RoboDual-上海交大-2025-2-6-开源
迈向协同、通用且高效的机器人操作双系统
https://robodual.github.io/
RoboDual 总览:
我们的目标是构建一个协同的双系统框架,将“大规模预训练的通用系统”所具备的广泛适用性,与“专用系统”在特定任务上的高效适应能力相结合。
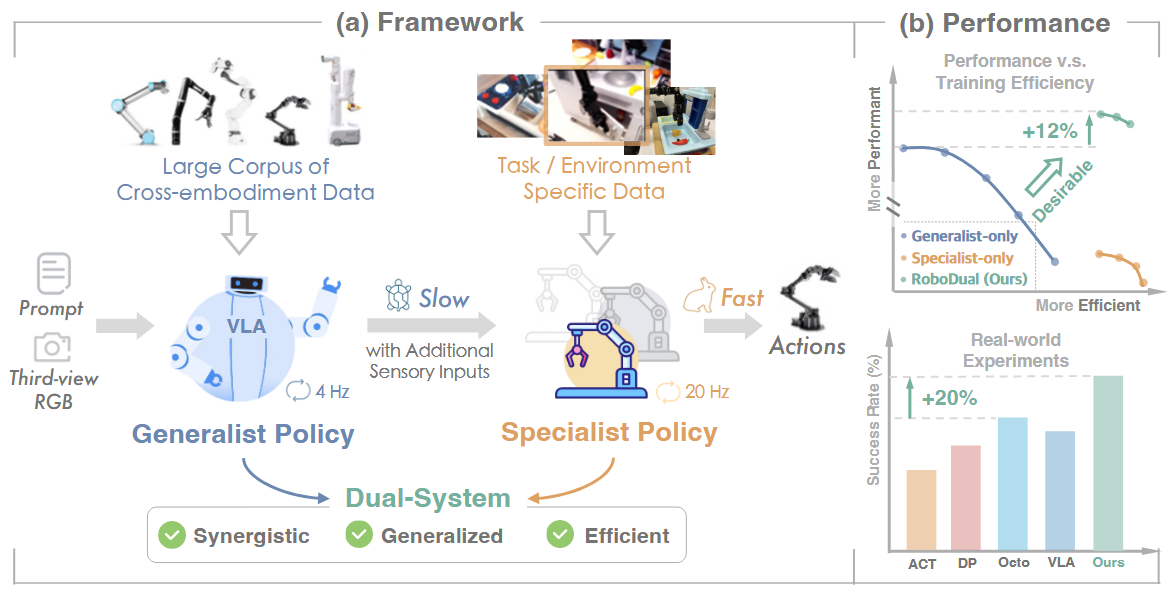
图a展示框架:快速的专用策略依托训练于大规模数据的通用系统所生成的“慢速但通用”的决策输出,在实时且高精度的控制上发挥作用。
图b展示性能:在真实机器人实验中,RoboDual 在性能和效率方面均明显优于单一系统,并超越了此前的最新技术水平20%(Octo)。
0. 摘要
随着对能够在多变且多样环境中灵活工作的机器人系统需求不断增长,通用策略的重要性也日益凸显,它通过利用大规模、跨平台的多样化数据集,来实现广泛的适应能力和高级的推理判断。然而,这类通用策略在推理效率低和训练成本高方面存在困难。
相比之下,专用策略则针对特定领域的数据精心设计,能在具体任务上以更高的效率实现精确控制。然而,它缺乏应对多样化应用场景的泛化能力。
RoboDual,一个将通用策略与专用策略优势相结合的协同双系统框架。
设计了一种基于扩散变换器(diffusion transformer)的专用模块,依赖于基于VLA所提供的高层任务理解和离散化动作建议,这个专用模块会接收这些离散建议,再生成多步动作序列。
扩散变换器(diffusion transformer):
结合了扩散模型与Transformer,擅长逐步“细化”动作,从粗到细生成一系列高质量控制信号。
与 OpenVLA 相比,通过仅引入一个拥有 2000 万可训练参数的专用策略,RoboDual 在真实机器人环境下性能提升了 26.7%,在 CALVIN 基准上提升了 12%。
它仅使用 5% 的演示数据就能保持强劲表现,并且在真实部署中支持高达 3.8 倍 的控制频率。相关代码将开源。
https://github.com/OpenDriveLab/RoboDual?tab=readme-ov-file
1. 介绍
传统的机器人学习方法,通常依赖为特定机器人和特定任务精心准备的数据集来训练策略。由此得到的策略可视为“专用型”,典型代表有 ACT(Zhao 等,2023)和 Diffusion Policy(Chi 等,2023),它在专门设计的场景和任务上表现出极高的精度,但往往泛化能力有限。
随着机器人越来越多地应用于开放式、多任务环境,这推动了“通用型”策略的发展,如 RT-2(Brohan 等,2023a)和 Octo(Ghosh 等,2024)。
它们利用大规模、多源异构数据集来提升跨领域泛化能力,并力图将网络知识转化为机器人控制能力。
VLA 方法将大规模跨平台数据与预训练大型(视觉)语言模型结合,促进了常识推理与指令执行等能力的实现。
尽管基于 VLA 的通用策略在知识迁移与跨场景泛化方面表现出色,但仍存在若干局限:
1)不能开箱即用地部署到新平台或新环境,需要额外的适配(OpenVLA在其他人的验证中也没做到);与专用策略相比,通用模型的微调过程对数据和训练成本的要求更高
2)尽管 VLA 擅长高层决策,但其大规模模型特性导致推理延迟极高
3)当前通用模型仅支持单帧 RGB 观测,这虽有利于大规模数据训练,但在深度或触觉反馈等附加感知关键的任务中效果受限。
同时,集成这些额外模态需要耗费大量资源的再训练,并且存在灾难性遗忘的风险。
这也引发了一个疑问:仅依赖对通用模型的改进,是否足以解决这些挑战?在通用与专用之间,或许需要一种更平衡的解决方案。
我们认识到:通用模型提供了广泛的泛化能力并受益于网络规模的预训练,而专用策略在效率和快速适应特定任务方面表现优异。如图1a就是一个通用且高效的框架,使两种策略互补以提升表现。
以大规模预训练的 OpenVLA 作为通用策略的基础,为实现两模型的无缝协同,我们将专用模型设计为轻量且可扩展的扩散变换器(diffusion transformer)策略。专用模型将视觉、深度、触觉以及通用策略的建议,作为条件,输入专用网络。
