哈希表五大经典应用场景解析
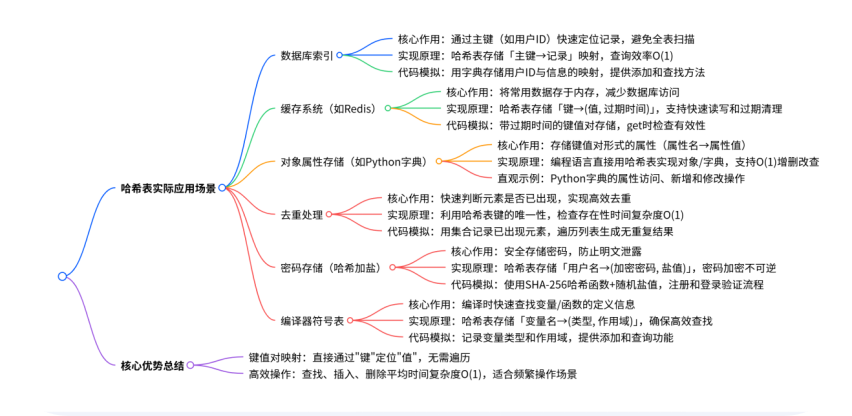
一、数据库索引(加速记录查找)
场景理解:数据库中,索引就像书的目录,通过 “主键”(如用户 ID)快速定位到整条记录,避免全表扫描。哈希表是实现索引的常用方式之一。
简单代码模拟:
# 用哈希表模拟数据库索引(键:用户ID,值:用户信息)
class DatabaseIndex:def __init__(self):self.index = {} # Python字典本质是哈希表,直接用它模拟def add_record(self, user_id, user_info):# 插入记录(O(1))self.index[user_id] = user_infodef find_record(self, user_id):# 查找记录(O(1))return self.index.get(user_id, "记录不存在")# 使用示例
db_index = DatabaseIndex()
db_index.add_record(1001, {"name": "Alice", "age": 25})
db_index.add_record(1002, {"name": "Bob", "age": 30})print(db_index.find_record(1001)) # 快速找到:{'name': 'Alice', 'age': 25}
print(db_index.find_record(9999)) # 未找到:记录不存在代码理解:
- 用 Python 字典(哈希表)
index存储 “用户 ID→用户信息” 的映射。 add_record对应数据库插入,find_record对应按 ID 查询,都是 O (1) 操作,比遍历所有记录(O (n))快得多。
二、缓存系统(如 Redis)
场景理解:缓存是把常用数据存到内存中,避免重复计算或查询数据库。哈希表能快速判断数据是否在缓存中,并快速存取。
简单代码模拟:
# 用哈希表模拟缓存系统(带过期时间简化版)
class SimpleCache:def __init__(self):self.cache = {} # 存储键值对:{key: (value, 过期时间)}self.expire_time = 5 # 假设缓存5秒后过期(简化)def set(self, key, value):# 存入缓存(记录当前时间+过期时间)import timeexpire_at = time.time() + self.expire_timeself.cache[key] = (value, expire_at)def get(self, key):# 从缓存获取(先检查是否存在且未过期)import timeif key not in self.cache:return "缓存未命中"value, expire_at = self.cache[key]if time.time() > expire_at:del self.cache[key] # 过期则删除return "缓存已过期"return value# 使用示例
cache = SimpleCache()
cache.set("user_1001", "Alice")print(cache.get("user_1001")) # 缓存命中:Alice(5秒内)
import time
time.sleep(6) # 等待6秒,超过过期时间
print(cache.get("user_1001")) # 缓存已过期代码理解:
- 哈希表
cache存储键值对,同时记录过期时间,确保数据不过期。 set和get操作都是 O (1),符合缓存 “快速读写” 的需求(Redis 的核心数据结构之一就是哈希表)。
三、对象属性存储(如 Python 字典)
场景理解:JavaScript 对象、Python 字典本质上是哈希表,用于存储键值对形式的属性(如对象的属性名和属性值)。
直观示例:
# Python字典本身就是哈希表的实现
person = {"name": "Alice","age": 25,"city": "Beijing"
}# 查找属性(O(1))
print(person["name"]) # Alice# 新增属性(O(1))
person["email"] = "alice@example.com"# 修改属性(O(1))
person["age"] = 26print(person) # {'name': 'Alice', 'age': 26, 'city': 'Beijing', 'email': 'alice@example.com'}代码理解:
- 字典的键(如 "name")通过哈希函数映射到内存地址,所以查找 / 修改属性时不需要遍历,直接定位,效率极高。
- 这就是为什么编程语言中用哈希表实现对象 / 字典 —— 满足 “频繁读写属性” 的需求。
四、去重处理(快速判断元素是否存在)
场景理解:需要快速判断一个元素是否已出现(如去重、查重),哈希表的key唯一性可以高效解决。
简单代码示例:
# 用哈希表给列表去重
def remove_duplicates(arr):seen = set() # 集合本质是哈希表(只存键,不存值)result = []for item in arr:if item not in seen: # 检查是否已出现(O(1))seen.add(item) # 记录已出现的元素(O(1))result.append(item)return result# 使用示例
arr = [3, 1, 2, 3, 2, 4, 1]
print(remove_duplicates(arr)) # [3, 1, 2, 4]代码理解:
- 集合
seen利用哈希表特性,item not in seen判断的时间复杂度是 O (1),比用列表判断(O (n))快得多。 - 适合处理大数据量去重(如日志去重、用户 ID 去重)。
五、密码存储(哈希加盐)
场景理解:不能明文存储密码,需用哈希函数加密(如 SHA-256),并加入 “盐值”(随机字符串)防止彩虹表破解。哈希表用于存储 “用户名→加密后的密码”。
简单代码示例:
import hashlib
import random
import string# 生成随机盐值
def generate_salt(length=8):return ''.join(random.choices(string.ascii_letters + string.digits, k=length))# 密码加密(哈希+盐值)
def hash_password(password, salt=None):if not salt:salt = generate_salt()# 密码+盐值一起哈希hash_obj = hashlib.sha256((password + salt).encode())return hash_obj.hexdigest(), salt # 返回哈希值和盐值# 模拟密码存储(哈希表)
password_db = {} # {用户名: (哈希值, 盐值)}# 注册:存储加密后的密码
def register(username, password):hashed_pwd, salt = hash_password(password)password_db[username] = (hashed_pwd, salt)# 登录:验证密码
def login(username, password):if username not in password_db:return Falsestored_hash, salt = password_db[username]# 用相同的盐值加密输入的密码,再对比哈希值input_hash, _ = hash_password(password, salt)return input_hash == stored_hash# 使用示例
register("alice", "mypass123")
print(login("alice", "mypass123")) # 正确:True
print(login("alice", "wrongpass")) # 错误:False代码理解:
- 哈希表
password_db存储用户名与加密后的密码(哈希值 + 盐值)。 - 核心是 “哈希不可逆”:即使黑客拿到哈希值,也无法反推原始密码(加盐后更安全)。
六、编译器符号表(快速查找变量定义)
场景理解:编译器在编译代码时,需要快速查找变量 / 函数的定义(如作用域、类型),符号表就是用哈希表实现的。
简单代码模拟:
# 用哈希表模拟编译器符号表(存储变量信息)
class SymbolTable:def __init__(self):self.table = {} # {变量名: (类型, 作用域)}def add_symbol(self, name, var_type, scope):# 记录变量信息self.table[name] = (var_type, scope)def lookup_symbol(self, name):# 查找变量信息(编译时检查变量是否已定义)return self.table.get(name, f"变量{name}未定义")# 使用示例
symbol_table = SymbolTable()
# 模拟编译过程中记录变量
symbol_table.add_symbol("count", "int", "global")
symbol_table.add_symbol("name", "str", "local")# 编译时查找变量
print(symbol_table.lookup_symbol("count")) # ('int', 'global')
print(symbol_table.lookup_symbol("age")) # 变量age未定义代码理解:
- 编译器在解析代码时,每遇到一个变量就存入符号表,后续用到时快速查找(O (1)),确保变量已定义且类型正确。
- 哈希表的快速查找能力保证了编译效率。
总结:哈希表的核心价值
所有场景都围绕哈希表的两个核心优势:
- 键值对映射:直接通过 “键” 定位 “值”,无需遍历。
- 高效操作:查找、插入、删除的平均时间复杂度是 O (1),适合频繁操作的场景。
作为初学者,不需要死记硬背场景,只需理解:当需要 “通过一个标识快速找到对应数据” 时,哈希表通常是最佳选择。代码实现上,Python 的dict和set已经封装了哈希表的功能,直接使用即可(底层原理就是我们之前学的哈希表结构)。