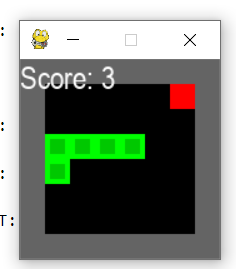
当前位置: 首页 > java >正文 Policy Gradient思想、REINFORCE算法,以及贪吃蛇小游戏(四)(完结) java 2025/7/16 6:19:26 文章目录 前情提要pytorch实现数据从哪儿来?REINFORCE算法的不足之处全部代码 前情提要 我们上次推导出了REINFORCE算法等效的损失函数。 L ( θ ) ≈ − E τ ∼ π θ 查看全文 http://www.xdnf.cn/news/458.html 相关文章: 基于 Linux 环境的办公系统开发方案 智能座舱架构与芯片 - 背景篇 医院科研科AI智能科研支撑平台系统设计架构方案探析 点云(Point Cloud)介绍 Cocos Creater打包安卓App添加隐私弹窗详细步骤+常见问题处理 第33讲|遥感大模型在地学分类中的初探与实战 PyTorch :优化的张量库 数据从辅存调入主存,页表中一定存在 websocket和SSE学习记录 得物官网sign签名逆向分析 Qt QWidget介绍及学习方法路线分享 服务治理-服务注册 【记录】服务器安装ffmpeg 在 Amazon Graviton 上运行大语言模型:CPU 推理性能实测与调优指南 整合SSM——(SpringMVC+Spring+Mybatis) 10.thinkphp的响应 Android studio开发——room功能实现用户之间消息的发送 sqilite_web安装使用 实现Azure Function安全地请求企业内部API返回数据 Rust网络编程实战:全面掌握reqwest库的高级用法 Meteonorm8-免费使用教程(详细教程-免费) 数据结构(6)——队列 STM32N6如何调试下载代码 MCP认证难题破解:常见技术难题实战分析与解决方案 哈夫曼编码和哈夫曼树 Dify快速入门之构建工作流 Python语法系列博客 · 第4期[特殊字符] 函数的定义与使用:构建可复用的模块 java ai 图像处理 php实现zip压缩 Linux:基础IO---动静态库