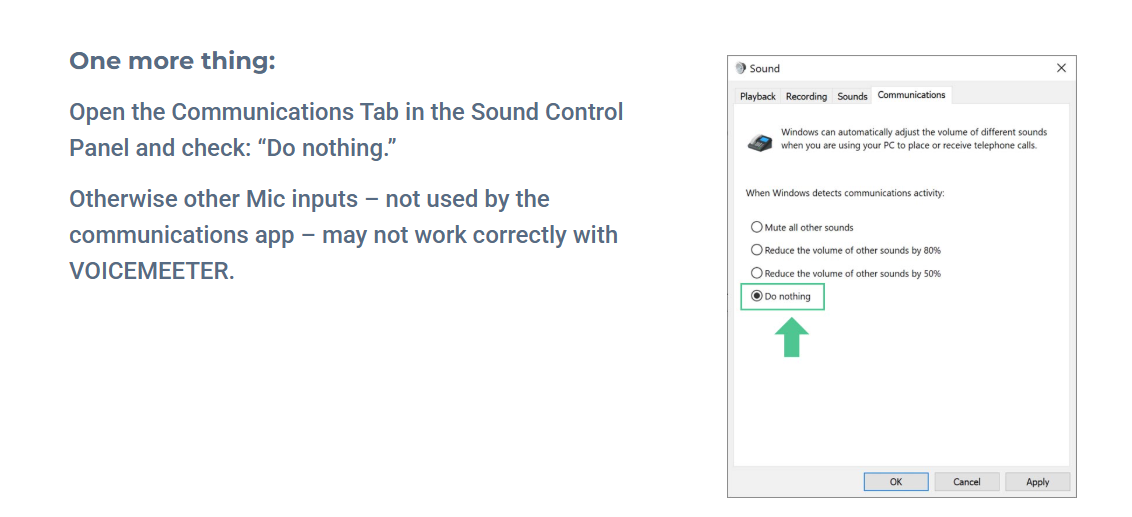
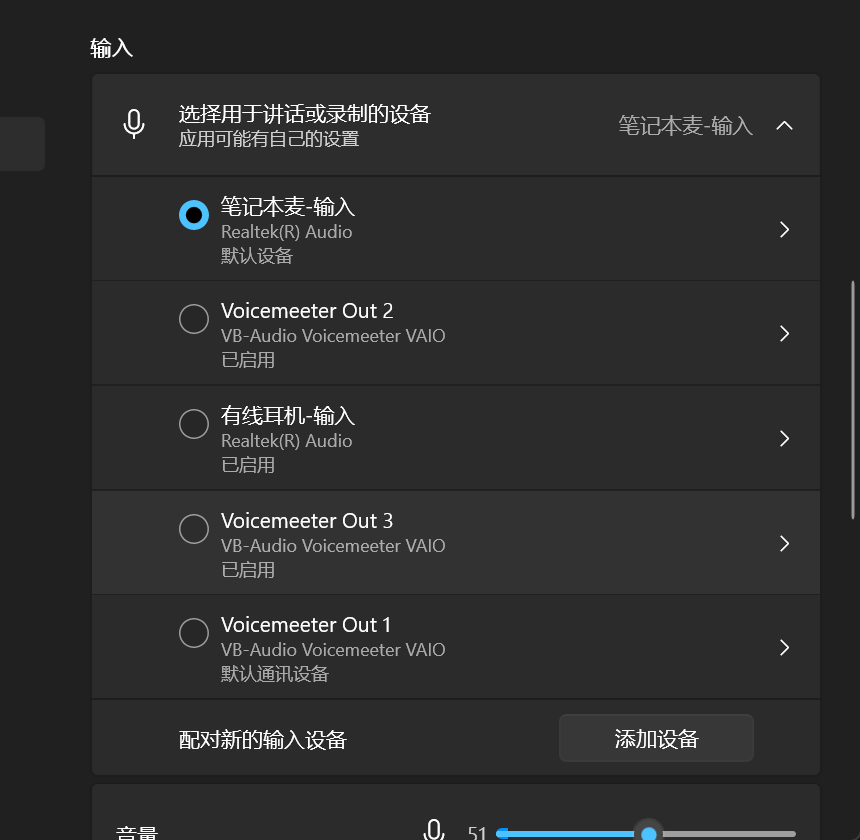
自由学习记录(91)
voice Meeter设置电脑的应用的声音都被复制一份到自己里面
这个麻烦,官方 的做法都是中转,
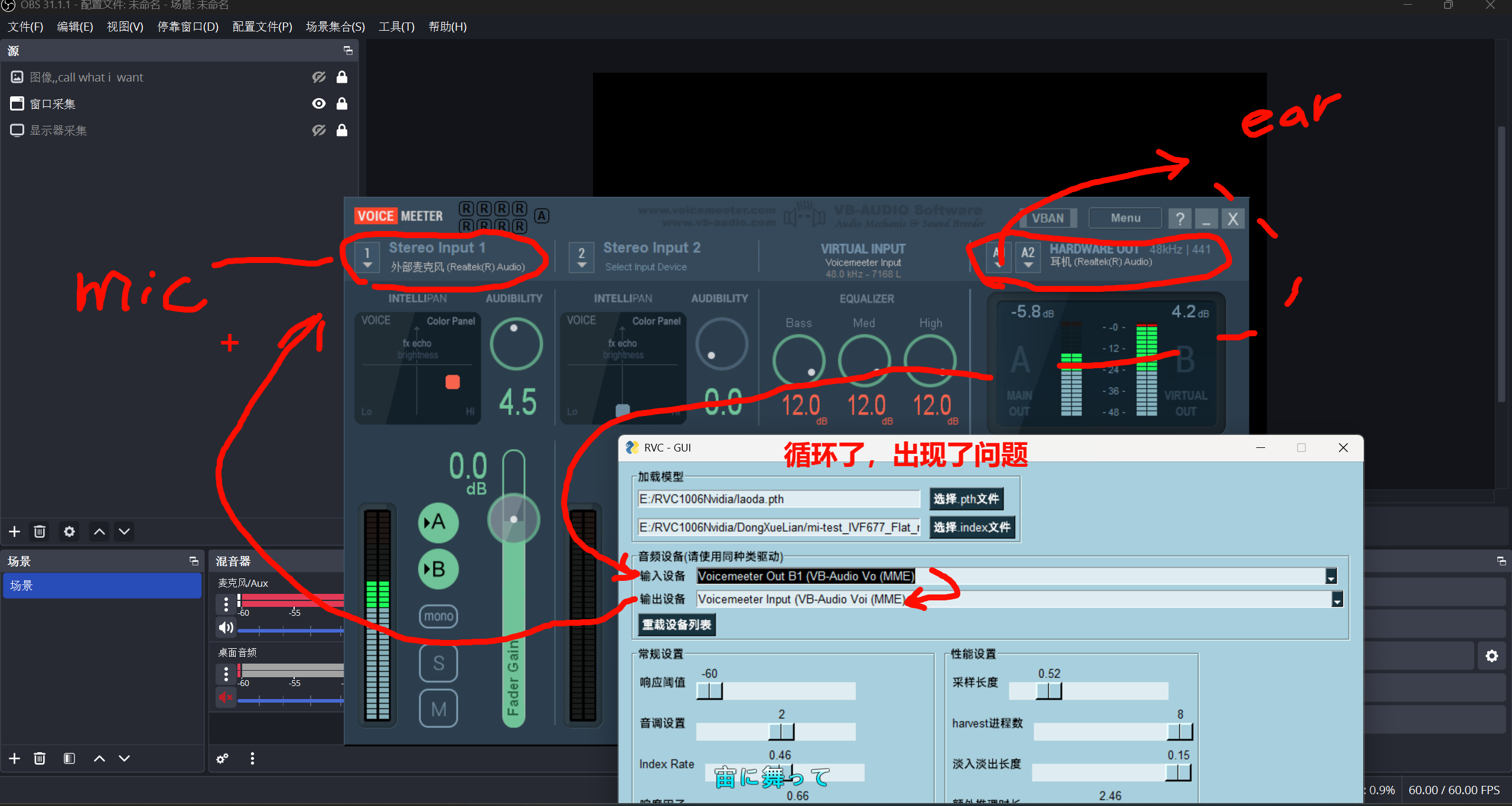
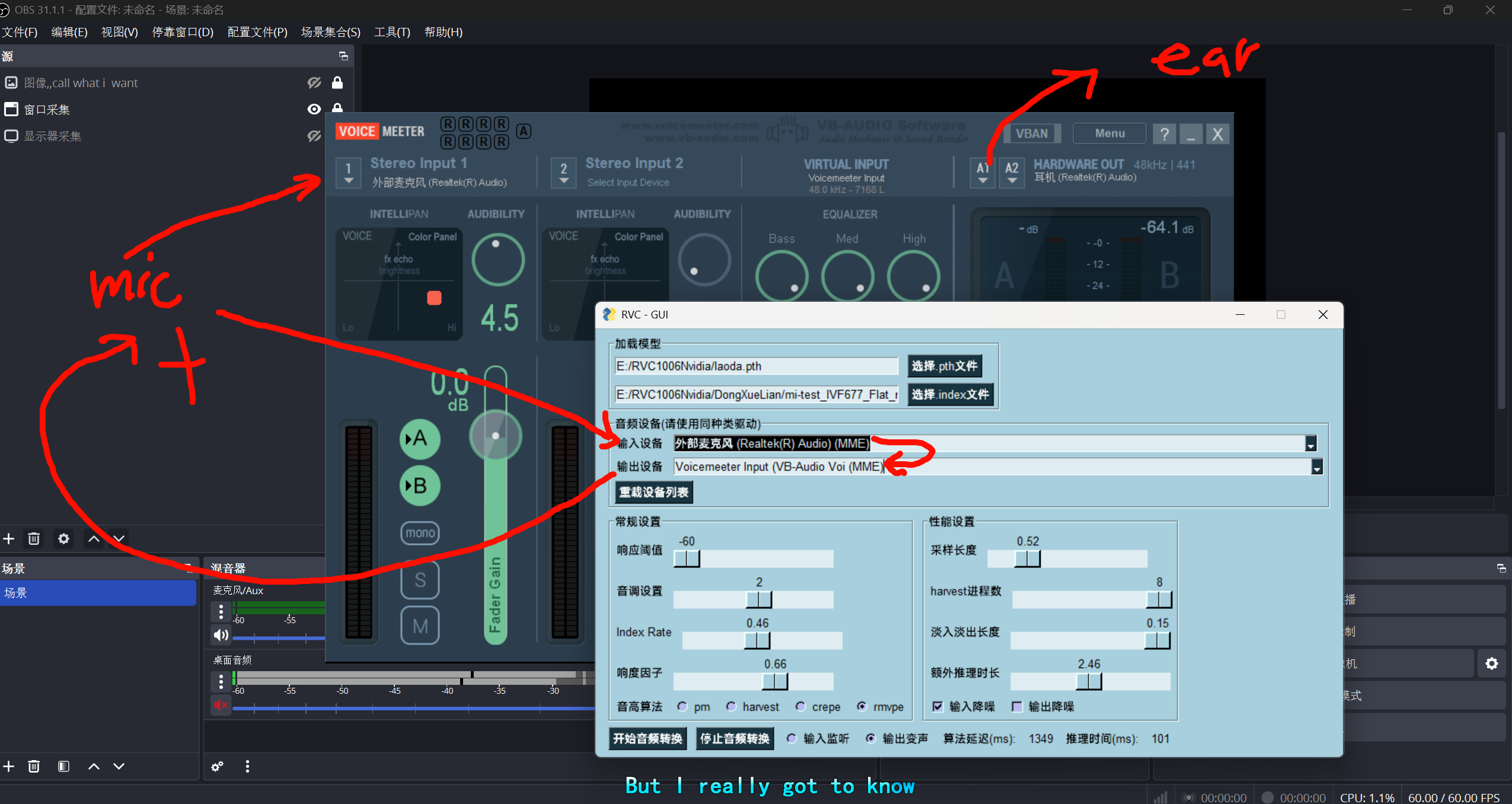
当麦out

for mic talk
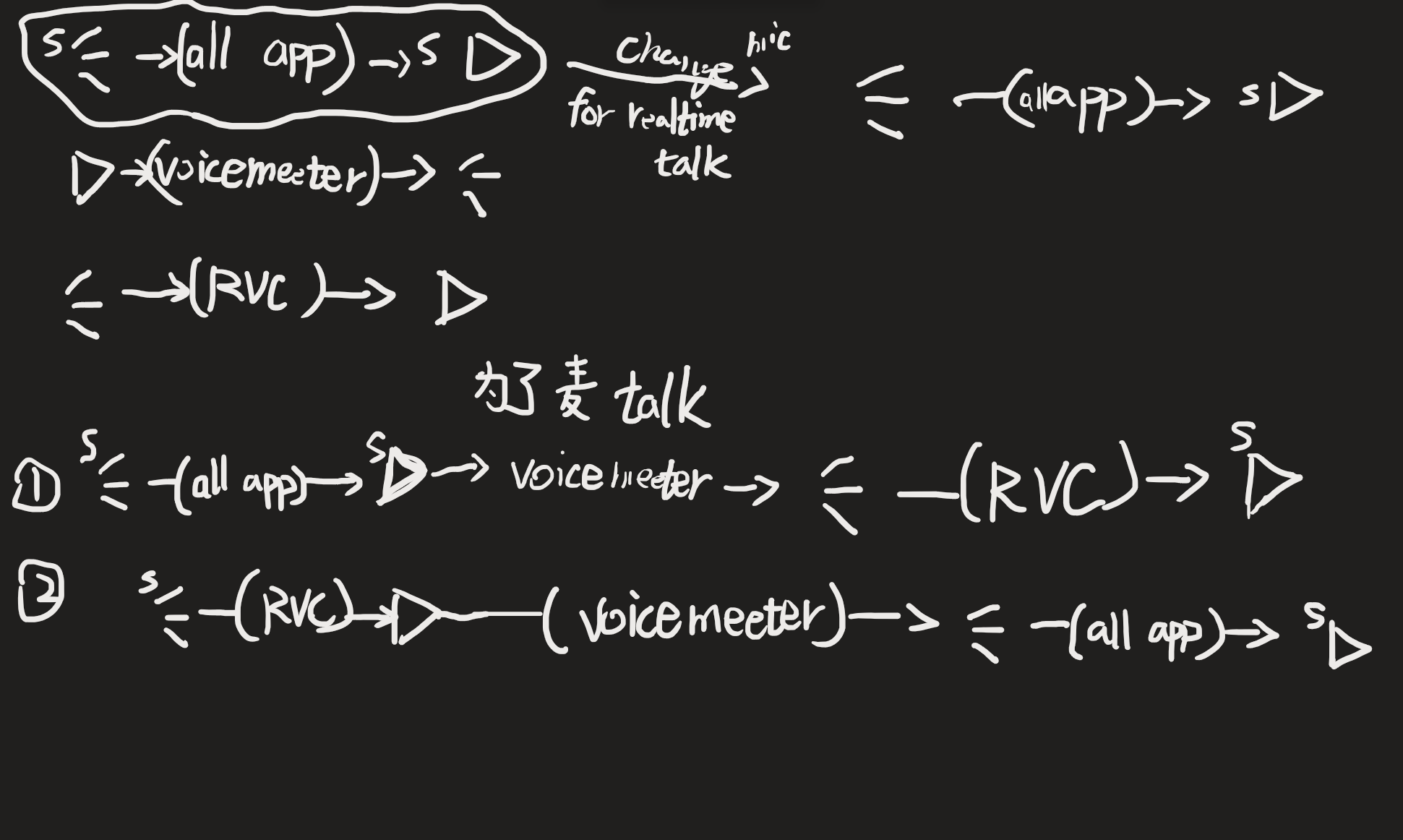
对,,如果是系统的声音要当做麦来使用,这需要额外的对系统的播放设备和接受设备进行修改了
上面的2是最符合自然逻辑的,voiceMeeter就是充当了一个反转器,让play--->Mic
因为系统的mic 和play都可以修改成虚拟的设备
发挥的是----voice Meeter的虚拟麦和虚拟Player可以顶替系统mic和系统Player
准确的说,是发挥了替换系统Player的作用
这是关键点
还忽略了一个关键点,voice也可以不顶替,只是新增两个设备
voice可以控制系统麦不参与最终的假麦的输出
voice可以mix 系统mic和系统声音
把系统Player设置成voice input,音都进voice中,此时充当输入的mic
等价了
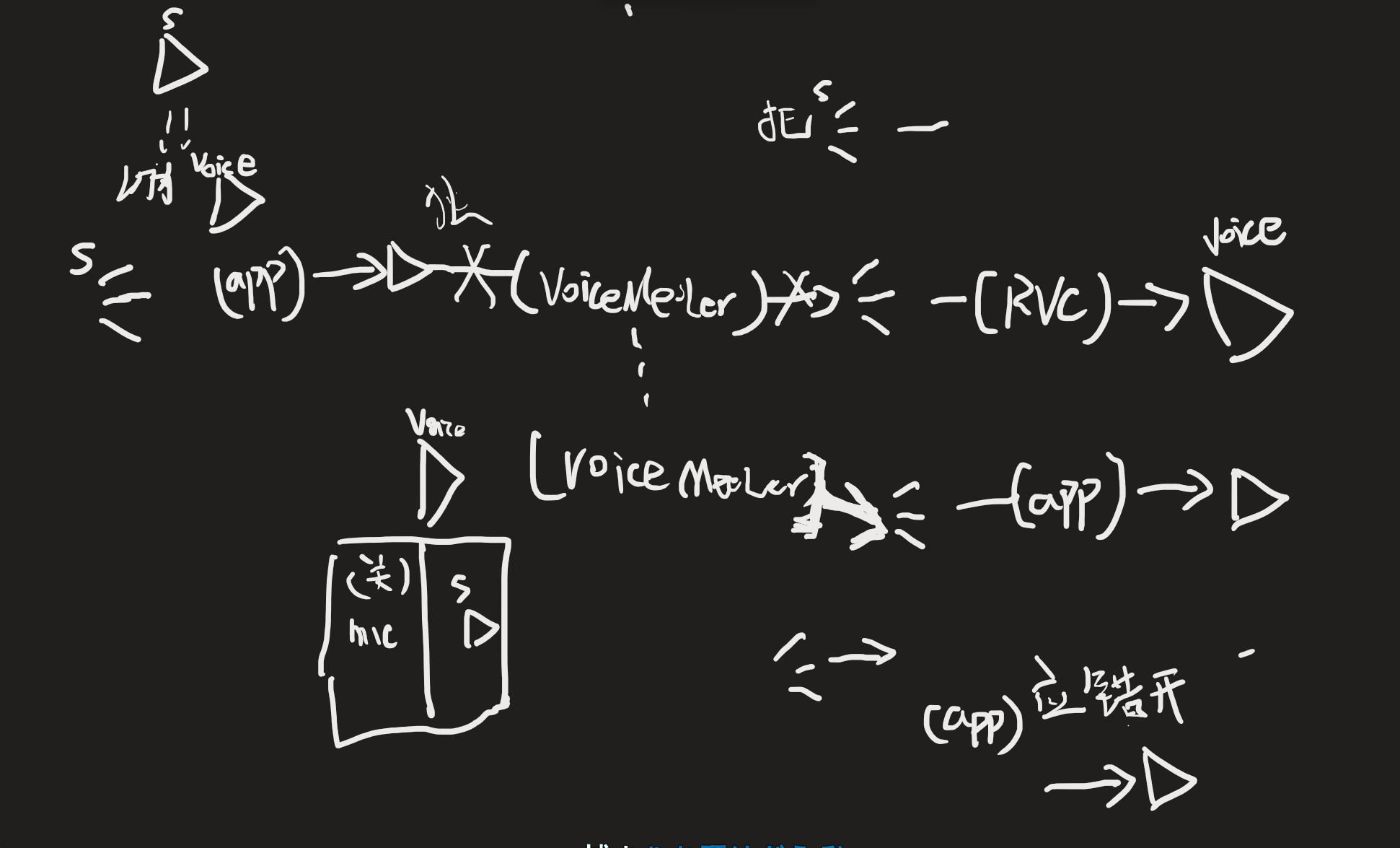
应该是一些app的声音由另一些app来承担,而不是完全的每个应用作为一个端点
每一个input ,可以选择是要发给Player段还是Record段
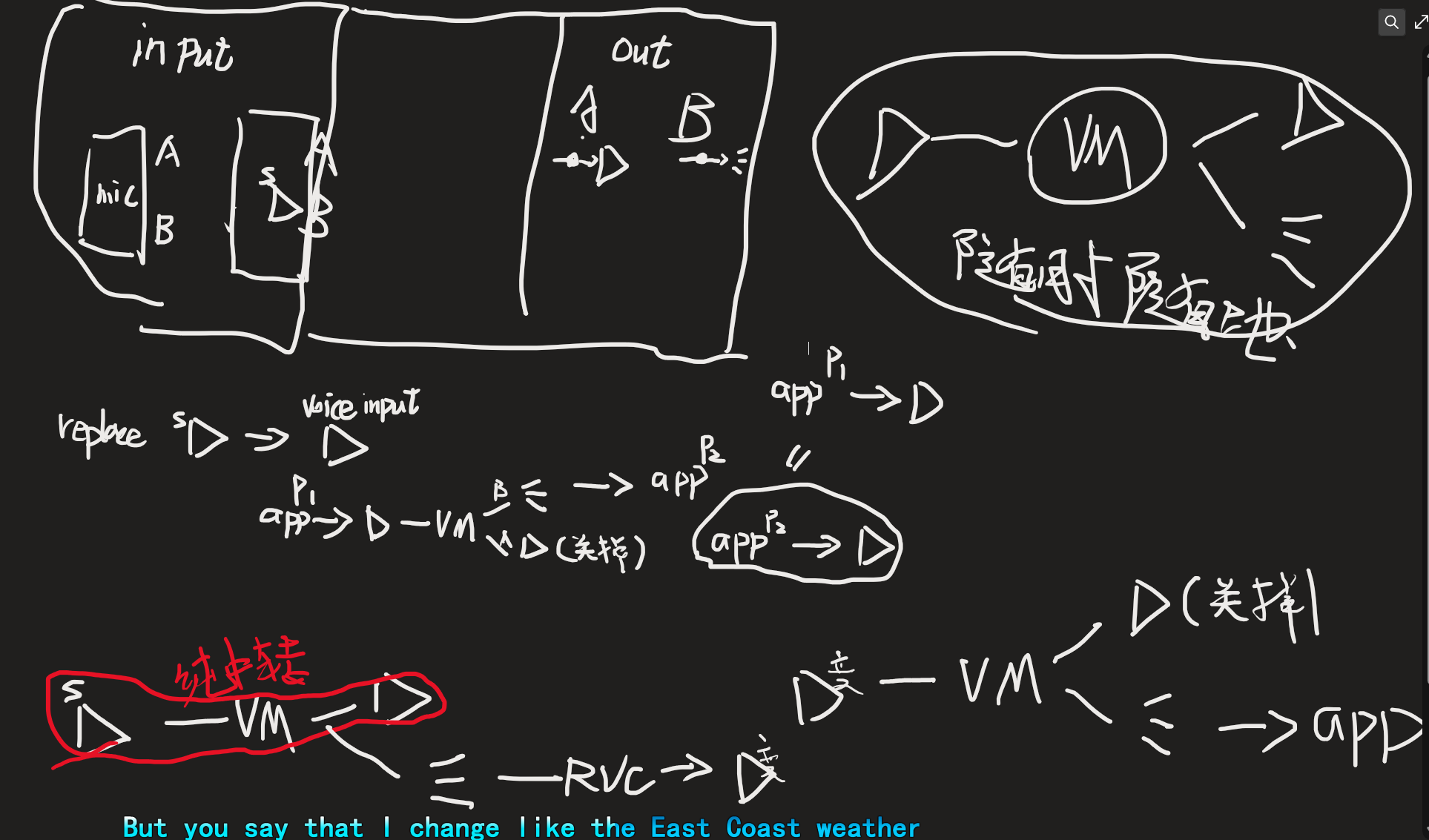
自己都迷了,,
中转站,控制得当,则任意输入输出,而不是单一的不能mix
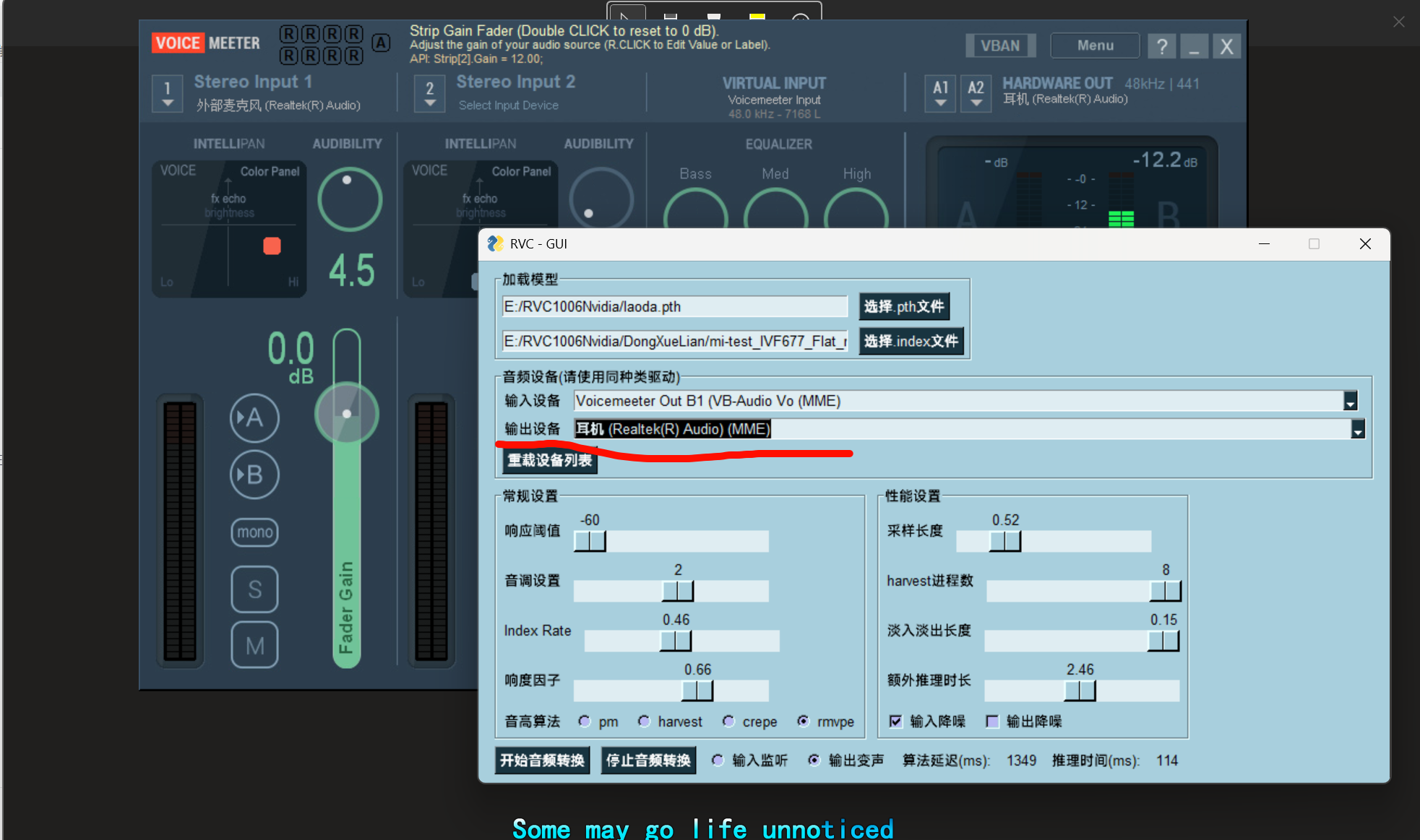
真的累啊,,达成一个目的,和讲清楚过程,差太多 了,知道基本的使用
首先rvc是中心,先配置rvc的输入和输出
在里面找
obs是独立的,可以自己挑设备,哪个做麦
系统设置和这个不一样完全没问题,因为在obs自己里面可以专业软件让你额外设置
,系统设置那的麦依然是相当于默认非音乐软件的自动设置
还是有冲突问题
,要额外开b2作为输出?--rvc里选

不对,是再增加一个input的输出段,和virtual input分开
路由器:把声音灵活分配、复制
-
VoiceMeeter 可以把任意一条输入(物理麦、应用输出、RVC 处理结果…)勾选路由到不同的“出口”:
-
A1–A5 → 送到你自己的耳机/音箱听;
-
B1–B3 → 送到虚拟麦,让游戏/语音软件接收。
-
-
你的麦克风 → RVC → VoiceMeeter → 勾 B1 → 游戏里当麦用;
-
