数据分析编程第八步:文本处理
8.1 数据介绍
情感词典 sentiment_lexicon.csv
| 字段名 | 含义 |
|---|---|
| Word | 单词 |
| Sentiment_Score | 情感打分,正面情绪最高 5 分,负面情绪最低 -5 分 |
8.2 找出客户反馈信息中的高频词汇
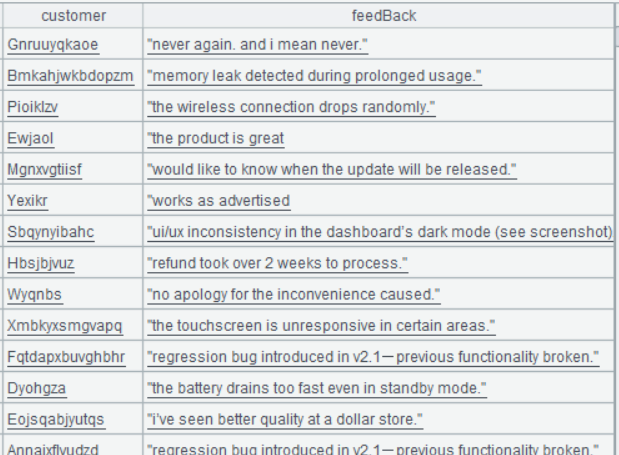
第一步:读数,把反馈信息中的字符统一成小写,且去掉两端的空白字符
| A | |
|---|---|
| 1 | =file(“sales.csv”).import@tc(customer,feedBack) |
| 2 | =A1.run(feedBack=trim(lower(feedBack))) |
A1 的运行结果:
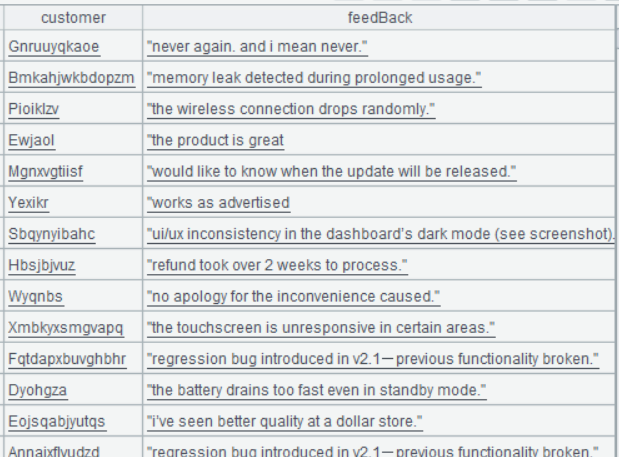
A2 trim() 函数去掉字符两端的空白符,lower 函数把字符串变成小写。
A2 的运行结果:
第二步:将反馈信息变成单词序列,然后按单词分组统计出现的频次
| A | |
|---|---|
| 3 | =A2.conj(feedBack.words()) |
| 4 | =A3.groups(~:value;count(1):Count) |
| 5 | =A4.sort(-Count) |
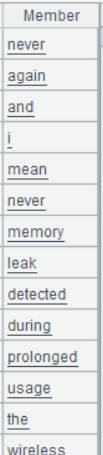
A3 feedBack.words()表示将 feedBack 变成单词序列,conj() 函数将序列的序列合并成一个大序列
A3 的运行结果:
A4 将 A3 按单词分组汇总,统计每个单词出现的频次
A4 的运行结果:
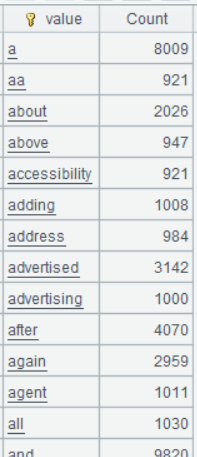
A5 按单词出现的频次逆序排序,出现频次高的排在前面
A5 的运行结果:
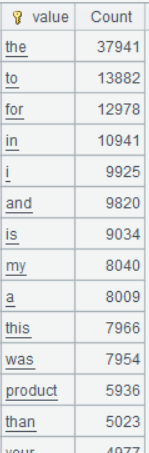
第三步:去掉无意义的词汇
从 A5 的结果可以看出,大量的介词、连词、定冠词等无业务意义的词汇出现频次很高,需要将这些词汇剔除:
| A |
|---|---|
| 6 | [the,to,for,in,i,and,is,my,a,this,was,than,as,after,no,you,would,s,by,never,of,with,up,me,during,it,t,be,on,will,even,please,d,v,or,your] |
