MiniLLM:大型语言模型的知识蒸馏
Abstract
知识蒸馏(KD)是一种极具前景的技术,能够有效降低大型语言模型(LLMs)的高计算需求。然而,现有的KD方法主要应用于白盒分类模型,或通过训练小模型来模仿ChatGPT等黑盒模型API。如何将白盒LLMs的知识有效蒸馏到小模型中仍待深入探索——随着开源LLMs的蓬勃发展,这一问题显得愈发重要。本研究提出了一种将LLMs蒸馏至小型语言模型的创新方法。我们首先将标准KD方法中采用的前向Kullback-Leibler散度(KLD)目标替换为反向KLD,该指标更适用于生成式语言模型的蒸馏,可防止学生模型高估教师分布的低概率区域;进而推导出针对该目标的有效优化方法。经蒸馏的学生模型命名为MINILLM。在指令跟随任务中的大量实验表明:相较于基线模型,MINILLM能生成响应精度更高、整体质量更优、暴露偏差更低、校准性更好且长文本生成能力更强的输出。该方法具有显著的可扩展性,可适用于1.2亿至130亿参数规模的不同模型家族。相关代码、数据及模型检查点已开源:https://github.com/microsoft/LMOps/tree/main/minillm。
1 Introduction
随着大型语言模型(LLMs;BMR+20,HZD+21,BHA+21,CND+22,Ope23)的快速发展,知识蒸馏(KD;HVD15)作为降低其高计算资源需求的常用技术,通过使用大型教师模型监督训练小型学生模型来实现。当前主要采用两类蒸馏方法:黑盒KD(仅能获取教师模型生成的文本)和白盒KD(可访问教师模型的输出分布或中间隐藏状态)[JBMD21]。近期研究表明,基于LLM应用程序接口生成的提示-响应对进行小模型微调的黑盒KD已取得显著成果[TGZ+23,CLL+23,WWZ+23,PLH+23]。随着开源LLMs的涌现[ZRG+22,TLI+23],白盒KD对学术界和工业界价值愈发凸显——由于学生模型能从教师模型的输出分布和隐藏状态中获取更优质的信号,其性能潜力可得到显著提升。然而现有白盒KD研究主要针对参数量小于10亿的语言理解模型[SDCW19,WWD+20],针对LLMs的白盒KD仍属空白领域。
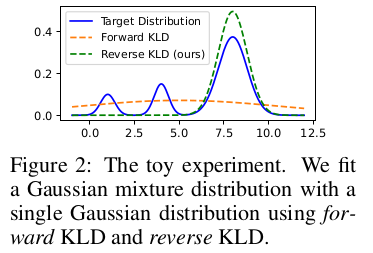
本研究重点探讨可获取教师模型输出分布的白盒LLM蒸馏。我们认为标准KD目标函数[KR16,SST+20,CLL+23,TGZ+23]对生成式任务的LLMs并非最优解。给定教师分布p(y|x)和参数化学生分布qθ(y|x),标准KD目标(包括序列模型的若干变体)本质上是最小化教师与学生分布之间的近似前向Kullback-Leibler散度(KLD),即KL[p||qθ],这会强制qθ覆盖p的所有模态。对于输出空间仅含有限类别(p(y|x)和qθ(y|x)模态较少)的文本分类任务,KL[p||qθ]效果良好;但在LLMs常见的开放域文本生成任务中,由于模型容量限制,复杂输出空间中p(y|x)的模态数量远超qθ(y|x)表达能力。最小化前向KLD会导致qθ对p的空白区域赋予过高概率[MG19],并在自由生成时产生p分布下极不可能出现的样本[Hus15]。
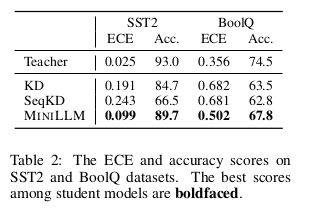
为解决该问题,我们提出最小化已在计算机视觉[LPSK23]和强化学习[CPO19]领域广泛应用的反向KLD(KL[qθ||p])。如表2及第2.1节所述,相较于KL[p||qθ],最小化KL[qθ||p]会使qθ捕捉p的主要模态,并对p的空白区域赋予低概率[M+05]。在LLM文本生成中,这意味着学生模型避免学习教师分布中过多长尾变异[HBD+20],转而聚焦生成内容的正确性——这对需要真实性与可靠性的实际场景至关重要[JLF23]。如第2.2节所示,为优化minθ KL[qθ||p],我们通过策略梯度[SMSM99]推导目标函数的梯度。为进一步稳定和加速训练,我们提出:(1)单步分解降低方差,(2)教师混合采样缓解奖励破解,(3)长度归一化消除长度偏差。最终在第2.3节给出完整KD算法。经蒸馏的学生模型命名为MINILLM,表明该方法适用于压缩大型(生成式)语言模型且效果显著。
我们在涵盖多种NLP任务的指令跟随场景[SWR+22,WBZ+22]中,将方法应用于参数量1.2亿至130亿不等的各类生成式语言模型[RWC+19,ZRG+22,TLI+23]。实验采用5个数据集,通过Rouge-L[Lin04]、GPT-4反馈和人工评估进行验证。结果表明MINILLM在所有数据集上均稳定优于标准KD基线,且从1.2亿到130亿模型均展现良好扩展性(见图1)。进一步分析显示,MINILLM具有更低的暴露偏差、更优的校准性、更强的长文本生成能力,且多样性损失可忽略不计。
2 Method

2.1 MINI LLM: Knowledge Distillation with Reverse KLD

2.2 Optimization with Policy Gradient
