极致业务弹性 密度性能双管齐下—联想问天 WR5220 G5 服务器测试
从20世纪90年代以互联网革命为代表的第二次信息化浪潮,到近十年以云计算、人工智能为代表的第三次信息化浪潮,服务器作为核心算力平台,正不断面临需求日趋多样化的挑战——有的业务需求强调高并发性,有的需要超高性能。人工智能,尤其是大语言模型的发展,让服务器的形态进一步发生了分化。对于主流的通用服务器,用户期望是能够整合多元化算力,并强调业务的混合部署。
为了应对服务器需求的变化,上游厂商对处理器规格进行了细分,譬如英特尔在新一代的Birch Stream平台中,就将至强6处理器分为性能核(P)、能效核(E),平台分为AP、SP并对应不同的接口(LGA-7529和LGA-4710),组合出4大系列,以应对不同应用场景。而从服务器厂商角度看,研发的每一个服务器平台除了适配“性格迥异”的处理器,更重要的是竭尽所能提供充足的弹性以应对复杂多元的用户需求,这需要深厚的技术积淀,以及对用户需求的深刻理解。
尊重传统,但内涵更多
联想问天 WR5220 G5是面向主流市场的新一代2U双路机架式服务器,基于英特尔Birch Stream-SP平台,搭配至强6500/6700系列能效核或性能核处理器,内核数量、内存带宽、PCIe通道数量等规格均有显著的提升。

至强6能效核与性能核处理器面向不同的应用场景。其中,配置能效核处理器的服务器倾向于相对传统的应用场景,如企业常用的ERP、CRM等应用,以及Web、微服务、CDN等。配置性能核处理器的服务器主要服务于高性能运算、AI、大数据分析等,以及分布式系统、虚拟桌面等。为了应对如此多元化的场景,联想问天 WR5220 G5提供了很强的扩展弹性。

英特尔Birch Stream平台有两种插座,规格最强的Birch Stream-AP支持6900系列处理器,核心数量、内存通道更多,功耗也更高——单处理器可达500W。Birch Stream-SP在提升性能和扩展能力的时候,更注重延续部署传统。
