QT开发---字符编码与QString和QByteArray
字符编码的发展史
字符编码是计算机存储和传输文本的基础,其发展伴随计算机技术的全球化而不断演进
早期编码(单字节编码)
- ASCII 码(1963 年):美国信息交换标准代码,用 7 位二进制表示 128 个字符(含英文字母、数字、标点和控制字符),是最早的通用编码。
- 扩展 ASCII:部分厂商将 8 位二进制用于编码,扩展出 128 个额外字符(如欧洲语言的特殊符号),但缺乏统一标准,导致兼容性问题。
多字节编码(区域化编码)
为解决非英语字符的表示问题,各国推出本地化编码:
- GB2312(1980 年):中国国家标准,收录 6763 个简体汉字,采用双字节编码,兼容 ASCII。
- GBK(1995 年):扩展 GB2312,收录 21003 个汉字,包含繁体和日韩汉字。
- Big5(1984 年):中国台湾地区的繁体汉字编码,收录 13053 个汉字。
- Shift_JIS、EUC-JP:日本针对日语(含假名、汉字)的编码。
- ISO-8859 系列:国际标准化组织制定的多语言编码,如 ISO-8859-1 覆盖西欧语言,ISO-8859-5 支持西里尔字母。
统一编码(全球化编码)
- Unicode(1991 年):由 Unicode 联盟推出,目标是为世界上所有字符分配唯一编码,涵盖文字、符号、表情等,初期用 16 位表示(支持 65536 个字符),后扩展至 32 位,理论可容纳 100 多万个字符。
- UTF-8(1992 年):Unicode 的可变长度编码方案,用 1-4 字节表示字符:英文字母占 1 字节(兼容 ASCII),汉字通常占 3 字节,解决了 Unicode 存储和传输效率问题,成为互联网和跨平台应用的主流编码。
- UTF-16/UTF-32:Unicode 的其他实现方式,UTF-16 用 2 或 4 字节,UTF-32 固定 4 字节,适用于特定场景(如 Windows 内核、Java 内部)。
随着移动互联网和全球化的推进,字符编码逐渐向 UTF-8 统一,主流系统(Windows、macOS、Linux)和编程语言(Python 3、Java、JavaScript)均默认支持 UTF-8,有效解决了多语言文本的兼容问题。同时,Unicode 不断更新,纳入新字符(如 emoji 表情)以适应时代需求。
QString
QString是 Qt 框架中用于处理字符串的核心类,专为 Unicode 设计,提供了丰富的字符串操作功能,是 Qt 开发中最常用的数据类型之一。
QString 存储由 16 位 QChar 组成的字符串,每个 QChar 对应一个 UTF-16 编码单元。(代码值超过 65535 的 Unicode 字符通过代理对存储,即两个连续的 QChar)
Unicode 是一项国际标准,支持当今使用的大多数书写系统。它是 US-ASCII(ANSI X3.4-1986)和 Latin-1(ISO 8859-1)的超集,且所有 US-ASCII/Latin-1 字符在相同的代码位置上均可使用
在底层实现中,QString 采用隐式共享(写时复制)机制,以减少内存占用并避免不必要的数据复制。这也有助于降低存储 16 位字符(而非 8 位字符)带来的固有开销
除了 QString,Qt 还提供 QByteArray 类,用于存储原始字节和传统的以 '\0' 结尾的 8 位字符串。在大多数情况下,QString 是首选类。它在整个 Qt API 中被广泛使用,而 Unicode 支持确保了应用程序便于本地化翻译(若你希望在未来拓展应用市场)。QByteArray 适用的两个典型场景是:需要存储原始二进制数据时,以及内存占用至关重要的场景(如嵌入式系统)
基本特性
- Unicode 支持:内部以 UTF-16 编码存储字符,可无缝处理全球各种语言的字符,包括汉字、日文、韩文等复杂文字
- 动态内存管理:自动管理内存分配与释放,无需手动处理字符串长度和内存空间
- 隐式共享:采用写时复制(Copy-On-Write)机制,高效处理字符串的复制和传递,减少内存占用和开销
- 空字符串处理:区分空字符串(
"")和 null 字符串,API 设计友好
常见操作
这里只对QString和QByteArray类中常用方法介绍,若要深入学习,可以在QT文档中查看更多祥光内容,也可在网上查阅相关资料。