推理阶段,通用模型提供周详但相对较慢的条件信号,以支持快速响应的专用模型进行多步动作展开,从而实现精准且具泛化性的控制。如此,RoboDual 融合了通用模型的高层任务理解与泛化能力,以及专用模型的高效动作优化,在多种任务上均取得了卓越表现。
如图 1(b) 所示,在 CALVIN 基准上,相较于仅使用通用模型的方案,RoboDual 实现了 12% 的性能提升,且训练成本极低。
总结而言,我们的贡献有三方面:
- 我们提出了一种新颖方法,将通用策略与专用策略整合到一个协同框架中,称为 RoboDual,秉承双系统理念。该方法发挥了各自优势,为 VLA在灵巧操作任务中的实用化铺平了道路。
- 我们提出了一种基于扩散变换器的专用策略,该框架支持灵活整合多模态数据,并允许在训练数据层面对两模型进行解耦,从而增强各自的优势和能力。
- 通过大量真实环境和仿真实验,我们证明了双系统方法在各类任务中均优于仅使用专用或通用模型的方案。
2. 相关技术
通用策略
Octo使用基于 Transformer 的策略,在 Open-X-Embodiment 数据集的 80 万条轨迹上训练,从而能灵活地微调以适配新的机器人形态。
OpenVLA是目前最先进的通用策略,它直接将预训练的视觉-语言模型作为“词表”,将动作也当作“词”来生成机器人操作。与T5和Octo 不同,OpenVLA 利用更广泛的视觉-语言数据集来汲取世界知识。
尽管 OpenVLA 的泛化能力很强,但其数十亿参数的模型规模,既增大了数据需求,也拖慢了推理速度,因此作为通用策略部署在异构机器人平台上会受限。
与此相对,我们提出了一种新颖且成本更低的双系统框架,以解决这些问题,而不是再去搞一个更大、更要数据的新通用模型。
专用策略
我们把专用模型作为一种精度极高的策略,它只被训练去执行一小部分任务或功能。这类模型通常使用为其特定应用精心挑选的数据集。虽然许多专用策略在少样本模仿学习上表现突出,但它们通常不支持语言输入,因此需要为不同任务训练不同模型。
基于 Transformer 的模型已经成为提取多模态特征的强大工具,其处理异构观测的灵活性大幅提升了操作能力
在我们的工作中,专用模型被设计为一种可扩展的扩散变换器策略,擅长在统一框架下处理多模态输入和通用模型输出作为输入条件的情况。
此外,我们展示了与通用模型协作的同时如何增强泛化能力,并使之前仅用专用模型无法应对的多指令任务得以顺利执行。
将LLM嵌入到多层级的控制架构中
一个关键领域是高层任务规划,LLM 使用自然语言将任务分解,这使机器人能将抽象指令转化为具体动作。随后出现了使用结构化代码进行控制的工作,将用户指令映射为可执行程序。
另一类工作,包括 RoboFlamingo 和 LCB,通过潜在空间表示实现分层控制,在 LLM 潜在输出上再加一个动作解码网络,直接回归生成动作。
虽然我们的框架也遵循分层思路,但它不需要显式地分解任务,也无需对分离的策略进行端到端优化。我们利用离散化动作输出和潜在嵌入作为两模型之间的“接口”,而不是预定义的低层技能。
假设我们要让机械臂完成“从桌面抓起红色积木并放入盒子”的任务:
1.高层 LLM 规划
输入:视觉感知到的 RGB 图像与指令 “pick up the red block and put it in the box”。
输出:离散动作 token 序列:[LOCATE_BLOCK, ALIGN_GRIP, GRASP, LIFT, MOVE_TO_BOX, RELEASE],以及一段潜在向量 z 用于精细控制2.中层接口同步
离散 token 提供宏观动作顺序;
潜在向量 zz 则携带如抓取力度、移动速度等细节信息,由下层网络解码。3.低层控制器执行
接收到 token GRASP,低层策略根据当前 zz 向量解码出关节角度变化指令,驱动机械臂完成精准抓取;
随后,MOVE_TO_BOX token 触发路径规划模块,结合 zz 中的速度偏好,实现平稳移动,并最终 RELEASE。
这种设计无需为“抓取”、“移动”、“放置”分别训练独立策略,只要高层模型能学会在接口空间中输出合适的 token 和潜在向量,就可驱动同一套低层控制网络完成多种任务
