Flink流水线集成Gravitino
1.Gravitino简介
Apache Gravitino is a high-performance, geo-distributed, and federated metadata lake. It manages the metadata directly in different sources, types, and regions. It also provides users with unified metadata access for data and AI assets.(Apache Gravitino 是一个高性能、跨地域、联合的元数据湖系统。它直接管理不同来源、类型和区域的元数据,为用户提供统一的数据和 AI 资产元数据访问接口。)
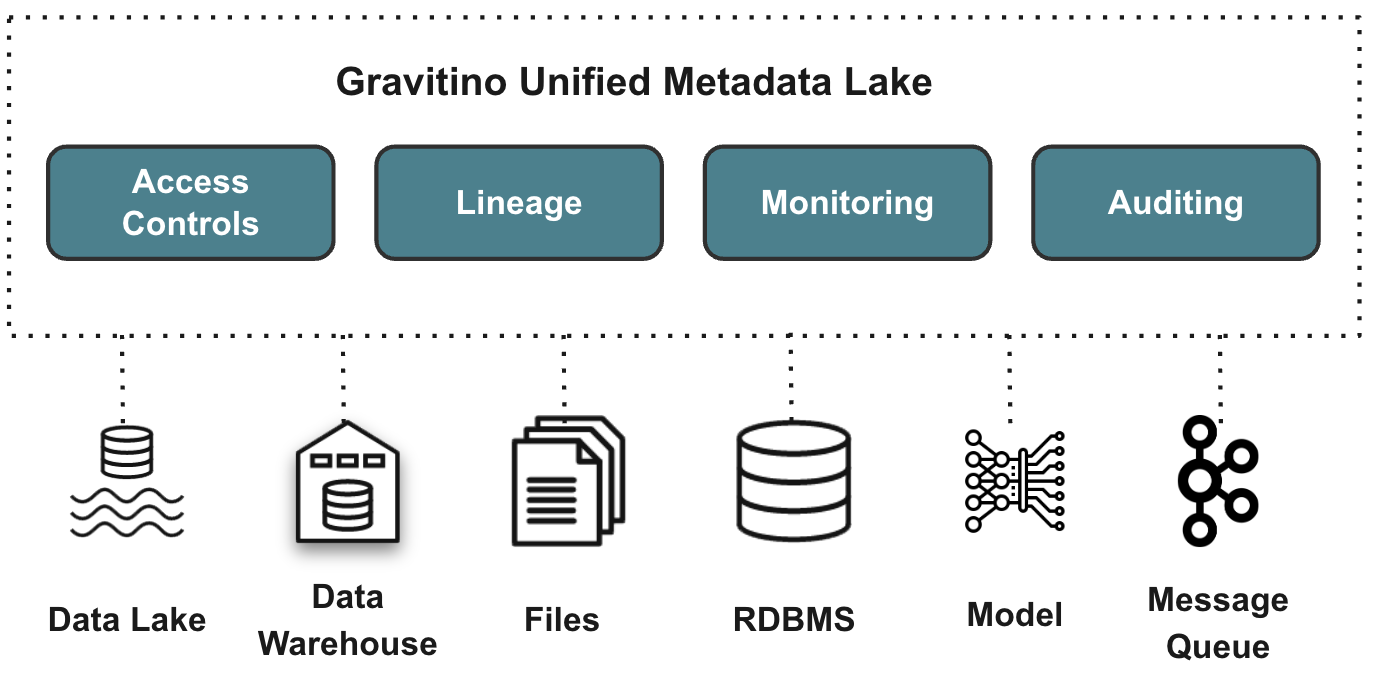
Gravitino 主要提供以下几个关键特性:
- 为多区域数据提供单一真实来源,支持跨地域分布式架构
- 统一管理数据和 AI 资产,服务用户和引擎
- 集中化安全管理,为不同数据源提供统一的安全控制
- 内置数据管理和数据访问管理功能
2.Gravitino系统演示
metalake:
catalog:
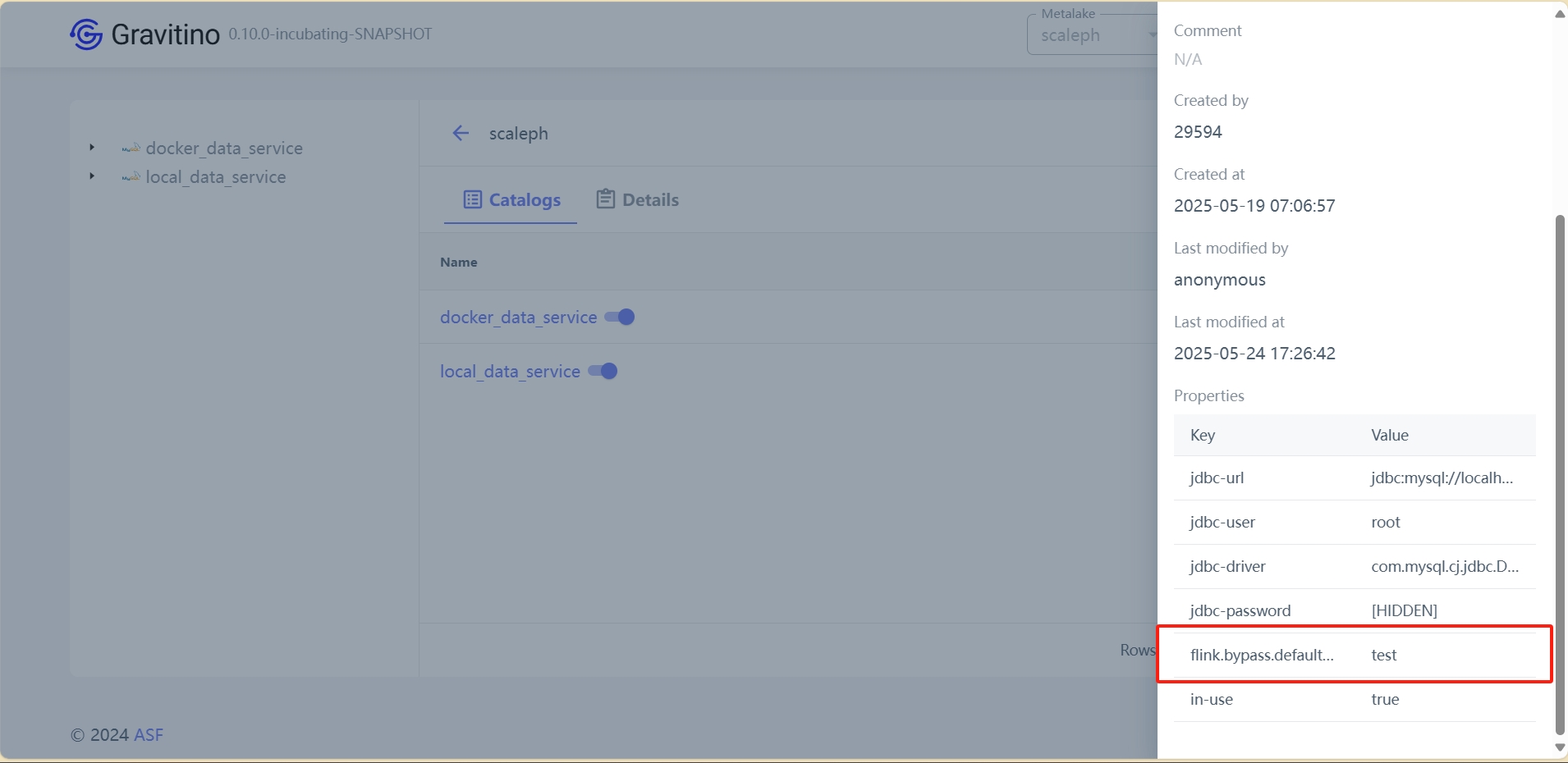
database:
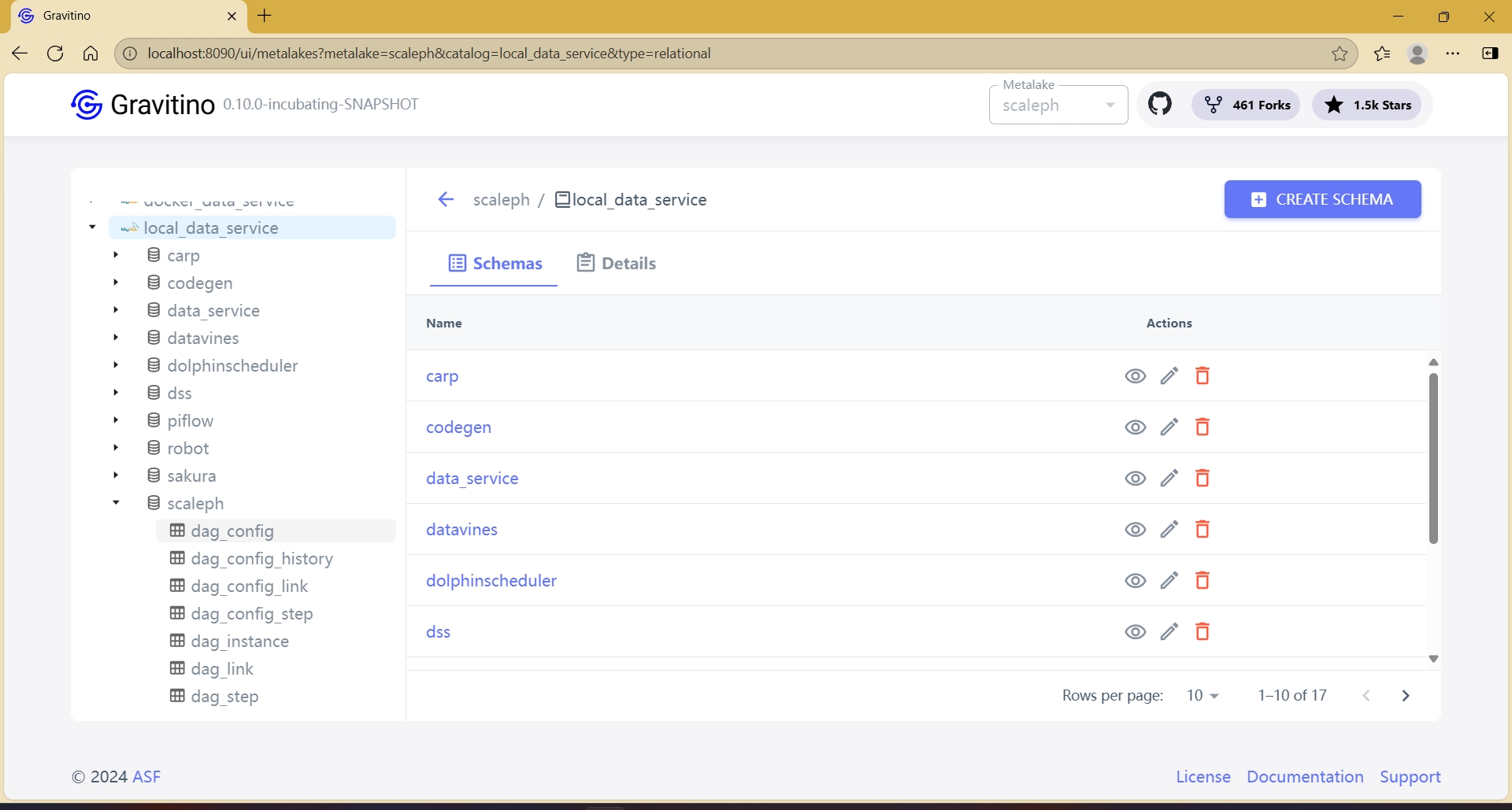
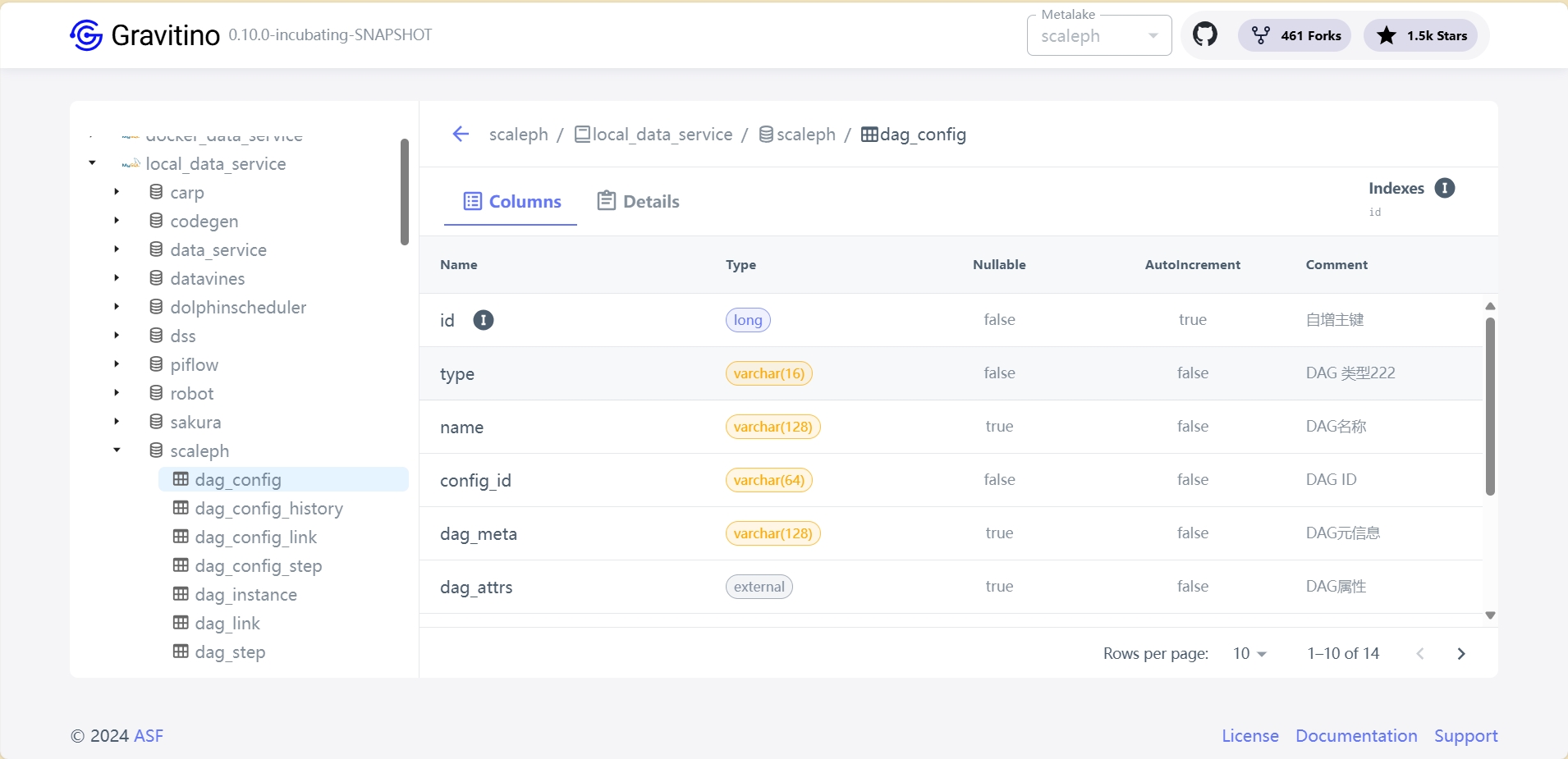