联想问天 WR5220 G5属于Birch Stream-SP平台,很好地体现了“传统”这个特点,乍看之下,其内部布局与之前几代服务器大同小异。散热器体积不大,因为SP系列的处理器功耗不超过350W。而且,处理器的封装尺寸与前几代至强可扩展处理器相同,可以追溯到第三代至强可扩展处理器——英特尔刻意让这一尺寸在跨越4代之多的处理器当中保持一致。处理器插座没有扩大,内存插槽自然也就可以继续保持在32条(双路共16通道、2DP)。对于19英寸机架而言,这也是目前内存扩展能力最好的形态。至强6的内存速率提升至DDR5 6400MT/s,还支持8000MT/s的MRDIMM。

样机的风扇墙是4个8056尺寸的双转子风扇,12V、10.7A。为了应对高性能、高密度的部署,联想问天 WR5220 G5也准备了多层次的液冷方案,可选覆盖CPU、GPU、内存,以及主板电压调节元件等热源。

强大扩展弹性
以存储支持能力为例,我们这次测试的联想问天 WR5220 G5样机配置的前窗已经完全NVMe化,更适应AI时代高性能存储的需要。样机的3组背板各有4个MCIO x8接口与主板直连,可以支持24块2.5英寸U.2接口NVMe SSD。对于前窗没有满配24块SSD的用户,还可以使用通风模块代替空闲的驱动器托架。一个通风模块可占4个2.5英寸仓位。

联想问天 WR5220 G5还可以选配E3.S 1T、E3.S 2T等形态的设备,包括SSD、CXL内存等。在使用E3.S 1T情况下,整机可支持多达48个NVMe SSD,这在2U机型中内相当罕见。对于需要大容量、低成本存储扩展的用户,联想问天 WR5220 G5还可以支持20个3.5英寸SATA/SAS硬盘,或者45个2.5英寸盘。2.5英寸U.2、E3.S、M.2等形态的存储可以混合部署。以下图为例,这是16个2.5英寸+4个E3.S 2T(x8)的形态。

PCIe扩展卡方面,联想问天 WR5220 G5可以提供18个PCIe槽,高性能的双宽卡可以在后窗安装4块,或者结合后窗、前置、中置插槽配置多达16块半高卡——在2U标准机架空间内提供这样的扩展能力还是相当惊人的。这样的PCIe扩展潜力对于机器学习、大语言模型业务整合大量AI算力与网络能力至关重要
