【大模型系列篇】Qwen3思考预算及思考模式切换实现原理探索

我们之前一期有介绍过阿里发布并开源的Qwen3大语言模型,无缝集成思考模式、多语言和MCP智能体:《Qwen3开源全新一代大语言模型来了,深入思考,更快行动》,感兴趣的小伙伴可以跳转阅读。
而在本次开源的 Qwen3 的更新中,核心亮点之一是支持思考模式的切换。Qwen3 既可以在思考模式下深思熟虑,也可以在非思考模式中提供快速的响应。更重要的是,这两种模式的结合增强了 Qwen3 实现稳定且高效的“思考预算”控制能力。如下图所示,随着思考预算分配的提升,模型在评测集上的得分也逐渐提升。这样一来,用户可以根据不同的任务难度分配不同的预算,从而在速度与性能之间实现更优的平衡。
那么,思考预算和思考模式切换都是如何实现的呢?
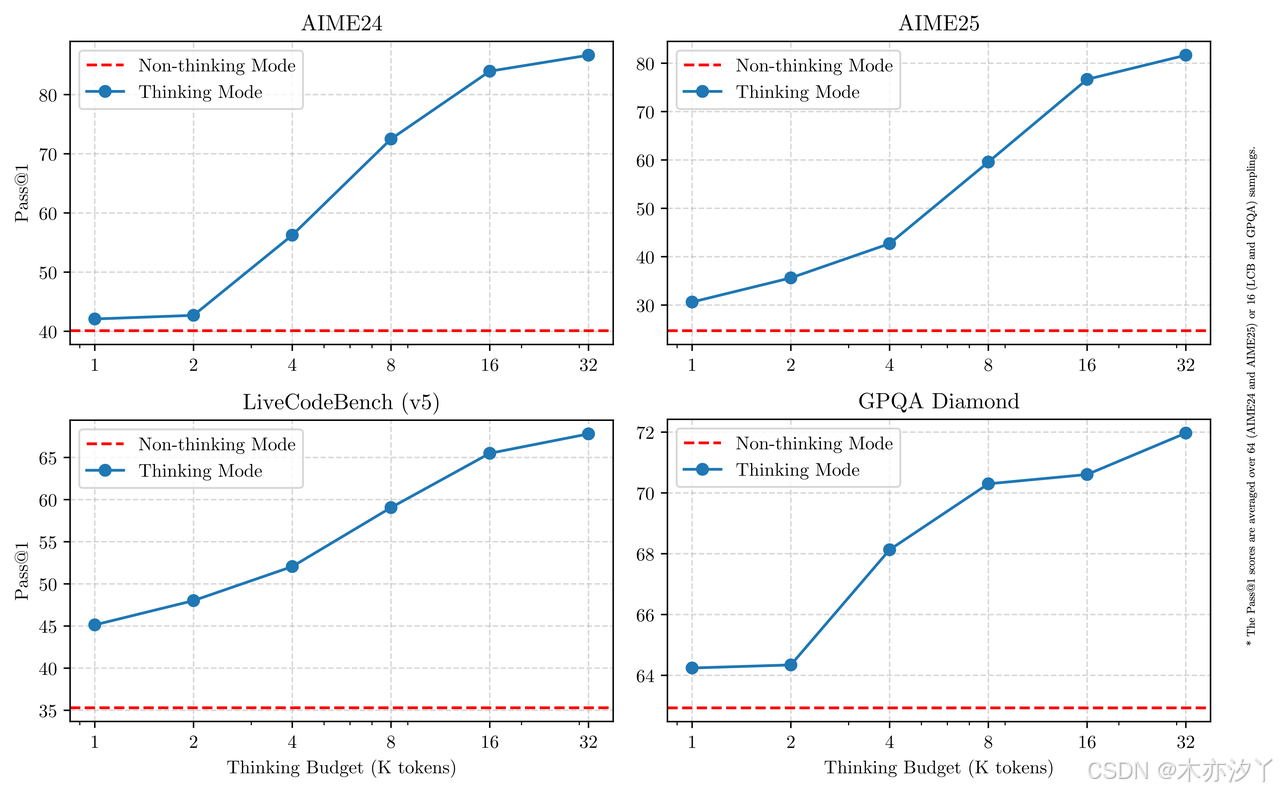
思考预算原理
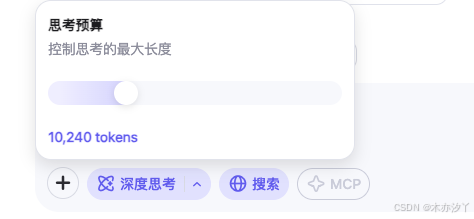
在 Qwen Chat 网页版 chat.qwen.ai 上,深度思考的思考预算是可调节的,粒度为 1024 tokens,最大可达 38912 tokens,也就是 38 * 1024 tokens,如下图所示。
那么,在解密思考预算调整的原理之前,我们先来看一个例子。下图展示了 Qwen3-235B-A22B 在 1024 tokens 的思考预算下回答问题的情况。(为了能让 Qwen3 可以思考到 1024 tokens 或者更多,这里使用了一个马尔科夫链的相关问题)
示例问题:
假设赌徒初始本金为 A 元,每局赌博有 50% 概率赢 1 元或输 1 元,目标是达到 N 元或破产。此问题可通过马尔科夫链建模,计算最终破产或成功的概率,请问如何计算?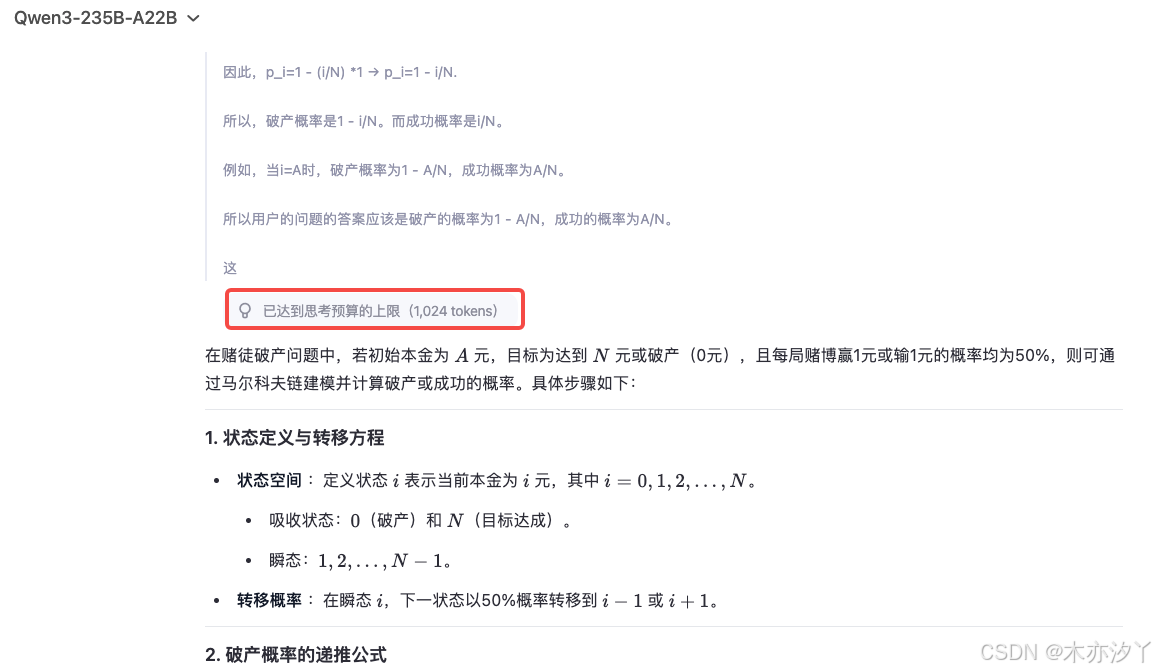
Qwen3 在达到思考预算上限时,思考过程就戛然而止了。所以很难不让人相信,思考预算的实现原理就是,统计思考过程中的(<think> 后) tokens 数量,达到思考预算上限时,立刻停止思考(强行截断停止),并补上 </think>,以进入输出阶段。
思考模式切换
Qwen3 思考模式切换的原理相对透明,可以在 Qwen3 的 tokenizer_config.json 中的 chat_template 中看到。下面展示了 Jinja 格式的 Qwen3 对话模板。
{%- if tools %}{{- '<|im_start|>system\n' }}{%- if messages[0].role == 'system' %}{{- messages[0].content + '\n\n' }}{%- endif %}{{- "# Tools\n\nYou may call one or more functions to assist with the user query.\n\nYou are provided with function signatures within <tools></tools> XML tags:\n<tools>" }}{%- for tool in tools %}{{- "\n" }}{{- tool | tojson }}{%- endfor %}{{- "\n</tools>\n\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\n<tool_call>\n{\"name\": <function-name>, \"arguments\": <args-json-object>}\n</tool_call><|im_end|>\n" }}
{%- else %}{%- if messages[0].role == 'system' %}{{- '<|im_start|>system\n' + messages[0].content + '<|im_end|>\n' }}{%- endif %}
{%- endif %}
{%- set ns = namespace(multi_step_tool=true, last_query_index=messages|length - 1) %}
{%- for message in messages[::-1] %}{%- set index = (messages|length - 1) - loop.index0 %}{%- if ns.multi_step_tool and message.role == "user" and not(message.content.startswith('<tool_response>') and message.content.endswith('</tool_response>')) %}{%- set ns.multi_step_tool = false %}{%- set ns.last_query_index = index %}{%- endif %}
{%- endfor %}
{%- for message in messages %}{%- if (message.role == "user") or (message.role == "system" and not loop.first) %}{{- '<|im_start|>' + message.role + '\n' + message.content + '<|im_end|>' + '\n' }}{%- elif message.role == "assistant" %}{%- set content = message.content %}{%- set reasoning_content = '' %}{%- if message.reasoning_content is defined and message.reasoning_content is not none %}{%- set reasoning_content = message.reasoning_content %}{%- else %}{%- if '</think>' in message.content %}{%- set content = message.content.split('</think>')[-1].lstrip('\n') %}{%- set reasoning_content = message.content.split('</think>')[0].rstrip('\n').split('<think>')[-1].lstrip('\n') %}{%- endif %}{%- endif %}{%- if loop.index0 > ns.last_query_index %}{%- if loop.last or (not loop.last and reasoning_content) %}{{- '<|im_start|>' + message.role + '\n<think>\n' + reasoning_content.strip('\n') + '\n</think>\n\n' + content.lstrip('\n') }}{%- else %}{{- '<|im_start|>' + message.role + '\n' + content }}{%- endif %}{%- else %}{{- '<|im_start|>' + message.role + '\n' + content }}{%- endif %}{%- if message.tool_calls %}{%- for tool_call in message.tool_calls %}{%- if (loop.first and content) or (not loop.first) %}{{- '\n' }}{%- endif %}{%- if tool_call.function %}{%- set tool_call = tool_call.function %}{%- endif %}{{- '<tool_call>\n{"name": "' }}{{- tool_call.name }}{{- '", "arguments": ' }}{%- if tool_call.arguments is string %}{{- tool_call.arguments }}{%- else %}{{- tool_call.arguments | tojson }}{%- endif %}{{- '}\n</tool_call>' }}{%- endfor %}{%- endif %}{{- '<|im_end|>\n' }}{%- elif message.role == "tool" %}{%- if loop.first or (messages[loop.index0 - 1].role != "tool") %}{{- '<|im_start|>user' }}{%- endif %}{{- '\n<tool_response>\n' }}{{- message.content }}{{- '\n</tool_response>' }}{%- if loop.last or (messages[loop.index0 + 1].role != "tool") %}{{- '<|im_end|>\n' }}{%- endif %}{%- endif %}
{%- endfor %}
{%- if add_generation_prompt %}{{- '<|im_start|>assistant\n' }}{%- if enable_thinking is defined and enable_thinking is false %}{{- '<think>\n\n</think>\n\n' }}{%- endif %}
{%- endif %}我们直接来看最后几行,也就是 add_generation_prompt 部分。
{%- if add_generation_prompt %}{{- '<|im_start|>assistant\n' }}{%- if enable_thinking is defined and enable_thinking is false %}{{- '<think>\n\n</think>\n\n' }}{%- endif %}
{%- endif %}上面就是 add_generation_prompt 部分的代码。可以看到,如果传入了 enable_thinking 并且为 false 的情况下,模型就会在 <|im_start|>assistant\n 的后面再补上 <think>\n\n</think>\n\n 以让模型结束思考,直接进入输出阶段。
让我们再来看 QwQ 在 add_generation_prompt 时的行为,来更好地理解 Qwen3 的思考模式切换逻辑。
{%- if add_generation_prompt %}{{- '<|im_start|>assistant\n<think>\n\n' }}
{%- endif %}可以看到 QwQ 通过补上额外的 <think> 来让模型强制进入思考阶段。而Qwen3 通过补上 <think>\n\n</think>\n\n 的方式告诉模型,思考阶段什么都没有,但是思考阶段已经结束了,需要进入最终输出阶段了,从而实现了思考模式切换。
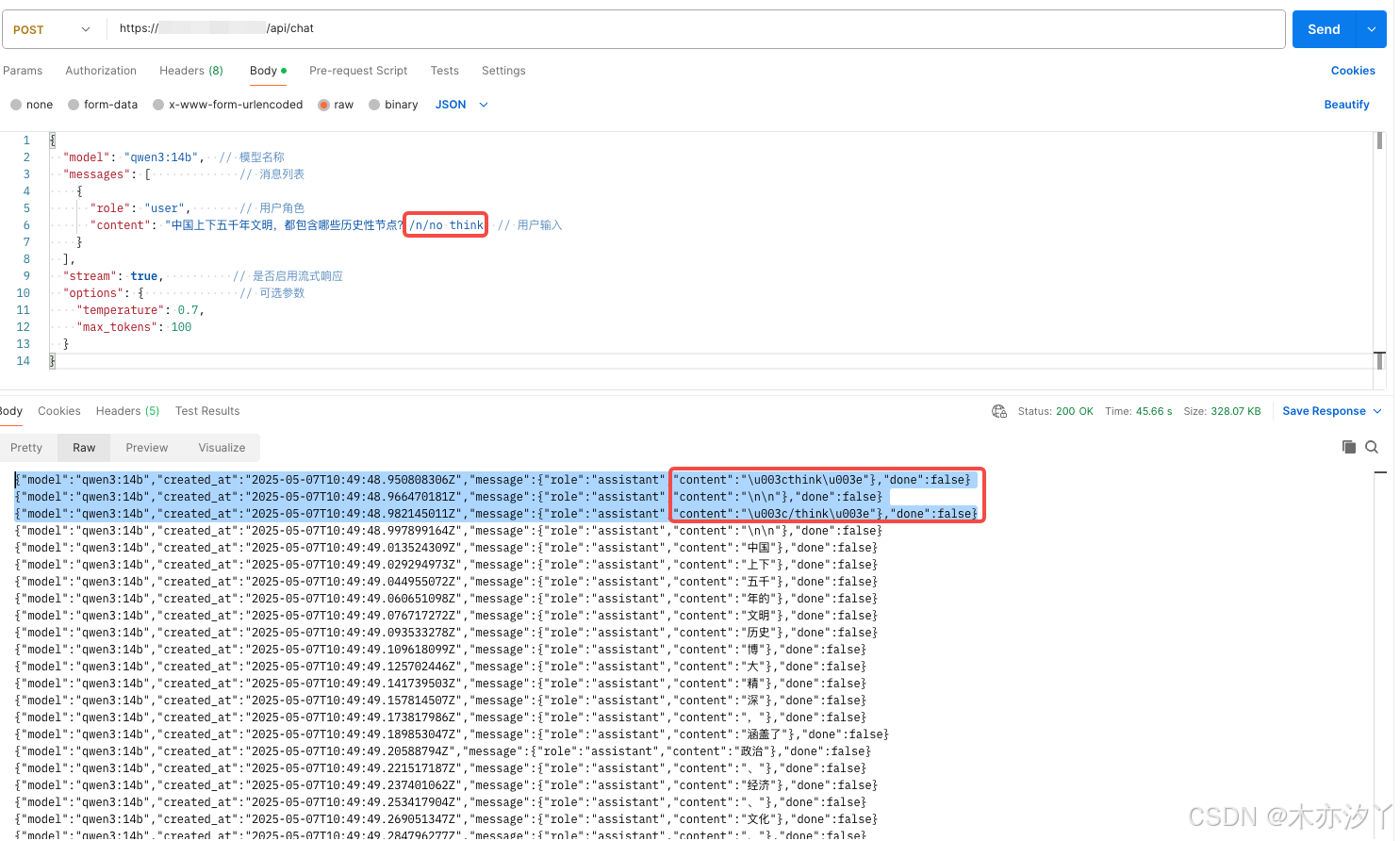
更多关于Qwen3思考模式的探索,欢迎跳转阅读《对Qwen3提到的thinking和no thinking混合思考模式的讨论》。