酷狗音乐 → 单独指定输出到 VoiceMeeter AUX → RVC → 再勾 B1 → 游戏里当背景声/变声用。
你说的“一一对应”
-
不是 A1 = In1,B1 = Out1 这种一一对应。
-
而是 所有输入通道都可以任意勾选 A1/A2/A3 或 B1/B2/B3。
-
然后:
-
A1/A2/A3 分别送去你指定的硬件输出设备;
-
B1/B2/B3 分别送去 Windows 里的虚拟麦设备。
-
也就是说,,,输入input的设备
具有是要发到哪些信道上的能力,,
xxxxxx
input里的ab五个可开关,是对应着五个out进行开关
-
A1 / A2 / A3 → 对应你在右上角 “Hardware Out” 里绑定的 1/2/3 个硬件输出设备(耳机、音箱、声卡…)。
-
B1 / B2 → 对应 Windows 录音设备里的 Voicemeeter Out B1 / B2,也就是虚拟麦。
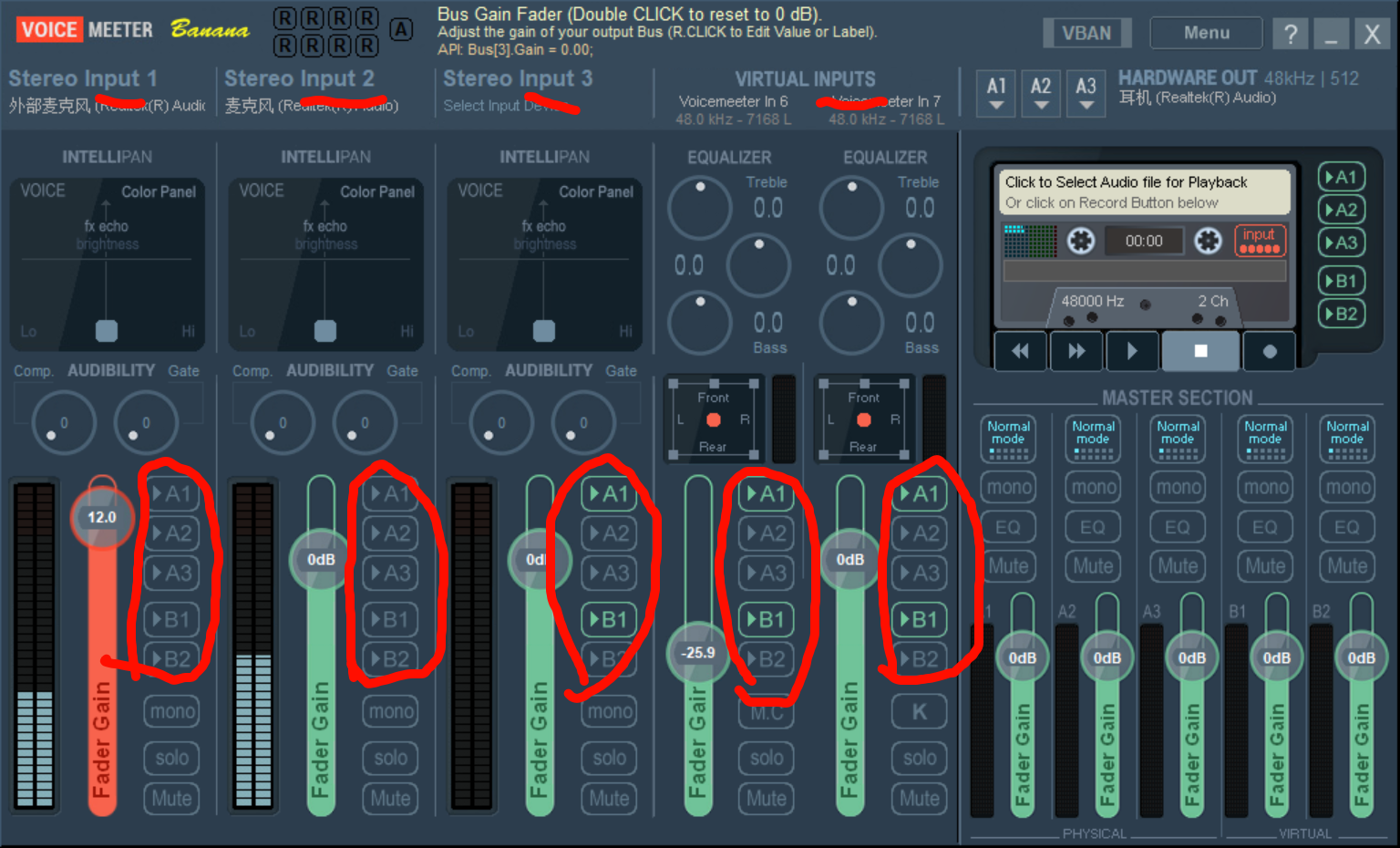
只开input里的a1和b1
意思是所有的input,要mix在一起传给右上角的out A1设备,作为一个叫做A1的输出设备装全部的数据
以及所有的input会混在一起,作为一个叫out B1的虚拟麦输入设备,
两个虚拟设备,一个输出设备A,一个输入设备B
这就是 VoiceMeeter 在 Windows 里容易让人迷糊的地方:它的虚拟输入(播放设备)全部都显示成“扬声器 VB-Audio Voicemeeter VAIO”,名字几乎一样,不标注 AUX 或 VAIO2,很难区分。
Windows 里,播放设备的名字是由驱动写死的,VoiceMeeter 给每个虚拟输入都注册成一个“扬声器”,结果就是你看到好几行一样的名字。
但实际上它们在内部是不同的端口:
-
第一个是 Voicemeeter VAIO Input
-
第二个是 Voicemeeter AUX Input
-
(如果是 Potato 版本,还会有 VAIO3)
有两种办法:
1. 用电平条试探
-
打开酷狗,把它的输出切到其中一个“扬声器 VB-Audio Voicemeeter VAIO”。
-
看 VoiceMeeter 面板上 Virtual Inputs 哪一条电平跳动(VAIO / AUX / VAIO3)。
-
这样你就知道这个“扬声器”对应哪条虚拟输入。
2. 手动重命名设备(推荐)
-
在 Windows 声音设置 → 右键设备 → 属性 → 常规 → 重命名。
-
例如改成:
-
Voicemeeter VAIO (系统声)
-
Voicemeeter AUX (酷狗专用)
-
Voicemeeter VAIO3 (备用)
-
这样一来,列表里就不会全是“扬声器”,你可以清楚地挑选。
xxxxx
美的效果,然后是性能好的效果,
也就是说,两个虚拟的输出有多个数据传输类型的变种?其他的关掉就可以?
