SERL——针对真机高效采样的RL系统:基于图像观测和RLPD算法等,开启少量演示下的RL精密插拔之路(含插入基准FMB的详解)
前言
如此文《RLDG——RL知识蒸馏通用体:先基于精密任务训练RL策略,后让其自动生成数据,最后微调VLA,效果超越人类演示数据》的开头所说
- 最开始是因为一公司找我们,希望帮他们复现RLDG,于此便研究且解读了该RLDG
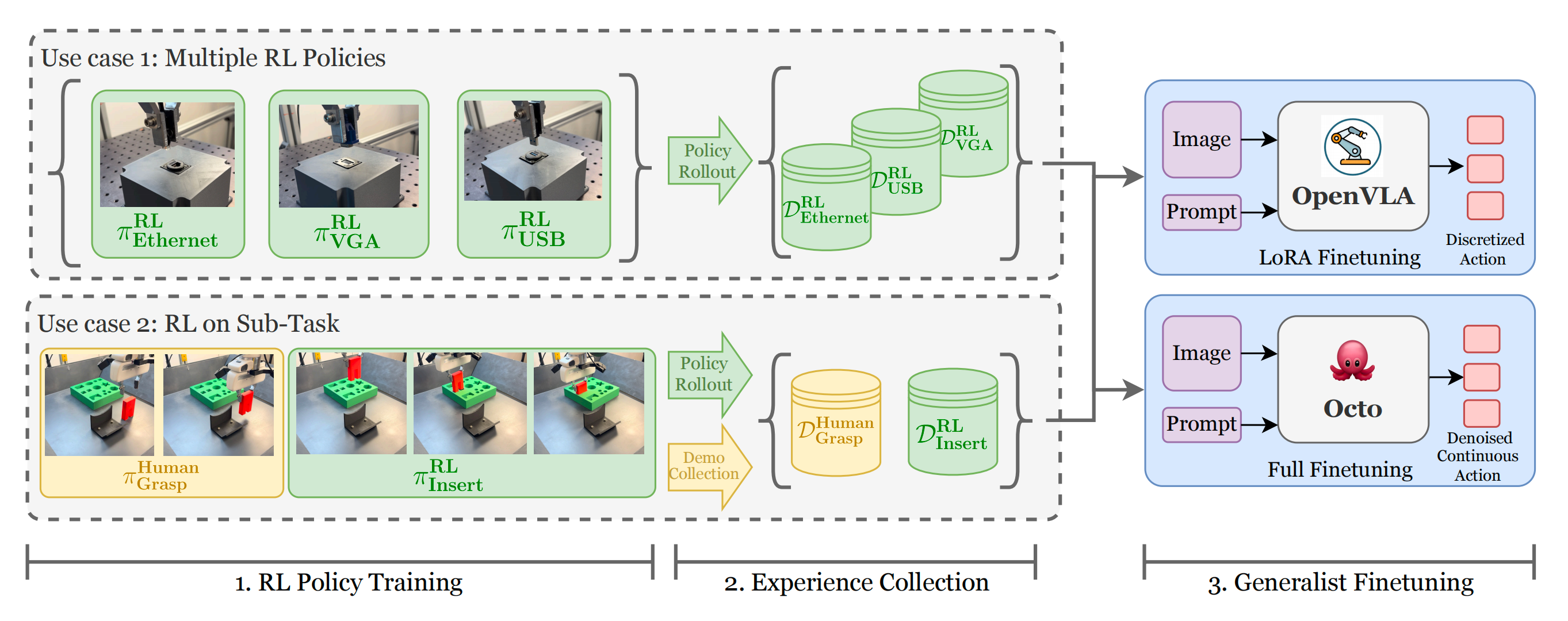
- 解读过程中发现,其采用本博客中解读过的「HIL-SERL」来实现RLDG,而HIL-SERL用的算法是RLPD(23年2月)
故我又解读了RLPD - 顺带,把之前HIL-SERL的解读 又反复修订了几遍
修订过程中,发现其前身工作SERL(24年1月底) 也值得解读、研究下(且顺带修订了24年1月中旬发布的FMB,详见本文第二部分 )
故,便成就了本文
- 而对于上面三点,重新梳理一下顺序(颜色越深代表该工作越新):RLDG(24年12月) → HIL-SERL(24年10月) → SERL(24年1月底)/FMB(24年1月中旬) → RLPD(23年2月),便是从最新的工作一路回溯
- 其实这种回溯很有必要,因为知道了最新工作的来龙去脉,把相关的工作都串起来,成为一个体系,如此
可以更好的指导我司「七月在线」的复现、研究工作
更可以帮助广大具身同行、本博客的广大读者,建立知识体系、减轻探索或研究的负担
何乐不为
第一部分 SERL
1.1 引言、相关工作
1.1.1 引言
如原论文所说,近年来,机器人强化学习(RL)取得了显著进展,取得了令人印象深刻的成果。例如,机器人可以进行乒乓球比赛(Büchler 等,2022),能够从原始图像中操控物体(Gupta 等,2021;Kalashnikov等,2021;Levine 等,2016b),并能抓取多种多样的物体(Levine 等,2018;Mahler等人,2017),以及执行各种其他技能
然而,尽管底层算法取得了重大进展,强化学习在实际机器人学习问题中的应用仍然具有挑战性,实际采用的案例也较为有限。作者认为,造成这一现象的部分原因在于,RL算法的实现,尤其是在真实世界的机器人系统中,涉及极为广泛的设计空间,并且限制机器人强化学习推广的,往往不是算法本身的局限性,而是如何在设计空间中进行有效探索的挑战
- 该领域的从业者普遍认为,强化学习算法的具体实现细节有时与算法本身的选择同等重要,甚至更为关键
- 此外,现实世界的学习还面临着奖励函数设计、环境重置的实现、样本效率、顺应性与安全控制等一系列额外挑战,这些问题进一步加剧了实现层面的压力
因此,现实世界机器人强化学习的应用和后续研究进展,很可能更多地受制于实现细节,而非新的算法创新
为了解决这一挑战,来自1 Department of EECS, University of California, Berkeley, 2 Department of Computer Science and Engineering, University of Washington, 3 Department of Computer Science, Stanford University, 4 Intrinsic Innovation LLC的研究者提出了一个开源软件框架,称之为Sample-Efficient Robotic reinforcement Learning(SERL),旨在促进强化学习在现实世界机器人领域的更广泛应用
- 其对应的paper为:SERL: A Software Suite for Sample-Efficient Robotic Reinforcement Learning
其对应的作者包括
Jianlan Luo1*, Zheyuan Hu1*, Charles Xu1, You Liang Tan1
Jacob Berg2, Archit Sharma3, Stefan Schaal4
Chelsea Finn3,Abhishek Gupta2 and Sergey Levine1 - 其对应的项目地址为:serl-robot.github.io
其对应的GitHub地址为:SERL Code、Robot Controller Code
下图展示了在现实世界中使用SERL解决的多种任务,包括PCB板插入(左)、电缆布线(中)和物体搬运(右)。SERL为现实世界的强化学习提供了开箱即用的解决方案,支持高效采样学习、奖励函数学习以及重置过程的自动化

具体而言,SERL包含以下组件:
- 面向实际机器人学习的高质量RL实现,支持图像观测和演示
- 多种与图像观测兼容的奖励指定方法的实现,包括分类器和对抗训练
- 支持学习“前向-后向”控制器,可以在试验之间自动重置任务(Eysenbach等,2018)
- 一个原则上可以将上述RL组件连接到任何机器人操作臂的软件包
