HBase实战(一)
关于HBase&HBase安装
1.关于HBase
1.1 HBase是什么?
HBase的官网地址:https://hbase.apache.org/
官网上对HBase的介绍非常的简单直接:
Apache HBase™ is the Hadoop database, a distributed, scalable, big data store.
Apache HBase是一个Hadoop上的数据库。一个分布式,可扩展的大数据存储引擎。HBase有个最明显的特征:
- HBase支持非常大的数据集,数十亿行*数百万列。如此庞大的数据量级,足以撑爆我们在J2EE阶段学习过的所有数据存储引擎。
- HBase支持大数据量的随机、实时读写操作。在海量数据中,可以实现毫秒级的数据读写。
- HBase从一开始就深度集成了Hadoop。HBase基于Hadoop进行文件持久化,还继承了Hadoop带来的强大的可扩展性。Hadoop可以基于廉价PC机组建庞大的应用集群。HBase也深度集成了Hadoop的MapReduce计算框架,并且也正在积极整合Spark。这使得HBase能够很轻松的融入到整个大数据生态圈。
- HBase的数据是强一致性的,从CAP理论来看,HBase是属于CP的。这种设计可以让程序员不需要担心脏读、幻读这些事务最终一致性带来的问题。
- 最后最重要的还是HBase的框架性能是足够高效的。HBase的开源社区非常活跃,他的性能经过很多大型商业产品的验证。Facebook的整个消息流转的基础设施就构建于HBase之上。
可以说正是Hadoop+HBase一起提供的强悍无敌的性能,支撑起了大数据的整个技术体系。这就好比必须要先有操作系统,能够通过文件、内存来存储资料,后面开发出来的各种应用程序才有用武之地。
聊到了Hadoop+HBase,就不得不说Google发布的三篇论文。长久以来,各大互联网公司都在注重构建服务,而对于业务数据,很难达到海量这个级别。而对于海量数据的处理,还只是Google这样的搜索引擎巨头在进行深入的研究。
2003年,Google发布Google File System论文,(GFS)这是一个可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用。它运行于廉价的普通硬件上,提供容错功能。从根本上说:文件被分割成很多块,使用冗余的方式储存于商用机器集群上。
紧随其后,2004年,Google公布了MapReduce论文,论文描述了大数据的分布式计算方式,主要思想是将任务分解然后在多台处理能力较弱的计算节点中同时处理,然后将结果合并从而完成大数据处理。
接着到了2006年,Google公布了BigTable论文,BigTable是一种构建于GFS和MapReduce之上的多维稀疏图管理工具。
正是这三篇论文,掀起了开源软件的大数据热潮。人们根据GFS,开发出了HDFS文件存储。MapReduce计算框架,也成了海量数据处理的标准。而HDFS与MapReduce结合在一起,形成了Hadoop。而BigTable更是启发了无数的NoSQL数据库。而HBase正是继承了正统的BigTable思想。所以,Hadoop+HBase是模拟了Google处理海量网页的三大基石实现的,他们也就成了开源大数据处理的基石。
1.2 HBase的数据结构
HBase也可以作为一个数据库使用,但是为了应对海量数据,他存储数据的方式与我们理解的传统关系型数据库有很大的区别。虽然他也有表、列这样的逻辑结构,但是整体上,他是以一种k-v键值对的方式来存储数据的。
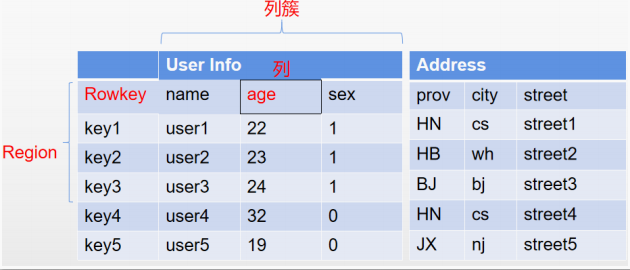
纵向来看,HBase中的每张表由Rowkey和若干个列族或者称为列簇组成。其中Rowkey是每一行数据的唯一标识,在对数据进行管理时,必须自行保证Rowkey的唯一性。接下来HBase依然会以不同的列来管理数据,但是这些列分别归属于不同的列簇。在HBase中,同一张表的数据,只需要保证列簇是相同的,而列簇下的列,可以是不相同的。所以由此可以扩展出非常多的列。在HBase中,对于同一张表,不建议定义过多的列簇,通常不要超过三个。而更多的数据,可以以列的方式来扩展。
