HashMap(JDK1.7、JDK1.8)原理与结构分析与synchronizedMap()
目录
一、HashMap。
jdk1.7。
jdk1.8。
6个核心常量。(控制底层结构)
hash计算(二次hash)。下标计算。(hash&(容量-1))
初始容量。链表与红黑树间转换条件。
扩容机制。(核心)
二、线程安全的HashMap?(synchronizedMap)
一、HashMap。
jdk1.7。
- JDK1.7:底层是数组 + 链表(Entry 数组)。
- 可以看源码(之前是Entry对象)Node对象。(我看的这个是jdk21,也就是jdk1.8后)
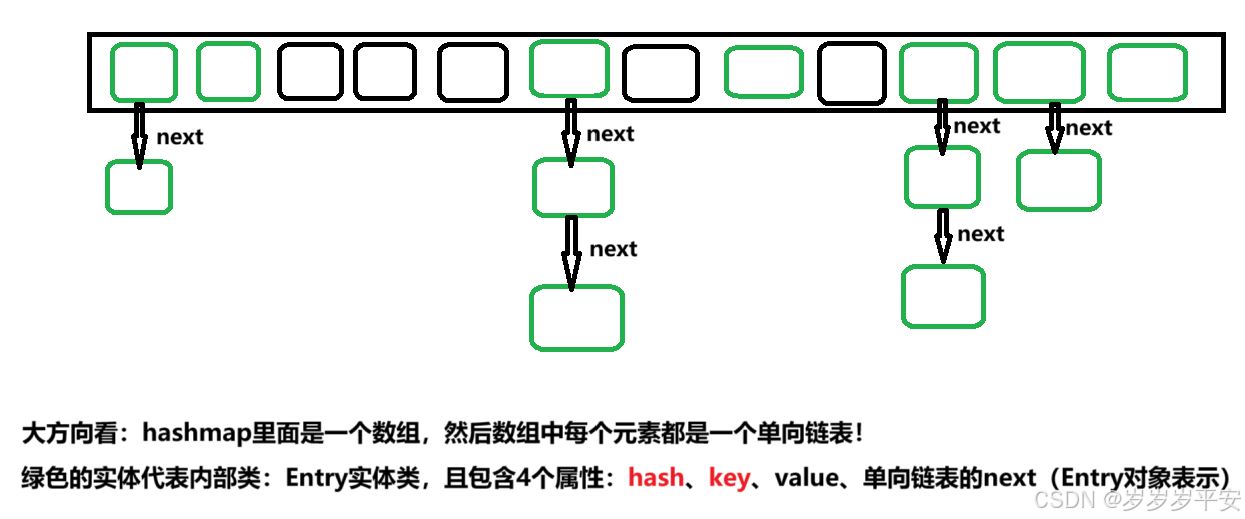
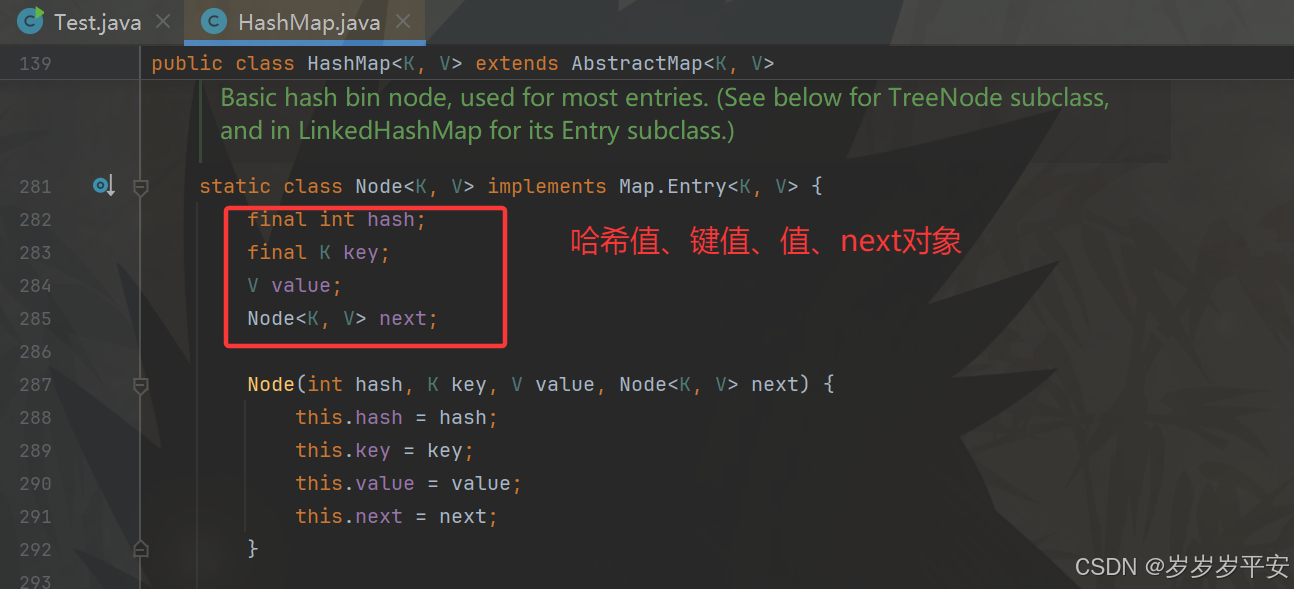
jdk1.8。
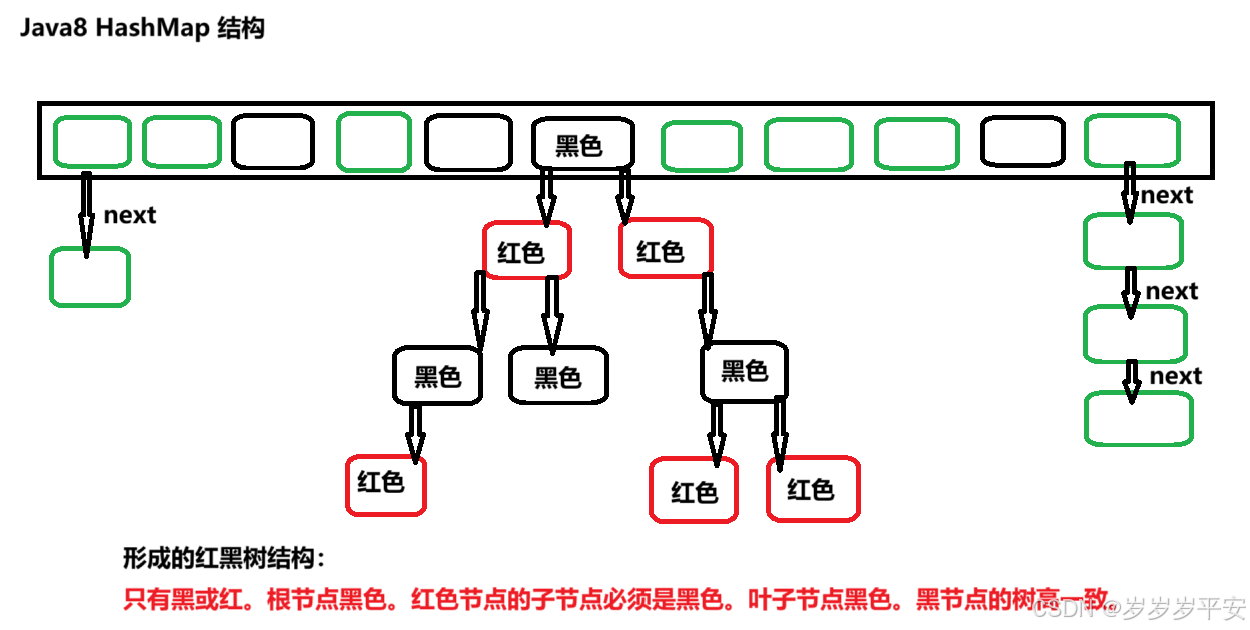
- JDK1.8:底层是数组 + 链表 + 红黑树(Node 数组。链表长度达标后转为红黑树)。
6个核心常量。(控制底层结构)
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;- 设定 HashMap 底层数组默认初始容量为16,且容量必须为 2 的幂。
static final int MAXIMUM_CAPACITY = 1 << 30;- 限制 HashMap 底层数组最大容量为2³⁰。受 int 类型存储范围制约,避免容量过大超出合理范围。
static final float DEFAULT_LOAD_FACTOR = 0.75f;- 默认负载因子大小。当已存元素数超过 “当前数组容量 × 负载因子” 时,触发数组扩容,平衡空间与查询效率。
