无源域自适应综合研究【3】
一、研究背景与问题
- 域适应的意义:在深度学习中,模型在源域(有标签数据)训练后,应用到目标域(无标签数据)时,常因数据分布差异(域偏移)导致性能下降,无监督域适应(UDA)旨在解决这一问题。
- 无源源域适应的必要性:传统UDA依赖源域数据,但实际中源数据可能因隐私保护、存储成本、计算负担等无法获取,因此需要SFUDA方法——仅通过预训练的源模型和无标签目标数据实现知识迁移。
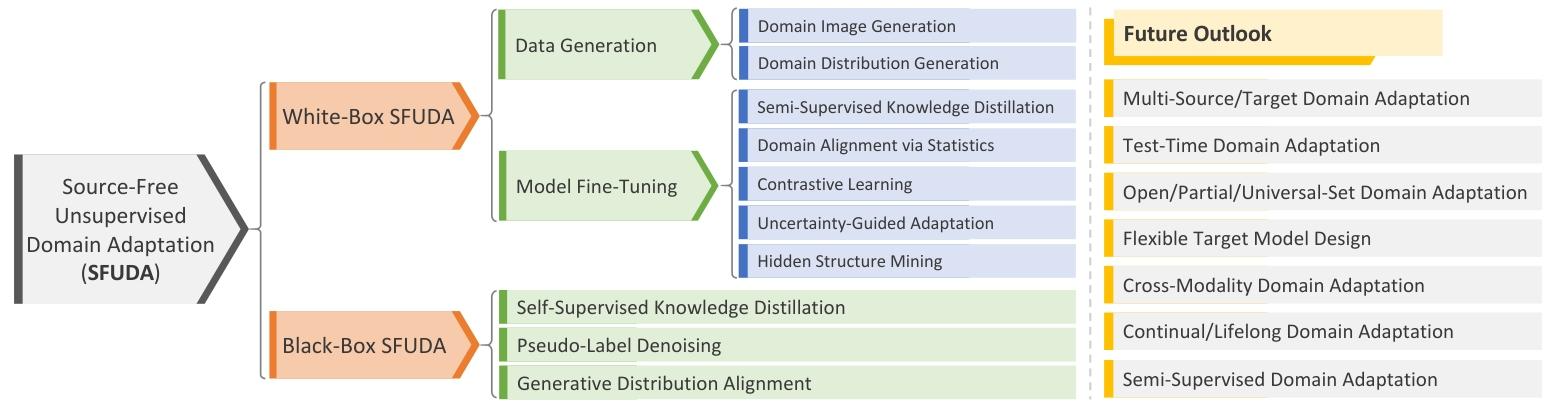
二、SFUDA的分类框架
论文将SFUDA方法分为白盒 和黑盒 两大类,核心区别在于是否可访问源模型的参数:
- 白盒SFUDA:可获取源模型参数,通过生成伪源数据或微调模型实现适应。
- 黑盒SFUDA:仅能通过API调用源模型(无法访问参数),通过知识蒸馏或伪标签优化实现适应。

三、白盒SFUDA方法
白盒方法进一步分为数据生成和模型微调两类:
1. 数据生成方法
通过生成类源数据(模仿源域分布),再应用传统UDA技术,具体包括:
- 域图像生成:
- 基于批归一化(BN)统计量迁移:利用源模型中存储的BN均值和方差,生成保留目标内容但具有源域风格的图像。
- 替代源数据构建:从目标域中筛选高置信度样本作为伪源数据,缩小域差距。
- 基于GAN的生成:通过GAN生成类源数据,结合对抗学习对齐域分布。
图3 噪声(Noise)与目标域数据经源模型分支处理,利用 BN 统计量对齐源与目标域特征分布,生成类源数据;再基于这些数据执行 UDA,缩小跨域差异。
注意:“Noise” 不是狭义的 “噪声干扰”,更偏向 “初始随机输入” ,常见形式:随机向量(如服从高斯分布的低维向量 )或随机初始化的图像块(像素值随机的低分辨率图像 )
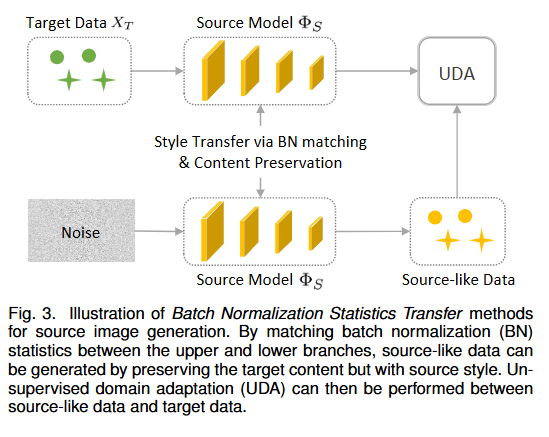
