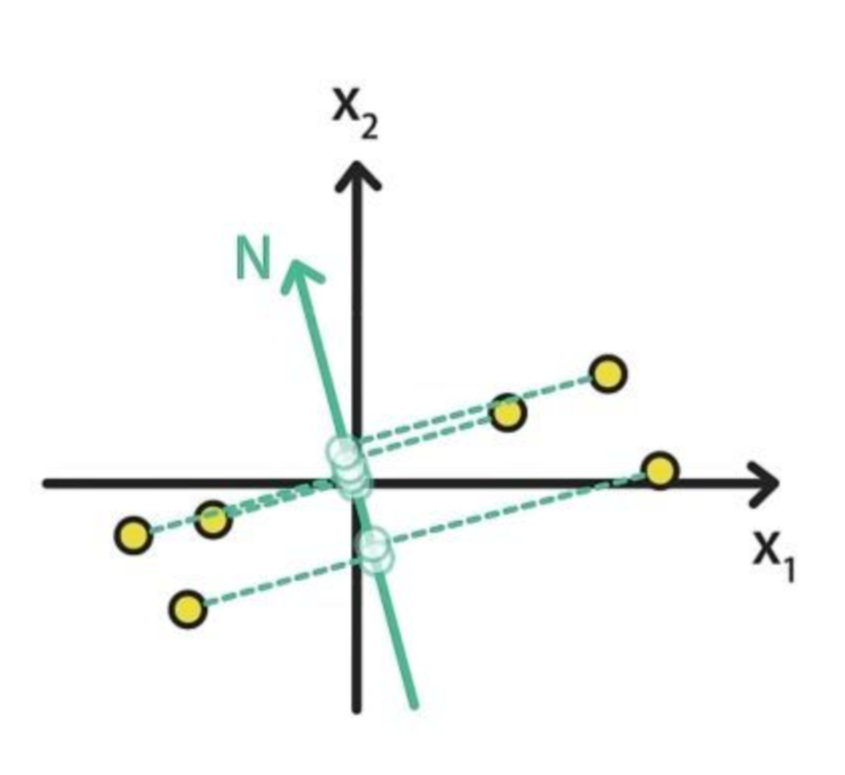
显而易见,蓝色距离之和小于绿色距离之和,所以M在最近重构性方面更好。
PCA的主要思想是将n维特征映射到k维上,这k维是全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的k维特征。
三、PCA求解过程
假设有m个样本,每个样本有n个特征那么样本集X为:
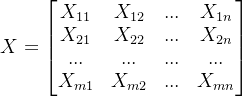
现在欲将X={x1,x2...xn}降到k维,具体过程如下:
(1)去中心化
将数据集中的每个特征的值减去其均值,使得每个特征的均值变为0。
首先计算每列特征的均值,其中xi为第i个特征:
![]()
接着让样本矩阵X中的每一个值进去其所在特征列对应的特征均值:
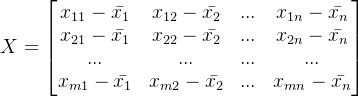
如下图所示为二维图像的去中心化示例:
首先,计算出样本的均值。
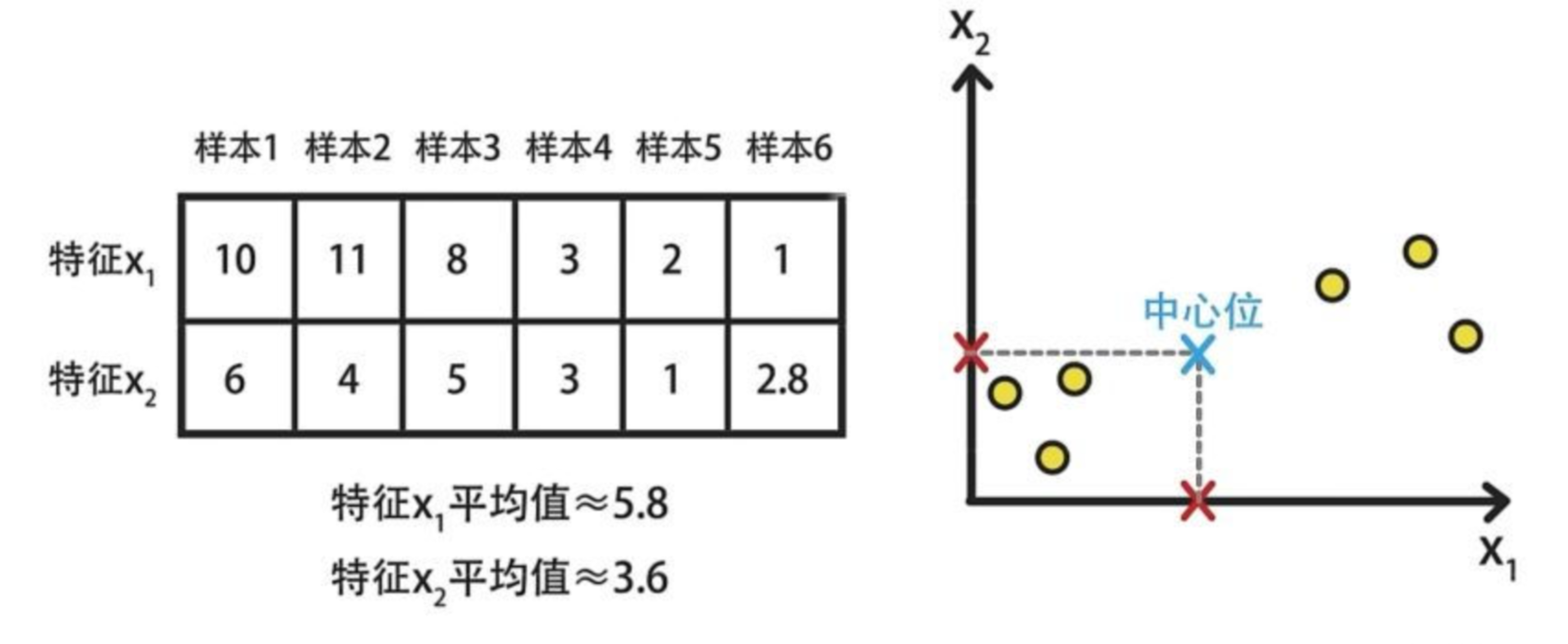
接着,样本对应的值减去均值(中心位移到了原点)实现图像去中心化。
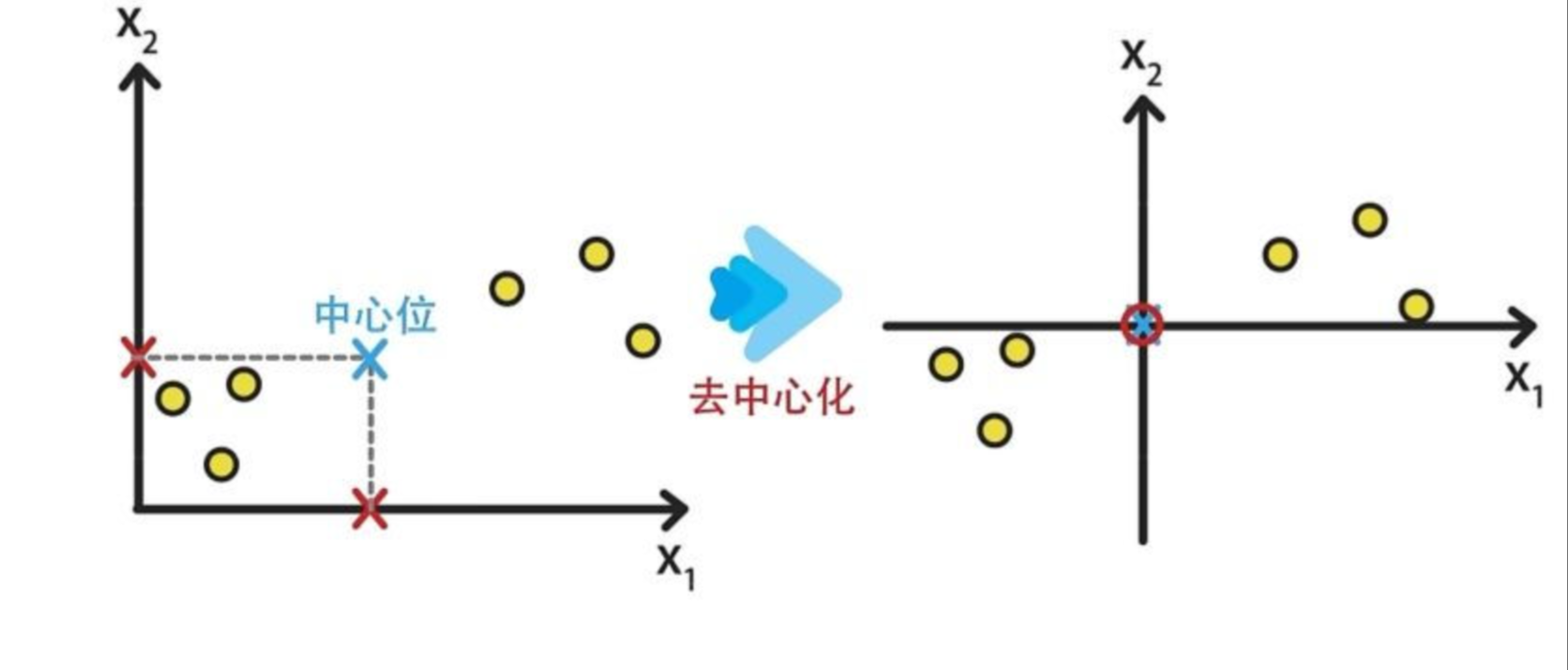
去中心化不会影响样本的分布性质,但会简化PCA算法的推导过程。
(2)计算协方差矩阵
![]()
Cov是一个n*n的矩阵。
计算数据的协方差矩阵,以了解数据特征之间的相关性。
(3)特征值和特征向量计算
求出协方差矩阵的特征值,及对应的特征向量
:
![]()