在SATA/SAS这类传统接口方面,联想问天 WR5220 G5也考虑的比较周到。一方面,在导风罩的左、中、右三处都安排了RAID卡电池位,可以灵活地适应安装大量SATA/SAS盘的情况。另一方面,主板上预留了板载SATA控制卡的位置,对于不打算部署SAS盘的用户(典型的如NVMe SSD+SATA启动盘),这种安排可以节约Riser空间。

性能核测试
我们
分别测试了联想问天 WR5220 G5配置两种处理器(能效核、性能核)的实际表现,内存配置为16条64GB DDR5 RDIMM 6400MT/s,共1TB。
首先出场的是性能核,至强6787P,其基本规格为:
- 内核数:86
- 总线程数:172
- 最大睿频频率:3.8 GHz
- 全核睿频频率:3.2 GHz
- 处理器基本频率:2.0 GHz
- 末级(L3)缓存:336 MB
- TDP:350W

至强6787P在搭配双路16通道、1DP RDIMM时,内存速率为6400MT/s。在MLC基准测试中,联想问天 WR5220 G5测得超过741GB/s的内存带宽,是理论值的90%以上。本处理器内部的内存访问带宽约为371GB/s,跨插槽(远程)内存访问带宽近190GB/s。
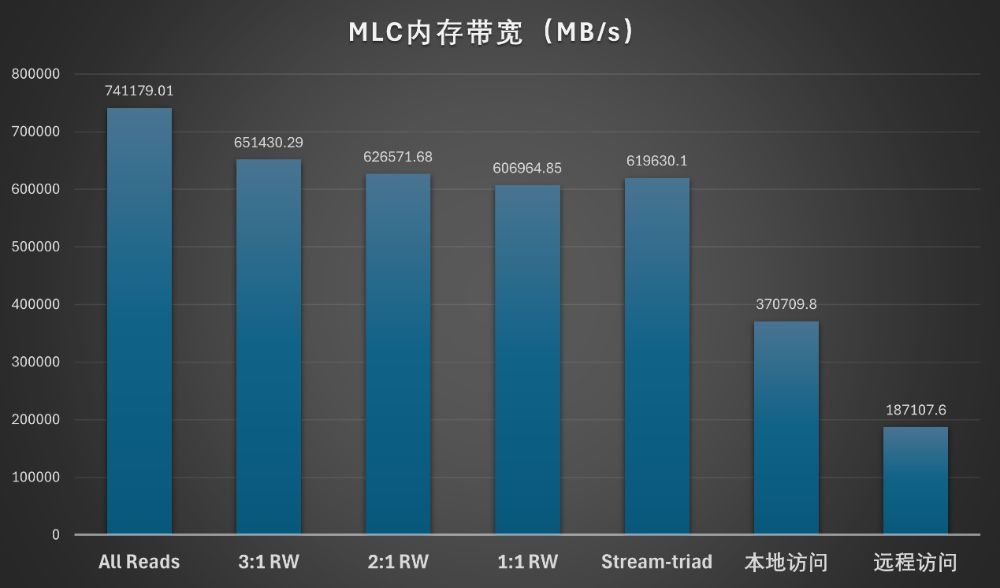
远程访问带宽主要与处理器的互联链路相关。联想问天 WR5220 G5的主板中,双路之间的UPI链接为4路。如果是Birch Stream-AP平台,可以有6路UPI,以获得更大的处理器间互联带宽。
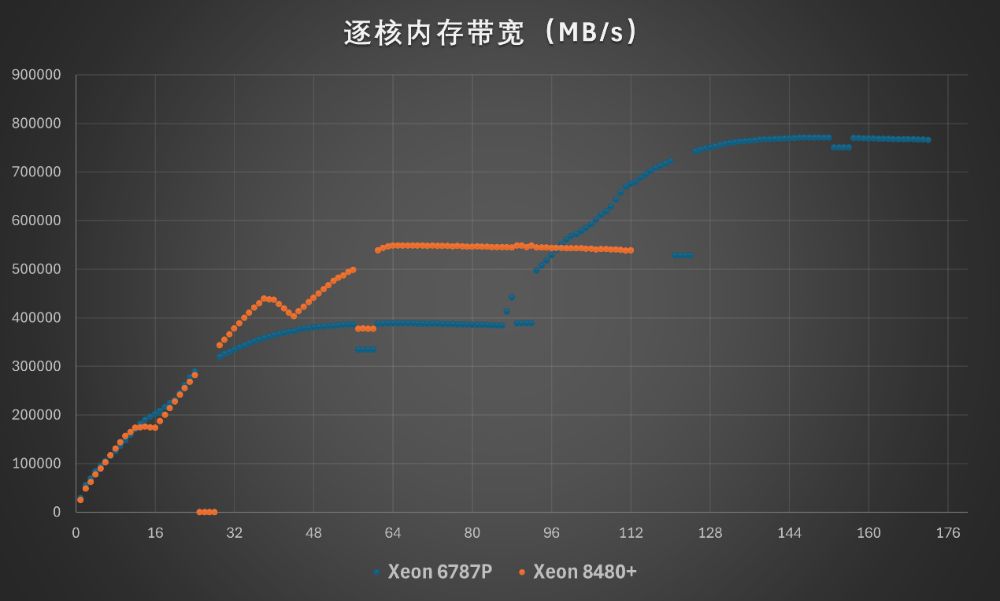
在逐核递增的内存带宽测试中,至强6787P的内存带宽增长迅速,在约48核时即可达到单路峰值,双路的内存带宽提升效率也很高。在这里我们使用了第四代至强可扩展处理器8480+的数据作为对比,可以直观的看到至强6的内存带宽和效率都有比较明显的改进。另外,至强在较低核数就能达到较高内存带宽的特点,体现了计算单元内集成内存控制器的优势。
 在计算密集型的测试,如V-Ray 3D渲染中,至强6787P可以获得19.4万分。
在计算密集型的测试,如V-Ray 3D渲染中,至强6787P可以获得19.4万分。大语言模型推理
