【论文解读】WebThinker:让推理模型学会深度和广度地搜索信息
1st author: Xiaoxi Li - Homepage
paper: [2504.21776] WebThinker: Empowering Large Reasoning Models with Deep Research Capability
code: RUC-NLPIR/WebThinker: 🌐 WebThinker: Empowering Large Reasoning Models with Deep Research Capability
5. 总结 (结果先行)
WebThinker 是一个很有前景的尝试,它试图解决 LRM 在面对复杂、知识密集型任务时深度不足、灵活性不够的问题。通过Deep Web Explorer 实现真正的网页“漫游”和信息“挖掘”,再结合Autonomous Think-Search-and-Draft 策略实现“边想边搜边写”的动态报告生成,确实让 LRM 的研究能力提升了一个档次。
这套框架的设计,特别是将工具使用和决策权交给 LRM 本身,并辅以 RL 进行优化,代表了 RAG 技术发展的一个重要方向:从“辅助增强”走向“自主研究”。这种赋予模型更大自主性和更复杂工具交互能力的思路,无疑是值得关注和借鉴的。它为构建更强大的 AI 研究助手、乃至通用问题解决系统,铺设了一条意义的道路。
1. 思想
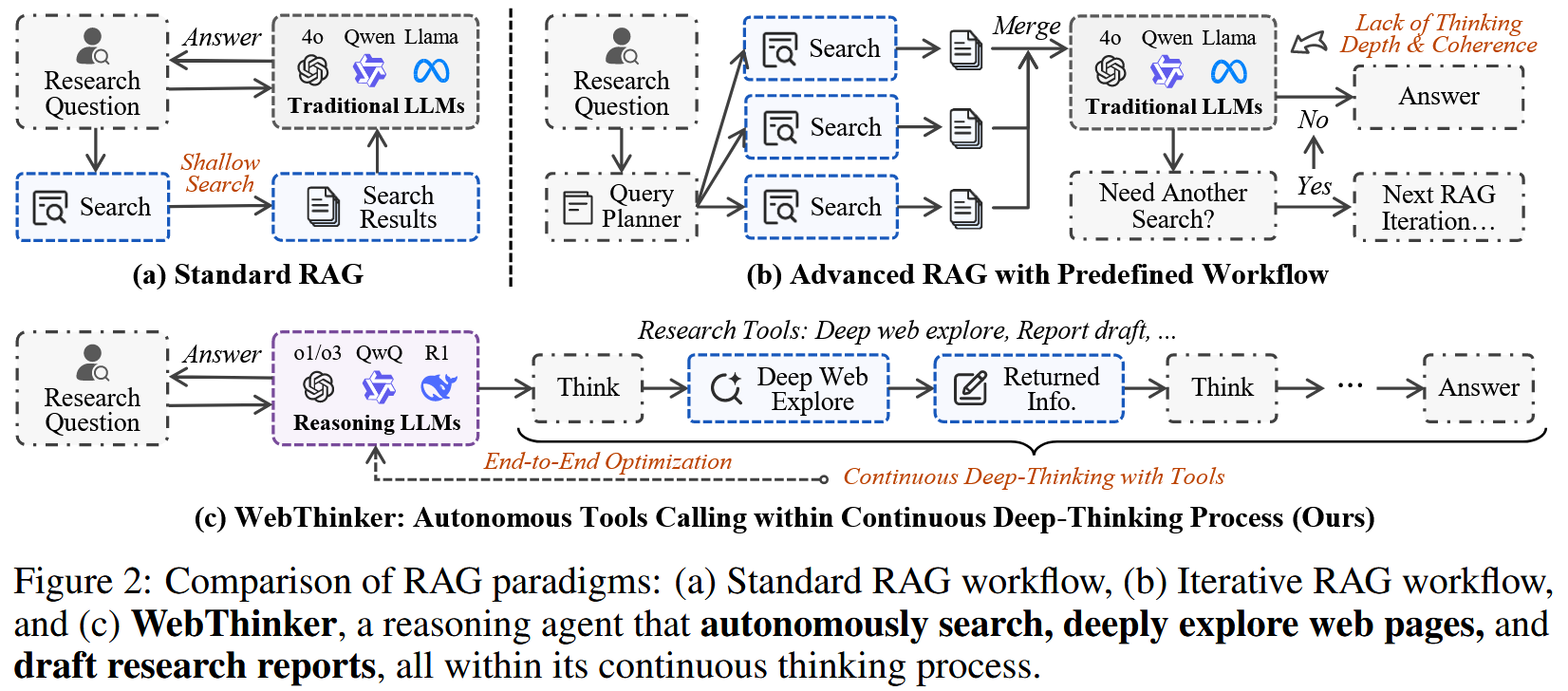
现有的大模型,比如 GPT 系列或者 DeepSeek-R1,推理能力很强,但无法应对需要实时、新鲜、或者非常专门知识的问题。传统的 RAG (Retrieval-Augmented Generation) 方案,往往是先检索一批文档,然后一股脑喂给模型,或者走一些固定的、预设的流程。这种方式有点“死板”,限制了模型探索信息的深度和广度。
WebThinker 的核心思想是:赋予 LRM 自主进行深度研究的能力。什么叫自主?就是模型自己决定什么时候该去网上搜点什么,搜到东西后怎么看、点哪个链接继续看,以及什么时候把看到的东西组织成报告的一部分。不再是“喂料式”的 RAG,而是让模型成为一个带腿(能上网)、带手(能点链接)、带脑子(能思考和写作)的“研究员”。
他们认为,真正的“深度研究”应该是:
- 动态探索 (Dynamic Exploration):能根据当前信息和目标,决定下一步是继续搜索、还是深入浏览某个网页。
- 实时综合 (Real-time Synthesis):不是搜完所有东西再开始写,而是边搜集、边思考、边组织、边写作,动态调整报告内容。
这有点像把 LLM 从一个“知识库查询接口”升级成一个“初级研究助理”。
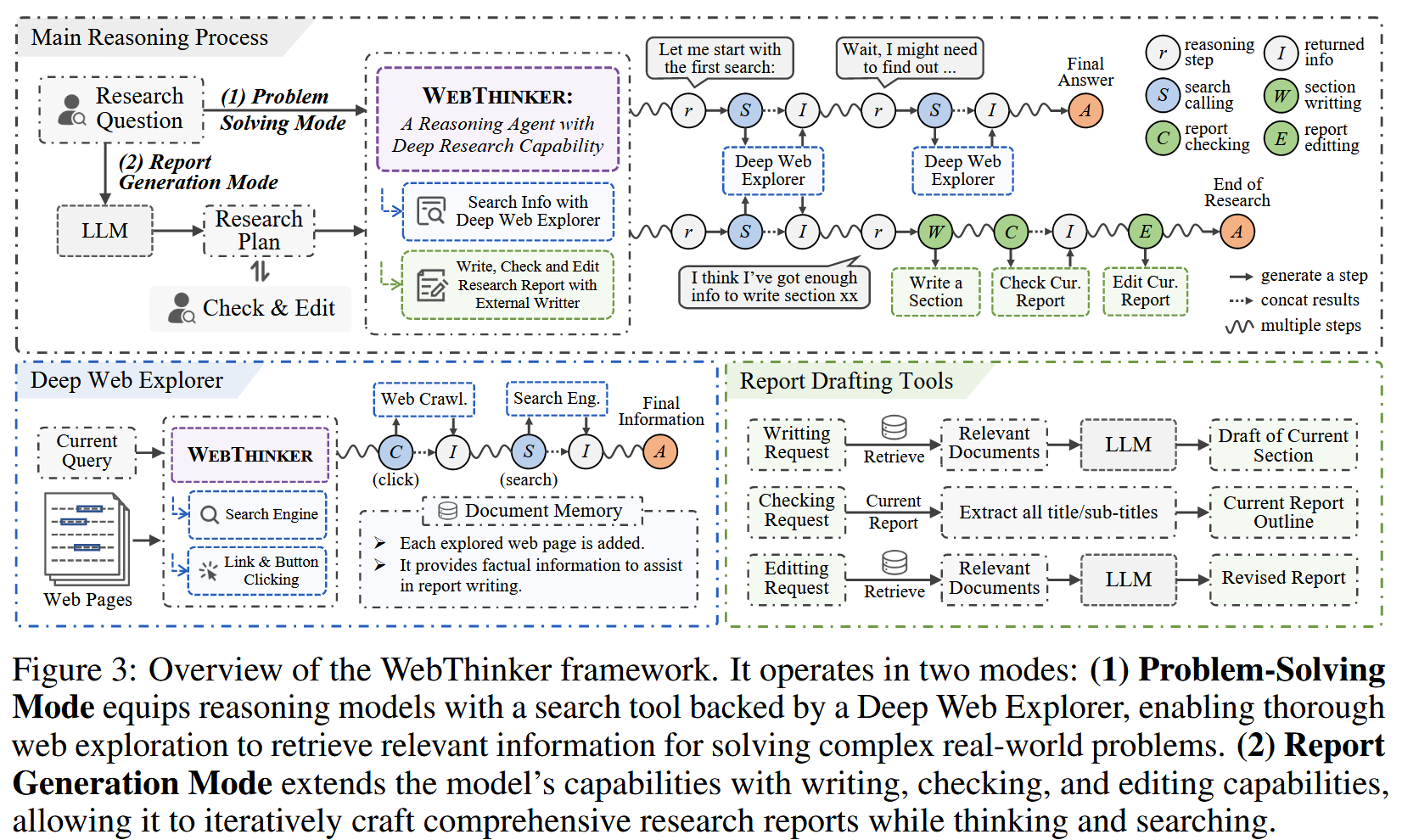