图4 代理源数据构建:从目标域数据里筛选样本,构建代理源数据(Surrogate Source Data) ,模拟源域数据分布(比如选与源域风格 / 特征相似的目标样本 )。
UDA 适配:用构建好的 “代理源数据” 替代真实源数据,执行标准无监督域适应(UDA) ,缩小与目标域的差异。
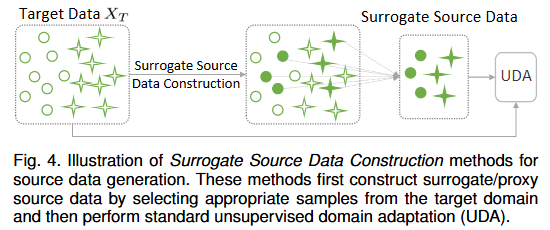
图5 核心流程:用噪声 + 预定义标签(Pre-defined Label)输入 GAN 生成器,生成类源数据;再将生成数据与目标域数据输入无监督域适应(UDA)模块.同时生成数据经源模型计算交叉熵损失做约束,实现跨域适配。
作用:在无真实源数据时,借 GAN 生成模拟源域的数据,结合 UDA 和损失函数,让模型在 SFUDA 场景下迁移知识,是 “生成式数据补充 + 域适应” 的典型策略。
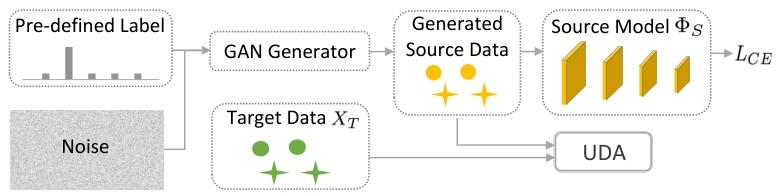
小结:代理源数据构建方法总体上优于基于gan的生成器。基于gan的方法恢复的源数据通常存在模式崩溃问题(模式崩溃指的是生成器生成的数据过于单一,只覆盖了真实数据分布中的一小部分模式,无法生成多样化的输出。),导致图像质量低
- 域分布生成:不直接生成图像,而是对齐源与目标域的特征原型或分布(如高斯混合模型GMM)。
2. 模型微调方法
直接微调预训练源模型,利用目标域无标签数据进行自监督学习,包括:
- 自监督知识蒸馏:通过师生网络(如mean-teacher策略)保留源知识并适应目标域。
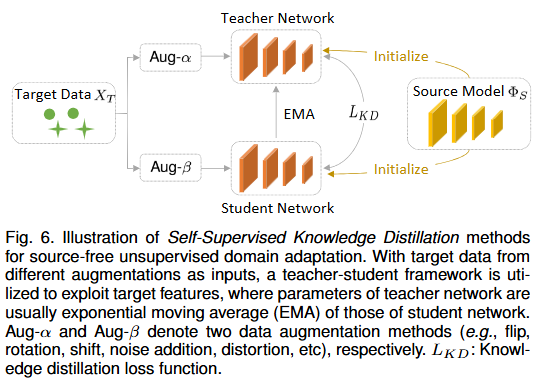
- 初始化师生网络:用预训练好的源模型初始化教师网络,学生网络单独初始化,构建师生框架 。
- 目标数据增强:对目标域数据执行两种不同的数据增强操作,得到两组增强后的数据。
- 知识传递与蒸馏:增强后的两组数据,分别输入教师网络和学生网络;通过计算知识蒸馏损失,约束学生网络的输出与教师网络对齐,让学生网络 “模仿” 教师网络的预测模式,间接学习源域知识 。