Gravitino 中的变化会直接反映在底层系统中
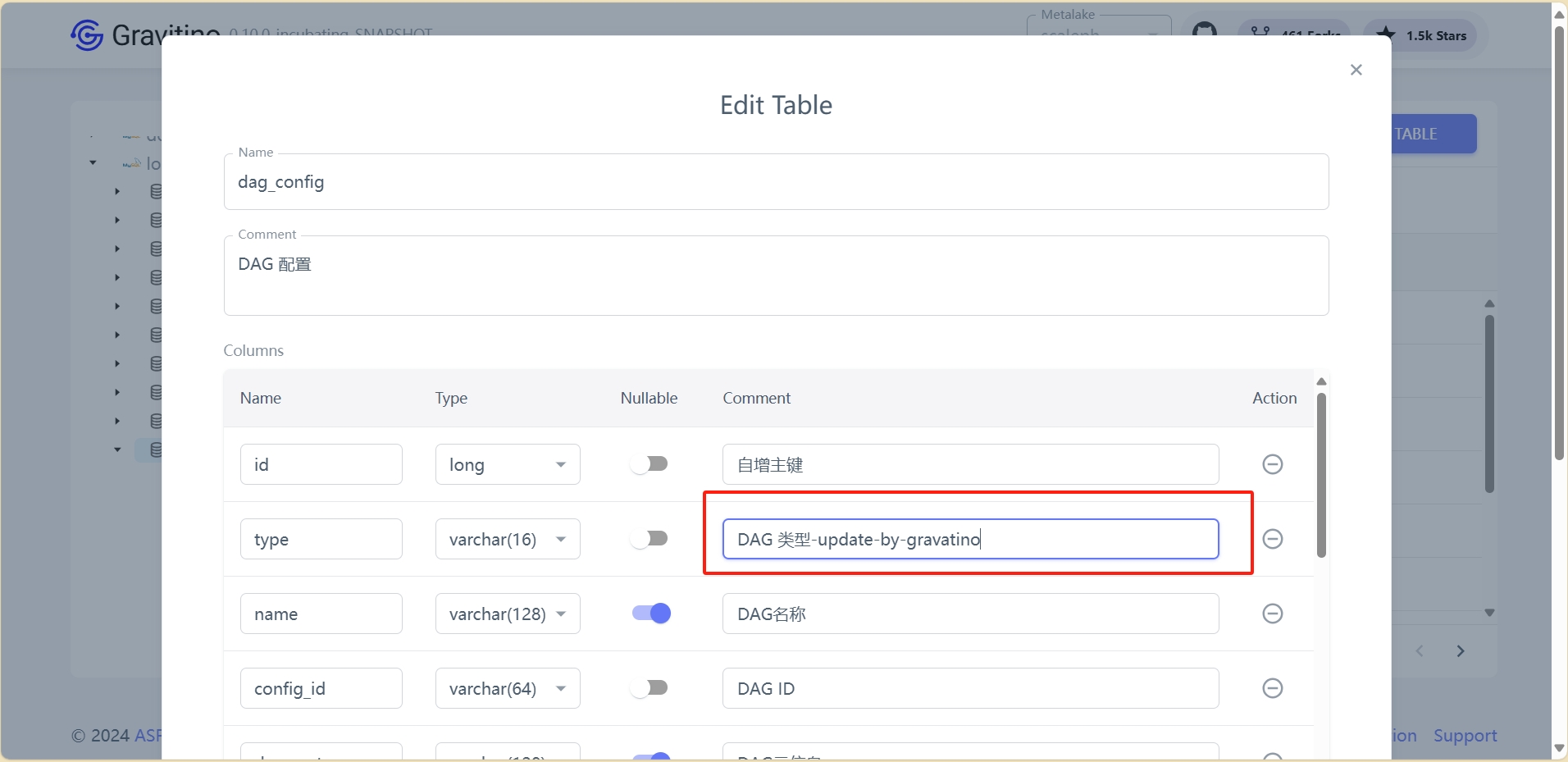
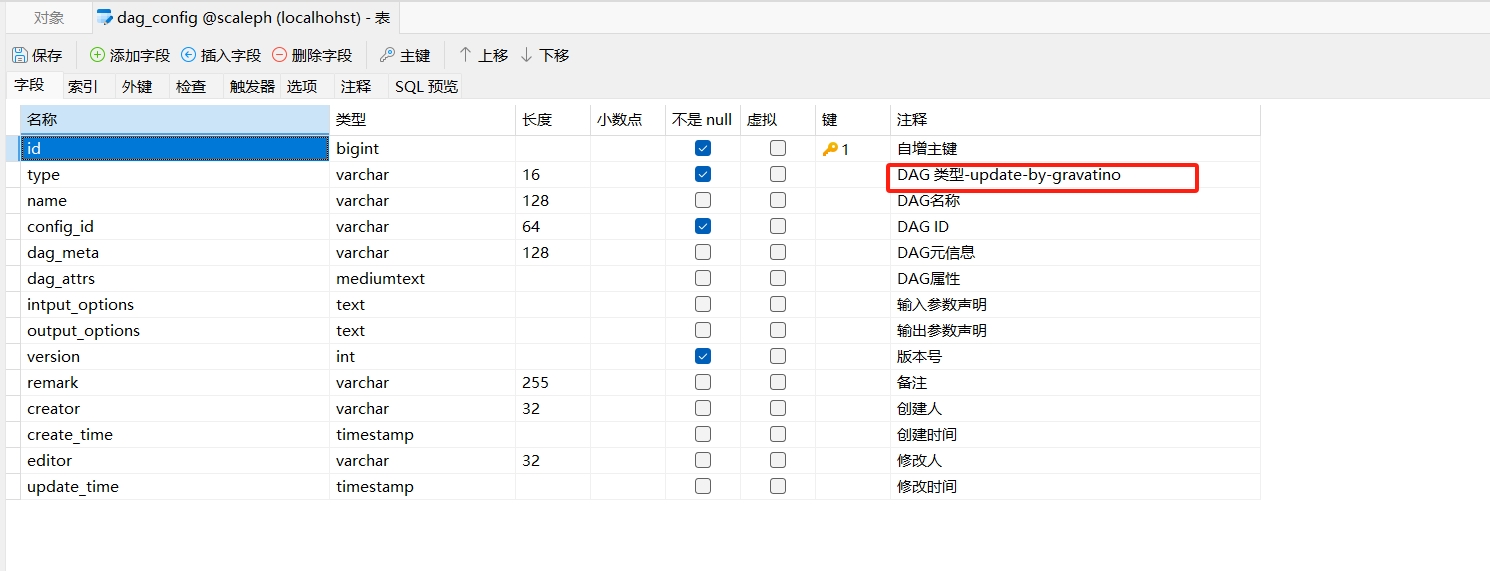
注:如需使用flink-connector,需要添加flink.bypass.default-database属性来指定默认数据库,不然会抛出异常
Caused by: java.lang.NullPointerException: default-database should not be null. at org.apache.gravitino.flink.connector.jdbc.GravitinoJdbcCatalogFactory