-
真正的虚拟输出设备只有两条(Banana 里就是 VAIO 和 AUX)。
-
你看到的其他一大堆“扬声器 (VB-Audio Voicemeeter VAIO)”只是 同一条设备在不同音频传输方式 (Host API) 下的“变种入口”。
常见的几种 API:
-
MME → 最老的接口,兼容性好,但延迟大;
-
WASAPI → Windows 现代接口,延迟较低,推荐;
-
DirectSound → 游戏常用,延迟介于 MME 和 WASAPI;
-
KS (Kernel Streaming) → 直接驱动级别,延迟最低,但兼容性差。
所以其他的东西关掉就可以
在一台笔记本电脑上,自带的麦克风和扬声器在 Windows 里通常会以 硬件厂商 + Realtek/Intel/Conexant 等音频芯片驱动的名字出现。
先不顺规矩,才顺规矩
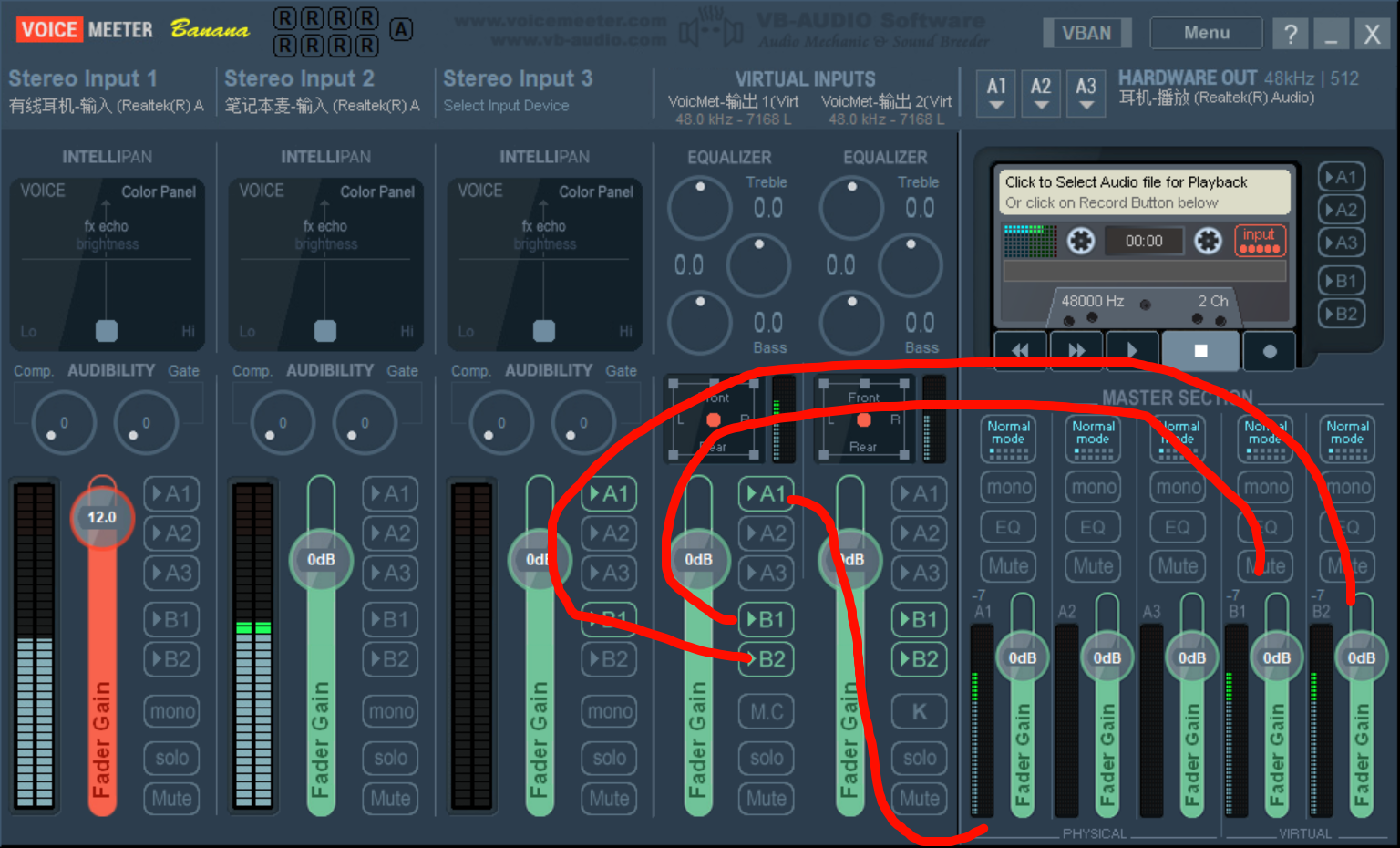
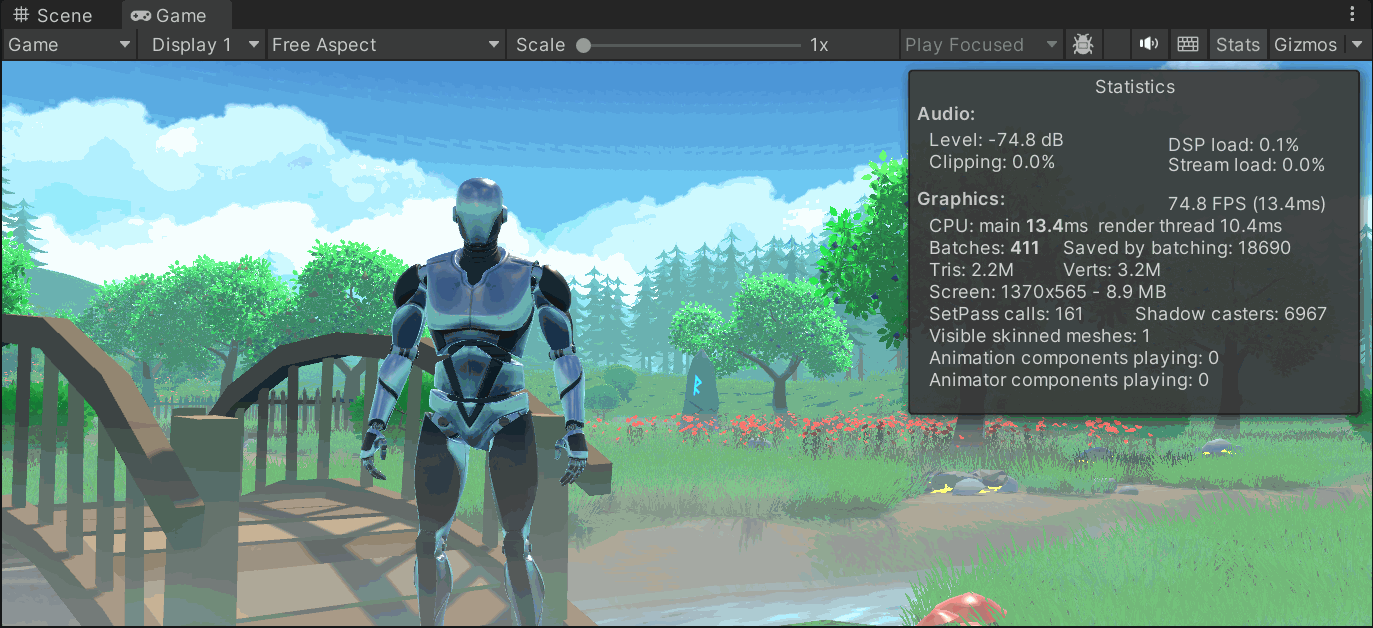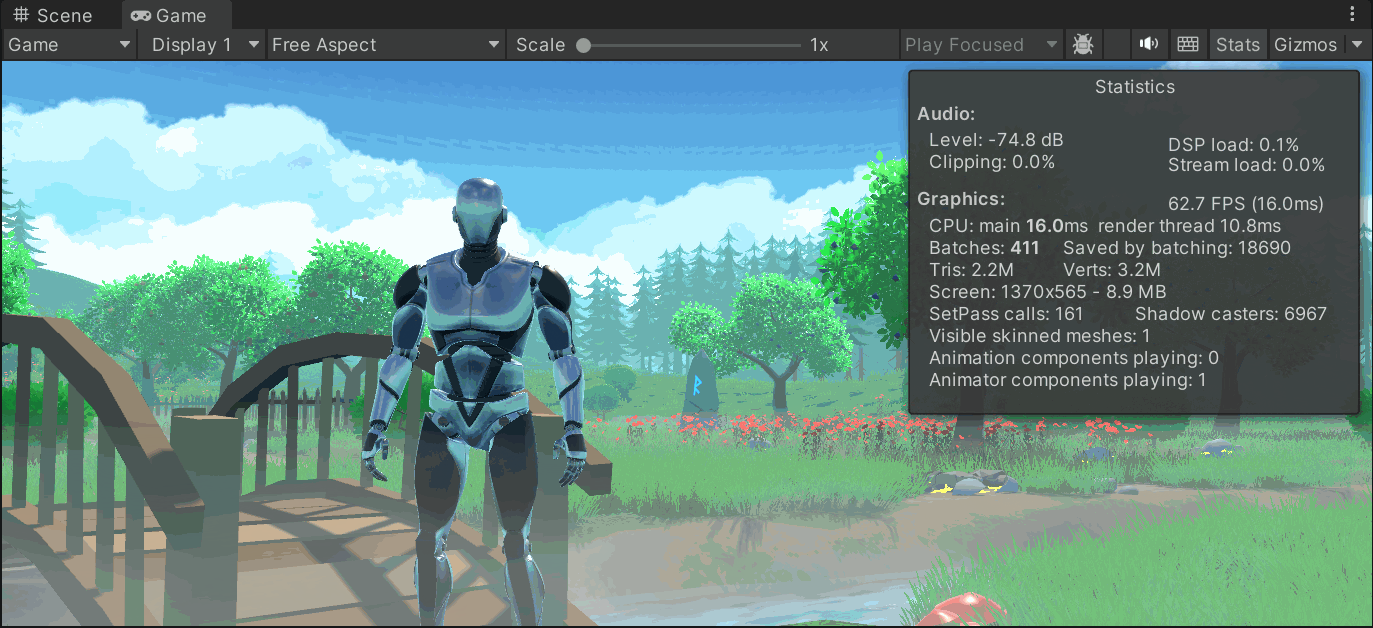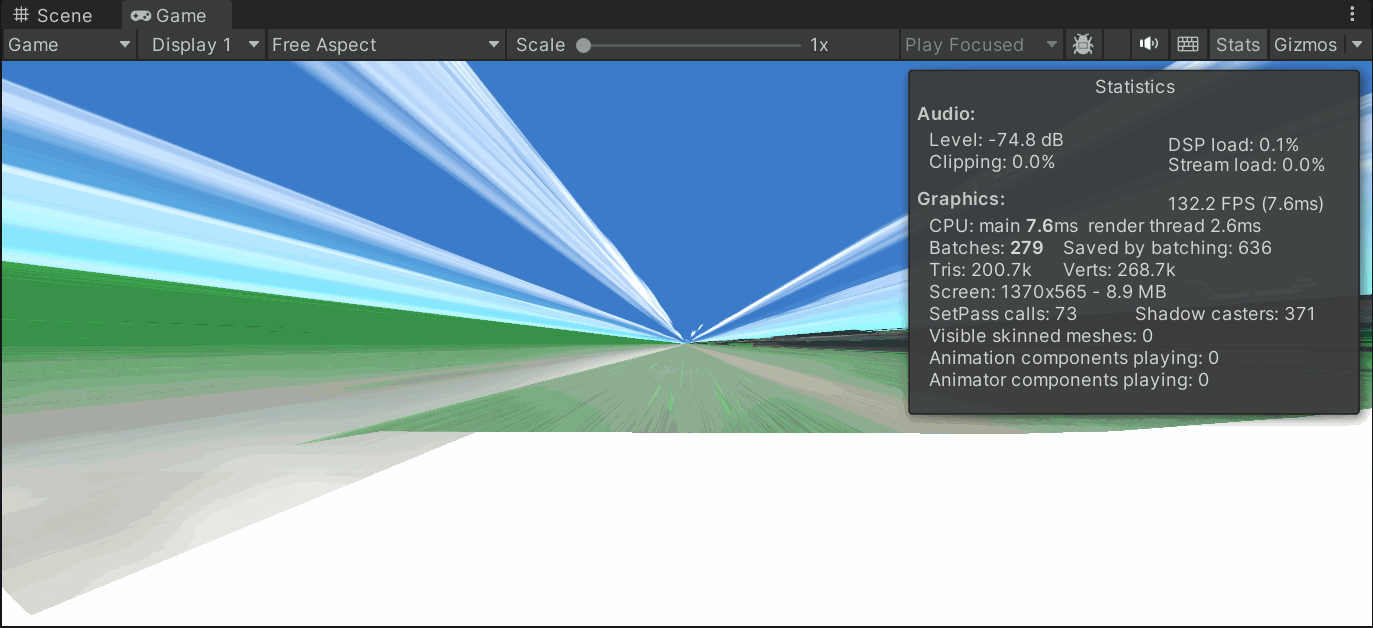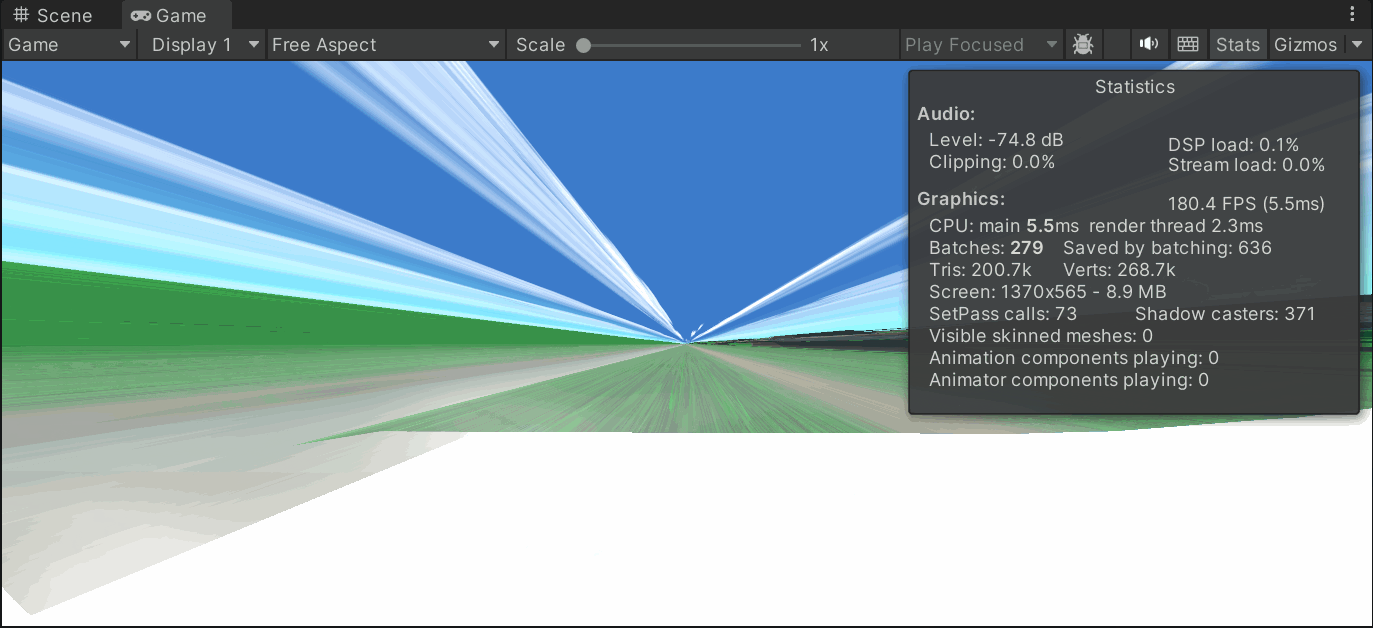
5 个总线输出通道 (Bus / Out) 的音量控制:
-
A1、A2、A3 → 三个 物理输出,对应你在右上角 “HARDWARE OUT” 里选的设备(耳机 / 扬声器 / 声卡)。
-
B1、B2 → 两个 虚拟输出,对应 Windows 录音设备里的 Voicemeeter Out (B1/B2),软件和游戏会把它们当成“虚拟麦克风”。
VoiceMeeter 的 “Out” 类型
-
A1/A2/A3:这是硬件输出(耳机/音箱),不会出现在输入设备列表里,因为它们不是“麦克风”。
-
B1/B2:这是虚拟输出(虚拟麦),会在输入设备里显示为 Voicemeeter Out。
-
如果你用 Potato 版本,会有 B1/B2/B3;Banana 就只有 B1/B2。
只有在vm开启时,才会激活out麦--B1/B2/B3
-
Windows 输入设备里的 Voicemeeter Out N = VoiceMeeter 面板右下角的 B 通道(虚拟麦)。
-
所以你看到的
Out 1/2/3,并不是 A1/A2/A3,而是 B1/B2/B3。 -
A1/A2/A3 只对应到右上角你选的硬件耳机/音箱,不会在这里显示成“麦”。
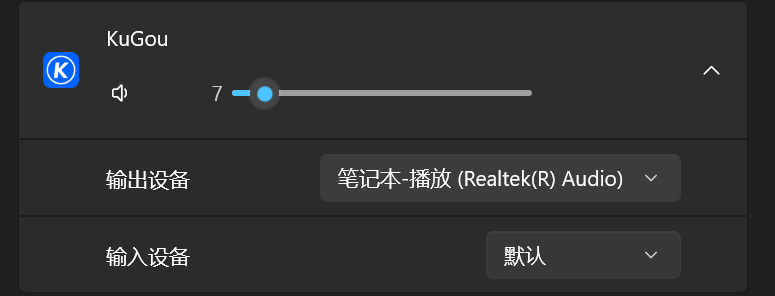
我在纯粹的不管vm的情况下,我的酷狗设置输出设备为电脑扬声器,,但是依然是在我的默认扬声器里播放了,
原因
在 Windows 的机制里:
-
有些应用(特别是国内播放器类,比如酷狗、QQ 音乐)并不是完全遵守 Windows 的 per-app 输出 API。
-
即使你在「高级音量设置」里切换了,它们仍然会绑定到 系统默认设备。
-
所以你看到的情况就是:虽然设置成“笔记本-播放”,但实际依然跑到了你系统的“默认扬声器”。
爱很简单,很清澈,很纯真,看着sweet多了
酷狗不听劝,不会单独把自己的声道分出去,,只听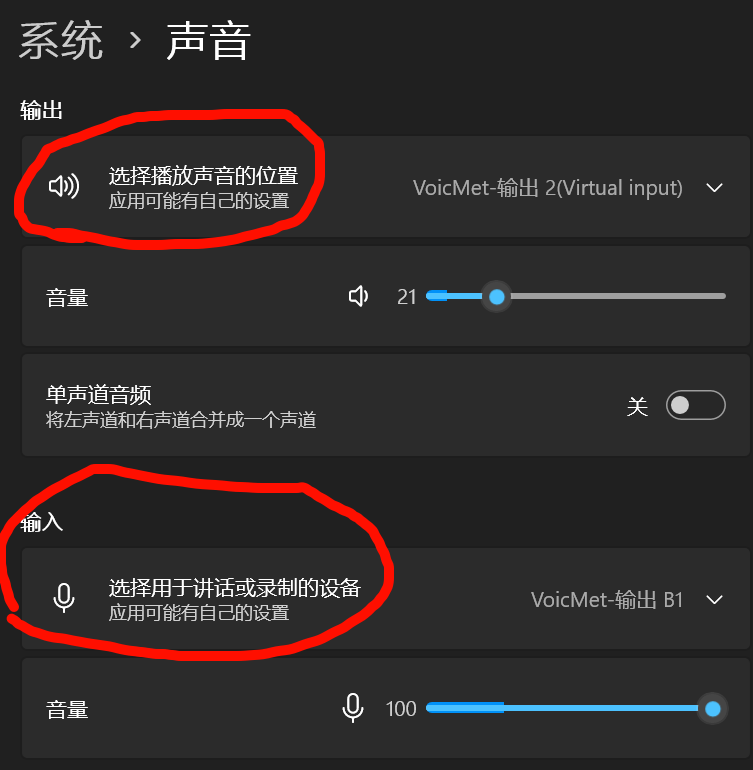
这里的综合设置
不能单独设置,但是谷歌可以,适配性好的就可以单独分出来了,
想要酷狗的声音拿去做rvc的输入
就必须得在默认这里设置了,,
就不知道一般 的游戏可以单独设置声道吗
试一下少女前线
靠,少女前线就没问题,,看来是音乐播放软件为了保护一些什么版权设置的门槛吧,
还有一点就是,如果开了vm,就要做好把输出设备给vm的打算,,否则游览器视频都会给你卡主的,,大致什么问题,也觉得不是不合理,所以开了就准备完全接管了,反正vm里面可以放给三个设备,,和在这里设置完全一样的
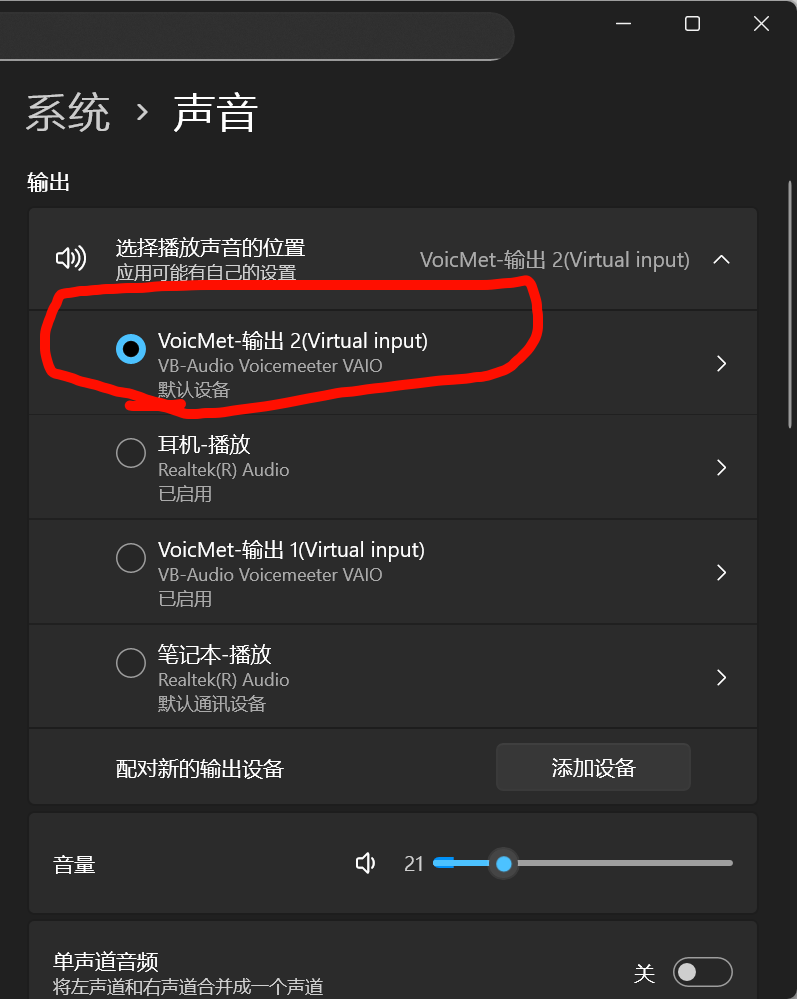
总之开了vm,就把这两个给修改了,不然会出问题,游览器声音播放冲突,直接卡主
重点就是开了vm,把这里配置好之后,就系统设置就完全无效了,不要管了
一切听vm的
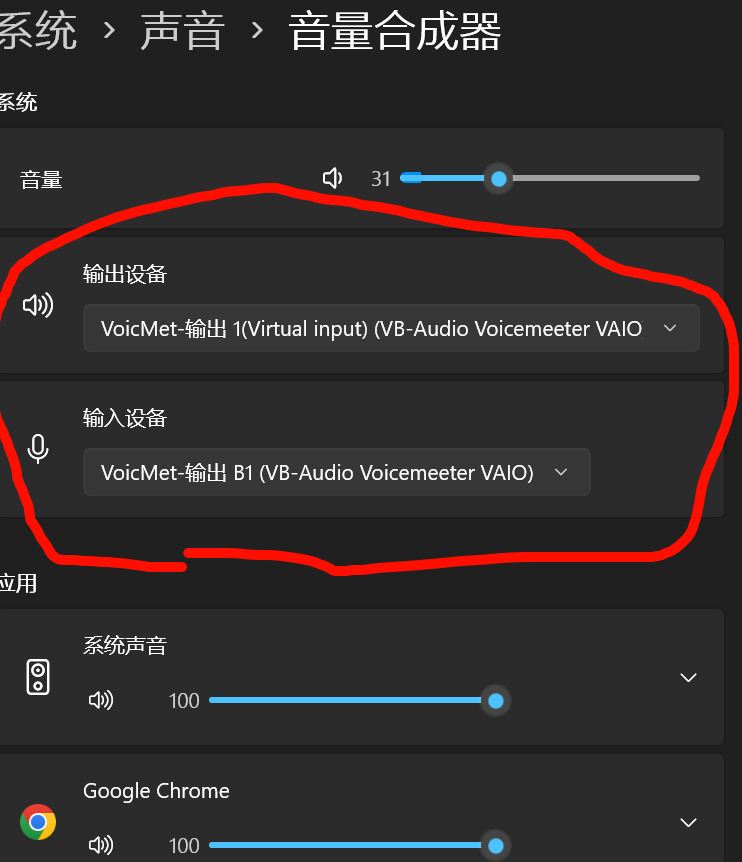
打开vm,会自动调整音量,,让整体能输出一个舒服 的麦范围,并且调整输出达到和原本的系统输出到耳机里一样的音量大小
也是管不上,管 了更糟的地方
先做事,再记录
记住,这一切都配置好了,,再打开你的rvc,,---再次强调,一切都配置好了,再打开你的rvc
此时你的输入设备和输出设备的选择,才会清晰明了的
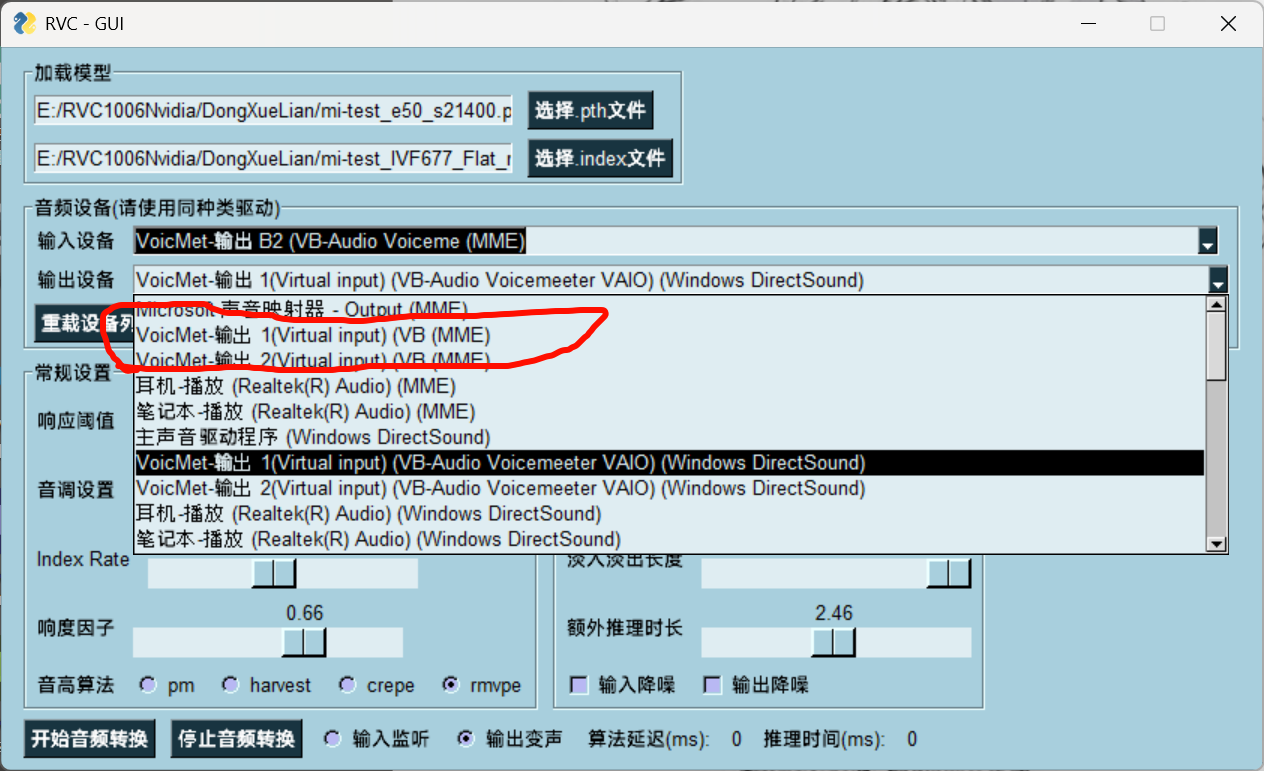
那这样看,甚至还需要第三条线才可以做到了
一个作为游戏正常听,一个作为分出来的酷狗音乐
一个作为rvc转换之后的接受的第三Virtual input了
而问题是,那不是banana版本了
所以可以做的是,v1接受酷狗,v2接收返回出的rvc结果
然后A123 B12
A123全关掉
B用系统麦输出
只能这样,关掉除了酷狗之外的全部声音,,,靠,,那就不能依然正常的听到系统的声音了
在 VoiceMeeter Banana 里,虚拟输入(Virtual Inputs)确实只有 2 条:
-
Voicemeeter VAIO Input
-
Voicemeeter AUX Input
如果你需要 3 条虚拟输入(比如:
-
系统声
-
酷狗单独一路
-
另一个应用 / RVC 输出),
那 Banana 不够用。
不对不对不对不对
可以作为一个直接输出的麦啊,不用额外第三个input
因为我并不打算听这个input

是存在解法的,,两个是够的
不行不行,,服了,,还是要三个Virtual input,,rvc不能直接输出给b1,只能输出给Virtual input
换成potato,,三个
设备里也非常的简洁了,很干净
差太多了
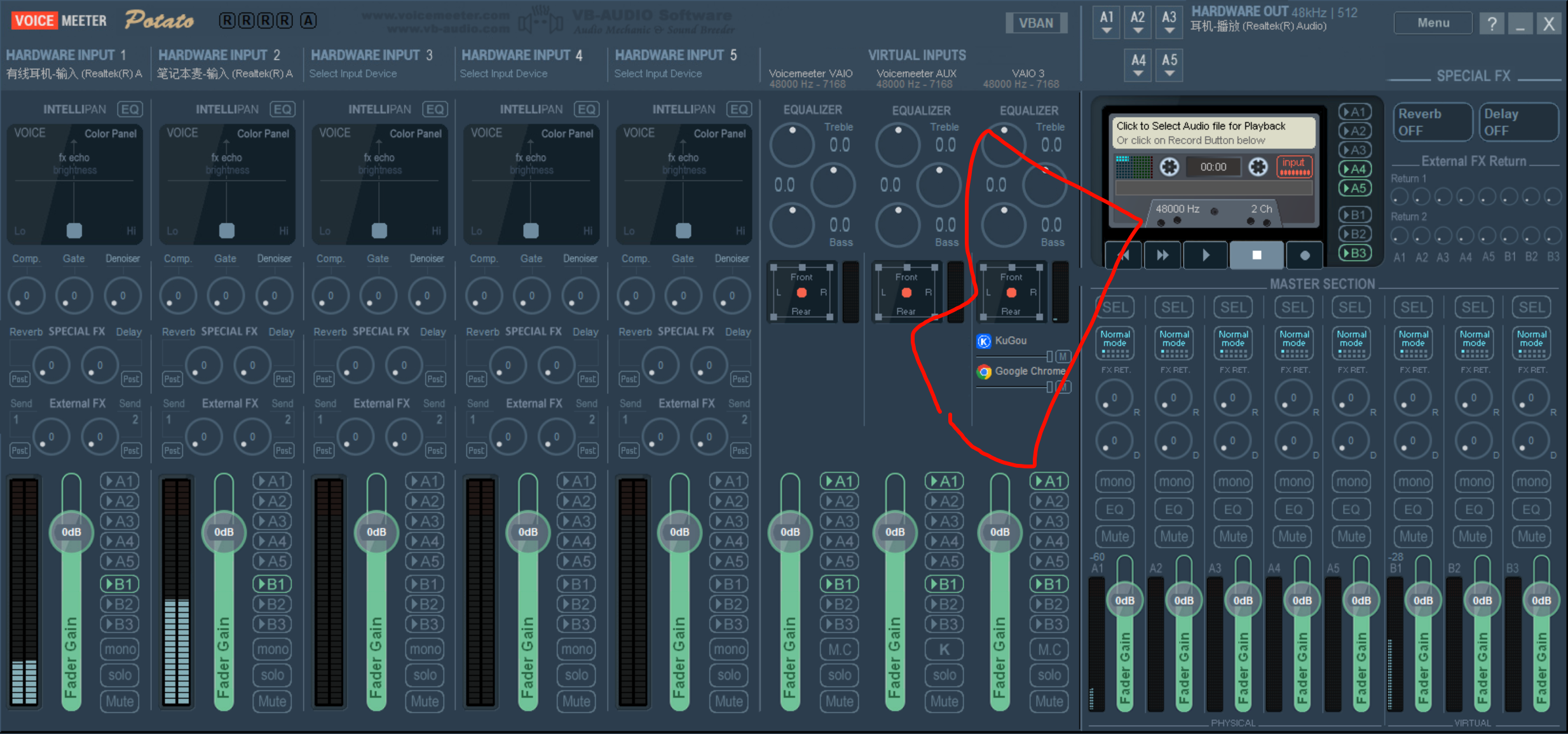