通用模型和专用模型在训练数据层面上可以解耦,各自发展专长,这也为利用多种模态输入带来了灵活性。
3. RoboDual-通用-专业的协同
在 3.1 节中,我们将介绍通用策略——它在整个框架中充当细致稳健的高层规划器。
在 3.2 节中,我们阐述专用策略的设计原则——它针对精准的实时控制进行了优化,并支持统一条件化。
最后,在第 3.3 节中,我们详细介绍了训练与推理流程。
系统框架示意图见下图图 2。
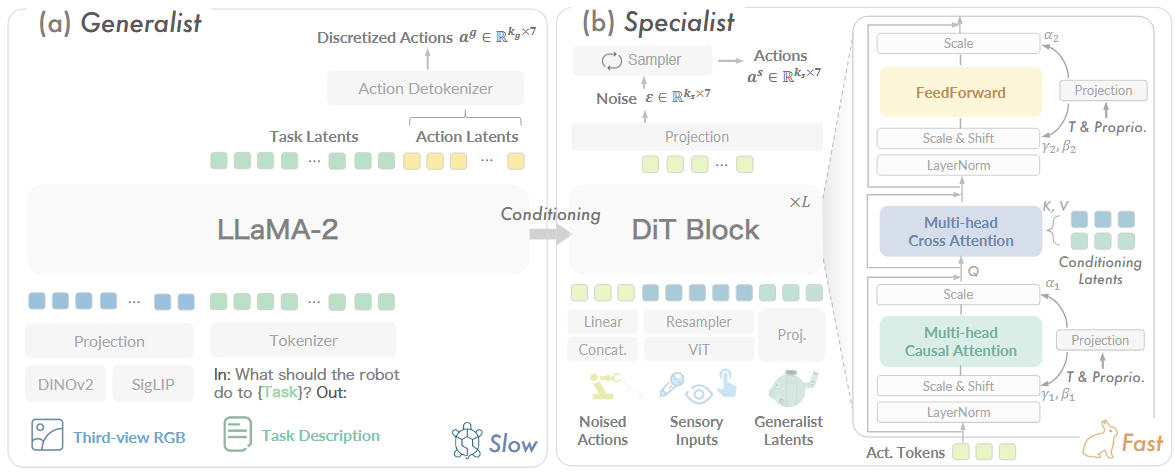
通用部分就是OpenVLA的结构,可以查看:
专业部分接收:
- 通用模型输出的:
- 离散化动作 token(Act Tokens),告诉它“大致要干啥”。
- Task Latents,提供抓取力度、速度等细节向量。
- 本地感知
- 传感输入:触觉、关节自感等,保证操作安全可靠。
- “Noised Actions”:在训练时给真实动作加噪,让模型学会如何去噪预测更精准的指令。
DiT模块中:
- Cross-Attention:将通用策略输出(绿色、黄色方块)作为条件,指导底层 Transformer 聚焦到正确的时刻和动作要点。
- Causal Self-Attention + FeedForward:在保留时序连贯性的同时,利用多头注意力捕获动作与传感信号的复杂关联。
- Projection & Resampler:对潜在向量进行降维或上采样,确保不同模态输入在统一的表示空间里对齐。
输出:
去噪后的动作 aˢ:真正送到机械臂的关节角度与手爪力度指令,实时性极高(fast),保证精准执行。
Sampler 就是那个「把噪声变成动作」的扩散采样器,驱动我们的 Diffusion Transformer 从随机噪声中一步步“抽样”出机械臂要执行的精准控制命令。
3.1 通用模型:一个自回归的VLA模型
我们的通用模型基于 OpenVLA构建,该模型拥有 70 亿参数,是一个自回归的视觉-语言-动作模型,使用了大规模机器人操作数据集进行训练,包括 Open-X-Embodiment、Bridge V2、DROID等。
自回归(autoregressive):模型在生成每个动作或标记时,会参考之前已生成的内容,实现时序依赖。
通用模型采用了 Prismatic-7B,尽管在大规模跨平台数据集上进行了充分训练,OpenVLA 在全新环境或新型机器人平台上仍无法直接实现零样本部署。
因此,针对我们特定的机器人系统和测试环境(包括新的坐标系、摄像机角度等),仍需进行适配,我们通过 LoRA微调来实现这一点。
看来我也应该要做这一步
尽管如此,我们希望利用 OpenVLA 所蕴含的大量预训练知识,为我们的双系统框架赋予基本的泛化能力。
自回归生成与动作分块
与 RT-2 和 OpenVLA 相同,我们将 LLaMA 分词器中最不常用的 256 个词映射到 [–1, 1] 区间内均匀分布的动作区间。
这种方法使我们能够根据词表中词的索引,将语言token“解码”成离散化的动作值。
通用模型以自回归方式对每个自由度的动作进行解码,当前步的解码依赖于输入提示和已解码的token。
我们进一步在原始 OpenVLA 基础上扩展,使其能预测长度为 kg 的动作分块。
“Action Chunks” 动作分块:本质上是将多步动作打包预测并执行的技术思路
kg:通用模型一次生成 kg 步的动作
这种更长时域的规划,不仅增强了通用模型捕捉人类演示中非马尔可夫行为的能力,也为专用模型提供了更丰富的条件信息。
非马尔可夫行为(non-Markovian behavior):当前动作不仅依赖于上一状态,还与更久远的上下文有关。
分词器中使用 [space] 标记来区分每个时间步的动作输出。
[space] 标记:作为动作序列的分隔符,类似句子里的空格,用于划分时序单元。
然而,动作分块会因为需要生成更多标记而增加 VLA 的推理延迟。这也进一步凸显了对专用模型的需求:在连续的 VLA 输出之间以更高频率运行,以实现更及时的控制。
3.2 专用模型:一个可控的扩散变换器策略