.createCatalog(GravitinoJdbcCatalogFactory.java:48)
Apache Gravitino核心能力
统一元数据管理
Gravitino 为不同类型的元数据源提取统一的元数据模型和 API。例如,针对表格数据的关系型元数据模型,如 Hive、MySQL、PostgreSQL 等,也包括 Apache Doris。也针对所有非结构化数据的文件元数据模型,如 HDFS、S3 和其他格式。
端到端数据治理
Gravitino 的目标是提供一个统一的元数据治理层,以统一的方式管理端到端的元数据,其中包括访问控制、审计、发现等功能。端到端数据治理意味着对数据从产生到使用的整个过程进行全面的管理和控制,确保数据的准确性、完整性、安全性和可用性。例如,通过访问控制功能,可以限制不同用户对数据的访问权限;审计功能可以记录数据的使用情况和变化历史;发现功能可以帮助用户快速找到所需的数据。
直接元数据管理
与传统元数据管理系统需要从底层系统主动或被动地收集元数据不同,Gravitino 直接管理这些系统。它提供了一组连接器来连接不同的元数据源。Gravitino 中的变化会直接反映在底层系统中,反之亦然。这意味着 Gravitino 能够更直接地与元数据源进行交互,实现更高效的元数据管理。
多引擎支持
Gravitino 支持不同的查询引擎来访问元数据。目前,它已经支持了 Trino,Apache Spark 和 Apache Flink,用户可以使用这些引擎来查询元数据和数据,而无需更改现有的 SQL 方言。