直接还可以单独挑出来mute
离谱
-
Voicemeeter VAIO Input:第一条虚拟输入,Windows 里显示为一个“扬声器”。
-
Voicemeeter AUX Input:第二条虚拟输入,AUX 就表示“额外的/辅助的”输入通道。
-
如果是 Potato 版,还会有第三条 Voicemeeter VAIO3 Input。
所以,AUX Input = 第二条独立的虚拟输入声卡,它的作用是给你分流:
-
你可以把“系统默认声音”放到 VAIO Input;
-
把“酷狗音乐”单独指定到 AUX Input;
-
然后在 VoiceMeeter 面板上,这两路声音就是两条分开的推子,你可以分别控制要不要推给耳机(A1)或虚拟麦(B1/B2)。
测试麦克风,只能通过obs的外界软件测试
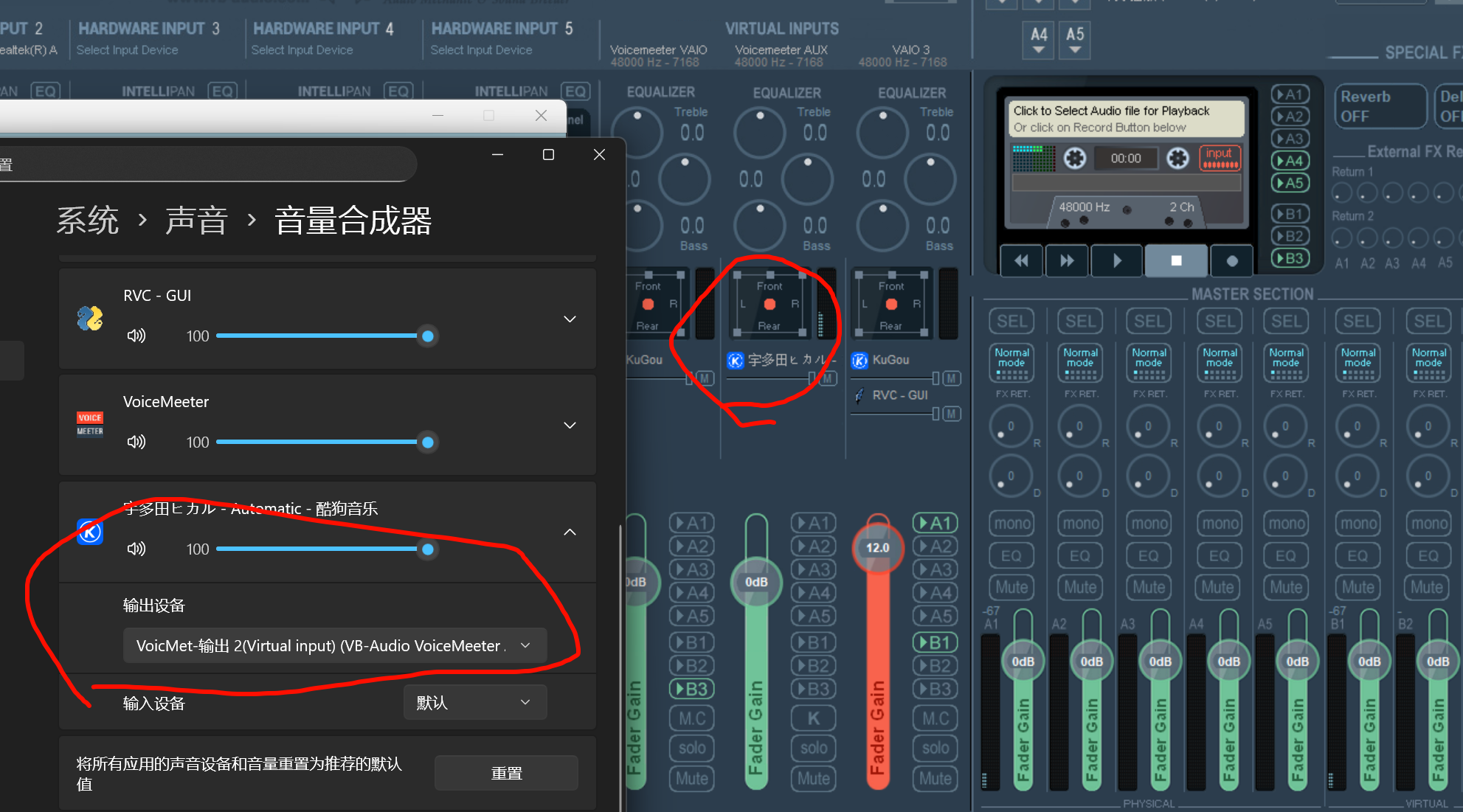
原来都是banana的错,potato就可以把酷狗分出来啊
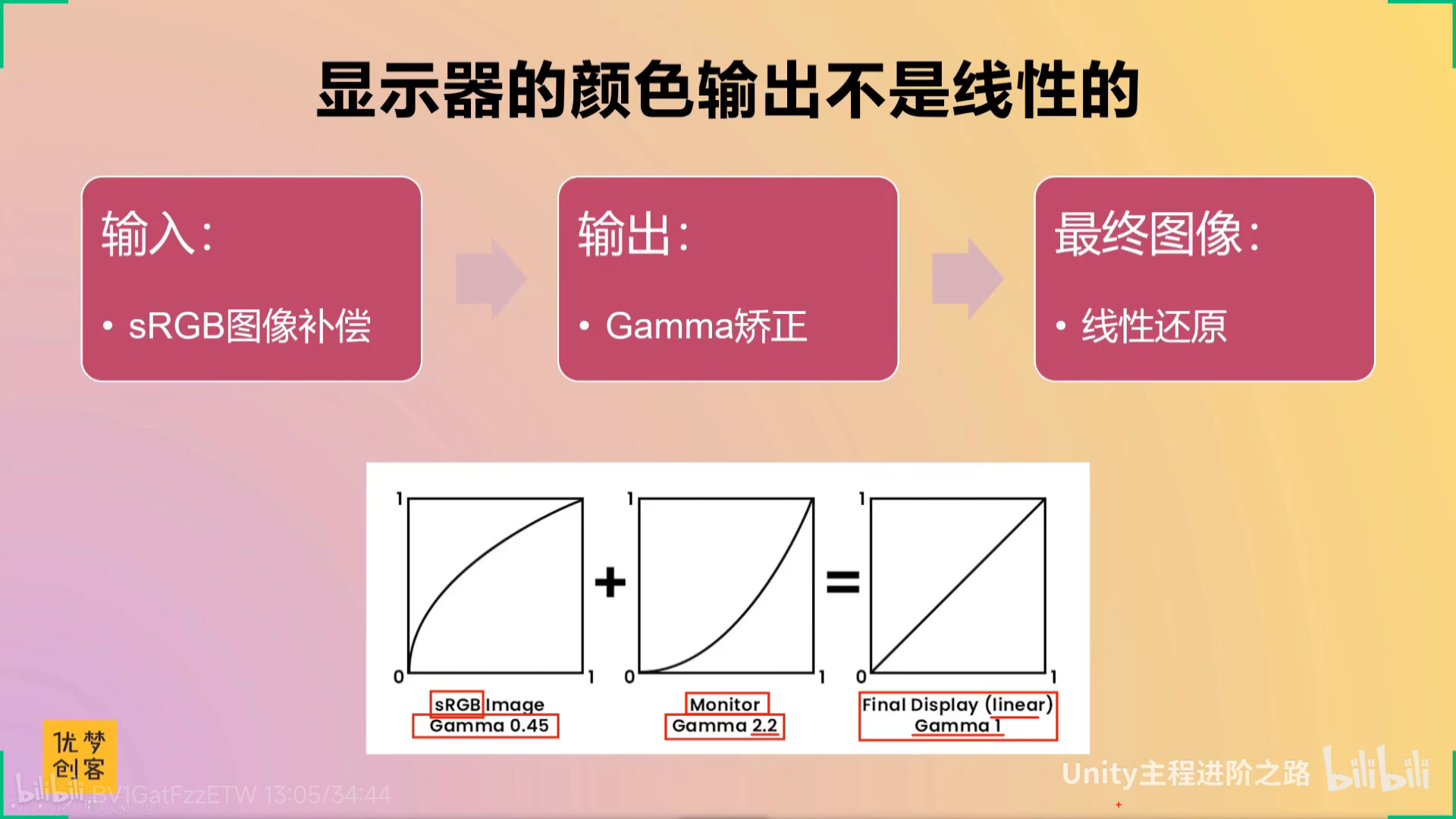
【【TA面试必问】线性与Gamma 颜色空间-哔哩哔哩】 https://b23.tv/X4wMwUN
伽玛2.2,伽玛0.45,还有点专业


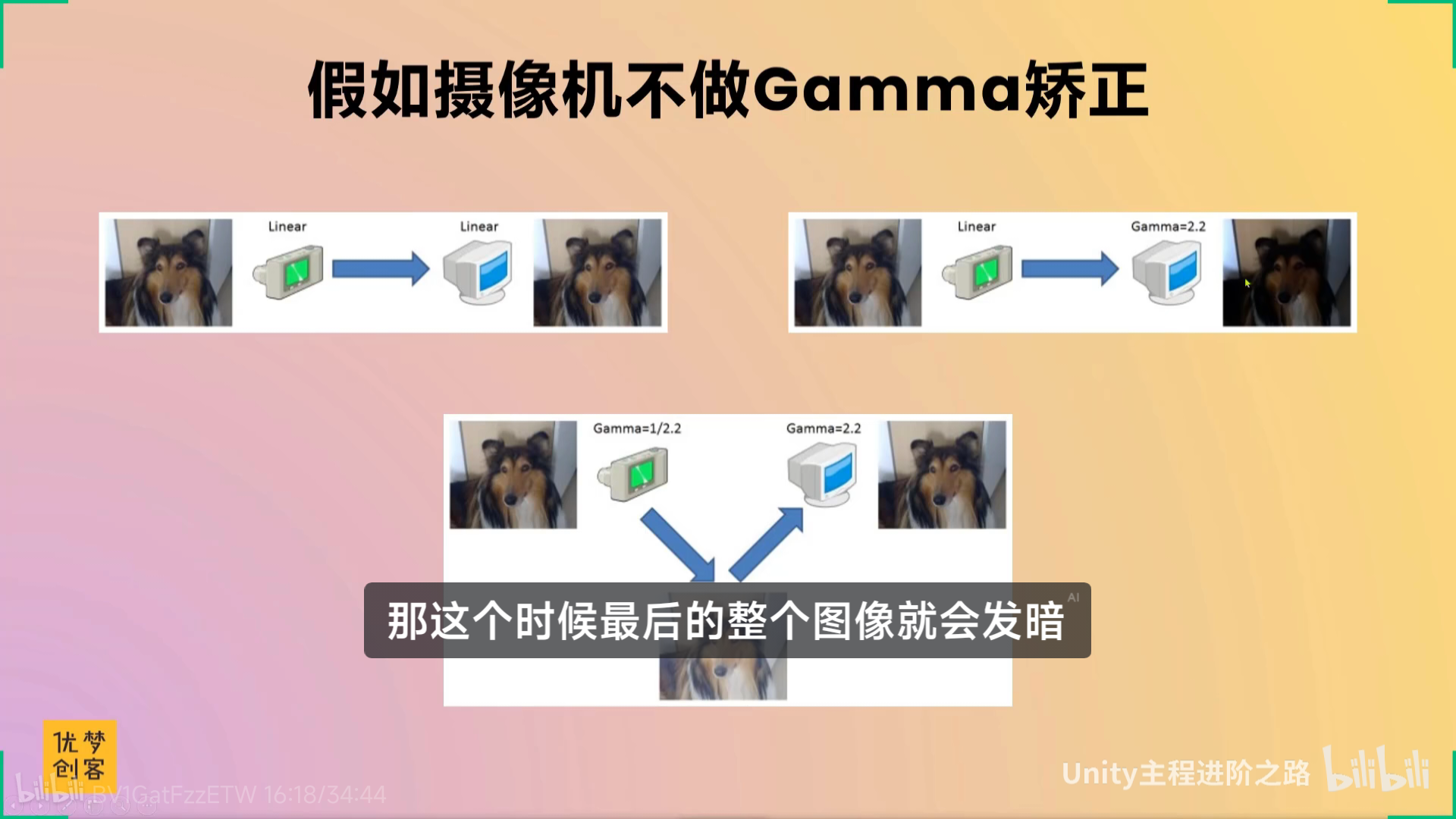
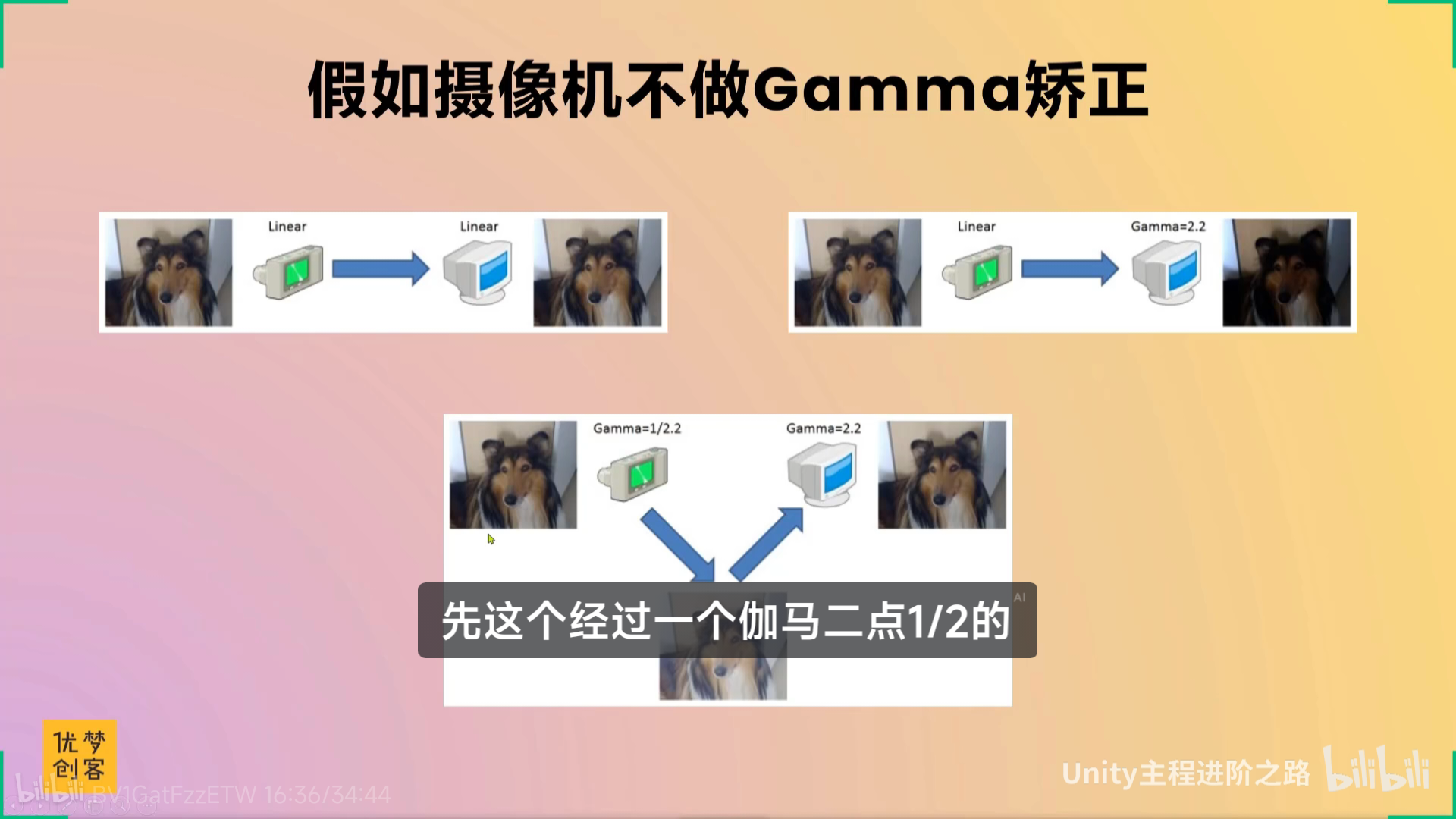
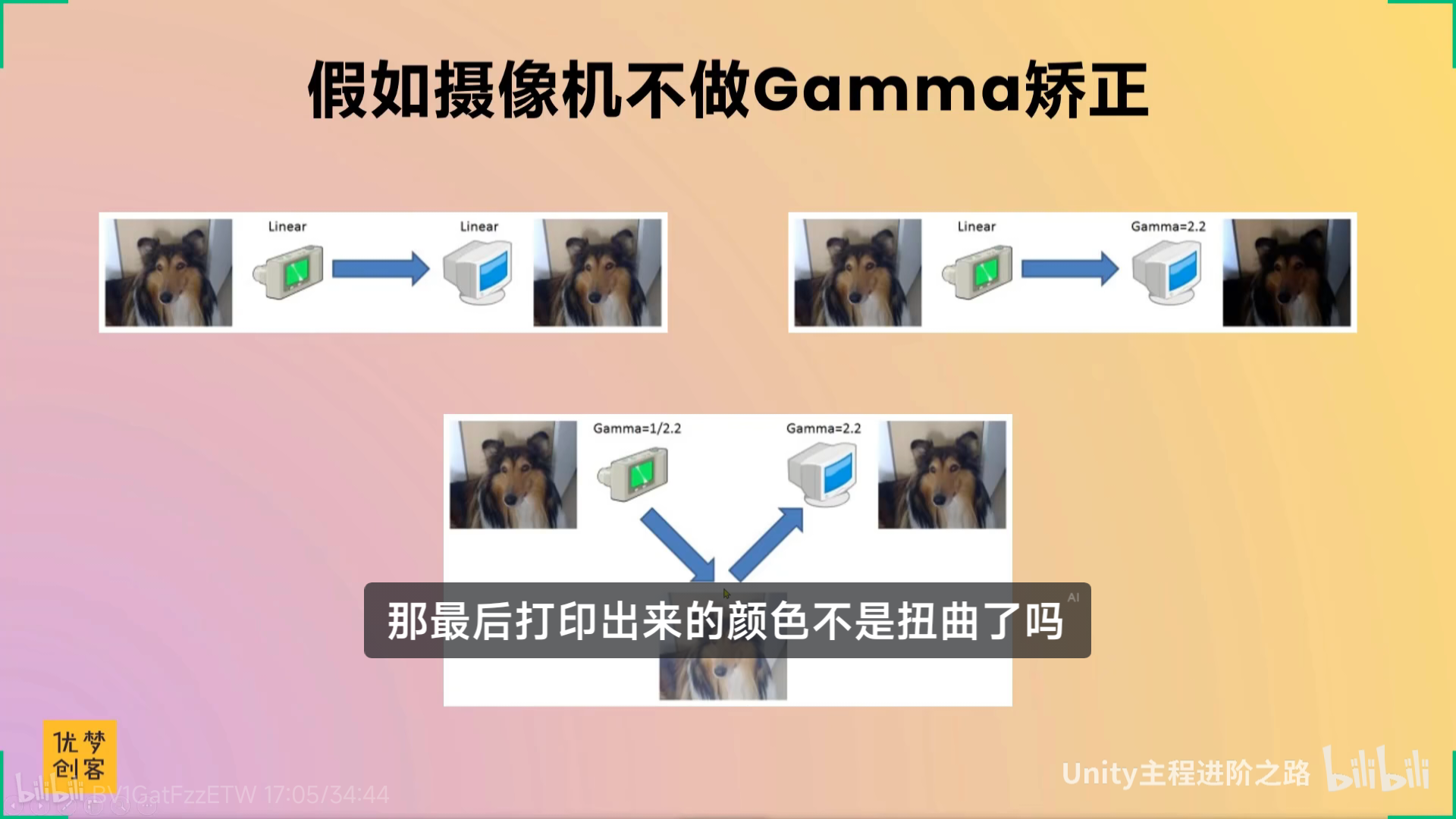
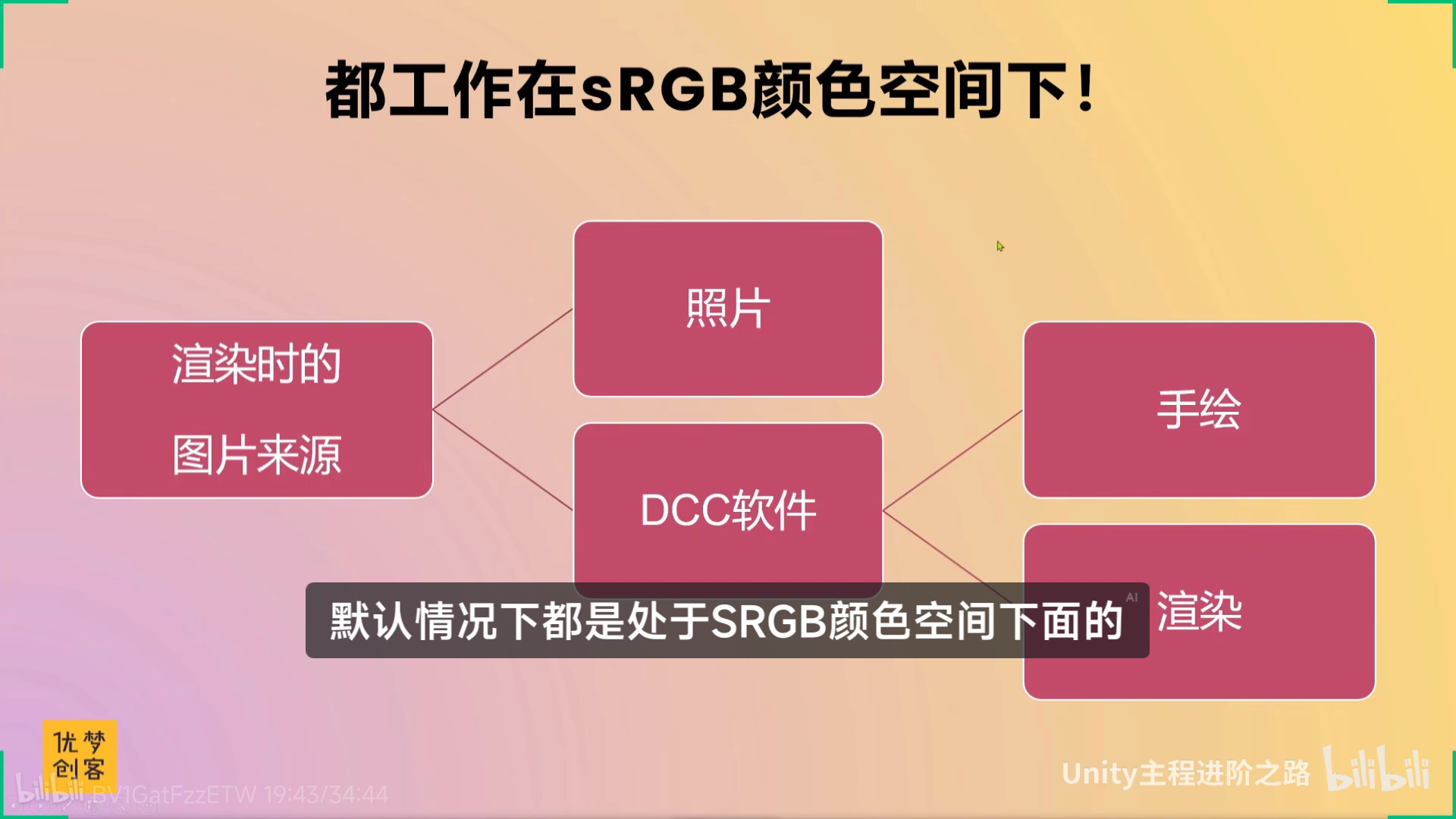
xxxxxxx
小问题
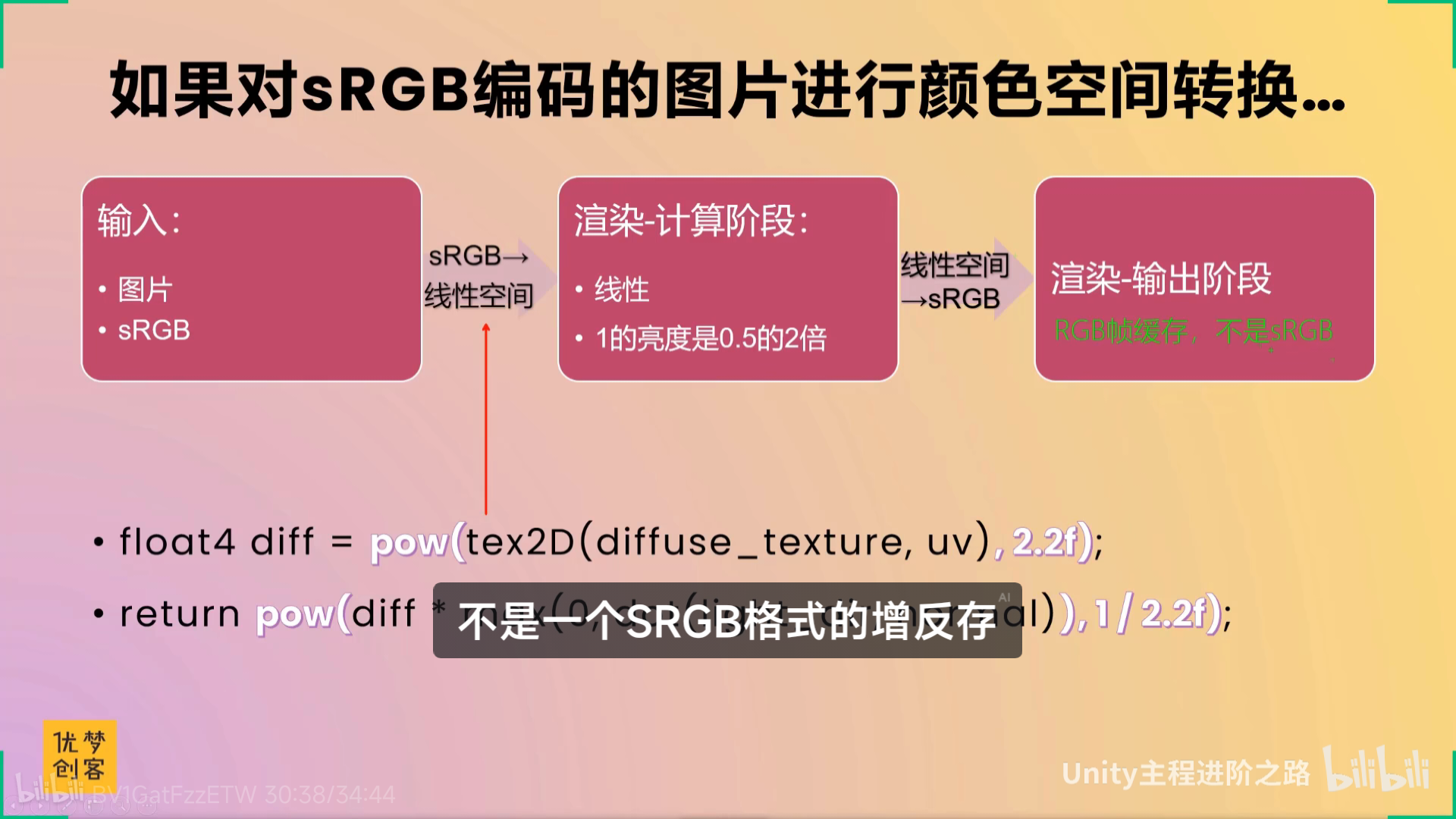
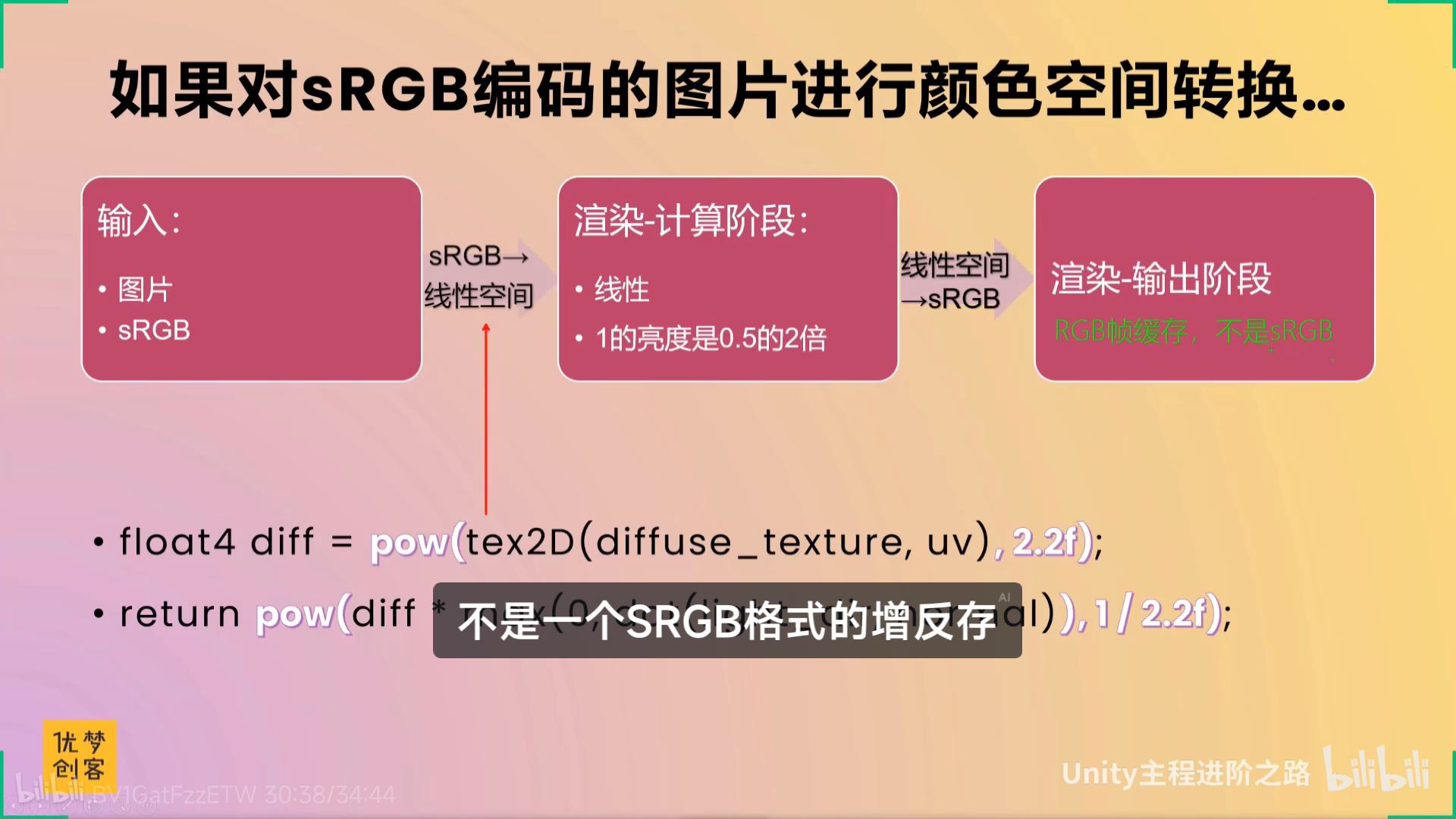
单纯只是看还是太淡了,不上unity做实在感受不到什么东西
还是回到之前来看----relax蛮久的
想一下,先把这个描边的远近距离解决,然后再找一个sdf渲染?体积云,ray marching?
render doc,
render doc里面的调式 很精细,看到分了很多阶段,过程的理解反而比一些散开的教程要更加完整,还有substance designer的使用,里面的重要部分
那要从什么下手去学?既然要熟悉整个渲染的过程,,render doc是最好的上手的地方,如果有不懂就额外的去搜,,rayMarch,,体积云体积雾,,但是想先找一些项目去熟悉一下再去render doc,,感觉现在就render doc有太多不懂的地方了
法线外扩描边实现与优化 - silence394 - 博客园
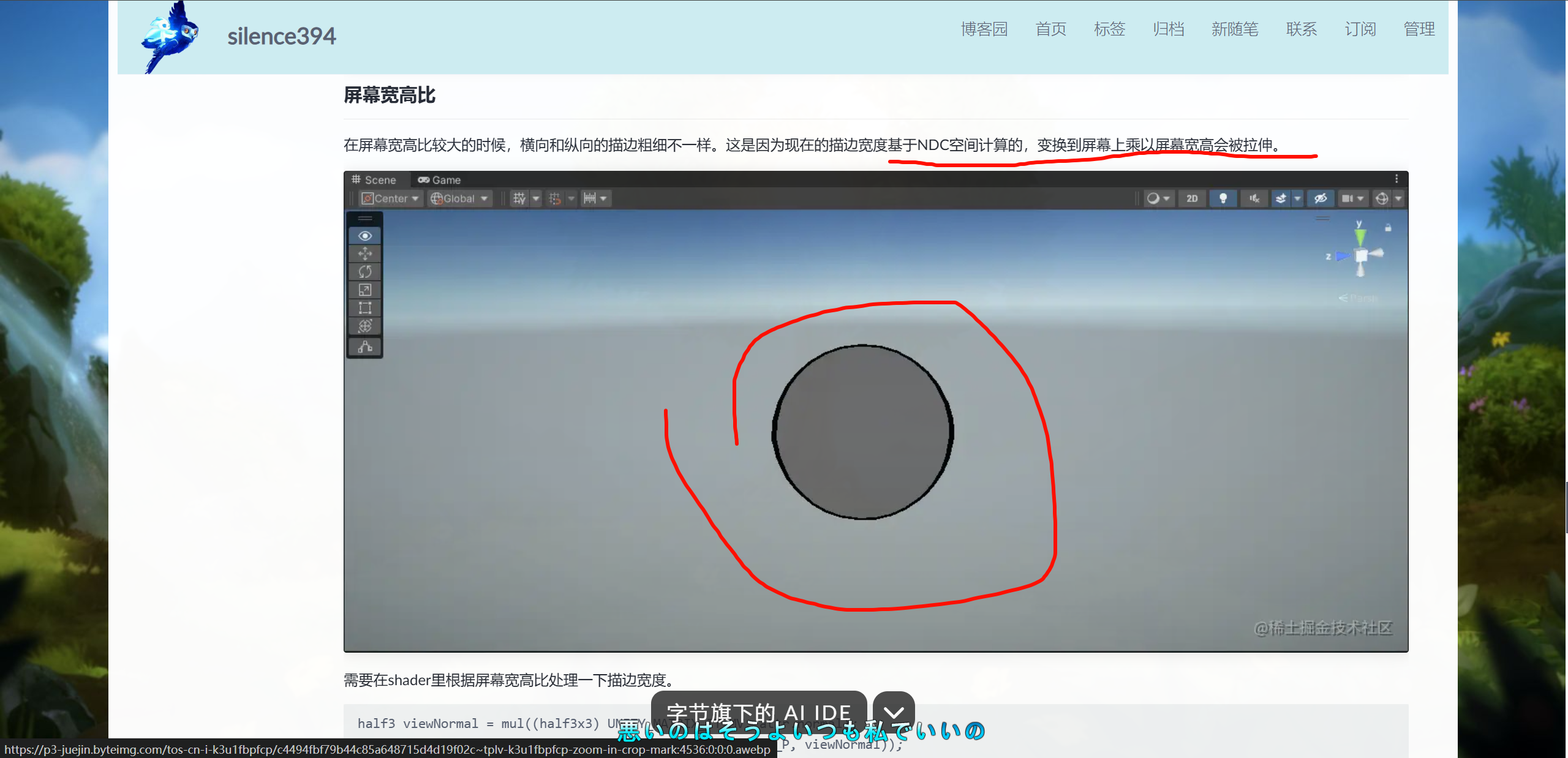
现在的描边是固定宽度的,当摄像机拉的很远时,物体已经很小了,但是描边仍然很粗,这是错误的效果。所以我们会对描边宽度根据距离加个衰减处理。这里采用的是smoothstep,有经验的同学可以用表现更好的衰减方式。
half dis = distance(_WorldSpaceCameraPos, TransformObjectToWorld(attr.position));
float multiper = 1.0 - smoothstep(0, 1, dis / _OutlineMaxDistance);pos.xy += clipNormal.xy * _OutlineWidth * pos.w * multiper;
当然这只是一个最简单的描边实现,想要在项目里实现好的效果,需要根据美术的需求,定制描边的实现,如描边宽度,衰减等。
平滑法线
法线外扩描边有一个严重的效果问题:描边会断裂。以一个正方体的描边为例
这是立方体虽然有6个面,但是有24个顶点,也就是相同空间位置的点,在不同的面上是不同的顶点,自然这个顶点的法线也是不同的。经过法线外扩就会看到同一个空间位置顶点处的描边会出现断裂。
-
先建立 TBN,把 smoothNormal 转到切线空间备用。
-
再把法线从模型空间一路变换到裁剪空间,并修正宽高比。
-
根据相机距离算一个衰减系数 multiper,保证远处描边不会显得过粗。
-
最终在裁剪空间坐标上对顶点 xy 偏移,实现后处理描边的效果。
// ---------- 构建 TBN 矩阵,用来把 smoothNormal 转换到切线空间 ----------// 从 mesh attribute 里取法线
half3 normal = attr.normal;// 从 mesh attribute 里取切线(xyz = 切线方向,w = 切线正负手性)
half4 tangent = attr.tangent;// 通过 normal × tangent 得到副切线(binormal/bitangent),并乘上 w 保证正交一致
half3 binormal = normalize(cross(normal, tangent.xyz) * tangent.w);// 构造 TBN 矩阵(行向量分别是切线、副切线、法线)
half3x3 tbn = half3x3(tangent.xyz, binormal, normal);// 转置以保证矩阵方向符合后续乘法使用习惯
tbn = transpose(tbn);// 用 TBN 把顶点属性中的平滑法线(通常在顶点数据里额外存的)转换到切线空间
half3 smoothNormal = mul(tbn, attr.smoothNormal);attr.smoothNormal 本身不是 Unity 自动提供的变量,而是 需要你在顶点数据里提前准备好的。换句话说:
-
Unity 内置的 vertex attribute(在
appdata_full、Attributes里)一般只有position、normal、tangent、texcoord、color这些。 -
smoothNormal并不属于 Unity 默认的 attribute,你要么是:-