- 核心逻辑:借 “数据增强 + 师生蒸馏”,在无真实源数据时,把源模型(教师)的知识,迁移到目标域的学生模型中,区分师生,不是 “重复初始化”,而是 “让模型在传承源域知识的同时,适配目标域” —— 老师当 “知识锚点”,学生当 “创新适配器”,分工实现。【Chen等人[23]首先根据计算损失将目标数据划分为干净和有噪声的子集,并将其视为标记和未标记的示例,然后利用平均教师技术为未标记的目标数据自生成伪标签以进行领域适应。】
SFUDA 场景下的跨域知识迁移 。 - 统计域对齐:利用预训练源模型中存储的批量统计数据来近似不可访问源数据的分布,然后通过减小源域与目标域之间的分布差异进行跨域自适应。
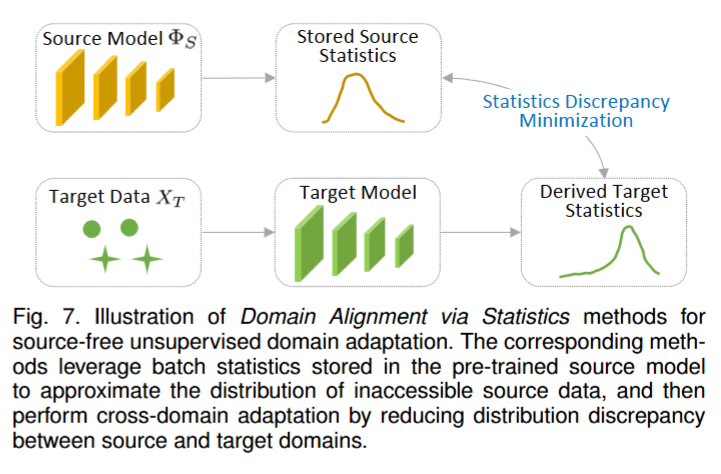
- 从源模型中提取存储的 “源域统计量”(如 BN 层的均值、方差 ),作为源域分布的 “近似替身”。
- 用目标域数据训练目标模型,推导目标域的统计量。
- 通过最小化统计量差异,让目标域统计量向源域统计量对齐,缩小跨域分布差异。
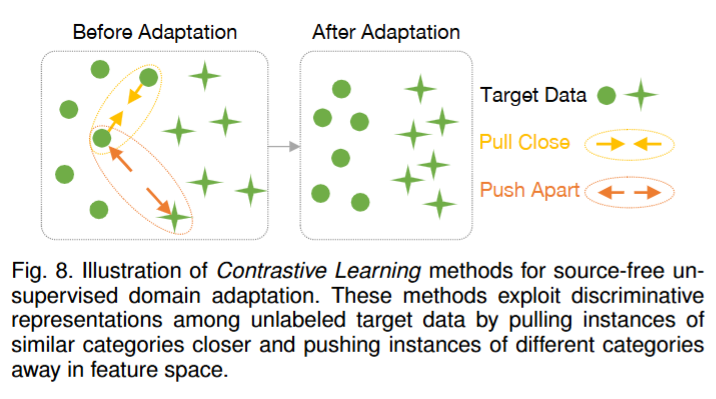
- 对比学习:主要思想是在特征空间中拉近同类样本、推远异类样本,增强判别性。
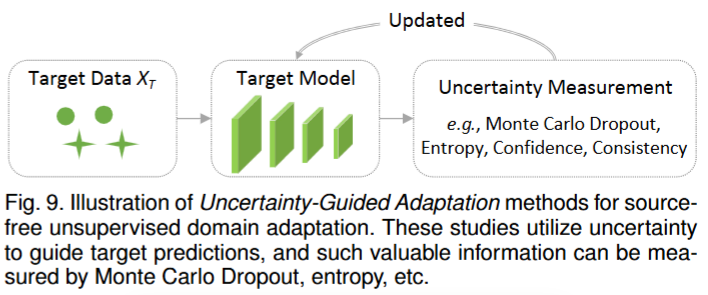
- 不确定性引导适应:模型输出经不确定性度量(Uncertainty Measurement)模块处理,通过如蒙特卡洛 dropout、熵、置信度、一致性等方法评估不确定性,再依据结果更新目标模型,实现自适应优化 。去除噪声伪标签。【蒙特卡罗 Dropout 】
- 隐藏结构挖掘:考虑了目标域的内在特征结构,并通过聚类感知伪标签来更新目标模型。利用目标域的聚类结构,通过伪标签迭代优化模型。
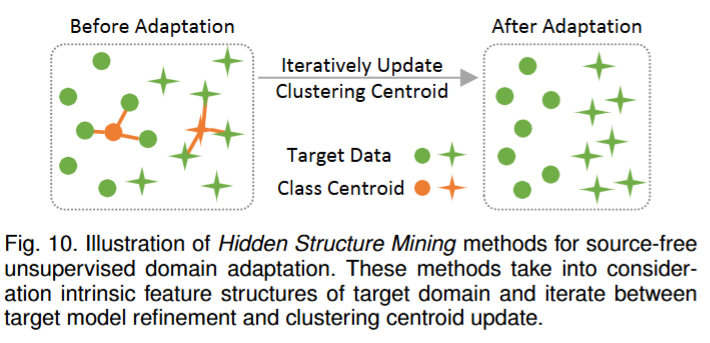
