【图像算法 - 24】基于深度学习与 OpenCV 实现人员跌倒识别系统(目标检测方案 - 跌倒即目标)
摘要: 本文将详细介绍一种创新的人员跌倒识别方法:将“跌倒的人”本身作为一个独立的目标类别进行训练和检测。我们利用深度学习目标检测模型和 OpenCV 计算机视觉库,直接训练一个模型来识别“站立的人”和“跌倒的人”两种状态。这种方法避免了基于规则(如宽高比)判断的复杂性和误报问题,将跌倒识别简化为一个标准的多类别目标检测任务。文章将完整呈现从数据准备、模型训练到最终识别应用的全过程。
关键词: YOLO12, OpenCV, 人员跌倒识别, 目标检测, 深度学习, 多类别检测, Python, 智能监控, 计算机视觉
1. 引言
人员跌倒检测是智慧养老、安防监控等领域的重要应用。传统的跌倒识别方法常依赖于姿态估计或基于目标检测框的几何特征(如宽高比)进行规则判断,这些方法虽然有效,但存在误报率高(如弯腰、下蹲被误判)、鲁棒性差(受摄像头角度影响大)、逻辑复杂等问题。
本文提出并实现一种更直接、更鲁棒的方案:将“跌倒”视为一个需要检测的独立目标类别。我们不再先检测“人”,再判断其状态,而是训练一个 YOLO12 模型,使其能够直接输出“person-falling”检测结果。这种方法将复杂的“行为分析”问题,转化为标准的“多类别目标检测”问题,大大简化了后处理逻辑,提升了系统的准确性和泛化能力。
【图像算法 - 24】基于深度学习与 OpenCV 实现人员跌倒识别系统(目标检测方案 - 跌倒即目标)
2. 技术方案:跌倒即目标
2.1 核心思想
-
数据标注:
在数据集中,明确标注一种类别:
person-falling: 已经跌倒或正在跌倒过程中的人。
-
模型训练: 使用标注好的数据集训练 YOLO12 模型,使其学习区分这两种视觉模式。
-
推理识别: 在实际应用中,模型直接输出检测框及其对应的类别(
person-falling),无需任何额外的判断逻辑。

2.2 优势
- 简化逻辑: 推理过程就是标准的检测流程,后处理代码极简。
- 提高准确性: 模型直接从大量标注数据中学习“跌倒”的复杂视觉特征(不仅仅是宽高比),能更好地区分跌倒与下蹲、弯腰等相似动作。
- 增强鲁棒性: 对摄像头角度、距离的依赖性降低,因为模型学习的是更本质的视觉模式。
- 易于扩展: 可以轻松扩展更多类别,如
person-sitting,person-lying等。
3. 环境准备
3.1 软件依赖
【图像算法 - 01】保姆级深度学习环境搭建入门指南:硬件选型 + CUDA/cuDNN/Miniconda/PyTorch/Pycharm 安装全流程(附版本匹配秘籍+文末有视频讲解)
# 安装 PyTorch (根据你的CUDA版本选择)
pip install torch torchvision torchaudio# 安装 YOLOv8
pip install ultralytics# 安装 OpenCV
pip install opencv-python# 其他
pip install numpy
pip install PyQt5
4. 数据集准备与标注
这是本方案成功的关键。
4.1 数据收集
- 收集包含“跌倒的人”的图像或视频帧。
- 来源:
- 公开数据集(如跌倒检测专用数据集)。
- 网络图片(注意版权和隐私)。
- 最佳选择: 在目标应用场景下(如养老院房间、走廊)进行模拟拍摄(需确保安全并获得许可)。
- 确保数据多样性:不同光照、角度、服装、背景、跌倒姿势(向前、向后、向侧)。
4.2 数据标注
labelme数据标注保姆级教程:从安装到格式转换全流程,附常见问题避坑指南(含视频讲解)
- 使用标注工具(Labelme, CVAT, Roboflow 等)。
- 为每张图像中的每个人标注边界框,并选择正确的类别:
person-falling
- 标注质量: 框要紧密贴合人体,类别标签准确无误。
4.3 数据集配置文件
创建 fall_detection.yaml 文件:
# 数据集路径
train: /path/to/your/dataset/images/train
val: /path/to/your/dataset/images/val
# test: /path/to/your/dataset/images/test (可选)# 类别数量
nc: 1# 类别名称
names: ['person-falling']
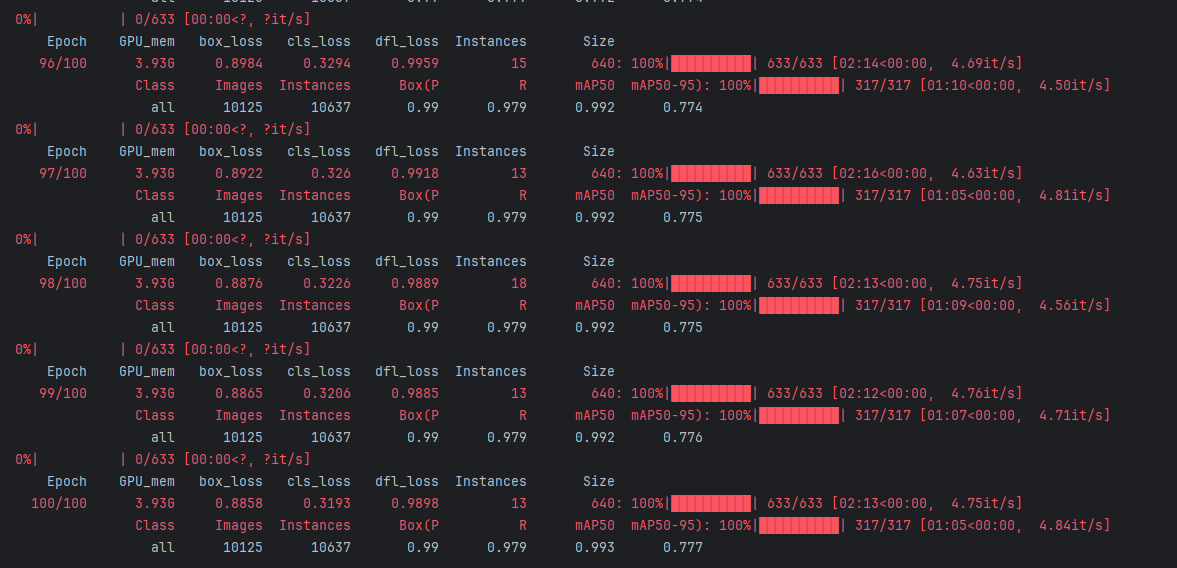
5. 模型训练
5.1 开始训练
使用 ultralytics 命令行或 Python API。
命令行方式:
yolo train data=fall_detection.yaml model=yolo12n.pt epochs=100 imgsz=640
Python API 方式:
from ultralytics import YOLO# 加载预训练模型 (可选,也可从头训练)
model = YOLO('yolov8s.pt') # 或 'yolov8n.pt' for smaller/faster# 训练模型
results = model.train(data='fall_detection.yaml',epochs=100,imgsz=640,batch=16, # 根据GPU内存调整name='fall_detection_v1'
)# 评估模型
results = model.val()

6. 人员跌倒识别实现
训练完成后,使用最佳权重进行推理。
6.1 加载训练好的模型
from ultralytics import YOLO
import cv2# 加载训练好的模型
model = YOLO('runs/detect/fall_detection_v1/weights/best.pt') # 替换为你的路径
6.2 视频流识别(核心代码)
# 打开视频流
cap = cv2.VideoCapture(0) # 0 为默认摄像头,或视频文件路径while cap.isOpened():success, frame = cap.read()if not success:break# 使用训练好的模型进行预测results = model(frame)# 解析结果for result in results:boxes = result.boxesfor box in boxes:# 提取坐标x1, y1, x2, y2 = box.xyxy[0].cpu().numpy().astype(int)# 提取置信度conf = box.conf.cpu().numpy()[0]# 提取类别IDcls_id = int(box.cls.cpu().numpy()[0])# 获取类别名称class_name = model.names[cls_id] # 应为 'person-falling'# 根据类别设置颜色和标签if class_name == 'person-falling':color = (0, 0, 255) # 跌倒:红色label = f'FALLING! {conf:.2f}'# 在图像上绘制cv2.rectangle(frame, (x1, y1), (x2, y2), color, 2)cv2.putText(frame, label, (x1, y1 - 10),cv2.FONT_HERSHEY_SIMPLEX, 0.9, color, 2)# 显示结果cv2.imshow('Fall Detection - YOLO (Direct)', frame)if cv2.waitKey(1) == ord('q'):breakcap.release()
cv2.destroyAllWindows()
7. 可视化UI
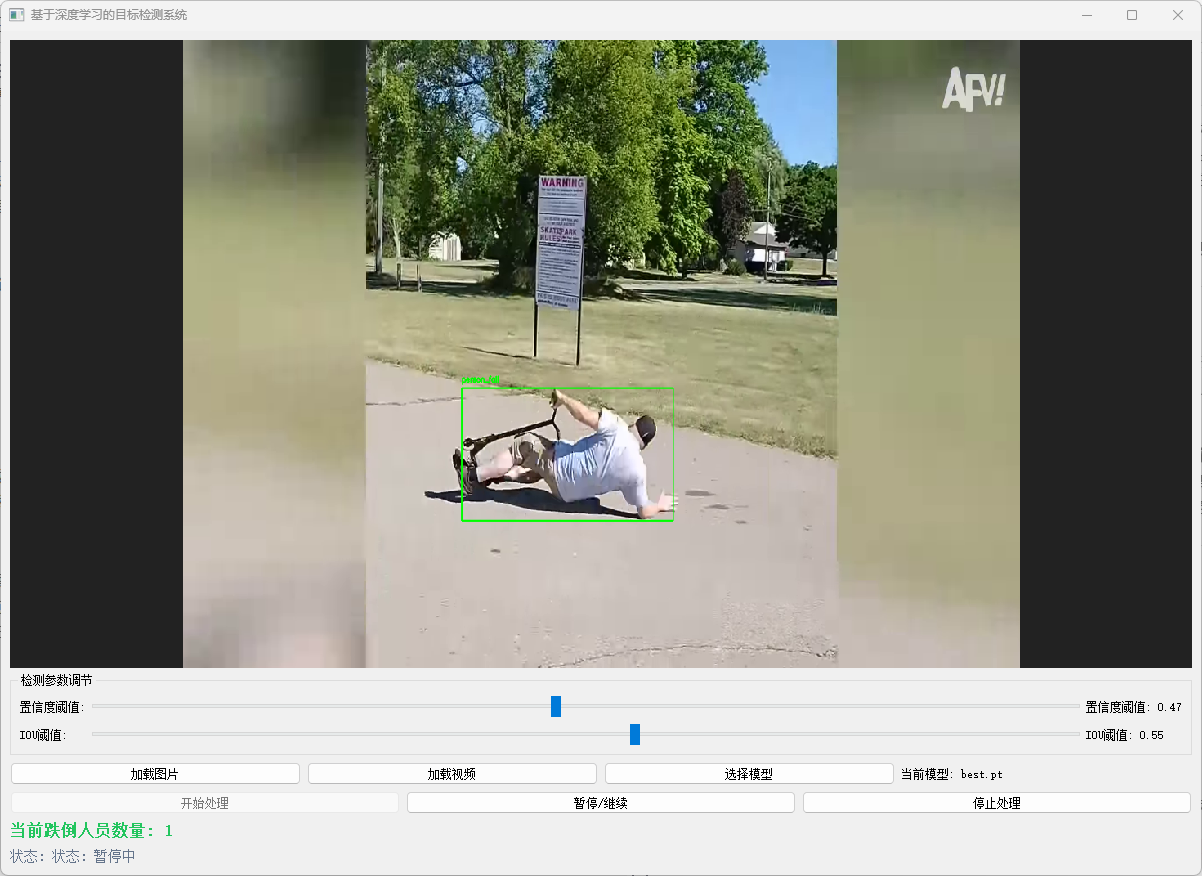
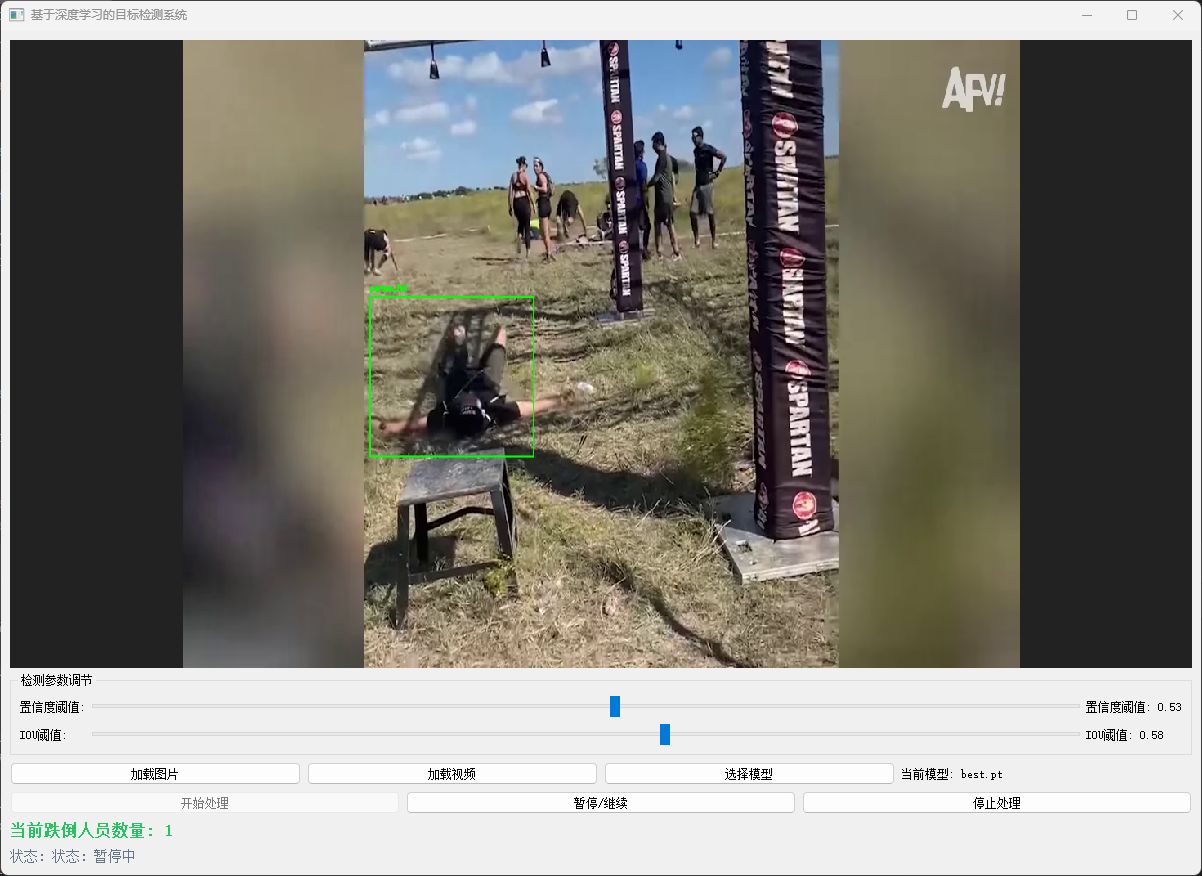
8. 优化与挑战
-
数据是关键:
“跌倒”的样本通常比“站立”少得多,容易导致类别不平衡。需要:
- 尽可能收集或生成更多的跌倒样本。
- 使用数据增强(旋转、翻转、亮度调整、Mosaic等)。
- 考虑在损失函数中加入类别权重。
-
跌倒的定义: “跌倒”是一个过程,从开始跌倒到完全倒地。需要明确定义哪些帧属于
person-falling类别(例如,身体倾斜角>60度且向下运动)。 -
隐私问题: 涉及人员图像,需严格遵守隐私法规,考虑在设备端处理或使用模糊化技术。
-
模型泛化: 模型在训练集之外的环境(不同房间、不同人)表现如何,需要充分测试。
-
实时性: 确保模型在目标硬件上能达到所需的帧率。
9. 总结
本文提出并实现了将“跌倒”作为独立目标进行检测的创新方案。通过直接训练目标检测模型识别 person-falling 两类,我们成功地将复杂的跌倒识别问题简化为标准的多类别目标检测任务。该方法逻辑清晰、实现简单、准确率高,有效规避了基于规则判断的诸多弊端。
虽然对高质量、平衡的数据集依赖性强,但随着数据工程和数据增强技术的发展,这一方案展现出巨大的应用潜力。它为构建更智能、更可靠的人员安全监控系统提供了一条高效、直接的路径。
往期相关内容
【图像算法 - 03】YOLO11/YOLO12/YOLOv10/YOLOv8 完全指南:从理论到代码实战,新手入门必看教程(文末有视频介绍)
【图像算法 - 04】Jetson 部署必看:YOLOv8/YOLOv10/YOLO11/YOLO12 毫秒级推理全指南(理论 + 代码实战,新手入门零门槛教程)
【图像算法 - 05】RK3588 部署实战:YOLO11/YOLOv8(det/seg/pose/obb) 毫秒级推理入门(理论精讲 + 代码落地,新手零门槛上手)
【图像算法 - 06】YOLO 全家桶人体姿态识别完全指南:从 YOLOv8 到 YOLO12 核心原理 + 代码实战,新手入门保姆级教程(附视频详解)
【图像算法 - 12】OpenCV-Python 入门指南:图像视频处理与可视化(代码实战 + 视频教程 + 人脸识别项目讲解)