在过去几代产品中,英特尔至强处理器逐步强化AI处理能力,以适应大数据、深度学习等应用发展的需要。从第四代至强可扩展处理器引入的AMX进一步提升了AI加速效果。至强6性能核处理器增加了内核数量、内存带宽,AMX也扩展了数据类型支持,AI性能也相应提升。我们利用系统内存容量的优势,在联想问天 WR5220 G5上部署DeepSeek-R1满血版和蒸馏版模型,均选择英特尔AMX可以支持的精度(INT8、FP16、BF16等)。其中,DeekSeek-R1 671B用的是INT8量化版,DeepSeek-R1-Distill-Qwen-32B的精度为FP16。测试只调用一颗处理器的算力。
DeepSeek满血版
在满血版、较短上下文(128Token输入,1024Token输出)情况下,提升并发数可以获得总吞吐量的持续增加。
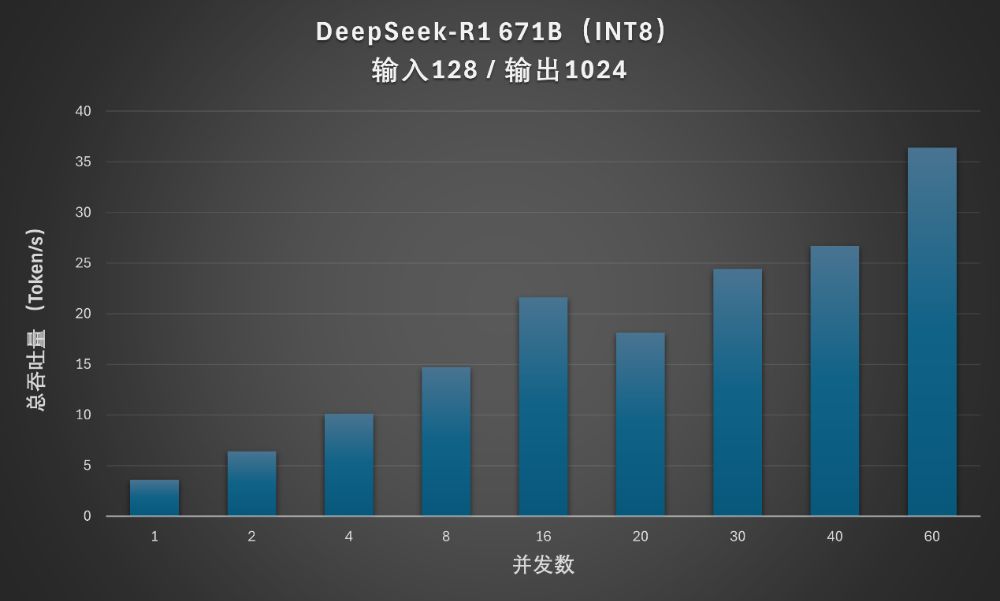 当30~40并发时,首Token输出延迟还可以控制在3秒以内。
当30~40并发时,首Token输出延迟还可以控制在3秒以内。
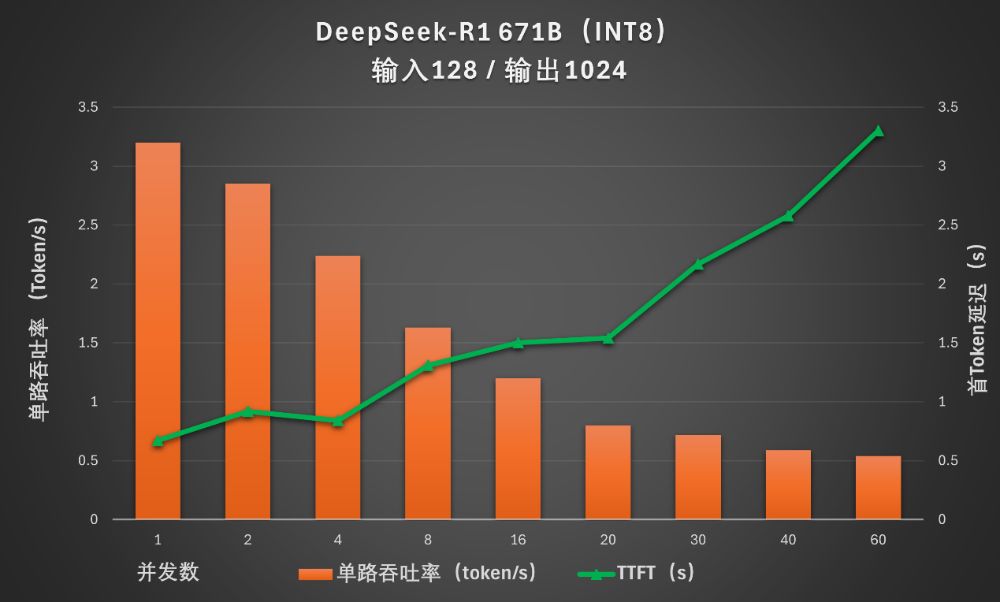
在满血版、中等输入、较长输出(128Token输入,1024Token输出)情况下,并发数提升到60时,总吞吐量的持续增加到28Token/s。
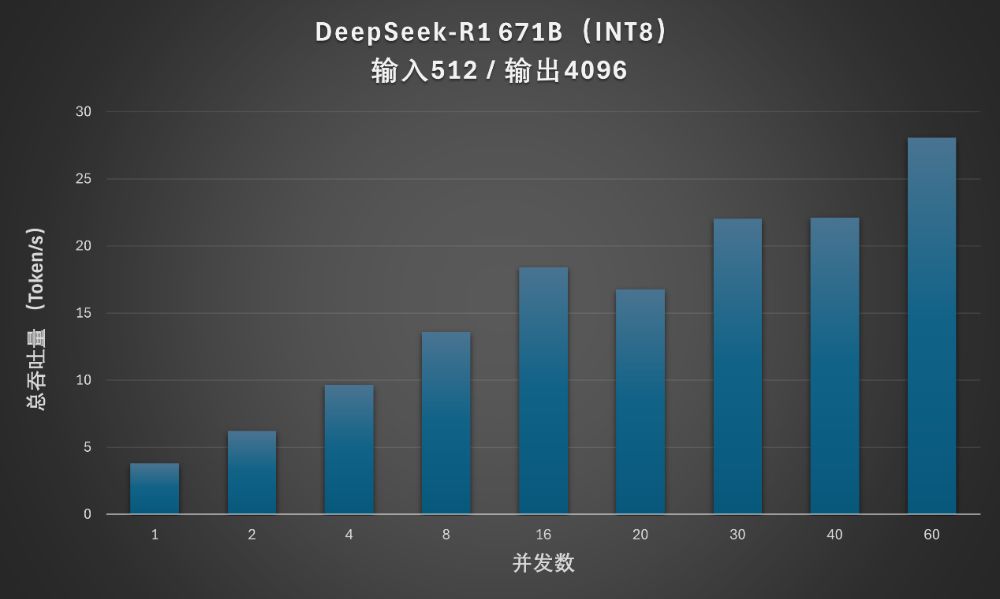
并发数在16以下时,首Token输出延迟还可以控制在2秒以内。并发数增加到20以上时,延迟变得不可接受。
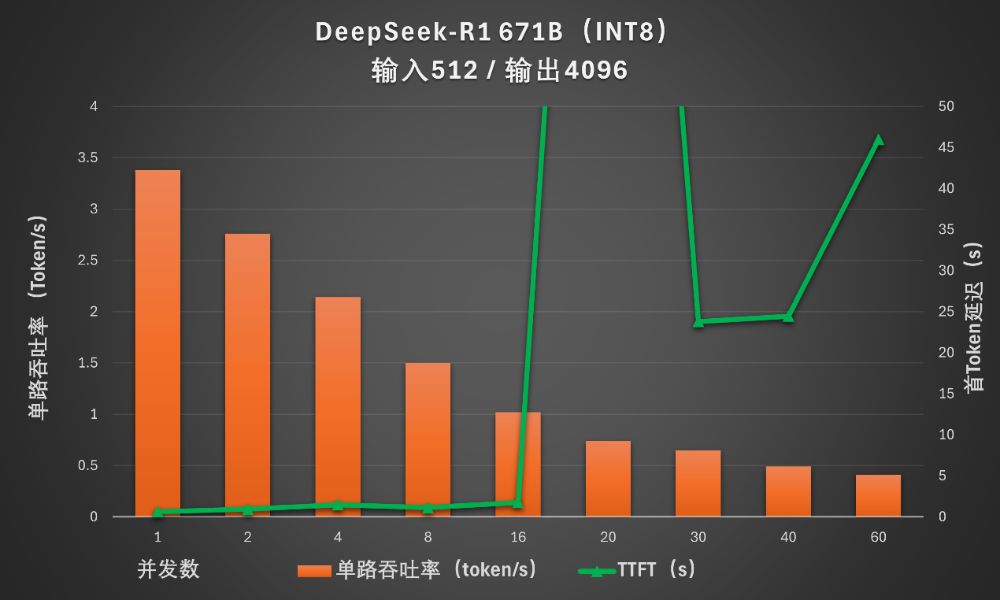
在更大规模的上下文设置下,联想问天 WR5220 G5依旧可以完全依赖单颗至强6性能核处理器跑DeepSeek-R1满血版,但首Token输出延迟会超过5秒,在这里我们就不列出具体的延迟数据了。我们将简化的吞吐量数据整理为下图:
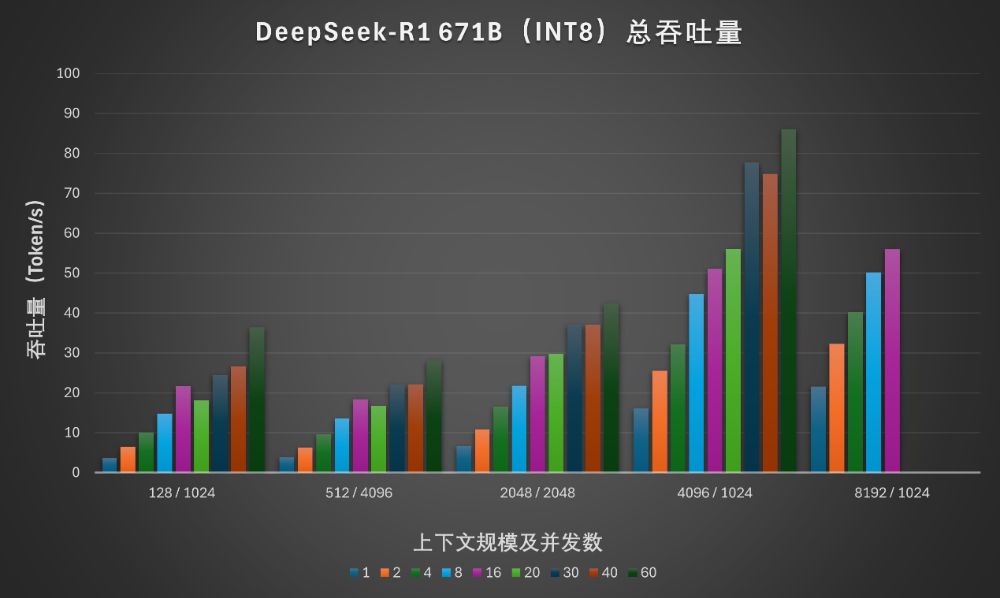