在 建模软件里烘焙/存储 平滑法线到某个 channel(比如额外的 texcoord 或 color)然后在 Shader 里当成
attr.smoothNormal来用。 -
或者在 MeshImporter / 自定义脚本 里给 mesh 顶点数据加上这组额外的
smoothNormal。
-
所以回答你的问题:
-
它 不是应用阶段(Unity 内置变量)自动有的;
-
而是你自己算/自己传进去的(通常在 mesh 预处理或导入阶段计算好,然后存进一个顶点 channel,Shader 里拿来用)。
// ---------- 计算视空间和裁剪空间下的法线 ----------// 将模型空间法线变换到视空间
half3 viewNormal = mul((half3x3) UNITY_MATRIX_IT_MV, attr.normal);// 将视空间法线再变换到裁剪空间,并归一化
half3 clipNormal = normalize(mul((half3x3) UNITY_MATRIX_P, viewNormal));// 处理屏幕宽高比,避免横竖方向缩放不一致导致的失真
float4 screenParam = GetScaledScreenParams();
half aspect = screenParam.y / screenParam.x;
clipNormal.x *= aspect;
是clip下的normal进行aspect的缩放;、
// ---------- 根据摄像机距离对描边宽度做衰减 ----------// 计算顶点到摄像机的距离
half dis = distance(_WorldSpaceCameraPos, TransformObjectToWorld(attr.position));// multiper = 1 - smoothstep(0,1, dis/_OutlineMaxDistance)
// 作用:距离越近 multiper 越接近 1,描边正常;
// 距离接近或超过 _OutlineMaxDistance 时 multiper → 0,描边逐渐消失/变细
float multiper = 1.0 - smoothstep(0, 1, dis / _OutlineMaxDistance);
// ---------- 实际应用描边位移 ----------// pos 为裁剪空间坐标
// 在 xy 平面方向上,沿 clipNormal.xy 外扩
// 外扩宽度由:描边宽度 * 齐次坐标 w * multiper 共同决定
pos.xy += clipNormal.xy * _OutlineWidth * pos.w * multiper;
// 计算顶点到摄像机的距离
half dis = distance(_WorldSpaceCameraPos, TransformObjectToWorld(attr.position));
// multiper = 1 - smoothstep(0,1, dis/_OutlineMaxDistance)
// 作用:距离越近 multiper 越接近 1,描边正常;
// 距离接近或超过 _OutlineMaxDistance 时 multiper → 0,描边逐渐消失/变细
float multiper = 1.0 - smoothstep(0, 1, dis / _OutlineMaxDistance);
做 后处理描边(全屏 pass),你拿到的 SV_POSITION 只是屏幕像素位置,不再有模型的 worldPos。这时要恢复距离,必须依赖 深度图 + 相机矩阵,而且要保证:
-
你采样的是正确的
_CameraDepthTexture(或_CameraDepthNormalsTexture), -
矩阵用
unity_CameraProjection/unity_CameraInvProjection+unity_CameraToWorld对应的那台相机。
否则就会出现“距离在动,但和相机关系不大”的情况。
如果你是做 后处理描边,那这个 Pass 未必是物体自己的渲染,而是屏幕空间的描边 Pass。这种 Pass 里用 _WorldSpaceCameraPos + worldPos 计算的距离并不等价,因为这里的像素并不对应单一的 3D 点,而是通过深度图恢复的。如果代码混用了物体 Pass 和后处理 Pass 的写法,也会出现“不跟相机”的感觉。
对啊,,我去,渲染的是屏幕上的一张图啊,我在想什么啊
那就不可能----不能用vert传入的那个世界坐标啊
你说的对,我是后处理描边,我只能用clip坐标转深度法线图得到距离
做的是 后处理描边,就不能再像物体 Pass 那样直接拿 worldPos 来算距离了,因为在全屏 quad 的 frag 里,每个像素并没有对应的“顶点世界坐标”。
-
_CameraDepthNormalsTexture会在前向渲染里多渲一遍法线 pass,比单独开_CameraDepthTexture要重一点。 -
精度:深度依然是非线性的,远处距离差异很小,衰减可能不明显。
-
平台差异:移动端上有些平台对 depthnormal 支持不好,可能需要手动 fallback。

顶点外扩法线的不好的地方
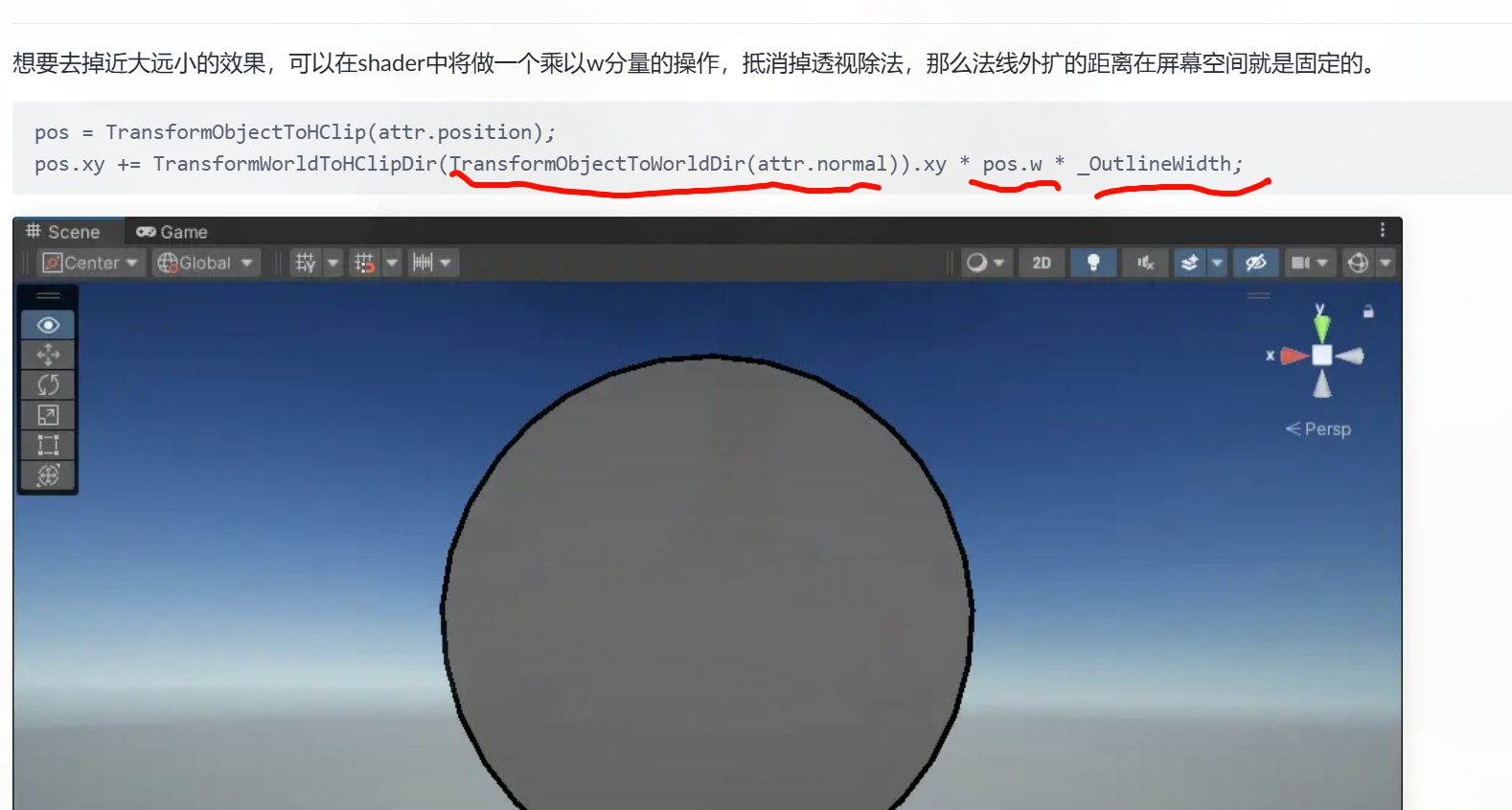
你在 URP 里把纹理声明成 TEXTURE2D 却用 tex2D 调,编译器会报“不匹配”。
-
URP:
TEXTURE2D/TEXTURE2D_X + SAMPLER + SAMPLE_TEXTURE2D/SAMPLE_TEXTURE2D_X -
Built-in:
sampler2D + tex2D
NDC 坐标系是二维的,常用于图形渲染管线中,表示屏幕上的位置,x/y 轴范围都是 [-1, 1]。
告一段落了,,描边后处理
那个全屏的噪声雾效
在片元阶段拿到当前像素的 深度值(通常来自 _CameraDepthTexture)。
雾浓度计算
-
使用线性化的深度作为输入,代入雾的浓度公式:
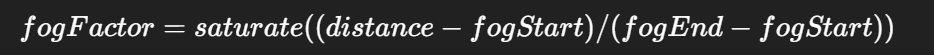
-
这里
fogStart、fogEnd是控制雾出现的起止距离; -
fogFactor就代表了该像素被雾覆盖的比例(0=无遮挡,1=完全雾化)。
-
fogStart、fogEnd是控制雾出现的起止距离; -
fogFactor就代表了该像素被雾覆盖的比例(0=无遮挡,1=完全雾化)。
finalColor = lerp(sceneColor, _FogColor, fogFactor);
这样近处基本保持原色,远处逐渐被雾色覆盖。
高度雾:雾浓度不仅依赖深度,还依赖像素的世界空间高度(y 值),可以表现“雾在地面更浓,往上稀薄”。
指数雾:用指数函数代替线性公式,更接近真实大气散射效果:

应用方式
-
可以作为一个 全屏后处理 pass 来做(最常见,性能开销小);
-
也可以在物体 shader 里直接混合雾色(Unity 内置雾就是这样做的),不过这样不容易实现体积感和高度差。
矩阵 frustumCorners 构建的用途其实就是:把屏幕空间的像素,和相机空间的“射线方向”对应起来,方便在后处理的 fragment shader 里做逐像素的体积雾采样。
ComputeScreenPosToWorld 等价于:
float4 clip = float4(ndc, depth01, 1);
float4 view = mul(UNITY_MATRIX_I_P, clip);
view /= view.w;
float3 worldPos = mul(unity_CameraToWorld, float4(view.xyz, 1)).xyz;
关键是:这里用的 depth01 是 [0,1] 的 非线性深度,而不是线性化后的。

unity_CameraInvProjection 本质上就是用来把 clip → view 的。
-
你传进去的“假 clip”虽然不严格,但数值范围还算接近,经过除 w 后,大多数情况下会还原成一个“近似合理”的视空间坐标。
-
所以表现出来是“能算出世界坐标,能做距离衰减”。
换句话说,你相当于 绕过了 Unity 提供的 LinearEyeDepth / ComputeWorldSpacePosition 公式,硬把 eyeDepth 塞进 clip.z,用 invProjection 硬解出来,结果还能用。
float depth01 = SAMPLE_DEPTH_TEXTURE(_CameraDepthTexture, i.uv);
float3 worldPos = ComputeWorldSpacePosition(i.uv, depth01, UNITY_MATRIX_I_VP);
这里:
-
depth01是 0~1 的非线性深度(z-buffer); -
ComputeWorldSpacePosition会帮你走完整流程:NDC → Clip → View → World,内部自动用_ZBufferParams把深度线性化。
真正的 Clip 空间值
-
定义:clip space =
projectionMatrix * viewSpacePos,结果是(x, y, z, w)。 -
在这里,
x, y, z的范围和w有关,并不是固定 [-1,1],而是 [-w, w]。 -
只有除以
w(即透视除法)之后,才会进入 NDC,这时候才变成 [-1,1]。
所以「真 clip 空间值」当然可以算:你只要拿到视空间坐标,乘投影矩阵就有了。但问题是:
-
在 后处理 full-screen pass 里,你根本没有每个像素的视空间位置。只有屏幕 uv + 深度。
-
你从屏幕 uv 得到的是 NDC.xy([-1,1]),然后用深度重建 z,再通过逆投影算回视空间。
-
这就是为什么在后处理里,大家不直接去恢复“真 clip 值”,而是跳过它,用 NDC+深度就够了。
为什么“不方便算”
-
缺信息:后处理片元一开始只知道 uv(0~1),而 clip 需要完整的
(x, y, z, w)。 -
w 的值取决于相机投影:每个像素的
w要通过相机投影矩阵和深度算出来,而你本来就是要从深度去重建空间位置。
多余一步:通常流程是
uv → NDC → (加深度) → 逆投影 → view space → world space
中间 clip 空间是过渡结果,直接用 NDC 来构造更简洁。
为什么我们直接用 UV→NDC 来重建射线,而不去“真 clip 空间”,不会导致信息丢失?
-
Clip space:在做透视除法之前,坐标范围是 [-w, w]。
-
NDC:clip 除以 w 后,坐标就变成标准化的 [-1,1]。
所以 NDC 是 clip space 的无损归一化形式:
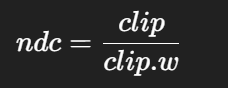
换句话说,NDC 就是把 clip 空间的「方向信息」保留了,只是把幅度(受 w 影响的那部分)折叠进 z、深度里去了。
我们要的是什么信息?
在后处理重建世界坐标时,我们需要两样东西:
-
射线方向 (x,y) —— 即屏幕上这个像素对应的方向。
-
深度 z —— 这个像素到底离相机多远。
-
射线方向:NDC 的 (x,y) 完全能表达,因为透视除法以后,像素对应的方向在 [-1,1] 区间里正好标准化了。
-
深度:clip.w 里携带的“透视缩放”信息已经通过深度缓冲保存了,你再采样深度就能补回这部分数据。
因此,虽然我们不再直接存 clip.xy,但通过 NDC.xy + 深度值,我们依然能完全恢复视空间位置,不丢信
一个公式直观解释
世界坐标重建常用公式:
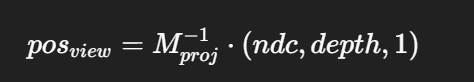
你会发现公式里用的就是 NDC,而不是 clip。原因就在于 —— clip 除以 w 得到的 ndc,再配合深度,一样能还原回去。
我们直接用 NDC 的 xy (从 uv*2-1 得到) 来代替“真 clip.xy”,不会造成信息丢失。因为 clip→NDC 是一一对应的映射,而缺少的那部分 w 信息已经在深度缓冲里补回来了。
