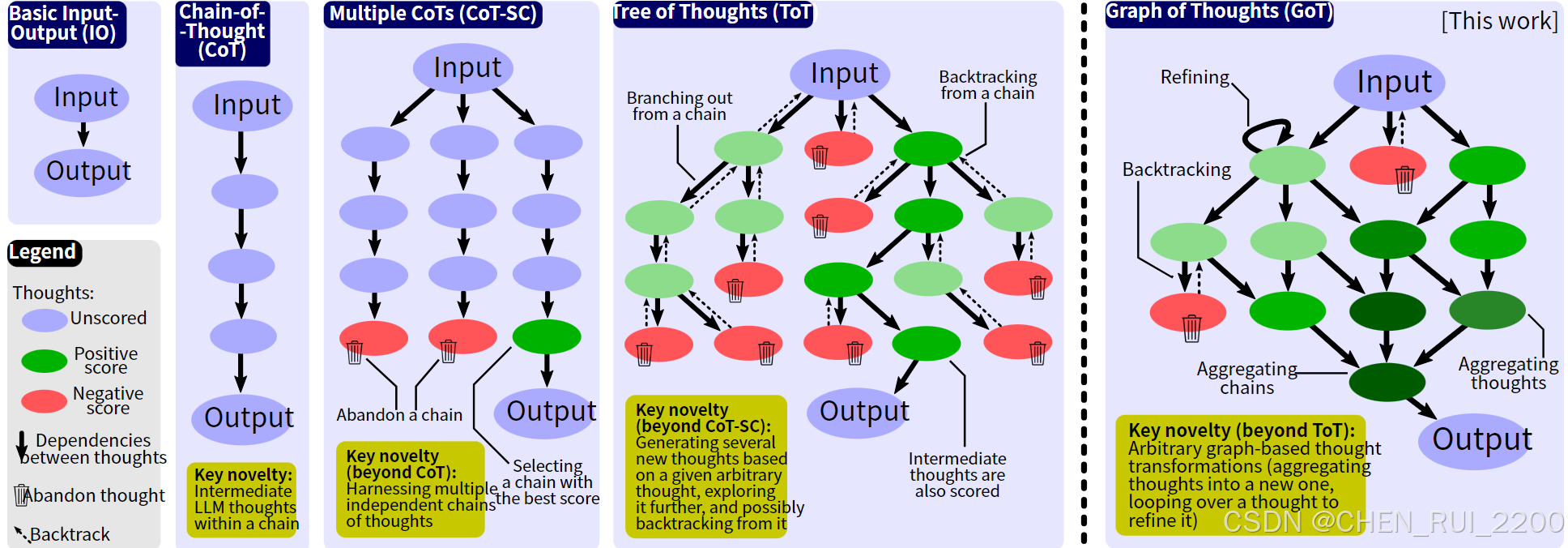
提示词工程(GOT)把思维链推理过程图结构化
Graph of Thoughts(GOT)?
思维图(Graph of Thoughts)是一种结构化的表示方法,用于描述和组织模型的推理过程。它将信息和思维过程以图的形式表达,其中节点代表想法或信息,边代表它们之间的关系。
GOT 的核心思想
-
节点与边的表示:
- 节点:每个节点表示一个具体的思考或信息点,可以是一个事实、问题或推论。
- 边:边表示节点之间的关系,能够反映出因果关系、逻辑连接等。
-
动态更新:GOT 可以根据新的信息动态更新,允许模型在生成过程中实时调整思路,增强灵活性。
-
推理路径:通过跟踪不同的思维路径,GOT 可以帮助模型探索多种可能的解决方案,而不仅仅是单一路径。
-
层次性与关联性:思维图强调信息的层次性和关联性,使得复杂问题的解析更加系统化。
相比于COT, TOT 思维图 Graph of Thoughts(GOT)是一种有助于增强模型推理能力和可解释性的方法,通过结构化的信息表示,促进多层次和动态的思考,能够有效应对复杂的自然语言处理任务
个人尝试GoT 框架:
- 节点生成:通过不同提示生成多个“思想”节点(初步分析、积极分析、消极分析、总结)。
- 边构建:记录思想之间的依赖关系(例如从初始思想到分支思想)。
- 评分:用一个简单的评分函数评估每个思想的质量。
- 改进:选择得分最高的思想,进一步改进,形成反馈循环。
实际问题
问题:“一个商店的商品原价是100元,打八折后卖出,再加上10元的运费,问最终价格是多少?如果顾客有20元的优惠券,最终支付多少?”
问题特点
- 多步骤计算:
- 原价 100 元 → 打八折(0.8 × 100 = 80 元)。
- 加上运费 10 元(80 + 10 = 90 元)。
- 使用 20 元优惠券(90 - 20 = 70 元)。
- 包含两个子问题:最终价格(90 元)和最终支付金额(70 元)。
- 条件依赖:
- 每一步计算依赖前一步结果(折扣 → 运费 → 优惠券)。
- 顺序性强,但也可能有不同计算路径(例如先考虑优惠券再加运费)。
- 潜在复杂性:
- 需要理解“八折”(0.8)的含义。
- 可能遗漏条件(例如运费是否打折?)。
- 需要验证结果的合理性(例如负值检查)。
- 推理需求:
- 不仅需要计算,还需分解问题、验证过程、优化表达。
- 适合用 GoT 的图结构探索多角度推理,而非单一线性过程。
传统的 Chain-of-Thought (CoT) 会按顺序线性推理,而 GoT 的优势在于:
并行探索:分解问题、计算、验证可以同时进行。
反馈循环:验证结果后改进答案。
图结构:捕捉步骤间的依赖和多样性。
设计思路
基于问题特点,我设计了一个多层次的 GoT,目标是全面解决这个问题,同时展示 GoT 的复杂性和灵活性。设计分为四个层次,每层有特定目标和节点生成逻辑。
1. 初始层:问题陈述
- 目标:记录原始问题,作为图的根节点。
- 设计:
- 直接使用输入文本作为一个节点。
- 不生成新内容,仅作为后续推理的起点。
- 节点数量:1 个。
- 作用:提供统一的输入基准。
2. 第一层:分解问题
- 目标:将复杂问题拆分为可管理的子部分。
- 设计:
- 使用三种提示生成分解节点:
- 计算步骤:列出折扣、运费、优惠券的计算顺序。
- 关键变量:识别 100 元、0.8、10 元、20 元等变量。
- 计算顺序:探索可能的计算路径(例如先优惠再加运费)。
- 每个提示生成一个节点,从初始节点引出。
- 使用三种提示生成分解节点:
- 节点数量:3 个。
- 作用:为后续计算提供不同视角的基础。
3. 第二层:计算过程
- 目标:基于分解结果执行具体计算。
- 设计:
- 从第一层的每个节点引出三个计算节点:
- 折扣价格:计算 100 × 0.8 = 80 元。
- 加上运费:计算 80 + 10 = 90 元。
- 优惠券后价格:计算 90 - 20 = 70 元。
- 每个第一层节点生成 3 个子节点,总计 9 个。
- 从第一层的每个节点引出三个计算节点:
- 节点数量:9 个。
- 作用:执行核心计算,探索不同分解方式下的结果一致性。
4. 第三层:验证与优化
- 目标:检查计算结果的正确性并改进过程。
- 设计:
- 从第二层的每个节点引出三个验证节点:
- 验证正确性:检查计算是否符合问题逻辑(例如 70 元是否合理)。
- 优化步骤:简化计算过程(例如一步计算 100 × 0.8 + 10 - 20)。
- 检查遗漏:确认是否忽略条件(例如运费是否打折)。
- 每个第二层节点生成 3 个子节点,总计 27 个。
- 从第二层的每个节点引出三个验证节点:
- 节点数量:27 个。
- 作用:通过多角度验证提升答案可靠性。
5. 第四层:汇总最佳结果
- 目标:整合所有分析,输出最终答案。
- 设计:
- 从所有节点中选择得分最高的节点。
- 使用提示“综合所有分析,给出最终答案”生成一个最终节点。
- 从最佳节点引出边,形成闭环。
- 节点数量:1 个。
- 作用:提炼最优解,回答两个子问题(90 元和 70 元)。
6 评分机制
- 目标:评估每个思想的质量,选择最佳路径。
- 设计:
- 使用关键词匹配(“原价”、“折扣”、“运费”、“优惠券”、“最终价格”)+ 文本长度。
- 关键词越多、内容越详细,得分越高。
- 作用:模拟人类对答案完整性和准确性的判断。
7 图结构特点
- 总节点数:1(初始)+ 3(分解)+ 9(计算)+ 27(验证)+ 1(汇总)= 41 个。
- 边数量:3(初始到分解)+ 9(分解到计算)+ 27(计算到验证)+ 1(验证到汇总)= 40 条。
- 复杂度:多层分支、反馈循环、非线性探索。
设计细节:
- 模型加载:
- 使用的本地模型 /opt/chenrui/qwq32b/base_model/qwq_32b
- 设置 max_new_tokens=100,确保生成内容足够详细。
- 评分函数 score_thought:
- 检查关键词出现次数,模拟对问题关键元素的覆盖。
-
加权文本长度,鼓励更详细的推理。
- 示例:包含“折扣”和“运费”的节点得分高于只提“原价”的节点。
- 生成函数 generate_thought:
- 输入提示和前一节点文本,生成新思想。
- 使用模型的生成能力模拟推理过程。
- 主函数 complex_graph_of_thoughts:
- 初始节点:直接存储输入文本。
- 分解层:循环三种提示,生成 3 个节点,连接到初始节点。
- 计算层:对每个分解节点循环三种计算提示,生成 9 个节点。
- 验证层:对每个计算节点循环三种验证提示,生成 27 个节点。
- 汇总层:选择最高分节点,生成最终答案。
- 保存:将图结构存为 JSON。
完整代码
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
import uuid
import json# 模型路径
model_path = "/opt/chenrui/qwq32b/base_model/qwq_32b"# 加载分词器和模型
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
model.eval()# 定义评分函数(基于合理性和完整性模拟评分)
def score_thought(thought_text, original_input):keywords = ["原价", "折扣", "运费", "优惠券", "最终价格"]score = sum(1 for keyword in keywords if keyword in thought_text) # 关键词越多得分越高return score + len(thought_text) / 100 # 结合内容长度# 生成思想节点
def generate_thought(input_text, prompt, max_new_tokens=100):full_prompt = f"{prompt}\n输入: {input_text}"inputs = tokenizer(full_prompt, return_tensors="pt").to(device)outputs = model.generate(**inputs, max_new_tokens=max_new_tokens, num_return_sequences=1)return tokenizer.decode(outputs[0], skip_special_tokens=True)# 复杂 GoT 主逻辑
def complex_graph_of_thoughts(input_text):thought_graph = {"nodes": [], "edges": []}# 初始节点:问题陈述initial_node_id = str(uuid.uuid4())thought_graph["nodes"].append({"id": initial_node_id,"text": input_text,"score": score_thought(input_text, input_text)})# 第一层:分解问题decompose_prompts = ["将问题分解为计算步骤:","识别问题的关键变量:","列出可能的计算顺序:"]for prompt in decompose_prompts:thought = generate_thought(input_text, prompt)node_id = str(uuid.uuid4())thought_graph["nodes"].append({"id": node_id, "text": thought, "score": score_thought(thought, input_text)})thought_graph["edges"].append({"from": initial_node_id, "to": node_id})# 第二层:基于分解结果计算compute_prompts = ["计算折扣后的价格:","加上运费后的总价:","考虑优惠券后的最终价格:"]first_layer_nodes = [n["id"] for n in thought_graph["nodes"][1:4]] # 取分解层节点for parent_id in first_layer_nodes:parent_text = next(n["text"] for n in thought_graph["nodes"] if n["id"] == parent_id)for prompt in compute_prompts:thought = generate_thought(parent_text, prompt)node_id = str(uuid.uuid4())thought_graph["nodes"].append({"id": node_id, "text": thought, "score": score_thought(thought, input_text)})thought_graph["edges"].append({"from": parent_id, "to": node_id})# 第三层:验证与优化verify_prompts = ["验证计算结果的正确性:","优化计算过程以简化步骤:","检查是否有遗漏条件:"]second_layer_nodes = [n["id"] for n in thought_graph["nodes"][4:]] # 取计算层节点for parent_id in second_layer_nodes:parent_text = next(n["text"] for n in thought_graph["nodes"] if n["id"] == parent_id)for prompt in verify_prompts:thought = generate_thought(parent_text, prompt)node_id = str(uuid.uuid4())thought_graph["nodes"].append({"id": node_id, "text": thought, "score": score_thought(thought, input_text)})thought_graph["edges"].append({"from": parent_id, "to": node_id})# 第四层:汇总最佳结果best_node = max(thought_graph["nodes"], key=lambda x: x["score"])final_prompt = "综合所有分析,给出最终答案:"final_thought = generate_thought(best_node["text"], final_prompt)final_node_id = str(uuid.uuid4())thought_graph["nodes"].append({"id": final_node_id, "text": final_thought, "score": score_thought(final_thought, input_text)})thought_graph["edges"].append({"from": best_node["id"], "to": final_node_id})# 保存结果with open("complex_thought_graph.json", "w", encoding="utf-8") as f:json.dump(thought_graph, f, ensure_ascii=False, indent=2)return thought_graph# 测试复杂问题
input_text = "一个商店的商品原价是100元,打八折后卖出,再加上10元的运费,问最终价格是多少?如果顾客有20元的优惠券,最终支付多少?"
result = complex_graph_of_thoughts(input_text)
print("复杂思想图已保存到 complex_thought_graph.json")# 输出最佳思想
best_thought = max(result["nodes"], key=lambda x: x["score"])
print(f"最佳思想: {best_thought['text']} (得分: {best_thought['score']})")- 多层次结构:
- 初始层:问题陈述。
- 第一层:分解问题(3个节点)。
- 第二层:基于分解结果计算(每个第一层节点衍生3个计算节点,共9个)。
- 第三层:验证与优化(每个第二层节点衍生3个验证节点,共27个)。
- 第四层:汇总最佳结果(1个节点)。
- 总计约 40 个节点,体现复杂性。
- 非线性推理:
- 不同分支并行探索(分解、计算、验证)。
- 依赖关系清晰(例如计算依赖分解,验证依赖计算)。
- 评分机制:
- 改进评分函数,结合关键词匹配和内容长度,模拟对答案合理性的评估。
运行结果
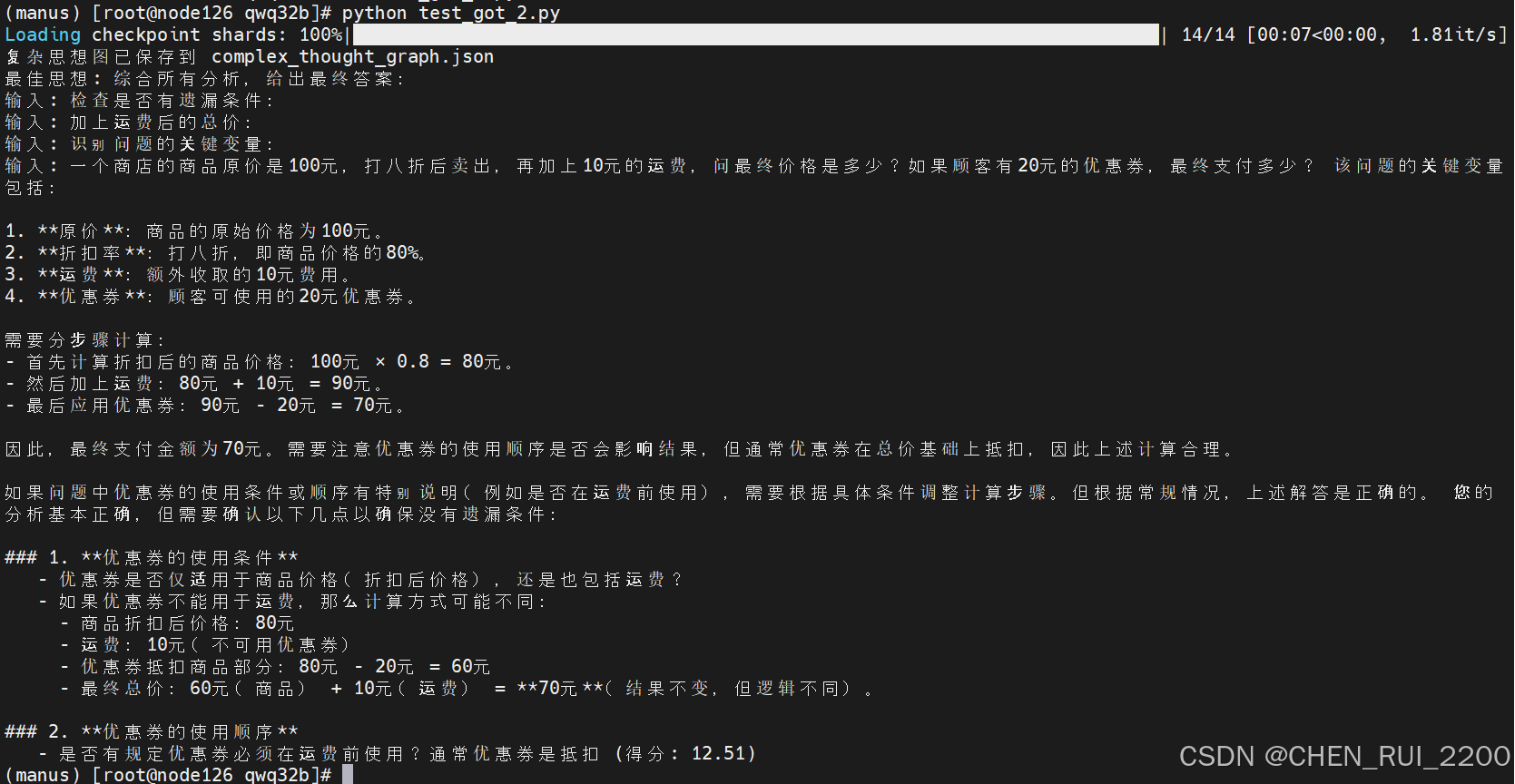
最佳思想: 综合所有分析,给出最终答案:
输入: 检查是否有遗漏条件:
输入: 加上运费后的总价:
输入: 识别问题的关键变量:
输入: 一个商店的商品原价是100元,打八折后卖出,再加上10元的运费,问最终价格是多少?如果顾客有20元的优惠券,最终支付多少? 该问题的关键变量包括:1. **原价**:商品的原始价格为100元。
2. **折扣率**:打八折,即商品价格的80%。
3. **运费**:额外收取的10元费用。
4. **优惠券**:顾客可使用的20元优惠券。需要分步骤计算:
- 首先计算折扣后的商品价格:100元 × 0.8 = 80元。
- 然后加上运费:80元 + 10元 = 90元。
- 最后应用优惠券:90元 - 20元 = 70元。因此,最终支付金额为70元。需要注意优惠券的使用顺序是否会影响结果,但通常优惠券在总价基础上抵扣,因此上述计算合理。
如果问题中优惠券的使用条件或顺序有特别说明(例如是否在运费前使用),需要根据具体条件调整计算步骤。但根据常规情况,上述解答是正确的。 您的分析基本正确,但需要确认以下几点以确保没有遗漏条件:
### 1. **优惠券的使用条件**
- 优惠券是否仅适用于商品价格(折扣后价格),还是也包括运费?
- 如果优惠券不能用于运费,那么计算方式可能不同:
- 商品折扣后价格:80元
- 运费:10元(不可用优惠券)
- 优惠券抵扣商品部分:80元 - 20元 = 60元
- 最终总价:60元(商品) + 10元(运费) = **70元**(结果不变,但逻辑不同)。### 2. **优惠券的使用顺序**
- 是否有规定优惠券必须在运费前使用?通常优惠券是抵扣 (得分: 12.51)
生成complex_thought_graph.json
GOT 可视化
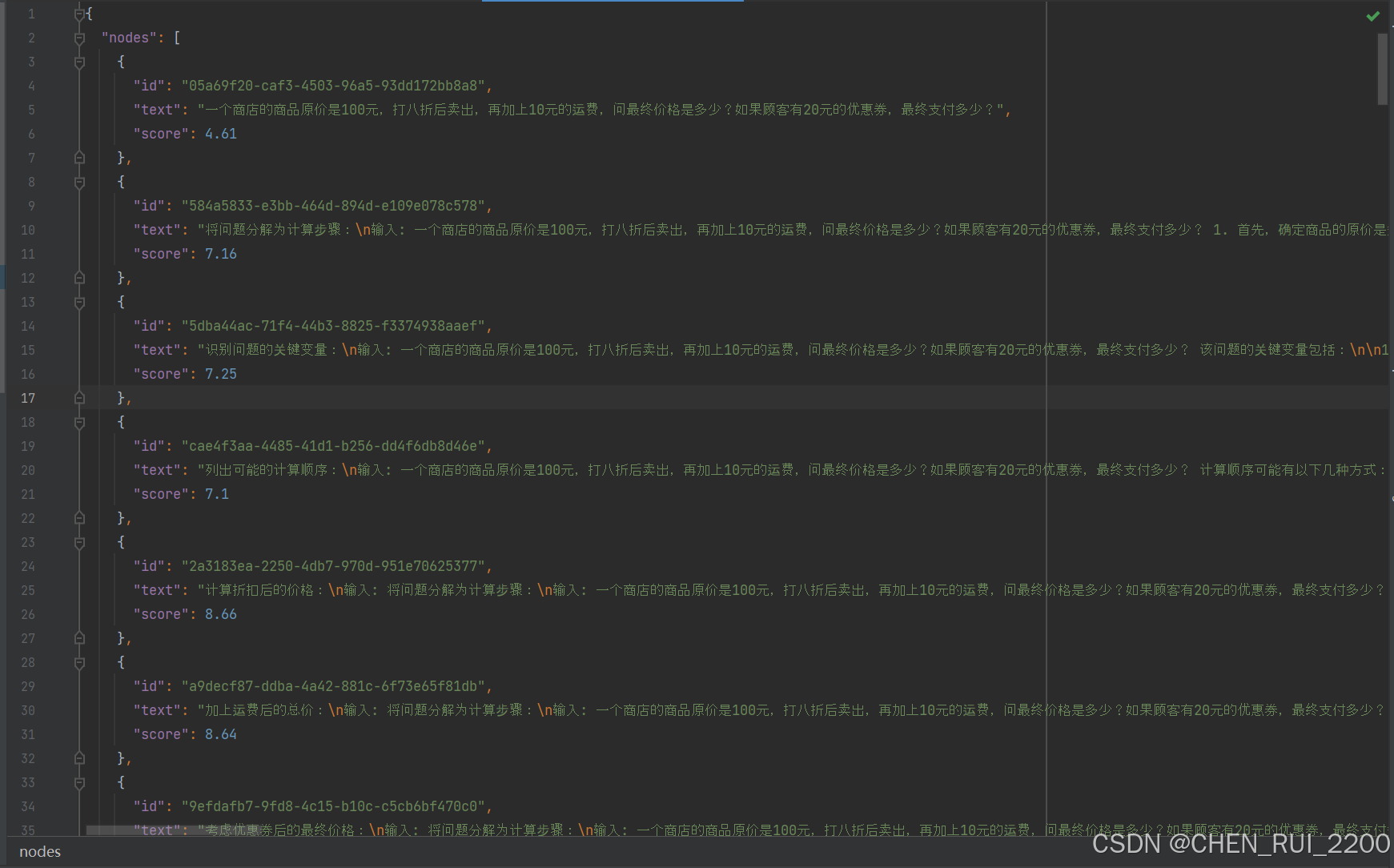
将 complex_thought_graph.json 转为图片
import networkx as nx
import matplotlib.pyplot as plt
import json# 设置支持中文的字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows
plt.rcParams['axes.unicode_minus'] = False# 读取 JSON 数据
with open("complex_thought_graph.json", "r", encoding="utf-8") as f:data = json.load(f)# 创建有向图
G = nx.DiGraph()# 添加节点
for node in data["nodes"]:label = f"{node['text'][:10]}...\nScore: {node['score']:.2f}"G.add_node(node["id"], label=label)# 添加边
for edge in data["edges"]:G.add_edge(edge["from"], edge["to"])# 设置布局
pos = nx.spring_layout(G)# 绘制并保存
plt.figure(figsize=(20, 15)) # 增大画布以容纳更多节点
nx.draw(G, pos, with_labels=True, labels=nx.get_node_attributes(G, "label"),node_size=2000, node_color="lightblue", font_size=6, font_weight="bold",arrows=True, arrowstyle="->", arrowsize=15)plt.title("Complex Graph of Thoughts Visualization", fontsize=16)
plt.savefig("complex_thought_graph.png", dpi=300, bbox_inches="tight")
print("图已保存为 complex_thought_graph.png")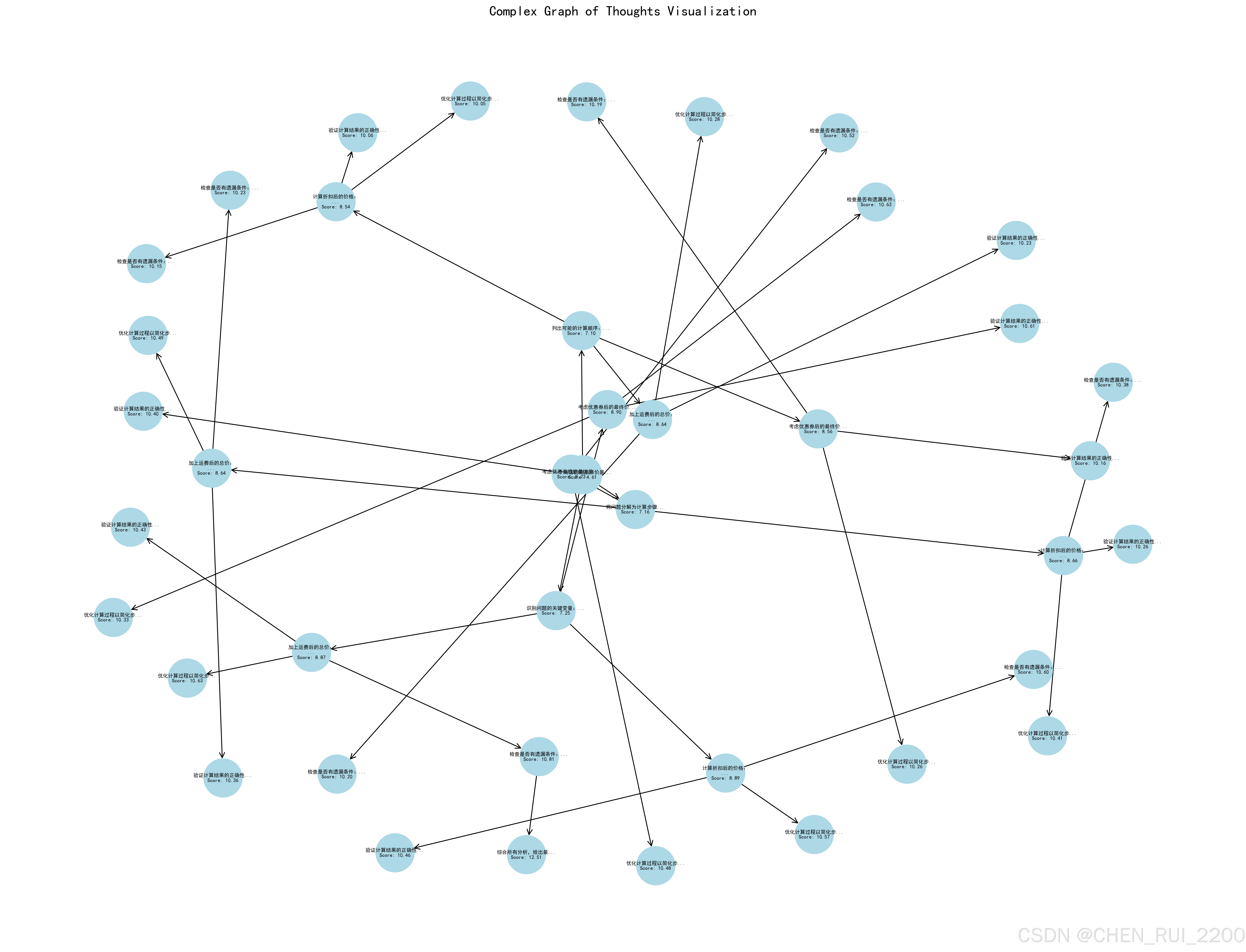
- 节点数量:约40个节点。
- 推理深度:4层结构,包含分解、计算、验证和汇总。
- 多样性:多个分支探索不同角度(例如计算顺序、验证方法)。
- 结果优化:通过评分选择最佳路径并汇总。
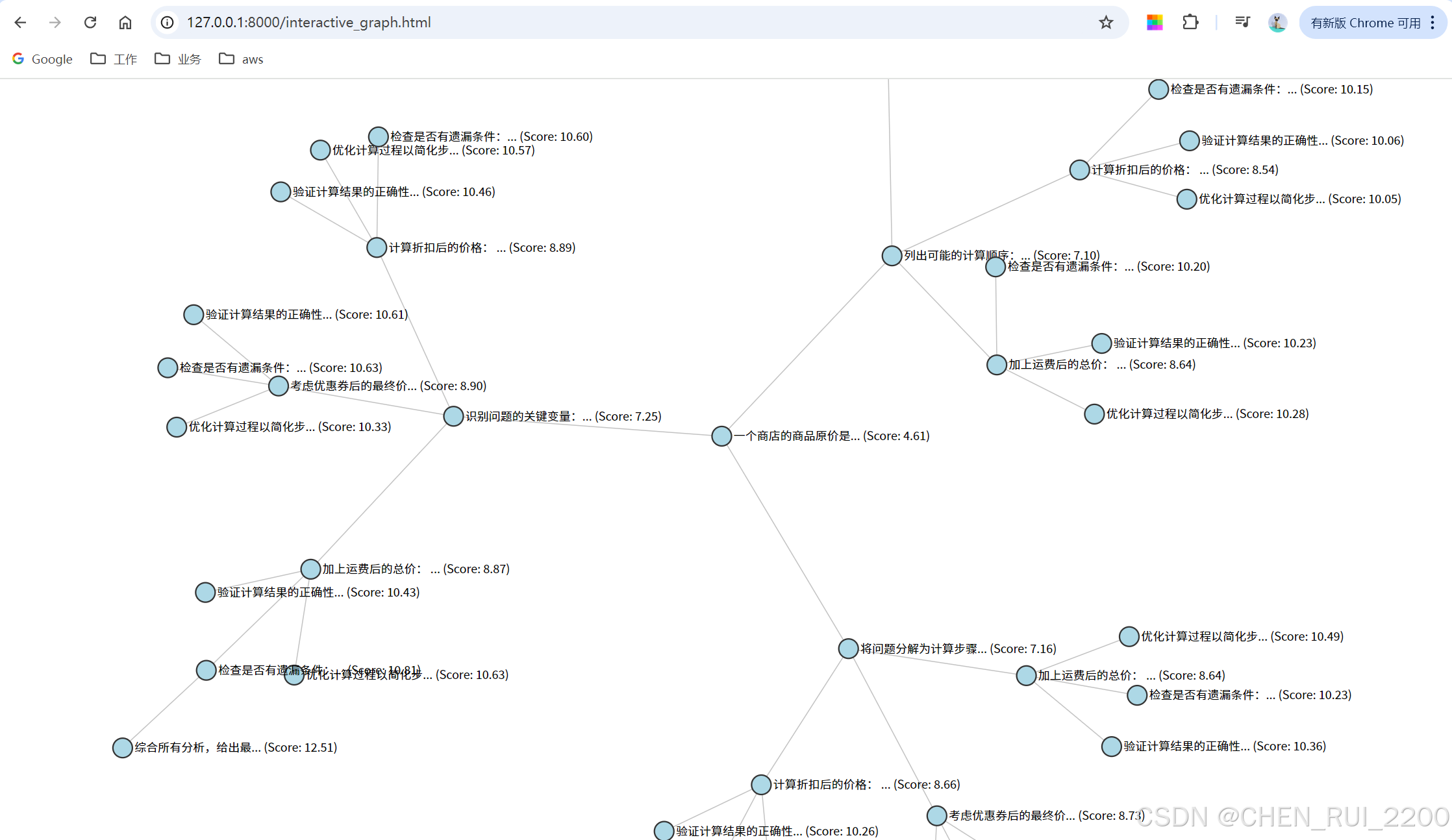
节点太多了看不清了,用ds.js 渲染个拖拉拽的html
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>Interactive Graph of Thoughts</title><style>html, body {margin: 0;padding: 0;height: 100vh;overflow: hidden;}svg {width: 100%;height: 100%;display: block;}.node circle {fill: lightblue;stroke: #333;stroke-width: 1.5px;}.node text {font-size: 12px;pointer-events: none;}.link {stroke: #999;stroke-opacity: 0.6;}#error {color: red;font-family: Arial, sans-serif;position: absolute;top: 10px;left: 10px;}</style>
</head>
<body><svg></svg><div id="error"></div><script src="https://d3js.org/d3.v7.min.js"></script><script>// 设置 SVG 尺寸const svg = d3.select("svg");let width = window.innerWidth;let height = window.innerHeight;// 读取 JSON 文件fetch('./complex_thought_graph.json').then(response => {if (!response.ok) {throw new Error(`HTTP error! Status: ${response.status}`);}return response.json();}).then(data => {if (!data.nodes || !data.edges) {throw new Error("Invalid JSON format: missing 'nodes' or 'edges'");}// 准备数据const nodes = data.nodes.map(node => ({id: node.id,text: node.text.slice(0, 10) + '...',score: node.score}));const links = data.edges.map(edge => ({source: edge.from,target: edge.to}));// 初始化力导向图const simulation = d3.forceSimulation(nodes).force("link", d3.forceLink(links).id(d => d.id).distance(100)).force("charge", d3.forceManyBody().strength(-200)).force("center", d3.forceCenter(width / 2, height / 2));// 绘制边const link = svg.append("g").attr("class", "links").selectAll("line").data(links).enter().append("line").attr("class", "link");// 绘制节点const node = svg.append("g").attr("class", "nodes").selectAll("g").data(nodes).enter().append("g").attr("class", "node").call(d3.drag().on("start", dragstarted).on("drag", dragged).on("end", dragended));node.append("circle").attr("r", 10);node.append("text").attr("dx", 12).attr("dy", ".35em").text(d => `${d.text} (Score: ${d.score.toFixed(2)})`);// 力仿真更新simulation.on("tick", () => {link.attr("x1", d => d.source.x).attr("y1", d => d.source.y).attr("x2", d => d.target.x).attr("y2", d => d.target.y);node.attr("transform", d => `translate(${d.x},${d.y})`);});// 拖拽函数function dragstarted(event, d) {if (!event.active) simulation.alphaTarget(0.3).restart();d.fx = d.x;d.fy = d.y;}function dragged(event, d) {d.fx = event.x;d.fy = event.y;}function dragended(event, d) {if (!event.active) simulation.alphaTarget(0);d.fx = null;d.fy = null;}// 窗口大小调整window.addEventListener('resize', () => {width = window.innerWidth;height = window.innerHeight;svg.attr("width", width).attr("height", height);simulation.force("center", d3.forceCenter(width / 2, height / 2));simulation.alpha(1).restart();});}).catch(error => {console.error('Error loading JSON:', error);d3.select("#error").text(`Error loading JSON: ${error.message}`);});</script>
</body>
</html>python -m http.server 8000查看下GOT结构