【大模型原理与技术-毛玉仁】第四章 参数高效微调
4 参数高效微调
4.1 参数高效微调简介
下游任务适配

对于预训练数据涉及较少的垂直领域,大语言模型需要对这些领域及相应的下游任务进行适配。上下文学习和指令微调是进行下游任务适配的有效途径,但它们在效果或效率上存在缺陷。为弥补这些不足,参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)技术应运而生。



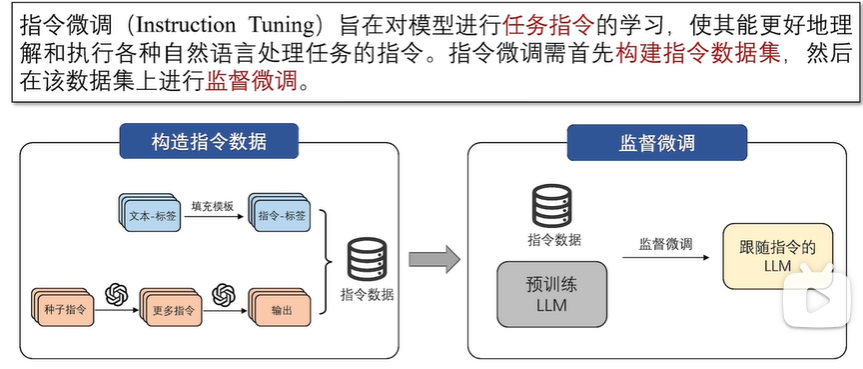
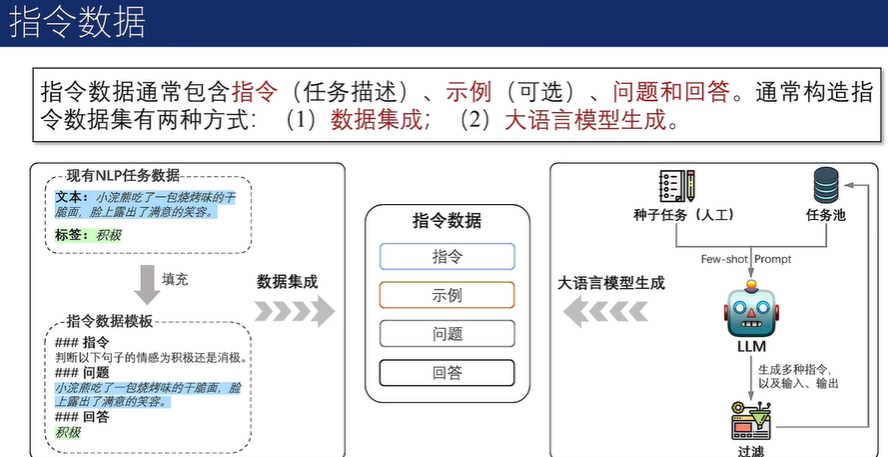
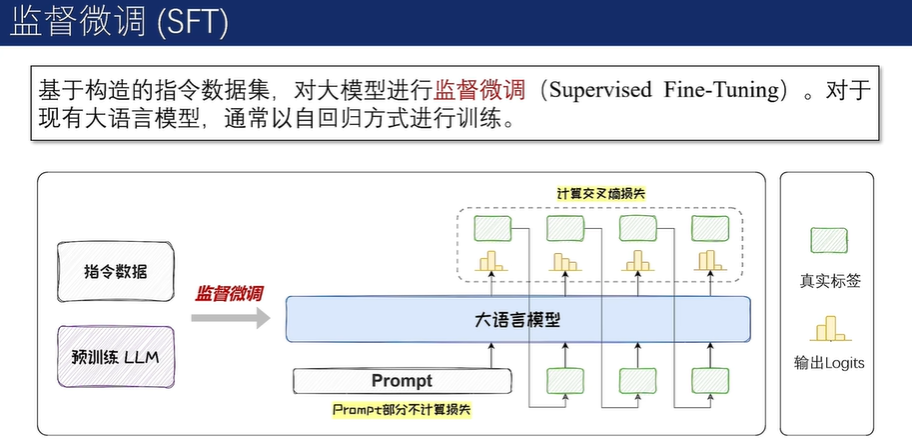
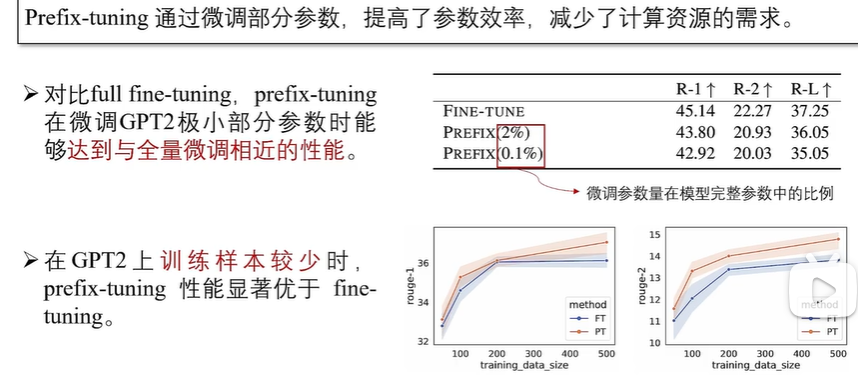
通过上述方法构建完数据集后,可以用完全监督的方式对预训练模型进行微调,在给定指令和输入的情况下,通过顺序预测输出中的每个token来训练模型。

