召回12:曝光过滤 Bloom Filter
曝光过滤问题
如果用户看过某个物品,就不再把该物品曝光给用户。重复观看同一个物品会降低用户的体验,但是在例如 youtube 之类的长视频平台,往往不适用曝光过滤。
对于每个用户,记录最近 1 个月内曝光给他的物品(小红书只会召回最近 1 个月以内的笔记,因此只需要记录 1 个月的曝光历史)。记录更长时间曝光的物品收益不大,资源消耗很大,性价比不高。
对于每个召回的物品,判断是否已经被曝光过,排除掉已经曝光过的物品。
一个用户看过 n n n 个物品,本次召回 r r r 个物品,如果暴力对比,需要 O ( n r ) O(nr) O(nr) 的时间。太慢!使用 Bloom Filter 进行优化。
Bloom Filter
判断一个物品 ID 是否是已曝光的物品。
判断为 no,一定不在。
判断为 yes,很可能在,但是有误伤的可能性。
如果只留下 no 的,虽然可能会有误伤,但是一定会把已曝光的排除。在海量数据下这个误伤的影响是微乎其微的。
判断方法:设长度为 m m m 的二进制向量,使用 k k k 个哈希函数,将已曝光的物品使用 k k k 个哈希函数所得到位置全部置为 1,如果新物品使用这 k k k 个哈希函数有至少一个位置不为 1,那么这个物品一定还未曝光,这时误伤概率也很小了。很显然, 物品个数 n n n 越大越容易误伤,向量长度 m m m 越大哈希碰撞概率越小。误伤的概率为 δ ≈ ( 1 − exp ( − k n m ) ) k \delta \approx \left( 1 - \exp \left( - \frac{kn}{m} \right) \right)^{k} δ≈(1−exp(−mkn))k ,则最优参数为 k = 1.44 ⋅ ln ( 1 δ ) k = 1.44 \cdot \ln\left( \frac{1}{\delta} \right) k=1.44⋅ln(δ1), m = 2 n ⋅ ln ( 1 δ ) m = 2n \cdot \ln\left( \frac{1}{\delta} \right) m=2n⋅ln(δ1)
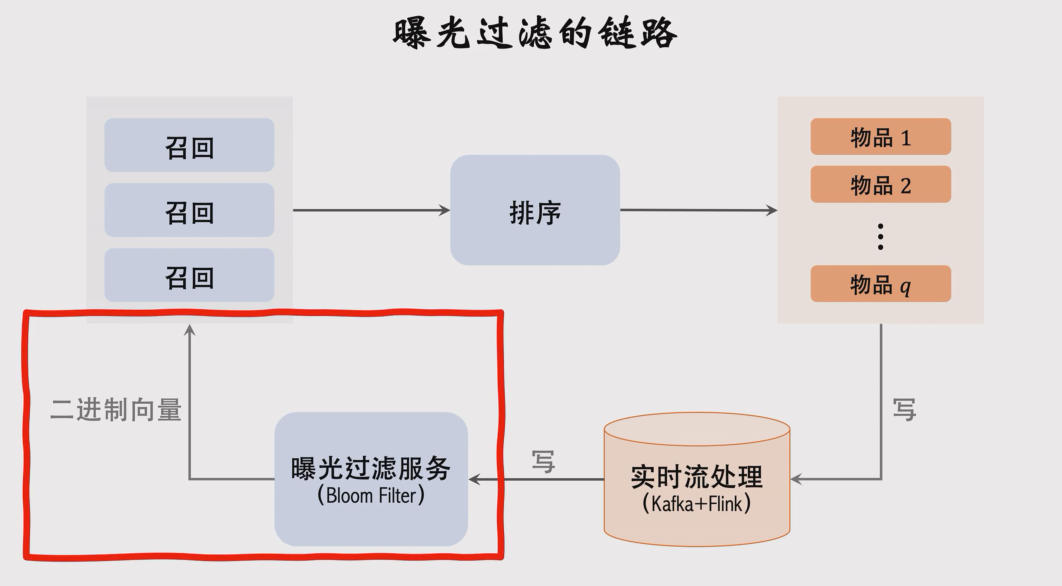
实时流处理一定要快,否则可能会出现用户两次刷新出现同样的内容。
Bloom Filter的缺点
只支持添加物品,不支持删除物品。从集合中移除物品,无法消除其对向量的影响。每天都需要移除时间大于 1 个月的物品,想要删除一个物品,需要重新计算二进制向量,这就有些慢了。