构建于预训练通用策略之上,该专用策略旨在在有限训练数据和计算资源下,提升性能并降低控制延迟。为充分利用多模态传感输入(如 RGB、深度、触觉)及通用策略的专属知识,我们基于扩散变换器(DiT)设计专用策略,用于对动作序列进行可控去噪。
基础架构:
图 2(b) 展示了专用模型结构,主要由多层 DiT 模块 堆叠而成。每个DiT模块包含:因果自注意力层(处理时序动作),交叉注意力层(融合多源信息),以及逐点前馈层(执行非线性变换)。
类比图像扩散模型,我们将 7 自由度动作 视为 7 通道“像素”,线性投影为单个token,供扩散变换器处理。该方式支持动作token的时间扩展,以灵活的长度 ks 预测动作分块(action chunking)
使用 ViT(Vision Transformer)作为通用感知编码器,对 RGB、深度、触觉等多模态输入进行编码;仅在 patchify 层给一个不同的通道数就行。
Vision Transformer(ViT)会将输入图像先切分为固定大小的小块(patch),并对每个 patch展开后通过一个线性投影(patchify 层)映射到一个向量空间,随后再与位置编码一起送入 Transformer 编码器;对于不同模态(如RGB 三通道、Depth 一通道或触觉多通道)的输入,只需要修改这个 patchify 层的“输入通道数”(in_channels),其余架构与权重保持一致,即可实现多模态感知的统一编码。
对于 RGB 输入,采用自监督预训练的 DINO 模型进行编码,并在训练中保持参数冻结。其他模态的编码器网络被限制为 6 层、隐藏维度 256,以保证模型轻量高效。
除图像外,本框架也可接入其他序列化的传感输入(如力度、温度等),展示了高度的模态扩展性。
这个力度我个人认为采摘草莓是需要的。深度判断草莓的熟度也是必要的
多模态条件下的动作去噪
专用模型通过多种条件源提升策略质量:1)机器人本体感知(位置/速度等),2)多模态传感,3)通用策略离散动作,4)通用模型的潜在向量(图 2(a))。每种条件源提供不同信息,使策略更加信息丰富且鲁棒。
本体感知经由两层 MLP 处理,并与时间步嵌入结合,实现对每一采样的自适应条件化。除学习 γ/β 两参数以做自适应层归一化外,还在残差连接中加入缩放系数 α,以保证条件注入的稳定性和训练鲁棒性。
两层 MLP 的结构:一个简单的多层感知机(MLP),包含两层全连接 + 激活(例如 ReLU)。
功能:
1.降维与特征提取:把高维的原始本体感觉信号映射到与 Transformer 输入维度匹配的 embedding 空间;
2.非线性变换:学习到更富表达力的内部特征表征,便于后续条件注入
为何要加时间步条件:
在扩散模型中,不同的去噪步骤 k 与噪声水平息息相关。若不告诉网络当前是在“第几步”,它无法分辨应该执行怎样程度的去噪。
将 MLP 处理后的 proprio embedding 与 time‐step embedding 拼接(或相加),得到最终的条件向量 ck
这样,每一条训练/推理样本不仅有噪声输入,还能同时拿到“现在我处于哪个扩散步骤 + 当前本体感觉如何”的双重信息,从而自适应地调节Transformer 的行为
标准 LayerNorm 计算每个样本的特征均值 μ 和标准差 σ,归一化后再做计算,其中 γ,β 是可学习参数,用于 全局尺度与位移。
在 FiLM(Feature‐wise Linear Modulation)或 AdaLN(Adaptive LayerNorm)中,γ,β 不再是固定的,而是由条件向量 ck 通过一支小型网络 回归 (linear → split)得到,这样即可让 LayerNorm 对不同步骤/本体状态 动态调整。
为什么要额外的 α?
数字稳定性:直接把 FiLM 输出加到主干网络上,可能引入过大/过小的梯度;
训练鲁棒性:可学习的 α 可以在训练初期减小残差分支的权重,等主干稳定后再放大,避免梯度爆炸或失效
Raw Proprio States ──► [2‐layer MLP] ──► proprio_emb ─┐├─► concat ─► c_k ─► [γ,β ← MLP] ─► Adaptive LN