static final int TREEIFY_THRESHOLD = 8;- 链表转红黑树的阈值。当链表元素数多于 8 时,将链表转换为红黑树,优化查询性能(红黑树查询复杂度更低 )。
static final int UNTREEIFY_THRESHOLD = 6;- 红黑树转链表的阈值。当红黑树中元素数少于 6 时,红黑树转回链表,因元素少时长链表查询也较高效,且转换成本低。
static final int MIN_TREEIFY_CAPACITY = 64;- 最小树形化数组容量。若数组(桶)数量小于 64,即便链表元素数超 8,也先扩容而非转红黑树。因小容量数组扩容成本低,能减少哈希冲突 。
hash计算(二次hash)。下标计算。(hash&(容量-1))
- hash计算的过程直接看源码。
- HashMap不会直接使用key对象的 hashCode() 返回值作为哈希值!而是对其进行了二次哈希处理,这样做的目的是让哈希值更加均匀地分布,减少哈希冲突。
- 首先判断key是否为null,如果key是null,直接返回哈希值:0。
- 如果key不为null,获取key的 hashCode() 值赋值给变量h,然后将h的高 16 位与低 16 位进行异或(^)操作,得到最终的哈希值。
初始容量。链表与红黑树间转换条件。
- 数组初始容量默认是16,但如果通过构造方法 new HashMap(int initialCapacity) 指定初始大小时,HashMap会自动将其调整为最近的2的幂次方(如:指定10,实际初始容量是16)。
- 数组的容量必须是2的幂次方!才能通过:key的hash值&(容量-1) 计算下标(等价于取模运算,但效率更高)。