- 一种特别适用于处理丰富接触操作任务的阻抗控制器设计原则
本文的目标不是提出新的算法或方法论,而是为社区提供一个资源,为机器人学者在未来机器人RL研究以及可能将机器人RL作为子程序的其他方法,打下良好的基础
- 然而,在评估我们框架的过程中,作者还得出了一个具有科学意义的实证观察:当在精心设计的软件包中正确实现时,当前高样本效率的机器人RL方法能够在相对较短的训练时间内取得非常高的成功率
- 他们的评估任务如图1所示:
包括涉及动态接触的精密插入任务、具有复杂动力学的可变形物体操作,以及机器人必须在没有人工重置的情况下学习的物体重新定位任务
对于每一项任务,SERL都能够在每个策略15-60分钟(以实际时间计算)的训练内高效学习,并实现接近完美的成功率,尽管所学习的策略在操作时基于图像观测
这一结果具有重要意义,因为强化学习,尤其是结合深度网络和图像输入时,通常被认为效率极低
SERL的结果对这一假设提出了挑战,表明只要对现有技术进行细致实现,配合精心设计的控制器,以及合理选择奖励设定和重置机制的组件,就能够构建出足够高效、适用于实际应用的整体系统
1.1.2 相关工作
首先,对于现实世界强化学习的算法
现实世界的机器人强化学习要求算法具备高样本效率、能够利用机载感知,并支持易于指定的奖励与重置机制
已有多种算法展现出能够直接在现实环境中高效学习的能力(Riedmiller等,2009;Westenbroek等,2022;Yang等,2020;Zhan等,2021;Hou等,2020;Tebbe等,2021;Popov等,2017;Luo等,2019;Zhao等,2022;Hu等,2024;Johannink等,2018;Schoettler等,2020)
这些算法采用了
- 离策略强化学习的变体(Kostrikov等,2023;Hu等,2024;Luo等,2023)
- 基于模型的强化学习(Hester和Stone,2013;Wu等,2022;Nagabandi等,2019;Rafailov等,2021;Luo等,2018)
- 以及在策略强化学习(Zhu等,2019)
与此同时,推断奖励的技术也取得了进展,包括
- 通过成功分类器从原始视觉观测中推断奖励(Fu等,2018;Li等,2021)
- 基于基础模型的奖励(Du等,2023;Mahmoudieh等,2022;Fan等,2022)
- 以及基于视频的奖励(Ma等,2023b;a)
此外,为实现自主训练,关于无重置学习的算法也取得了多项进展(Gupta等,2021;Sharma等,2021;Zhu等,2020;Xie等,2022;Sharma等,2023),这些进展使得以最少人工干预实现自主训练成为可能
尽管上述算法进展极为重要,本工作的贡献在于提供一个框架和软件包,使现实世界中的强化学习能够以高样本效率进行,并提供一套可直接应用于多种任务的方法选择
其次,对于强化学习软件包
目前已有多种强化学习(RL)软件包(Seno 和 Imai, 2022;Nair 和Pong;Hill 等, 2018;Guadarrama 等,2018),但据我们所知,目前尚无专门针对现实世界机器人强化学习的解决方案
- SERL基于近期提出的 RLPD 算法构建,该算法是一种具有高更新比的数据的离策略强化学习算法。SERL 并不是一个用于在仿真环境中训练智能体的强化学习算法库,尽管它可以被改造用于该目的
- 相反,SERL 提供了一个完整的机器人控制技术栈,从底层控制器到支持异步高效训练的强化学习算法接口,再到推断奖励与无需重置的训练机制等附加工具
因此,SERL 为非专业用户提供了一套开箱即用的工具包,使其能够在现实世界中使用强化学习训练物理机器人,这不同于以往旨在实现多种方法的库——SERL 实现了组件的完整“纵向”集成,而以往的库则更侧重于“横向”扩展 - SERL 也不是像(Yu 等, 2019;James 等,2020;Mittal 等, 2023)那样的强化学习基准包。SERL 允许用户直接在现实世界中定义自己的任务和成功度量标准,提供实际用于控制和训练机器人操作臂的软硬件基础设施
最后,对于面向现实世界强化学习的软件
- 此前已有多个软件包提出了针对现实世界强化学习的基础设施,例如用于灵巧操作(Ahn 等,2019)、桌面家具组装(Heo 等,2023)、腿式运动(Kostrikov 等,2023)以及插销任务(Levine 等,2016a)
- 这些软件包在特定场景下表现有效,但通常依赖于特权信息或特定的训练设置,例如显式跟踪(Levine 等,2016a;Ahn 等,2019)或纯本体感知(Kostrikov 等,2023),或仅限于模仿学习
在 SERL 中,作者展示了一个完整的系统栈,可广泛应用于多种机器人操作任务,无需像以往工作那样对训练设置进行特权化处理
1.1.3 预备知识和问题陈述
机器人强化学习任务可以通过一个MDP 来定义,其中