| 7 | =A6.sort() |
| 8 | =A5.select(!A7.contain@b(value)) |

A8 从 A5 中选出 value 不在 A7 中的记录,A7.contain@b(value) 中 @b 选项表示,当 A7 按 value 有序时,采用二分法查找,效率更高。
A8 的运行结果:
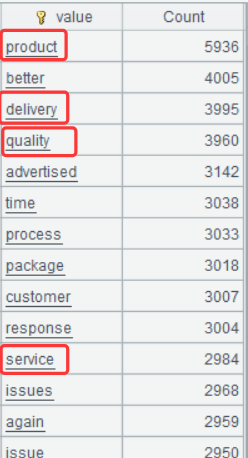
这种过滤掉无意义词汇后更简洁的结果,能立即突显客户关注的核心议题——产品、质量、服务与交付。企业可利用这些信息,精准识别客户讨论最频繁的业务维度。
8.3 分析客户对产品的满意度
顾客对产品满意还是不满意?情感分析可以帮助回答这个问题。让我们实现一个简单的基于词典的方法:
第一步:读取销售数据中的客户名称和客户反馈,并整理客户反馈内容,转换成单词序列,内容同上例
| A | |
|---|---|
| 1 | =file(“sales.csv”).import@tc(customer,feedBack) |
| 2 | =A1.run(feedBack=trim(lower(feedBack))) |
| 3 | =A2.derive(feedBack.words():Words) |
A3 将 feedBack 转成单词序列,并存储在新添加的字段 Words 中。
A3 的运行结果:
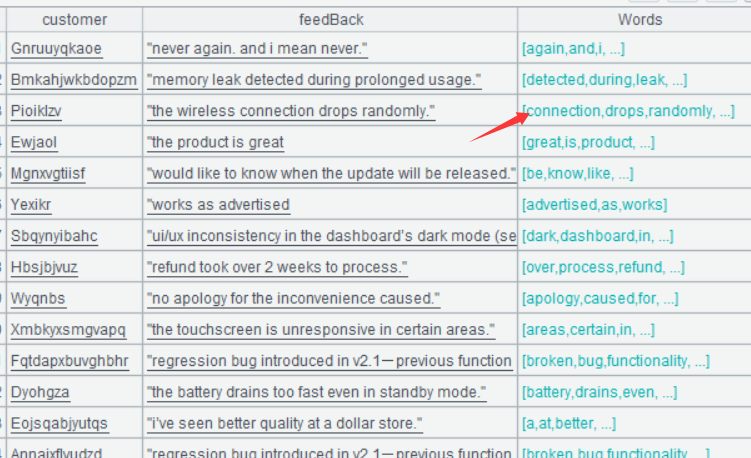
双击任意行的 Words 字段值,可以看到:
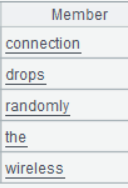
第二步:读取情感词典
| A | |
|---|---|
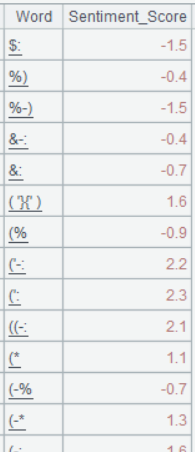
| 4 | =file(“sentiment_lexicon.csv”).import@ct() |
A4 的运行结果:
第三步:将情感词典和客户反馈单词序列关联,计算平均情感得分
| A | |
|---|---|
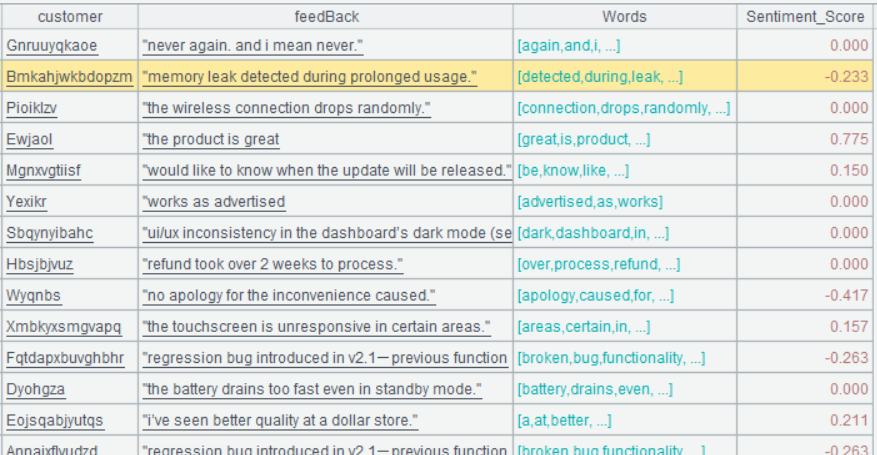
| 5 | =A3.derive(A4.align@b(Words:~,Word).avg(ifn(~.Sentiment_Score,0)):Sentiment_Score) |