链表转红黑树触发条件(JDK1.8):
- 链表长度 > 8(即第 9 个元素插入时);
- 数组容量 > 64。
- 若数组容量≤64,即使链表长度 > 8,也会先优先扩容数组,而非转红黑树。(因为小容量数组扩容成本更低,且能减少冲突)。
- 红黑树转链表:当红黑树节点数 ≤6 时,会退化为链表(避免频繁转换的性能消耗)。
- 红黑树查找、插入、删除时间复杂度均为 O (logn),优于长链表的 O (n)。

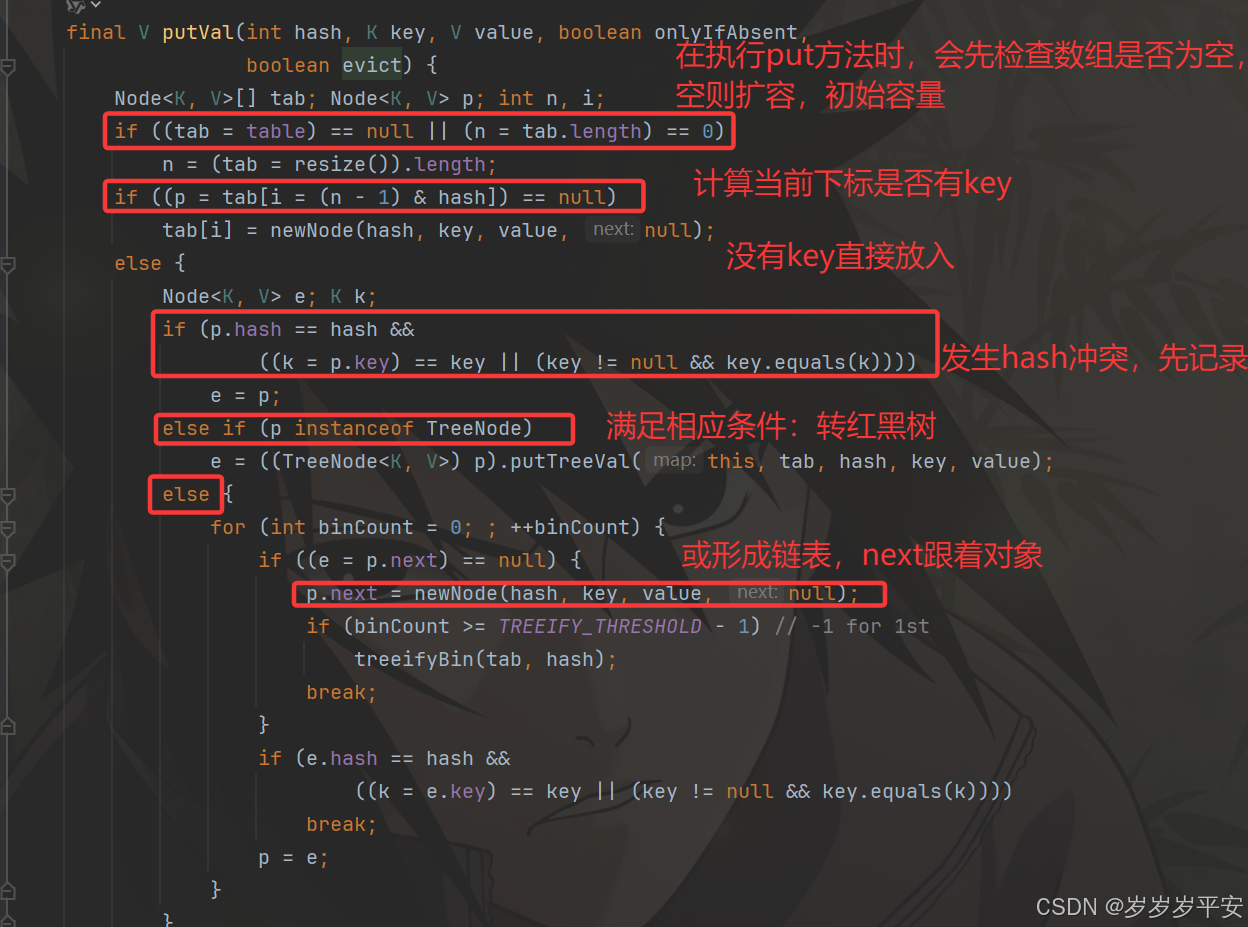
扩容机制。(核心)
- 扩容(resize)是当元素数量(size)超过 容量 × 负载因子(默认 0.75) 时触发,新容量为原容量的 2 倍(保证仍是 2 的幂次方)。
- jdk1.7。
- 需要重新计算哈希(rehash)。对每个节点的 key 重新计算 hash 值,再通过 hash&(新数组容量-1) 得到新下标。
- 链表插入顺序:采用头插法(新节点插入链表头部),可能导致多线程扩容时出现链表环(死循环)。
- jdk1.8。
- 无需重新计算 hash。利用容量是 2 的幂次方的特性,通过 原hash值&原数组容量 判断节点位置:
- 结果为 0:下标不变。
- 结果非 0:下标 = 原下标 + 原容量。
- 链表插入顺序:采用尾插法(保持原链表顺序),避免了 JDK1.7 的链表环问题。
- 红黑树处理:扩容时会将红黑树拆分为两个链表(或红黑树),分别放入新数组的两个位置。
二、线程安全的HashMap?(synchronizedMap)
- HashMap 本身是非线程安全的。
