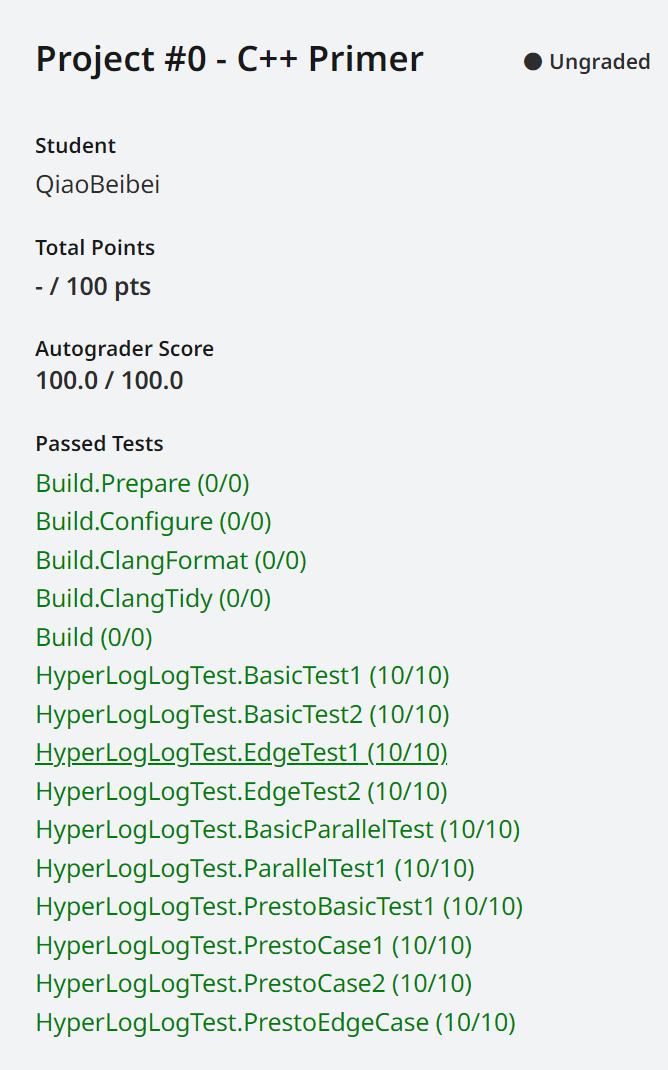
CMU-15445(2)——PROJECT#0-C++PRIMER
PROJECT#0 - C++PRIMER
作业的详细描述原文如下:
Project #0 - C++ Primer | CMU 15-445/645 :: Intro to Database Systems (Fall 2024)
然后完成两个task:
- implement a basic HyperLogLog data structure
- implement Presto’s dense layout implementation of HLL
我将从我的角度记录这个项目本身的背景知识,并解释我对这两个task的理解。
Project Specification
考虑跟踪单日访问网站的唯一用户数量这一问题。对于仅由少数人访问的小型网站,这一任务非常直接;但对于拥有数十亿用户的大型网站,处理起来则困难得多。在这种情况下,将每个用户存储在列表中并检查重复项是不现实的。海量数据会导致一系列重大挑战,包括内存耗尽、处理速度缓慢以及其他效率问题。
HyperLogLog(HLL)是一种用于跟踪大型数据集基数的概率数据结构。HLL 适用于上述场景,其目标是在不显式存储每个元素的情况下,统计大规模数据流中的唯一元素数量。HLL 依赖巧妙的哈希机制和紧凑的数据结构,只需传统方法所需内存的一小部分,即可提供对唯一用户数的准确估计。这使其成为现代数据库分析中的重要工具。
简单来说就是面多大规模用户数据,如何去重并统计总数(常规方法用位图解决,布隆过滤器对于某些情况也适用)
HLL 的核心是通过哈希函数将元素映射到二进制位序列,利用 “前导零计数” 来概率性地估计基数,避免显式存储所有元素。HLL 的概率计数机制基于以下参数:
b:哈希值的二进制表示形式中的初始位数,用于划分桶(Bucket)的初始位数,决定桶的数量m = 2^b。m:桶的数量(也称为寄存器Registers),每个桶存储一个非负整数。p:哈希值中左起第一个1的位置(即前导零的数量加 1)。
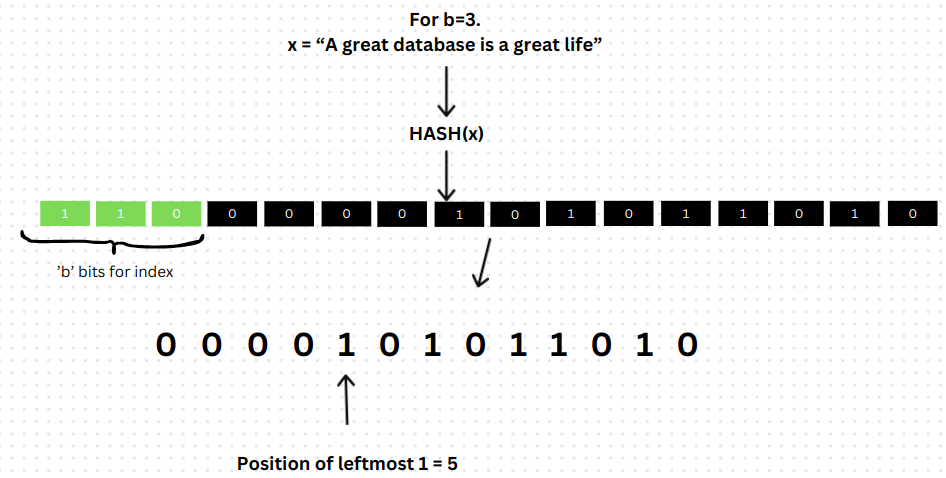
以字符串 "A great database is a great life" 为例,说明算法的工作原理:
- 首先对字符串进行哈希处理,生成哈希值,并转换为二进制表示。假设为:
110 0000101011010
-
从哈希值的二进制形式中,从最高有效位(MSB)开始提取 b 位(
101),根据这 b 位计算对应的寄存器索引(例如,若 b=3,则 2^3=8 个寄存器,索引范围为 0-7,且110转换为十进制是6,因此该元素属于桶6)。初始时,每个寄存器的值为 0(即register[0]~register[7]初始均为 0)。 -
从剩余的二进制位中,找到最左侧 1 的位置 p(即前导零的数量加 1)。例如,若剩余位为
000010...,则前导零有 4 个,p=4+1=5。则该元素在桶6,且值为p=5。
-
对于当前寄存器索引(由前 b 位确定),将其值更新为 max (寄存器当前值,p)。
- 比较当前寄存器值
0和新计算的p=4,取最大值:register[6] = max(0, 5) = 5 - 若后续有另一个元素也属于桶 6,且计算得到
p=3,则:register[6] = max(5, 3) = 5 - 若新元素的
p=6,则:register[6] = max(5, 6) = 6
- 比较当前寄存器值
按上述步骤添加集合中的所有元素之后,按以下方式计算基数(唯一元素数):
- 若共有 m 个寄存器,则基数估计公式为:
N = α m ⋅ m 2 ⋅ ( ∑ j = 0 m − 1 2 − R [ j ] ) − 1 N = \alpha_m \cdot m^2 \cdot \left(\sum_{j = 0}^{m - 1} 2^{-R[j]}\right)^{-1} N=αm⋅m2⋅(j=0∑m−12−R[j])−1
其中,α_m是修正常数(当m较大时,通常取 0.79402),R[j]是第 j 个寄存器(桶)的值。
为什么HLL能够适用于海量数据去重估计总数?
HyperLogLog(HLL)的核心创新在于彻底摒弃了传统去重方法中 “存储具体元素” 的思路,转而通过捕捉哈希值的二进制特征来实现基数估算,这使其空间复杂度从依赖数据规模的 O (N) 骤降至仅与固定桶数相关的 O (M)(M是桶的数量)。具体来说,HLL 首先将每个元素通过哈希函数转换为 64 位二进制串,取前 b 位确定该元素所属的桶(共 m=2^b 个桶,例如 b=14 时 m=16384),然后对剩余二进制位统计 “从最低位开始的连续零的最大数量”(或者通过前导零+1作为计数,记作 p 值)—— 这个 p 值越大,说明该元素在哈希空间中越 “独特”(出现概率越低)。每个桶仅存储所有归属元素中最大的 p 值(即 r_max),这种 “只存最大值” 的策略让每个桶仅需占用 1 字节(8 位)存储空间,即使 m=16384,总内存也仅需 16KB 左右。
这种设计的精妙之处在于,通过数学公式将各桶的 r_max 转化为基数估计值:利用调和平均原理,将所有桶的 1/(2^r_max) 进行聚合,结合修正常数后得到最终结果。以 m=16384 为例,m² 达到约 2.7 亿,配合 0.794 的修正常数,该公式能有效将亿级规模的基数映射到 16KB 的内存空间中。由于每个元素的处理仅涉及固定的哈希计算和桶内比较,HLL 的插入和查询操作均能在 O (1) 时间内完成,极大提升了大数据场景下的处理效率。
不过 HLL 的优势建立在概率统计的基础上,这意味着它的计算结果是一个估算值而非精确计数,典型误差率约为 1%(通过增加桶数可进一步降低)。此外,当唯一元素数量较小(如 N<1000)时,哈希分桶的统计特性难以充分发挥,此时传统集合结构可能更精准;而当唯一元素数远大于桶数(如亿级规模)时,HLL 的估算精度和内存效率达到最佳平衡,成为数据库分析、流量统计等场景的首选方案。这种 “以概率换空间” 的设计,让 HLL 在不存储任何原始数据的前提下,用极小的内存开销实现了对大规模数据基数的高效估算。
如果要精确去重可采用位图来记录每一个元素,如果想一个元素是否存在集合中,可采用布隆过滤器。
不同桶使用的数据量
| 桶数 (m) | 内存占用 | 理论误差率 | 实际应用场景 |
|---|---|---|---|
| 16 | 16B | ~26% | 玩具示例 |
| 256 | 256B | ~6.5% | 小规模基数统计 |
| 16384 | 12KB | ~0.81% | 亿级数据(如 Redis) |
| 131072 | 96KB | ~0.28% | 超大规模数据(如 GCP) |
- Redis 的选择:16384 个桶在内存(12KB)和精度(0.81%)之间取得平衡,适用于多数互联网场景(如 Reddit 的帖子浏览量统计)。
- 扩展性:若需更高精度(如 0.28%),可增加桶数至 131072,但内存消耗增至 96KB。
在实际实现中,一些系统存储寄存器中最左边的 1 位 (MSB) 的位置,而另一些系统则存储最右边的连续 0 位 (LSB) 的计数。本项目内容
- Task 1 将使用前一种方法,将最左边的 1 位的位置存储在 register 中。
- Task 2 将使用后一种方法,将最右边的连续零的计数存储在register 。
Task#1
task1其实就是让我们实现HLL的数据结构,在该task中,我们需要用到以下文件:
src/primer/hyperloglog.cpp:实现我们定义的函数src/include/primer/hyperloglog.h:定义了一些我们需要实现的函数test/primer/hyperloglog_test.cpp:用来测试TASK1是否通过
hyperloglog.h
hyperloglog.h 中已经帮我们提前声明了一些我们需要实现的函数,主要内容如下:
/** @brief Capacity of the bitset stream. */
#define BITSET_CAPACITY 64namespace bustub {template <typename KeyType>
class HyperLogLog {/** @brief Constant for HLL. */static constexpr double CONSTANT = 0.79402;public:/** @brief Disable default constructor. */HyperLogLog() = delete;explicit HyperLogLog(int16_t n_bits);/*** @brief Getter value for cardinality.** @returns cardinality value*/auto GetCardinality() { return cardinality_; }auto AddElem(KeyType val) -> void;auto ComputeCardinality() -> void;private:/*** @brief Calculates Hash of a given value.** @param[in] val - value* @returns hash integer of given input value*/inline auto CalculateHash(KeyType val) -> hash_t {Value val_obj;if constexpr (std::is_same<KeyType, std::string>::value) {val_obj = Value(VARCHAR, val);} else {val_obj = Value(BIGINT, val);}return bustub::HashUtil::HashValue(&val_obj);}auto ComputeBinary(const hash_t &hash) const -> std::bitset<BITSET_CAPACITY>;auto PositionOfLeftmostOne(const std::bitset<BITSET_CAPACITY> &bset) const -> uint64_t;/** @brief Cardinality value. */size_t cardinality_;/** @todo (student) can add their data structures that support HyperLogLog */
};} // namespace bustub
代码中,静态常量CONSTANT 其实就是用于计算基数估计公式中的 α_m ,通常取0.79402。
大部分公有函数都需要我们实现,有必要的话还需要我们自己额外定义一些辅助函数,这些函数的作用如下:
-
默认构造函数被显示
delete,需要我们实现只接收一个参数且禁止隐式转换的HyperLogLog构造函数,形参其实就是前导位数的参数b。 -
GetCardinality()用于返回当前集合的基数估计值,我们需要将集合中的元素都添加进HLL,然后通过上面介绍的公式生成一个值,将该值赋值给私有成员变量size_t cardinality_,然后返回该值即可。 -
AddElem(KeyType val)用于根据输入值生成哈希值并存储到对应的寄存器中,其实就是将输入值存储到HLL中。输入值的变量类型是KeyType,这是一个模板类,我们需要特化该类才能使用。 -
ComputeCardinality()用下面的公式计算基数估计值,在调用GetCardinality()前,应该要确保集合的元素都被添加到HLL,并且ComputeCardinality()被调用。
N = α m ⋅ m 2 ⋅ ( ∑ j = 0 m − 1 2 − R [ j ] ) − 1 N = \alpha_m \cdot m^2 \cdot \left(\sum_{j = 0}^{m - 1} 2^{-R[j]}\right)^{-1} N=αm⋅m2⋅(j=0∑m−12−R[j])−1
私有部分同样提供了一些辅助函数,CalculateHash(KeyType val)是内置的一个哈希函数,用于计算哈希值,但是计算出来的哈希值还需要调用我们实现的 ComputeBinary(hash_t hash) 才能将哈希值转换为二进制,进而才能添加至 HLL。
此外,还需要我们定实现一些额外的辅助函数:
ComputeBinary(hash_t hash):将给定的哈希值转换为 64 位二进制流(否则测试可能失败)。PositionOfLeftmostOne(...):计算二进制串中最左侧 1 的位置。
最后,除了该类已经提供的用于存储基数估计值的变量 cardinality_ 外,还需要我们自定义数据结构用于存储每个桶的寄存器值,初始化大小为2^n_bits,每个元素初始化为0,调用构造函数时完成:
std::vector<uint8_t> registers_;
哈希函数已经帮我们实现,可以参考以下实现过程:
inline auto CalculateHash(KeyType val) -> hash_t {Value val_obj;if constexpr (std::is_same<KeyType, std::string>::value) {val_obj = Value(VARCHAR, val); // 处理字符串类型,创建VARCHAR类型的Value对象} else {val_obj = Value(BIGINT, val); // 处理其他类型(如整数),创建BIGINT类型的Value对象}return bustub::HashUtil::HashValue(&val_obj); // 使用HashUtil生成64位哈希值
}
Value 是一个自定义的类,实现文件在./src/include/type/value.h,就是对不同的数据类型进行封装,这样方便统一处理不同的数据。
整体思想类似于STL的迭代器,对原生指针和自定义类型加了一层封装类,然后就可以使用同一个STL算法对不同的迭代器进行处理。
VARCHAR 和 BIGINT 是枚举值:
namespace bustub {
// Every possible SQL type ID
enum TypeId { INVALID = 0, BOOLEAN, TINYINT, SMALLINT, INTEGER, BIGINT, DECIMAL, VARCHAR, TIMESTAMP, VECTOR };
} // namespace bustub
枚举值对应的数据类型表如下:
| 构造函数参数 | 数据类型 | 说明 |
|---|---|---|
int8_t | TINYINT/BOOLEAN | 8 位整数(布尔值用 0/1 表示) |
int16_t | SMALLINT | 16 位整数 |
int32_t | INTEGER | 32 位整数 |
int64_t | BIGINT | 64 位整数 |
double/float | DECIMAL/FLOAT | 浮点型数据 |
uint64_t | TIMESTAMP | 时间戳(通常存储为 Unix 时间戳) |
const char*, uint32_t | VARCHAR | 变长字符串(手动管理内存或由类托管) |
std::vector<double> | VECTOR | 向量类型(如用于存储数组或集合) |
hyperloglog.cpp
因为课程要求,代码不能公布,因此这里我只说一下我的思路。
初始代码如下:
namespace bustub {/** @brief Parameterized constructor. */
template <typename KeyType>
HyperLogLog<KeyType>::HyperLogLog(int16_t n_bits) : cardinality_(0) {}/*** @brief Function that computes binary.** @param[in] hash* @returns binary of a given hash*/
template <typename KeyType>
auto HyperLogLog<KeyType>::ComputeBinary(const hash_t &hash) const -> std::bitset<BITSET_CAPACITY> {/** @TODO(student) Implement this function! */return {0};
}/*** @brief Function that computes leading zeros.** @param[in] bset - binary values of a given bitset* @returns leading zeros of given binary set*/
template <typename KeyType>
auto HyperLogLog<KeyType>::PositionOfLeftmostOne(const std::bitset<BITSET_CAPACITY> &bset) const -> uint64_t {/** @TODO(student) Implement this function! */return 0;
}/*** @brief Adds a value into the HyperLogLog.** @param[in] val - value that's added into hyperloglog*/
template <typename KeyType>
auto HyperLogLog<KeyType>::AddElem(KeyType val) -> void {/** @TODO(student) Implement this function! */
}/*** @brief Function that computes cardinality.*/
template <typename KeyType>
auto HyperLogLog<KeyType>::ComputeCardinality() -> void {/** @TODO(student) Implement this function! */
}template class HyperLogLog<int64_t>;
template class HyperLogLog<std::string>;} // namespace bustub
构造函数
- 在实现构造函数前,需定义一个容器 registers_ 存储桶中的数值,寄存器的值最大是64,范围在 0 到
64 - b,因此使用uint8_t类型即可。 - 此外,需额外定义一个互斥mutex用于保证线程安全
ComputeBinary
直接调用std::bitset<64> 的构造函数返回 64 位二进制即可。
PositionOfLeftmostOne
在 std::bitset 里,最左边的位是最高位,因此我们需要从 std::bitset 的最高位(BITSET_CAPACITY - 1 - n_bits_)开始,向最低位(0)遍历。
- 当找到第一个值为
1的位时,通过BITSET_CAPACITY - i - n_bits_计算出前导零的数量; - 如果整个
std::bitset都是0,则返回BITSET_CAPACITY - n_bits_,表示所有位都是前导零。
整个时间复杂度是O(n)
GetBucketValue
自定义一个 GetBucketValue 辅助函数,用于获取二进制哈希值前 b 位的十进制数,用于找该元素对应的桶索引。整体思路是将结果值在每次循环中左移一位,然后将位图中的当前索引代表的高位加入到结果值后面,直至循环结束。
举例:
- 第一次循环(
i = 0):value <<= 1;:value左移一位,由于value初始值为 0,左移后仍为 0。bset[BITSET_CAPACITY - 1 - i]即bset[63],对应二进制数的最高位,值为 1。value |= static_cast<uint8_t>(bset[63]);:将 1 加入到value中,此时value的二进制表示为00000001,十进制值为 1。
- 第二次循环(
i = 1):value <<= 1;:value左移一位,二进制表示变为00000010,十进制值为 2。bset[BITSET_CAPACITY - 1 - i]即bset[62],值为 1。value |= static_cast<uint8_t>(bset[62]);:将 1 加入到value中,此时value的二进制表示为00000011,十进制值为 3。
- 第三次循环(
i = 2):value <<= 1;:value左移一位,二进制表示变为00000110,十进制值为 6。bset[BITSET_CAPACITY - 1 - i]即bset[61],值为 0。value |= static_cast<uint8_t>(bset[61]);:将 0 加入到value中,此时value的二进制表示仍为00000110,十进制值为 6。
- 第四次循环(
i = 3):value <<= 1;:value左移一位,二进制表示变为00001100,十进制值为 12。bset[BITSET_CAPACITY - 1 - i]即bset[60],值为 1。value |= static_cast<uint8_t>(bset[60]);:将 1 加入到value中,此时value的二进制表示为00001101,十进制值为 13。
InsertPToBucket
定义辅助函数 InsertPToBucket,用于在对应的桶中插入值,注意,每个桶中存储的是每个元素p值的最大值,因此需要进行大小判断、线程安全以及越界判断。
AddElem
AddElem 很简单,先生成哈希值,然后将哈希值转换为二进制并求出桶索引和p值,再将p值插入到相应桶中。
ComputeCardinality
ComputeCardinality() 简单实现公式即可,不过在修改 cardinality_ 的时候要保证线程安全。
结果是小于或等于该值的最大整数,可通过 static_cast<size_t> 将小数部分截断。
Q&A
- 构造函数接收的 b 值如果小于 0,构造函数中得 return,如果是抛出异常的话 HyperLogLogTest.EdgeTest1 没办法通过。
// HyperLogLogTest.EdgeTest1 无法通过
if (n_bits < 0) {throw std::invalid_argument("n_bits must be greater than or equal to 0");
}
// 测试通过
if (n_bits < 0) {return;
}
Task#2
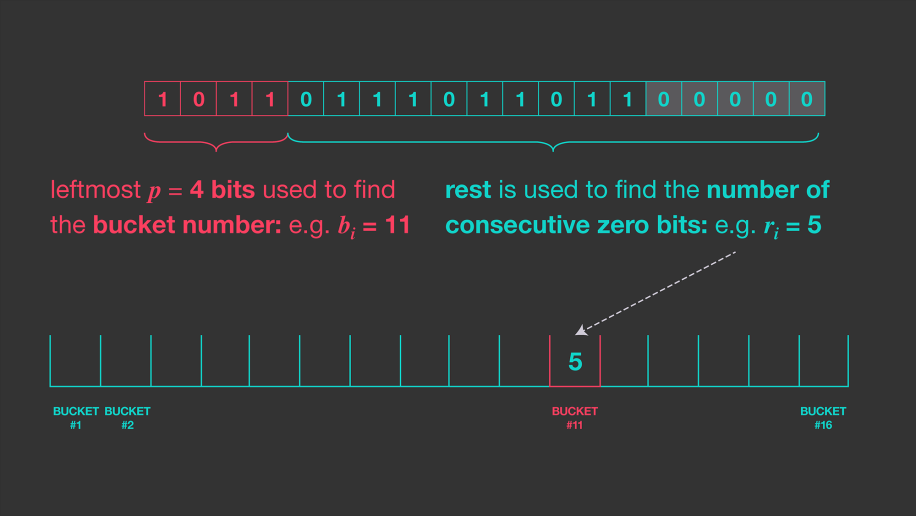
task2 主要要求我们实现HyperLogLog(HLL)算法的密集布局( Presto )。在 task1 中,我们找 p 值其实是在找最高位起始 1 的索引,但是在 task2 中,p 的值是从最低位开始的连续零的计数。如下图:
内容分析
Presto 特有的 HyperLogLog(HLL)数据结构实现有两种布局格式:稀疏布局和密集布局。初始时使用稀疏布局以节省内存,当输入数据结构超过稀疏布局的预设内存限制,Presto 自动切换为密集布局。
-
稀疏布局:存储一组相邻的 32 位条目 / 桶,按桶索引升序排列。当新数据传入时,Presto 会检查桶号是否已存在:若存在则更新其值;若不存在则分配新的 32 位内存地址以存储该值。随着更多数据流入,桶的数量可能超过预设内存限制,此时 Presto 会切换为密集布局表示。
-
密集布局:具有固定数量的桶,相关内存从初始化阶段即完成分配。桶值存储为相对于基线值的增量,基线值按
baseline = min(buckets)计算。桶值被编码为 4 位值的序列(如下图所示)。根据 HLL 算法的统计特性,4 位足以编码给定 HLL 结构中的大部分值。对于超过 2^4 的增量,余数将存储在溢出条目列表中。
举个例子,加入某个元素的二进制哈希值最右侧的连续零个数是33,33的二进制为 0100001,这种情况下,密集桶没办法存储(因为密集桶最大存储上限是 15),因此需要该二进制拆开,前 3 个最高有效位(MSB)为 010,最后 4 个最低有效位(LSB)为 0001。其中,0001 存储在密集桶中,而最高有效位 010(即溢出位)则存储在溢出桶中。计算的时候再综合二者的内容进行求解基数估计值。
完成TASK#2,需用到以下文件:
src/include/primer/hyperloglog_presto.hsrc/primer/hyperloglog_presto.cpptest/primer/hyperloglog_test.cpp
hyperloglog_presto.h
hyperloglog_presto.h 中已经帮我们提前声明了一些我们需要实现的函数,主要内容如下:
/** @brief Dense bucket size. */
#define DENSE_BUCKET_SIZE 4
/** @brief Overflow bucket size. */
#define OVERFLOW_BUCKET_SIZE 3/** @brief Total bucket size. */
#define TOTAL_BUCKET_SIZE (DENSE_BUCKET_SIZE + OVERFLOW_BUCKET_SIZE)namespace bustub {template <typename KeyType>
class HyperLogLogPresto {/*** INSTRUCTIONS: Testing framework will use the GetDenseBucket and GetOverflow function,* hence SHOULD NOT be deleted. It's essential to use the dense_bucket_* data structure.*//** @brief Constant for HLL. */static constexpr double CONSTANT = 0.79402;public:/** @brief Disabling default constructor. */HyperLogLogPresto() = delete;explicit HyperLogLogPresto(int16_t n_leading_bits);/** @brief Returns the dense_bucket_ data structure. */auto GetDenseBucket() const -> std::vector<std::bitset<DENSE_BUCKET_SIZE>> { return dense_bucket_; }/** @brief Returns overflow bucket of a specific given index. */auto GetOverflowBucketofIndex(uint16_t idx) { return overflow_bucket_[idx]; }/** @brief Retusn the cardinality of the set. */auto GetCardinality() const -> uint64_t { return cardinality_; }auto AddElem(KeyType val) -> void;auto ComputeCardinality() -> void;private:/** @brief Calculate Hash.** @param[in] val** @returns hash value*/inline auto CalculateHash(KeyType val) -> hash_t {Value val_obj;if constexpr (std::is_same<KeyType, std::string>::value) {val_obj = Value(VARCHAR, val);return bustub::HashUtil::HashValue(&val_obj);}if constexpr (std::is_same<KeyType, int64_t>::value) {return static_cast<hash_t>(val);}return 0;}/** @brief Structure holding dense buckets (or also known as registers). */std::vector<std::bitset<DENSE_BUCKET_SIZE>> dense_bucket_;/** @brief Structure holding overflow buckets. */std::unordered_map<uint16_t, std::bitset<OVERFLOW_BUCKET_SIZE>> overflow_bucket_;/** @brief Storing cardinality value */uint64_t cardinality_;// TODO(student) - can add more data structures as required
};} // namespace bustub
密集桶和溢出桶的位数是固定的,分别是4和3。
默认构造函数被delete,需要我们实现一个禁止隐式转换的构造函数 explicit HyperLogLogPresto(int16_t n_leading_bits);
此外,还需要我们实现 AddElem(KeyType val) 和 ComputeCardinality(),用于向HLL中添加元素和计算基数估计值。
密集桶和溢出桶的数据结构分别是 vector 和 无序map,且每个溢出桶对应一个索引(前b位十进制值)。密集桶中每个元素都是长度为4的位图,用于存储每个桶对应的元素的二进制哈希值最右侧连续零的计数;由于密集桶的位数上限是4,当某个桶对应的元素哈希值右侧连续零个数超过15时,溢出桶就用来存储密集桶表示范围的部分计数信息,避免信息丢失。这两个数据结构加起来和 TASK#1 的registers_相似。
不同的是,在TASK1中
registers_(桶数)的内存(2^b * 类型大小)在构造函数中就要分配好,且是固定不变的;而在 TASK2 中,密集桶的内存大小和 TASK1 一样是固定的,但桶中的元素类型是
std::bitset<4>,而registers_的元素类型是 uint8_t (因为TASK1中哈希值只转换为了64为二进制,因此 p 值最大也就是64,uint8_t 的最大上限是255);溢出桶用于处理密集桶无法容纳的计数信息,在初始状态下,不分配内存,但随着添加的元素数量不断增加,某些桶的计数可能会超出密集桶的表示范围,这时就需要使用溢出桶来存储额外的信息,内存使用会随着需要存储溢出信息的桶的数量增加而上升。
任务要求我们将哈希值转换为 64 位二进制,然后计算 LSB,因此我们还需要额外实现辅助函数帮助我们将哈希值转换为64位二进制,以及求低位开始的连续零个数。
整体思路和 TASK#1 类似,寄存器赋值同样是 max(register[index], p) 的方式,只不过多了密集桶和溢出桶两个数据结构,在添加元素时,首先根据元素的哈希值确定对应的桶索引,然后将最右侧连续零的计数信息存储在密集桶中。如果计数超过了密集桶的表示范围,则将超出部分存储在溢出桶中。在计算基数时,算法会综合考虑密集桶和溢出桶中的计数信息,利用特定的公式进行计算,从而得到更准确的基数估计结果。
hyperloglog_presto.cpp
主要实现的就只有三个函数,很简单,除此之外我们还需要添加将十进制哈希值转换为二进制、获取右连续零个数以及将桶索引对应的密集桶和溢出桶二进制位图提取出来合并成7位位图等辅助函数。
/** @brief Parameterized constructor. */
template <typename KeyType>
HyperLogLogPresto<KeyType>::HyperLogLogPresto(int16_t n_leading_bits) : cardinality_(0) {}/** @brief Element is added for HLL calculation. */
template <typename KeyType>
