PYTHON从入门到实践-17通过网络API获取数据与可视化
在当今的大数据时代,API(应用程序编程接口)已成为获取和交换数据的重要方式。本文将通过两段实用的 Python 代码,带大家学习如何调用公开 API 获取有价值的数据,并进行简单的处理与可视化。我们将分别实现调用 GitHub API 获取热门 Python 项目信息并绘制柱状图,以及调用 Hacker News API 获取文章详情数据。
一、调用 GitHub API 获取热门 Python 项目并可视化
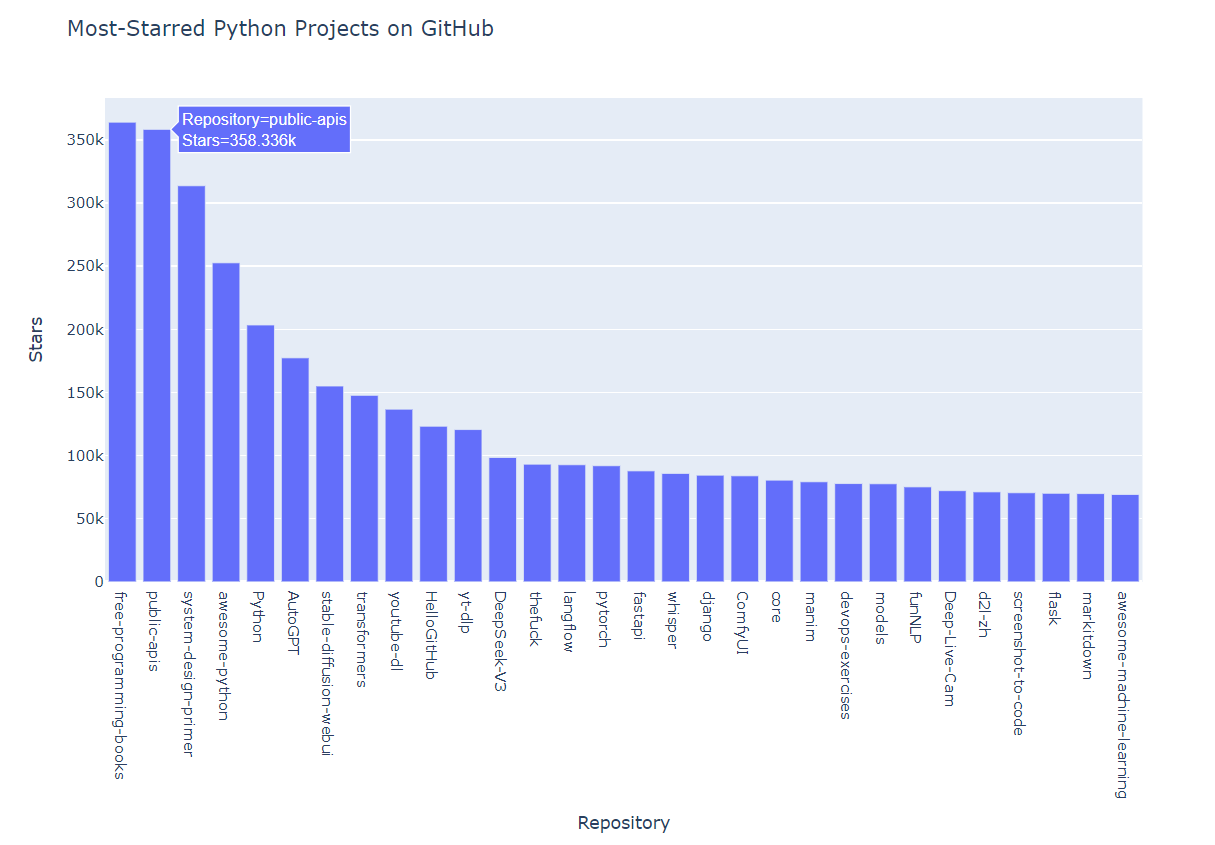
GitHub 作为全球最大的代码托管平台,拥有海量的开源项目。通过其提供的 API,我们可以方便地获取各类项目信息。下面的代码将为我们筛选出星标数超过 10000 的热门 Python 项目,并通过柱状图直观展示它们的星标数量。
首先,我们需要导入必要的库。requests库用于发送 HTTP 请求,plotly.express则用于数据可视化:
import requests import plotly.express as px |
接下来,我们构造 API 请求的 URL 和头部信息。这里的 URL 指定了我们要搜索的是编程语言为 Python、按星标数排序且星标数超过 10000 的仓库。头部信息则告诉 GitHub API 我们期望的响应格式:
url = "https://api.github.com/search/repositories?q=language:python+sort:stars+stars:>10000" headers = {"Accept": "application/vnd.github.v3+json"} res = requests.get(url, headers=headers) print("HTTP响应码:", res.status_code) |
发送请求后,我们首先查看 HTTP 响应码。如果响应码为 200,说明请求成功。随后,我们将响应的 JSON 数据转换为字典,并提取其中的项目信息:
json_result = res.json() repos_dict = json_result["items"] |
得到项目信息后,我们需要从中提取绘图所需的数据,即仓库名和对应的星标数。通过循环遍历项目列表,我们将这两项数据分别存入两个列表中:
repo_names = [] star_counts = [] for repo in repos_dict: repo_names.append(repo["name"]) star_counts.append(repo["stargazers_count"]) |
最后,我们使用plotly.express绘制柱状图。设置 x 轴为仓库名,y 轴为星标数,并为图表添加合适的标签和标题。调用fig.show()方法可以在浏览器中显示图表:
fig = px.bar( x=repo_names, y=star_counts, labels={"x": "Repository", "y": "Stars"}, title="Most-Starred Python Projects on GitHub" ) fig.show() |
运行这段代码后,我们将得到一个交互式的柱状图,清晰地展示了 GitHub 上最受欢迎的 Python 项目及其星标数量。通过这个图表,我们可以快速了解当前 Python 领域的热门项目,为自己的学习和开发提供参考。
二、调用 Hacker News API 获取文章详情
Hacker News 是一个著名的技术资讯网站,上面有大量关于计算机科学、创业等领域的讨论。其提供的 API 可以让我们方便地获取网站上的文章和评论信息。下面的代码将演示如何获取指定文章的详细信息。
同样,我们需要导入requests库用于发送 HTTP 请求,以及json库用于处理 JSON 数据:
import requests import json |
Hacker News 的 API URL 格式相对简单,每个文章都有一个唯一的 ID,通过这个 ID 我们可以构造出获取该文章详情的 URL。这里我们以 ID 为 31353677 的文章为例:
url = "https://hacker-news.firebaseio.com/v0/item/31353677.json" r = requests.get(url) print(f"Status code: {r.status_code}") |
发送请求后,我们同样先查看响应码以确认请求是否成功。然后,将响应的 JSON 数据转换为字典,并使用json.dumps()方法将其格式化输出,以便我们更好地查看数据结构:
response_dict = r.json() response_string = json.dumps(response_dict, indent=4) print(response_string) |
运行这段代码后,我们将看到该文章的详细信息,包括标题、URL、发布时间、作者、评论数等。这些信息对于我们分析文章内容、了解技术趋势等都非常有价值。
三、总结与拓展
通过本文介绍的两段代码,我们学习了如何使用 Python 调用公开 API 获取数据,并进行简单的处理和可视化。这只是 API 应用的冰山一角,在实际开发中,我们还可以根据需要对获取到的数据进行更深入的分析和处理。
例如,对于 GitHub 的项目数据,我们可以进一步提取项目的创建时间、更新时间、贡献者数量等信息,分析项目的活跃度和发展趋势。对于 Hacker News 的文章数据,我们可以批量获取热门文章,分析其中的关键词,了解当前的技术热点。
此外,在调用 API 时,我们还需要注意遵守 API 的使用规范,如合理控制请求频率、不要滥用 API 等。许多 API 都有调用限制,超过限制可能会被暂时或永久禁止访问。
希望本文能为大家提供一个良好的开端,帮助大家更好地利用 API 获取和处理数据,为自己的学习和工作带来便利。