从汇总数据还可以看出,随着上下文规模提升,联想问天 WR5220 G5用纯CPU处理DeepSeek-R1满血版的总吞吐量是持续增加的,直到8192/1024才会遇到瓶颈。这体现的是大容量内存的优势:在满足置入模型权重的要求之外,还可以容纳很大规模的KV Cache,可以支持很大的上下文规模和并发规模,从而换得较高的总吞吐量。实际上,我们还曾用短上下文(输入512/输出16)、大并发(200),获得1141.93Token/s的极限吞吐量。就输出质量而言,长上下文的支持能力愈发受到重视,尤其是考虑到长思维链对上下文长度和推理质量的影响。8192的输入足够处理万字长文,如果不要求高并发和实时性,偶尔在CPU上跑跑是可行的。
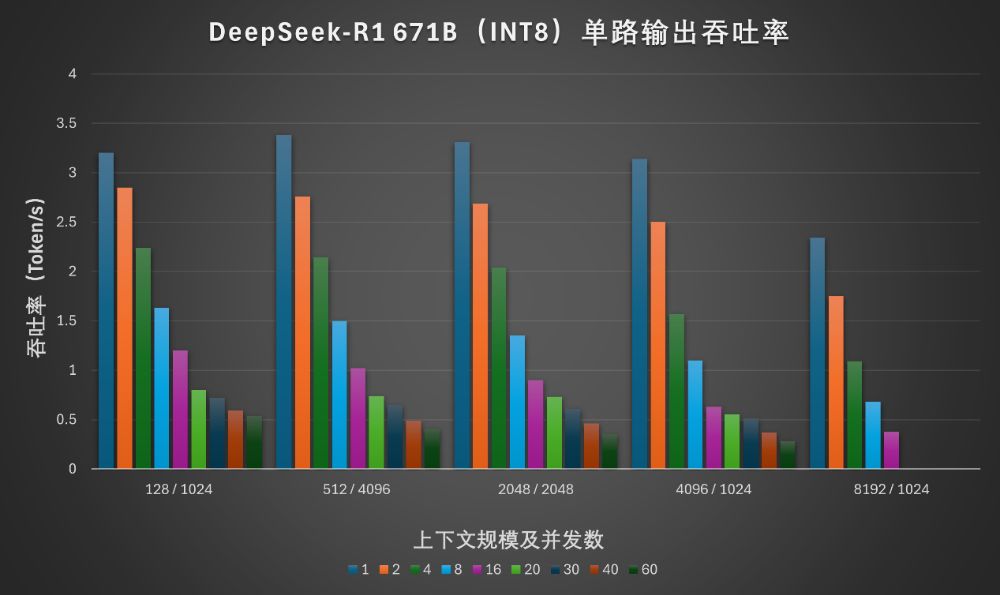
单路输出的吞吐率可以体现使用体验和实用性。对于满血版模型,纯CPU在多数上下文规模设置下,三五个并发可以提供2~3Token/s的输出,对于偶尔需要高质量推理的用户可以体验一下满血版所能带来的上限。
DeepSeek蒸馏版
联想问天 WR5220 G5用纯CPU处理蒸馏版大模型DeepSeek-R1-Distill-Qwen-32B时,在较短上下文的情况下,同样的并发数下可以获得比满血版更高的吞吐量。在30并发下,可以得到超过83 Token/s的水平。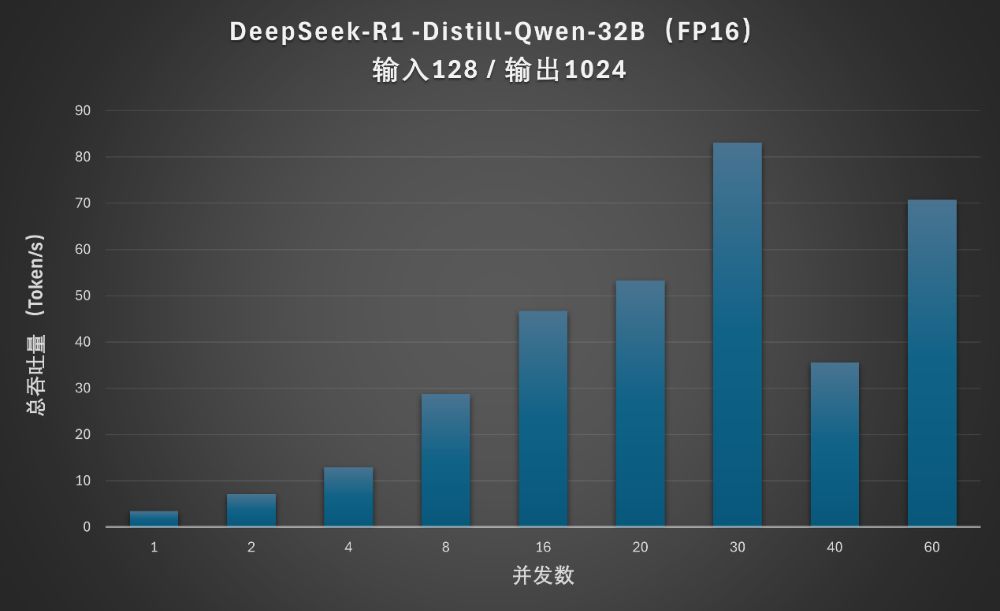
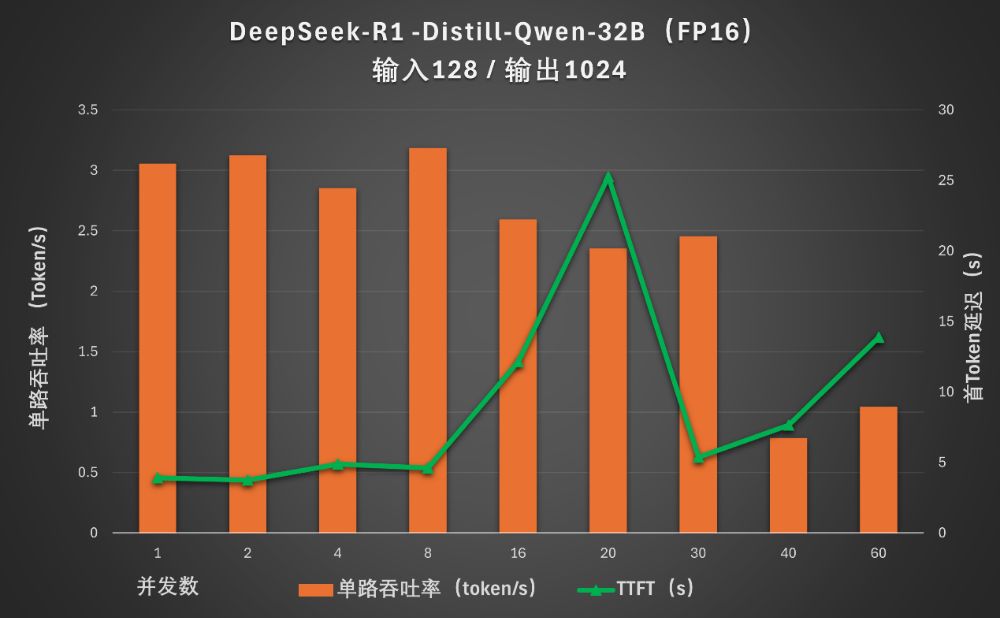
但蒸馏版模型的输出延迟较大,并发数8时也接近5秒。在并发数低于8的情况下,平均每个会话每秒可以输出3个Token,跟人类的阅读速度还是匹配的。
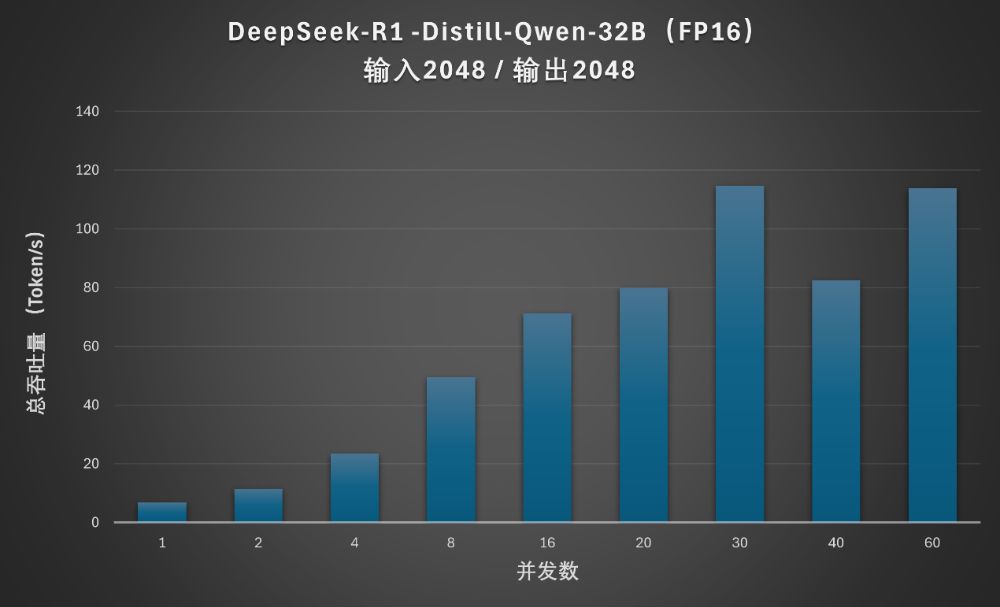
当上下文长度增加到各2048Token时,至强6787P依旧可以输出较高的总吞吐量,60并发时大约114 Token/s。
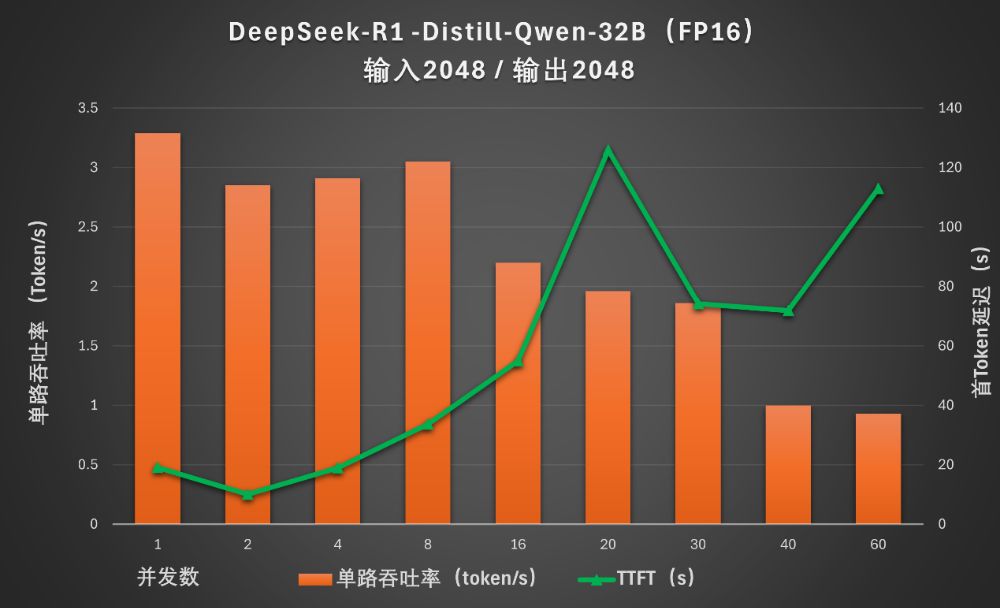
但这种上下文设置下,首Token延迟会超过10秒。到8个并发时,延迟超过了30秒,但每个会话还能保持在每秒3个Token左右的水平。
我们将各种上下文规模和并发数的总吞吐量汇总为下图。单颗至强6性能核处理器跑DeepSeek-R1的32B蒸馏版可以获得超过200Token/s的吞吐量。