特征值和特征向量描述了数据在不同方向上的变异程度。
(4)选择主成分
根据特征值的大小,选择前几个最大的特征值对应的特征向量作为主成分。这些特征向量代表了数据中的主要变化方向:
将特征向量按对应特征值从左到右按列降序排列成矩阵,取前k列组成矩阵W(投影矩阵),即阶矩阵。
(5)数据转换
将原始数据通过投影矩阵转换到主成分空间,得到新的数据集。这个新数据集的维度小于原始数据集,但保留了大部分的数据变异性:
通过计算降维到k维后的样本特征,即
阶矩阵。
四、PCA算法代码实现
具体代码如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.datasets import fetch_olivetti_faces
from PIL import Image
import os# 配置matplotlib支持中文显示
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC", "sans-serif"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 1. 加载ORL_Faces数据集
def load_orl_faces(data_dir):"""加载ORL人脸数据集"""faces = []labels = []# 遍历文件夹,假设文件夹结构为:data_dir/sX/Y.pgmfor person_id in range(1, 41):person_dir = os.path.join(data_dir, f"s{person_id}")if not os.path.exists(person_dir):continuefor img_id in range(1, 11):img_path = os.path.join(person_dir, f"{img_id}.pgm")if os.path.exists(img_path):# 读取图像并转为灰度图img = Image.open(img_path).convert('L')# 转为numpy数组并展平为一维向量face_vector = np.array(img).flatten()faces.append(face_vector)labels.append(person_id)return np.array(faces), np.array(labels)# 2. 执行PCA降维
def apply_pca(faces, n_components=15):"""对人脸数据应用PCA降维"""pca = PCA(n_components=n_components)# 拟合PCA模型并转换数据faces_pca = pca.fit_transform(faces)return pca, faces_pca# 3. 可视化主成分(特征脸)
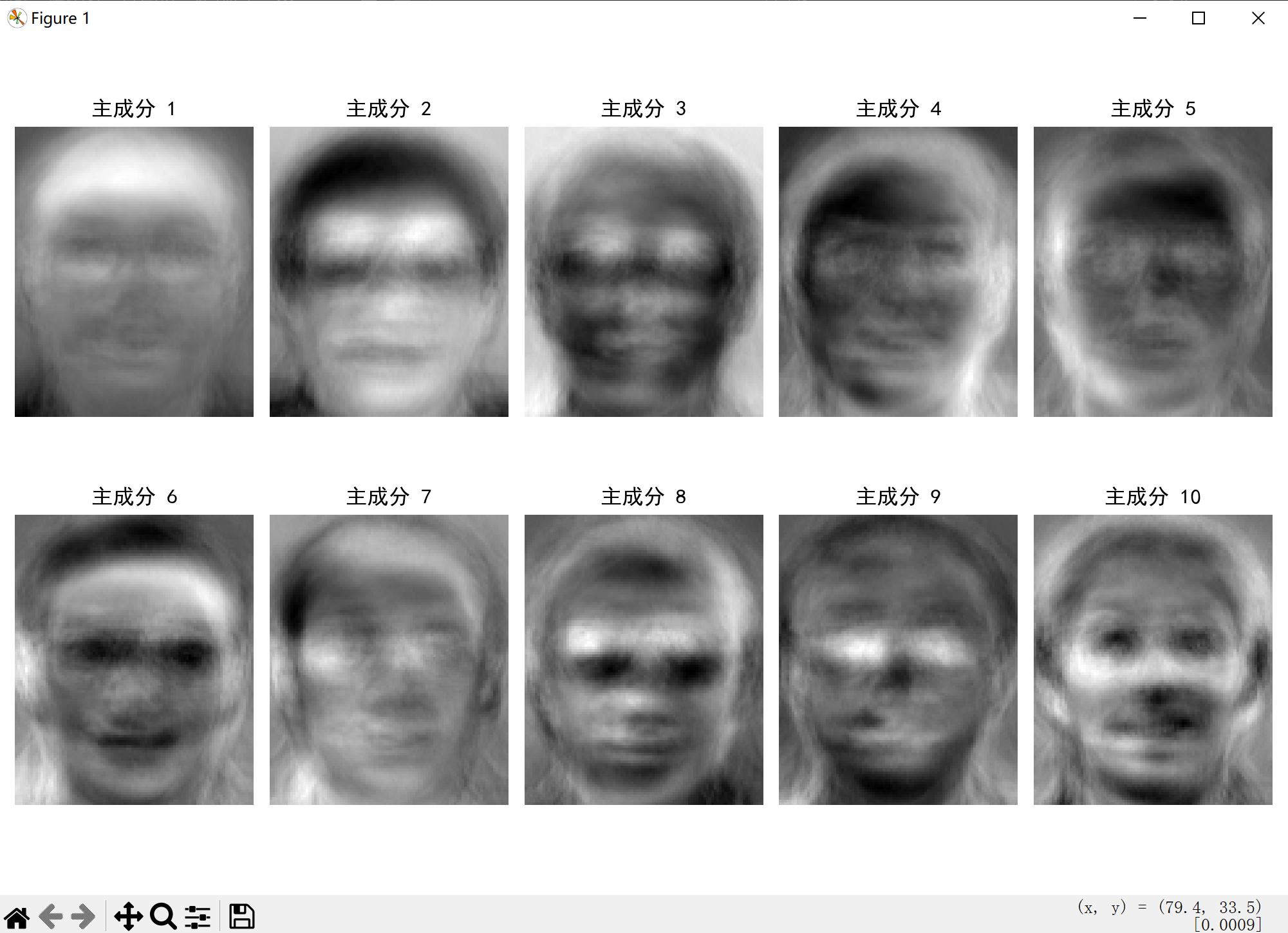