Sinusoidal k ──► [Fourier + MLP] ──► timestep_emb ─┘ │ │└─────► α (scalar) ─► Residual Scale对于视觉/深度/触觉等输入,我们引入 多头注意力池化 → MLP,在降低token长度的同时,有选择地提取关键特征。每种传感输入使用 8 个可学习查询。该重采样器既保证特征表达,又加速多步去噪,尤其适合“多视角+历史帧+多模态”这类灵巧操作场景。
将通用策略的离散化动作与对应时刻的“加噪动作”拼接,通过线性层投影到共享潜在空间。该思路源自视频预测模型,将已知帧与噪声帧拼接以预测未来。对通用模型的任务/动作潜向量做线性映射以对齐隐藏空间,方法简单高效,且保留了 VLA 原有位置编码。最终,将映射后的通用潜向量与重采样观测嵌入拼接,作为交叉注意力层的键/值输入。
多源条件化让专用策略能高效利用全面上下文,实现更加信息驱动的决策。
考虑到通用与专用模型推理时异步运行(一次通用推理,多次专业输出),我们设计了滑动窗口条件化,以兼顾时序连贯与计算效率。
具体流程:专用模型推理 τs 步后,仅保留通用策略最近 kg−τs 步动作作为下次条件,形成滑动时间窗(滑动窗口)。
该滑动观测窗既保证通用高层规划与专用低层执行的对齐,也降低了时间错位的风险。
为提升 RoboDual 对真实延迟波动的鲁棒,我们将其融入延迟感知训练增强中。专用策略在训练时故意拿到比通用策略“快 τ 步”的观测,模拟两者推理过程不同步的场景,从而让专用策略学会预测未来 τ 步的环境状态,以便在实际部署中及时跟上通用策略粗慢的高层指令。
若通用模型在时间 t 输出高层指导信号(如动作 token 或潜在向量),专用策略此时看到的是时刻 t+τ 的观测;当 τ=0,就完全同步;当 τ>0,就属于“领先”观测。
具体地,设 τ=2,专用策略在训练时看到的是时刻 5、6 的图像和传感;通用策略输出的指导却是基于时刻 3 的高层意图。
专用策略要结合 5、6 的观测来推断:时刻 3 → 时刻 5 环境发生了什么变化,从而正确地执行第 3 步和第 4 步的动作。
通过上述设计,RoboDual 的专用策略不仅会“听懂”高层通用模型的意图,还能“预判”并补偿两者在时间上的错位,从而在实际部署中实现鲁棒、高效的闭环控制。(真实实验时,让他自己学会在还没收到通用输出时预测若干步,从而连续控制)
3.3 训练和推理阶段的具体流程和配置
通用训练
我们沿用了 OpenVLA 所采用的离散标记预测方法,这与 only-解码器 的大型语言模型的 next-token 预测预训练目标天然契合。
模型 g ϕ gϕ gϕ 接收提示 p p p 和真实动作前缀 a<i,通过最小化下一标记负对数概率之和来训练:
L g e n = E [ − ∑ i = 1 N a l o g P ( a i = a i ∣ p , Lgen=E[−∑i=1NalogP(a^i=ai∣p, Lgen=E[−∑i=1NalogP(ai=ai∣p, a<i)]
其中 N a N_a Na 为动作标记总长度。推理时,通用策略以自回归方式,仅依据先前生成的标记 ^a<i 来解码下一个动作标记 ^a<i
这种训练方式几乎与“语言建模”一模一样,只不过“词典”里新增了动作标记。
相较于回归损失(直接预测连续动作值),离散标记损失更稳定,也能直接利用现有 LLM 架构与优化器。
专用训练
继 Diffusion Policy(Chi 等,2023),我们以动作去噪目标训练专用策略。设来自数据集 Da 的初始轨迹 a0 时长为 ks,随机噪声 ϵ∼N(0,I),及时间步 t∼U(1,100),前向扩散为
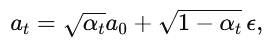
其中 αt 为单步加噪系数。训练时最小化:
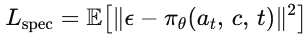
使模型学习从加噪动作 at 中恢复噪声 ϵ,从而得到干净动作。
我们尝试从零开始训练轻量级专用模型,仅 20M 可训练参数,训练耗时约 8 GPU-小时,即可在双系统中获得 17% 的性能提升,相比仅对 VLA 单独额外训练数天所获 10% 增益更为显著。更细的在附录和4.4中。