A5 A4.align@b(Words:~,Word) 的含义: 将 A4 和 Words 字段关联,关联值是 Words 的当前成员和 A4 的 Word 字段。.avg(ifn(~.Sentiment_Score,0)) 表示对关联后的结果算平均得分,其中 ifn(~.Sentiment_Score,0) 表示如果 ~.Sentiment_Score 为 null,则取 0,以防有些单词不在词典中。
A5 的运行结果:
第四步:给客户情感得分评级
| A | |
|---|---|
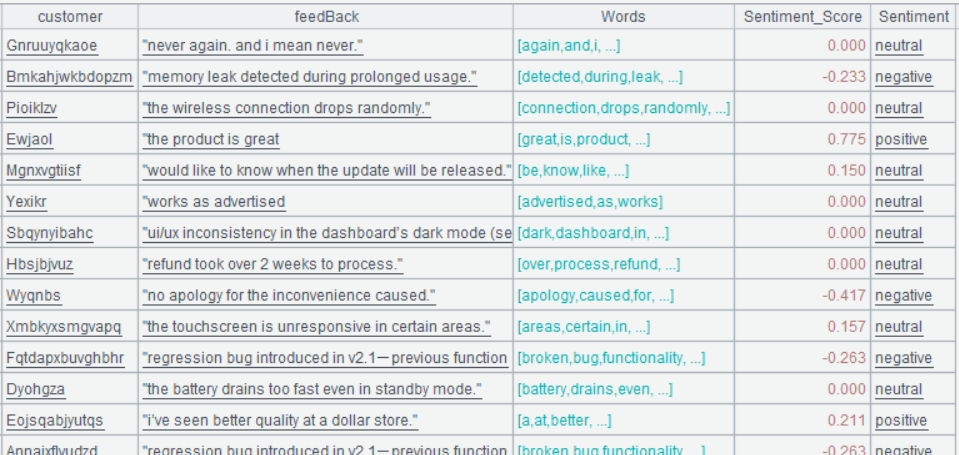
| 6 | =A5.derive(if(Sentiment_Score>0.2:“positive”,Sentiment_Score<-0.2:“negative”;“neutral”): Sentiment) |
A6 最终得分大于 0.2 的视为 positive, 小于 0.2 的视为 negative,其余均视为 neutral。
A6 的运行结果:
该分析可让您快速了解客户情绪概况。例如,您可能会发现:
- 65% 的反馈为正面,20% 为负面,15% 为中立
- 某些产品的负面反馈明显多于其他产品
- 特定地区的客户反馈往往更加积极
- 客户情绪随时间推移呈现改善趋势
这些洞察能帮助您:
- 定位需要改进的环节
- 追踪产品服务优化后的成效
8.4 客户讨论主题分析
除了情感倾向,您可能还想了解客户讨论的具体主题。我们可以实施一个基于关键词的简易主题分类方案:
第一步:读取销售数据中的客户名称和客户反馈,并整理客户反馈内容,转换成单词序列,内容同上例
| A | |
|---|---|
| 1 | =file(“sales.csv”).import@tc(customer,feedBack) |
| 2 | =A1.run(feedBack=trim(lower(feedBack))) |
| 3 | =A2.derive(feedBack.words().sort():Words) |
第二步:产生一个简易的主题词汇表
| A | |
|---|---|
| 4 | =[[“price”,“cost”,“expensive”,“cheap”,“affordable”,“fees”,“cheaper”,“charged”,“refund”,“money”,“worth”,“penny”,“buy”,“lower”,“higher”,“overpriced”,], [“quality”,“durable”,“broke”,“