Python 大模型知识蒸馏详解,知识蒸馏大模型,大模型蒸馏代码实战,LLMs knowledge distill LLM
一、原理
将待压缩的模型作为教师模型,将体积更小的模型作为学生模型,让学生模型在教师模型的监督下进行优化,将学生模型学习到教师模型的概率分布,通过kl散度进行控制。
二、方法
对于大模型的知识蒸馏,主要分为两种:
其一、黑盒知识蒸馏。
使用大模型生成数据,通过这些数据去微调更小的模型,来达到蒸馏的目的。缺点是蒸馏效率低,优点是实现简单。
其二、白盒知识蒸馏。
获取学生模型和教师模型的输出概率分布(或者中间隐藏层的概率分布),通过kl散度将学生模型的概率分布向教师模型对齐。 下面主要介绍和测试白盒知识蒸馏: 白盒知识蒸馏主要在于模型分布的对齐,模型分布对齐主要依赖kl散度,对于kl散度的使用又有如下几种方式:
(一)、前向kl散度。
也就是我们经常说的kl散度。
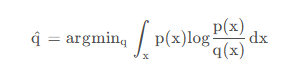
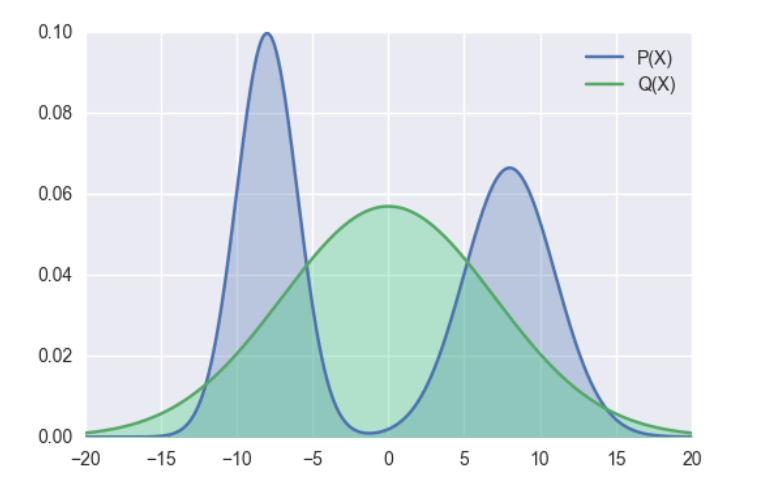
p为教师模型的概率分布,q为学生模型的概率分布,minillm论文中提到前向kl散度可能会使学生模型高估教师模型中概率比较低的位置,结合公式来看,当p增大时,为了使得kl散度小,则q也需要增大,但是当p趋于0时,无论q取任何值,kl散度都比较小,因为此时p(x)log((p(x)/q(x)))的大小主要受p(x)控制,这样起不到优化q分布的效果,可能会使q分布高估p分布中概率低的位置。 下图展示了前向kl散度的拟合情况,前向kl散度是一种均值搜索,更倾向于拟合多峰
(二)、反向kl散度。
为了缓解前向kl散度的缺点,提出了反向kl散度。
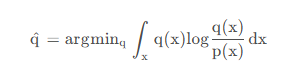
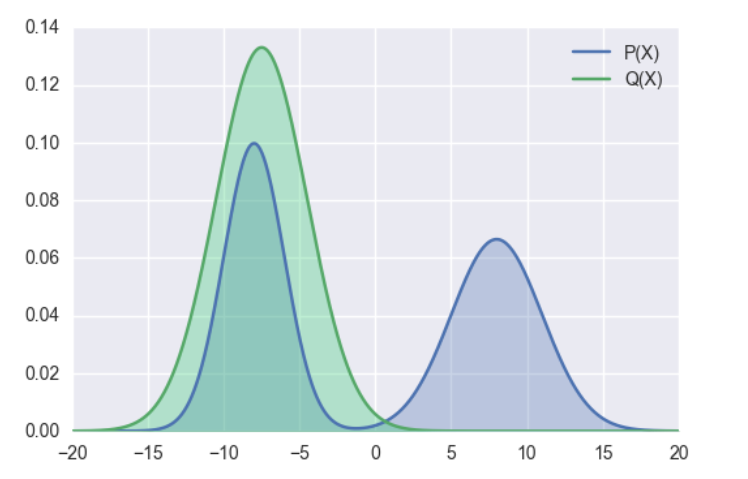
p为教师模型的概率分布,q为学生模型的概率分布,当p趋于零时,为了使kl散度小,q也需趋于0。 minillm论文中说对于大模型的知识蒸馏,反向kl散度优于前向kl散度,但是也有其他论文说反向kl散度不一定比前向kl散度更优,实际选择中,可能要基于实验驱动。 反向kl散度是一种模式搜索,更倾向于拟合单个峰
(三)、偏向前kl散度。
对学生模型的分布和教师模型的分布进行加权作为学生模型的分布。
(四)、偏向反kl散度。
对学生模型的分布和教师模型的分布进行加权作为教师模型的分布。
三、测试
qwen2.5-3b作为教师模型,qwen2.5-0.5b作为学生模型
流程如下:
1、将qwen2.5-3b模型在指定数据集上微调(训练数据5000条,测试数据1000条,测试准确度为81.1%)
2、探索如下三种方案下的蒸馏效果(均使用前向kl散度):
2.1 不微调学生模型+kl散度损失
蒸馏1个epoch,准确度70.5%
蒸馏2个epoch,准确度73%
2.2 微调学生模型(模型准确度80.3%)+kl散度损失
蒸馏2个epoch,准确度61.9%
2.3 不微调学生模型+kl散度损失和交叉熵损失加权
蒸馏2个epoch,70.5%
3、上述实验中只使用kl散度的效果最好,如下实验中使用kl散度的变种进行测试,经过测试,效果都不如前向kl散度效果好。
3.1 反向kl散度
准确率只有54%
3.2 偏向前向kl散度
损失下降异常,效果很差,不断重复输出。
由于资源和时间的限制,所有测试均保持相同的超参数,未针对不同损失设置不同超参数。
四、代码实战
train.py
from transformers import AutoModelForCausalLM, AutoTokenizer, DefaultDataCollator
from peft import LoraConfig, get_peft_model, TaskType
from peft import PeftModel
import torch
import torch.nn as nn
import torch.nn.functional as F
from transformers import Trainer, TrainingArguments
from dataset import SFTDataset
from utils import compute_fkl, compute_rkl, compute_skewed_fkl, compute_skewed_rklclass KGTrainer(Trainer):def __init__(self,model = None,teacher_model = None,if_use_entropy = False,args = None,data_collator = None, train_dataset = None,eval_dataset = None,tokenizer = None,model_init = None, compute_metrics = None, callbacks = None,optimizers = (None, None), preprocess_logits_for_metrics = None,):super().