使用英伟达 Riva 和 OpenAI 构建 AI 聊天机器人
在本地部署小型语音AI 对话机器人还是非常重要的,比如在机器人领域。本文介绍英伟达的小型jetson AI 模块实现AI 。
Jetson 简介
硬件
Jetson AGX Orin series
- 最多 275 个 TOPS
- 15-60W
- 100mm x 87mm
- 起价 899 美元
Jetson Orin NX series
- 最多 100 个 TOPS
- 10-25W
- 70mm x 45mm
- 起价 399 美元
Jetson Orin Nano series
- 最多 40 个 TOPS
- 7-15W
- 70mm x 45mm
- 起价 199 美元
Jetson AGX Xavier series
- 最多 32 TOPS
- 10-30W | 20-40W
- 100mm x 87mm
- 起价 899 美元
Jetson Xavier NX series
- 21 TOPS
- 10-20W
- 70mm x 45mm
- 起价 399 美元
Jetson TX2 series
- 1.3 TFLOPS
- 7.5-15W | 10-20W
- 起始尺寸 70mm x 45mm
- 起始价格 149 美元
Jetson Nano
- 0.5 TFLOPS
- 5-10W
- 70mm x 45mm
- 99美元
项目
该项目使用部署在 NVIDIA Jetson 设备上的 NVIDIA Riva 和 OpenAI API 构建了一个交互式聊天机器人。它具有以下特点:
- 唤醒词检测
- 持续对话
让我们看一下架构:
首先,从麦克风输入的语音会利用 Riva 的自动语音识别(ASR)库转换成文本,然后传递给 OpenAI API。当 OpenAI API 返回结果后,会利用 Riva 的文本转语音(TTS)库将文本转换成语音,并通过麦克风输出。
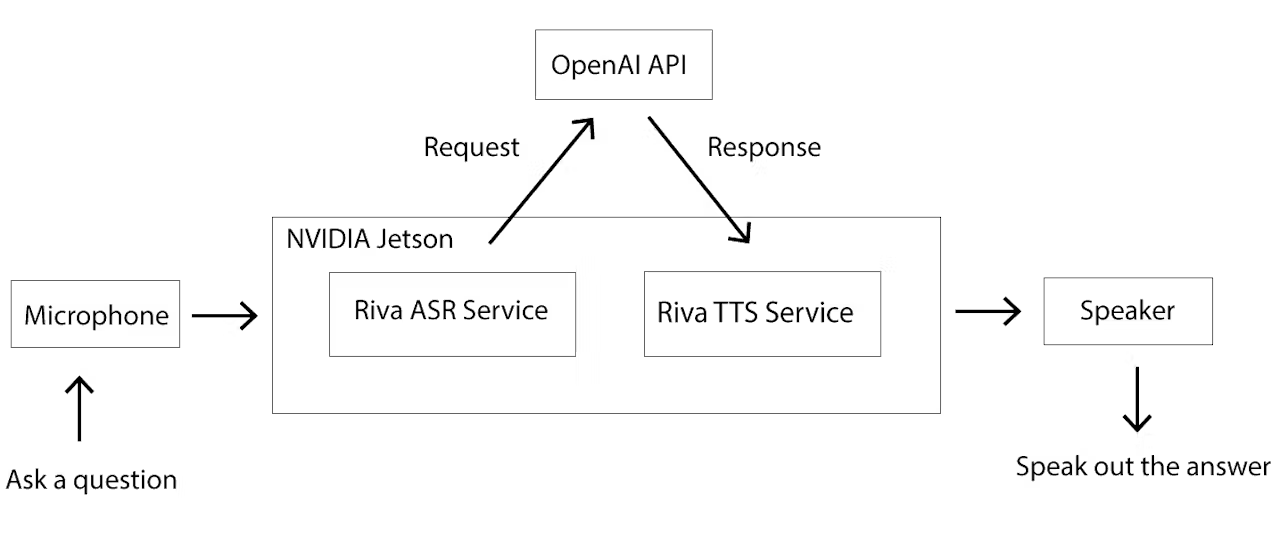
显然,并没有在jetson 上部署本地大模型,又一些文章介绍在jetson Orin NX 16GB上部署 ollama +riva+ollama2 的本地部署方式。
Riva 是什么?
Riva是由 NVIDIA 开发的语音处理平台,旨在帮助开发者构建强大的语音应用程序。它提供多种语音处理功能,包括自动语音识别 (ASR)、文本转语音 (TTS)、自然语言处理 (NLP)、神经机器翻译 (NMT) 和语音合成。它利用 NVIDIA 的 GPU 加速技术,即使在高负载下也能确保高性能,并提供用户友好的 API 接口和 SDK 工具,方便开发者轻松构建语音应用程序。Riva 在 NVIDIA NGC™ 中提供预训练的语音模型,这些模型可以使用 NVIDIA NeMo 在自定义数据集上进行微调,从而将特定领域模型的开发速度提高 10 倍。
Riva 中的 ASR 是什么?
Riva 的 ASR(自动语音识别)是 NVIDIA 开发的一项先进技术。它利用深度学习模型和算法,将口语准确地转换为书面文本。它广泛用于实时转录、语音命令和其他语音转文本应用。
Riva 中的 TTS 是什么?