为什么在 clip space 下,合法的顶点都会满足

从view space转换到clip space,我认为的是把view space下的所有三维坐标点,通过投影矩阵到摄像机的近平面上,此时的xyzw,下一步是同时除以w,再下一步就是裁剪范围之外的,然后剩下的点数据都是clip space的数据
而其中的xy都会小于w,z在0到1之间,w此时为1
原本xy是的范围是什么,除以w后的范围就会直接变成w的范围,那原本的xy范围都是w的平方?
现在的思路基本对,但有几个关键点混在一起了,我帮你把 View Space → Clip Space → NDC 这条链路重新梳理一遍:
View Space
点在相机空间下的坐标:
Clip Space
应用投影矩阵(透视投影为例):
这里的范围:
-
在裁剪测试之前,要求:
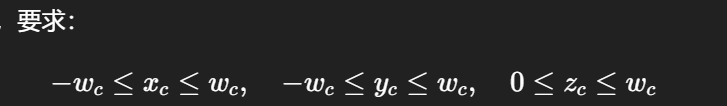
-
所以 x、y 的范围不是固定的 [-1,1],而是随 w_c(也就是深度)缩放的 [-w_c, +w_c]。
-
w_c 本身大约等于视空间 z 分量(和相机看过去的深度成比例)。
透视除法 → NDC
透视除法: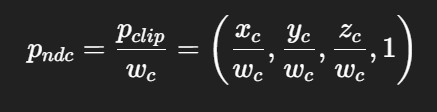
-
范围:
-
x,y ∈ [-1,1]
-
z ∈ [0,1] (D3D/Unity) 或 [-1,1] (OpenGL)
-
w 恒为 1
-
这样得到的才是“规范化设备坐标 (NDC)”。
View space 的范围
在 view space(也叫相机空间):
-
相机在原点
(0,0,0),面向 -Z 轴(Unity/DirectX 约定)。 -
近平面:
z = near,远平面:z = far。 -
在 z = near 的平面上,
-
x 的范围是
[-near*tan(fov/2)*aspect, +near*tan(fov/2)*aspect], -
y 的范围是
[-near*tan(fov/2), +near*tan(fov/2)]。
👉 可以看到,x,y 的范围 随着 z 成正比增长(z 越远,x、y 可取的范围越大)。
一个点在视空间坐标是 (x_v, y_v, z_v)。
-
这里的 x_v, y_v 大小和 z 成正比:离相机越远,投影到屏幕上就越大范围。
-
所以在 view space 里,x/y 并没有固定范围,只要 z 变大,x/y 可以无限大。
-
-
xc=xv⋅Ax_c = x_v \cdot Axc=xv⋅A
-
yc=yv⋅By_c = y_v \cdot Byc=yv⋅B
-
zc=f(zv)z_c = f(z_v)zc=f(zv) (非线性映射)
-
wc=zvw_c = z_vwc=zv
-
所以 在 clip 空间里,x_c 和 y_c 都与 z_v 成比例增长,w_c 也等于 z_v。

一个直观例子
假设 60° FOV,相机近平面 1m:
-
在 view space:当 z_v=1 时,x_v 最大约 ±0.577;当 z_v=10 时,x_v 最大约 ±5.77。
-
变到 clip space:w_c ≈ z_v。
-
所以 |x_c| ≤ w_c。
-
再除以 w_c:x_ndc ∈ [-0.577,0.577] ÷ 0.577 → [-1,1]。
这就保证了所有点在 NDC 下都落在标准立方体 [-1,1]³ 内。

顶点输入阶段开始的数据,一直到view space结束为止,所有的四维值,第四维的w实际上都不用,因为这个w是为了进入clip space是投影矩阵要设置的值? 但我记得有些数据传入的时候是四维的,normal好像就是,Position好像也是 如果不是刻意做想通过修改w影响最终效果,从最基础的物理模拟上来说,在vert函数里返回的clipPos之前,是不应该修改vertex的w值的,想要顶点形变动画的话也只是修改xyz的值
建模还是三d,听着舒服多了
-
顶点位置传进来一般是
float4 position : POSITION,但建模工具里实际存的通常是 3D 坐标 (x, y, z)。 -
GPU 在装配阶段会自动把它扩展成
float4(x, y, z, 1)传进着色器。
fov所以最高也才179,还是这个神经效果,所以z必然大于,是一定没问题的
Object Space / World Space / View Space 的运算中,你的 w 基本上都是 1,没有特别的物理意义,只是数学上的一个扩展位。
View Space 之前
模型变换、观察变换里,都是 4×4 仿射矩阵乘 (x,y,z,1)。
法线、切线这类方向向量,不需要平移,它们传进来时一般是 float3,但在内部计算时会补成 (x,y,z,0),也就是 w=0。这样矩阵乘法的时候就不会引入平移成分。
所以:
-
点坐标:w=1。
-
方向向量(normal、tangent):w=0。
View Space → Clip Space
-
到投影矩阵这里,w 开始“有用”了。
-
透视投影矩阵会设置
clipPos.w = z_view(或某种线性变换)。 -
这样做的原因是为了在做透视除法时,让 x、y 随着 z 拉远而收缩,形成正确的透视缩小效果。
-
在这一步,clipPos 的 (x,y,z,w) 已经不再是简单的“(坐标,1)”,而是混合了 z 的信息。
“在 vert 函数里返回 clipPos 之前,是不应该修改 vertex 的 w 值吧?”
对,常规情况不应该改。
-
如果你在 Object/World/View 阶段就随意改 w,会破坏矩阵计算的一致性,结果不可控。
-
唯一会自动改 w 的就是投影矩阵阶段,它负责设置 w 来制造透视效果。
-
如果你要做顶点动画(变形、抖动、骨骼动画),应该只改 xyz。
当然,特殊效果(比如鱼眼投影、非线性变形)里,有人会故意篡改 w,然后利用透视除法制造特殊的缩放/扭曲。但那是刻意设计的“投影技巧”,不是常规路径。
全局雾为什么要算相机近平面四个角的方向,然后塞到矩阵里传给 shader?
背景:后处理 Shader 里只有屏幕 UV
在 OnRenderImage 的后处理里,传到 fragment shader 的输入只有一个 uv 坐标(范围 0~1)。
-
uv=(0,0)表示屏幕左下角的像素, -
uv=(1,1)表示屏幕右上角的像素。
但光有 uv 你根本不知道这个像素在 3D 世界里对应的是哪条「从相机出发的射线」。而体积雾需要 沿着像素射线 去算雾浓度。
为什么体积雾要引入「射线」这个概念
相机成像本质就是一堆射线
-
每个屏幕像素对应一条 从相机出发,穿过视锥体近平面某个点的射线。
-
像素的颜色 = 这条射线上积累的光信息(真实物理是积分:吸收 + 散射 + 发射)。
-
所以如果要在屏幕后处理阶段模拟「雾在空间里分布」,必须知道像素对应哪条射线。
没有射线,你只知道「屏幕上有个点」,但不知道它在三维空间里穿过什么区域,就没办法去算雾浓度。
雾的本质是“沿射线积分”
体积雾和普通的 screen-space fog(比如 lerp(sceneColor, fogColor, depth))不同。
-
普通雾:只看像素到相机的距离,用一个公式做混色。
-
体积雾:沿射线累加雾介质的贡献(每隔一小段取一次雾密度,累积下去),效果会更有体积感。
因此需要明确「这条射线在世界里怎么走」。
射线矩阵的作用
_FrustumCornersRay 其实就是把「相机 → 近平面四角的方向向量」传给 shader,
这样每个像素的 uv 就可以在这四个方向之间插值,得到对应的射线。
float3 rayDir = normalize(mul(_FrustumCornersRay, float4(uv,1,1)));
for (float t=0; t<maxDistance; t+=step) {
float3 samplePos = cameraPos + rayDir * t;
// 在 samplePos 位置查雾密度,累加
}
这就是所谓「射线行进 (ray marching)」,它跟光线追踪是一个数学思路,只是简化了。
在 vert 阶段通过 判断 uv 属于哪个象限(四块),把对应的 corner ray 塞到插值变量里传下去,fragment shader 就能在光栅化插值过程中拿到“每个像素对应的射线方向”。
你贴的 frag 里有这一句:
float3 worldPos = _WorldSpaceCameraPos + linearDepth * i.interpolatedRay.xyz;
射线方向的大致确认,是为了确认像素的位置,还是因为这个效果就是通过模拟很多射线从摄像机发出然后穿过很多像素,在穿过的过程里对这些像素进行混合?
案是前者。
射线方向的主要用途:确定像素的 3D 位置
在后处理体积雾这个实现里,射线方向的唯一作用就是帮助我们把「屏幕上的一个像素」对应回「世界空间里的一个点」。
-
我们从深度图采到的只是一个值(多远)。
-
要还原出 3D 坐标,必须知道它在相机坐标系里沿着哪条方向线。
-
所以
worldPos = cameraPos + depth * rayDir。
这里的 rayDir 就是“射线方向”,作用类似于 坐标系的查找索引,帮助把屏幕二维像素 + 深度值 → 世界三维位置。
你说的“很多射线从摄像机发出然后穿过很多像素,对这些像素进行混合”那是 光线追踪 / ray marching 思想,在真正的体积渲染里确实会这样做(比如 GPU 里一步步采样体积密度)。
但是这里的实现方式比较简化:
-
它没有在射线上步进采样多个点,而是只取了 深度对应的那个点,用世界高度去算雾浓度。
-
所以严格来说,这是一种 屏幕空间的雾近似,不是完整的体积光学模拟。
Stanford Dragon(斯坦福龙),它确实是计算机图形学和渲染领域里一个非常常见的

和 Stanford Bunny(斯坦福兔子)一样,属于“标准测试模型”。研究人员在做渲染算法、全局光照、体积散射、次表面散射、路径追踪等实验时,常常用这些模型来演示效果。
龙模型比兔子复杂得多,有非常细致的曲面、细长的尾巴和尖锐的特征,适合测试渲染算法的 高频细节表现。
-
经典测试资产:因为它是公开免费的,很多论文、教材和渲染器 demo 都会拿它展示效果。
-
复杂度适中:比 Bunny 更有挑战,但比更复杂的“Lucy Statue”之类模型轻量,渲染起来不会太慢。
-
视觉辨识度高:学图形学的人一看就知道“哦,这是在测试渲染”。
The Stanford 3D Scanning Repository
STL 是一种非常常见的三维模型文件格式,全称是 Stereolithography,也叫 Standard Tessellation Language。最初由 3D Systems 公司在 1980 年代为立体光刻(3D 打印的早期工艺)开发。
STL vs OBJ
-
OBJ:可以包含顶点坐标、法线、UV、材质引用(.mtl),更适合渲染和游戏引擎。
-
STL:只有几何三角面,轻量但单调,主要用于 3D 打印。
举个例子:
-
你要把“斯坦福龙”导入 Unity、Blender 里做渲染 → 选
OBJ。 -
你要把它交给 3D 打印机 → 选
STL。
int index = 0;
if (v.texcoord.x < 0.5 && v.texcoord.y < 0.5) {
index = 0;
} else if (v.texcoord.x > 0.5 && v.texcoord.y < 0.5) {
index = 1;
} else if (v.texcoord.x > 0.5 && v.texcoord.y > 0.5) {
index = 2;
} else {
index = 3;
}
#if UNITY_UV_STARTS_AT_TOP
if (_MainTex_TexelSize.y < 0)
index = 3 - index;
#endif
o.interpolatedRay = _FrustumCornersRay[index];
shader里这一块告诉我一个片元只可以选有一个方向
float linearDepth = LinearEyeDepth(SAMPLE_DEPTH_TEXTURE(_CameraDepthTexture, i.uv_depth));
float3 worldPos = _WorldSpaceCameraPos + linearDepth * i.interpolatedRay.xyz;
frag这里告诉我,一个片元的位置只能从相机出发,沿着这个方向最多 到far顶端,
所以我觉得一整块的像素都是取这种方法计算出来的,所以worldpos非常不精确
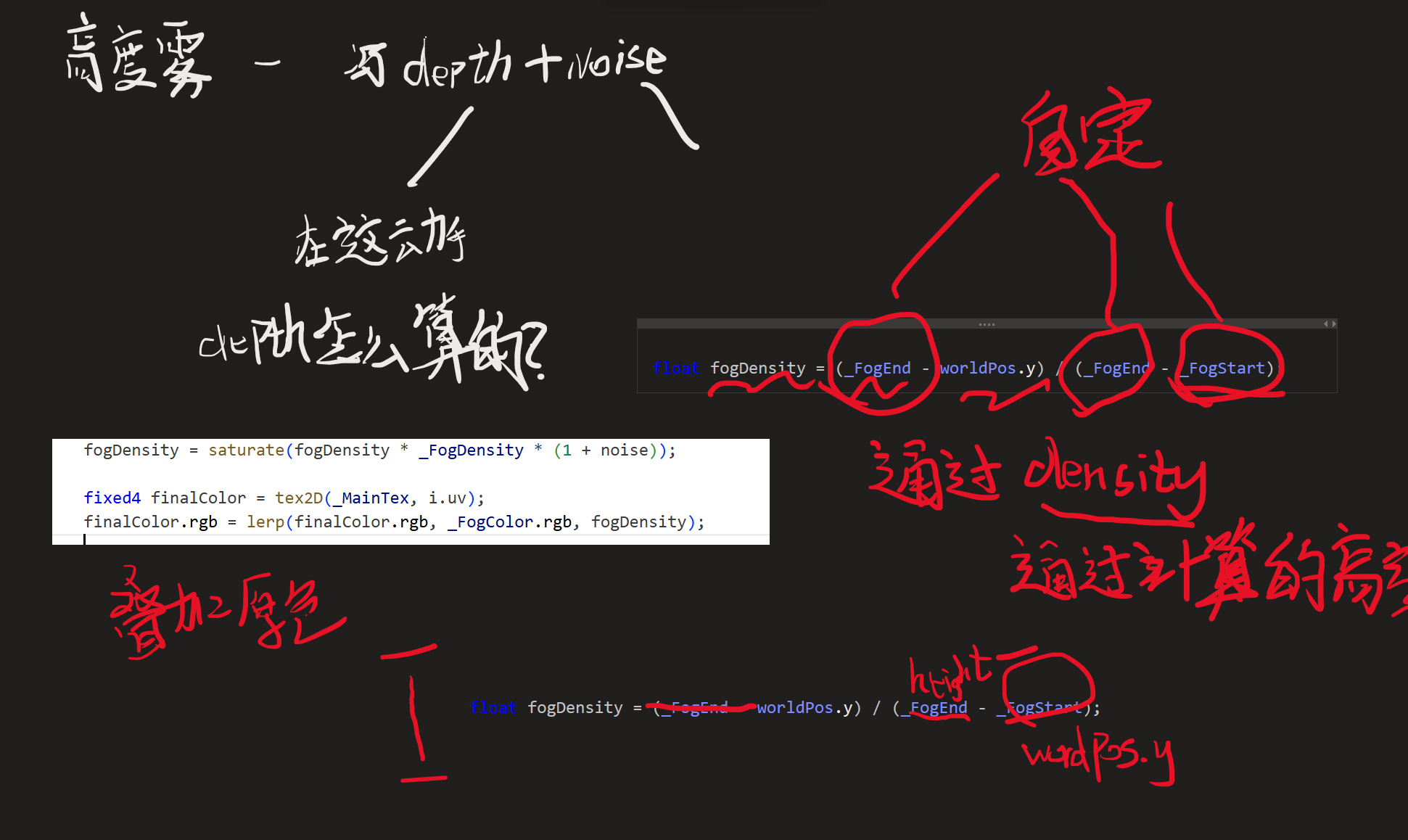
float fogDensity = (_FogEnd - worldPos.y) / (_FogEnd - _FogStart);
fogDensity = saturate(fogDensity * _FogDensity * (1 + noise));
这里之后直接利用了worldPos.y,但是值是不精确的,我决定很不合适
有两个关键误解
在顶点着色器里跑的(vert(appdata_img v) 只会运行在全屏四个顶点上):
int index = 0;
if (v.texcoord.x < 0.5 && v.texcoord.y < 0.5) index = 0; // BL
else if (v.texcoord.x > 0.5 && v.texcoord.y < 0.5) index = 1; // BR
else if (v.texcoord.x > 0.5 && v.texcoord.y > 0.5) index = 2; // TR
else index = 3; // TL
o.interpolatedRay = _FrustumCornersRay[index];
目的:给四个顶点各自绑定“视锥体的四个角射线”。
随后这个 o.interpolatedRay 是一个可插值的 varying,进入光栅化后,GPU 会对它进行二维(透视校正)插值。所以在片元阶段 i.interpolatedRay 不是常量,而是随屏幕位置连续变化的向量(既随 x,又随 y 变化),绝不是“只沿对角线/只依赖某一角”。
快测法:在 frag 里直接输出它看看——

float3 col = normalize(i.interpolatedRay) * 0.5f + 0.5f;
return float4(col, 1.0f);
你会看到全屏平滑渐变(两维变化),而不是四块或一条线。
只有当你显式用了 nointerpolation/flat(HLSL)之类的限定符,varying 才不会插值;你这份代码没有用,默认会插值。
“worldPos 很不精确”?——现在再看则是非常精确了
float linearDepth = LinearEyeDepth(SAMPLE_DEPTH_TEXTURE(_CameraDepthTexture, i.uv_depth));
float3 worldPos = _WorldSpaceCameraPos + linearDepth * i.interpolatedRay;
用的都是插值之后的值
当前这个片元,先通过
直接用 i.uv(NDC 方法)
是的,你说的这种是常见方法:
-
从
i.uv([0,1]) → 映射到 NDC [-1,1]。 -
再配合深度图,反投影回世界空间:
float2 ndc = i.uv * 2 - 1;
float4 clip = float4(ndc, depth, 1);
float4 view = mul(unity_CameraInvProjection, clip);
float3 world = mul(unity_CameraToWorld, view/view.w).xyz;
这样也能得到像素的世界坐标。
👉 所以,你的直觉没错,这条路完全能走通。
四个角向量的方法
书里的实现是另外一种思路:
-
预先算出相机近平面四个角的世界空间方向(TL、TR、BL、BR)。
-
在顶点着色器里绑定给全屏 quad 的四个顶点。
-
GPU 在光栅化时帮你对每个片元做双线性插值,得到射线方向。
-
最后乘以线性深度,就能还原世界坐标。
两种方法的差异与取舍
| 方法 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| NDC + InvProjection | 每个片元手动用 uv→ndc,再用投影逆矩阵求方向/位置 | 精确,完全基于矩阵,概念直接 | 每个片元都要矩阵乘,性能稍低 |
| 四角射线插值 | 四角射线方向 → GPU 插值 → depth × dir | 计算量小,shader 更轻,GPU 原生插值帮忙做了大半 | 有一点近似,理论上比逆投影略损失精度(但几乎忽略不计) |
为什么书里用了四向量方法
主要是性能考虑 + 便于讲解:
-
教材时代的硬件性能有限,一帧几百万像素,逐像素矩阵运算比插值贵。
-
用四角插值,省掉了
mul(invProj, …)的运算,速度更快。 -
思路直观:从相机发射射线,穿过深度,还原世界位置,这和“体积雾”的概念联系紧密。
现在的情况
-
现代 GPU 足够快,直接用 NDC + InvProjection 方法也没什么问题(Unity 自带的 SSAO/屏幕空间阴影等很多效果就是这么做的)。
-
而“四角插值”方法仍然常见,因为它代码短、概念直观,而且省点算力。
但我现在想要实现的一个效果是 ,在我的地形上面生成雾,根据以地形为起点,向上生成雾 就不用像这里面写的这样在脚本里创建实例材质,我自己用shader创建一个实例材质往上面拖就可以了
https://www.adobe.com/learn/substance-3d-designer/web/the-pbr-guide-part-1
fixed4 frag(v2f i) : SV_Target{//return fixed4((normalize(i.interpolatedRay) * 0.5f) + fixed3(0.5, 0.5, 0.5), 1);float linearDepth = LinearEyeDepth(SAMPLE_DEPTH_TEXTURE(_CameraDepthTexture, i.uv_depth));float3 worldPos = _WorldSpaceCameraPos + linearDepth * i.interpolatedRay.xyz;//像素对应的世界坐标float2 speed = _Time.y * float2(_FogXSpeed, _FogYSpeed);float noise = (tex2D(_NoiseTex, i.uv + speed).r - 0.5) * _NoiseAmount;float fogDensity = (_FogEnd - worldPos.y) / (_FogEnd - _FogStart);fogDensity = saturate(fogDensity * _FogDensity * (1 + noise));fixed4 finalColor = tex2D(_MainTex, i.uv);finalColor.rgb = lerp(finalColor.rgb, _FogColor.rgb, fogDensity);return finalColor;}要怎么做,改一个好的效果出来---------
可以得到的只有像素对应的那个世界位置,而想要做到用后处理的方法把事情解决,,只有一个worldPos是不够的
为什么不够,,,,,像素shader可以处理的只是像素,不能跨级干涉其他的像素,而高度这种 想要以worldPos为基准,就必须有额外的控制,告诉上面多少米是需要影响的区域
如果非要做的话,是存图,把信息告诉出去,才能使用
所以可以做的是,把每个像素的世界位置,用一张图pass传出去,
在这个后处理之前就先处理的一次
// Upgrade NOTE: replaced 'mul(UNITY_MATRIX_MVP,*)' with 'UnityObjectToClipPos(*)'Shader "Custom/GlobalHeightFog_Post"
{Properties{_MainTex ("Base (RGB)", 2D) = "white" { }_FogDensity ("Fog Density", Float) = 1.0_FogColor ("Fog Color", Color) = (1, 1, 1, 1)// _FogStart ("Fog Start", Float) = 0.0// _FogEnd ("Fog End", Float) = 1.0_NoiseTex ("Noise Texture", 2D) = "white" { }_FogXSpeed ("Fog Horizontal Speed", Float) = 0.1_FogYSpeed ("Fog Vertical Speed", Float) = 0.1_NoiseAmount ("Noise Amount", Float) = 1_FogHeight ("Fog Height", Float) = 1.0}SubShader{CGINCLUDE#include "UnityCG.cginc"float4x4 _FrustumCornersRay;sampler2D _MainTex;half4 _MainTex_TexelSize;sampler2D _CameraDepthTexture;half _FogDensity;fixed4 _FogColor;// float _FogStart;// float _FogEnd;float _FogHeight;sampler2D _NoiseTex;half _FogXSpeed;half _FogYSpeed;half _NoiseAmount;struct v2f{float4 pos : SV_POSITION;float2 uv : TEXCOORD0;float2 uv_depth : TEXCOORD1;float4 interpolatedRay : TEXCOORD2;};v2f vert(appdata_img v){v2f o;o.pos = UnityObjectToClipPos(v.vertex);o.uv = v.texcoord;o.uv_depth = v.texcoord;#if UNITY_UV_STARTS_AT_TOPif (_MainTex_TexelSize.y < 0)o.uv_depth.y = 1 - o.uv_depth.y;#endifint index = 0;if (v.texcoord.x < 0.5 && v.texcoord.y < 0.5){index = 0;}else if (v.texcoord.x > 0.5 && v.texcoord.y < 0.5){index = 1;}else if (v.texcoord.x > 0.5 && v.texcoord.y > 0.5){index = 2;}else{index = 3;}#if UNITY_UV_STARTS_AT_TOPif (_MainTex_TexelSize.y < 0)index = 3 - index;#endifo.interpolatedRay = _FrustumCornersRay[index];return o;}fixed4 frag(v2f i) : SV_Target{//return fixed4((normalize(i.interpolatedRay) * 0.5f) + fixed3(0.5, 0.5, 0.5), 1);float linearDepth = LinearEyeDepth(SAMPLE_DEPTH_TEXTURE(_CameraDepthTexture, i.uv_depth));float3 worldPos = _WorldSpaceCameraPos + linearDepth * i.interpolatedRay.xyz;//像素对应的世界坐标float2 speed = _Time.y * float2(_FogXSpeed, _FogYSpeed);float noise = (tex2D(_NoiseTex, i.uv + speed).r - 0.5) * _NoiseAmount;float fogDensity = worldPos.y / (_FogHeight + worldPos.y) ;//fogDensity = saturate(fogDensity * _FogDensity * (1 + noise));fogDensity = saturate(fogDensity * _FogDensity);fixed4 finalColor = tex2D(_MainTex, i.uv);finalColor.rgb = lerp(finalColor.rgb, _FogColor.rgb, fogDensity);return finalColor;}ENDCGPass { }Pass{CGPROGRAM#pragma vertex vert#pragma fragment fragENDCG}}FallBack Off
}我要在前面的那个空pass里面和后面的那个pass一样,计算出当前图的每个像素的世界坐标值
我可以把这个值存起来,然后让后面的那个pass再直接访问吗