小结:1.对比学习,可能并不适合语义分割。 2.数据生成方法可以与模型微调方法结合使用。例如,可以首先通过选择适当的目标样 本生成虚拟源域,因此可以应用标准的无监督域自适应框架。为了进一步利用目标信息,考虑目标样本的几何结构并生成相应的目标伪标签来微调目标模型。这两个步骤可以迭代优化,帮助生成更具代表性的源域,并细化目标模型。
四、黑盒SFUDA方法
黑盒方法无法访问源模型参数,主要通过源模型输出(如预测概率)实现适应,包括:
- 自监督知识蒸馏:通过师生框架(教师为源模型,学生为目标模型)强制输出一致性,迁移知识。【伪标签去噪方法的性能不如自监督知识蒸馏方法】
- 伪标签去噪:修正源模型对目标域的噪声预测(如动态阈值筛选可靠标签)。
- 生成分布对齐:通过变分自编码器等生成源域分布的近似,实现域对齐。【不太适合于语义分割任务】
五、关键对比与策略
- 白盒vs黑盒:
- 白盒性能更优(可挖掘更多源知识),但存在隐私泄露风险;黑盒隐私性更好,但性能可能受限。
- 白盒需共享模型架构,黑盒可灵活设计轻量目标模型,适合低资源场景。
- 提升泛化性的策略:
- 熵最小化:降低预测不确定性,鼓励置信输出。one-hot 编码是将每个类别用一个只含有 0 和 1 的向量来表示,向量的长度等于类别的总数。
- 多样性损失:避免预测标签偏向多数类。【早期学习、稳定性、局部平滑、混合等正则化策略,分别从防过拟合标签噪声、稳参数、提鲁棒性、减噪声影响等方面助力模型优化。】
- 标签平滑:将硬标签转为软标签,防止源模型过自信。
六、未来方向
- 多源/多目标域适应:利用多个源域的互补信息,或适应多个目标域。
- 测试时适应:在推理阶段实时适应目标域,无需预收集目标数据。
- 开放/部分/通用集适应:处理源与目标域标签空间不一致的场景(如目标域包含新类别)。
- 跨模态适应:如从CT到MRI的医学影像迁移,或图像到视频的跨模态任务。
原文题目:Source-Free Unsupervised Domain Adaptation: A Survey请大家自行搜索阅读原论文