__init__(model,args,data_collator,train_dataset,eval_dataset,tokenizer,model_init,compute_metrics,callbacks,optimizers,preprocess_logits_for_metrics,)self.teacher_model = teacher_modelself.if_use_entropy = if_use_entropydef compute_loss(self, model, inputs, return_outputs=False):outputs = model(**inputs)with torch.no_grad():teacher_outputs = self.teacher_model(**inputs)loss = outputs.losslogits = outputs.logitsteacher_logits = teacher_outputs.logits# 如果教师模型和学生模型输出形状不匹配,对学生模型进行padding或对教师模型进行截断if logits.shape[-1] != teacher_logits.shape[-1]:# gap = teacher_logits.shape[-1] - logits.shape[-1]# if gap > 0:# pad_logits = torch.zeros((logits.shape[0], logits.shape[1], gap)).to(logits.device)# logits = torch.cat([logits, pad_logits], dim=-1)teacher_logits = teacher_logits[:, :, :logits.shape[-1]]labels = inputs['labels']kl = compute_fkl(logits, teacher_logits, labels, padding_id=-100, temp=2.0)if self.if_use_entropy:loss_total = 0.5 * kl + 0.5 * losselse:loss_total = klreturn (loss_total, outputs) if return_outputs else loss_totalif __name__ == '__main__':# 学生模型model = AutoModelForCausalLM.from_pretrained("Qwen2.5-0.5B-Instruct")lora_config = LoraConfig(r=8, lora_alpha=256, target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],lora_dropout=0.1, task_type=TaskType.CAUSAL_LM)# 使用lora方法训练model = get_peft_model(model, lora_config)model.cuda()print(model.print_trainable_parameters())tokenizer = AutoTokenizer.from_pretrained("Qwen2.5-0.5B-Instruct")# 教师模型,在给定数据上通过lora微调teacher_model = AutoModelForCausalLM.from_pretrained("Qwen2.5-7B-Instruct")# 是否加载lora模型lora_path = 'qwen2.5_7b/lora/sft'teacher_model = PeftModel.from_pretrained(teacher_model, lora_path)teacher_model.cuda()teacher_model.eval()args = TrainingArguments(output_dir='./results', num_train_epochs=10, do_train=True, per_device_train_batch_size=2,gradient_accumulation_steps=16,logging_steps=10,report_to='tensorboard',save_strategy='epoch',save_total_limit=10,bf16=True,learning_rate=0.0005,lr_scheduler_type='cosine',dataloader_num_workers=8,dataloader_pin_memory=True)data_collator = DefaultDataCollator()dataset = SFTDataset('data.json', tokenizer=tokenizer, max_seq_len=512)trainer = KGTrainer(model=model,teacher_model=teacher_model, if_use_entropy = True,args=args, train_dataset=dataset, tokenizer=tokenizer, data_collator=data_collator)# 如果是初次训练resume_from_checkpoint为false,接着checkpoint继续训练,为Truetrainer.train(resume_from_checkpoint=False)trainer.save_model('./saves')trainer.save_state()dataset.py