字符串创建与初始化
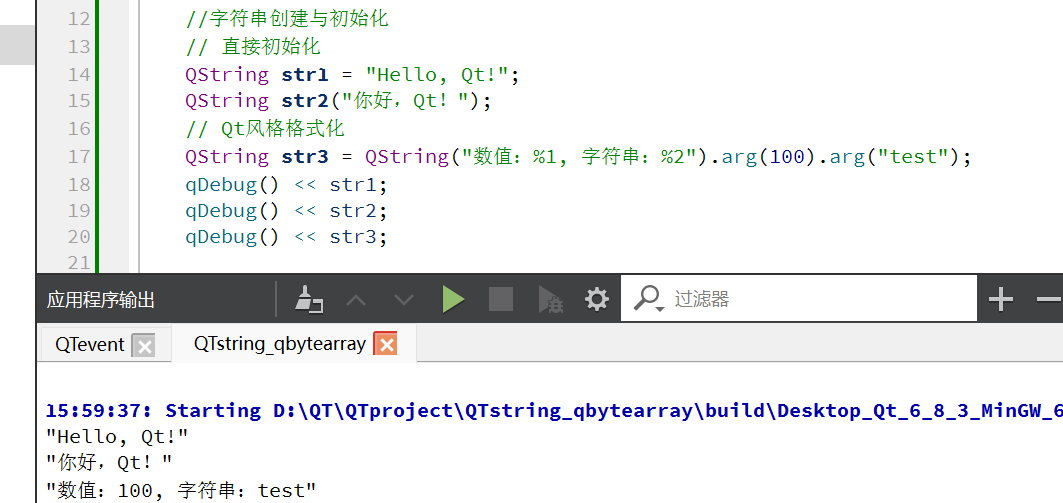
//字符串创建与初始化// 直接初始化QString str1 = "Hello, Qt!";QString str2("你好,Qt!");// Qt风格格式化QString str3 = QString("数值:%1, 字符串:%2").arg(100).arg("test");qDebug() << str1;qDebug() << str2;qDebug() << str3;字符串拼接 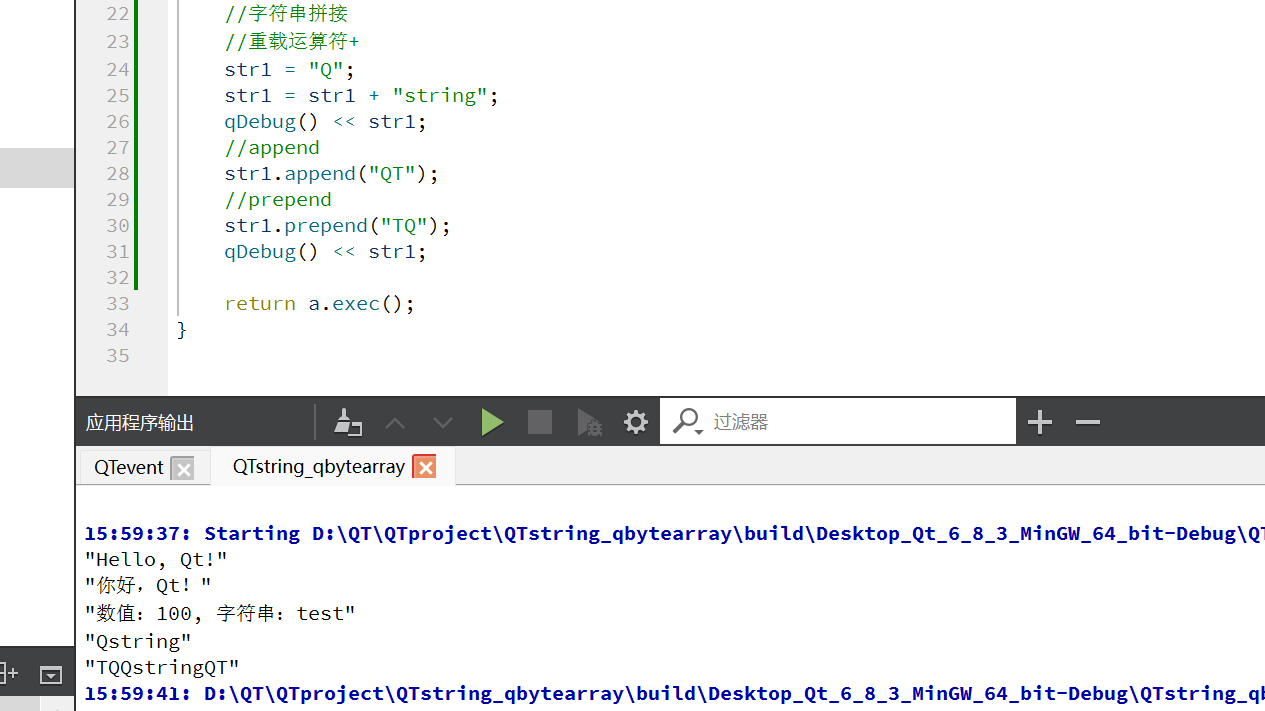
//字符串拼接//重载运算符+str1 = "Q";str1 = str1 + "string";qDebug() << str1;//append在字符串尾部添加str1.append("QT");//prepend在字符串头部添加str1.prepend("TQ");qDebug() << str1;计算字符串长度
//length() size() 字符串的字符数量
//count()无参时,统计字符数量
//count()有参时,统计字符出现次数
int n = str.count("l");
qDebug() << str.length() << str.size() << str.cout();
//计算字节大小
int bytes = str.toUtf8().size(); // 返回 UTF-8 编码的字节数字符串判断是否为空
bool isEmpty() 字符串是否为空字符串(即长度为 0)
bool isNull() 字符串是否为空值(null),即从未被初始化或显式设置为 null
//QString 是值类型,默认构造的字符串是空字符串 "",不是 null
qDebug() << str.isEmpty() << str.isNull();判断是否包含子字符串
contains()
bool QString::contains(const QString &str,Qt::CaseSensitivity cs = Qt::CaseSensitive) const;
bool QString::contains(QLatin1String str,Qt::CaseSensitivity cs = Qt::CaseSensitive) const;
bool QString::contains(QChar ch,Qt::CaseSensitivity cs = Qt::CaseSensitive) const;
enum CaseSensitivity {CaseInsensitive = 0, // 不区分大小写CaseSensitive = 1 // 区分大小写(默认)
};
//基本子串查找(最常用)
bool result = str.contains("QT"); 默认区分大小写
//查字符
bool result = contains(QChar('x'));提取子串
QString::section() 是 Qt 中用于 按分隔符把字符串切成若干段并取出其中一段 的快捷函数。
它不会改变原串,而是返回一个新的 QString
QString QString::section(QChar sep,int start,int end = -1,QString::SectionFlags flags = SectionDefault) const;
str = "/abc/def/gh";
str = section('/',2,2);
str = section('/',2,3);
0x00 对空字段进行计数,不包括前导和尾随分隔符,并且区分大小写对分隔符进行比较
0x01 将空字段视为不存在
0x02 把前导分隔符包含在结果中
0x04 把尾随分隔符包含在结果中
0x08 匹配分隔符时忽略大小写
字符串分割
QStringLiteral是 Qt 提供的一个宏,用于在编译期将字符串字面量直接转换成QString的内部数据结构(QStringData)。优势:避免了运行时的内存分配和字符编码转换(如从
const char*到 UTF-16),提升了性能,尤其在频繁使用相同字符串时。适用场景:常用于创建短小的、硬编码的字符串(如
"OK"),或需要高效构造QString的地方。