表示状态观测(例如,一张图像结合当前末端执行器的位置)
表示动作(例如,期望的末端执行器位姿)
是初始状态的分布
是依赖于系统的未知且可能具有随机性的转移概率
- 且r : S × A →R 是奖励函数,用于编码任务
最优策略π 是指能够最大化累计期望奖励的策略,即,其中期望是针对初始状态分布、转移概率以及策略π 来计算的
虽然强化学习任务的规范简明扼要,但将现实世界的机器人学习问题转化为强化学习问题时需格外谨慎
- 首先,学习策略
的算法样本效率至关重要:当学习必须在现实世界中进行时,每一分钟、每一小时的训练都意味着成本。可以通过采用高效的离策略强化学习算法(Konda 和 Tsitsiklis, 1999;Haarnoja等, 2018;Fujimoto 等, 2018)来提升样本效率
同时也可以通过引入先验数据和示范(Rajeswaran 等, 2018;Ball 等, 2023;Nair等, 2020)来加速训练,这对于实现最快的训练速度尤为重要 - 机器人强化学习中的许多挑战不仅仅在于优化π的核心算法。例如,奖励函数
可能依赖于图像观测,并且用户很难手动指定
此外,对于机器人在每次试验之间重置到初始状态的情景任务,实际上将机器人(及其环境)重置到这些初始状态之一是一个必须以某种方式实现自动化的机械操作
- 再此外,控制器层负责将MDP动作
(例如末端执行器的位姿)与实际的低级机器人控制进行对接,这一环节同样需要极为谨慎,尤其是在机器人与环境中的物体发生物理接触的任务中
该控制器不仅需要具备高度的精确性,还必须足够安全,以便强化学习算法在训练过程中能够通过随机动作进行探索
而SERL 旨在为上述每项挑战提供现成的解决方案,包括
- 高质量实现的、能够融合先验数据的高样本效率离策略off-policy RL方法
- 多种奖励函数指定方式
- 用于学习重置的前向-后向算法
- 以及适用于在不损坏机器人或环境中物体的前提下学习高接触任务的控制器
1.2 现实世界中的高效样本机器人强化学习
- 核心强化学习算法源自RLPD(Ball等,2023),而RLPD本身是soft actor-critic (Haarnoja等,2018)的一种变体:这是一种基于off-policy的Q函数行为者-评论家方法,能够高效地将先前的数据(无论是次优数据还是演示数据)整合进回放缓冲区以实现高效学习
- 奖励函数可以通过二元分类器或VICE(Fu等,2018)进行指定,后者提供了一种在强化学习训练过程中,利用来自策略的附加负样本来更新分类器的方法,在机器人状态足以评估任务成功与否的情况下(例如在PCB板组装任务中),奖励函数也可以由人工指定
- 重置机制可通过前向-后向架构(Sharma等,2021)实现,该算法同时训练两种策略:一种是执行任务的前向策略,另一种是将环境重置回初始状态的后向策略
- 在机器人系统方面,作者还提供了一个通用适配器,用于将他们的方法与任意机器人对接
- 以及一个特别适用于高接触操作任务的阻抗控制器
接下来,会逐一详解
1.2.1 核心强化学习算法:RLPD
在该场景下部署强化学习算法需要满足若干要求:
- 算法必须高效,能够在每个时间步进行多次梯度更新
- 能够轻松整合先前数据,并在后续经验中持续改进
- 便于新用户调试和扩展
为此,作者基于近期提出的 RLPD(Ball 等,2023)算法,该算法在样本高效的机器人学习中表现出色
RLPD 是一种基于 off-policy 的 actor-critic强化学习算法,借鉴了 soft-actorcritic(Haarnoja 等,2018)等时序差分算法的成功经验,但为满足上述需求做出了一些关键修改
RLPD 主要有三项核心改进:
- 高更新-数据比训练(UTD)
- 在先验数据和策略内数据之间进行对称采样,使得每个批次中一半来自先验数据,另一半来自在线重放缓冲区
- 在训练期间进行层归一化正则化
该方法可以从零开始训练,或使用先前数据(例如,演示)来引导学习
算法的每一步都根据各自损失函数的梯度,更新参数化Q 函数和
的参数:
其中,是一个目标网络(Mnih 等人,2013),而actor 损失使用带有自适应调整权重
的熵正则化(Haarnoja 等人,2018)
- 每次更新步骤使用对每个期望的基于样本的近似,其中一半样本来自先验数据(例如,演示数据),另一半样本来自回放缓冲区(Mnih 等人,2013)
- 为了高效学习,在环境中的每个时间步执行多次更新步骤,这被称为update-to-date(UTD)比率,并且通过对critic 进行层归一化正则化,可以实现更高的UTD 比率,从而实现更高效的训练(Ball 等人,2023)
关于RLPD的更多介绍,请参见此文《RLPD——利用离线数据实现高效的在线RL:不进行离线RL预训练,直接应用离策略方法SAC,在线学习时对称采样离线数据》
1.2.2 利用分类器进行奖励规范