什么硬件?
4. 实验
我们做了很多实验,来看看我们的方法效果好不好,特别是它在通用性、效率和适应能力方面表现如何。
在4.2 中:研究 RoboDual 是否比以前的方法在模拟和现实测试中成功率更高?
在4.3 中:研究 RoboDual 是否具备通用的操作能力?
在4.4 中:RoboDual 的适应能力和推理效率如何?
在4.5 中:双系统的协同作用是怎么产生的?
4.1 评估环境
在 CALVIN 上进行仿真实验
CALVIN是一个广泛认可的模拟基准,用于评估长时序、基于语言指令的操作任务。
我们的目标是通过自由格式的语言指令,展示系统在多任务学习下的通用性。
此外,我们研究专用模型如何利用多种输入模式,不仅仅局限于通用模型的第三视角 RGB 图像,以提升操作性能。
有关基准测试和实现细节的更多信息,请参见附录 A。
真实机器人实验
所有真实环境实验都在一个 ALOHA 平台上进行,该平台具有 7 自由度(DoF)的运动空间,并配备一个第三视角 RGB 相机。
我们评估策略在单指令任务(例如 “Lift the pod lid”、“Pour shrimp into bowl”、“Push block Left”)和多指令任务(例如 “Put (obj) into basket”、“Knock (obj) over”)上的表现。
此外,我们提出了一套涵盖多种通用性考察维度的评估任务:1)位置变化;2)视觉干扰;3)未见过的背景;4)新颖物体。
草莓的晃动、叶子遮挡、光斑、换一个草莓园场景(不同棚架、不同地面)、奇形怪状的草莓(或新品种)
每个任务根据难度使用“瞬移”方式采集 20 到 120 条示范数据。
瞬移(teleportation):在模拟中直接把机器人摆到不同初始状态,而不需要它自己移动过去,省时高效。
为了建立基准,我们选取了最先进、最常用的专用策略 ACT和 Diffusion Policy,以及通用模型 Octo 和 OpenVLA 进行对比分析。
为了更清晰地对比,我们的方法是:先让通用模型在所有任务上训练,然后再分两种方式训练专用模型——一种用单任务数据,一种用多任务数据。再在特定场景上进行微调以优化性能。
对于所有任务,我们在 15 次独立实验中计算平均成功率并报告。更多细节请参见附录 A。
4.2 与最先进方法的比较
CALVIN 基准测试。
我们在 CALVIN ABC→D 上,将 RoboDual 的表现与其他最先进的方法进行比较。
ABC→D 表示在 A、B、C 三组任务上训练,然后在 D 组任务上测试
对草莓机器人而言,就相当于先用三种类型的草莓采摘场景(不同光照、不同果实密度、不同植株姿态)来训练,再在第四种全新场景(如不同品种草莓、不同棚架结构)中测试。
结果见表 1。我们完成任务的平均长度从 3.27 提升至 3.66。
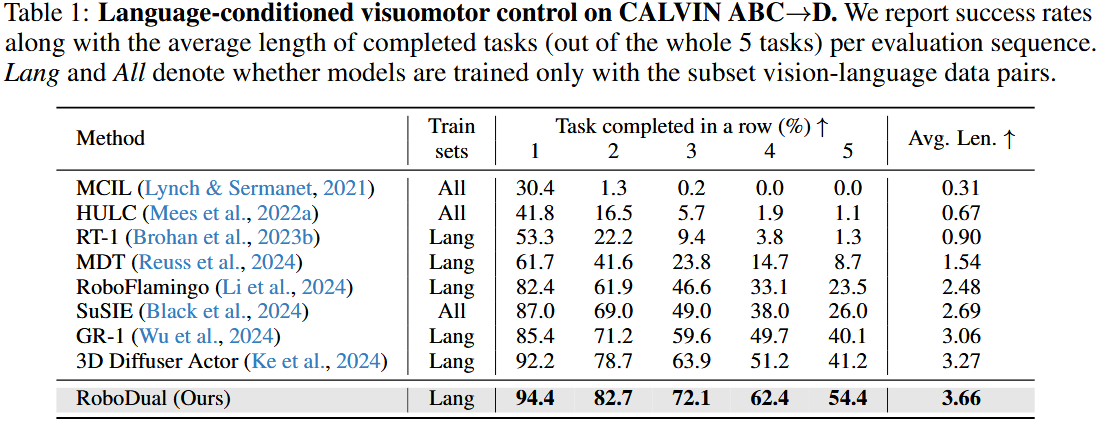
连续完成 5 步任务的成功率提高了 13.2%。 “定位草莓 → 伸出机械臂 → 夹取草莓 → 摘下草莓 → 放入收纳”
此外,我们进一步考察了各方法对不完全标准任务指令的鲁棒性,结果见表 2。
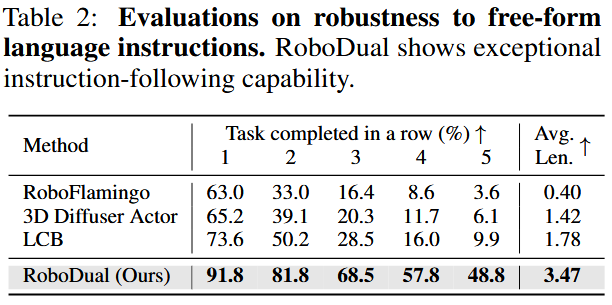
所有方法都仅在 ABC 组任务及其原始语言标注上训练,并使用由 GPT-4 丰富的语言指令进行评估。
尽管 RF 和 LCB 方法在使用丰富指令时表现相比表 1 大幅下降,我们的方法几乎不受影响,且相比 LCB 在平均完成长度上几乎翻倍。
这一提升得益于通用模型的语义理解能力以及专用模型对条件潜变量变化的鲁棒性。
条件潜变量:模型内部用来表达指令信息的“向量”表示。专用模型对这些向量的微小变化不敏感,确保稳定执行。
真实环境实验
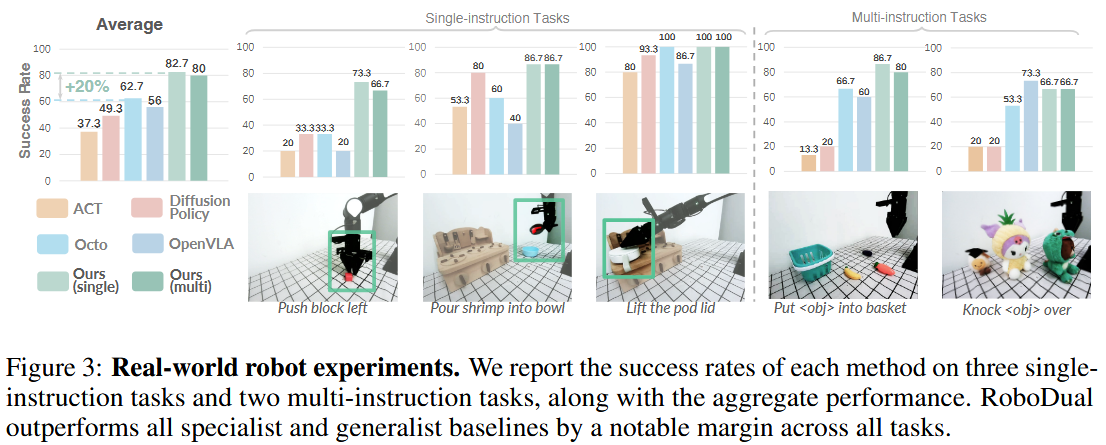
最先进的专用策略 Diffusion Policy 在更灵巧但定义较窄的任务上控制更平滑、成功率也很高。然而,它在多指令任务上表现不佳——在 “Put into basket” 这类任务中成功率仅为 20%。