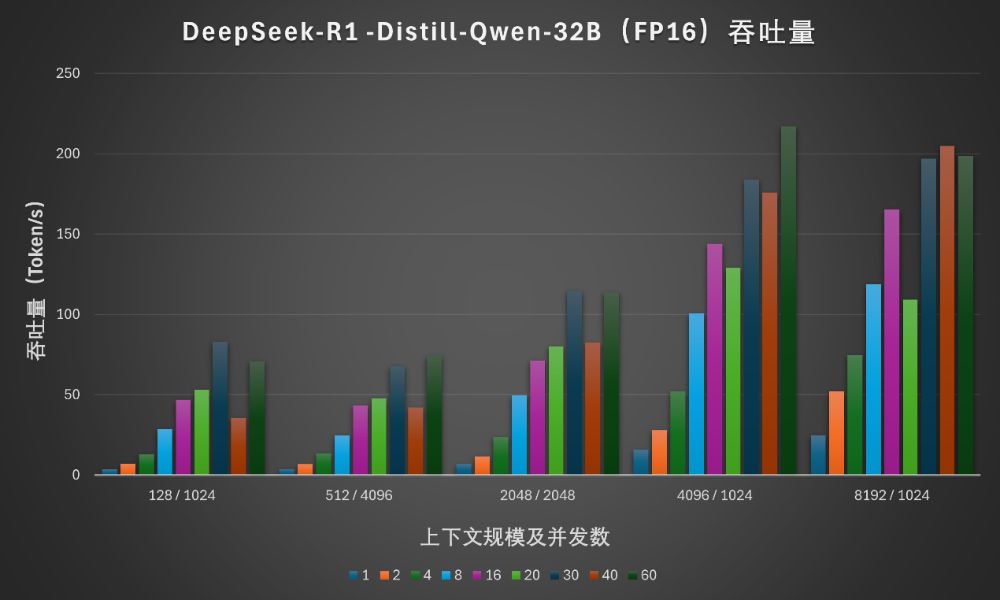
对于较短的上下文,30并发下的单路输出吞吐率是可以接受的。中等规模上下文适宜的并发数在20以内。
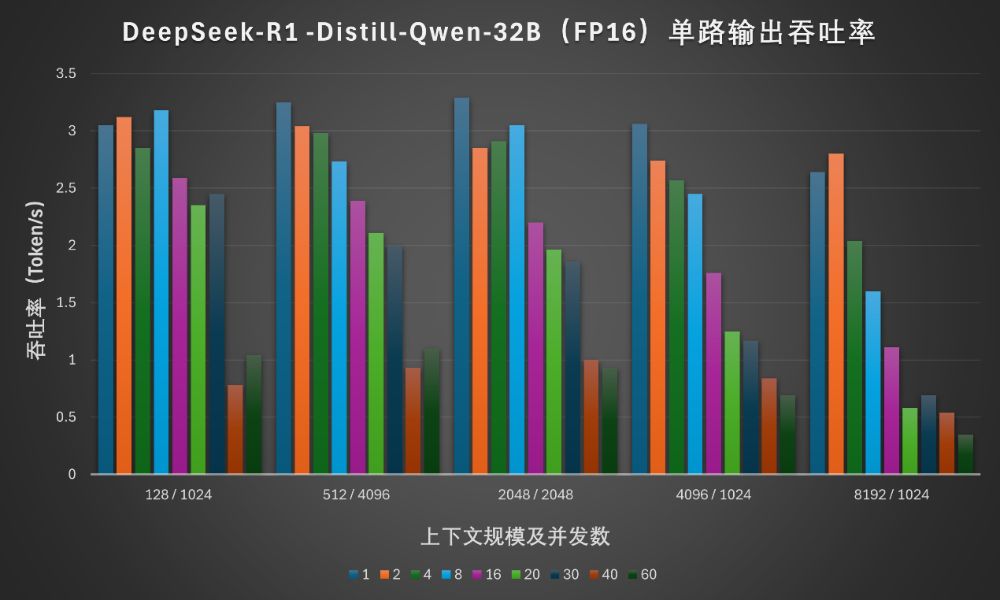
对于32B模型,纯CPU在多数上下文规模设置下,16并发以内,可以提供2~3Token/s的输出,基本上可以满足正常阅读速度的需要。较短的上下文规模甚至可以让30并发也有可用性,也能满足中型企业的需求。影响这项指标(底线)的主要因素是内存/显存的带宽。至强6在内存带宽上的提升在前面的基础测试当中已经可以直观看到。
在通常的概念中,大语言模型的推理任务并非CPU的强项,效费比无法与GPU、NPU相比。但是,纯CPU推理具有大容量内存的优势,可以跑超大规模的模型,在较低的并发数下也可以提供实用的体验。对于更小规模的模型,可以提供的吞吐量(主要影响并发数)还会更高。
因此,对于AI应用并非高频需求的用户,可以在至强6性能核上混合部署传统业务和实时性要求不高的AI业务——毕竟我们的测试只使用了至强6性能核的部分算力。在真正应用环境中,混合、弹性部署是很典型的。
能效核测试
我们在联想问天 WR5220 G5上测试的能效核处理器是至强6780E。
- 内核数:144
- 总线程数:144
- 最大睿频频率:3.0 GHz
- 处理器基本频率:2.2 GHz
- 末级缓存:108 MB
- TDP:330W
至强6能效核的优势领域是云原生、微服务等应用,用于替换老旧服务器平台,以更高的部署密度、更好的能效来改善TCO。因此,我们使用基于Whitley平台的同类型服务器进行对比测试,参考平台的处理器为至强银牌4310。
- 内核数:12
- 总线程数:24
- 最大睿频频率:3.30 GHz
- 处理器基本频率:2.10 GHz
- 末级缓存:18 MB
- TDP:120W
将不同代的联想服务器摆在一起时,我们也可以直观看到继承与发展。从继承的角度,二者的布局,包括风扇墙和处理器、内存区域都比较近似,运维习惯相同。从发展的角度看,二者的扩展能力差异很大:图左参考平台的前窗是典型的以3.5英寸硬盘为主的布局,驱动器数量少,线缆也不多;而图右的联想问天 WR5220 G5前窗选配可支持24个NVMe SSD,相应的也需要更多的MCIO线缆。