当使用图像观测进行学习时,奖励函数很难手工指定,因为机器人通常需要某种感知系统——哪怕仅仅是为了判断任务是否成功完成
虽然某些任务,例如图1 中的PCB板组装任务

可以根据末端执行器的位置(假设物体被刚性地夹持在夹爪中)手工指定奖励,但大多数任务都需要从图像中推断奖励
在这种情况下,奖励函数可以由一个二元分类器提供,该分类器接收状态观测 并输出一个二元” 事件”
发生的概率,对应于任务的成功完成。奖励随后由
给出
- 该分类器可以通过手工指定的正例和负例进行训练,也可以通过一种称为VICE(Fu 等,2018)的对抗性方法进行训练
后者解决了在基于分类器的奖励学习中可能出现的奖励利用问题,并且在分类器训练集中无需负例:当RL 算法优化奖励时,可能会发现” 对抗性” 状态,这些状态会欺骗分类器
错误地输出较高的概率
- VICE 通过将策略访问过的所有状态以负标签的形式加入分类器的训练集,并在每次迭代后更新分类器,从而解决该问题
这样,强化学习过程类似于生成对抗网络(GAN)(Goodfellow 等,2014),其中策略充当生成器,奖励分类器则作为判别器。因此,SERL框架支持所有三种类型的奖励
1.2.3 需重置的正向-反向控制器的训练
在学习情节性任务时,机器人必须在每次任务尝试之间重置环境。例如,在图1中的物体重新定位任务中,每当机器人成功将物体移动到目标箱后,必须将其取出并放回初始箱
- 为了消除人工“重置”的需求,SERL 通过使用前向和后向控制器(Han 等,2015;Gupta 等,2021)支持“免重置”训练
在该设置中,两个策略由两个独立的强化学习代理同时训练,每个代理都有自己的策略、Q函数和奖励函数(通过前一节的方法指定) - 前向代理学习执行任务,后向代理学习返回到初始状态。虽然也可以采用更复杂的免重置训练方法(Gupta 等,2021),但作者发现这种简单的方法对于学习如图1中重新定位技能的物体操作任务已经足够
1.2.4 软件组件
- 环境适配器:SERL 旨在便于在多种机器人环境中使用。尽管提供了一套 Gym 环境包装器和 Franka 机械臂的机器人环境作为入门指南,用户仍然可以根据需要使用他们已有的环境,或开发新的环境
因此,只要机器人环境类似于 Gym(Brockman 等,2016),该库不会对其施加额外限制,如图2 所示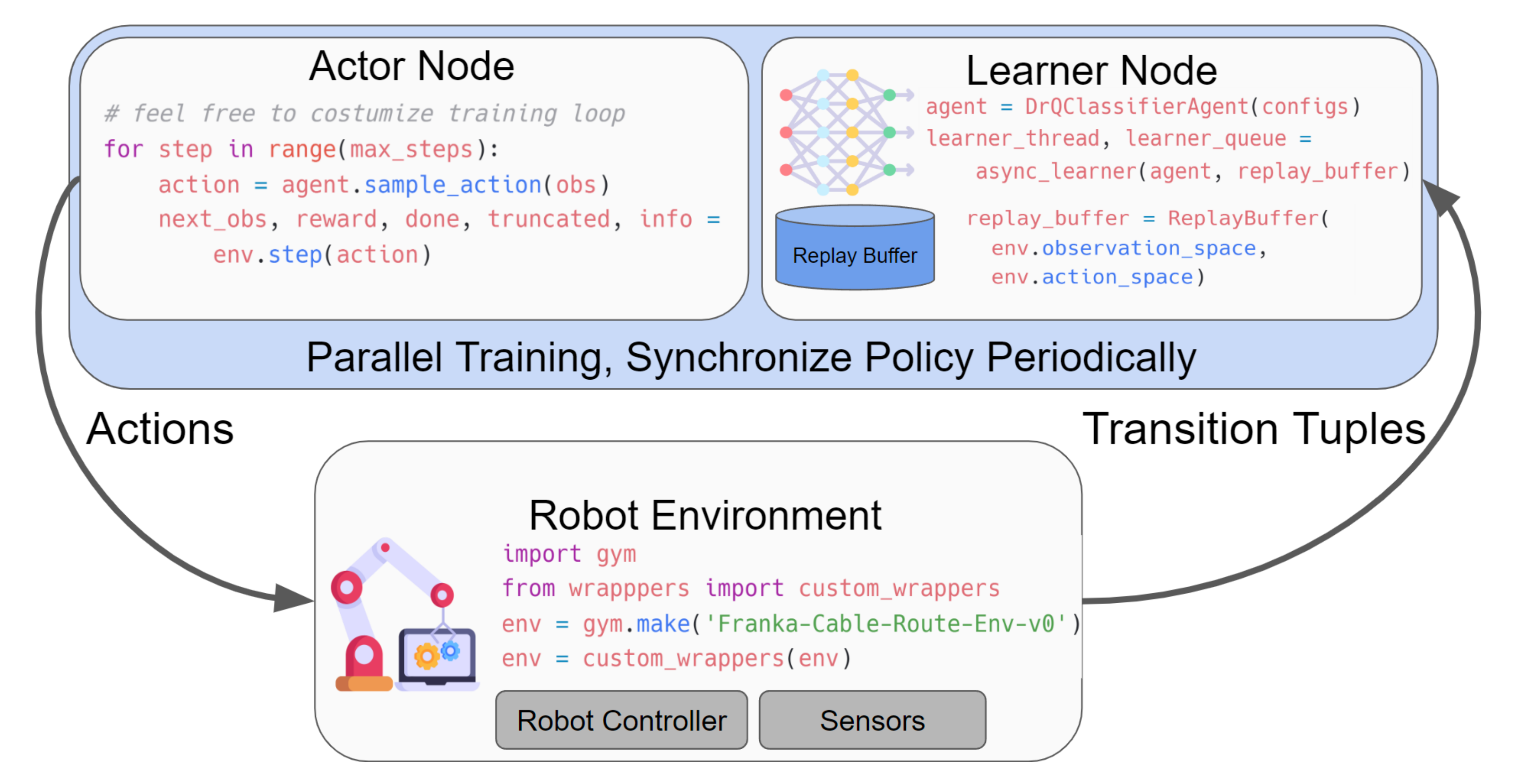
- 执行者节点与学习者节点:SERL支持并行训练与执行,只需几行代码即可实现动作推断与策略更新的解耦,如图2所示
在具有高UTD比率的样本高效型真实世界学习问题中,作者发现这种方式非常有益。通过将执行者与学习者分配到不同的线程,SERL不仅能够保持控制频率以固定速率进行,这对于需要即时反馈和反应的任务至关重要——挺像VLA中的快慢双系统,例如可变形物体和高接触操作任务,同时也减少了在真实环境中训练所需的总实际时间
1.2.5 面向高接触任务的阻抗控制器
虽然他们的软件包理论上应兼容任何OEM机器人控制器,但作者发现控制器的选择会极大影响最终性能。这种影响在涉及大量接触的操作任务中尤为明显
例如,在图1所示的PCB插入任务中,过于刚性的控制器可能导致脆弱的引脚弯曲,从而增加插入难度;而过于柔顺的控制器则可能难以及时将物体定位到位
机器人强化学习的典型设置采用两层控制层级,其中RL策略以远低于下游实时控制器的频率生成设定点动作。RL控制器可以为低级控制器设定目标,这可能导致物理上不理想的后果
为说明这一点,可以看下图4所示的分层控制器结构——RL策略的输出在一个时间块内由下游控制器进行跟踪
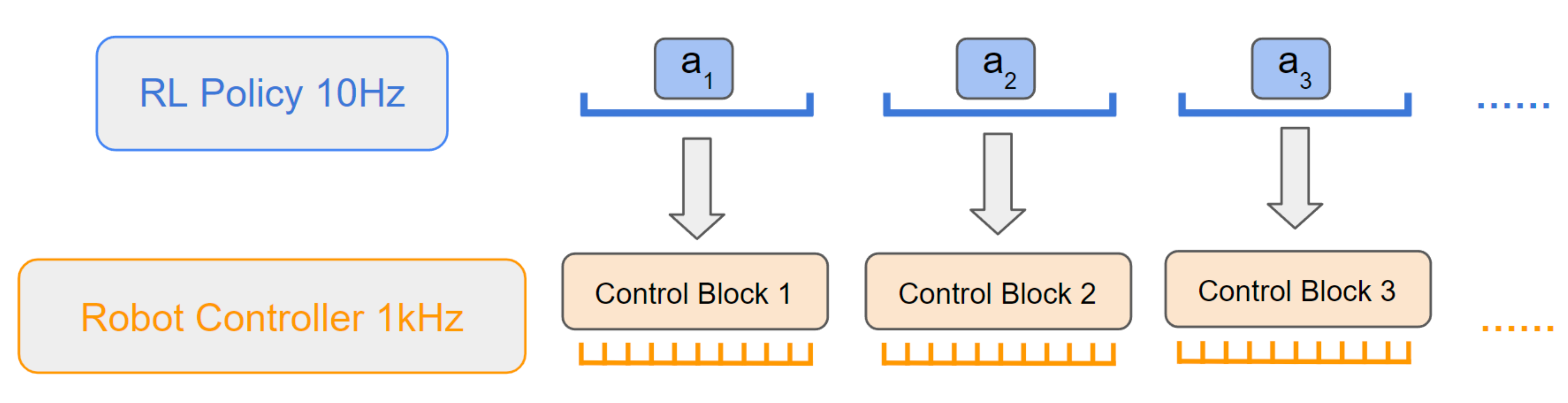
其中高级RL控制器以10Hz的频率发送控制目标,供低级阻抗控制器以1KHz的频率跟踪,因此RL的一个时间步会阻塞低级控制器的100个时间步以执行
该控制器的典型阻抗控制目标为
其中,
为测量位姿,
为上游控制器计算得到的目标位姿,
为前馈力,
为Coriolis force,该目标随后将通过将雅可比矩阵的转置相乘并加上零空间力矩,转换为关节空间力矩
- 它的作用类似于一个以
为平衡点的弹簧-阻尼系统,其中刚度系数为
,阻尼系数为
。如上所述,如果
- 因此,约束其产生的交互力至关重要。然而,直接降低增益会影响控制器的精度。因此,应当约束
,使得
,这样由弹簧-阻尼系统产生的力将被限制在
之内,其中
为控制频率
人们可能会想,是否应该直接对RL策略的动作输出进行裁剪
- 这看起来似乎合理,但在某些场景下并不实用:例如,像PCB板这样的物体可能只需要非常小的交互力,这意味着Δ非常小,通常只有微米级;如果RL策略只能以微米级的步进进行移动,将导致极其漫长的学习过程或非常不稳定的训练,因为一次episode 需要足够的时间步来让机械臂能够跨越较远的距离(例如,接近插入点)
- 然而,如果直接在实时层进行裁剪,这将在很大程度上缓解该问题,而无需将RL 策略限制为小动作。只要