相比之下,使用 OpenX 预训练的通用模型(Octo 和 OpenVLA)在涉及多物体、需要语言指令的多样化任务上表现更好。但对于 OpenVLA 来说,其对数据的需求量大以及推理速度慢,可能是限制其整体性能的主要瓶颈。其较高的推理延迟还会导致动作抖动和停顿,削弱其在精细控制任务上的表现。
RoboDual 利用通用模型的高层推理能力来引导专用模型实现平滑控制,在单指令和多指令任务上均表现出色。
RoboDual 对比先前最好的那一套方法,整体成功率高出 20 个百分点,并在所有任务中都能保持至少 60% 的成功率。
4.3 泛化能力评估
我们从四个不同维度评估 RoboDual 及基准方法的通用性,详见图 4。

位置泛化、视觉干扰、背景变化、新物体:
不同棚架布局、不同光照、不同草莓品种以及不同地面
详细的结果见表 3。
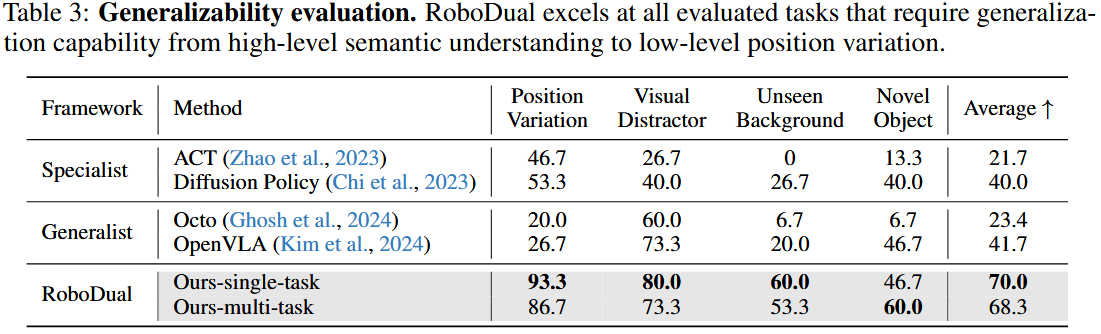
在需要位置泛化的“将方块放入碗中”任务里,专用策略和 Octo 都对某些测试位置表现出明显偏好,这可能是因为训练时各位置示范数据分布不均(训练时“方块在左侧”的示范很多,但“方块在右侧”的示范很少,导致偏差)造成的。
草莓机器人如果只学了“草莓在树顶”的示范,却在“草莓长在底部”时摘不下来,就说明存在位置偏好。
虽然 OpenVLA 能朝正确方向移动,但由于控制更新频率不足,它无法快速调整末端执行器,常常在夹取前就把物体推偏了。
相比之下,RoboDual 的多任务和单任务版本在这一挑战性任务上都表现出色。
分别指 Ours-multi-task 和 Ours-single-task,前者用混合数据训练,后者用专一数据训练。
我们还注意到,RoboDual 具有错误纠正能力:若第一次尝试失败,会再次尝试重新夹取,录像演示中可见这一点。
视频演示:
https://robodual.github.io/resources/robodual/generalization/put_block/10demos_ood_regrasp.mp4
此外,多亏利用了大规模预训练的 VLMs,RoboDual 在需要高层泛化的任务上(如“视觉干扰”和“新物体”)超越了 ACT 和 Diffusion Policy。
草莓机器人在叶片密集遮挡下或遇到新培育的草莓品种时,都能正确识别并采摘。
这些结果展示了 RoboDual 在多种场景下的卓越通用能力。
4.4 效率分析
训练效率
我们首先研究 RoboDual 在新环境下的高效适应能力,详见图 5。图中横轴向左代表训练时长增加。
“仅通用模型”和“仅专用模型”这两种变体,都是严格按照我们框架中的配置来实现,以保证公平对比。为了让专用模型在 CALVIN 上支持多任务学习,我们使用 T5-xxl对任务指令进行编码,并将生成的语言嵌入与视觉观测拼接后作为条件输入。
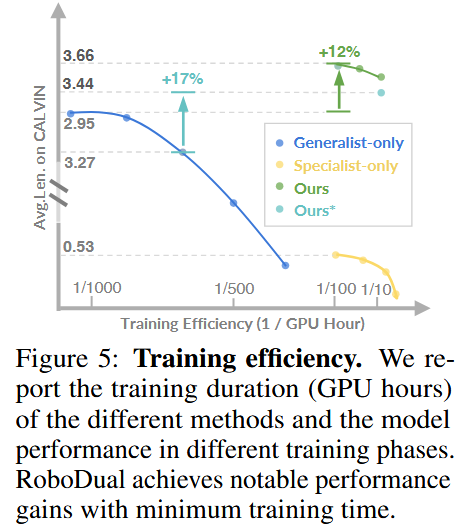
仅通用模型在 CALVIN 上大约经过 1 400 GPU 小时训练后,性能稳定在 3.27。在此基础上,RoboDual 结合了仅有 2 000 万可训练参数的专用模型,在一台配备八块 A100 的节点上仅用 1 小时训练,就将性能提升到 3.52。
我们的方法最终在已充分训练的通用模型之上,再额外提升了 12% 性能。这些结果表明,RoboDual 是一种成本效益极高的方法——只需极少训练就能显著提升性能。
数据效率
接着我们研究专用模型在有限的领域内数据下如何高效适应新环境并提升整体性能。
在CALVIN 上的结果见表 4(a)。表中有 5%、10%、100% 数据量对应的平均完成长度。
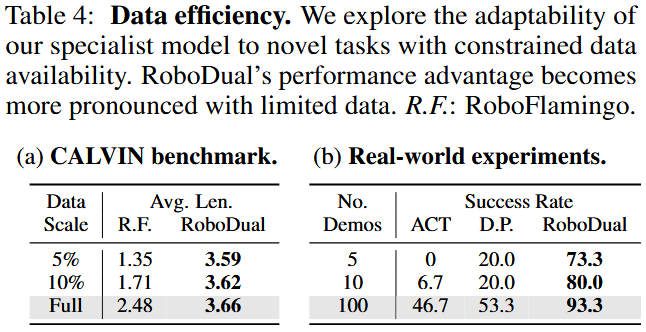
我们选取同样利用大规模 VLM 的 RoboFlamingo 作为对比对象。我们先用 RoboFlamingo 在全量 CALVIN 数据上训练好的官方检查点做初始化,然后重置其基于 LSTM 的动作解码头,用子集数据重新训练。
当只使用 5% 示范时,RoboFlamingo 的性能几乎下降一半,而 RoboDual 在有限数据下仍保持稳定,平均完成长度为 3.59,展现出卓越的数据效率。
