网络原理(TCP协议性质)
1.滑动窗口
之前我们在讲解TCP协议前面几个性质的时候,我们通过那些确实已经可以确保信息正确的传输了,但是我们前面所讲的就是客户端发送一个信息,我们的服务器接受一个元素之后再给客户端发送 ACK,这样就实现了信息的可靠传输,但是我们可以清晰的感觉到一个缺点就是我们的性能很差,尤其是时间往返较长的时候。下面我们介绍的滑动窗口就是提升效率的,用于解决这个问题。
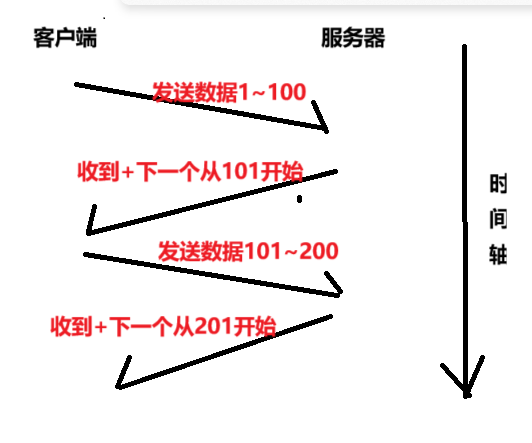
上面是我们正常的信息发送的过程,我们既然说了这个传输的效率就是很慢,那么我们不妨尝试一下发送多条数据,这样的话明显的效率提高了很高。
不知道大家是否了解滑动窗口这个概念。
滑动窗口在我们学习算法的时候,就是存在的,就是同向双指针的移动(也就是两个变量的移动)通过两个指针之间的移动,指针之间所包含的内容就可以看做一个窗口,通过移动两个指针就会间接的移动窗口,这一概念就是滑动窗口。
下面给大家先介绍一个名词——窗口大小。窗口大小其实就是无需等待确认应答一次批量能够发送多少数据的最大值。
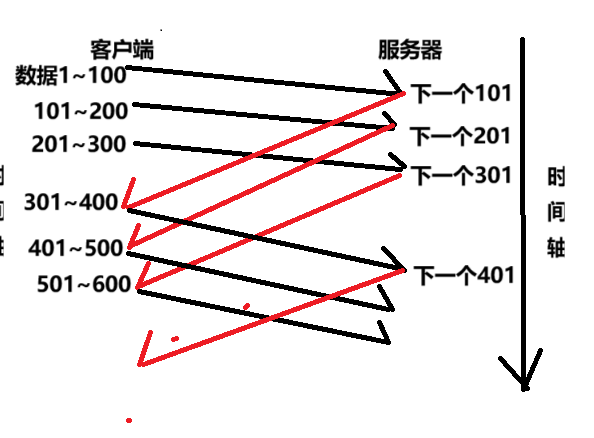
我们观察上面的图,上述的图就是给我们清晰的展示了,传送信息的过程。
我们上面不是说了窗口大小是什么了(这里的窗口大小就是300字节).我们第一次发送的信息是不需要等待到服务器返回的 ACK 的,直接进行发送。
当我们收到第一个传输过去的段传过来的ACK后就可以进行向下继续发送(滑动窗口向下依次推动),依此类推。
操作系统内核为了维护这个滑动窗口,需要开辟 发送缓冲区 来记录嗨哟那些数据没有进行服务器返回的ACK ,收到应答的数据进行从缓冲区里面进行删除。
那么我们上面进行了正常数据进行的传输,当然也会发生丢包的现象。
之前我们在谈到丢包的时候,说明了会发生两种情况,一种是数据包进行丢失,另外一种是 确认应答的ACK丢失。
下面我们分为两种情况进行讨论。
情况一:数据包到达,CAK丢失。
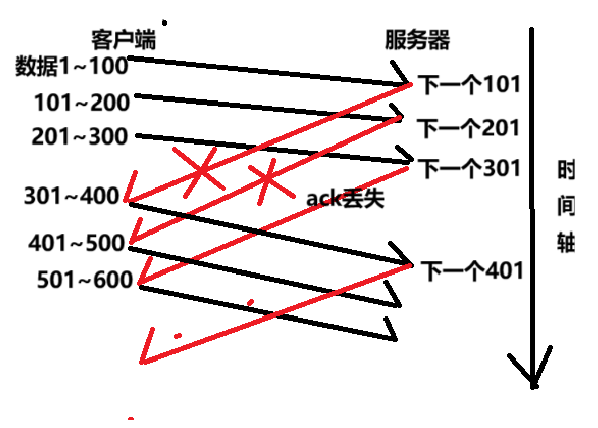
这里呢我们要是前面的ACK丢失了不用去担心,只要我们后面的ACK到达了就可以了,后面的ACK到达了就可以进行确认。
为啥可以进行通过后面的ACK确认前面的信息?
是因为我们返回的ack里面存储的是下一个字节的序号,只要我们后面的信息到达之后,就证明服务器已经收到了正确的数据信息;要是没有接受到的话那么后面的ACK也不会接收到,因为后面接受数据的序号就没有进行递增。
例如,发送方按顺序发送了数据包 1、2、3,接收方正确接收后应发送 ACK 确认号为 4(假设每个数据包长度为 1 字节)。如果确认数据包 2 的 ACK 丢失,但确认数据包 3 的 ACK(确认号为 4)到达了发送方,发送方就可以知道数据包 1、2、3 都已经被正确接收,因为确认号 4 表示接收方期望接收下一个字节是从序号 4 开始的,也就意味着序号小于 4 的数据包都已经被接收。
看到这里其实还是有另外一个问题就是我们要是最后一个ACK也丢失了,那么我们后续没有ACK进行返回怎么确认最后这个数据到达?
其实呢在我们真实的情况中两种机制是共同存在的,并且不会产生冲突,即快速重传和超时重传。当我们最后一个ACK丢失的话就是数据比较少的时候,系统就会进行超时重传操作 ,使得重新发送丢失的数据;当我们数据多的时候就会进行快速重传。
情况二:数据包丢失
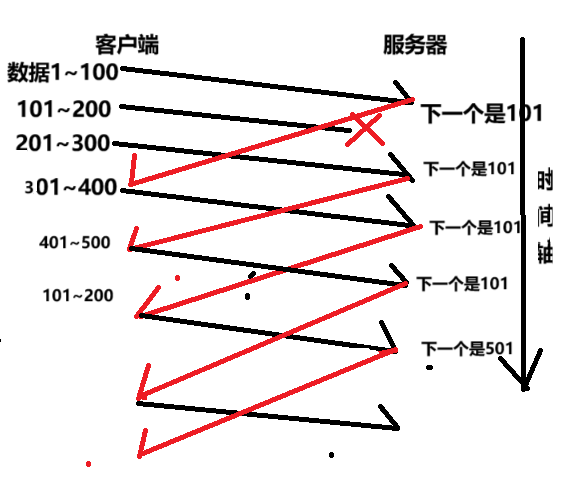
接收方收到乱序的数据包时,会重复发送对最后一个按序接收的数据包的确认(ACK)。当发送方收到连续多个相同(通常的阈值是3)的 ACK 时,就会意识到有数据包丢失,不等定时器超时,立即重传丢失的数据包。 一旦丢失的数据收到之后就会从发送到哪里开始进行重发。
我们在上述图中就是在101出现了问题,但是后面由于窗口的大小就使得后面的信息继续传输,这些数据都是放到了操作系统里面的接受缓冲区中,直到收到相对应的ACK才会从接受缓冲区中进行删除。这种机制就叫做 快速重传。
2.流量控制。
接收端处理数据的速度是有上限的 ,当我们要是没有节制的一直通过发送端发送数据就会使得缓冲区里面的数据瞬间放满,这就会造成数据的丢失,即丢包。通过上述的场景我们引入了流量控制的概念。
流量控制就是通过接收端的处理能力,进行控制发送端的发送速度(即控制窗口的大小来进行控制窗口接受数据的量)这种机制就是流量控制。
我们通过知道缓冲区的剩余空间大小来反向制约发送方的发送速度。
主要通过下面的操作:
1.接收端在返回ACK的时候就是通过在TCP报头中放入缓冲区剩余空间的大小,让发送端收到ACK的时候就知道了我们接受端缓冲区里面的空间大小是多少。
2.窗口大小字段越大,说明网络的吞吐量就越高。
3.接收端一旦发现缓冲区快满的时候,就会将窗口的大小设置为更小的数值通知给发送端。
4.发送端接收到这个窗口之后就会将自己的发送速度减慢。
5.我们的流量控制是在滑动窗口的基础上面实现的。
6.当接受端缓冲区满了之后就会将窗口的大小设置为0;这时发送方就会停止发送数据;但会发送端会定期发送一个窗口探测数据段,使接收端第一时间将窗口的大小告诉给发送端。
(窗口探测包不会去发送业务数据,并且是周期性发送,要是只发送一次,这个窗口探测包也丢失了,就会造成窗口大小恢复了发送方不知道,还是停止发送数据的)
我们前面在介绍TCP协议格式的时候说了,TCP首部有一个16位窗口字段,就是存放窗口大小信息的,16位数字最大能表示65535,那么TCP的窗口大小是不是最大也是表示65535字节?
其实不是的,实际上在TCP的首部中存在一个窗口扩展因子,发送方收到ACK后,设置窗口大小等于16位大小 << M位。
3.拥塞控制。
我们上述提出了流量控制之后就会很高效,安全的发送数据了。但是还是存在问题的,当我们刚开始突然发送了大批量的数据之后,就会引发问题。我们在发送之前其实是不知道发送的网络状况的,要是网络状况好的话,还可能会成功的发送;但是当网络状况不好的时候,我们突然发送大量数据过去就会造成雪上加霜。所以在上述情况的前提下,我们提出了拥塞控制。拥塞控制就是会在刚开始的时候不会一下发送大量数据,要是网络没问题的话,我们再去将数据量提高;当网络情况差的话,我们就不会给本就不好的状况增加负担。
我们观察下面的客户端和服务器的图:
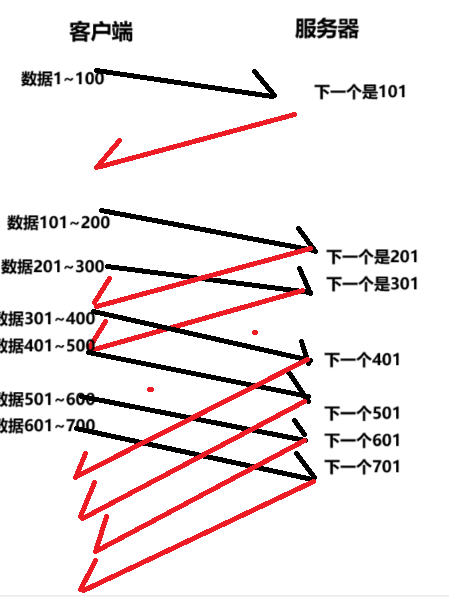
我们观察上面的客户端和服务器的交互过程我们可以看到刚开始数据传输的速度是很慢的,之后是成线性增长的。
我们注意下面几点:
1.拥塞控制就是限制滑动窗口的发送速率的
2.发送开始的时候, 定义拥塞窗⼝⼤⼩为1;
3.每次收到⼀个ACK应答, 拥塞窗⼝加1;
4.每次发送数据包的时候, 将拥塞窗⼝和接收端主机反馈的窗⼝⼤⼩做⽐较, 取较⼩的值作为实际发送的窗⼝;
5.少量的丢包我们仅仅是触发超时重传,大量丢包之后我们就认为是网络拥塞。
下面是拥塞窗口随着时间变化的图片:
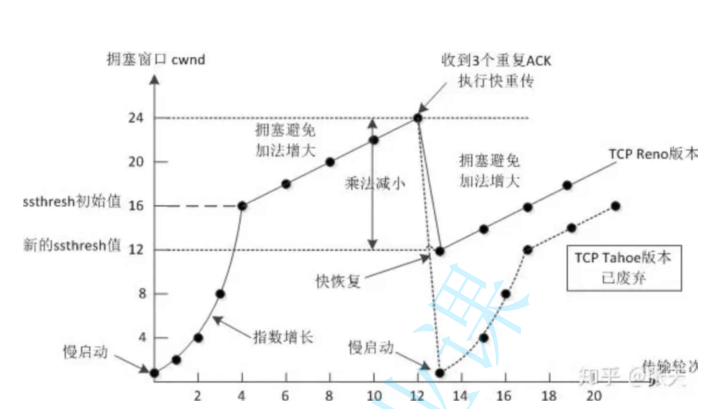
我们观察上图,可以清晰的看到:
1.刚开始我们进行的是慢启动,这个过程呈现的是指数增长的,我们慢启动指数变化的中间点是慢启动的阈值(阈值就是感觉我们快到达最大值了,就将增长的速度减下来了之后慢慢增长)。
2.慢启动之后我们进行的是线性增长,增长的速度就变得比指数增长的慢了,就这样一直增长直到我们接收到三个重复的ACK的时候(丢包)我们的窗口大小就到达了最大值。
3.当我们到达最大值得时候,我们就会让拥塞窗口进行减少,当我们出现大量丢包的时候我们就会将窗口大小重新设置为一再次进行上述操作;当出现少量丢包的时候就会将窗口大小降低到慢启动阈值的一半,之后进行传输数据的时候窗口大小就会进行线性增长。
拥塞控制其实就是TCP协议想将数据最大可能得传输给对方,但是又要避免网络造成太大压力的最优方案。
4.延时应答。
前面讲述的性质其实已经达到了数据安全高效的传输,但是我们还可以提高网络的利用率,就是我们下面要讲述的——延时确认应答,作用就是提高窗口的大小。
我们传输数据的时候的本质目标就是保证网络不拥塞的情况下,尽可能的提高传输效率,前提是要保证可靠性。
下面举一个例子带大家进行理解:
假设我们在传输500k的数据的时候,我们的缓冲区的大小是1M,我们要是按照前面所说的直接返回ACK的话,那么我们返回的窗口大小就是500M。但是当我们的处理速度很快的时候,例如10MS我们就可以进行处理了缓冲区里面的500K的数据。这样看的话,接收端的处理还是远远没有达到上限的,及时窗口再大一些我们其实也是可以处理过来的,等接收端稍微等一会的话我们返回的窗口大小就可以是1M,这个比我们前面所说的500K是有很大的差距的。
我们前面所说的也不是所有的包都可以进行延时应答的操作:
1.我们会隔几个包之后就会进行一次应答。(我们一般是隔两个包)
2.我们要是超过了最大的等待时间就会返回应答一次。(最大时间是200MS)
下面是客户端和服务器之间的交互过程:
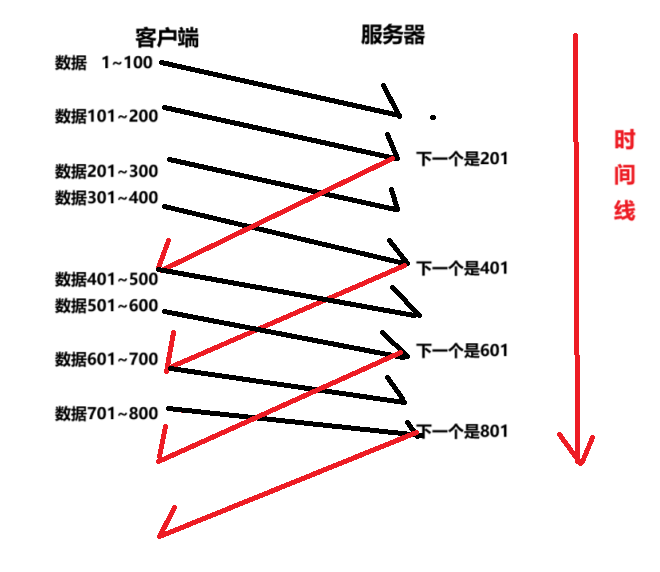
我们观察上图可以看到我们的数据传输到服务器之后,不会直接进行ACK的返回,会先等一会等下一个数据的过来后,直接返回后面的数据的ACK。
5.捎带应答。
我们前面在说延迟的基础上,我们发现很多情况都是这样的,在我们客户端和应用层交流的时候也是进行的 “一问一答” 的方式,那么我们还有返回ACK,那么就可以顺便发送过去了,就节省了发送的空间。
下面是捎带应答的客户端和该服务器之间的交互过程:
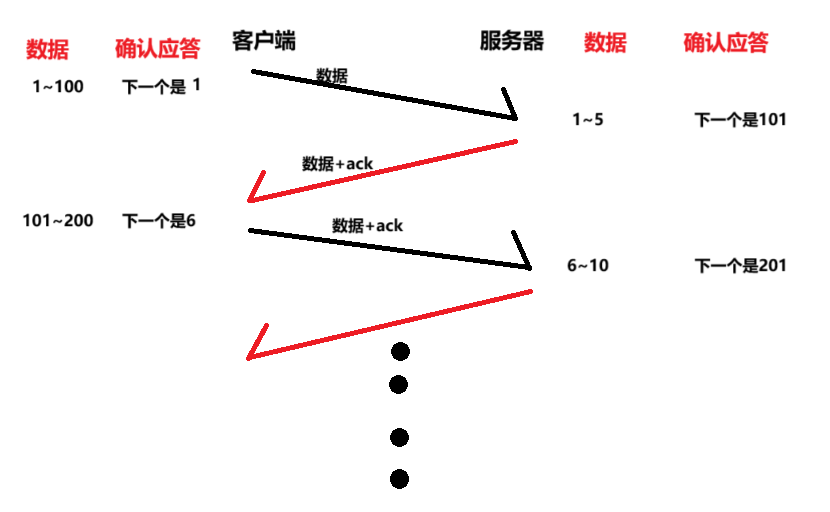
6.面向字节流。
创建⼀个TCP的socket, 同时在内核中创建⼀个 发送缓冲区 和⼀个 接收缓冲区;
1.调⽤write时, 数据会先写⼊发送缓冲区中;
2.如果发送的字节数太⻓, 会被拆分成多个TCP的数据包发出;
3.如果发送的字节数太短, 就会先在缓冲区⾥等待, 等到缓冲区⻓度差不多了, 或者其他合适的时机发送出去;
4.接收数据的时候, 数据也是从⽹卡驱动程序到达内核的接收缓冲区;
我们将数据放到缓冲区里面的话,就会出现一个问题,也就是——粘包问题。
粘包问题就是我们一下将数据放到了缓冲区里面中间没有区分的标记,就会使得我们的数据进行错读。那么我们怎么才能读到完整的应用层数据包。
解决办法:从应用层入手,合理设计应用层协议,让每个包的边界比较清晰。
1.引入特殊分隔符进行分割。这个方法固然可以但是有一个致命的缺点,就是我们的包数据里面就不能包含该分隔符了。
2.在应用层数据包开头的地方,我们通过设置一个固定长度用于约束整个数据长度,这样的话我们就可以清晰的读取到数据。
注意:粘包问题只是存在于TCP中,UDP中不存在。因为TCP存储数据的容器结构就类似于数组,所有的数据都是连续存储的;UDP的存储结构的容器就类似于链表,是链表的话就不存在上述所说的粘包问题。
7.异常情况。
进程终⽌: 进程终⽌会释放⽂件描述符, 仍然可以发送FIN. 和正常关闭没有什么区别.
机器重启: 和进程终⽌的情况相同.
机器掉电/⽹线断开: 接收端认为连接还在, ⼀旦接收端有写⼊操作, 接收端发现连接已经不在了, 就
会进⾏reset. 即使没有写⼊操作, TCP⾃⼰也内置了⼀个保活定时器, 会定期询问对⽅是否还在. 如果对⽅不在, 也会把连接释放.
7.