,其中
是一个block 内的控制时间步数,如图4 所示,就不会阻碍RL 策略在自由空间的运动。这个值通常很大(例如,M = 100)
同时,每当发生接触时,作者在实时层严格执行参考约束
有人可能会想是否可以通过使用外部力/力矩传感器来实现相同的效果。这在多种原因下可能并不可取:
- 力/力矩传感器可能有显著的噪声,获得合适的硬件和校准可能很困难;
- 即使作者得到了这样的阈值,设计既能适应策略学习又能遵守力约束的机器人运动也并非易事
在实际操作中,作者发现以这种方式裁剪参考简单但非常有效,并且对于实现基于RL 的高接触操作任务至关重要。作者在Franka Panda 机器人上测试了他们的控制器,并在他们的软件包中包含了Franka Panda 的实现
然而,这一原理可以很容易地在任何力矩控制的机器人上实现。为了验证所提出控制器的实际性能,作者报告了如图3 所示在自由空间和与桌面接触时移动机器人时的实际跟踪性能
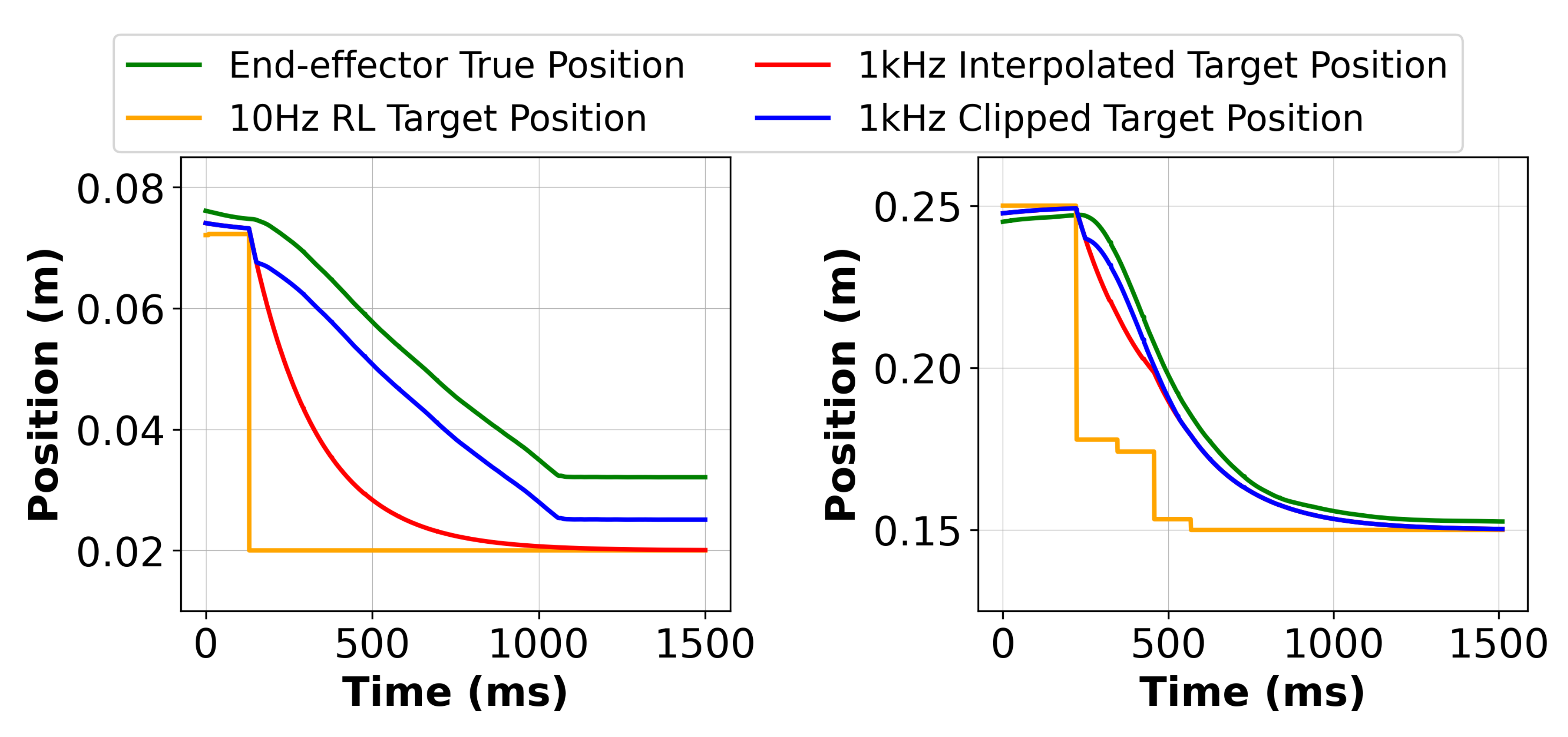
可以看到控制器确实在接触时夹紧了参考,同时允许在自由空间中实现快速运动
1.2.6 相对观测与动作框架
动作空间的选择对于强化学习训练过程的简便性以及所学策略在测试时对扰动的泛化能力都尤为重要。尽管SERL可以通过标准的强化学习环境接口操作各种动作表示,但作者发现,在相对坐标系中表示观测和动作是一种便捷的机制
- 为了开发能够适应动态目标的智能体,作者提出了一种无需物理移动即可模拟移动目标的训练流程
例如,目标(如PCB插座孔)相对于机器人基座固定,奖励可以通过「1.2.2 利用分类器进行奖励规范」节中提供的任一标准方法进行指定 - 在每次训练回合开始时,机器人的末端执行器姿态在工作空间内预先定义的区域内被均匀随机化
机器人的本体感知信息是相对于末端执行器初始位姿的参考系表达的;而策略输出的动作(6D扭转)则是相对于当前末端执行器参考系的。这等价于从附着在末端执行器的参考系来看,物理上移动了目标,更多细节见附录7
因此,即使物体发生移动,或者如作者部分实验中,在任务过程中受到扰动,策略依然能够成功执行
关于相对观测与动作框架的详细说明
- 设机器人的基坐标系为
;对于第
次策略执行,作者用
表示在某一时刻
相对于
表达的末端执行器坐标系,其中
对于每一次执行,是从指定随机区域的均匀分布中采样得到的
作者希望将这种本体感知信息相对于- 因此,只要机器人末端执行器与目标之间的相对空间距离保持一致,策略就可以应用于新的位置。这种方法可以防止在参考坐标系
作者通过应用以下齐次变换来实现这一点
其中用
表示坐标系
与
之间的齐次变换矩阵。然后将从
中提取的位置和旋转信息输入到策略中
- 进一步而言,用
该策略生成一个六自由度(6 DoF)扭转动作,该动作在其当前接收观测值的参考坐标系中表达,即
在数学上,六自由度扭转动作在时刻
- 为了与机器人控制软件对接,该软件期望动作
以基坐标系
中是齐次变换
的一个函数,定义如下
1.3 实验
作者的实验评估旨在研究系统在学习多种机器人操作任务方面的效率,包括富有接触的任务、可变形物体操作以及自由漂浮物体操作。这些实验展示了 SERL 的广泛适用性和高效性
至于硬件选型使用 Franka Panda 机械臂,并在末端执行器上安装了两台腕部摄像头以获取近距离视角。更多细节可参考 https://serl-robot.github.io/
- 且作者采用了在 ImageNet 上预训练的 ResNet-10(He 等, 2015)作为策略网络的视觉骨干,并将其连接到一个两层的MLP。观测信息包括摄像头图像和机器人本体感知信息,如末端执行器的位姿、扭转、力和力矩
- 策略输出从当前位姿起始的 6 维末端执行器增量位姿,由低层控制器进行跟踪
评估任务如图5所示,具体描述如下:

- PCB插拔:将连接器插入PCB板需要精细、接触丰富的操作,且精度需达到亚毫米级。由于此类接触丰富的交互难以仿真和迁移,该任务非常适合在真实环境中进行训练
每次训练和评估开始时,末端执行器的初始位姿会在起始区域内均匀采样,具体如表2所示

- 线缆布线:该任务要求将一根可变形的线缆引导到夹子的紧密卡槽内。机器人需要感知线缆,并精细地操控,使其一端能够准确插入夹子,同时在另一位置保持线缆
这对于依赖基于模型控制或将物体视为刚体的任何方法来说尤其困难,因为该任务对视觉感知和可变形物体的处理能力都提出了较高要求。这类任务在制造和维护场景中经常出现。与PCB任务类似,末端执行器的初始位姿会在起始区域内均匀采样,具体如上表表2所示 - 物体重新定位:该任务要求在不同的箱子之间移动一个自由漂浮的物体,需要进行抓取和重新放置。在操作这类自由漂浮物体时,奖励推断和无重置训练的复杂性尤为突出
作者将前向任务定义为从箱子中拾取该物体,然后将其放置到左侧,而反向任务则将物体移回起始料箱,撤销前向任务的操作