从横向来看,HBase中的记录,会划分为一个一个的Region,存储在不同的RegionServer上。并且会在不同的RegionServer之前形成备份,以Region为单位提供了故障后自动恢复的机制。
最后,从整体来看,HBase虽然还是以HDFS作为文件存储,但是他存储的数据不再是简单的文本文件,而是经过HBase优化压缩过的二进制文件,所以他的存储文件通常是不能够直接查看的。
1.3 HBase的基础结构
HBase整体的基础架构如下图:
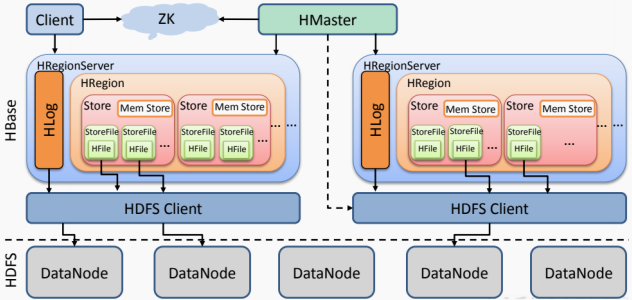
其中:
- client客户端包含了访问HBase的接口,另外也维护了对应的缓存来加速对HBase的访问。
- RegionServer直接对接用户的读写请求,是真正干活的节点。他会将数据以StoreFile的形式存储到不同的HDFS目录中。
- HMaster主要是维护一些集群的元数据信息,同时监控RegionServer的服务状态,并且通过Zookeeper提供集群服务,向客户端暴露集群的服务端信息。
1.4 HBase适用场景
对比Hive,Hive提供了基于SQL的对海量数据进行查询统计的功能,但是Hive不存储数据,所有数据操作都是对HDFS上的文件进行操作,所以他对数据的查询操作能做的优化比较有限。同时Hive也无法直接管理数据,对数据的管理依赖于MapReduce,所以延迟非常高。所以Hive通常只适用于一些OLAP的场景,并且通常是与其他组件结合一起进行使用。
而HBase与Hive的区别就非常明显。HBase基于HDFS来存储数据,但是他存储的数据都是经过自己优化索引后的数据,所以他对数据的存储是非常高效的,比HDFS直接存储文件的性能要高很多,可以作为整个大数据的存储基石。而HBase以类似于Redis的列式存储来管理数据,对数据的增删改都会非常高效,可以达到毫秒级响应。同时,也提供了完善的客户端API,所以他完全可以作为传统意义上的数据库使用,适用于大部分的OLTP的场景。但是他的缺点也比较明显,基于列式存储的数据,天生就不太适合大规模的数据统计,所以在很多OLAP的场景,需要结合其他一些组件如spark、hive等,来提供大规模数据统计的功能。
2.HBase安装
2.1 配置免密登录
准备3台服务器,并修改各服务区的hosts文件:
vim /etc/hosts10.86.97.210 hadoop01
10.86.97.211 hadoop02
10.86.97.212 hadoop03
- 生成密钥对(每台服务器执行):
ssh-keygen -t rsa -b 4096 -P '' -f ~/.ssh/id_rsa
- 合并公钥并分发(在hadoop01上执行):
# 合并公钥:
cd ~/.ssh
cat id_rsa.pub >> authorized_keys # 添加本机公钥
ssh hadoop02 "cat ~/.ssh/id_rsa.pub" >> authorized_keys # 远程获取并追加 hadoop02 公钥
ssh hadoop03 "cat ~/.ssh/id_rsa.pub" >> authorized_keys # 追加 hadoop03 公钥#分发合并后的 authorized_keys 到所有节点:
scp authorized_keys hadoop02:~/.ssh/
scp authorized_keys hadoop03:~/.ssh/
- 设置严格权限(所有节点):
chmod 700 ~/.ssh # 目录权限
chmod 600 ~/.ssh/authorized_keys # 公钥文件权限
- 验证免密登录:
# 在hadoop01上测试:
ssh hadoop02 # 应直接登录,无需密码
ssh hadoop03 # 应直接登录,无需密码2.2 安装zookeeper
zookeeper部署参考,百度网盘:https://pan.baidu.com/s/1qlabJ7m8BDm77GbDuHmbNQ?pwd=41ac

2.3 安装JDK
安装JDK,参考:https://blog.csdn.net/taotao_guiwang/article/details/139624776
2.4 安装hadoop
- 下载 Hadoop 并解压
https://downloads.apache.org/hadoop/common/hadoop-3.4.1/hadoop-3.4.1.tar.gz
