【AI论文】PHYBench:大型语言模型中物理感知与推理能力的全面评估
摘要:我们介绍了一种新颖的高质量基准,即PHYBench,旨在评估大型语言模型(LLMs)在物理环境中的推理能力。 PHYBench由500个精心策划的物理问题组成,这些问题基于现实世界的物理场景,旨在评估模型理解和推理现实物理过程的能力。 该基准涵盖了力学、电磁学、热力学、光学、现代物理学和高等物理学,难度范围从高中练习到本科问题和物理奥林匹克竞赛挑战。 此外,我们提出了表达式编辑距离(EED)分数,这是一种基于数学表达式之间编辑距离的新颖评估指标,它有效地捕捉了模型推理过程和结果之间的差异,超越了传统的二元评分方法。 我们在PHYBench上评估了各种LLM,并将其性能与人类专家进行了比较。 我们的研究结果表明,即使是最先进的推理模型也明显落后于人类专家,突出了他们的局限性以及在复杂的物理推理场景中需要改进。 我们的基准测试结果和数据集可以在phybench-demo/上公开获取。Huggingface链接:Paper page,论文链接:2504.16074
研究背景和目的
随着人工智能技术的迅速发展,大型语言模型(Large Language Models, LLMs)在理解和生成自然语言方面取得了显著进步。然而,尽管LLMs在文本生成、问答系统等任务中表现出色,它们在理解和推理物理世界方面的能力仍然有限。物理感知与推理能力是人类智能的重要组成部分,它涉及对物理世界的深刻理解、对物理定律的准确应用以及复杂的符号推理。为了推动LLMs在物理领域的发展,需要一种能够全面评估其在物理环境中推理能力的基准。
当前,尽管已经存在一些用于评估LLMs推理能力的基准,如MathArena等,但它们主要集中在数学和逻辑推理领域,缺乏对物理感知和推理能力的针对性评估。此外,这些基准往往采用二元评分方法,即仅判断模型输出是否正确,而无法深入评估模型推理过程的准确性和完整性。因此,开发一种能够全面评估LLMs在物理环境中推理能力的新基准显得尤为重要。
PHYBench正是为了填补这一空白而设计的。它旨在通过一系列精心策划的物理问题,全面评估LLMs在物理感知和推理方面的能力。这些问题涵盖了力学、电磁学、热力学、光学、现代物理学和高等物理学等多个领域,难度从高中练习题到本科问题和物理奥林匹克竞赛挑战不等。通过评估LLMs在这些问题上的表现,我们可以深入了解它们在物理感知和推理方面的能力水平,并为未来的模型改进提供指导。
研究方法
数据集构建
PHYBench数据集由500个精心策划的物理问题组成,这些问题均基于现实世界的物理场景。为了确保问题的质量和多样性,我们采取了以下措施:
-
问题来源:我们邀请了178名北京大学物理学院的学生参与问题的贡献和精炼。这些问题主要来源于学生的物理练习和竞赛题目,经过改编后适应于LLMs的评估需求。
-
问题要求:所有问题都必须满足以下要求:
- 文本可解性:问题必须完全通过文本描述解决,不允许使用图表或多模态输入。
- 严格符号答案:解决方案必须是单一、明确的符号表达式(如2mg + 4mv²₀/l),允许不同的等价形式。
- 表述清晰:问题的表述必须严格精确,避免歧义。
-
多轮学术评审:问题经过三轮学术评审,包括初始过滤、歧义检测和修订以及迭代改进循环。最终,我们邀请了81名北京大学的学生独立解决数据集中的问题,以建立人类基线性能。
评估指标
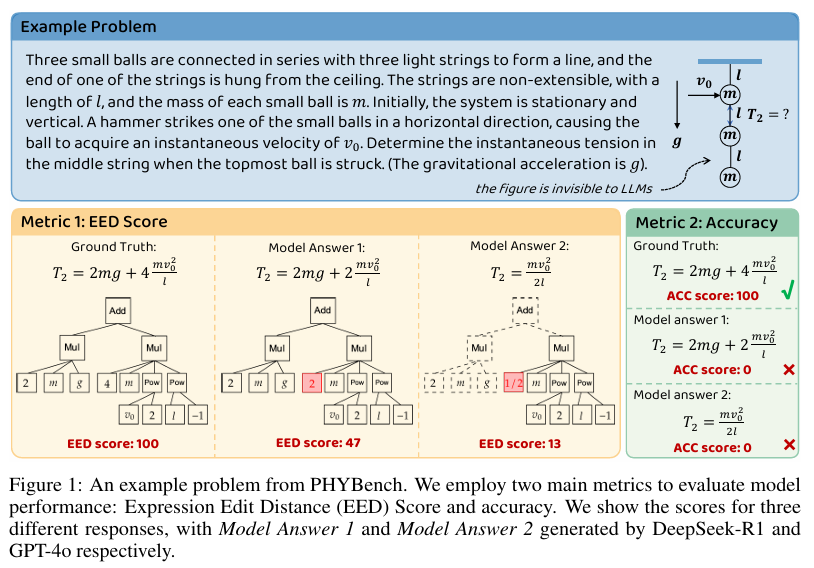
除了传统的准确率(Accuracy)指标外,我们还提出了表达式编辑距离(Expression Edit Distance, EED)分数作为一种新的评估指标。EED分数基于数学表达式之间的编辑距离,能够更有效地捕捉模型推理过程和结果之间的差异。
-
简化表达式:首先,将标准答案(gt)和模型生成答案(gen)从LaTeX格式转换为与SymPy兼容的格式,并使用simplify()函数进行简化。
-
等价性检查:如果简化后的gt和gen表达式相同,则EED分数为100,表示完全正确。
-
树转换和编辑距离计算:如果表达式不同,则将它们转换为树结构,并使用扩展的Zhang-Shasha算法计算它们之间的最小编辑距离。
-
相对编辑距离和评分:计算相对编辑距离r(编辑距离与标准答案树大小的比率),并根据r的值确定EED分数。
研究结果
我们在PHYBench上评估了多种LLMs,包括Gemini 2.5 Pro、o3、DeepSeek-R1等,并将它们的性能与人类专家进行了比较。研究结果表明:
-
性能差距:即使是最先进的推理模型,如Gemini 2.5 Pro,在PHYBench上的表现也显著落后于人类专家。这表明LLMs在物理感知和推理方面仍然存在很大的局限性。
-
EED分数的优势:EED分数相比传统的准确率指标具有更高的样本效率。在500个问题上使用EED分数进行评估,其判别力相当于在大约1500个问题上使用准确率指标。
-
模型性能分析:不同模型在不同物理领域和难度级别上的表现存在差异。例如,Gemini模型在解决难题方面表现出色,而在较容易的问题上则与其他模型表现相当。
-
错误分析:我们将模型在PHYBench上的错误分为物理感知(PP)和鲁棒推理(RR)两类。PP错误主要涉及对物理过程和模型技能的不足理解,而RR错误则涉及在复杂推理过程中保持一致性以及准确解决方程的能力。
研究局限
尽管PHYBench在评估LLMs物理感知与推理能力方面取得了显著进展,但仍然存在一些局限性:
-
数据集规模:尽管PHYBench包含了500个问题,但相对于物理学的广阔领域来说,这一规模仍然有限。未来需要进一步扩大数据集规模,以更全面地评估LLMs的物理推理能力。
-
评估指标:尽管EED分数相比传统的准确率指标具有更高的样本效率,但它仍然是一种基于数学表达式的评估方法。未来需要探索更多元化的评估指标,以更全面地评估LLMs的物理感知与推理能力。
-
模型类型:本研究主要评估了基于Transformer架构的LLMs。未来需要探索其他类型的模型(如图神经网络、记忆增强模型等)在PHYBench上的表现。
未来研究方向
针对上述局限性,我们提出了以下几个未来研究方向:
-
扩大数据集规模:通过邀请更多物理学生和专家参与问题贡献和评审,进一步扩大PHYBench数据集规模,以更全面地评估LLMs的物理推理能力。
-
开发新评估指标:结合物理学领域的知识和认知科学的研究成果,开发更多元化的评估指标,以更全面地评估LLMs的物理感知与推理能力。
-
探索其他模型类型:评估不同类型模型(如图神经网络、记忆增强模型等)在PHYBench上的表现,探索它们在物理感知与推理方面的优势和局限性。
-
结合物理实验数据:将物理实验数据与PHYBench相结合,为LLMs提供更丰富的物理感知和推理训练信号,进一步提升它们在物理领域的应用能力。
-
推动跨学科合作:加强物理学、计算机科学和认知科学等领域的跨学科合作,共同推动LLMs在物理感知与推理方面的发展。通过跨学科的合作与交流,我们可以更深入地理解物理推理的本质和挑战,为LLMs的改进提供更有力的支持。