处理器方面,我们的对比测试主要关注的不是绝对性能的落差,而是能效的改进。
在BenchSEE中,联想问天 WR5220 G5搭配的至强6780E的处理器性能功耗比为635.7,是第三代至强可扩展处理器的4倍;内存的性能功耗比差距接近2倍。
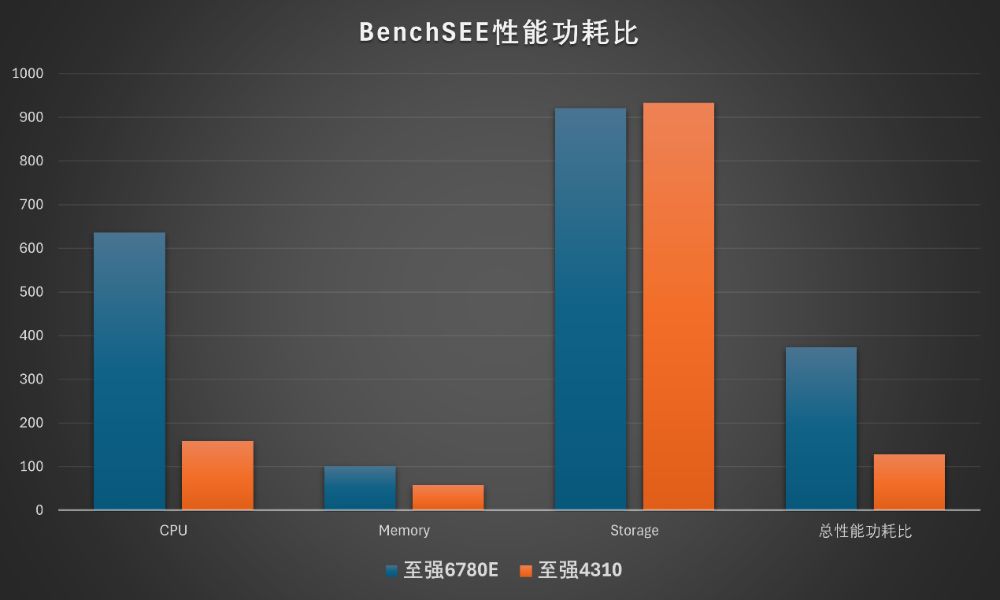 如果具体看性能测试的子项,能效差异最大的是加密,尤其是SHA256,有七八倍的优势。虽然至强6能效核削减了AVX512,但还是针对AES做了强化,测试结果比预期还要好。
如果具体看性能测试的子项,能效差异最大的是加密,尤其是SHA256,有七八倍的优势。虽然至强6能效核削减了AVX512,但还是针对AES做了强化,测试结果比预期还要好。

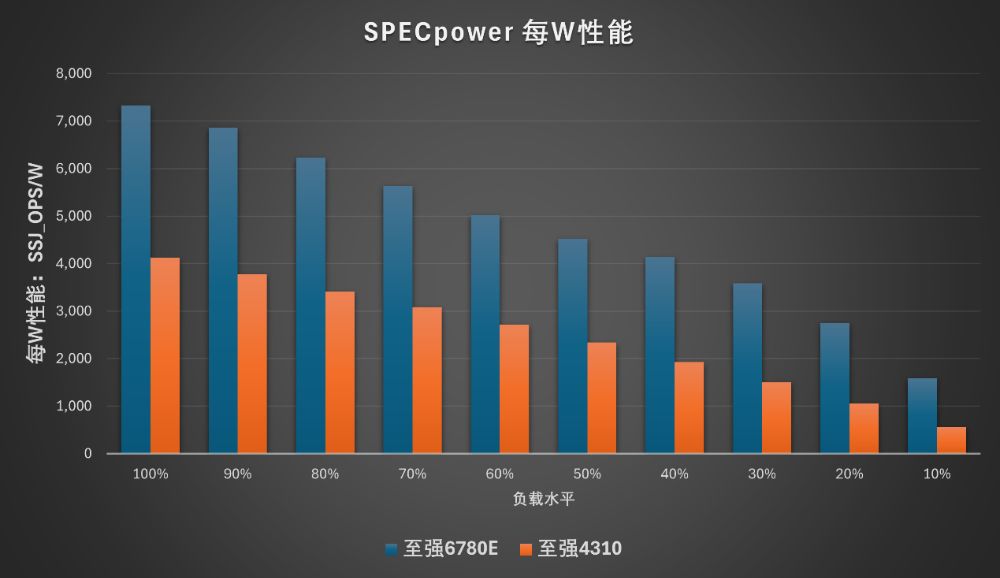
SPECpower测试主要用于评估Java应用的功耗情况,对网站、云服务很有代表性。在这个项目中,配备双路6780E的联想问天 WR5220 G5满负荷功耗为950W,可以提供近7百万ops,平均每瓦性能超过7300ops。参考平台满负荷功耗在400W左右,虽然是新平台的一半不到,但性能只有四分之一左右,能效明显不如基于至强6能效核的新平台。
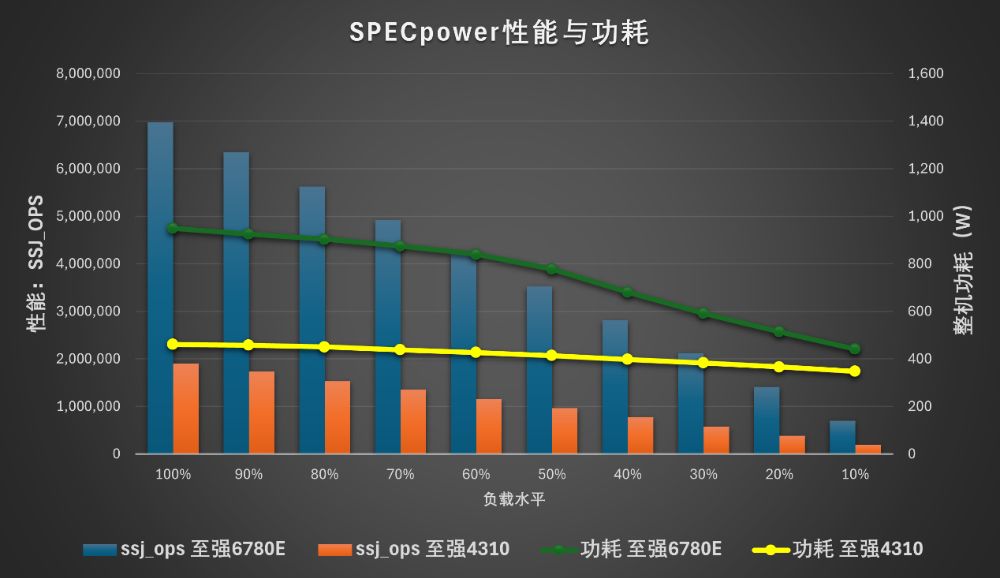
除了满负荷,在较低负荷下,联想问天 WR5220 G5的整机功耗会有比较明显的下降,在10%负荷时的功耗只有442W,不到满负荷时的一半,只比参考平台高不到100W,但提供的性能却是参考平台的3.5倍以上。换句话说就是,在较低负荷下,联想问天 WR5220 G5的能效相对参考平台的优势更大:从满负荷的约1.8倍,提升到10%负荷的近3倍。
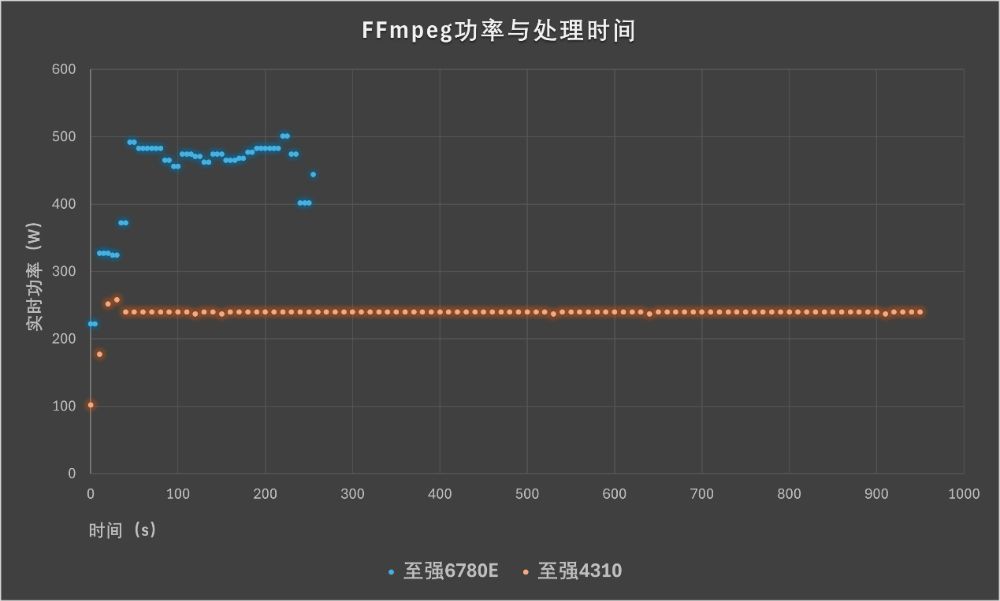
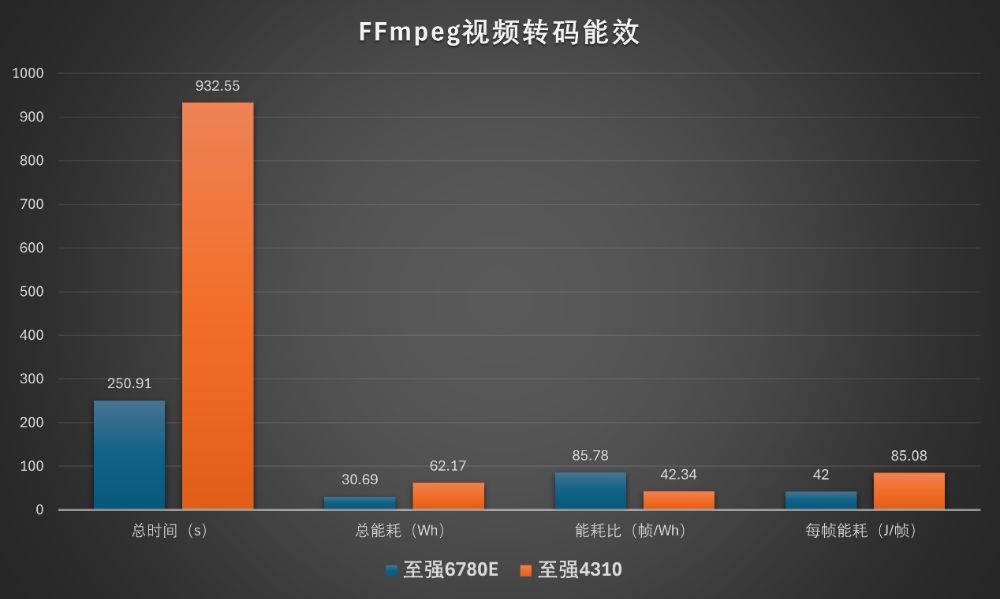