def visualize_principal_components(pca, n_components=10):"""可视化前n个主成分(特征脸)"""plt.figure(figsize=(12, 8))for i in range(n_components):# 将主成分重构为图像形状(假设原始图像为112x92)component = pca.components_[i].reshape(112, 92)plt.subplot(2, 5, i+1)plt.imshow(component, cmap='gray')plt.title(f'主成分 {i+1}')plt.axis('off')plt.tight_layout()plt.show()# 4. 可视化降维后的数据(使用前两个主成分)
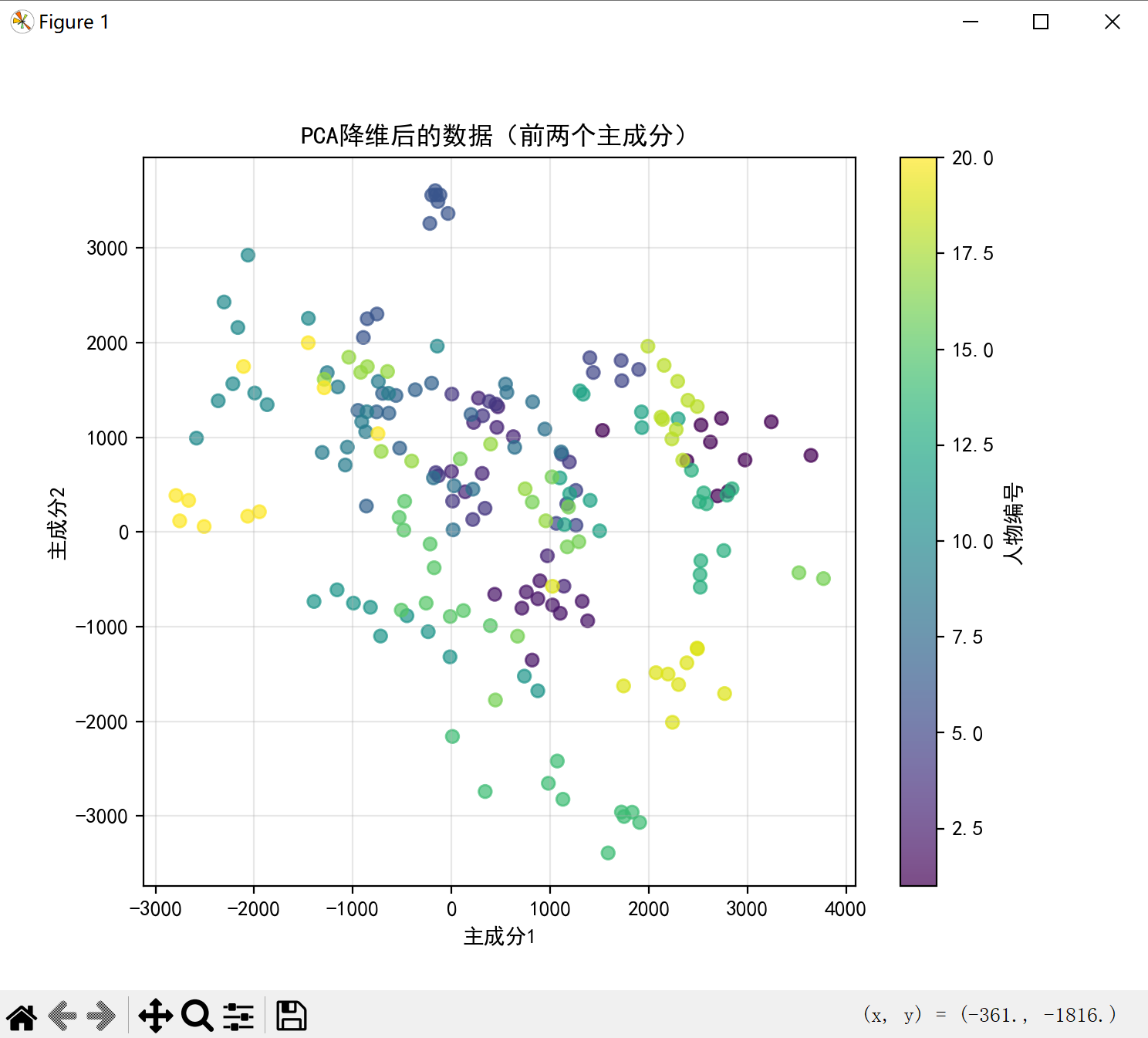
def visualize_reduced_data(faces_pca, labels, n_samples=200):"""使用前两个主成分可视化降维后的数据"""# 只取前n_samples个样本以便可视化if len(faces_pca) > n_samples:faces_pca = faces_pca[:n_samples]labels = labels[:n_samples]plt.figure(figsize=(10, 8))# 使用散点图可视化,不同颜色代表不同人物scatter = plt.scatter(faces_pca[:, 0], faces_pca[:, 1], c=labels, cmap='viridis', alpha=0.7)# 添加图例plt.colorbar(scatter, label='人物编号')plt.title('PCA降维后的数据(前两个主成分)')plt.xlabel('主成分1')plt.ylabel('主成分2')plt.grid(True, alpha=0.3)plt.show()# 5. 计算并可视化方差解释率