2. 方法
WebThinker 主要通过两个核心模块和一个优化策略来实现其目标:
Deep Web Explorer (深度网络探索器)
这是 WebThinker 的“腿”和“眼”,它不是简单地抓取搜索结果,而是让 LRM 主动去“冲浪”和“挖掘”。当主 LRM 在推理过程中遇到知识缺口时,它会调用 Deep Web Explorer。这个 Explorer 本身也是一个 LRM,它被赋予了两种基本工具:
- 搜索引擎 ( T s T_s Ts):调用外部搜索引擎(比如 Bing)获取初步的网页列表。
- 导航工具 ( T n T_n Tn):模拟点击网页上的链接或按钮,获取更深层次的页面内容 (用 Crawl4AI 实现)。
而且,这里的探索过程是分层和递归的:
- 主 LRM 遇到问题,生成一个子查询 q s q_s qs,交给 Deep Web Explorer。
- Deep Web Explorer 内部会进行自己的“思考-搜索-导航”循环:它会分析当前查询 q s q_s qs 和已获取的网页内容 D t D_t Dt (其中 D t D_t Dt 表示在探索步骤 t t t 时可用的网页内容,这个内容会随着导航动作而动态变化),决定是进行新的搜索,还是点击某个链接。
- 这个内部循环会持续,直到 Explorer 认为收集到了足够的信息,然后它会生成一个简洁的输出 O e x p O_{exp} Oexp 返回给主 LRM。
形式上,Explorer 的探索过程可以表示为:
P ( R e , O e x p ∣ q s , D , I e ) = ( ∏ t = 1 T e P ( R e , t ∣ R e , < t , q s , D t , I e ) ) ⋅ P ( O e x p ∣ R e , q s , D , I e ) P(R_e, O_{exp} | q_s, D, I_e) = \left( \prod_{t=1}^{T_e} P(R_{e,t} | R_{e,<t}, q_s, D_t, I_e) \right) \cdot P(O_{exp} | R_e, q_s, D, I_e) P(Re,Oexp∣qs,D,Ie)=(t=1∏TeP(Re,t∣Re,<t,qs,Dt,Ie))⋅P(Oexp∣Re,qs,D,Ie)
其中:
- R e R_e Re 是 Explorer 内部的推理链 (reasoning chain),由 T e T_e Te 个 token R e , t R_{e,t} Re,t 组成。
- O e x p O_{exp} Oexp 是 Explorer 最终提炼出的信息。
- q s q_s qs 是主 LRM 给 Explorer 的子查询。
- D D D 是初始网页内容 (可能为空)。
- I e I_e Ie 是给 Explorer 的特定指令。
- R e , < t R_{e,<t} Re,<t 表示在生成 R e , t R_{e,t} Re,t 之前已生成的所有 token。
- D t D_t Dt 是在 Explorer 内部推理步骤 t t t 时可用的网页内容,它会根据之前的搜索和导航动作动态更新。
Autonomous Think-Search-and-Draft (自主思考-搜索-草稿策略)
这是 WebThinker 的“写作大脑”。它将报告写作过程与信息搜集和推理过程融合,实现“边想边写”。主 LRM 除了可以调用 Deep Web Explorer ( T e x p T_{exp} Texp) 外,还配备了一套报告写作工具 T w r i t e = { T d r a f t , T c h e c k , T e d i t } T_{write} = \{T_{draft}, T_{check}, T_{edit}\} Twrite={Tdraft,Tcheck,Tedit}:
- T d r a f t T_{draft} Tdraft:草拟特定章节内容。
- T c h e c k T_{check} Tcheck:检查当前报告的结构和完整性 (比如返回大纲)。
- T e d i t T_{edit} Tedit:编辑已有报告内容。
一个巧妙的设计是,这些写作工具的底层实现是另一个辅助 LRM (assistant LLM)。这样做的好处是,主 LRM 负责高层级的任务编排 (决定什么时候写哪部分、什么时候检查、什么时候修改),而具体的文本操作则交给辅助 LRM。这避免了主 LRM 的思考流被繁琐的文本编辑打断。
所有通过 Deep Web Explorer 探索到的网页内容都会被存入一个文档记忆库 (Document Memory, M M M)。当主 LRM 调用写作工具时 (比如 T d r a f t T_{draft} Tdraft),它会生成一个编辑指令 e e e,辅助 LRM 会接收这个指令 e e e、当前的报告状态 r r r (可能是报告的某个片段或大纲) 以及从 M M M 中检索到的相关文档 D t o p − k D_{top-k} Dtop−k,然后生成更新后的报告内容 r n e w r_{new} rnew。
更新报告内容的概率可以表示为:
P ( r n e w ∣ e , D t o p − k , r ) = ∏ t = 1 T r n e w P ( r n e w , t ′ ∣ r n e w , < t ′ , e , D t o p − k , r ) P(r_{new} | e, D_{top-k}, r) = \prod_{t=1}^{T_{r_{new}}} P(r'_{new,t} | r'_{new,<t}, e, D_{top-k}, r) P(rnew∣e,Dtop−k,r)=t=1∏TrnewP(rnew,t′∣rnew,<t′,e,Dtop−k,r)
其中 r n e w , t ′ r'_{new,t} rnew,t′ 是新报告内容 r n e w r_{new} rnew 中的第 t t t 个 token。
整个研究和报告生成过程,从主 LRM 的视角看,是生成一个思考链 R R R 直到产生结束标记 y e n d y_{end} yend:
P ( R , y e n d ∣ I , q ) = ( ∏ t = 1 T R P ( R t ∣ R < t , I , q , { O e x p } j < i ( t ) ) ) ⋅ P ( y e n d ∣ R , M ) P(R, y_{end} | I, q) = \left( \prod_{t=1}^{T_R} P(R_t | R_{<t}, I, q, \{O_{exp}\}_{j<i(t)}) \right) \cdot P(y_{end} | R, M) P(R,yend∣I,q)=(t=1∏TRP(Rt∣R<t,I,q,{Oexp}j<i(t)))⋅P(yend∣R,M)
其中:
- R R R 是主 LRM 的推理和行动链,由 T R T_R TR 个 token R t R_t Rt 组成。
- I I I 和 q q q 分别是初始指令和用户查询。
- { O e x p } j < i ( t ) \{O_{exp}\}_{j<i(t)} {Oexp}j<i(t) 是在生成 R t R_t Rt 之前所有 Deep Web Explorer 调用返回的结果集合。
- 报告状态 r r r 并没有直接作为输入条件出现在主 LRM 的生成步骤中,而是通过主 LRM 的推理链 R R R (比如记录了已完成哪些章节) 和可用的上下文来隐式跟踪。文档记忆库 M M M 作为辅助 LRM 执行写作操作的知识基础。
这个策略的是迭代和实时性,报告是逐步完善的,而不是一次性生成。
RL-based Training Strategy (基于强化学习的训练策略)
为了让 LRM 更有效地使用这些研究工具 (包括 Deep Web Explorer 内部的工具和主 LRM 的报告写作工具),他们采用了基于强化学习的在线 DPO (Direct Preference Optimization) 策略。
- 偏好数据构建:首先用初始的 LRM 在各种复杂任务上采样大量的推理轨迹。然后根据最终答案的正确性/报告质量、工具使用的效率(调用次数越少越好)、思考的简洁性(在工具调用次数和结果都相同的情况下,输出短的轨迹更好)等标准,构建偏好对 ( R w , R l ) (R_w, R_l) (Rw,Rl),其中 R w R_w Rw 是好的轨迹, R l R_l Rl 是差的轨迹。
- 迭代在线 DPO 训练:用标准的 DPO损失函数进行训练,目的是提高 R w R_w Rw 的概率,降低 R l R_l Rl 的概率。这个过程是迭代的、在线的:训练好的模型再去采样新的轨迹,构建新的偏好数据,然后继续训练。
这样就能让模型用起工具来更“熟练”。
3. 优势
- 真正的深度探索:Deep Web Explorer 不仅仅是关键词匹配,它能模拟人一样点击链接、深入浏览,从而获取更隐藏、更专门的信息。
- 动态与迭代的报告生成:Autonomous Think-Search-and-Draft 策略使得报告写作不再是割裂的“先搜后写”,而是更加自然、实时的“边搜边想边写”,报告内容会随着新的发现而不断演进和完善。
- 高度的自主性和灵活性:LRM 自身决定何时搜索、何时导航、何时写作,而不是遵循固定的工作流。这使得 WebThinker 能够适应更复杂的、开放式的研究任务。
- 可解释的推理过程:由于整个过程是 LRM 的思考链驱动的,理论上可以更好地理解模型是如何一步步得到最终结果或报告的。
4. 实验
作者在多个任务上对 WebThinker 进行了评估:
- 复杂问题解决:用了 GPQA (博士级别科学问答)、GAIA (通用 AI 助手评估)、WebWalkerQA (深度网页信息检索)、HLE (Humanity’s Last Exam,极难的跨学科问题)。
- 科研报告生成:用了 Glaive 数据集上的开放式问题。
主要发现:
- WebThinker 全面超越:在所有任务上,WebThinker (特别是经过 RL 优化的版本 WebThinker-32B-RL) 均显著优于传统的 RAG 方法、仅使用内部知识的 LRM,以及一些已有的开源搜索增强框架 (如 Search-o1)。甚至在某些指标上超过了像 OpenAI Deep Research、Grok3 DeeperSearch 和 Gemini2.0 Deep Research 这样的闭源系统。
- Deep Web Explorer 至关重要:消融实验表明,移除 Deep Web Explorer 会导致性能大幅下降,证明了深度网页探索的必要性。仅禁用链接点击功能也会影响导航密集型任务的性能。
- Autonomous Think-Search-and-Draft 效果显著:对于报告生成任务,移除自主草稿功能会导致报告质量严重下降。禁用检查和编辑工具也会降低报告的连贯性等指标。
- RL 训练有效:RL 优化后的模型在复杂问题解决任务上表现更好,说明 DPO 确实提升了模型使用工具的能力。
- 对不同 LRM 基座的适应性:他在不同大小的 DeepSeek-R1 模型上验证了 WebThinker 框架的有效性,结果表明该框架具有良好的通用性。