Gravitino 也在进行与 AI 资产管理相关的工作。如将普通数据以及 AI 资产(如模型、特征等)的管理进行统一,实现一种统一的数据管理方式。
3. 集成演示
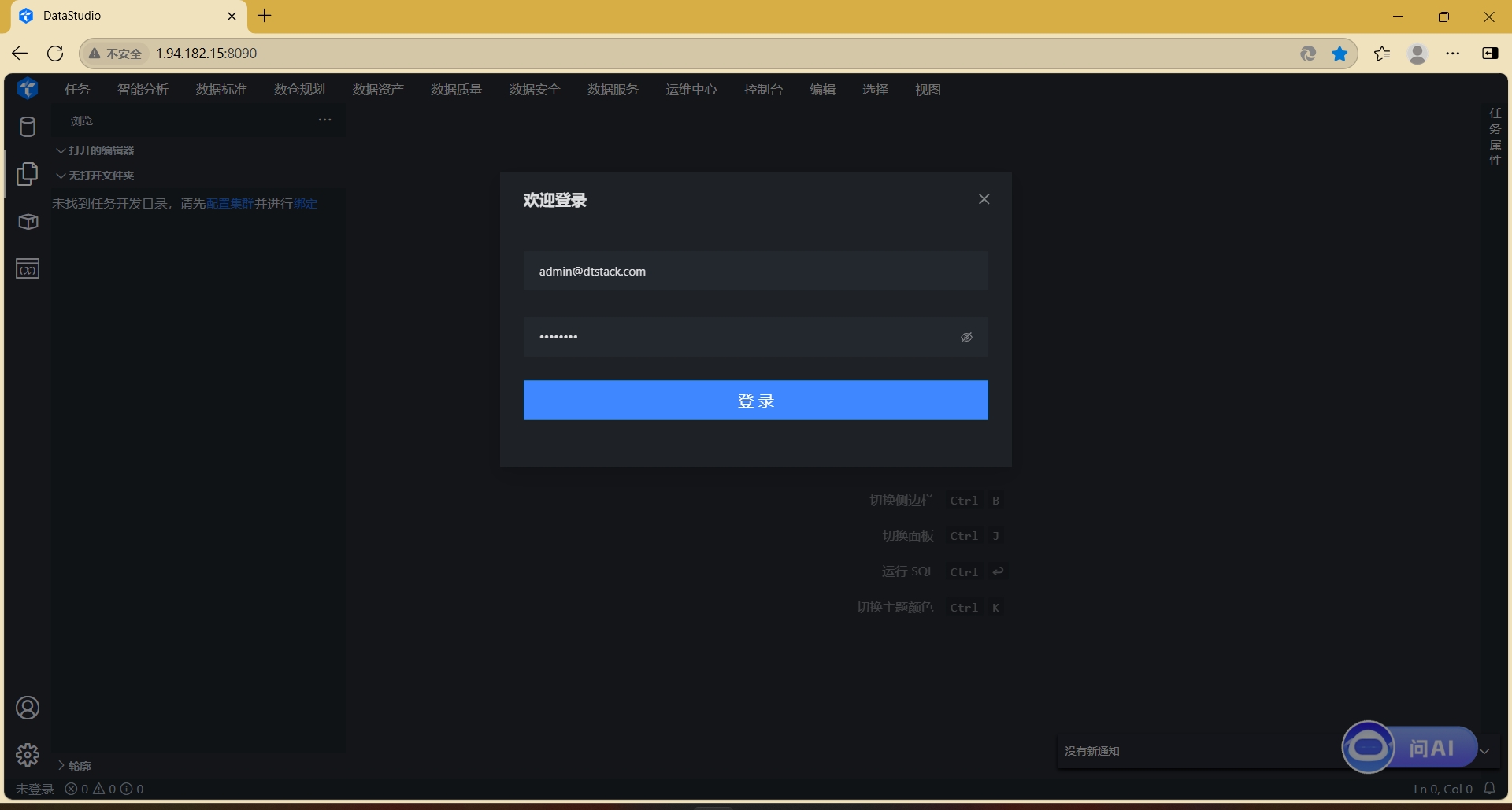
3.1 访问系统登录页面,输入账号密码完成身份验证。
3.2 创建任务
-
入口:通过顶部菜单栏选择 任务开发,或通过快捷入口 快速创建任务。
-
任务类型:选择
FlinkPipeline。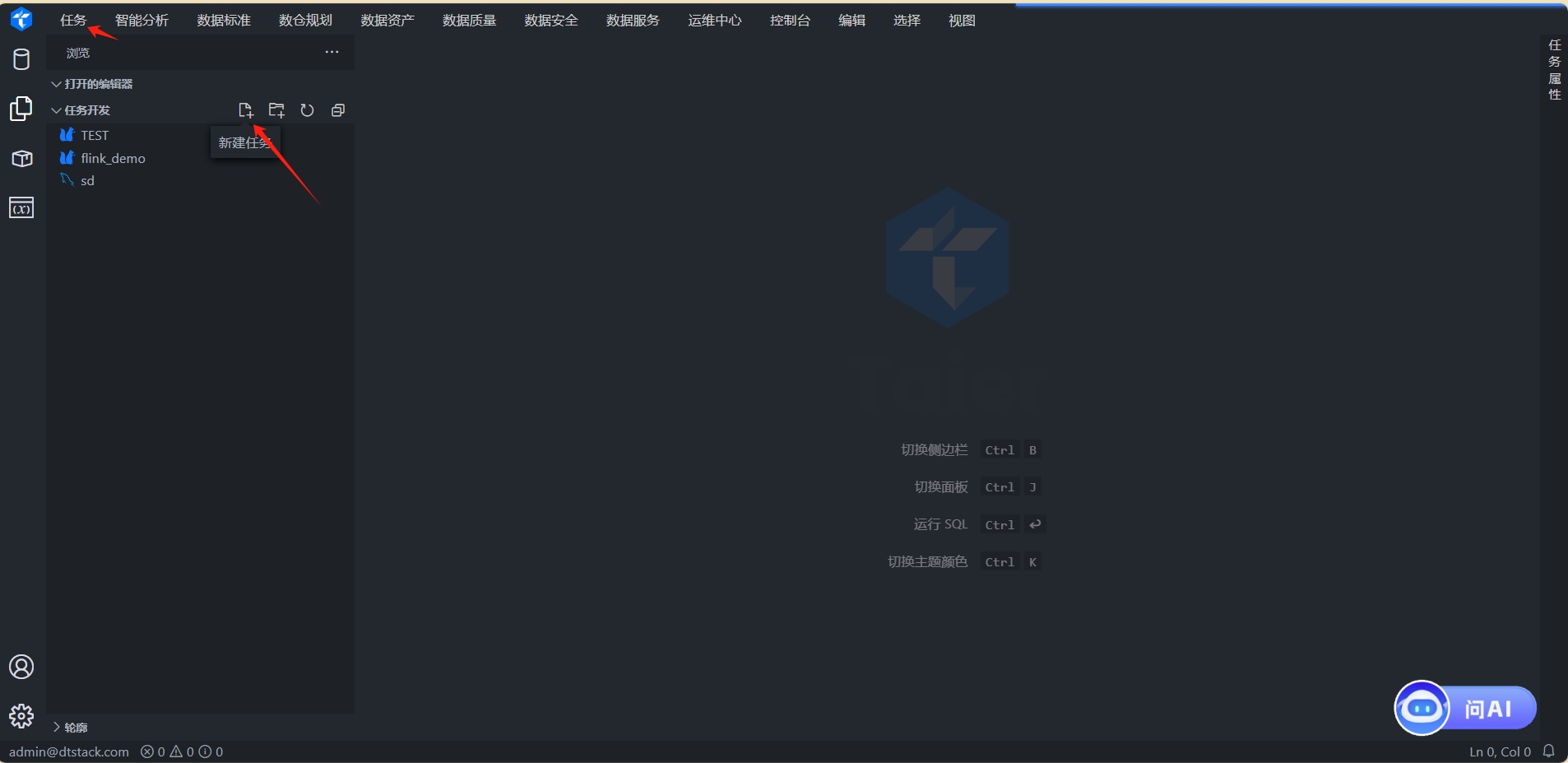
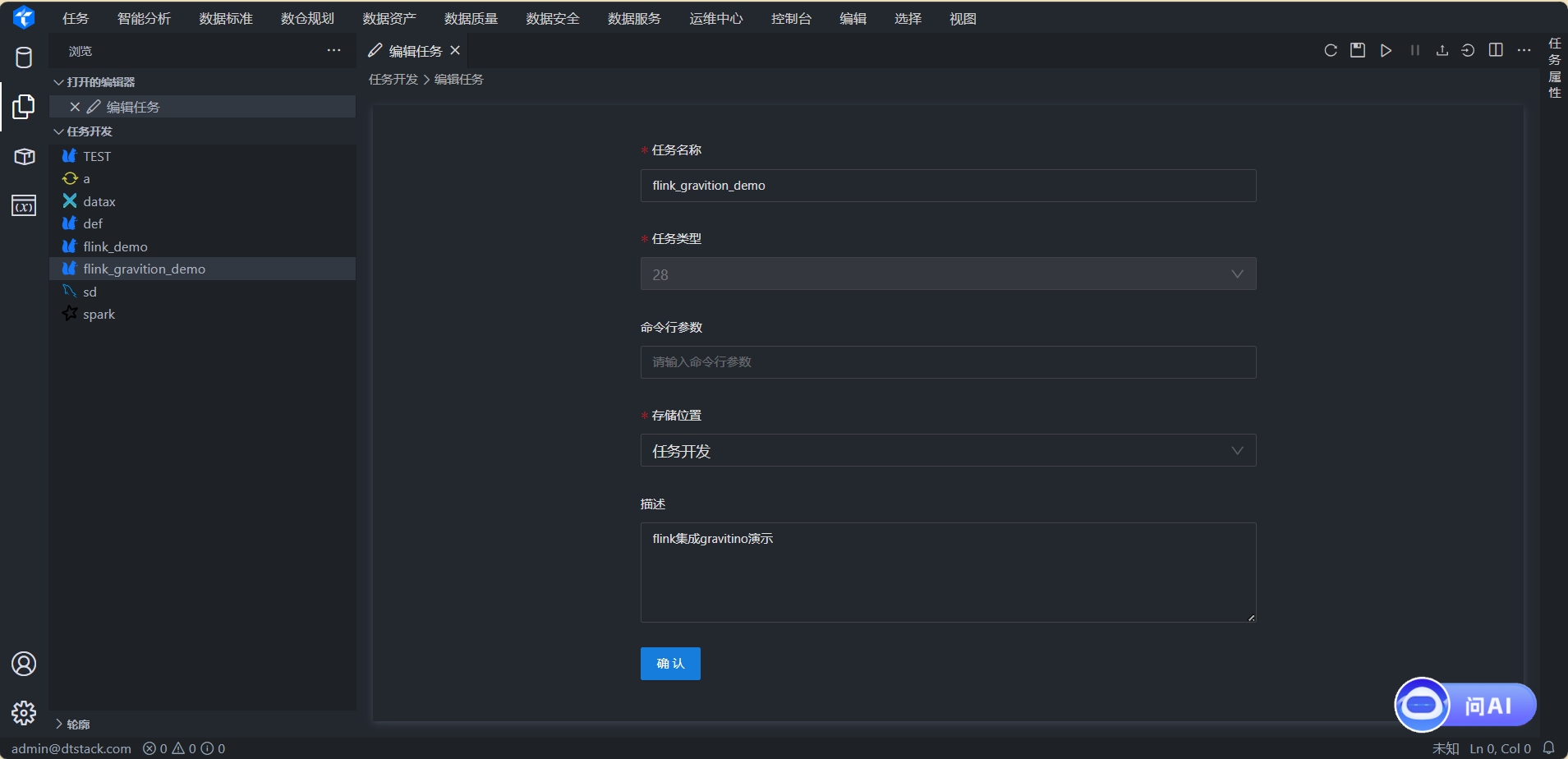
3.3 配置任务