放到“/home”路径下,解压:
tar -zxvf hadoop-3.4.1.tar.gz
- 配置 Hadoop 环境变量(在所有机器上执行)
echo "export HADOOP_HOME=/home/hadoop-3.4.1" >> ~/.bashrc
echo "export PATH=\$PATH:\$HADOOP_HOME/bin:\$HADOOP_HOME/sbin" >> ~/.bashrc
source ~/.bashrc
- 创建hadoop文件(在所有机器上执行):
mkdir -p /home/hadoop/hdfs/data
mkdir -p /home/hadoop/hdfs/name
mkdir -p /home/hadoop/hdfs/tmp
-修改 Hadoop 配置文件 core-site.xml(在所有机器上执行):
sudo vim $HADOOP_HOME/etc/hadoop/core-site.xml
core-site.xml 内容示例:
<configuration>
<property><name>hadoop.tmp.dir</name><value>file:/home/hadoop/hdfs/tmp</value>
</property>
<property><name>io.file.buffer.size</name><value>131072</value>
</property>
<property><name>fs.default.name</name><value>hdfs://hadoop01:9000</value>
</property>
<property><name>hadoop.proxyuser.root.hosts</name><value>*</value>
</property>
<property><name>hadoop.proxyuser.root.groups</name><value>*</value>
</property>
</configuration>- 修改 Hadoop 配置文件 hdfs-site.xml(在所有机器上执行):
sudo vim $HADOOP_HOME/etc/hadoop/hdfs-site.xml
<configuration>
<property><name>dfs.replication</name><value>2</value>
</property>
<property><name>dfs.namenode.name.dir</name><value>file:/home/hadoop/hdfs/name</value><final>true</final>
</property>
<property><name>dfs.datanode.data.dir</name><value>file:/home/hadoop/hdfs/data</value><final>true</final>
</property>
<property><name>dfs.namenode.secondary.http-address</name><value>hadoop02:9000</value>
</property>
<property><name>dfs.webhdfs.enabled</name><value>true</value>
</property>
<property><name>dfs.permissions</name><value>false</value>
</property>
</configuration>- 修改 Hadoop 配置文件 yarn-site.xml(在所有机器上执行):
sudo vim $HADOOP_HOME/etc/hadoop/yarn-site.xml
<configuration>
<property><name>yarn.resourcemanager.hostname</name><value>hadoop01</value>
</property>
<property><name>yarn.resourcemanager.address</name><value>hadoop01:8050</value>