对于每个任务,作者通过使用 Space Mouse进行 20 次远程操作演示来初始化强化学习(RL)训练
且为了验证仅靠演示无法解决该任务,还引入了行为克隆(BC)基线,采用了 100 个高质量专家远程操作演示,其数据量大致与 RL 收敛时的重放缓冲区中的总数据量相匹配
需要注意的是,这比SERL方法提供的演示数量多出 5 倍。RL 和 BC 的所有演示均采用表 2 中描述的初始末端执行器随机化方案收集。所有训练均在一块 Nvidia RTX 4090 GPU 上完成
1.3.1 评估结果
作者在表2中报告了实验结果,并在图5中展示了执行示例
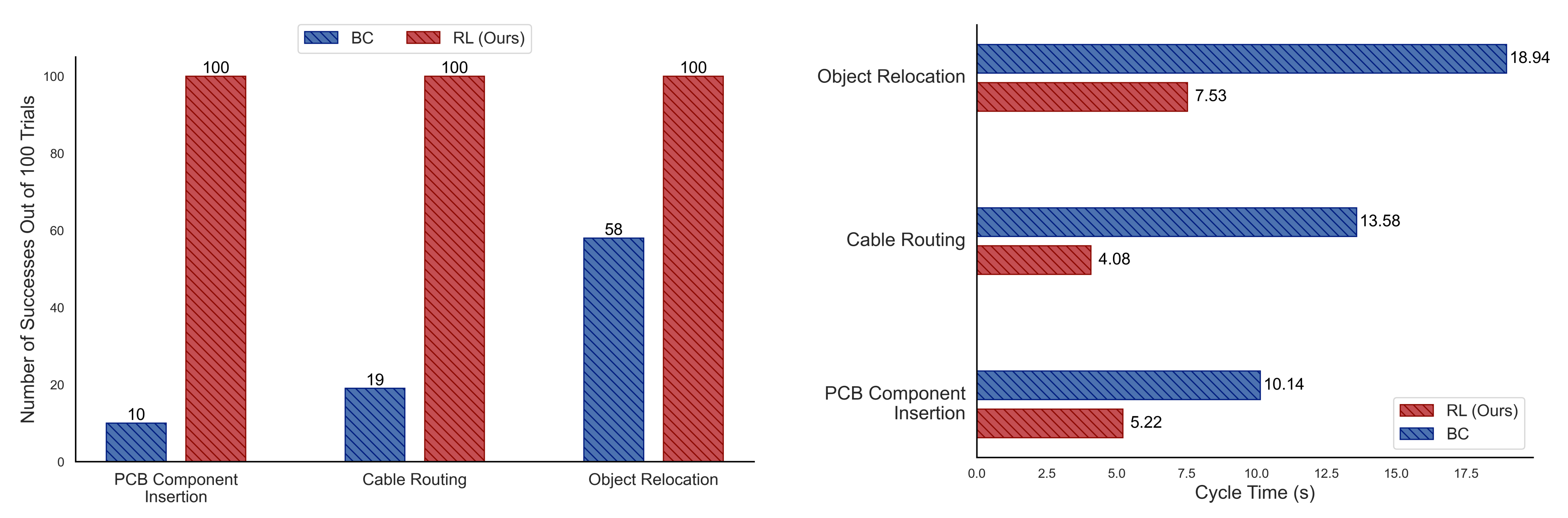
且作者在相同条件和协议下,对BC和RL策略进行了评估。SERL的RL策略在所有100次试验中,在全部三项任务上均实现了完美的成功率
- 对于PCB插入和线缆布线任务,SERL的RL策略在真实世界训练中不到30分钟内即可收敛,这一过程包括所有计算、重置和有意暂停
自由漂浮物体重新定位任务则学习了两个策略(前向和后向),总计每个策略的训练时间总计不到一小时 - 在电缆布线任务和PCB插入任务中,SERL的策略以远超BC基线的表现取得了显著优势,尽管训练所用演示数量仅为BC的五分之一,这表明仅靠演示数据是不够的
- 作者还在图6(下图左侧)和图7(下图右侧)中报告了成功率和周期时间的结果
学习得到的RL策略不仅在成功率上最多超过BC对照组10倍,还将初始人类演示的周期时间最多缩短了3倍
1.3.2 与以往系统的比较
由于实验设置存在诸多差异、缺乏一致开源的代码以及其他不一致之处,因此很难将SERL的结果与以往系统的结果直接进行比较
作者在表2中汇总了与SERL PCB板插入任务最为相似的任务的训练时间和成功率
作者选择该任务,是因为类似的插入或装配任务在先前的研究中已有探讨,并且此类任务通常在精度、柔顺控制和样本效率方面具有挑战性
- 与这些先前的工作相比,SERL的实验未采用奖励塑形方法,这通常需要大量的工程设计,尽管SERL确实使用了少量的示范数据(而部分先前工作则完全未使用)
先前的工作通常存在成功率较低、训练时间较长,或两者兼有的问题,这表明SERL实现的高样本效率强化学习在此类任务上能够达到或超越文献中最新方法的表现 - Spector 等人(Spector 和 Castro, 2021)的工作与SERL的性能最为接近,但他们的方法包含了许多针对插入任务特定的设计决策和归纳偏置,而SERL的方法则更为通用,几乎不依赖于任务特定的假设
尽管SERL系统的各个组件都基于(近期的)已有工作,但这种组合实现的最新性能很好地说明了作者想表达的主要观点:深度强化学习方法的具体实现细节会产生显著影响
1.3.3 可复现性
SERL 的核心使命之一是降低部署门槛,并鼓励在不同机器人系统上实现可复现的机器人强化学习。为此,作者展示了 SERL 软件套件在另一机构运行的机械臂上的成功集成
- 具体而言,华盛顿大学的研究人员设置了一个使用来自Functional Manipulation Benchmark『简称FMB,下文第二部分会详细介绍』的3D 打印部件的Peg Insertion 任务,并使用SERL 来解决这一具有挑战性的任务
- 最终,包括相关硬件和软件设置在内的总体准备时间不足3 小时。策略在19 分钟内收敛,并在有20 次初始人工演示的情况下达到了100/100 的成功率,成功复现了SERL的结果
// 待更
第二部分 通用机器人学习的操控基准FMB:方便评估零部件的插入效果
本第二部分 最开始属于此文《以Mobile ALOHA为代表的模仿学习的爆发:从Dobb·E、Gello到ALOHA、OK-Robot、UMI、DexCap、伯克利FMB》的第六部分,后转到此文中
2.1 Functional Manipulation Benchmark for Generalizable Robotic Learning
24年1月中旬,加州大学伯克利分校智能机器人实验室(RAIL)的研究团队提出了FMB(Functional Manipulation Benchmark for Generalizable Robotic Learning)
- 项目主页:https://functional-manipulation-benchmark.github.io/
- 论文地址:FMB: a Functional Manipulation Benchmark for Generalizable Robotic Learning
- 共同第一作者主页:
https://people.eecs.berkeley.edu/~jianlanluo/
https://charlesxu0124.github.io/
2.1.1 物体和任务
