Kubernetes一EFK日志架构
前言:
在云原生时代,Kubernetes已成为容器编排的事实标准,它赋予了应用极高的弹性、可移植性和密度。然而,这种动态、瞬时的特性也带来了可观测性的新难题:当数以百计的Pod在节点间频繁创建和销毁时,传统的基于文件的日志管理方式变得难以为继。开发者和运维人员无法再登录到特定的服务器去查看日志,故障排查与应用监控犹如大海捞针。
因此,一个能够自动采集、集中存储、并提供强大搜索与分析能力的日志系统不再是可选项,而是运维Kubernetes集群的关键基础设施。EFK栈(Elasticsearch, Fluentd, Fluent Bit)作为CNCF生态内广受认可的标准方案,完美地响应了这一需求。它提供了一套完整、高效且可扩展的框架,将分散在各处的容器日志转化为宝贵的运维洞察,是实现高效运维、保障业务稳定性的基石。本文将引导您深入了解EFK在Kubernetes中的架构与实践。
目录
一、Kubernetes日志系统部署
1.1 EFK组件镜像准备
1.2 存储卷配置
1.2.1 存储路径设置
1.2.2 状态服务配置
1.3 网络访问配置
1.3.1 服务暴露
1.3.2 防火墙规则
1.4 汉化配置
二、Fluentd日志收集配置
2.1 核心架构
2.2 配置文件解析
2.2.1 输入源配置
2.2.2 过滤规则
2.2.3 输出配置
2.3 污点容忍配置
三、Elasticsearch数据验证
3.1 集群状态检查
3.2 日志索引分析
3.2.1 日志字段映射
3.2.2 常见问题排查
四、图形化管理工具集成
4.1 工具部署流程
4.2 功能验证
五、配置文件深度解析
5.1 环境变量注入
5.2 插件加载机制
5.3 配置热加载
总结
一、Kubernetes日志系统部署
1.1 EFK组件镜像准备
-
镜像文件需从GitHub获取,访问方式决定配置文件调整方向
-
需根据实际需求修改service类型,如需外部访问需添加Ingress配置
-
官方镜像仓库地址:
github点com/kubernetes,包含已验证的部署方案
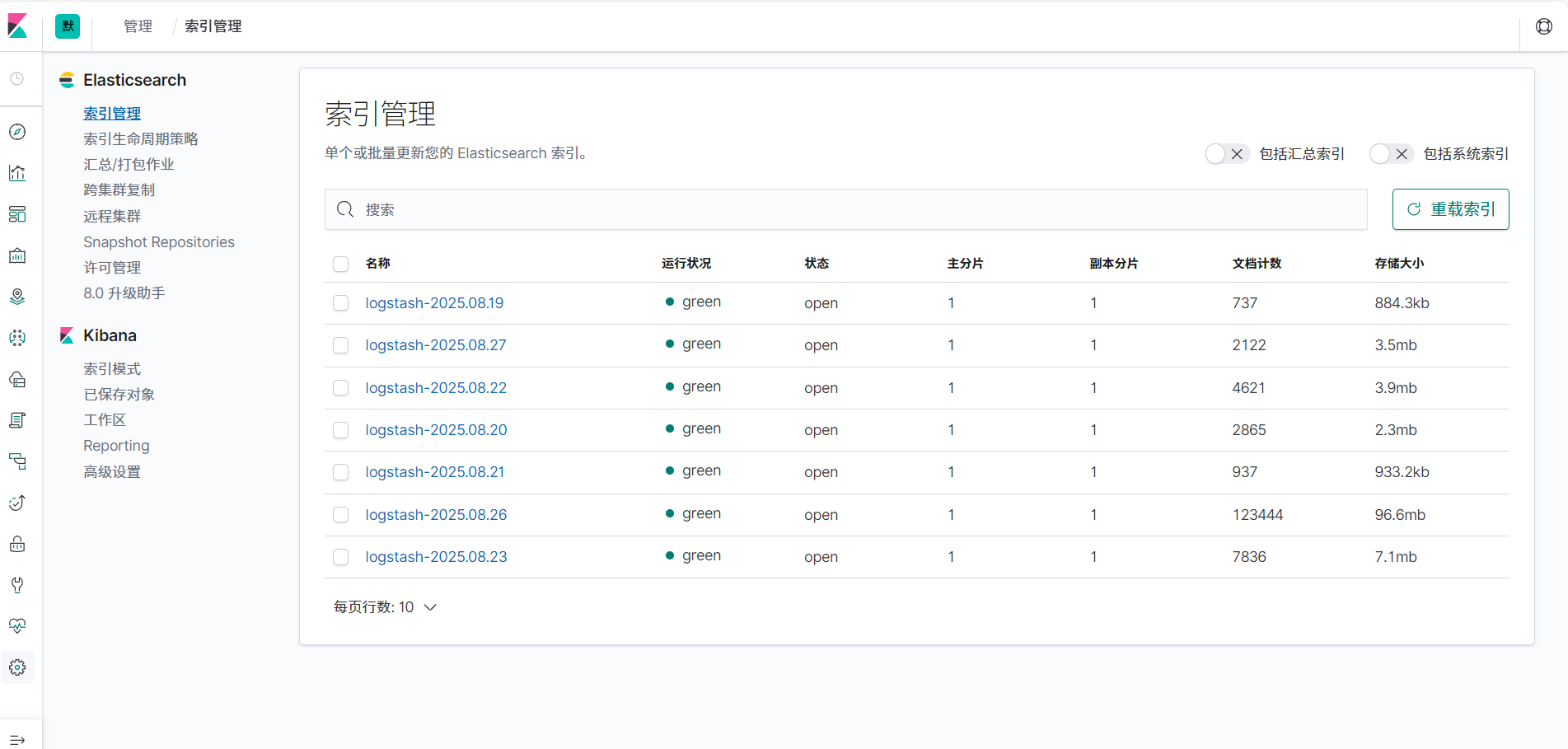
1.2 存储卷配置
1.2.1 存储路径设置
-
Elasticsearch数据目录默认为
/data/v1,可按需修改挂载路径 -
使用NFS存储时需在所有节点安装nfs组件,master节点可模拟NFS服务
-
关键配置参数对照表:
| 参数 | 默认值 | 作用 | 行号 |
|---|---|---|---|
| prevention name | elastic | 集群标识符 | 74 |
| service port | 5601 | Kibana访问端口 | 76 |
| transport端口 | 9300 | 集群内部通信端口 | 96 |
| http端口 | 9200 | REST API访问端口 | 96 |
1.2.2 状态服务配置
-
Elasticsearch需部署为StatefulSet,配置三个节点组成集群
-
节点启动参数通过环境变量传递:
es-class-0,es-class-1,es-class-2 -
集群内部通信使用9300端口,外部访问使用9200端口
1.3 网络访问配置
1.3.1 服务暴露
-
Kibana服务需修改Service类型为NodePort或LoadBalancer
-
端口映射关系:
-
5601: Kibana Web界面
-
9200: Elasticsearch API
-
9300: 集群节点通信
-
-
外部访问需绑定监听地址:
--network.host=0.0.0.0
1.3.2 防火墙规则

1.4 汉化配置
-
创建ConfigMap注入汉化文件
-
挂载路径:
/usr/share/kibana/config/kibana.yml -
配置文件核心内容:
i18n.locale: "zh-CN"server.host: "0.0.0.0"elasticsearch.hosts: ["http://elasticsearch:9200"]
二、Fluentd日志收集配置
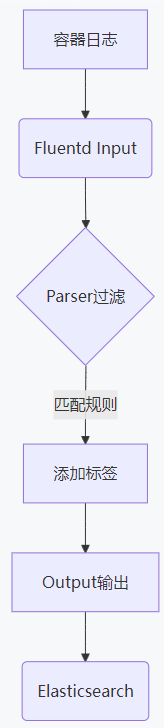
2.1 核心架构
2.2 配置文件解析
2.2.1 输入源配置
-
监听系统日志文件:
<source>@type tailpath /var/log/containers/*.logpos_file /var/log/fluentd-containers.log.postag kubernetes.*read_from_head true</source> -
接收TCP日志输入(兼容Filebeat):
<source>@type tcpport 5170bind 0.0.0.0</source>
2.2.2 过滤规则
-
使用grok解析Nginx日志:
<filter kubernetes.var.log.containers.nginx**>@type parserkey_name logreserve_data true<parse>@type grokpattern %{NGINXACCESS}</parse></filter> -
添加主机名标签:
<filter **>@type record_transformer<record>hostname "#{Socket.gethostname}"</record></filter>
2.2.3 输出配置
-
多索引路由输出:
<match kubernetes.var.log.containers.**>@type elasticsearchindex_name logstash-${record['tag']}</match> -
缓冲机制配置:
<buffer>@type filepath /var/log/fluentd-buffersflush_mode intervalflush_interval 5s</buffer>
2.3 污点容忍配置
确保DaemonSet可调度到master节点:
tolerations:- key: "node-role.kubernetes.io/master"operator: "Exists"effect: "NoSchedule" 三、Elasticsearch数据验证
3.1 集群状态检查
-
端口转发验证服务状态:
kubectl port-forward svc/elasticsearch 9200:9200curl localhost:9200/_cluster/health -
健康状态指标说明:
-
green:所有分片正常分配
-
yellow:主分片正常,副本未分配
-
red:主分片未能分配
-
3.2 日志索引分析
3.2.1 日志字段映射
| 字段名 | 来源 | 数据类型 | 说明 |
|---|---|---|---|
| @timestamp | 系统生成 | date | 日志产生时间 |
| log | 原始日志 | text | 完整日志内容 |
| stream | Docker驱动 | keyword | stdout/stderr |
| kubernetes.pod.name | K8s元数据 | keyword | Pod名称 |
3.2.2 常见问题排查
-
缺失审计日志:需单独收集
/var/log/messages -
字段解析失败:检查grok模式匹配正则
-
索引未创建:确认Fluentd输出标签匹配规则
四、图形化管理工具集成
4.1 工具部署流程
-
添加软件仓库源:
curl -sS https://downloads.lens.cloud/repo/rpm/lens.repo | sudo tee /etc/yum.repos.d/lens.repo -
安装Lens桌面客户端:
sudo dnf install lens-desktop -
导入kubeconfig文件:
-
路径:
~/.kube/config -
通过GUI界面加载集群配置
-
4.2 功能验证
-
集群资源监控看板:
-
Pod管理操作支持:
-
实时日志查看
-
终端接入
-
YAML编辑
-
五、配置文件深度解析
5.1 环境变量注入
-
Fluentd连接ES的配置逻辑:
hosts "#{ENV['FLUENT_ELASTICSEARCH_HOST'] || 'elasticsearch'}:#{ENV['FLUENT_ELASTICSEARCH_PORT'] || 9200}" -
默认值机制:双竖线
||实现短路或
5.2 插件加载机制
-
动态加载Ruby插件:
<system>rpc_endpoint 0.0.0.0:24444plugins_path /fluentd/plugins</system> -
插件类型清单:
-
输入插件(Input)
-
解析插件(Parser)
-
过滤插件(Filter)
-
输出插件(Output)
-
5.3 配置热加载
-
文件变更监听配置:
<source>@type httpport 8888bind 0.0.0.0<parse>@type json</parse></source>
总结:
构建Kubernetes环境的集中式日志系统是解锁容器化应用全栈可观测性的关键一步。通过部署和实施EFK日志架构,我们成功地将分散且易失的容器日志转化为稳定、可搜索且极具价值的数据资产。
该架构的优势集中体现在:
1.高效性与低损耗:采用Fluent Bit作为DaemonSet代理,以其卓越的性能和低资源开销,实现了从节点层面无侵入式的日志采集。
2.强大的检索与分析能力:Elasticsearch提供了近乎实时的日志索引和复杂的全文搜索能力,使得快速定位问题成为可能。
3.卓越的可视化:Kibana丰富的仪表盘和查询界面为运维和开发团队提供了统一的日志查看平台,极大地提升了协作效率和故障排查速度。
4.高可扩展性与可靠性:每个组件都可以进行水平扩展(如Elasticsearch集群、Fluentd聚合层),并通过持久化机制确保数据在组件故障时不会丢失。
总而言之,Kubernetes EFK日志方案不仅解决了容器日志管理的核心痛点,更通过将日志数据平台化,为性能监控、安全审计、业务分析等高级应用奠定了坚实的数据基础,是任何生产级Kubernetes集群不可或缺的核心组成部分。