</property>
<property><name>yarn.resourcemanager.scheduler.address</name><value>hadoop01:8030</value>
</property>
<property><name>yarn.resourcemanager.webapp.address</name><value>hadoop01:8099</value>
</property>
<property><name>yarn.resourcemanager.resource-tracker.address</name><value>hadoop01:8025</value>
</property>
<property><name>yarn.resourcemanager.admin.address</name><value>hadoop01:8041</value>
</property>
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value>
</property>
<property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
- 修改 Hadoop 配置文件 mapred-site.xml(在所有机器上执行)
sudo vi $HADOOP_HOME/etc/hadoop/mapred-site.xml
<configuration>
<property><name>mapreduce.framework.name</name><value>yarn</value>
</property>
</configuration>- 修改 Hadoop 配置文件 hadoop-env.sh(在所有机器上执行):
sudo vim $HADOOP_HOME/etc/hadoop/hadoop-env.shexport JAVA_HOME=/home/jdk1.8.0_351
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
- vim workers 添加如下(仅在hadoop01机器上执行):
sudo vim $HADOOP_HOME/etc/hadoop/workers
hadoop01机器添加:
hadoop01
hadoop02
hadoop03
- 格式化name文件夹:
hadoop namenode -format
- 启动集群:
start-all.sh
- 查看datanode健康状态:
hdfs dfsadmin -report
- 查看集群状态:
http://10.86.97.210:8099/cluster
2.5 安装Hbase
安装包下载地址:https://dlcdn.apache.org/hbase/2.6.3/
本文使用的2.6.3版本,相关资源在文末,提供网盘下载地址。官网兼容表格:
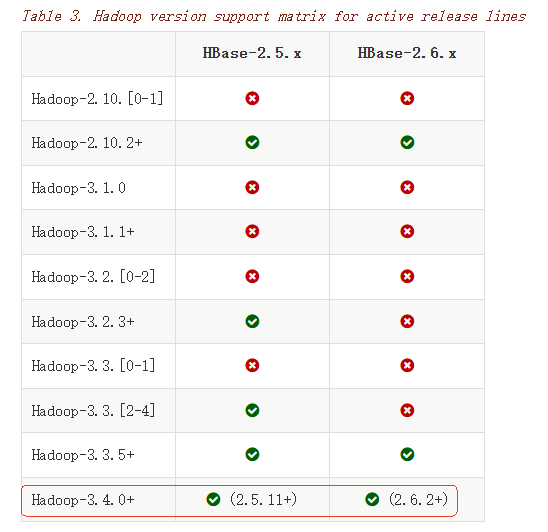
本文使用:hadoop3.4.1,hbase-2.6.3-hadoop3。
需要用到:hbase-2.6.3-hadoop3-bin.tar.gz
上传hbase-2.6.3-hadoop3-bin.tar.gz到各服务器的“/home”目录:
# 解压压缩包
tar -zxvf /home/hbase-2.6.3-hadoop3-bin.tar.gz
- 配置hbase-env.sh
vim /home/hbase-2.6.3-hadoop3/conf/hbase-env.sh
# 配置JAVA_HOME
export JAVA_HOME=/home/jdk1.8.0_351/
#是否使用HBase内置的ZK。默认是true。
export HBASE_MANAGES_ZK=false
- 修改hbase-site.xml,加入如下配置:
sudo vim /home/hbase-2.6.3-hadoop3/conf/hbase-site.xml