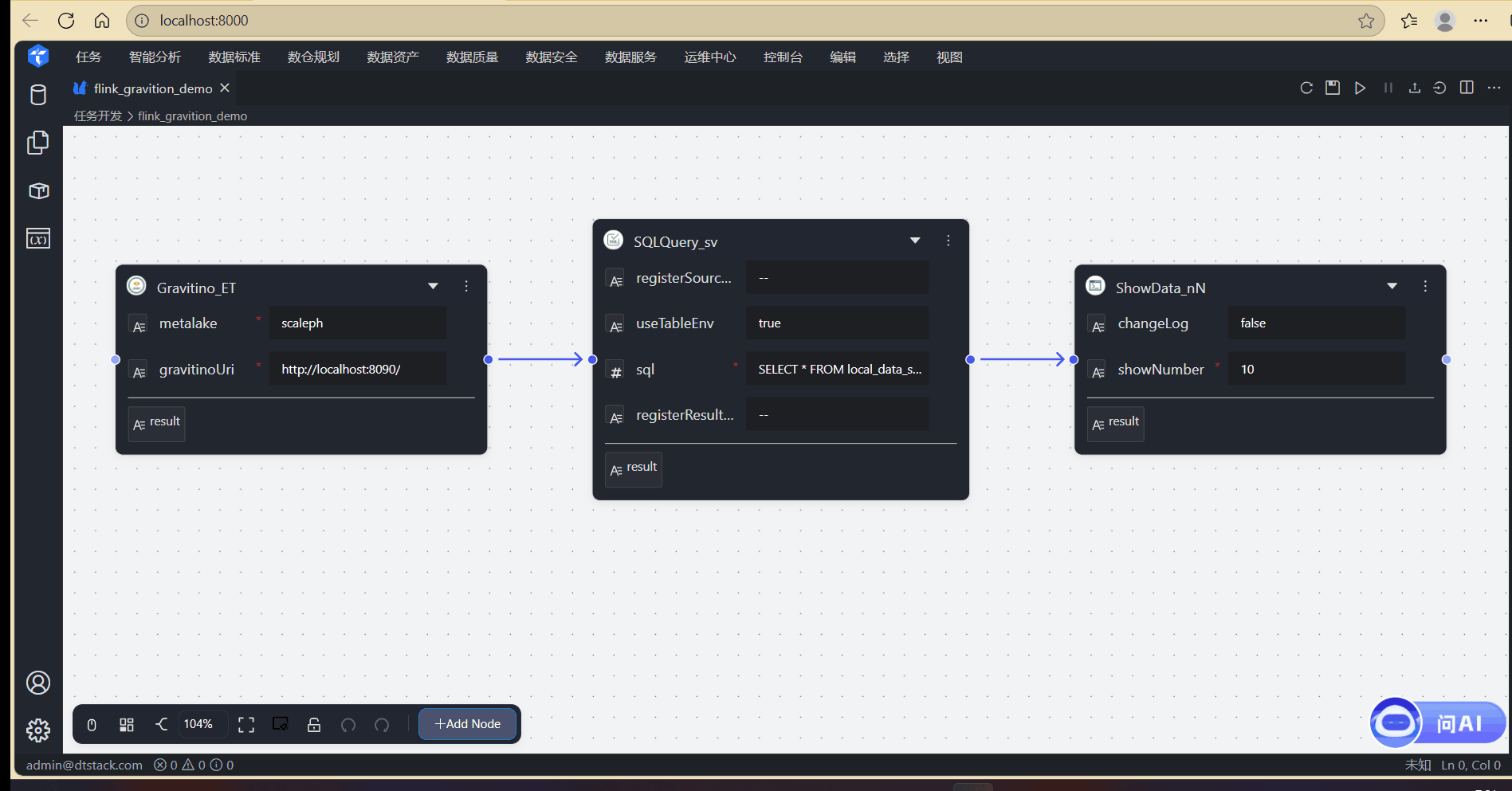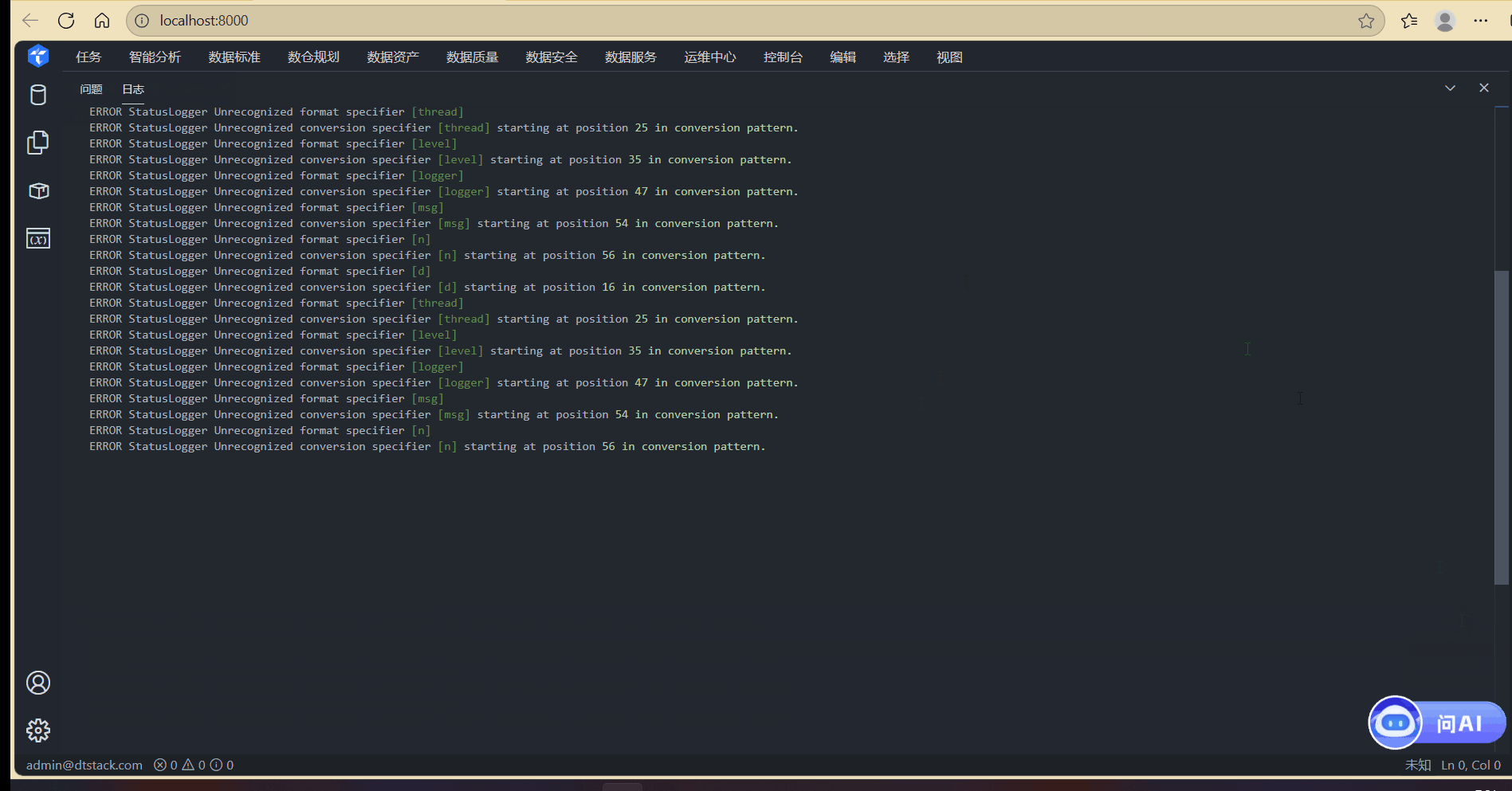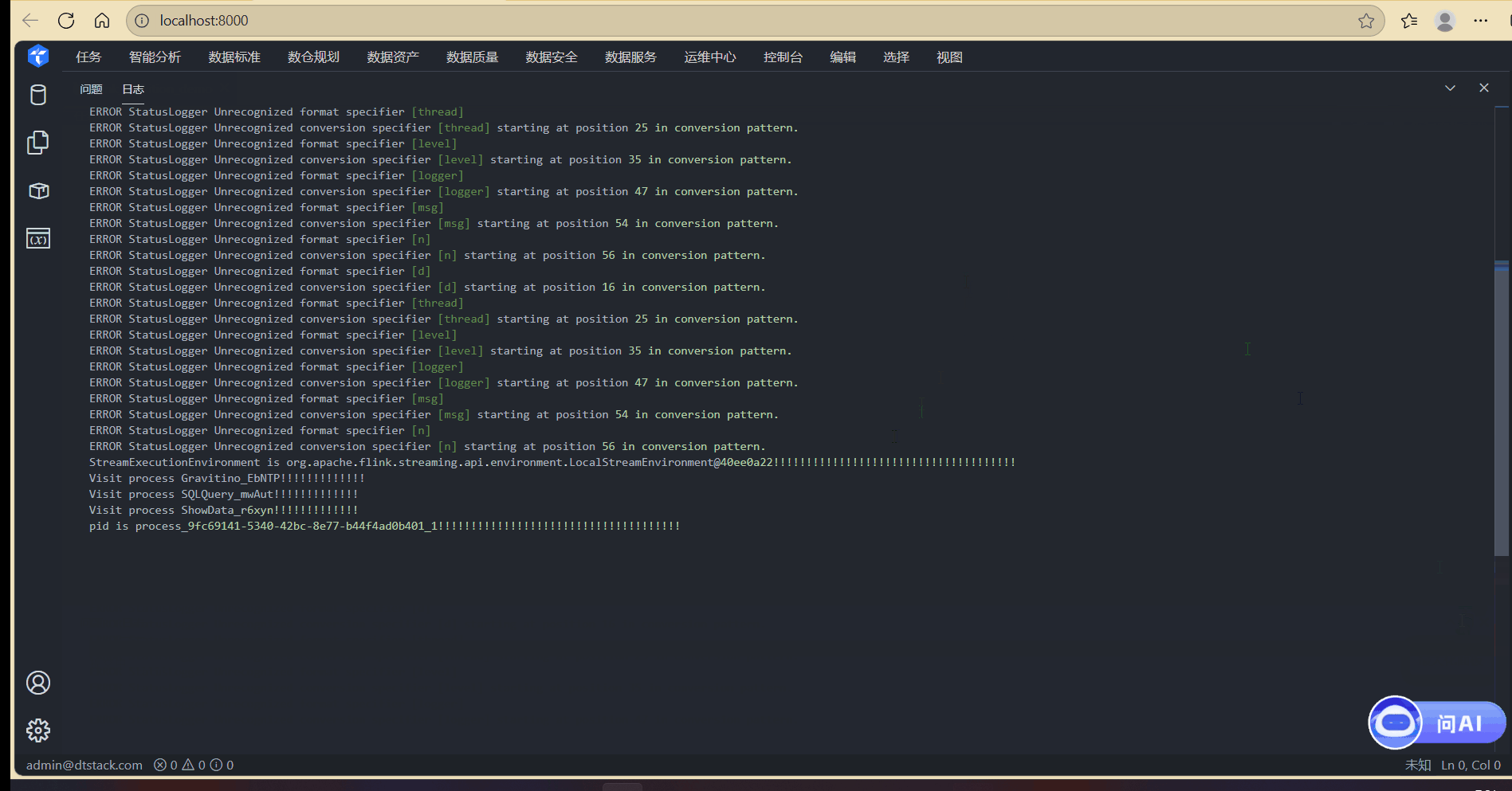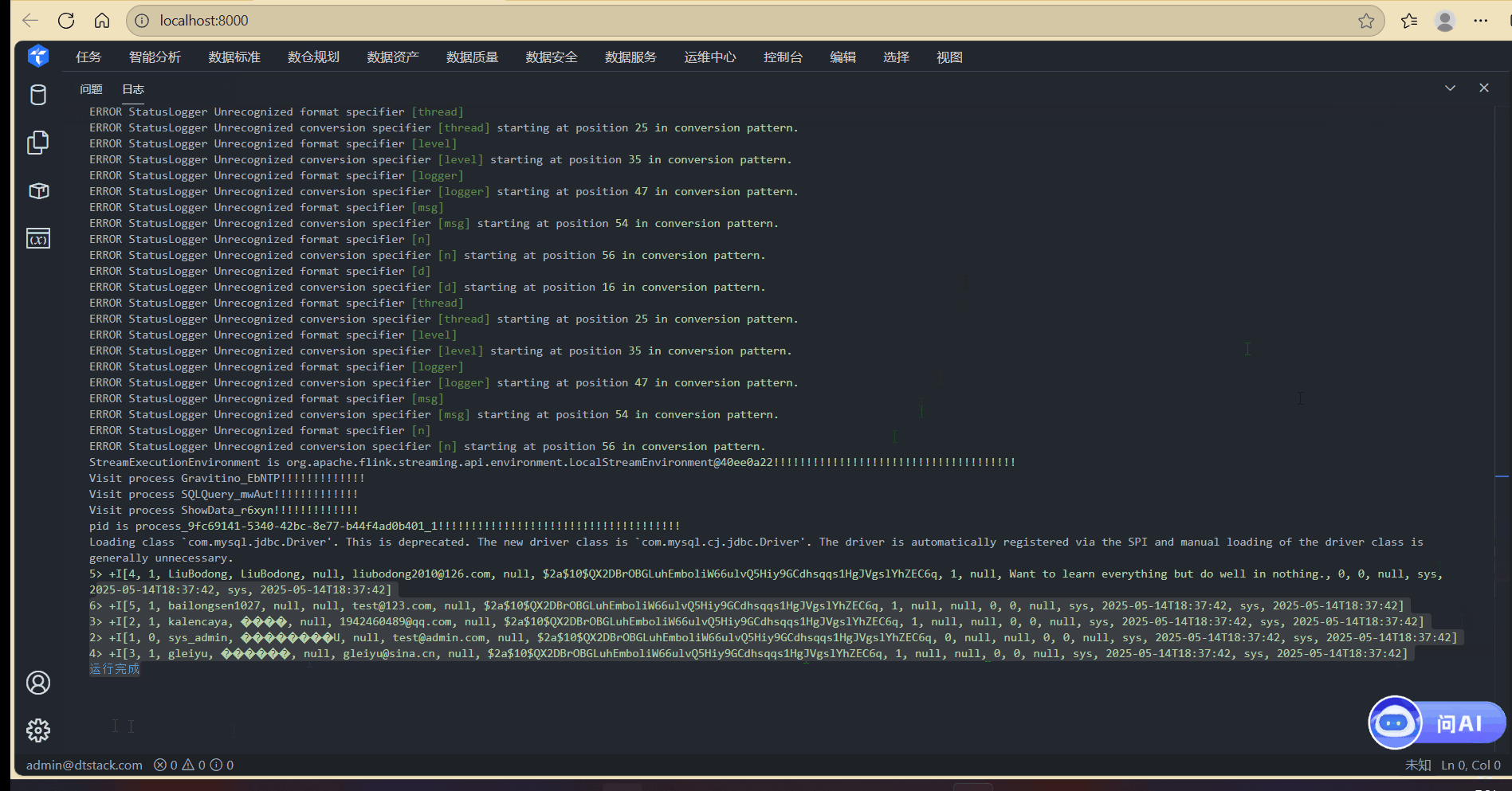
点击任务名称,进入任务详情页。任务节点如下
-
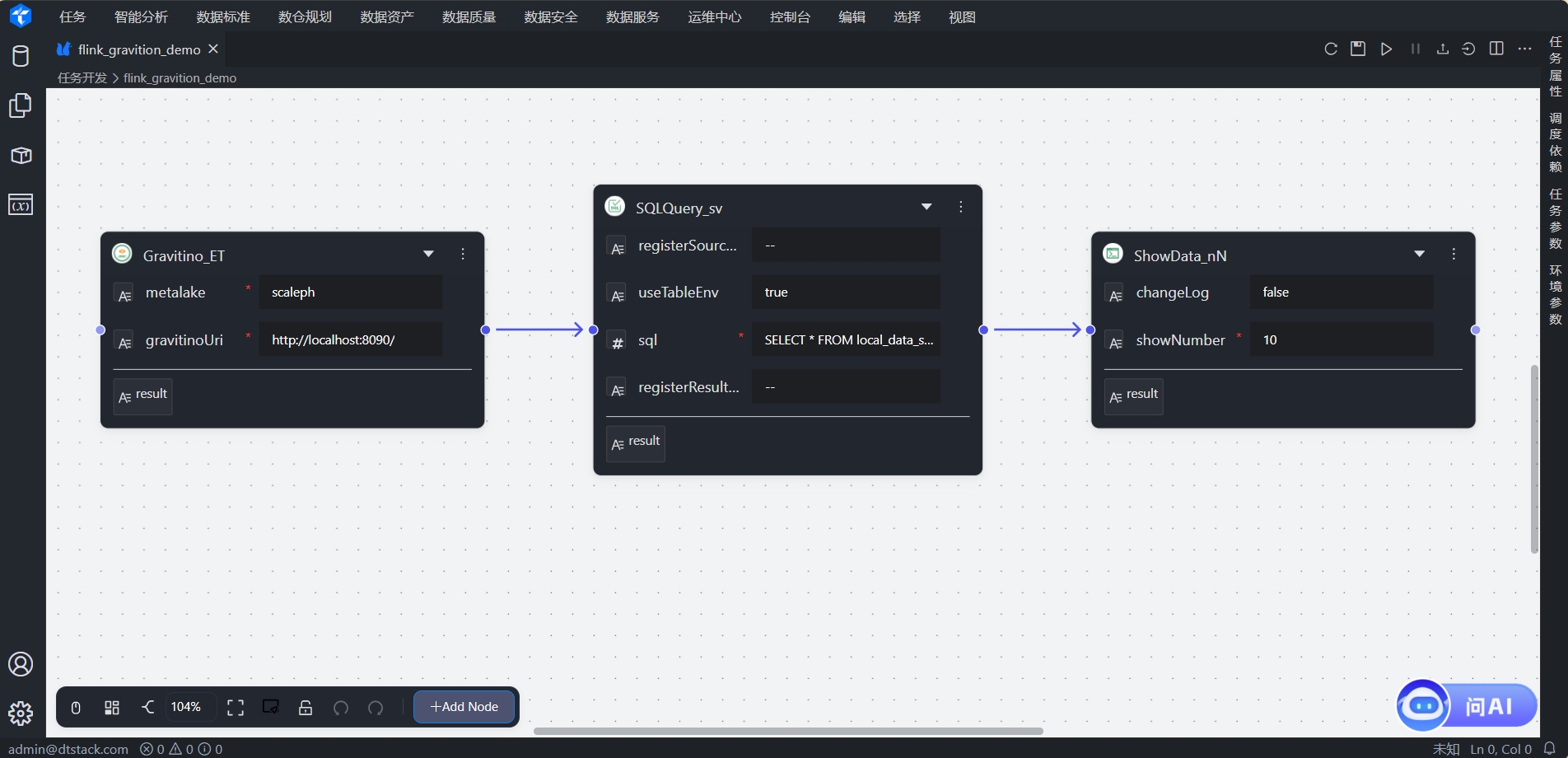
Gravatino节点:配置Gravatino连接信息
-
SQLQuery节点:执行sql查询语句,这里可以直接使用Gravatino中的元数据,如当前任务执行语句为
SELECT * FROM local_data_service.scaleph.sec_user,该语句会查询catalog为local_data_service,数据库为scaleph,表名为sec_user的数据。 -
ShowData节点:输出SQLQuery的执行结果。
3.4 运行任务
- 点击 运行 按钮启动任务。
🔗 平台体验地址:DataStudio (http://1.94.182.15:8090)
flink流水线集成Gravatino
参考链接:
[1] https://github.com/datastrato/gravitino/
[2] https://datastrato.ai/blog/gravitino-unified-metadata-lake/
[3] Flink connector jdbc catalog | Apache Gravitino