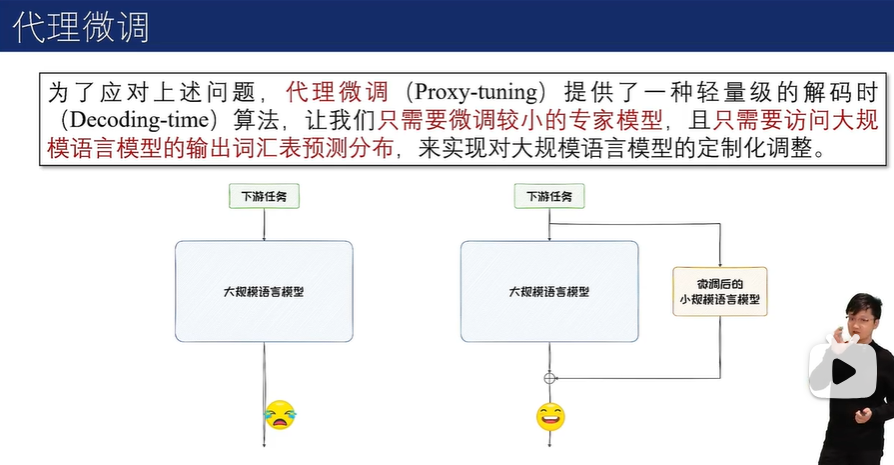
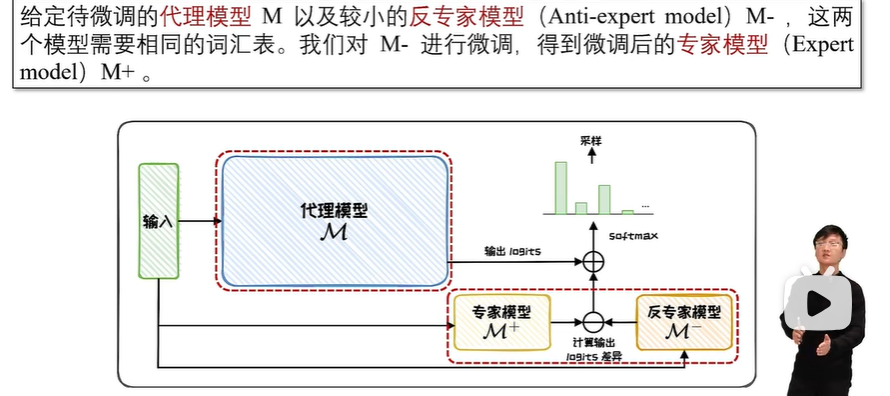
参数高效微调
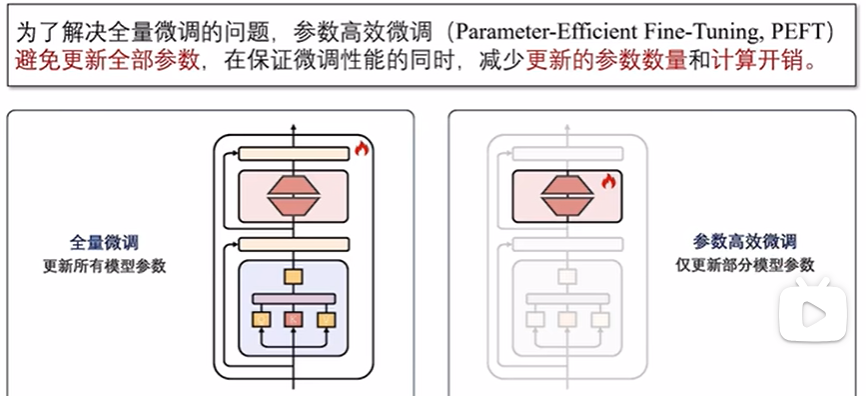
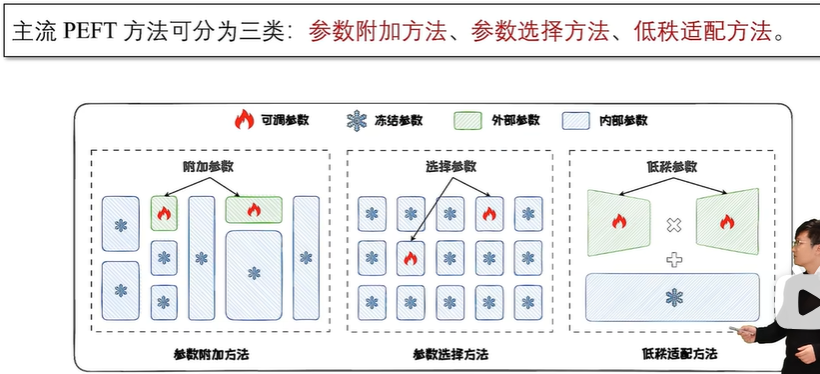
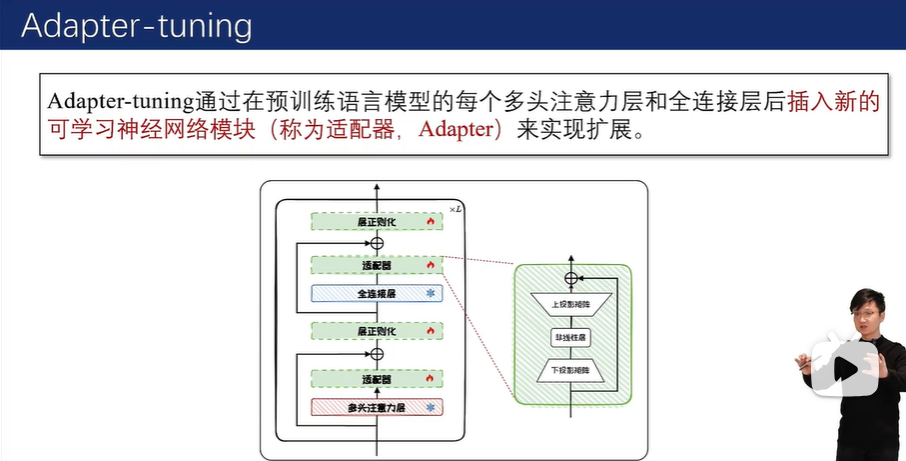
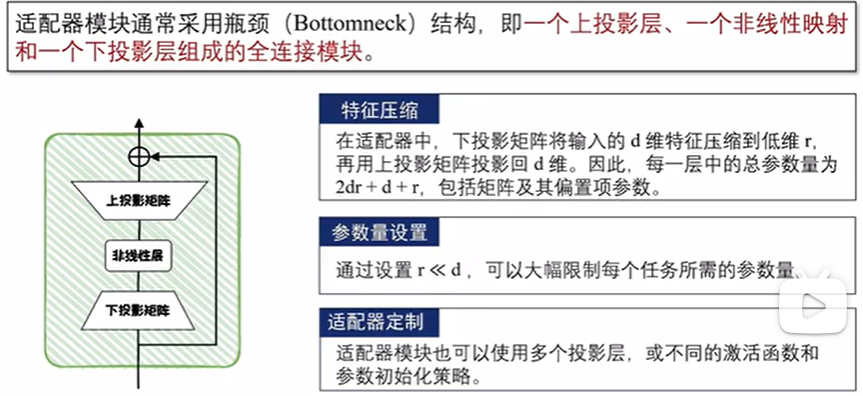
参数附加方法(Additional Parameters Methods)在模型结构中附加新的、较小的可训练模块。在进行微调时,将原始模型参数冻结,仅微调这些新加入的模块,从而来实现高效微调;
参数选择方法(Parameter Selection Methods)仅选择模型的一部分参数进行微调,而冻结其余参数;
低秩适配方法(Low-rank Adaptation Methods)通过低秩矩阵来近似原始权重更新矩阵,并冻结原始参数矩阵,仅微调低秩更新矩阵。
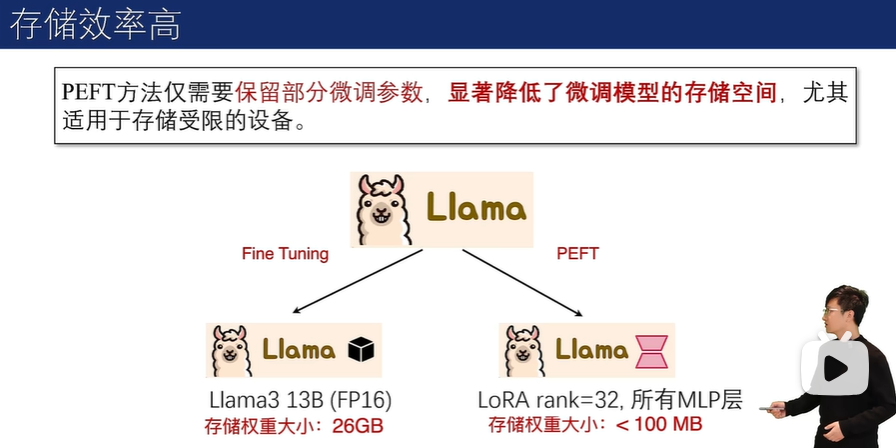
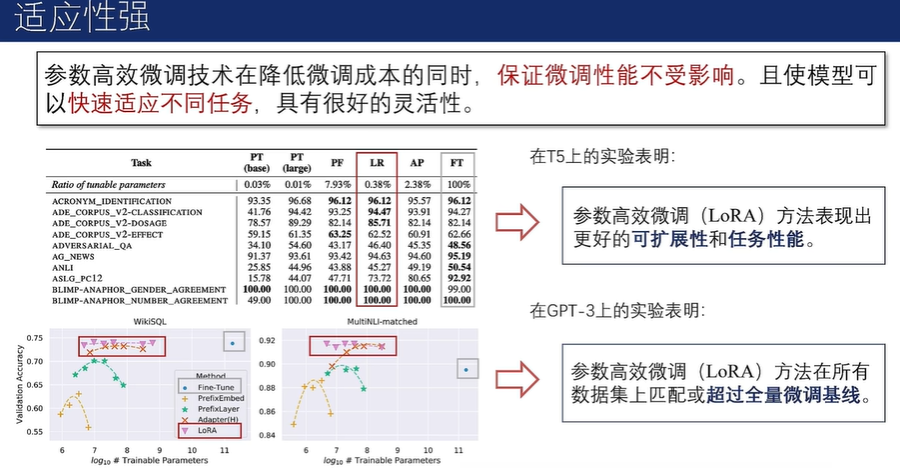
参数高效微调的优势