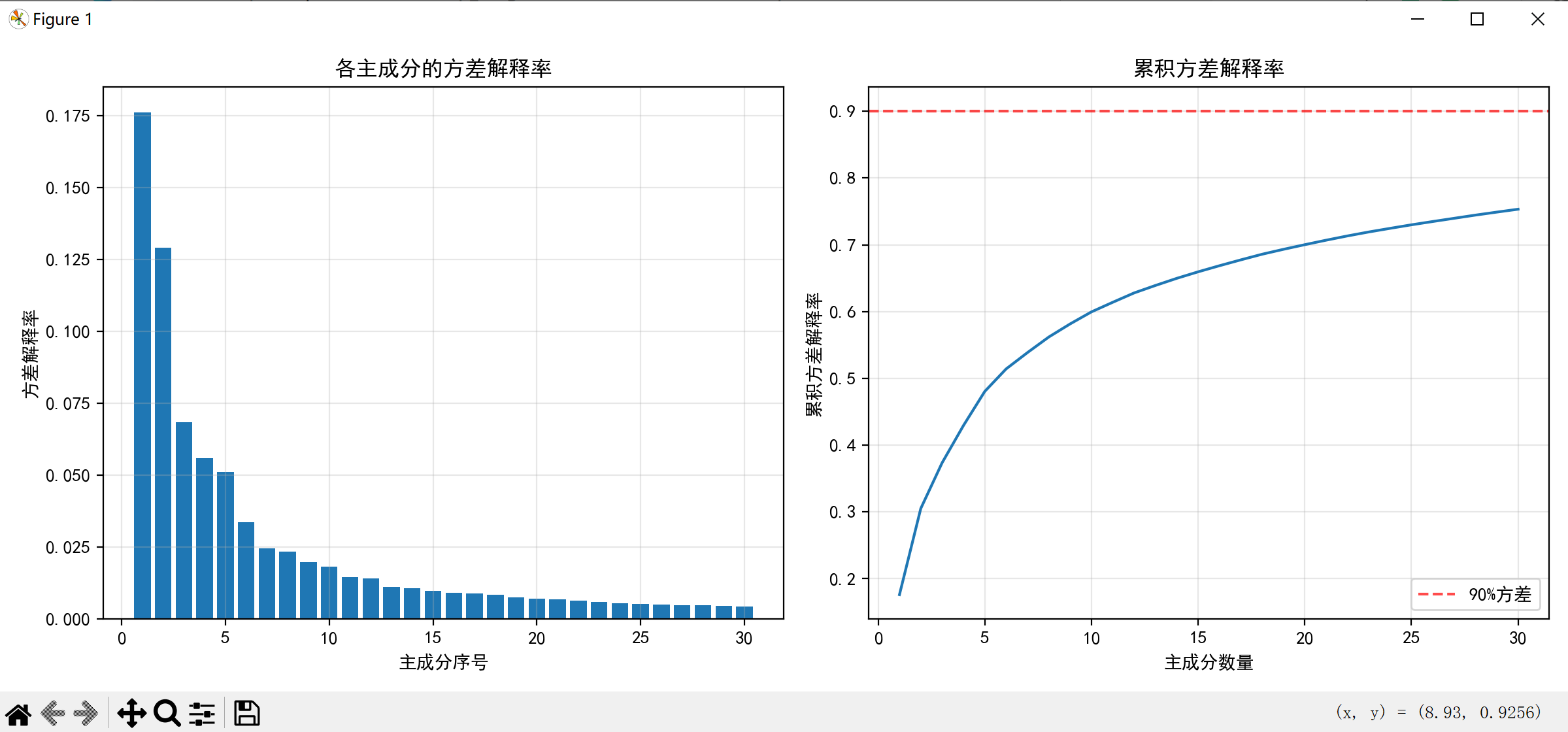
def visualize_variance_explained(pca):"""可视化各主成分的方差解释率及累积方差解释率"""plt.figure(figsize=(12, 5))# 绘制单个主成分的方差解释率plt.subplot(1, 2, 1)plt.bar(range(1, len(pca.explained_variance_ratio_) + 1), pca.explained_variance_ratio_)plt.xlabel('主成分序号')plt.ylabel('方差解释率')plt.title('各主成分的方差解释率')plt.grid(True, alpha=0.3)# 绘制累积方差解释率plt.subplot(1, 2, 2)cumulative_variance = np.cumsum(pca.explained_variance_ratio_)plt.plot(range(1, len(cumulative_variance) + 1), cumulative_variance)plt.xlabel('主成分数量')plt.ylabel('累积方差解释率')plt.title('累积方差解释率')plt.axhline(y=0.9, color='r', linestyle='--', alpha=0.7, label='90%方差')plt.legend()plt.grid(True, alpha=0.3)plt.tight_layout()plt.show()# 主函数
if __name__ == "__main__":# 数据集路径(请根据实际情况修改)data_dir = "ORL_Faces" # 假设ORL_Faces数据集在此目录下# 1. 加载数据print("正在加载ORL人脸数据集...")faces, labels = load_orl_faces(data_dir)print(f"数据加载完成,共{len(faces)}张人脸图像,每张图像维度:{faces.shape[1]}")# 2. 应用PCA降维print("正在执行PCA降维...")pca, faces_pca = apply_pca(faces, n_components=30)print(f"PCA降维完成,降维后维度:{faces_pca.shape[1]}")# 3. 可视化主成分(特征脸)print("可视化主成分(特征脸)...")visualize_principal_components(pca, n_components=10)# 4. 可视化降维后的数据print("可视化降维后的数据...")visualize_reduced_data(faces_pca, labels)# 5. 可视化方差解释率print("可视化方差解释率...")visualize_variance_explained(pca)运行结果如下: