39.MySQL索引
1.一个实例
假设我们现在某一个数据库中创建一个有1000万条记录的数据库表,它的查询效率是怎样的呢?
-- 创建无主键和索引的表
CREATE TABLE user_data_raw (id INT,name VARCHAR(50),email VARCHAR(100)
) ENGINE=InnoDB;-- 创建存储过程(先检查是否存在,避免重复创建导致的错误)
DROP PROCEDURE IF EXISTS GenerateUserData;
DELIMITER $$
CREATE PROCEDURE GenerateUserData()
BEGINDECLARE v_counter INT DEFAULT 1;DECLARE v_name VARCHAR(50);DECLARE v_email VARCHAR(100);DECLARE v_domain VARCHAR(20);START TRANSACTION;WHILE v_counter <= 10000000 DOSET v_name = CONCAT(ELT(FLOOR(1 + RAND() * 26), '张', '王', '李', '赵', '刘', '陈', '杨', '黄', '周', '吴', '徐', '孙', '马', '朱', '胡', '林', '郭', '何', '高', '罗', '郑', '梁', '谢', '宋', '唐'),ELT(FLOOR(1 + RAND() * 26), '伟', '芳', '娜', '秀英', '敏', '静', '强', '磊', '军', '洋', '勇', '艳', '杰', '娟', '涛', '明', '超', '云', '玲', '琳', '飞', '宇', '鹏', '丽', '建国'));SET v_domain = ELT(FLOOR(1 + RAND() * 5), 'gmail.com', 'yahoo.com', 'hotmail.com', 'qq.com', '163.com');SET v_email = CONCAT(SUBSTRING(v_name, 1, 1), FLOOR(RAND() * 10000), '@', v_domain);-- 显式插入 ID 值INSERT INTO user_data_raw (id, name, email) VALUES (v_counter, v_name, v_email);IF v_counter % 100000 = 0 THENCOMMIT;START TRANSACTION;END IF;SET v_counter = v_counter + 1;END WHILE;COMMIT;
END$$
DELIMITER ;-- 执行存储过程生成数据
CALL GenerateUserData();下面是执行结果:
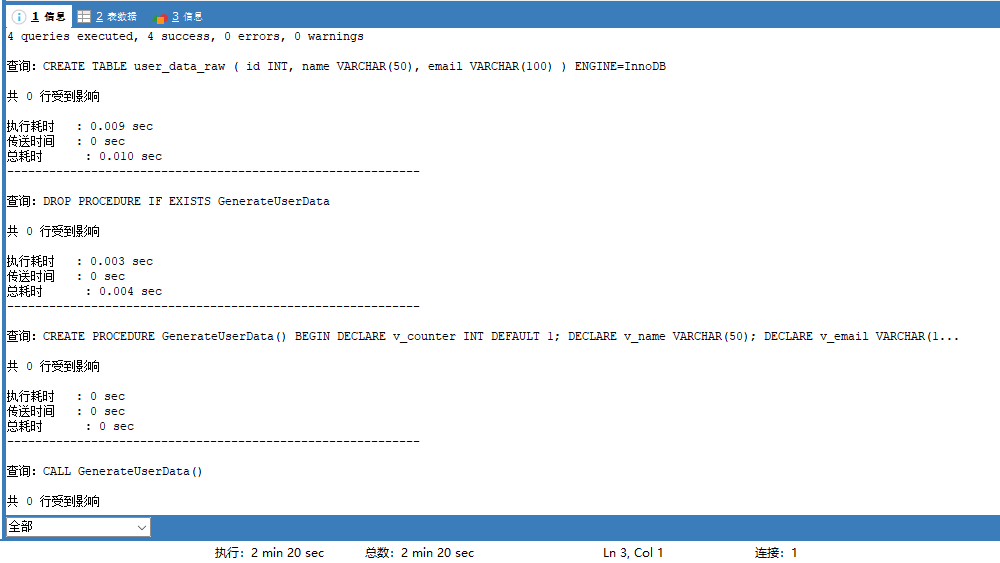
可以看到sql脚本单单执行就花了两分钟,生成的数据库文件就有500多MB:
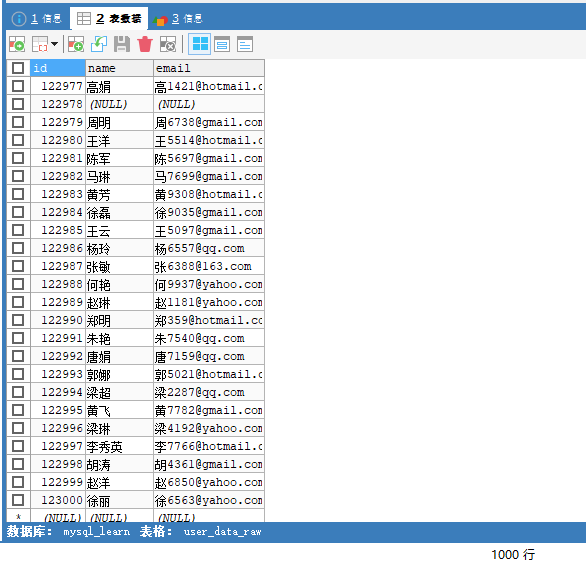
假设我们现在要查询id为122997的李秀英这条记录,一条查询语句需要执行多久呢?