我们使用FFmpeg考察通用服务器在媒体处理方面的表现。联想问天 WR5220 G5处理4个FFmpeg视频编码任务用时约250秒,平均功耗仅442W,而参考平台用时超过了930秒。新平台用不到两倍的能耗,在约四分之一的时间内完成任务,这意味着相同工作量的总能耗还不到老平台的一半。
我们将具体的数据按总时长、总能耗、单位能耗,以及能效比,分别整理为柱状图,也可以比较直观地看到新老平台的效能差异。
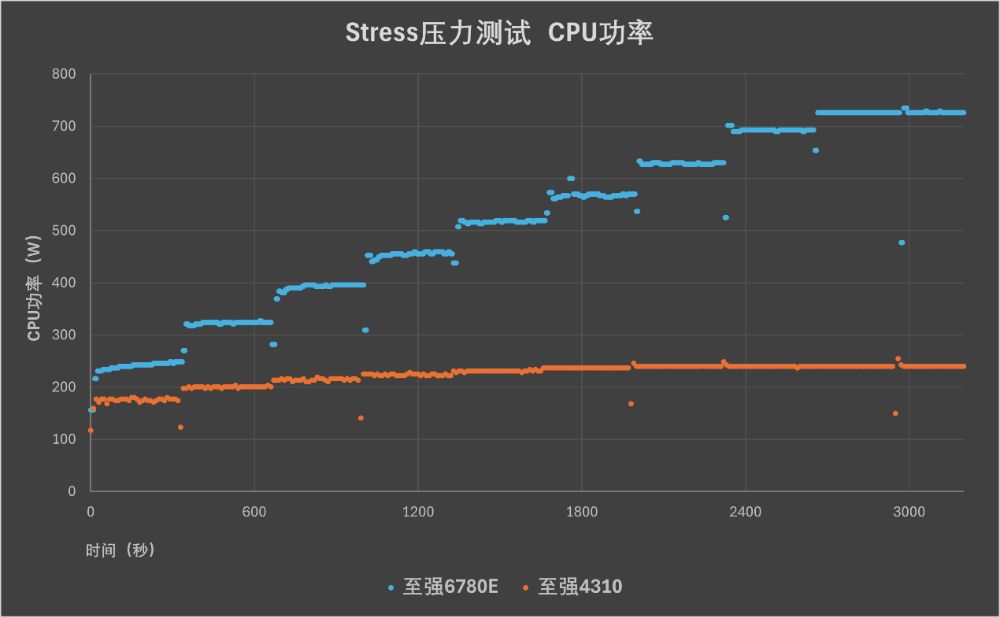
极限功耗方面,通过Stress进行压力测试中,WR5220 G5满负荷下处理器功耗可达726W,与双路至强6780E的TDP(350W×2)基本相符。更重要的是,通过至强6能效核处理器和第三代至强可扩展处理器的对比,我们可以发现至强6780E随着负荷的变化会积极的调整功率,峰谷落差更为明显——这与我们在SPECpower中观察到的情况是类似的。
整机功率角度看,联想问天 WR5220 G5满负荷下的功率约1100W,在任务调整瞬间会出现尖峰,峰值近1400W。在低负荷和闲置状态下,联想问天 WR5220 G5的整机功率与参考平台差不多。
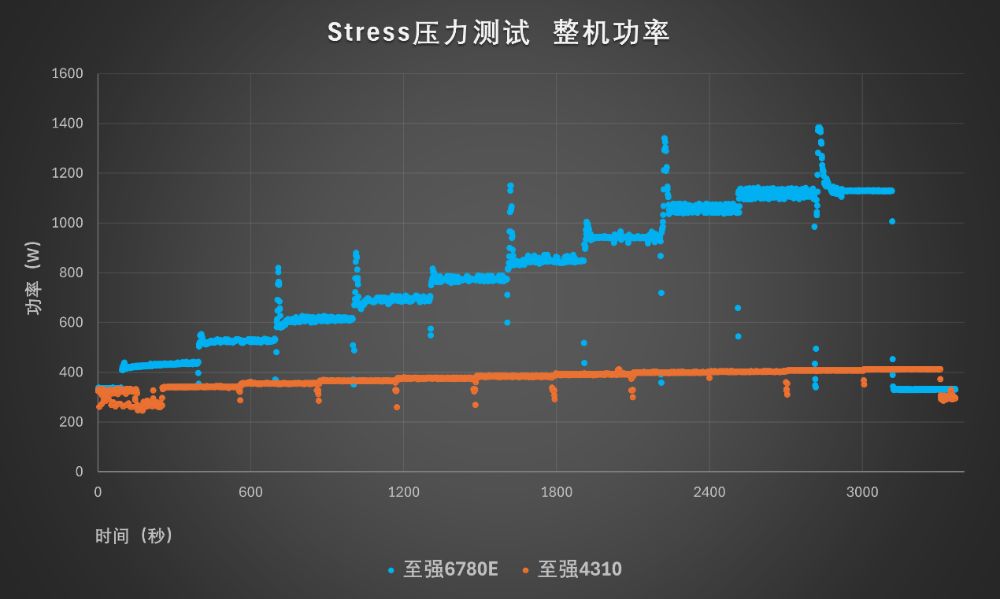
从资产折旧角度考虑,目前第二、第三代至强可扩展处理器平台已经进入替换周期,对于运行于这类通用服务器平台上的网站、微服务、非结构化数据库传统业务,至强6780E提供了更高的性能密度、更好的能效,可以节约机架空间,提升TCO表现。
结语:
联想问天 WR5220 G5的布局、散热要求、内存扩展都贴近传统通用服务器的运维习惯,在提供丰富PCIe扩展适应SSD、加速卡、高速网卡等外设发展的同时,也兼顾传统接口,高弹性设计可帮助用户平滑过渡。
新一代至强6平台在计算密度、内存性能上都有数倍的成长。联想问天 WR5220 G5在搭配至强6性能核处理器时,可以满足仿真分析、大数据等成熟业务对算力的需求,也可以满足AI推理、结构化数据库为代表的新兴应用需求。通过混合部署AI与传统算力密集型业务,可以带来很好的业务弹性,以适应不同类型用户带来的峰谷差异。在部署至强6能效核处理器时,则更强调在性能和扩展性方面的倍数级增效,进而实现明显的降本,可谓多、快、好、省。