auto HyperLogLogPresto<KeyType>::AddElem(KeyType val) -> void {/** @TODO(student) Implement this function! */
}/** @brief Function to compute cardinality. */
template <typename T>
auto HyperLogLogPresto<T>::ComputeCardinality() -> void {/** @TODO(student) Implement this function! */
}template class HyperLogLogPresto<int64_t>;
template class HyperLogLogPresto<std::string>;
} // namespace bustub
我这里讲一下我的思路:
HyperLogLogPresto(initial_bits) 中的步骤和 TASK1 差不多,主要区别在于内存分配策略,在 TASK1 中需要为 registers_分配内存,内存大小是 2^b * 类型大小,但是在 TASK2 中 resize 的是密集桶 dense_bucket_ 的大小,每个桶为固定 4 位的bitset,而溢出桶 overflow_bucket_ 初始不分配内存。
AddElem () 的流程同样和 TASK1 差不多,只不过在求最大右连续零和插入的时候有一些区别。找最大右连续零很简单,找二进制哈希值从最低位开始的最长连续零个数作为 p 值;在元素插入操作方面,TASK1 和 TASK2 都遵循相同的核心原则,即通过比较 max(register[index], p) 来确定最终要存储在对应桶内的值,将较大的 p 值保留下来。只不过 TASK2 复杂一些,当需要将 p 值插入到指定桶时,首先要从密集桶和溢出桶中提取对应桶索引的位图数据。将密集桶中对应位置的 4 位位图与溢出桶中对应位置(若存在)的 3 位位图进行合并,得到一个 7 位大小的位图,并将其转换为十进制数值,以此作为当前桶中已存储的值。接下来,将新计算得到的 p 值与这个已存储的值进行对比。若 p 值大于桶中已存储的值,表明需要对桶内数据进行更新。此时,将 p 值转换为 7 位的位图,把该位图的低四位存储到密集桶的对应位置,高三位则存储到溢出桶的对应位置,从而完成元素的插入和桶数据的更新。
ComputeCardinality() 需要先从密集桶和溢出桶中找到给定桶索引的位图,然后转为十进制作为 R[j],剩余的流程和 TASK1 一样。
N = α m ⋅ m 2 ⋅ ( ∑ j = 0 m − 1 2 − R [ j ] ) − 1 N = \alpha_m \cdot m^2 \cdot \left(\sum_{j = 0}^{m - 1} 2^{-R[j]}\right)^{-1} N=αm⋅m2⋅(j=0∑m−12−R[j])−1
注意:调用
AddElem()和ComputeCardinality()过程中需要用互斥保护共享资源
Q&A
1.符号注意对齐,在TASK1 中,索引类型是 uint8_t,在 TASK2 中,索引类型是 uint16_t
2.无论是前导零还是尾至零,都是将 64 位二进制的前 b 位去掉开始计算的
test
先将test/primer/hyperloglog_test.cpp中的测试函数第二个形参的前缀DIABLE_去掉,cd 到build执行:
make -j$(nproc) hyperloglog_test
./test/hyperloglog_test
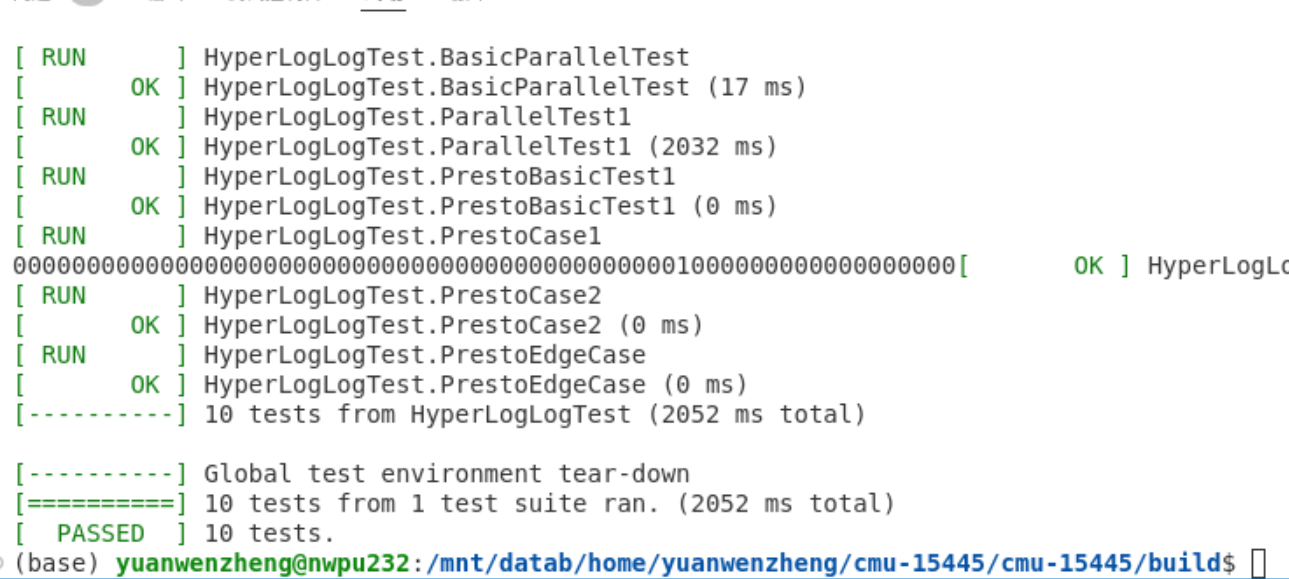
出现上图则测试成功,否则自行debug测试函数进行调试修改。
submit
首先在本地进行格式验证,先安装clang-fromat,clang-tidy
sudo apt-get install clang-format
apt-get install clang-tidy
然后在build文件夹下依次执行以下命令:
make format
make check-clang-tidy-p0
如果报错提示:
那么需要我们手动指定 clang-format 的路径,再重新进行 CMake 配置和编译:
rm -rf CMakeCache.txt CMakeFiles
cmake -DCLANG_FORMAT_BIN=$(which clang-format) ..
然后重新执行 make format
最后 cd到build下执行:
make submit-p0
然后会在根目录下创建一个名为 project0-submission.zip的存档,将它提交到 Gradescope即可。