import math
from typing import List, Optional, Tuple, Union
import torch
import torch.nn.functional as F
import torch.utils.checkpoint
from torch import nn
import os
import pandas as pdfrom torch.utils.data import IterableDataset, Dataset
import json
import numpy as np
from transformers import PreTrainedModel
from transformers.modeling_outputs import CausalLMOutputWithPast
from transformers import PretrainedConfig
from transformers import Trainer, TrainingArguments, AutoModelForCausalLM, AutoTokenizer, DefaultDataCollator, DataCollatorForTokenClassification, AutoConfigclass SFTDataset(Dataset):def __init__(self, data_path, tokenizer, max_seq_len):super().__init__()self.data_path = data_pathself.tokenizer = tokenizerself.max_seq_len = max_seq_lenself.padding_id = tokenizer.pad_token_idwith open(self.data_path, 'r', encoding='utf-8') as f:self.data = json.load(f)def __len__(self):return len(self.data) def __getitem__(self, index):line = self.data[index]instruction_text = line['instruction']input_text = line['input']output_text = line['output']query = instruction_text + input_textanswer = output_text + self.tokenizer.eos_tokenmessages = []messages.append({'role': 'user', 'content': query}) prompt = self.tokenizer.apply_chat_template(messages, tokenize=False) prompt_input_ids = self.tokenizer.encode(prompt)answer_input_ids = self.tokenizer.encode(answer)input_ids = prompt_input_ids + answer_input_idslabels = [-100] * len(prompt_input_ids) + answer_input_idsattention_mask = [1] * len(input_ids)text_len = len(input_ids)if text_len > self.max_seq_len:input_ids = input_ids[:self.max_seq_len]labels = labels[:self.max_seq_len]attention_mask = attention_mask[:self.max_seq_len]else:input_ids = input_ids + [self.tokenizer.pad_token_id] * (self.max_seq_len - text_len)labels = labels + [-100] * (self.max_seq_len - text_len)attention_mask = attention_mask + [0] * (self.max_seq_len - text_len)# input_ids = input_ids[:-1]# labels = labels[1:]return {'input_ids': torch.tensor(input_ids), 'attention_mask':torch.tensor(attention_mask), 'labels': torch.tensor(labels)}utils.py
import torch# 计算前向kl散度
def compute_fkl(logits, teacher_logits, target, padding_id,reduction="sum",temp = 1.0, ):logits = logits / tempteacher_logits = teacher_logits / templog_probs = torch.log_softmax(logits, -1, dtype=torch.float32)teacher_probs = torch.softmax(teacher_logits, -1, dtype=torch.float32)teacher_log_probs = torch.log_softmax(teacher_logits, -1, dtype=torch.float32)kl = (teacher_probs * (teacher_log_probs - log_probs)) kl = kl.sum(-1)if reduction == "sum":pad_mask = target.eq(padding_id)kl = kl.masked_fill_(pad_mask, 0.0)kl = kl.sum()return kl
# 计算反向kl散度
def compute_rkl(logits, teacher_logits, target, padding_id,reduction="sum", temp = 1.0):logits = logits / tempteacher_logits = teacher_logits / tempprobs = torch.softmax(logits, -1, dtype=torch.float32)log_probs = torch.log_softmax(logits, -1, dtype=torch.float32)teacher_log_probs = torch.log_softmax(teacher_logits, -1, dtype=torch.float32)kl = (probs * (log_probs - teacher_log_probs))kl = kl.sum(-1)if reduction == "sum":pad_mask = target.eq(padding_id)kl = kl.masked_fill_(pad_mask, 0.0)kl = kl.sum()return kl# 计算偏向前kl散度
def compute_skewed_fkl(logits, teacher_logits, target, padding_id, reduction="sum", temp = 1.0,skew_lambda = 0.1):logits = logits / tempteacher_logits = teacher_logits / tempprobs = torch.softmax(logits, -1, dtype=torch.float32)teacher_probs = torch.softmax(teacher_logits, -1, dtype=torch.float32)mixed_probs = skew_lambda * teacher_probs + (1 - skew_lambda) * probsmixed_log_probs = torch.log(mixed_probs)teacher_log_probs = torch.log_softmax(teacher_logits, -1, dtype=torch.float32)kl = (teacher_probs * (teacher_log_probs - mixed_log_probs))kl = kl.sum(-1)if reduction == "sum":pad_mask = target.eq(padding_id)kl = kl.masked_fill_(pad_mask, 0.0)kl = kl.sum()return kl
# 计算偏向反kl散度
def compute_skewed_rkl(logits, teacher_logits, target,padding_id,reduction="sum", temp = 1.0,skew_lambda = 0.1
):logits = logits / tempteacher_logits = teacher_logits / tempprobs = torch.softmax(logits, -1, dtype=torch.float32)teacher_probs = torch.softmax(teacher_logits, -1, dtype=torch.float32)mixed_probs = (1 - skew_lambda) * teacher_probs + skew_lambda * probsmixed_log_probs = torch.log(mixed_probs)log_probs = torch.log_softmax(logits, -1, dtype=torch.float32)kl = (probs * (log_probs - mixed_log_probs))kl = kl.sum(-1)if reduction == "sum":pad_mask = target.eq(padding_id)kl = kl.masked_fill_(pad_mask, 0.0)kl = kl.sum()return kl五、data格式
instruction_text = line['instruction']
input_text = line['input']
output_text = line['output']
{
'instruction':'很厉害的专家',
'input':'写一首诗',
'output':'巴拉巴拉小魔仙',
}