FMB 中的任务大致分为两类:单物体多步骤操控任务和多物体多步骤操控任务。这些任务旨在测试机器人的基本技能,如抓取、重新定位和装配等,这些都是完成整个任务所必需的技能。FMB 中的任务要求机器人不仅能完成单一的操控技能,还要求机器人能够将这些技能组合起来,完成更为复杂的多步骤任务。
FMB 的任务设计灵活多变,研究人员可以根据需要选择专注于单一技能,深入研究机器人的操控能力,也可以研究完整的多步骤任务,这需要机器人进行长期规划并具备从失败中恢复的能力。由于涉及选择合适的物体并推理操控物体的顺序,更为复杂的多步骤任务要求机器人能够做出复杂的实时决策


2.1.2 大型数据集
为了使机器人更好地理解和掌握复杂的任务
- 研究团队收集了一个涵盖上述任务的大规模专家人类示范数据集,包含超过22550个操作轨迹
且总共配备了四台Intel RealSense D405相机,其中两台安装在机器人末端执行器上,其余两台分别放置在箱体两侧,以便为箱内物体提供补充视角(且为了确保图像观测不受背景干扰,作者在工作区侧面围上了白色帘布)
we have four Intel RealSense D405cameras, two of which are mounted on the robot end-effector, and the rest are placed on each side of the bin to provide a complementary view of objects inthe bin
这些摄像机捕捉了对于机器人学习解决任务至关重要的 RGB 彩色图像信息、深度信息等数据,且提供了可做校准的相机内联功能,这种校准可以在必要时将深度图像转换为点云
We simultaneously capture RGB and depthimages from these cameras, and we also provide calibrated camera intrinsics. This calibration allows for the conversion of depth images into point clouds when necessary - 此外,数据集还记录了FrankaPanda机器人提供的末端执行器力/力矩信息(没有使用额外的力/力矩传感器,因为利用机器人自身的传感能力简化了标准化流程),这对于像装配这样需要接触大量物体的的任务非常重要
通过这些丰富的数据,机器人能够深入理解任务的每个细节,更加精确地模仿人类的操作技巧。正是由于数据的深度和广度,为机器人学习提供了坚实的基础。这使得机器人在执行复杂任务时,能够更加人性化和更灵巧地对任务作出响应
2.2 FMB的模仿学习系统
2.2.1 基于 Transformer 和 ResNet 的两种策略模型
简而言之,基于 Transformer 和 ResNet 的两种模型都使用了共享权重的ResNet 编码器,让其对每个图像视图进行编码,然后与本体感知信息、可选的物体、以及相应的机器人技能编码特征结合,以预测 7 自由度的动作,具体而言
在下图左侧所示的基于Transformer的策略中,他们提出了一个仅解码器Transformer架构(最近的研究表明,在机器人控制中,Transformer的主要优势在于处理多模态输入和利用大规模、多样化数据集进行扩展)

且为了对来自多个摄像机视角的图像进行标记
- 他们采用了共享权重的ResNet-34编码器(We use weight-shared ResNet-34 encoders to tokenize images from multiple camera views)
- 且为了满足策略输入的需要,还在输入侧添加了FiLM层来对object ID或primitive ID进行条件处理
We additionally add FiLM (Perez et al., 2018) layers to condition on the object ID or primitive ID if they are required as part of the inputs to the policies. - 机器人本体信息(Proprioceptive Information)通过MLP单独标记,并与正弦位置嵌入连接后通过具有4个注意力头和4个MLP层的自注意力层进行处理
Robot proprioceptive information is tokenized via an MLP separately. These tokens, after being concatenated together with sinusoidal position embeddings, are then processed through self-attention layers with four attention heads and four MLP layers.
在训练过程中,连续的6维机器人动作空间的每个维度都通过高斯量化器离散化为256个区间。在运行时向机器人发送指令时,离散化的动作空间会被转换回连续值
即Each dimension of the continuous 6D robot actionspace is discretized into 256 bins during training byusing a Gaussian quantizer. The discretized actionspace is converted back into continuous values whensending commands to the robot at runtime.
而在图中右侧所示的基于ResNet的策略中,该架构由ResNet-34视觉骨干网络和一个作为策略头部的MLP组成(It is composed of ResNet-34 vision backbones and an MLP as the policy head),且在所有任务中都采用这个通用结构,只对每个任务的特定输入进行调整
- 首先,该结构能够接收多张RGB和深度图像(且如paper 第11页右上角所述,同时使用深度和RGB信息训练的ResNet策略,始终优于使用相同数据数量训练的仅使用RGB的策略)
并分别通过权重共享的ResNet进行编码,随后将特征进行拼接(It takes multiple RGB and depth images and encodes them separately with weight-shared ResNets before concatenating the features) - 然后,如上图右侧的左下角所示,系统还会获取机器人的本体感知信息,如末端执行器的位姿、速度或力/力矩测量等,并在输入多层感知机(MLP)前进行线性投影
It also takes the robot’s proprioceptive information, such as end-effector pose, twist, or force/torque measurements, then performs linear projection before being fed into the MLP
且系统还能够能够同时基于object ID和manipulation skill ID进行条件控制,并以one-hot向量形式表示(这种机制对于处理长时间、多阶段任务非常重要),同样的,在进行线性投影之后进入MLP层
the system iscapable of conditioning on both the object ID and manipulation skill ID, which are represented as one-hot vectors,This mechanism is crucial for employing a hi-erarchical approach to effectively address long-horizon,multi-stage tasks. - 最终的输出结果包括6D末端执行器扭转和一个二进制变量,指示夹子是否应该打开或关闭(The output is a 6D end-effector twist as well as a binary variable that indicates whether the gripper should open or close)
2.2.2 多步骤任务的解决:分级控制 (hierarchical control)
对于一些简单任务,他们tested the performance of ResNet policies with and without action chunking(这个动作分块算法即斯坦福一研究团队提出的ACT),along with a Transformer-based policy without action chunking on seen and unseen objects.
- 在已见和未见物体上,ResNet策略没有动作分块时在旋转技能方面表现优于“有动作分块的ResNet策略” 和Transformer
The ResNetpolicy without action chunking outperforms its coun-terpart with action chunking and Transformer on therotate skill. - 然而,在夹具放置和重新抓取技能方面,相比有或没有动作分块的ResNet策略,Transformer策略表现更佳
In contrast, the Transformer policies out-perform ResNet policies with or without action chunk-ing for the place on fixture and regrasp skills
但对于多步骤任务,传统的 ResNet、Transformer 和 Diffusion 方法均未能奏效,好在该论文中提出的分级控制 (hierarchical control) 方法显示出了潜力
具体而言
- 复杂任务要求机器人能够像人类一样连续完成多个步骤。此前的方法是让机器人学习整个过程,但这种方法容易因为单一环节的错误而不断累计误差,最后导致整个任务失败
无论是在单物体还是多物体操控任务中,这种方法的成功率均为 0/10 - 针对累积误差问题,研究团队采用了分层控制策略
分层策略通过将任务分解成若干小块,每完成一块便相当于通过一个决策点,即使出现错误也能迅速纠正,避免影响后续环节
例如,如果机器人在抓取过程中未能稳固抓住物体,human oracle会持续让机器人尝试直至成功(The hierarchical policiesuse a human oracle as the high-level policy)
虽说有人类的高级策略赋予一定的先验知识了,但到底用什么样的策略可以做更好呢
如下图所示,对于Multi-Object Multi-Stage Manipulation任务而言,分层策略采用人类预测作为高级策略,依次触发具有每个阶段适当的原始和对象ID的低级策略(sequentially triggering a low-level policy with the appropriate primitive and object IDs for each stage)

- 与单一对象聚类任务相似,所有无条件策略均未能成功。值得注意的是,基于Transformer的策略表现出色,成功率达到7/10
(Similar to single-object ma-nipulation tasks, all unconditioned policies achieved zerosuccess. Remarkably, the Transformer-based policy outper-formed others, achieving a success rate of 7/10) - 之所以如此,与基于ResNet的策略相比,基于Transformer的策略能够有效地排除与任务无关的模态,例如在任务中不必要地插入第4个摄像机
In contrast to the ResNet-basedpolicies, the Transformer-based policies learned to ef-fectively ignore task-irrelevant modalities, such as thenon-essential fourth camera in the insertion task.
这一属性在FMB任务的多阶段、多任务模仿学习环境中特别有益
最终,机器人在学习后能够自主进行功能操控