Riva 的 TTS(文本转语音)是一项先进的技术,能够从书面文本生成高质量、自然的语音。它运用深度学习技术,能够生成发音和表达精准、类似人类的语音。开发者可以自定义参数,以实现所需的语音特性。它广泛应用于虚拟助手、有声读物和无障碍解决方案等应用。
硬件
Jetson Orin NX 16GB

JetPack SDK
为 Jetson 模块提供支持的 NVIDIA JetPack SDK 是构建端到端加速 AI 应用程序最全面的解决方案,可显著缩短产品上市时间。
NVIDIA JetPack 包含 3 个组件:
Jetson Linux:一个板级支持包 (BSP),包含引导加载程序、Linux 内核、Ubuntu 桌面环境、NVIDIA 驱动程序、工具链等。它还包含安全性和无线 (OTA) 功能。
Jetson AI Stack:CUDA 加速 AI 堆栈,包含一整套用于加速 GPU 计算、多媒体、图形和计算机视觉的库。它支持多种应用框架,例如用于构建、部署和扩展视觉 AI 应用的Metropolis 、用于构建高性能机器人应用的Isaac以及用于构建高性能计算 (HPC) 应用的Holoscan ,这些应用框架具有从边缘到云端的实时洞察和传感器处理能力。
Jetson 平台服务:一组可立即使用的服务,用于加速 Jetson 上的 AI 应用程序开发。
NanoLLM!
NanoLLM是一个轻量级、高性能的库,它使用针对量化 LLM、多模态、语音服务、带 RAG 的矢量数据库以及 Web 前端优化的推理 API。它可用于构建可部署在 Jetson 上的响应式、低延迟交互式代理。
-
支持的模型
-
Llama
-
Mistral
-
Mixtral
-
GPT-2
-
GPT-NeoX
-
-
SLM
-
StableLM
-
Phi-2
-
Gemma
-
TinyLlama
-
ShearedLlama
-
OpenLLama
-
-
VLM
-
Llava
-
VILA
-
NousHermes/Obsidian
-
-
Speech
-
Riva ASR
-
Riva TTS
-
Piper TTS
-
XTTS
-
英伟达公司AI实验室
https://www.jetson-ai-lab.com/
该网站提供了大量的培训课程,他们是更加模型和应用领域区分的。
Text (LLM)
| text-generation-webui | Interact with a local AI assistant by running a LLM with oobabooga's text-generaton-webui |
| Ollama | Get started effortlessly deploying GGUF models for chat and web UI |
| llamaspeak | Talk live with Llama using Riva ASR/TTS, and chat about images with Llava! |
| NanoLLM | Optimized inferencing library for LLMs, multimodal agents, and speech. |
| Small LLM (SLM) | Deploy Small Language Models (SLM) with reduced memory usage and higher throughput. |
| API Examples | Learn how to write Python code for doing LLM inference using popular APIs. |
Text + Vision (VLM)
Give your locally running LLM an access to vision!
| LLaVA | Different ways to run LLaVa vision/language model on Jetson for visual understanding. |
| Live LLaVA | Run multimodal models interactively on live video streams over a repeating set of prompts. |
| NanoVLM | Use mini vision/language models and the optimized multimodal pipeline for live streaming. |
| Llama 3.2 Vision | Run Meta's multimodal Llama-3.2-11B-Vision model on Orin with HuggingFace Transformers. |
Vision Transformers
| EfficientVIT | MIT Han Lab's EfficientViT , Multi-Scale Linear Attention for High-Resolution Dense Prediction |
| NanoOWL | OWL-ViT optimized to run real-time on Jetson with NVIDIA TensorRT |
| NanoSAM | NanoSAM , SAM model variant capable of running in real-time on Jetson |
| SAM | Meta's SAM , Segment Anything model |
| TAM | TAM , Track-Anything model, is an interactive tool for video object tracking and segmentation |
Image Generation
| Cosmos | Cosmos is a world model development platform that consists of world foundation models, tokenizers and video processing pipeline to accelerate the development of Physical AI at Robotics & AV labs. |
| Genesis | Genesis is a physics platform designed for general-purpose Robotics/Embodied AI/Physical AI applications. |
| Flux + ComfyUI | Set up and run the ComfyUI with Flux model for image generation on Jetson Orin. |
| Stable Diffusion | Run AUTOMATIC1111's stable-diffusion-webui to generate images from prompts |
| SDXL | Ensemble pipeline consisting of a base model and refiner with enhanced image generation. |
| nerfstudio | Experience neural reconstruction and rendering with nerfstudio and onboard training. |
Audio
| Whisper | OpenAI's Whisper , pre-trained model for automatic speech recognition (ASR) |
| AudioCraft | Meta's AudioCraft , to produce high-quality audio and music |
| Voicecraft | Interactive speech editing and zero shot TTS |
RAG & Vector Database
| NanoDB | Interactive demo to witness the impact of Vector Database that handles multimodal data |
| LlamaIndex | Realize RAG (Retrieval Augmented Generation) so that an LLM can work with your documents |
| LlamaIndex | Reference application for building your own local AI assistants using LLM, RAG, and VectorDB |
API Integrations
| ROS2 Nodes | Optimized LLM and VLM provided as ROS2 nodes for robotics |
| Holoscan SDK | Use the Holoscan-SDK to run high-throughput, low-latency edge AI pipelines |
| Jetson Platform Services | Quickly build microservice driven vision applications with Jetson Platform Services |
| Gapi Workflows | Integrating generative AI into real world environments |
| Gapi Micro Services | Wrapping models and code to participate in systems |
| Ultralytics YOLOv8 | Run Ultralytics YOLOv8 on Jetson with NVIDIA TensorRT. |
在这里,我们先熟悉 llamaspeak 使用流式 ASR/TTS 与 Llama 进行实时交谈,并与 Llava 讨论图像!
存在一些问题
能否在jetson nano 上实现这套方案。毕竟Jetson Orin NX 16GB还是比较贵。riva 支持中文的能力怎么样?是否可以跑 whisper。
个人感觉。目前硬件平台还是比较贵。 应用的场景受到限制。