QString::split() 用于把单个 QString 按指定的“分隔符”切成若干段,返回 QStringList
QStringList QString::split(const QString &sep,Qt::SplitBehavior behavior = Qt::KeepEmptyParts,Qt::CaseSensitivity cs = Qt::CaseSensitive) const;QStringList QString::split(QChar sep,Qt::SplitBehavior behavior = Qt::KeepEmptyParts,Qt::CaseSensitivity cs = Qt::CaseSensitive) const;QStringList QString::split(const QRegularExpression &re,Qt::SplitBehavior behavior = Qt::KeepEmptyParts) const;
behavior:
Qt::KeepEmptyParts(默认)保留空片段
Qt::SkipEmptyParts 丢弃空片段QString str1 = "a,,b,c";
QStringList list2 = str1.split(',', Qt::SkipEmptyParts);字符串移除
QString 的 remove() 系列接口用来原地删除字符、子串或符合正则的片段;
返回的是 QString&,支持链式调用
QString& remove(QChar c, Qt::CaseSensitivity cs = Qt::CaseSensitive);
QString& remove(const QString& str, Qt::CaseSensitivity cs = Qt::CaseSensitive);
QString& remove(const QRegularExpression& re);
QString& remove(int position, int n); // 从 position 开始删 n 个字符str1.remove(','); // 把逗号全部删掉
str1.remove(",,"); // 删除连续两个逗号
str2.remove(1, 2); // 从下标 1 开始删 2 个字符
str3.remove(QRegularExpression("\\d+")); // 删除所有数字串remove() 会直接修改原 QString字符串字符串转换
数值 → 字符串
QString::number(value, format, precision);
参数
value 任何整数或浮点类型
format 字符:
‑ 'f' 定点格式(3.140000)
‑ 'e' 科学计数法(3.14e+00)
‑ 'g' 自动选用 f 或 e(默认值)
‑ 'G' 同 g,但用 E 代替 e
precision 小数位数/有效数字,默认 6字符串 → 数值
int i = str.toInt (str);
float f = str.toFloat (str);
double d = str.toDouble(str);
默认按 10 进制,可用第二个参数指定进制 2~36与其他字符串类的对比
| 字符串类型 | 特点 | 适用场景 |
|---|---|---|
QString | 支持 Unicode,功能丰富,Qt 原生支持 | Qt 应用程序内部字符串处理 |
std::string | 标准 C++ 类,默认不支持 Unicode | 跨平台非 Qt 项目,标准库兼容场景 |
const char* | C 风格字符串,手动管理内存 | 与 C 语言库交互,底层操作 |
注意事项
- 编码转换:与外部系统交互时(如文件 IO、网络传输),需明确编码格式(如 UTF-8、GBK),使用
toUtf8()、fromLocal8Bit()等方法进行转换 - 性能考量:频繁的字符串拼接操作建议使用
QStringBuilder(通过%运算符)提高效率 - 隐式共享:在多线程环境中操作字符串时,需注意写时复制机制可能带来的线程安全问题
QByteArray
QByteArray是 Qt 框架中用于处理字节数据的核心类,专为存储原始二进制数据和 8 位字符串设计,提供了高效的字节操作功能。