- Java中可以利用 java.util.Collections 类的 synchronizedMap 方法,将 HashMap 包装成线程安全的映射集合。
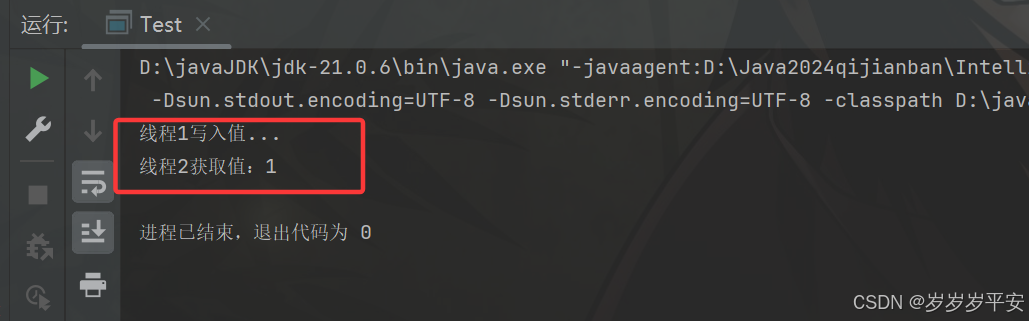
- 简单demo测试。
import java.util.Collections; import java.util.HashMap; import java.util.Map;public class Test {public static void main(String[] args) {HashMap<String,Object> hashMap = new HashMap();//使用Collections.synchronizedMap()方法 创建一个同步的HashMapMap<String, Object> syncMap = Collections.synchronizedMap(hashMap);//模拟多线程操作new Thread(()->{syncMap.put("key1","1");System.out.println("线程1写入值...");},"线程1").start();new Thread(()->{Object key1 = syncMap.get("key1");System.out.println("线程2获取值:"+key1);},"线程2").start();} }
- synchronizedMap 内部通过包装原Map,对几乎所有修改和访问方法(如:put、get、remove 等),都使用了同一把内置锁(this 锁,即包装后的 syncMap 实例作为锁对象)进行同步。保证多线程操作时同一时刻只有一个线程能执行这些方法,从而避免并发问题。