2025年五一杯C题详细思路分析
C题 社交媒体平台用户分析问题
问题背景
近年来,社交媒体平台打造了多元化的线上交流空间和文化圈,深刻影响着人们社交互动与信息获取。博主基于专业知识或兴趣爱好等创作出高质量内容,吸引并获得用户的关注。用户可以随时通过观看、点赞、评论等行为积极参与其中。博主依据平台的推荐机制和用户反馈,调整并提升内容质量,从而提高自身影响力。而用户则通过互动行为,反向影响平台的内容推荐系统。
现某社交媒体平台需深入分析现有用户和博主之间的互动行为关系,来预测用户行为,并优化内容推荐方法。附件1记录了该平台在2024.7.11-2024.7.20之间的数据,包括用户ID、用户行为、博主ID、时间。其中用户行为列中,数字1、2、3分别代表用户对博主发布内容的观看、点赞、评论,4代表关注该博主。时间列代表用户行为发生的时间。需要注意的是,用户点赞、评论和关注的行为均代表用户已观看了内容。此外,用户使用该社交媒体平台的频率和时间不同,若某段时间内附件1中没有记录某用户的行为数据,则代表该时段内用户没有使用该社交媒体平台。附件2中记录了2024.7.22用户进行观看、点赞、评论的行为数据。
假设:(1) 该平台用户和博主数量固定,不存在平台新用户/博主的加入和账号注销行为;(2)用户和博主的互动关系建立后不再变化,即平台中用户不存在取消点赞、删除评论、取消关注的行为。请结合附件数据,建立数学模型,解决下列问题。
问题分析:本题旨在通过社交媒体平台提供的用户与博主互动数据(观看、点赞、评论、关注),分析用户行为,预测后续行为,并为内容推荐策略提供支持。数据具有明显的时间序列特征和交互网络属性。
问题1分析:预测每个博主在7月21日新增的关注数
问题1. 基于用户与博主历史交互数据(观看、点赞、评论、关注)的统计分析,能够有效揭示用户行为特征,为内容优化和交互提升提供决策依据。根据附件1提供的数据,请建立数学模型,预测各博主在2024.7.21当天新增的关注数,并根据预测结果,在表1中填写当日新增关注数最多的5位博主ID及其对应的新增关注数。
思路分析:
任务本质为时间序列预测或分类回归建模,用户对博主的关注行为是建立在历史互动的基础上,因此应挖掘前10日(7.11–7.20)中,用户对博主的累积交互趋势,识别转化为“关注”的概率。
数据统计与预处理:
表1
| 统计项 | 数值 | 备注 |
| 总记录数 | 2,210,440 | 所有用户行为的总记录数 |
| 不同用户数 | 19,999 | 独立用户数量 |
| 不同博主数 | 42 | 独立博主数量 |
表2 用户行为分布
| 行为类型 | 行为代码 | 记录数 | 占比(约) |
| 观看 | 1 | 1,199,263 | 54.25% |
| 点赞 | 2 | 708,860 | 32.07% |
| 评论 | 3 | 243,453 | 11.01% |
| 关注 | 4 | 58,864 | 2.66% |
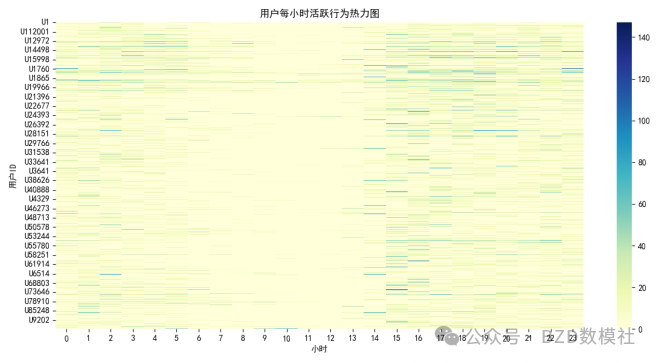
该热力图反映出用户在24小时内的行为频次分布,明显可以看到活跃高峰集中在14:00–19:00之间,尤其是16:00–17:00行为量较大;而凌晨时段(如0:00–8:00)行为极少。这种时间模式对问题4的“在线时段”预测尤为重要:用户具有较强的时间行为偏好,应在特征工程中引入“用户时段活跃概率”或“历史时段行为分布”作为预测依据。
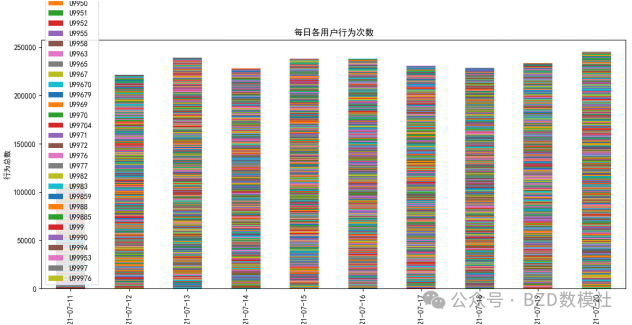
该图展示了各用户在不同日期的行为总数分布,具有明显的规律性:每日平台总活跃量大致稳定,用户行为分布也较为平滑,未出现极端峰值。这表明平台用户日活跃人数和行为总量波动不大,可在建模时合理假设用户使用平台的习惯稳定,同时也为问题3中的“是否在线”预测提供依据(如:连续活跃趋势、行为密度特征等)。
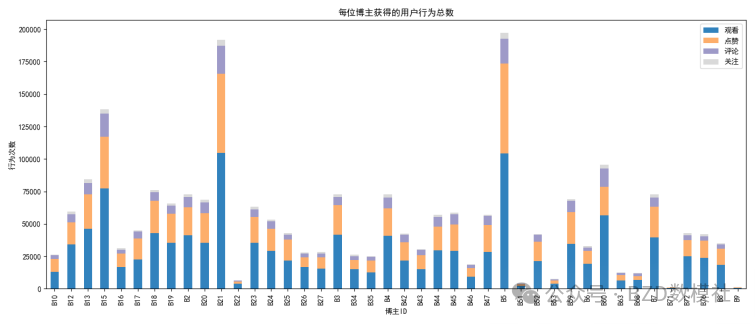
该热力图反映出用户在24小时内的行为频次分布,明显可以看到活跃高峰集中在14:00–19:00之间,尤其是16:00–17:00行为量较大;而凌晨时段(如0:00–8:00)行为极少。这种时间模式对问题4的“在线时段”预测尤为重要:用户具有较强的时间行为偏好,应在特征工程中引入“用户时段活跃概率”或“历史时段行为分布”作为预测依据。
建模流程:
利用2024年7月11日至7月20日的用户-博主交互数据(观看/点赞/评论/关注),选随机森林回归(Random Forest Regression),预测每位博主在7月21日新增关注量。随机森林算法是一种基于集成学习(Ensemble Learning)的机器学习算法,通过结合多个决策树的预测结果来提高模型的准确性和鲁棒性。核心主要分为以下五点:
1、Bootstrap聚合(Bagging):随机森林通过自助采样法(Bootstrap Sampling)从原始训练集中有放回地随机抽取多个子样本集,每个子集用于训练一棵独立的决策树。这种重采样策略增加了模型的多样性,同时通过聚合(如投票或平均)降低过拟合风险。
2、随机特征选择:在每棵决策树的节点分裂过程中,算法并非使用全部特征,而是从随机选取的特征子集中选择最优分裂点(通常子集大小为特征总数的平方根或对数)。这种双重随机性(数据样本和特征)进一步增强了模型的泛化能力,减少了树之间的相关性。
3、决策树集成:森林中的每棵树独立进行预测,分类任务采用多数投票法,回归任务采用平均值作为最终输出。这种“集体决策”机制能有效平衡单棵树的偏差和方差,提升整体模型的稳定性。其中,随机森林的基本单元为回归决策树,每棵树是一个 CART 回归树,使用如下目标函数进行分裂,对于节点
,其损失为:
4、天然评估机制:由于Bootstrap采样约有37%的样本未被选中(称为袋外数据OOB),这些数据可天然用于验证模型性能(OOB误差估计),无需额外交叉验证。
5、抗过拟合与鲁棒性:通过控制树的数量(n_estimators)、树的最大深度等参数,随机森林能在保持高精度的同时对噪声和异常值不敏感,且适用于高维数据。
Step 1:特征工程(以"博主"为单位聚合)
用户-博主维度构建特征:累计观看、点赞、评论次数;最近一次互动时间间隔;用户与博主间的“互动强度”得分(如行为加权和)。从数据中提取每位博主在7月11日-20日间的行为统计,构建以下特征:
总被观看数,点赞数,评论数,关注数(可按天聚合或总量)
其中,互动转化率:
日均行为量,波动性(std)等
活跃用户数(与该博主交互的用户总数)
Step 2:构建标签(Label)
计算每位博主在 7月21日的新增关注数,作为标签 y
Step 3:构造训练集并进行建模与训练
Step 4:预测与排序统计:预测为“关注”的用户-博主对中,按博主聚合,计算新增关注数排序,输出关注数最多的5个博主。
问题2分析:预测指定用户在7月22日的新关注行为
问题2. 附件2提供了2024.7.22当天用户进行观看、点赞、评论的行为数据,结合附件1中用户的历史行为数据,请建立数学模型,预测用户在2024.7.22产生的新关注行为,并将指定用户在2024.7.22新关注的博主ID填入表2。
表2 问题2结果
| 用户ID | U7 | U6749 | U5769 | U14990 | U52010 |
| 新关注博主ID |
注:若用户在2024.7.22关注多名博主,均填入表2;若用户在2024.7.22未新关注博主,无需填写。
思路分析:可将问题一的模型迁移应用到7月22日预测上,使用用户与博主在7.11–7.20的交互数据作为输入特征,其中,附件2提供了7月22日的“观看/点赞/评论”数据,用于增加实时行为信息。可以采用XGBoost方法来实现。定义每个样本为:
Step 2:特征工程(构造特征向量
)
表3
| 特征类型 | 例子 |
| 用户行为特征 | 用户U在7.11-20日的观看/点赞/评论/关注总数,日均行为 |
| 博主行为特征 | 博主 |
| 用户-博主交互特征 | 用户U对博主B的累计观看/点赞/评论/关注次数,最后一次互动时间距今几小时 |
| 行为比例特征 |
|
| 7.22即时行为特征 | 用户U在当天是否观看/点赞/评论了博主 B 内容(从附件2中提取) |
Step 3:构建训练集 & 标签集
对于每条用户-博主候选对(在附件2中出现),生成特征 + 标签
标签从“是否在7.22关注该博主”(来自附件1或真实标注)
Step 4:模型训练与预测
用训练好的模型预测:每个用户-博主对发生“关注”的概率,设定阈值(如0.5)筛选出预测为关注的博主,将预测关注的博主ID写入表2。
问题3分析:预测指定用户在7月21日是否上线,以及最可能互动的三位博主
问题3. 用户与博主之间互动数可视为点赞数、评论数、关注数之和,平台可据此制定合理的推荐方案,为用户推送“量身定制”的内容,增加用户与博主之间的互动。请基于附件1数据,建立数学模型,预测指定用户在2024.7.21当天是否在线(即使用该社交媒体平台),如果在线,进一步预测该用户可能与博主产生的互动关系,并给出可能与其产生互动数最高的3名博主,将对应的博主ID填入表3。
表3 问题3结果
| 用户ID | U9 | U22405 | U16 | U48420 |
| 博主ID 1 | ||||
| 博主ID 2 | ||||
| 博主ID 3 |
注:若该用户在2024.7.21未使用该社交媒体平台,则无需填写。
思路分析:两阶段进行建模分析。
第一阶段:预测用户是否在线(二分类问题)
输入:用户的历史行为统计
输出:1=在线,0=未在线
第二阶段:若在线,预测其与哪些博主可能产生互动(多分类或排序问题)
输入:用户-博主之间的历史交互强度 + 时间行为特征
输出:为每个候选博主打分,Top-3 输出
建模流程:
(1)构建用户时间行为画像:日活跃次数、总活跃天数、平均活跃时段、最近活跃天。若用户在7.20前连续多天活跃,推测其21日也可能上线
(2)训练是否上线模型(可以采用的方法如时间序列判别、Logistic回归、LSTM);
(3)若上线,预测互动强度:用问题一类似方法计算“互动得分”,然后输出分数最高的3个博主;
Step 1:是否在线建模(用户级别)
·特征构造:
·用户日均活跃次数
·最近一次活跃日期(距7月21日的天数)
·活跃间隔方差(是否稳定上线)
·活跃天数/总天数(活跃比)
·建模方法:二分类模型(如 RandomForestclassifier)
Step 2:互动博主预测(用户-博主对)
·构建侯选博主集:与用户在历史中有交互过的博主
·特征构造(用户-博主级别):
·历史互动总数(观看/点赞/评论/关注)
·最近一次互动时间(小时差)
·用户对博主的行为转化率(点赞率,评论率)
·博主整体活跃度
·构建回归模型或排序模型:预测"互动强度"
输出打分最高的 Top-3 博主作为结果
问题4分析:预测指定用户在7月23日的在线时段及互动最多的三位博主及时段
问题4. 平台在制定推荐方案时,会充分考虑不同用户使用社交媒体的时间习惯。在问题3的基础上,基于附件1数据,建立数学模型,预测表4中指定用户在2024.7.23是否在线(即使用社交媒体平台),进一步预测该用户在每个在线时段与每个博主的互动数,给出该互动数最高的3名博主ID以及对应的时段,并将结果填入表4。
表4 问题4结果
| 用户ID | U10 | U1951 | U1833 | U26447 |
| 博主ID 1 | ||||
| 时段1 | ||||
| 博主ID 2 | ||||
| 时段2 | ||||
| 博主ID 3 | ||||
| 时段3 |
注:若该用户在2024.7.23未使用该社交媒体平台,则无需填写;推荐时段,只能在以下24个时段中选取0:00-1:00, 1:00-2:00, ……, 23:00-24:00。
本质:多时段二分类+ 用户-博主-时段三维预测任务
思路分析:在问题三基础上进一步细化为“时段级别”的分析,体现出用户行为时间分布特征。由于每个用户24小时内存在不同活跃概率,可做时段粒度预测。
建模流程:
(1)按小时划分24个时段,统计历史7.11–7.20的用户活跃时段概率分布;
(2)预测用户在7.23是否在线 + 哪些时段在线(可用多标签分类);
(3)基于每个在线时段预测该用户在该时段与哪些博主可能互动(与问题三方法相似);
(4)输出互动数最高的三个“博主-时段”组合.
Step 1:每小时是否在线预测(用户 小时)
·构造每小时用户是否活跃的标签(历史7.11-7.20数据)
·特征示例:
·某用户在"周几+某小时"出现的频率
·用户高频活跃时段分布(如0:00-2:00)
·平均每日活跃时间窗(活跃中位数)
·建模为多标签分类或 24 个小时的二分类问题:
·Step 2:预测用户-博主在各时段的互动数
·构建特征:用户 博主 时段
·用户在该时段的历史行为频率
·用户对该博主在该时段的行为频率
·用户在该时段总行为频率占比
·博主在该时段的活跃程度
·模型预测每个组合的互动次数,取Top3:
| 任务阶段 | 推荐方法 |
| 特征构造 | 用户-博主行为统计、滑动时间窗、TF-IDF等 |
| 分类建模 | Logistic 回归、随机森林、XGBoost、LightGBM |
| 序列建模 | LSTM、GRU、Transformer(针对时序活跃度预测) |
| 相似度挖掘 | 协同过滤、余弦相似度、相对频率建模(辅助推荐) |
| 排序推荐 | 基于打分的Top-K推荐(如评分模型 + 排序) |
| 任务 | 指标 |
| 是否关注/上线预测 | Accuracy、Recall、Precision、F1-score |
| 行为预测 | AUC、Hit@K、NDCG@K |
| 排名推荐 | MAP、MRR、Top-K命中率 |
| 模型 | 用于 | 工具 |
| RandomForestClassifier | 是否在线预测(二分类) | sklearn |
| XGBoostClassifier | 高维组合建模 | xgboost |
| LightGBM Ranker | 博主排序推荐 | lightgbm |
| 多标签分类 | 每小时在线预测 | scikit-multilearn(或 One-vs-Rest) |
| 可选:协同过滤 | 用户-博主行为建模 | Surprise, implicit |
可视化建议:
用户行为热力图(用户vs 时段)
用户-博主交互网络图
活跃度趋势线(用户/博主时间序列)
推荐结果精度评估(AUC、Precision等)
注:该问题只是一个简单的思路,目前正在代码的优化以及全篇论文的写作。具体完整代码与完整论文稍后全部完成会进行发布。
后续方法和思路持续更新中,会对方法进行优化操作ing。