我们的方法优势在真实环境实验中也得到验证。表 4(b) 中,我们选取“将方块放入碗中”作为示例任务。
仅用 5 条示范训练,RoboDual 就达到了 73.3% 的成功率,是 Diffusion Policy(D.P.)性能的三倍多。相比之下,ACT 在如此有限的示范下完全无法抓起方块。
此外,还能在训练集中方块未出现过的位置上取得成功,仅用 5 条示范就能做到。
推理延迟分析
在真实环境实验中,我们让通用模型只输出一个动作(第 8 步),随后由专用模型以 0.035 秒的延迟连续快速推理八步。
相应地,RoboDual 在我们使用 NVIDIA A5000 Ada GPU 的真实部署中,可达 15 Hz 的控制频率,利于执行更灵巧的任务。
值得注意的是,推理延迟是 OpenVLA 性能下降的主要原因。在我们的系统中,OpenVLA 仅能以 3.9 Hz 运行,相较于真实任务中使用的 20 Hz 非阻塞控制器,系统动态变化显著。
可以看到,OpenVLA 常因无法在抓取前精确调整末端执行器位置,导致需要精细控制的任务(如“将方块放入碗中”)成功率较低(见表 3)。
因此,我们认为 RoboDual 是在多种机器人应用中部署大型 VLA 的有效且简便的方案。
在项目页面中提供了视频演示,以更直观地展示 RoboDual 在真实场景下的表现。
4.5 消融实验
本节通过消融实验,剖析不同设计要素对 RoboDual 协同效能的贡献。
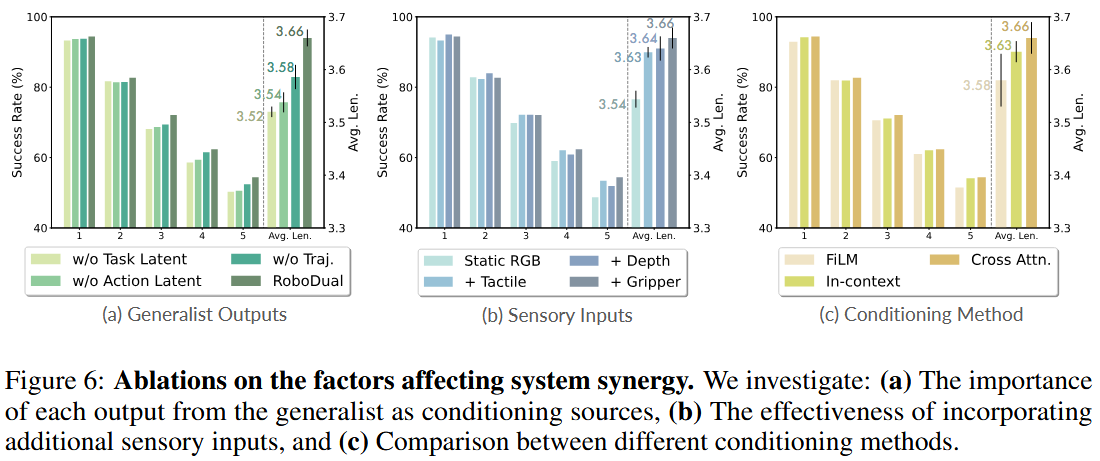
通用输出作为条件
将通用模型的多种输出(如粗略轨迹、动作潜变量、任务潜变量)传给专用模型,作为决策依据。图 6(a) 显示,通用模型提供的每一种条件信息都对协同增效有所贡献,并提升了整体性能。
尽管离散化的轨迹并不总是完美,但它们能提供合理的大致方向,专用模型可在此基础上迭代优化,从而带来约 0.8 的性能提升。此外,动作潜变量和任务潜变量(见图 2)分别承载了高层次的动作语义和任务信息,这对多任务学习至关重要。仅缺少任务潜变量就会导致平均完成长度下降约 0.14。(3.66-3.52)
额外感知输入
针对特定场景向专用模型添加额外传感输入,被证明是一种高性价比的策略。
我们的方法无需再对大型视觉-语言-动作模型(VLA)进行额外微调,同时不损失专用模型的推理效率。
草莓机器人直接在专用模块接入触觉与深度,无需重新训练通用的视觉语言模型。
如图 6(b) 所示,RoboDual 有效利用额外模态(如深度和触觉)以及额外视角(如夹爪摄像头),提升了整体性能。
条件传递方法
通用模型与专用模型之间的“桥梁”是通过稳健的条件传递机制搭建的。
我们评估了三种成熟的条件传递方法:FiLM、上下文条件和交叉注意,结果见图 6©。
基于交叉注意的方法在性能上略优于上下文条件,同时计算效率更高,因此我们最终采用它。
5. 结论与未来工作
我们提出了 RoboDual,一种协同双系统机器人操作框架,兼具视觉–语言–动作(VLA)模型的通用性与专用策略的效率和适应性。
我们设计的基于扩散变换器的专用模块能够实现更精细的控制,高效接入任意传感输入,并以极少的数据和训练代价适应多样化任务及异构环境。
通过协同合作,RoboDual 有效克服了现有 VLA 方法的若干局限,为大型通用策略的实际部署提供了一种经济高效且广泛适用的解决方案。
但是在当前 RoboDual 框架中,我们假设通用模型与专用模块的推理时间保持恒定。因此,在部署阶段,每次通用模型推理都会对应固定次数的专用模块推理。
此外,目前通用模型仅输出离散化的动作序列。鉴于自回归 VLA 的可扩展性,通用模型未来可进一步训练以实现任务分解、可行性标注 和目标图像生成。这些功能可作为强有力的补充,为通用模型与专用模块之间构建更优的“桥梁”。
未来方向:任务分解
让通用模型学会把复合指令拆成子任务序列,再交给专用模块精细执行。
自动将“摘完果园这排所有成熟草莓”拆分为“定位下一个草莓→夹取→放入篮子”循环子任务。
未来方向:可行性标注
通用模型能够从图像中标注可抓取部位,指导专用模块更好定位。
标注草莓果蒂位置和可抓取枝条,为专用模块提供精准抓点。