4.2 参数附加方法
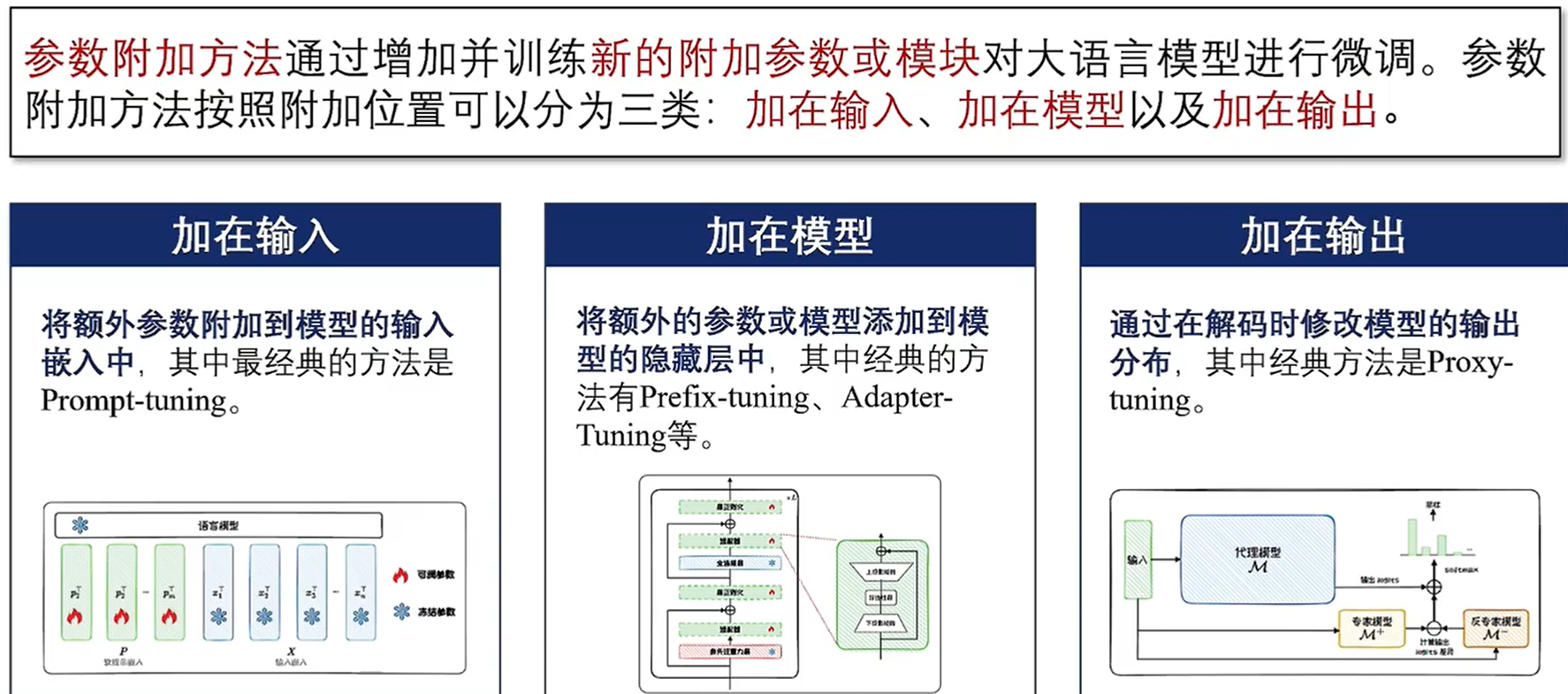
加在输入
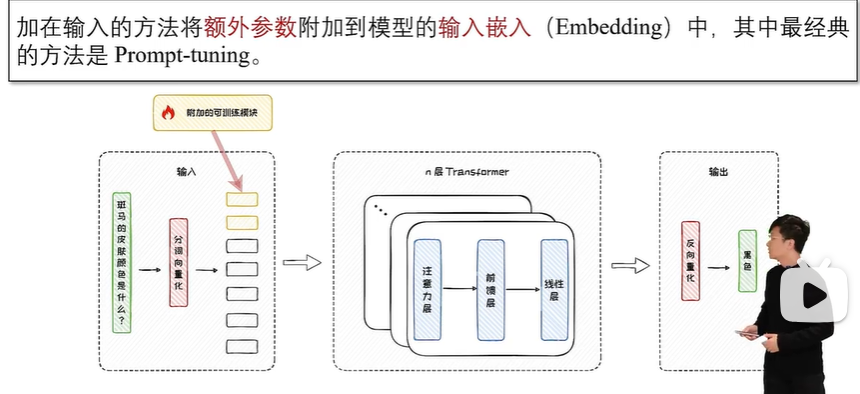