QByteArray 可用于存储原始字节(包括 '\0')和传统的以 '\0' 结尾的 8 位字符串。使用 QByteArray 比使用 const char * 更为便捷。在底层实现中,它始终确保数据后紧跟一个 '\0' 终止符,并采用隐式共享(写时复制)机制,以减少内存占用并避免不必要的数据复制
除了 QByteArray,Qt 还提供 QString 类用于存储字符串数据。在大多数情况下,QString 是首选类。它将内容视为 Unicode 文本(采用 UTF-16 编码),而 QByteArray 则尽量避免对所存储字节的编码或语义做任何假设(除少数使用 ASCII 编码的遗留场景外)。此外,QString 在整个 Qt API 中被广泛使用。QByteArray 适用的两个主要场景是:需要存储原始二进制数据时,以及内存占用至关重要的场景(例如,在嵌入式 Linux 上使用 Qt 时)
基本特性
- 双重用途:既可存储原始字节(包括
\0字符),也可存储以\0结尾的传统 8 位字符串 - 自动管理:内部维护
\0终止符,无需手动处理字符串结束标记 - 隐式共享:采用写时复制(Copy-On-Write)机制,优化内存使用和数据复制效率
- 兼容性:与 C 风格字符串(
const char*)无缝交互,简化传统 C API 调用
常见操作
//创建与初始化 // 直接初始化QByteArray ba1 = "Hello";QByteArray ba2("World", 5); // 指定长度// 从原始数据创建char Data[] = {0x00, 0x01, 0x02, 0x03};QByteArray ba3(Data, 4);// 填充初始化QByteArray ba4(10, 'A'); // 创建10个'A'的字节数组qDebug() << ba1 << ba2 << ba3 << ba4;QByteArray中许多方法与QString相似,这里不再重复说明,只介绍QByteArray中的方法
QByteArray::data()返回指向QByteArray数据的可写指针(char*),
用于直接操作底层字节数据
QByteArray::constData()返回指向QByteArray数据的只读指针(const char*),
常用于将QByteArray传递给需要 C 风格字符串(const char*)的函数
QByteArray::fill(char c, int size = -1)用指定字符c填充QByteArray
如果不指定size,则填充整个QByteArray;如果指定size,则填充到指定长度
QByteArray byteArray(5, 0); //创建长度为5,初始值为0的字节数组
byteArray.fill('X'); // 用 'X' 填充数组
// 十六进制转换
toHex() 用于将QByteArray中的数据转换为十六进制表示的QByteArray
fromHex() 则是将十六进制表示的QByteArray或QString转换回原始字节数据
QByteArray hexBa = ba.toHex();
QByteArray fromHex = QByteArray::fromHex(hexBa); // Base64编码
toBase64() 用于将QByteArray中的数据转换为 Base64 编码的QByteArray
fromBase64() 则是将 Base64 编码的QByteArray或QString转换回原始字节数据
QByteArray base64Ba = ba.toBase64();
QByteArray fromBase64 = QByteArray::fromBase64(base64Ba);与 QString 的对比
| 特性 | QByteArray | QString |
|---|---|---|
| 内部编码 | 8 位字节(无特定编码) | UTF-16(Unicode) |
| 主要用途 | 原始二进制数据、8 位字符串 | 文本字符串、多语言支持 |
| 内存占用 | 更节省(每个字符 1 字节) | 较高(每个字符 2 字节) |
| 适用场景 | 文件 IO、网络传输、二进制数据 | 界面文本、多语言处理 |
| 编码感知 | 无(需手动处理编码) | 有(原生支持 Unicode) |
注意事项
- 当需要处理文本数据时,优先使用