SELECT * FROM user_data_raw WHERE id = 122997;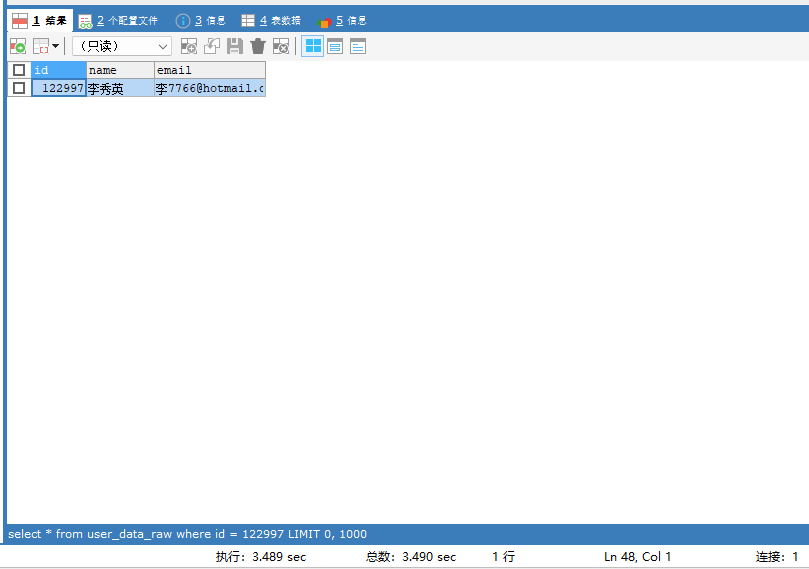
可见,该查询语句花了3秒钟多(根据电脑配置而定)。
现在为ID字段添加一个索引:
-- user_index 索引名称
-- ON user_data (id) : 表示在 user_data_raw表的 id列创建索引
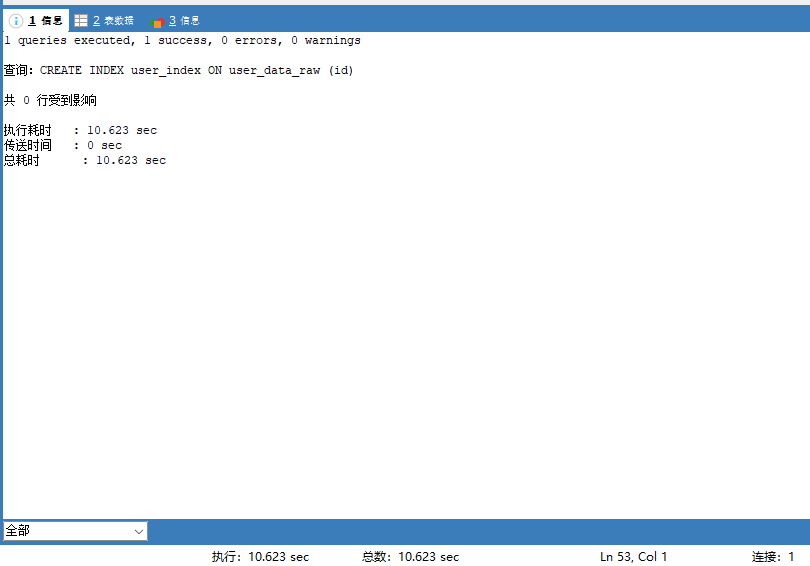
CREATE INDEX user_index ON user_data_raw (id);创建索引花了10秒多钟:
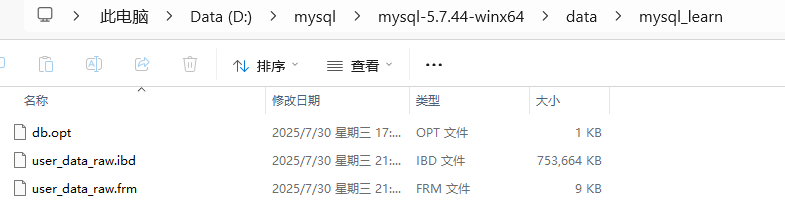
原先的数据库文件大小也增加到了700多MB:
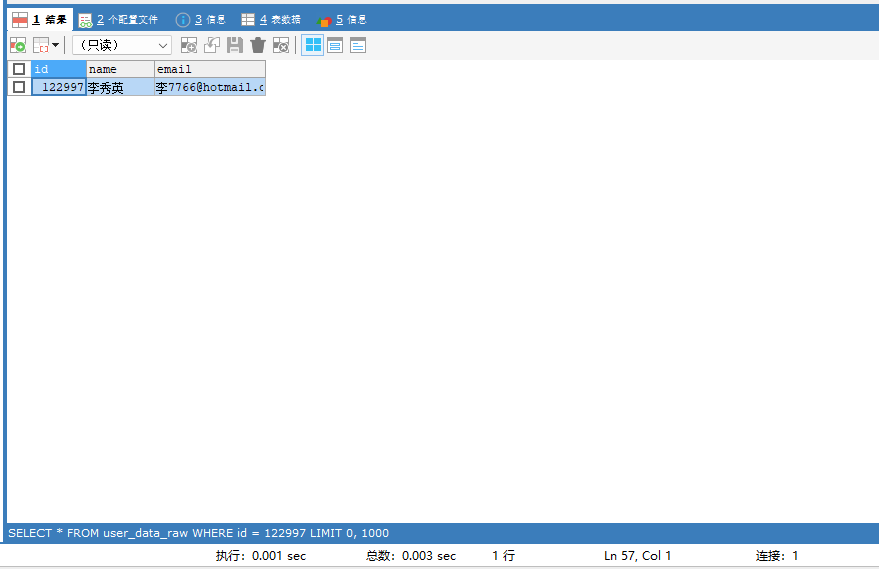
再来使用带索引的字段查询一下刚才的记录:
SELECT * FROM user_data_raw WHERE id = 122997;时间缩短到了0.001秒:
可见使用索引之后我们的查询效果翻倍。
总结一下:
说起提高数据库性能,索引是最物美价廉的东西了。不用加内存,不用改程序,不用调 sql,查询速度就可能提高百倍千倍。
但并不是说使用索引就可以解决所有问题,其提高的查询效率只对带索引字段起效果,并且生成索引需要占用一大部分磁盘空间。
例如我们再次执行一下不使用索引的查询语句:依旧会花费很长时间。
SELECT * FROM user_data_raw WHERE `name` = '李秀英' AND `email` = '李7766@hotmail.com';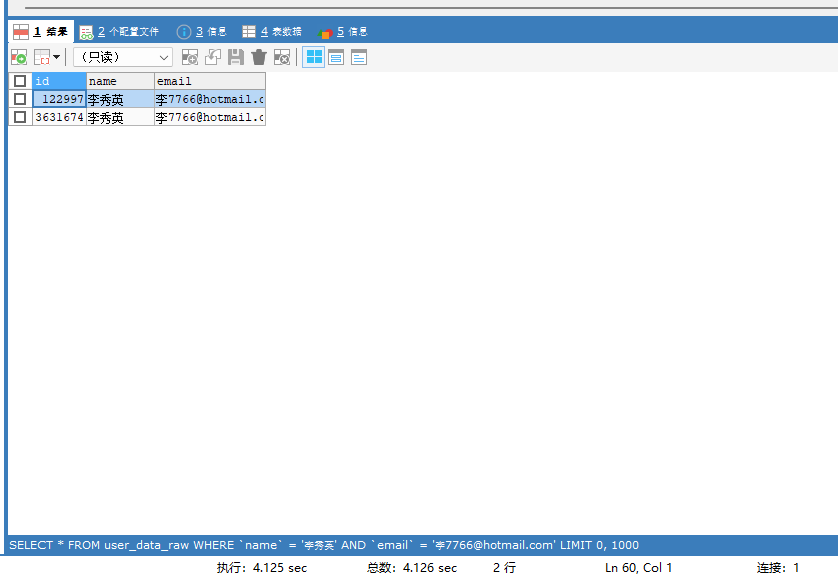
2.索引的原理
2.1没有索引为什么会慢?
在没有索引的情况下,执行查询语句所做的是全表扫描:

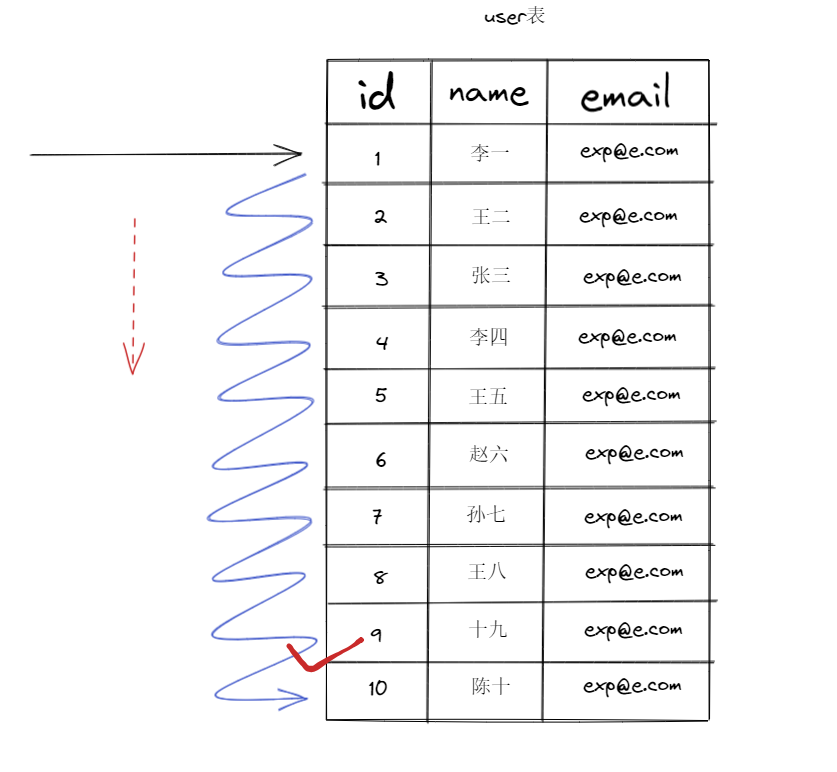
数据量多了,自然就慢了。
2.2有了索引为什么会快?
索引使用了特殊的数据结构来存储记录:
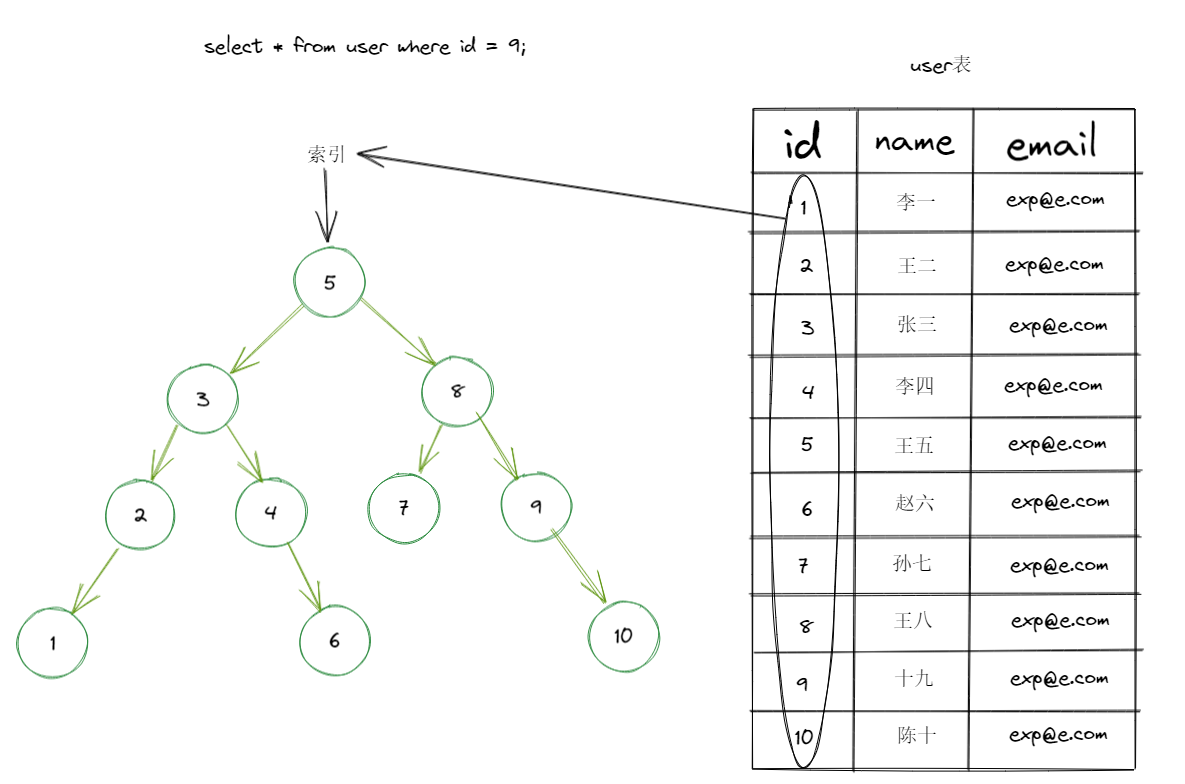
假设将id这个字段添加一个索引,该索引使用二叉搜索树这样的树型结构存储:
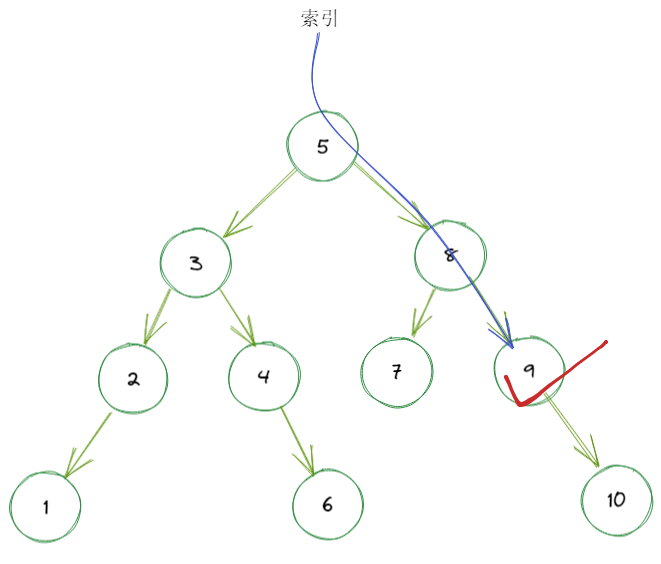
查询ID为9的记录只需要2次查询,与不适用索引的全表扫描相比,查询快非常多。
那假如我们使用索引查询30次,最低能覆盖多少条记录呢?
30 层的满二叉树有 2^30 - 1 个结点(计算得 1073741823 个)。
2.3索引的代价
1.磁盘的占用
索引的建立需要引入数据结构对记录的存储,会占用大量磁盘空间。在前一个示例中可见。
2.对 dml (update delete insert) 语句的效率影响
这些数据库语句执行时还需要对索引的结构进行修改,需要花费时间。
例如:删除id=9的这条记录
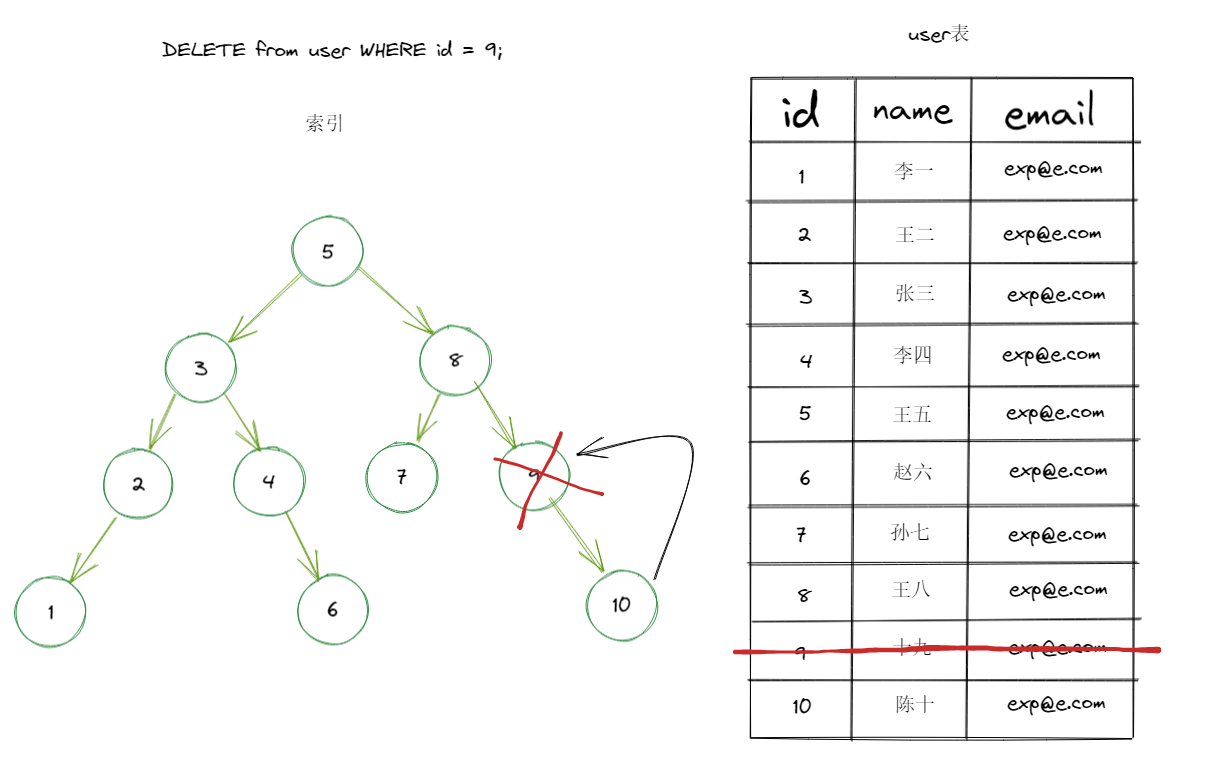
3.索引分类
3.1主键索引
主键自动的为主索引(类型 Primary key)
create table t1 (id int primary key, -- 主键,同时也是索引,称为主键索引.3.2唯一索引
唯一索引(UNIQUE)
create table t2(id int unique, -- id 是唯一的,同时也是索引,称为 unique 索引.3.3普通索引
普通索引(INDEX)
一般为那些普通的可以重复的字段建立的索引,例如NAME字段。
-- user_index 索引名称
-- ON user_data (id) : 表示在 user_data_raw表的 id列创建索引
CREATE INDEX user_index ON user_data_raw (id);3.4全文索引
全文索引(FULLTEXT)[适用于 MyISAM引擎]
全文索引(FULLTEXT Index)是一种专门针对 长文本内容 的索引技术,核心作用是 让“关键词搜索文本”的效率大幅提升,解决传统 LIKE '%关键词%' 全表扫描的性能问题。下面从 概念、原理、实际例子 展开解释:
一、全文索引解决的核心问题
想象一个场景:你有一张表存了10万篇文章,现在要搜“人工智能”相关的内容。
- 如果用
WHERE content LIKE '%人工智能%':数据库会逐行扫描content字段,数据量大时慢到“无法接受”(时间复杂度O(N),N是行数)。 - 如果给
content建全文索引:数据库会先把文本拆成关键词(如“人工智能”“技术”等),建立“关键词→出现位置”的映射,搜索时直接通过映射定位结果,速度呈数量级提升(类似字典的“拼音索引”,而非逐页翻找)。
二、全文索引的工作原理(倒排索引)
全文索引的核心是 倒排索引(Inverted Index),步骤如下:
- 分词:把文本拆成一个个“词”(英文按空格,中文需分词器,如MySQL的
ngram会把“人工智能”拆成“人工”“智能”“人工智”“工智能”等片段)。 - 建索引:记录每个词出现在哪些行(文档)里。例如:
- 文章1:“人工智能改变世界” → 词:
人工智能、改变、世界 - 文章2:“人工智能的技术突破” → 词:
人工智能、技术、突破 - 倒排索引:
人工智能→[1,2],改变→[1],世界→[1] ...
- 文章1:“人工智能改变世界” → 词:
- 搜索时:先对搜索词分词,再通过倒排索引快速找到包含这些词的行,还能按 相关性排序(比如词出现次数多的行排前面)。
三、实际例子:MySQL中的全文索引
以“博客系统搜文章”为例,步骤如下:
1. 创建表并添加全文索引
CREATE TABLE articles (id INT PRIMARY KEY AUTO_INCREMENT,title VARCHAR(200), -- 文章标题content TEXT, -- 文章内容(长文本)-- 给title和content字段建全文索引FULLTEXT (title, content)
) ENGINE=InnoDB; -- MySQL 5.6+版本,InnoDB支持全文索引2. 插入测试数据
INSERT INTO articles (title, content) VALUES
('AI发展趋势', '人工智能在医疗领域的应用越来越广泛'),
('编程技巧', 'Python和Java的语法差异分析'),
('科技前沿', '人工智能如何改变未来生活?');3. 用全文索引搜索
场景1:搜“人工智能”相关文章
SELECT * FROM articles
WHERE MATCH(title, content) AGAINST('人工智能' IN NATURAL LANGUAGE MODE);- 结果:会返回标题或内容包含“人工智能”的行(第1、3条),且按 相关性排序(比如第3条多次提“人工智能”,可能排更前)。
- 对比
LIKE:如果数据量是10万条,全文索引可能毫秒级返回,LIKE可能需要几秒甚至更久。
场景2:复杂搜索(布尔模式,支持+必须包含、-必须排除)
比如,搜**包含“人工智能”但不包含“医疗”**的文章:
SELECT * FROM articles
WHERE MATCH(title, content) AGAINST('+人工智能 -医疗' IN BOOLEAN MODE);- 结果:只返回第3条(“科技前沿”那篇,含“人工智能”但不含“医疗”)。
四、全文索引的适用场景
- 内容搜索:论坛帖子、新闻文章、商品描述的关键词搜索。
- 数据分析:从日志、报告中提取关键词(如从用户评论里搜“体验差”)。
- 简单场景:如果是复杂搜索(如精准中文分词、分布式),建议用Elasticsearch/Solr,但MySQL的全文索引胜在“和业务库一体,部署简单”。
五、关键注意事项
- 引擎和字段限制:仅支持
InnoDB(5.6+)和MyISAM引擎,且字段必须是char、varchar、text类型。 - 中文分词问题:MySQL默认英文分词(按空格),中文需用
ngram分词器(需手动配置,比如拆成2字或3字片段),否则分词效果差(比如“人工智能”会被拆成“人工”“智能”等,可能漏匹配)。 - 写入性能影响:建全文索引会增加写入耗时(因为要分词建索引),大数据量时需评估。
简单来说,全文索引是文本内容的“加速地图”,让你在海量文字里快速定位关键词,就像给书做了“目录”——不用逐页翻,直接找目录里的关键词跳转到对应内容。
一般开发,不使用 mysql 自带的全文索引,而是使用:全文搜索 Solr 和 ElasticSearch(ES):
Solr 是 “为企业级全文搜索而生的专业框架”,Solr 是 Apache 基金会开源的企业级搜索平台,基于 Apache Lucene 构建,专注解决海量文本数据的高效检索、分析与管理问题,为电商、媒体、金融等场景提供专业搜索能力。
ElasticSearch是一款分布式全文搜索引擎。
4.索引的使用
4.1创建索引
先创建一个表:
CREATE TABLE t01 (id INT ,`name` VARCHAR(32));查看一下表中的索引信息:
SHOW INDEXES FROM t01;可以看到表中的索引信息是没有的:
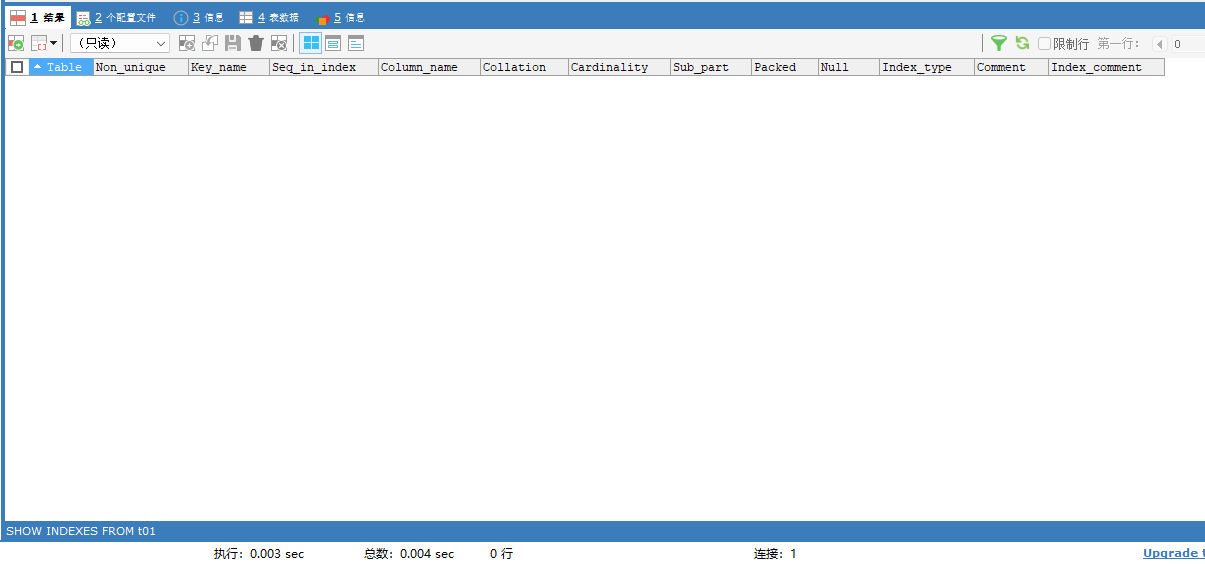
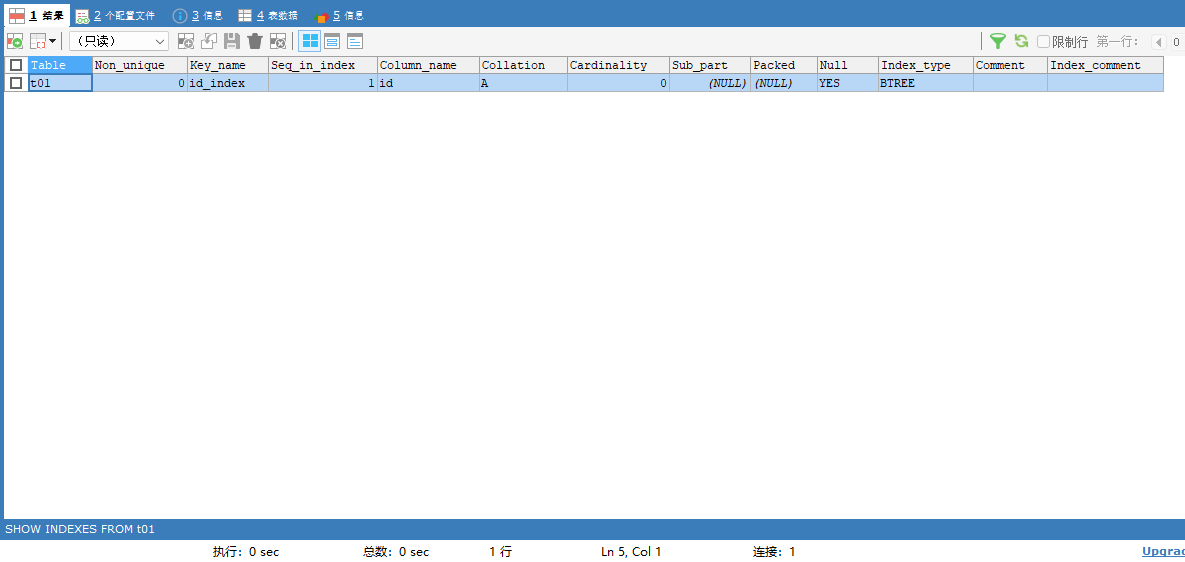
创建一个唯一索引:当我们认定某个字段的值不可以重复时优先采用唯一索引
CREATE UNIQUE INDEX id_index ON t01 (id);再次查看一下表中索引:可以看到多出了一个唯一索引
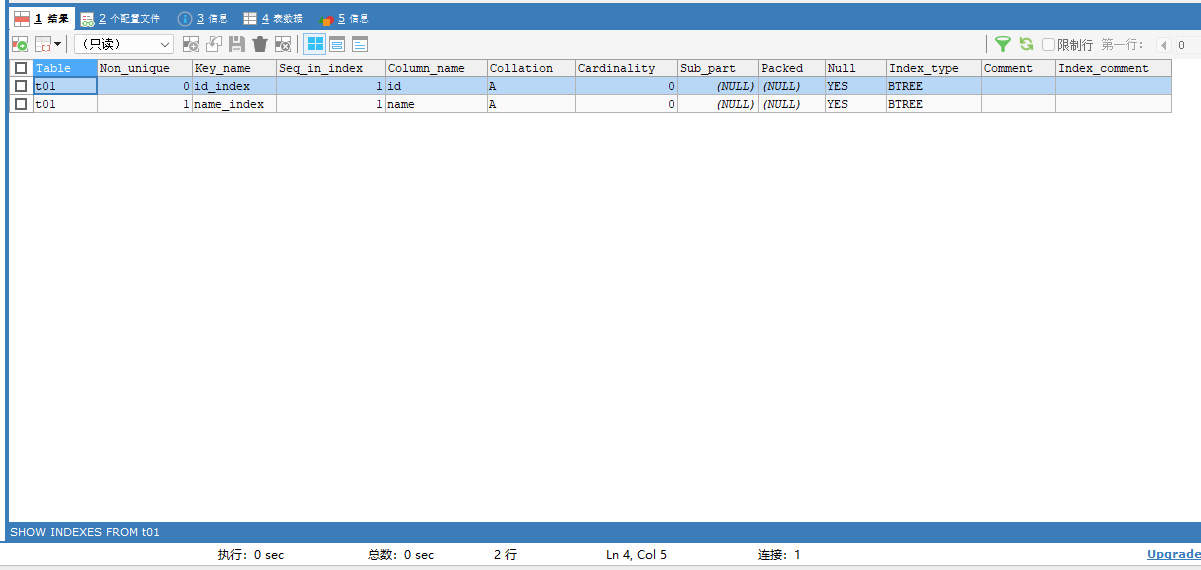
创建一个普通索引(方式1):优先为可以重复值的字段添加
CREATE INDEX name_index ON t01 (`name`);再次查看一下表中索引情况:可以发现又多出了一个普通索引
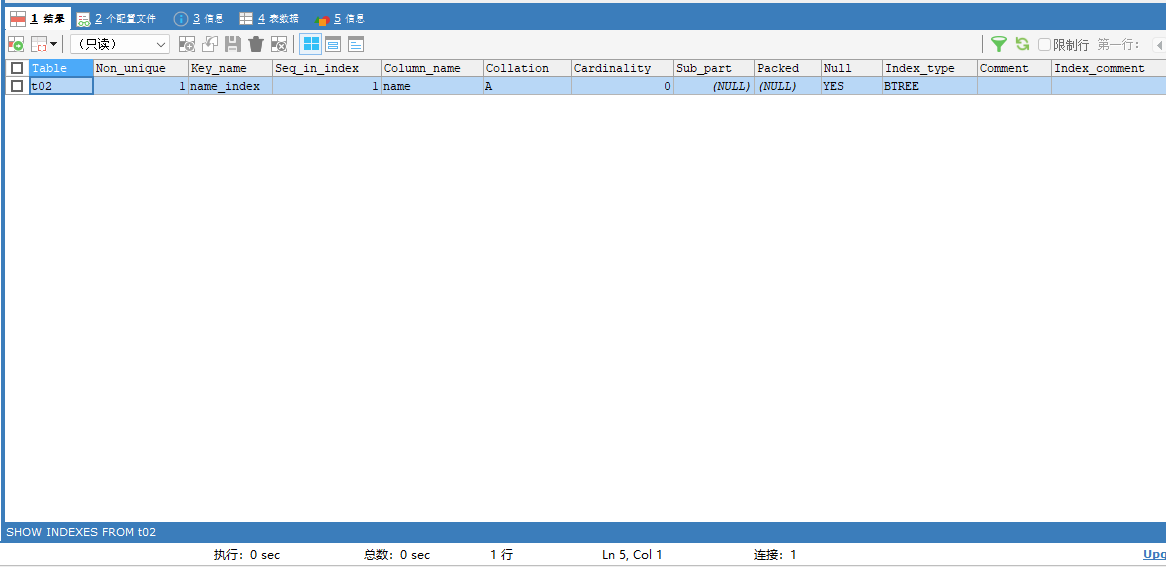
再次创建一个新表:
CREATE TABLE t02 (id INT,`name` VARCHAR(32)
);创建一个普通索引(方式2):
ALTER TABLE t02 ADD INDEX name_index (`name`);查看一下表2的索引情况:可以看到多出一个普通索引
创建一个主键索引:
ALTER TABLE t02 ADD PRIMARY KEY (id);查看一下表2的索引情况:可以看到多出一个主键索引
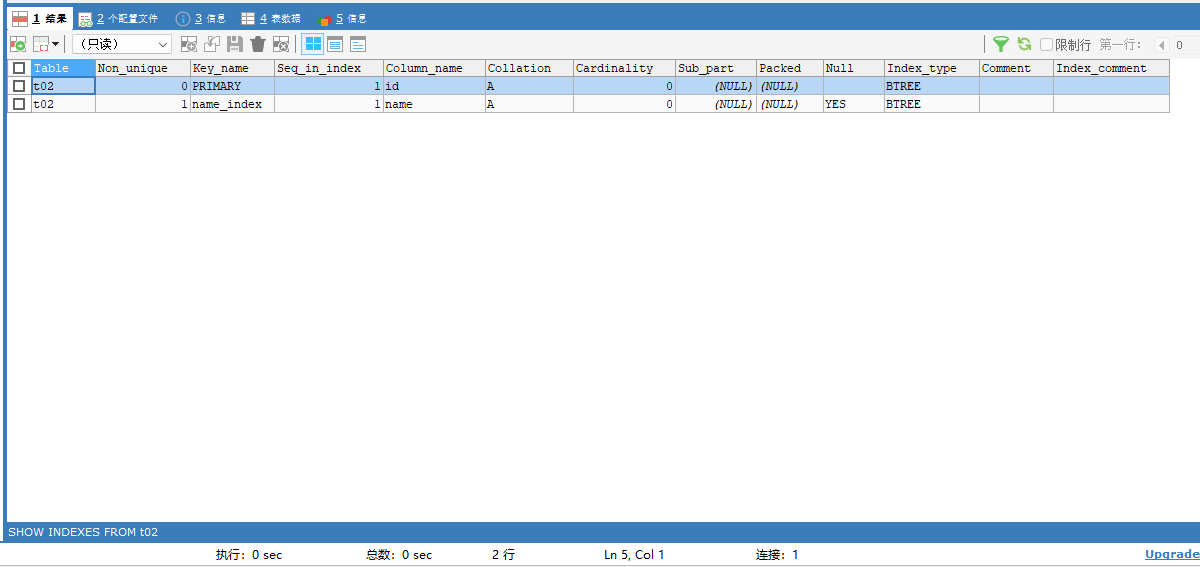
4.2查看索引
使用以下语句可以查看表中的索引情况:
方式1:
SHOW INDEXES FROM table_name;方式2:
SHOW INDEX FROM table_name;方式3:
SHOW KEYS FROM table_name;方式4:
DESC table_name;例如这里的name中的key显示为mul就是指name这个字段存在普通索引:
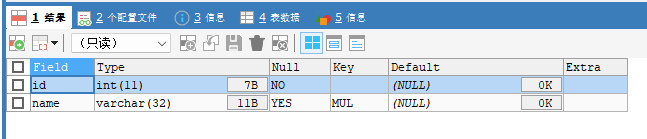
4.3删除索引
例如删除表t01中的索引:
首先一般需要查看一下索引的名字:
SHOW INDEXES FROM t01;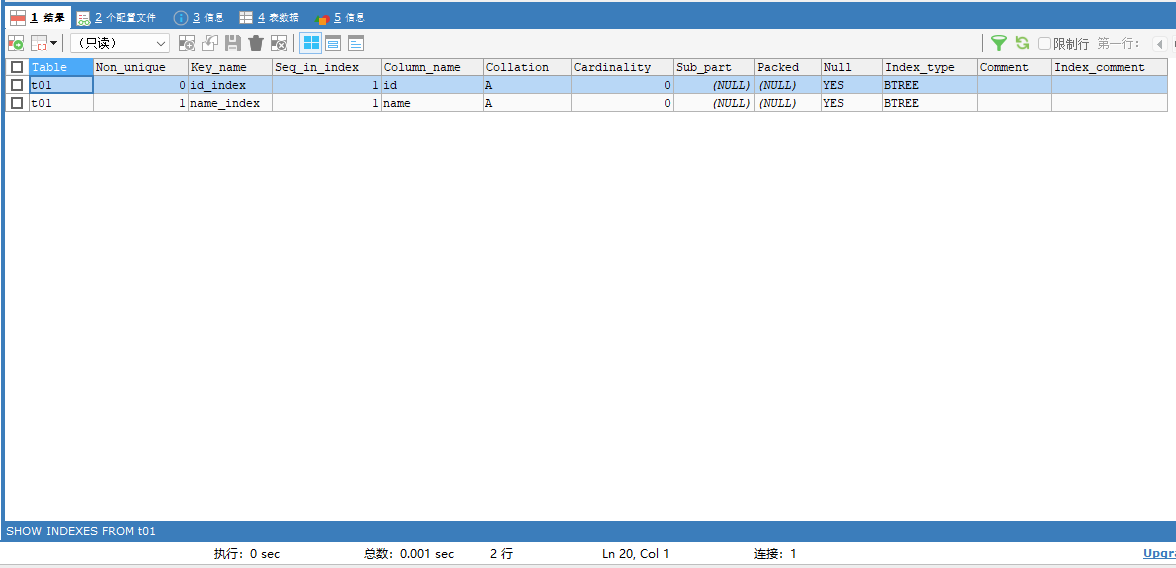
再用命令指定删除对应名字的普通索引:例如删除name_index这个普通索引
DROP INDEX name_index ON t01;查看以下结果:会发现t01这张表中只剩下一个以前创建的主键索引
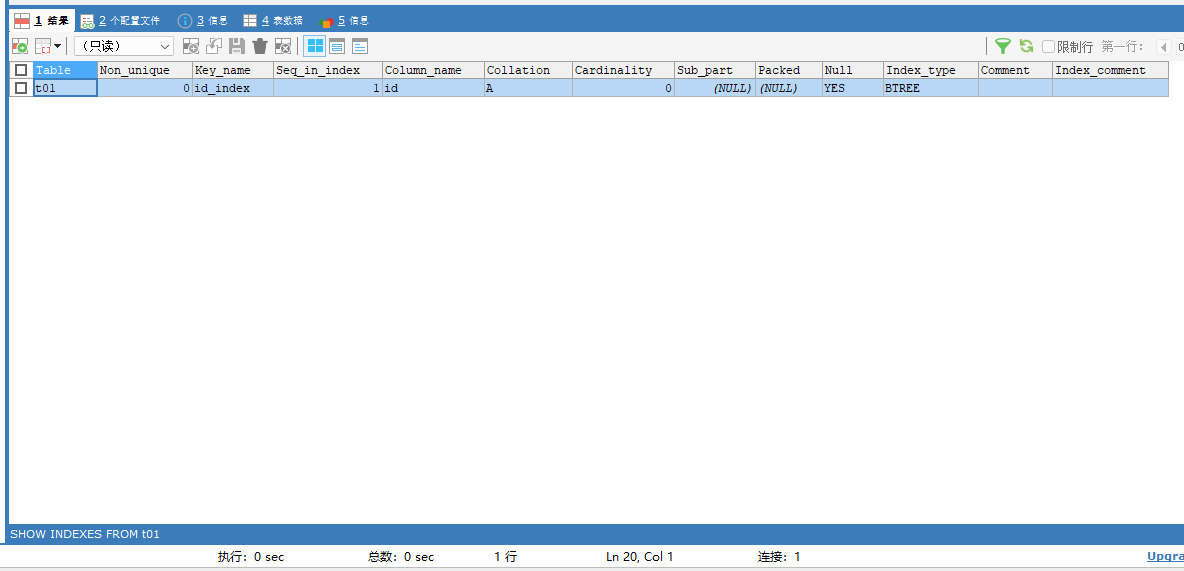
由于主键索引的删除方式不一样,我们再来演示以下删除主键索引,以t02这张表为例子:
先查看一下t02中的索引情况:可以看到是存在一个主键索引的
SHOW INDEXES FROM t02;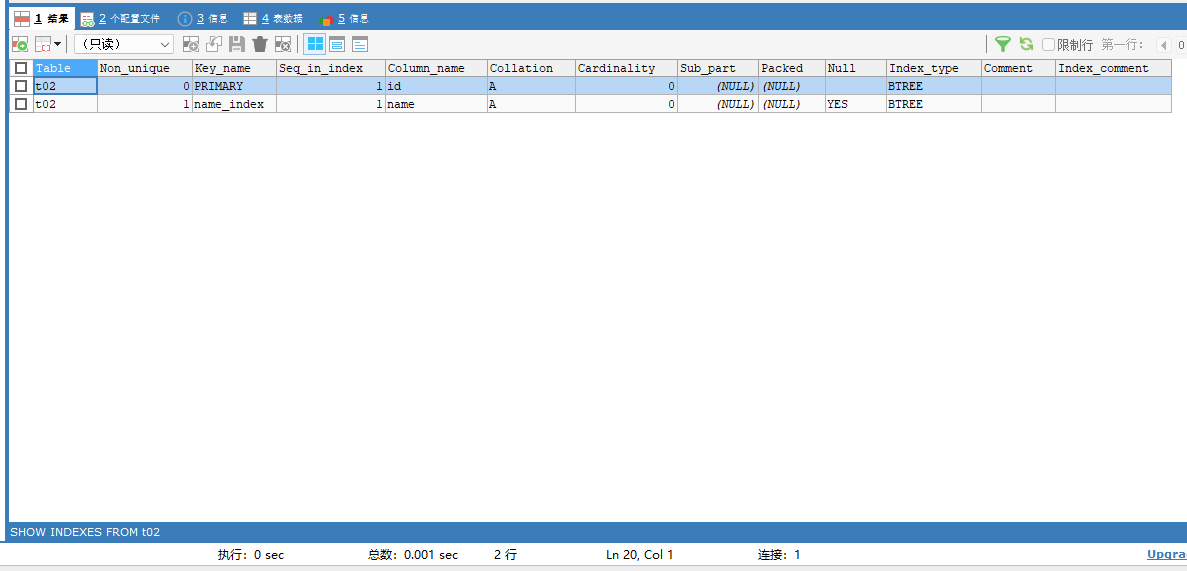
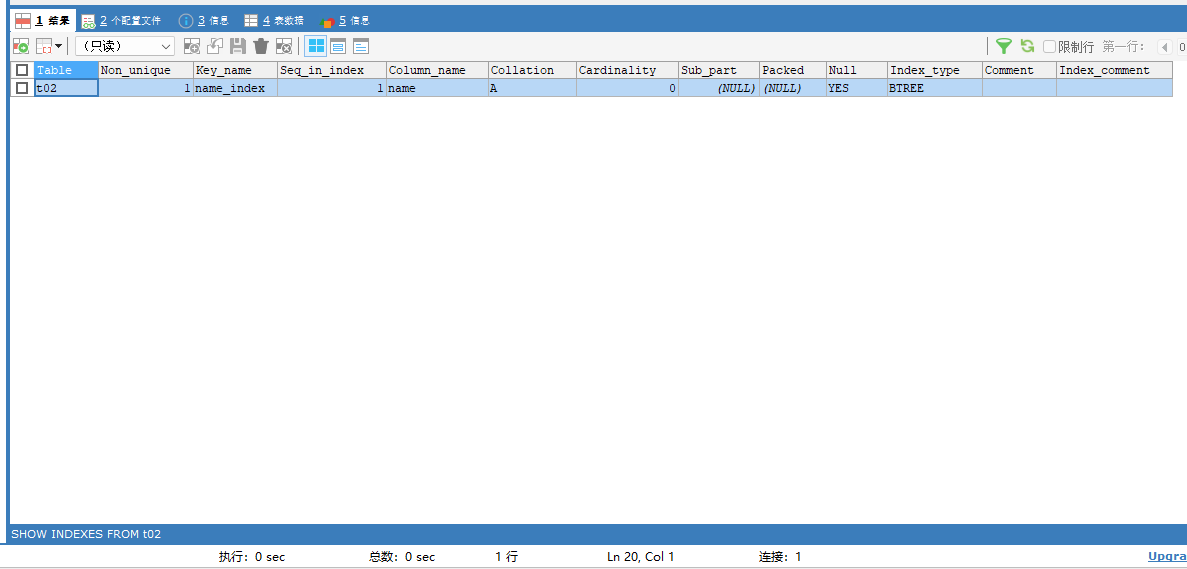
ALTER TABLE t01 DROP PRIMARY KEY;执行一下看结果:可以看到t02这张表中的主键索引被删除了。
5.创建索引的规则
小结:哪些列上适合使用索引?
- 较频繁的作为查询条件字段应该创建索引
select * from emp where empno = 1 - 唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件
select * from emp where sex = ' 男 ' - 更新非常频繁的字段不适合创建索引
select * from emp where logincount = 1 - 不会出现在 WHERE 子句中字段不该创建索引