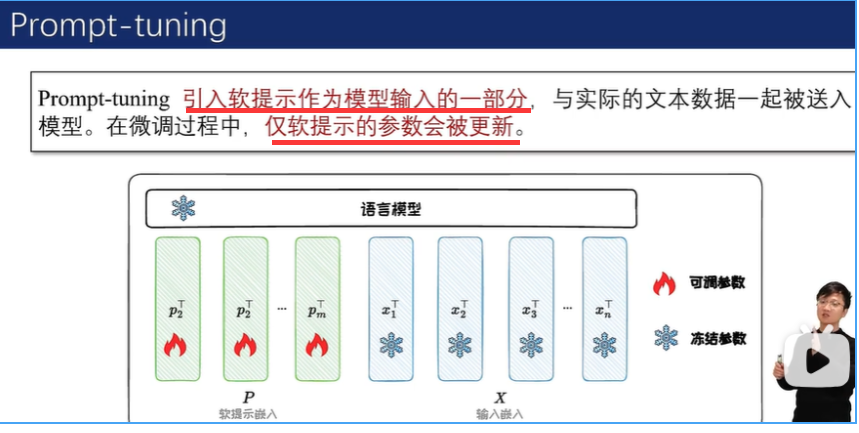


加在模型
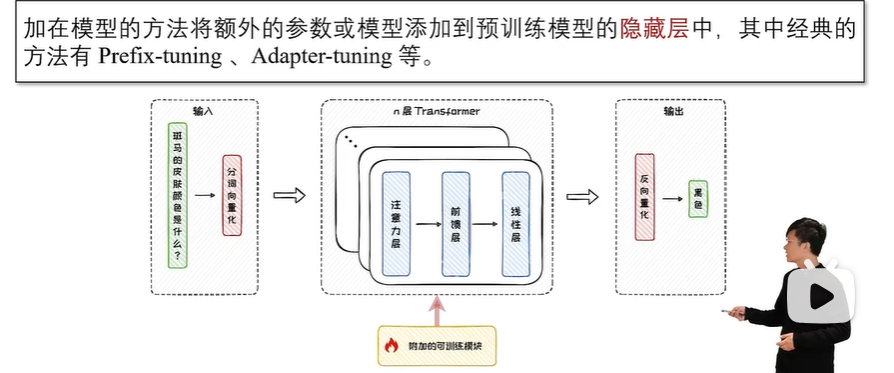
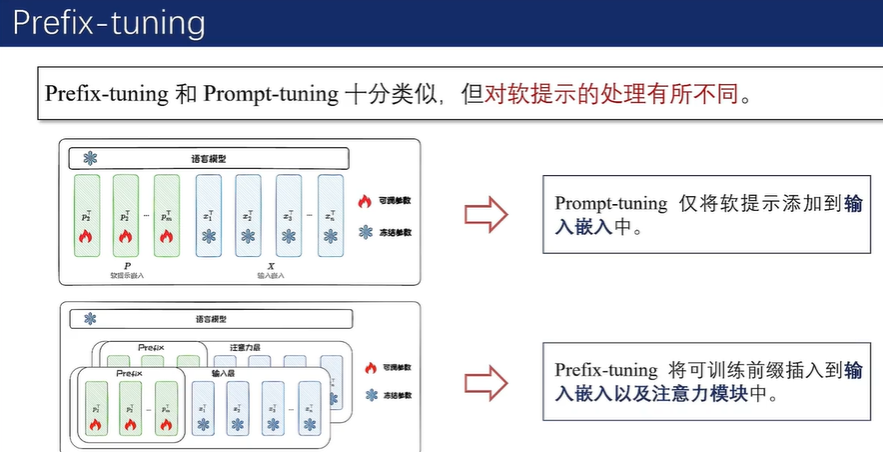
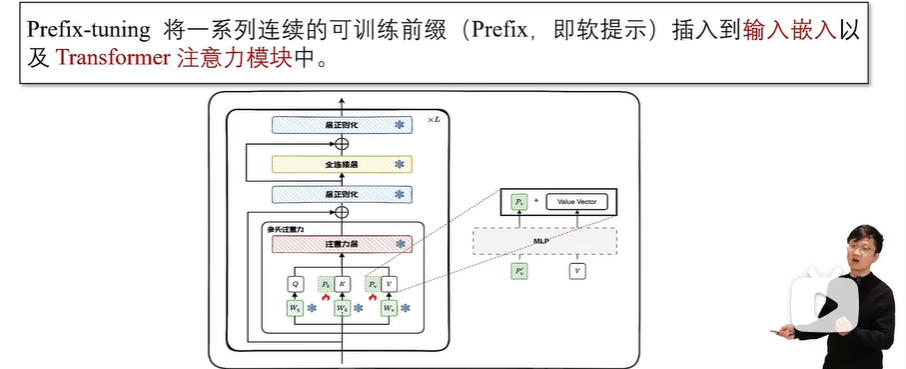
在实际应用中,通常需要在输入 Transformer 模型前,先通过一个多层感知机(MLP)进行重参数化。这意味着需要训练的参数包括MLP和前缀矩阵两部分。训练完成后,MLP的参数会被丢弃,仅保留前缀参数。
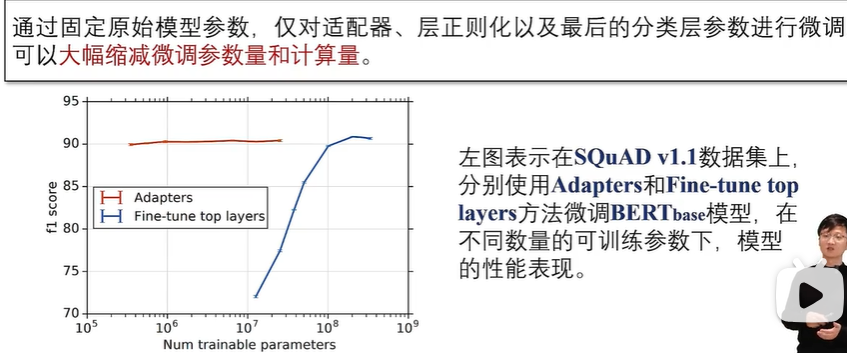

加在输出



三种参数附加方法小结

4.3 参数选择方法

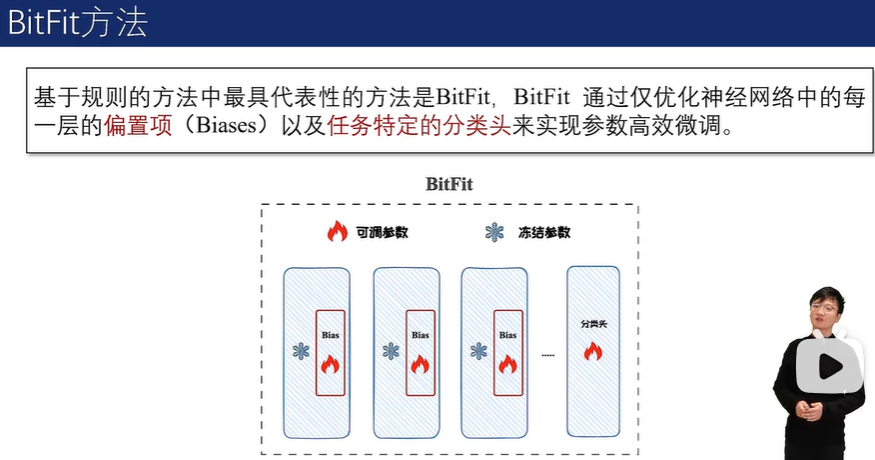
基于规则的方法


基于学习的方法
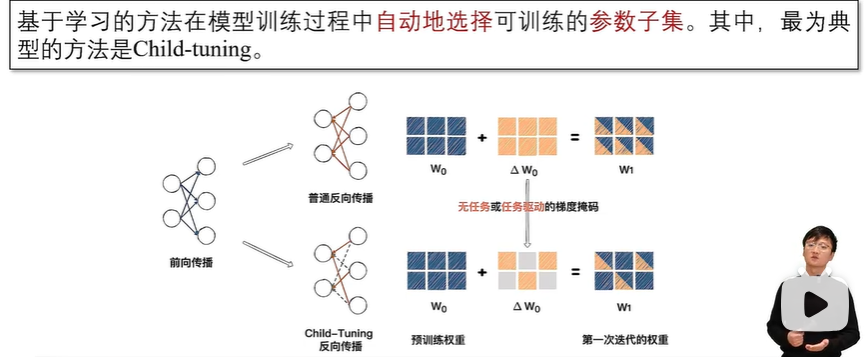


参数选择方法优缺点

4.4 低秩适配方法


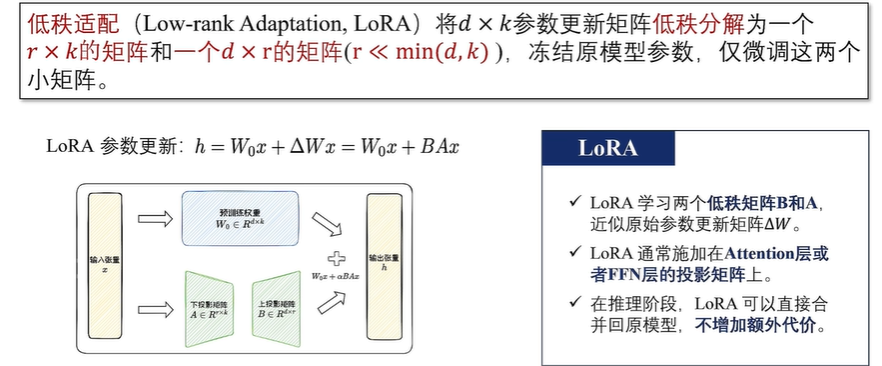
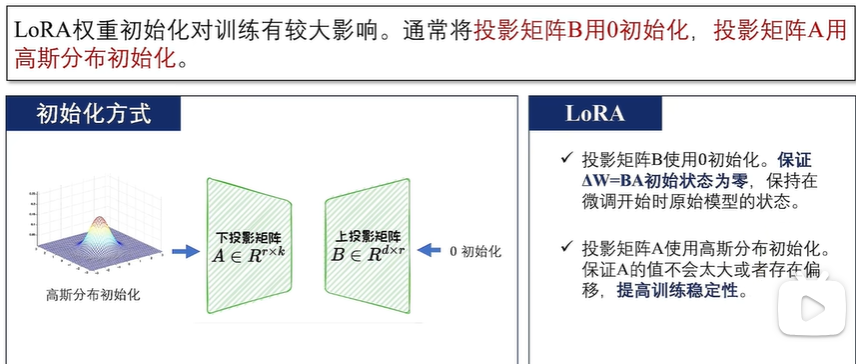
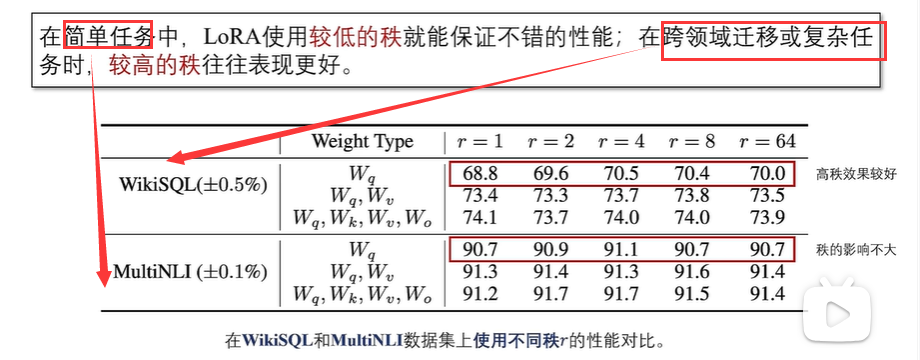
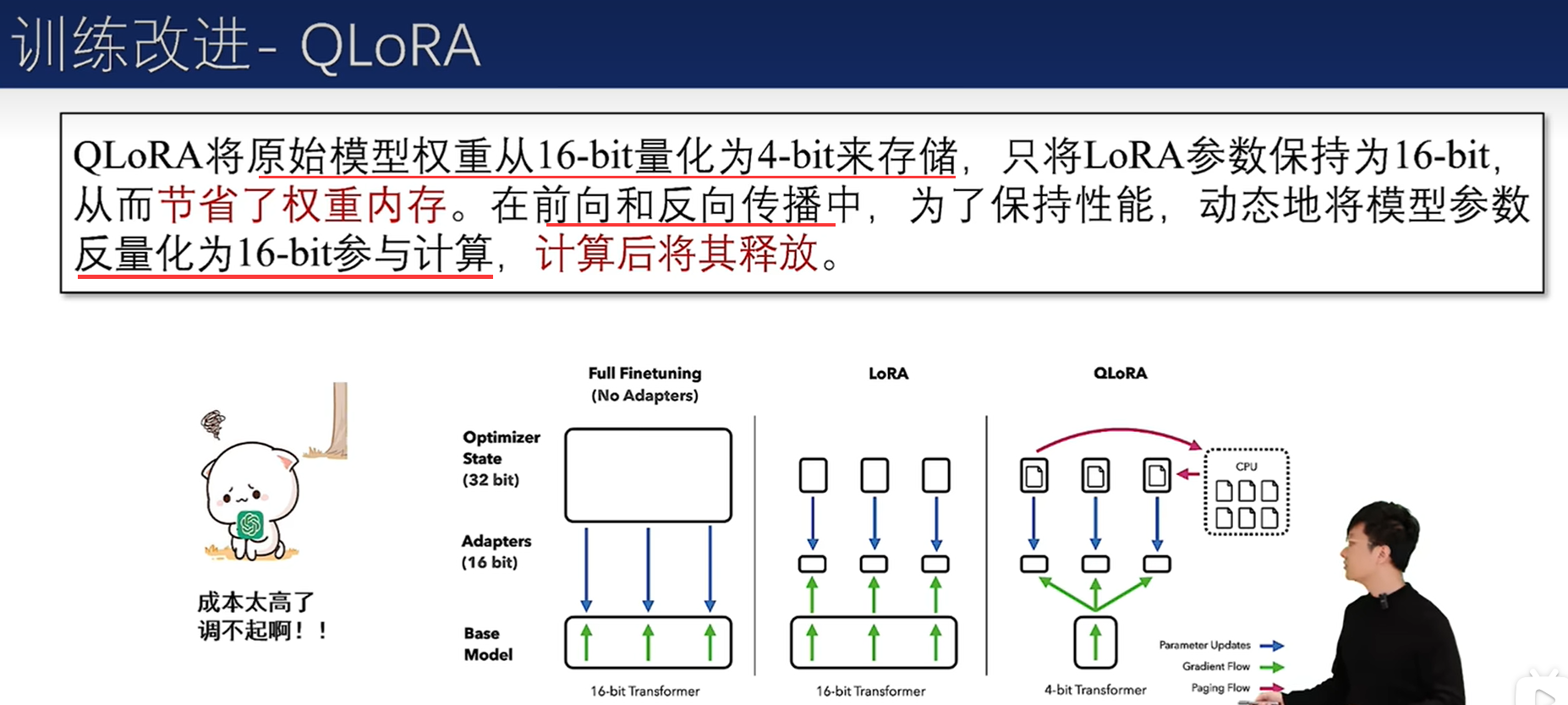
LoRA

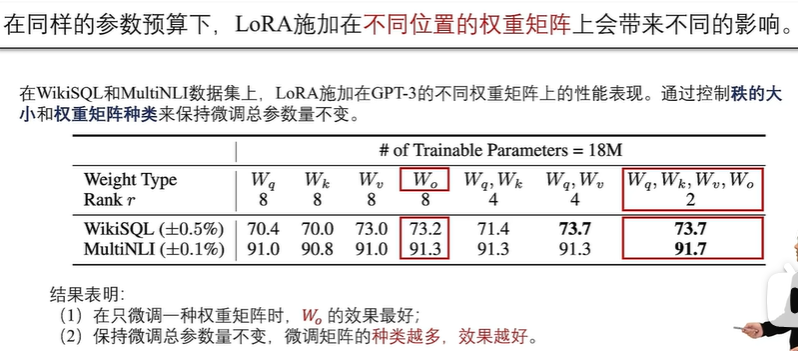
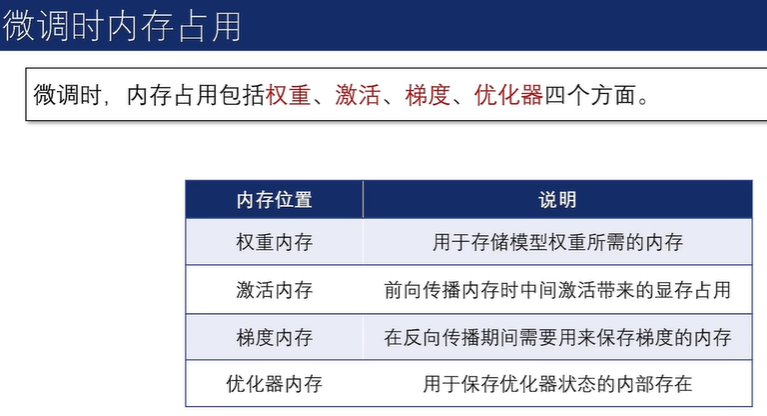
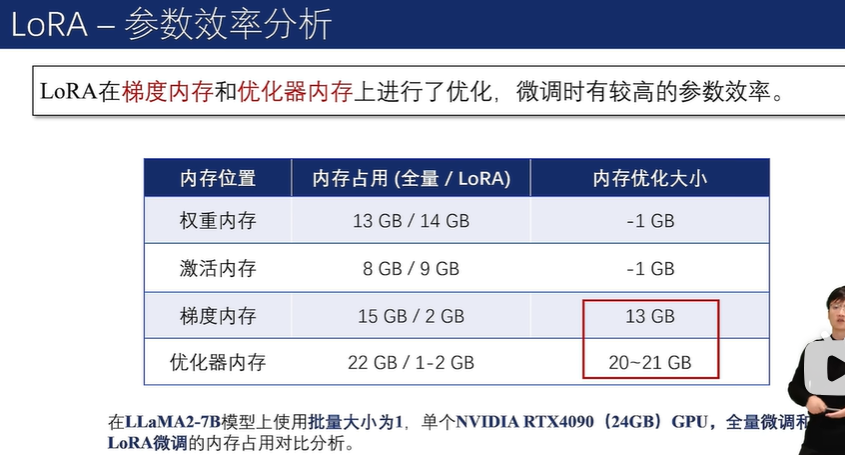
由于可训练参数较少,优化器内存和梯度内存分别减少了约 25GB 和 14GB。
另外,虽然 LoRA 引入了额外的 “增量参数”,导致激活内存和权重内存略微增加(总计约2GB),但考虑到整体内存的减少,这种增加是可以忽略不计的。
此外,减少涉及到的参数计算可以加速反向传播。与全量微调相比,LoRA 的速度提高了 1.9 倍。