QString并明确编码转换 - 使用
constData()而非data()获取只读数据,避免不必要的复制 - 对大型字节数组进行频繁修改时,可使用
reserve()预分配空间提升性能 - 与外部系统交互时,需明确数据编码格式(如 UTF-8、Latin-1)
string与QByteArray之间转换
std::string → QByteArray
使用静态方法 QByteArray::fromStdString(),直接将标准字符串转换为字节数组
std::string stdStr = "Hello World";
QByteArray ba = QByteArray::fromStdString(stdStr);
// 内部按 std::string 的原始字节(通常是系统默认编码)存储QByteArray → std::string
使用 QByteArray::toStdString() 方法,将字节数组转换为标准字符串
QByteArray ba = "Hello World";
std::string stdStr = ba.toStdString();std::string 与 QString 互转(需经 QByteArray 中转)
QString与QByteArray之间转换
QString 转 QByteArray
QString内部以 UTF-16 编码存储,转换为QByteArray时需指定目标编码格式
转为 UTF-8 编码(推荐)
QString str = "Hello World";
QByteArray ba = str.toUtf8(); 转为本地编码
QByteArray ba = str.toLocal8Bit();转为 Latin-1 编码
QByteArray ba = str.toLatin1(); 转为 UTF-16 编码
保留QString内部编码(UTF-16),可指定字节序(大端 / 小端)
//带字节序标记(BOM)
QByteArray ba = str.toUtf16();
//不带BOM,指定小端字节序
QByteArray ba = str.toUtf16(QTextCodec::LittleEndian);QByteArray 转 QString
QByteArray存储的字节数据需明确编码格式才能正确转为QString(Unicode)
从 UTF-8 编码转换(推荐)
QByteArray ba = "Hello World";
QString str = QString::fromUtf8(ba);从本地编码转换
QString str = QString::fromLocal8Bit(ba);从 Latin-1 编码转换
QString str = QString::fromLatin1(ba);从 UTF-16 编码转换
需指定字节序(与转换时一致)
// 从带BOM的UTF-16字节转换
QString str = QString::fromUtf16(reinterpret_cast<const ushort*>(ba.constData()));
// 从指定小端字节序的UTF-16字节转换(无BOM)
QString str = QString::fromUtf16(reinterpret_cast<const ushort*>(ba.constData()), ba.size()/2, QTextCodec::LittleEndian);关键注意事项
编码一致性:转换双方必须使用相同的编码格式,否则会出现乱码。
特殊字符处理:
- 若
QByteArray包含无法被目标编码识别的字节,QString会用�(替换字符)表示。 - 非 ASCII 字符(如中文、emoji)在
toLatin1()转换时可能丢失信息(被替换为?)。
- 若
空数据处理:
- 空
QString("")转换后为包含\0的QByteArray。 - 包含
\0的QByteArray转换为QString时,\0会被视为正常字符(而非字符串结束符)。
- 空
结语:
无论你是初学者还是有经验的开发者,我希望我的博客能对你的学习之路有所帮助。如果你觉得这篇文章有用,不妨点击收藏,或者留下你的评论分享你的见解和经验,也欢迎你对我博客的内容提出建议和问题。每一次的点赞、评论、分享和关注都是对我的最大支持,也是对我持续分享和创作的动力