lasting”,“sturdy”,“drops”,“randomly”,“drains”,“interface”,“leak”,“error”,“inconsistency”,“slower”,“freezes”,“resetting”,“overheats”,“compatibility”,“unresponsive”], [“service”,“support”,“help”,“response”,“staff”,“update”,“released”,“process”,“apology”,“inconvenience”,“patience”,“delivery”,“waited”,“rude”,“follow”,“available”,“late”]] |
| 5 | = [“price”,“quality”,“service”] |
| 6 | =A4.new(~.sort():Keys, A5(A4.#):Topics) |
A6 的运行结果:
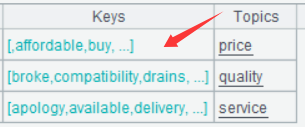
双击其中一行的 Keys 字段,可看到:
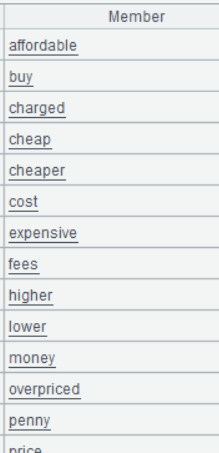
第三步:从 A6 中查找和 A3 中的每一个 Words 对应的 Topics,因为 A3 中的 Words 是一个单词的序列,所以可能会存在多个 Topics 的现象
| A | |
|---|---|
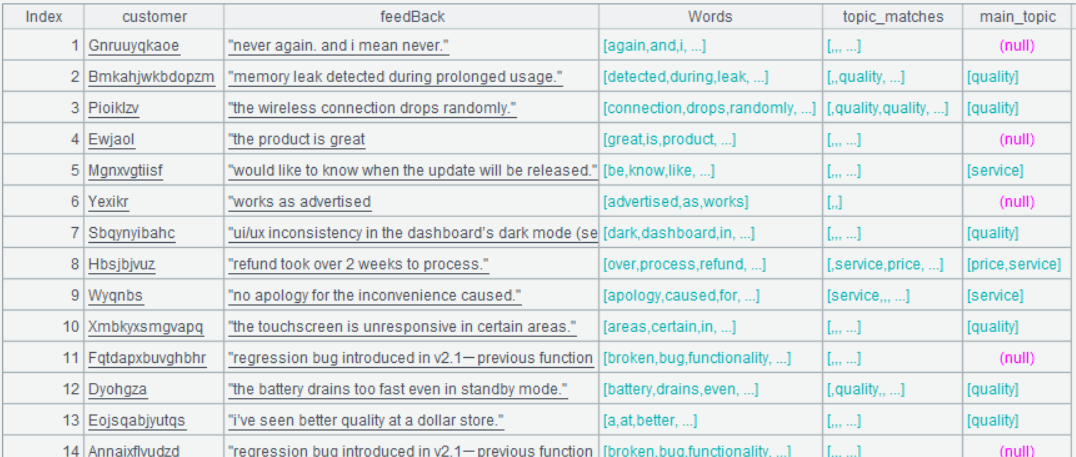
| 7 | =A3.derive(Words.(A6.select@1(Keys.contain@b(Words.~)).Topics):topic_matches) |
A7 select@1的含义是:查找到一条符合条件的记录,就不再继续往下查找
A7 的运行结果:
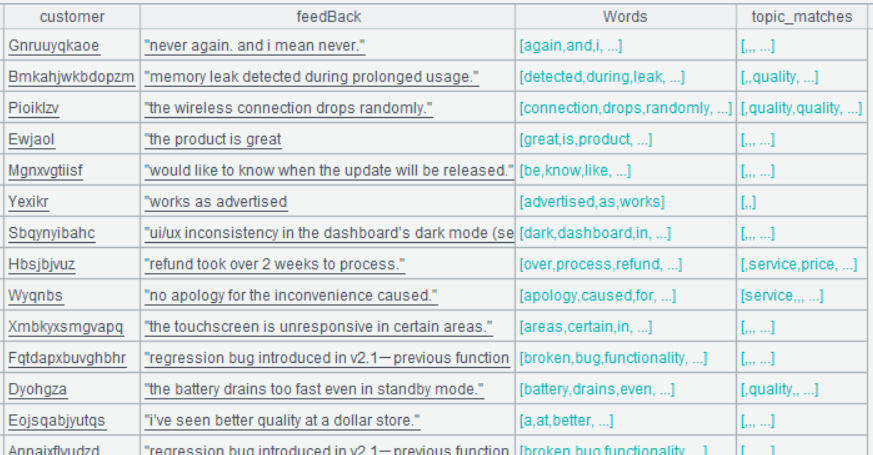
第四步:从 topic_matches 里找出出现频次最高的 topic 作为 main_topic
| A | |
|---|---|
| 8 | =A7.derive(topic_matches.select(~).groups(~:topics;count(1):c).maxp@a(c).id(topics):main_topic) |
A8 maxp@a 的选项 @a 的含义:如果最大值有并列的情况,则均选出。
A8 的运行结果: