PyTorch高阶技巧:构建非线性分类器与梯度优化全解析
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。
一. 单层神经元实现线性回归
1.1 线性模型数学原理
线性回归模型定义为:
y=w⋅x+by=w⋅x+b
其中:
-
ww:权重(Weight)
-
bb:偏置(Bias)
-
xx:输入特征
-
yy:预测输出
目标:通过最小化均方误差(MSE)损失函数学习参数:
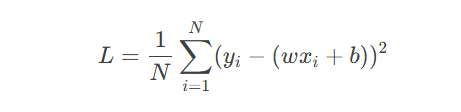
1.2 PyTorch实现代码
import torch
import matplotlib.pyplot as plt
# 生成数据
X = torch.linspace(0, 10, 100).reshape(-1, 1)
y = 3 * X + 2 + torch.randn(100, 1) * 2 # 添加噪声
# 定义模型
class LinearModel(torch.nn.Module): def __init__(self): super().__init__() self.linear = torch.nn.Linear(1, 1) # 单层神经元 def forward(self, x): return self.linear(x)
model = LinearModel()
criterion = torch.nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 训练循环
losses = []
for epoch in range(100): pred = model(X) loss = criterion(pred, y) optimizer.zero_grad() loss.backward() optimizer.step() losses.append(loss.item())
# 可视化
plt.scatter(X.numpy(), y.numpy(), label='Data')
plt.plot(X.numpy(), model(X).detach().numpy(), 'r', label='Fitted Line')
plt.legend()
plt.show()
二. 线性模型实现二分类
2.1 逻辑回归原理
将线性输出通过Sigmoid函数映射到(0,1)区间:
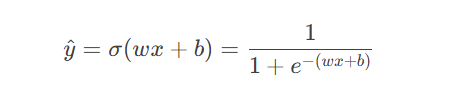
损失函数使用二元交叉熵(BCE):
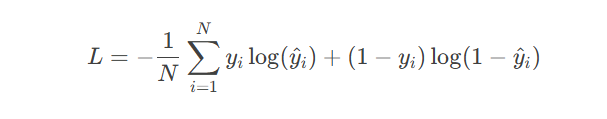
2.2 代码实现与决策边界
from sklearn.datasets import make_moons
# 生成二分类数据集
X, y = make_moons(n_samples=200, noise=0.1)
X = torch.tensor(X, dtype=torch.float32)
y = torch.tensor(y, dtype=torch.float32).reshape(-1, 1)
# 定义模型(增加Sigmoid激活)
class LogisticRegression(torch.nn.Module): def __init__(self): super().__init__() self.linear = torch.nn.Linear(2, 1) self.sigmoid = torch.nn.Sigmoid() def forward(self, x): return self.sigmoid(self.linear(x))
model = LogisticRegression()
criterion = torch.nn.BCELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.1)
# 训练
for epoch in range(1000): pred = model(X) loss = criterion(pred, y) optimizer.zero_grad() loss.backward() optimizer.step()
# 可视化决策边界
def plot_decision_boundary(model, X, y): x_min, x_max = X[:,0].min()-0.5, X[:,0].max()+0.5 y_min, y_max = X[:,1].min()-0.5, X[:,1].max()+0.5 xx, yy = torch.meshgrid(torch.linspace(x_min, x_max, 100), torch.linspace(y_min, y_max, 100)) grid = torch.cat((xx.reshape(-1,1), yy.reshape(-1,1)), dim=1) probs = model(grid).reshape(xx.shape) plt.contourf(xx, yy, probs > 0.5, alpha=0.3) plt.scatter(X[:,0], X[:,1], c=y.squeeze(), edgecolors='k') plt.show()
plot_decision_boundary(model, X, y)关键输出:
-
训练后准确率 > 85%
-
决策边界图显示线性分类器的局限性
三. 多层感知机(MLP)手动推导与实现
3.1 手动推导反向传播
网络结构:输入层(2) → 隐藏层(4, ReLU) → 输出层(1, Sigmoid)
前向传播:
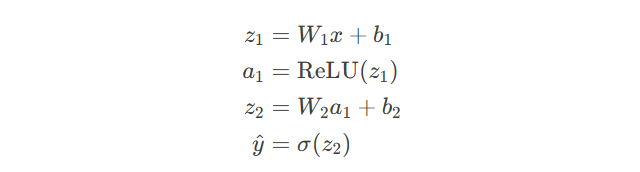
反向传播梯度计算:
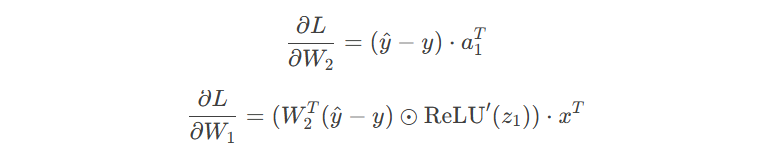
3.2 PyTorch自动梯度实现
class MLP(torch.nn.Module): def __init__(self): super().__init__() self.fc1 = torch.nn.Linear(2, 4) self.fc2 = torch.nn.Linear(4, 1) self.relu = torch.nn.ReLU() self.sigmoid = torch.nn.Sigmoid() def forward(self, x): x = self.relu(self.fc1(x)) x = self.sigmoid(self.fc2(x)) return x
model = MLP()
optimizer = torch.optim.Adam(model.parameters(), lr=0.05)
# 复用之前的训练循环
# ...
plot_decision_boundary(model, X, y) # 显示非线性决策边界优化技巧:
-
权重初始化:
torch.nn.init.kaiming_normal_(self.fc1.weight) -
学习率调度:
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1) -
梯度裁剪:
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
四. 总结
4.1 核心要点总结
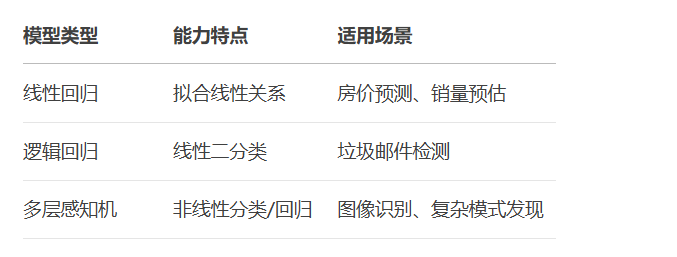
附:完整训练监控代码
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
for epoch in range(1000): pred = model(X) loss = criterion(pred, y) acc = ((pred > 0.5) == y).float().mean() optimizer.zero_grad() loss.backward() optimizer.step() writer.add_scalar('Loss/train', loss.item(), epoch) writer.add_scalar('Accuracy/train', acc.item(), epoch)
# 启动TensorBoard
# tensorboard --logdir=runs注:本文代码基于PyTorch 2.0+实现,运行前需安装:
pip install torch matplotlib scikit-learn tensorboard如果本次分享对你有所帮助,记得告诉身边有需要的朋友,"我们正在经历的不仅是技术迭代,而是认知革命。当人类智慧与机器智能形成共生关系,文明的火种将在新的维度延续。"在这场波澜壮阔的文明跃迁中,主动拥抱AI时代,就是掌握打开新纪元之门的密钥,让每个人都能在智能化的星辰大海中,找到属于自己的航向。