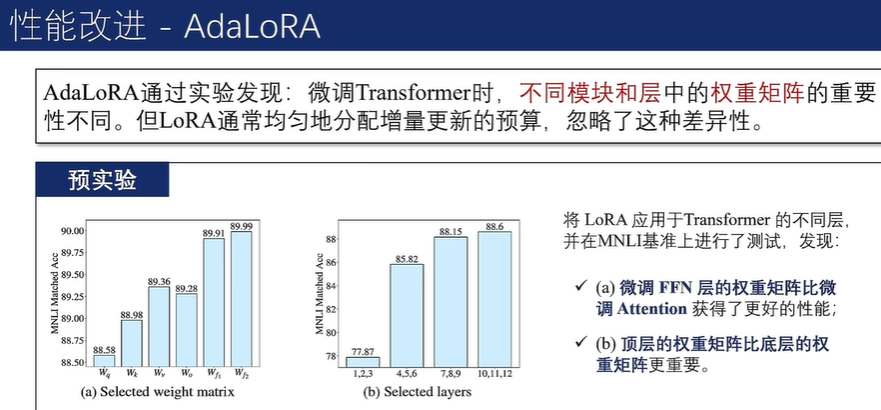
LoRA相关变体


奇异值分解的思想就是:把一个复杂矩阵分解成两个正交矩阵和一个对角矩阵相乘,来清晰地展示出矩阵本身的本质信息。对角矩阵的对角线上元素称为该复杂矩阵的奇异值。
奇异值的含义:
- 矩阵的奇异值代表了矩阵沿不同方向的 “重要程度”或“信息强度” 。
- 一般从大到小排序,较大的奇异值表示更显著的信息量。
矩阵的秩,就是矩阵中有效信息的多少。奇异值恰好表示了矩阵的信息量,因此:复杂矩阵的秩就等于它的奇异值中非零奇异值的个数。
根据梯度权重乘积大小的移动平均值构造奇异值的重要性得分,对不重要的奇异值进行迭代剪枝。
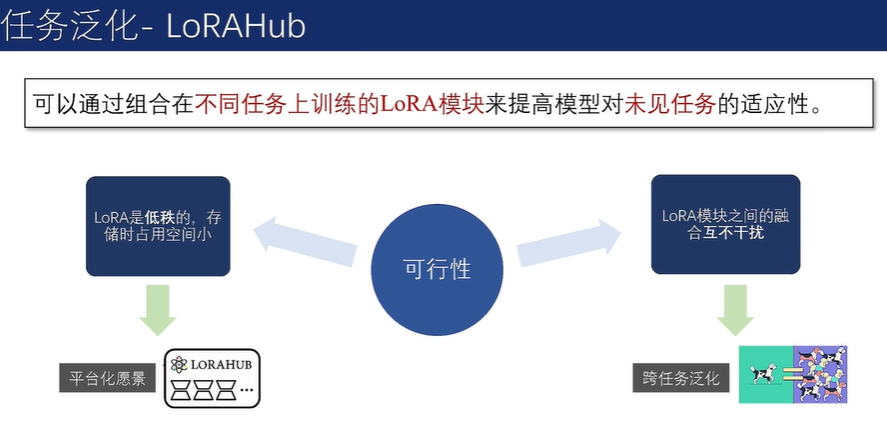
基于LoRA插件的任务泛化
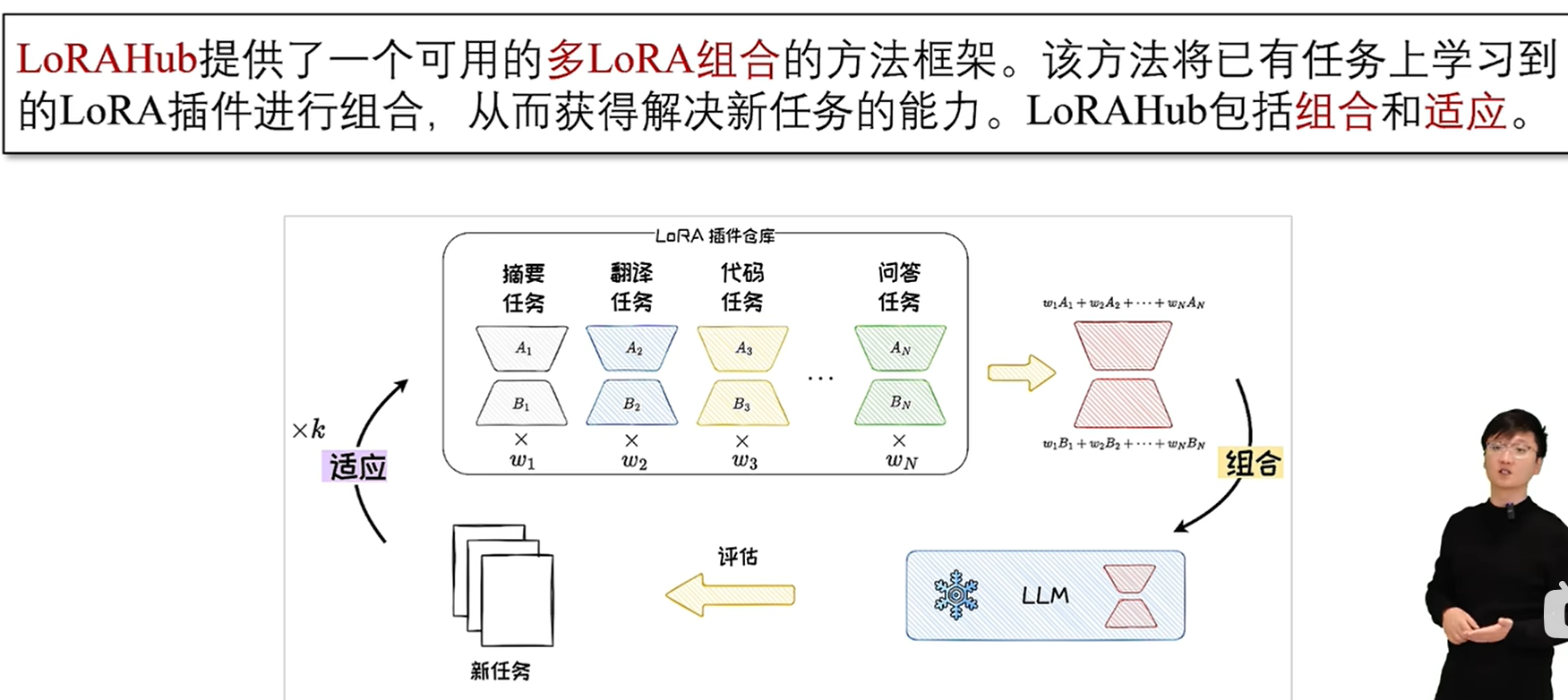
在组合阶段,LoRAHub 将已学习的 LoRA 模块通过逐元素线性加权组合为单一模块。
![]()
在适应阶段,给定一些新任务的示例,通过无梯度方法Shiwa自适应地学习权重组合。
适应和组合经过k 次迭代,直至找到最优的权重组合,以完成对新任务的适应。
4.5 参数高效微调的应用

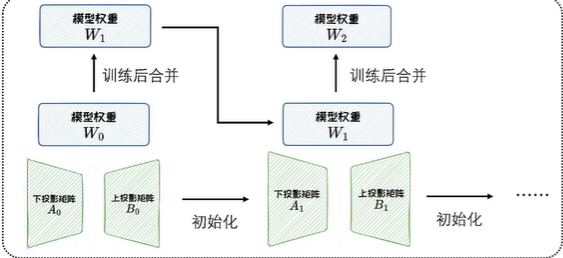
ReLoRA方法:ReLoRA在LoRA的基础上,通过多次重启(每隔一定训练步数将低秩矩阵与模型权重合并,并重新初始化生成新的低秩矩阵)来得到更好的训练效果。这种方法可以用于continue training继续预训练。
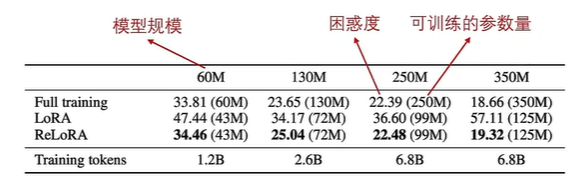
在从0开始预训练Transformer模型的实验中表明,ReLoRA方法可以达到与全量预训练相当的性能。

PEFT应用于垂域任务



PEFT主流框架
目前最流行的 PEFT 框架是由 Hugging Face 开发的开源库 HF-PEFT ,它旨在提供最先进的参数高效微调方法。
HF-PEFT的优势:
- 集成了多种先进的微调技术,如LoRA、Apdater-tuning、Prompt-tuning 和IA3 等;
- 支持与 Hugging Face 的其他工具如 Transformers、Diffusers 和Accelerate无缝集成,并且支持从单机到分布式环境的多样化训练和推理场景;
- 特别适用于大模型,能够在消费级硬件上实现高性能,并且可以与模型量化技术兼容,进一步减少了模型的内存需求;
- 支持多种架构模型,包括Transformer 和 Diffusion,并且允许用户手动配置,在自己的模型上启用 PEFT;
- 易用性,它提供了详细的文档、快速入门指南和示例代码 ,可以帮助用户了解如何快速训练 PEFT 模型,以及如何加载已有的 PEFT 模型进行推理。
