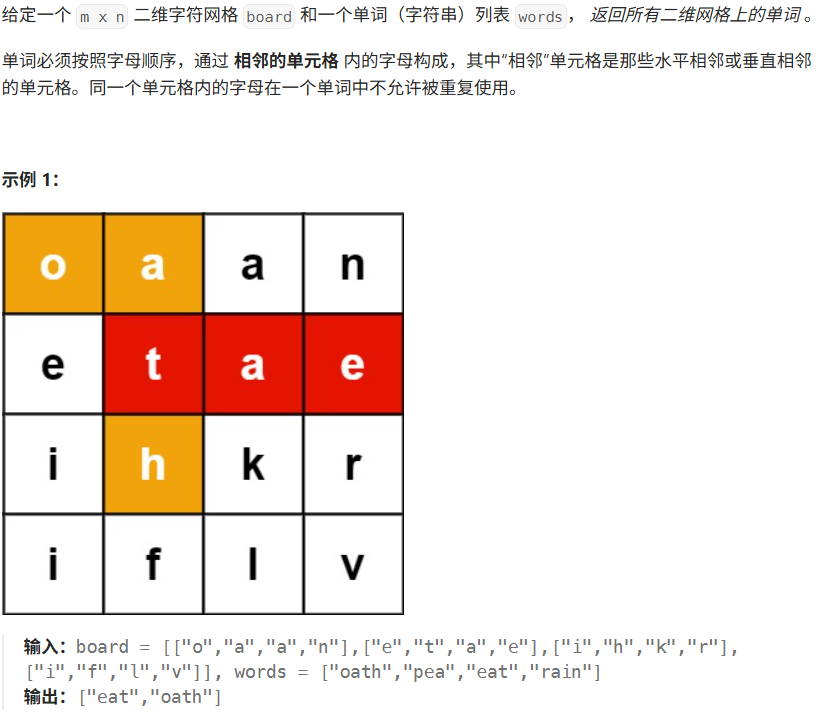
leetcode212.单词搜索II

时间复杂度可表示为 O( m×n × 4^L),其中:
m×n:网格大小;4^L:每个单词的回溯复杂度(每个字符有 4 个方向,单词长度为L)
与直接回溯对比:
直接回溯的时间复杂度可表示为 O(k × m×n × 4^L),其中:
k:单词列表的长度(如 1000 个单词);m×n:网格大小;4^L:每个单词的回溯复杂度(每个字符有 4 个方向,单词长度为L)。
问题的关键在于 k 这个因子—— 当单词列表较大(如k=1000)或存在大量公共前缀(如单词列表是["o","oa","oat","oath"])时,直接回溯会做大量 “重复工作”:
- 重复遍历网格:每个单词都要重新遍历一次网格的所有单元格,作为回溯起点;
- 重复匹配前缀:若多个单词有公共前缀(如 “oat” 和 “oath” 的公共前缀是 “o”“oa”),直接回溯会对每个单词重复匹配这些前缀。例如:
- 找 “oat” 时,要走 “o→a→t” 的路径;
- 找 “oath” 时,又要重新走 “o→a→t” 的路径,再延伸到 “h”;
- 两次回溯的前 3 步完全重复,没有复用任何计算结果。
前缀树(Trie)的核心作用是将所有单词的公共前缀 “合并存储”,让回溯从 “单词驱动” 转为 “路径驱动”—— 即遍历网格的一条路径,就能同时匹配所有含该路径前缀的单词,无需重复处理。
1. 时间复杂度优化:消去k因子
前缀树 + 回溯的时间复杂度是 O(m×n × 4^L),相比直接回溯少了k这个因子。原因是:
- 构建前缀树的时间是
O(total_char)(total_char是所有单词的字符总数,通常远小于k×L); - 回溯阶段只需遍历一次网格:从每个单元格出发,沿 4 个方向深入,每走一步就通过前缀树判断 “当前路径是否是任何单词的前缀”—— 若不是,直接剪枝(停止该方向的递归);若是,则继续深入,直到匹配到完整单词。
例如,对单词列表 ["o","oa","oat","oath"]:
- 构建前缀树后,回溯时走 “o→a→t→h” 的路径:
- 走到 “o” 时,匹配到单词 “o”;
- 走到 “oa” 时,匹配到单词 “oa”;
- 走到 “oat” 时,匹配到单词 “oat”;
- 走到 “oath” 时,匹配到单词 “oath”;
- 一条路径就完成了 4 个单词的匹配,无需对每个单词单独回溯。
class Solution {private class Trie {private TrieNode root;private class TrieNode {Map<Character, TrieNode> children;//当前节点的孩子String word;//存储完整单词,默认null,表示当前字符结尾的不是单词public TrieNode() {children = new HashMap<>();}}public Trie() {root = new TrieNode();}public void insert(String word) {TrieNode cur = root;for (int i = 0; i < word.length(); i++) {if (!cur.children.containsKey(word.charAt(i))) {cur.children.put(word.charAt(i), new TrieNode());}cur = cur.children.get(word.charAt(i));}cur.word = word;}}private int[][] dirs = {{-1, 0}, {0, 1}, {1, 0}, {0, -1}};//二维数组的四个方向private void dfs(char[][] board, int x, int y, Trie.TrieNode root, List<String> result) {//1.数组越界或者前缀不匹配或者已经访问过了,直接返回if (x < 0 || y < 0 || x >= board.length || y >= board[0].length || !root.children.containsKey(board[x][y])) {return;} else {//2.判断当前的这个字符能够作为单词的最后一个字符(注:当前字符标识是从子节点获取的),若能表示是单词直接存入结果中char ch = board[x][y];Trie.TrieNode child = root.children.get(ch);if (child.word != null) {result.add(child.word);child.word = null;}//3.标记当前字符已经访问过board[x][y] = '#';//4.四个方向递归看是否还有单词可以存入结果集中for (int[] dir : dirs) {dfs(board, x + dir[0], y + dir[1], root.children.get(ch), result);}//5.回溯,恢复单元格原始字符board[x][y] = ch;}}public List<String> findWords(char[][] board, String[] words) {List<String> result = new ArrayList<>();Trie trie = new Trie();for (String word : words) {trie.insert(word);}for (int i = 0; i < board.length; i++) {for (int j = 0; j < board[0].length; j++) {dfs(board, i, j, trie.root, result);}}return result;}
}