<configuration><property><name>hbase.cluster.distributed</name><value>true</value></property><!-- HBase 使用的 ZooKeeper 集群 --><property><name>hbase.zookeeper.quorum</name><value>hadoop01:2181,hadoop01:2182,hadoop01:2183</value></property><!-- HBase 根目录 --><property><name>hbase.rootdir</name><value>hdfs://hadoop01:9000/hbase</value> <!-- 存储在 HDFS 中 --></property><!-- 启用 HBase Master 和 RegionServer--><property><name>hbase.master</name><value>hbase://hadoop01:16000</value></property><property><name>hbase.master.port</name><value>16000</value></property><property><name>hbase.unsafe.stream.capability.enforce</name><value>false</value></property>
</configuration>
- 配置regionservers文件,在文件里列出集群中所有的节点:
vim /home/hbase-2.6.3-hadoop3/conf/regionservers
hadoop01
hadoop02
hadoop03
- 将hbase整体分发到其他服务器:
scp -r /home/hbase-2.6.3-hadoop3/ root@hadoop02:/home
scp -r /home/hbase-2.6.3-hadoop3/ root@hadoop03:/home
- 配置Hbase环境变量。将HBase安装目录配置到环境变量中,并将bin目录配置到PATH环境变量:
echo -e 'export export HBASE_HOME=/home/hbase-2.6.3-hadoop3 \nexport PATH=$PATH:$HBASE_HOME/bin' >> /etc/profile
# 立即生效
source /etc/profile
- 启动HBase:
在hadoop01上执行:
bash /home/hbase-2.6.3-hadoop3/bin/start-hbase.sh
-
访问:
http://10.86.97.210:16010/master-status
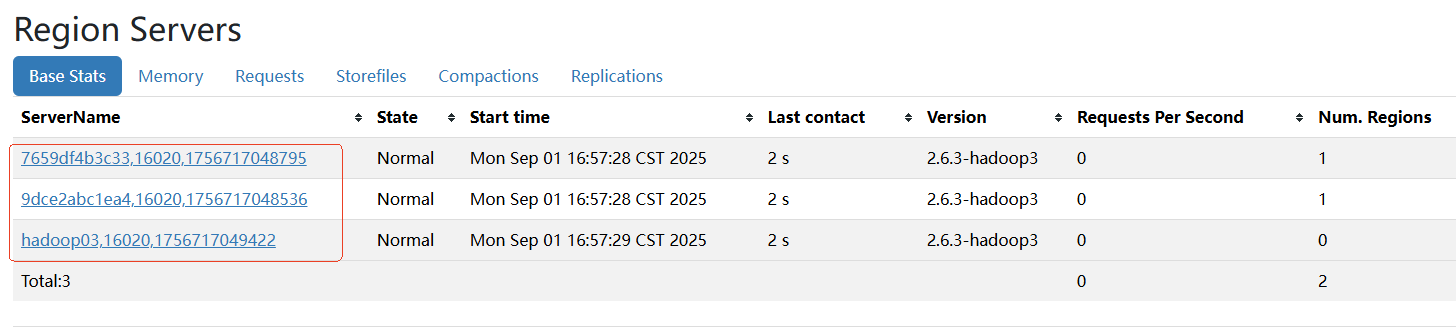
但是ServerName可读性比较差,需要在各服务器上修改hbase-site.xml:
sudo vim /home/hbase-2.6.3-hadoop3/conf/hbase-site.xml -
修改hbase.regionserver.hostname:
在hadoop01上面,添加:
<property><name>hbase.regionserver.hostname</name><value>hadoop01</value> <!-- 存储在 HDFS 中 --></property><property><name>hbase.master.hostname</name><value>hadoop01</value> <!-- 存储在 HDFS 中 --></property>
在hadoop02上面,添加:
<property><name>hbase.regionserver.hostname</name><value>hadoop02</value> <!-- 存储在 HDFS 中 --></property>
在hadoop03上面,添加:
<property><name>hbase.regionserver.hostname</name><value>hadoop03</value> <!-- 存储在 HDFS 中 --></property>
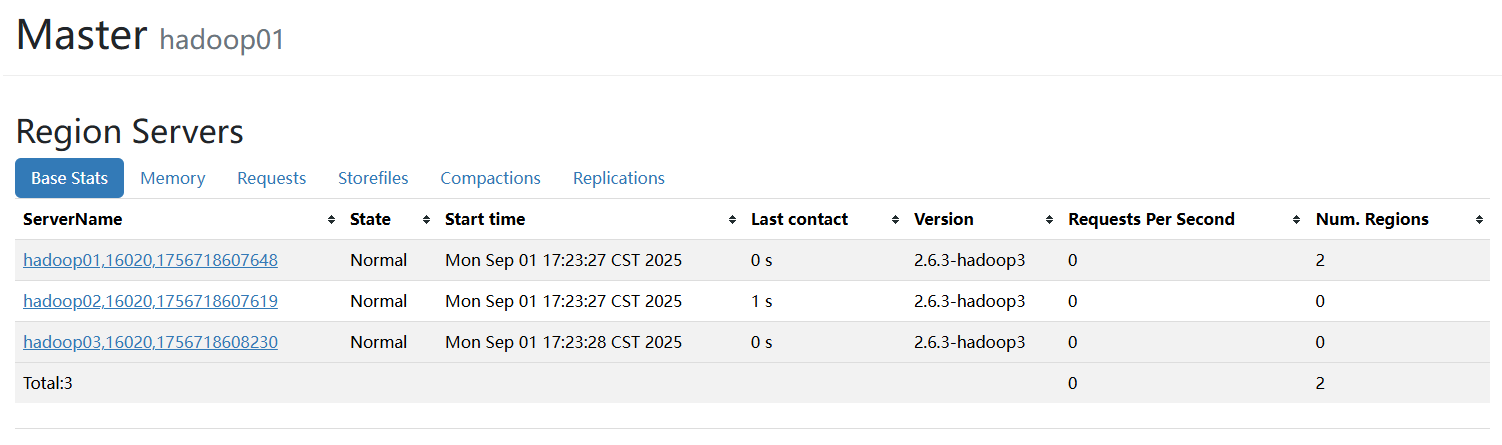
重启服务:
bash /home/hbase-2.6.3-hadoop3/bin/stop-hbase.sh
bash /home/hbase-2.6.3-hadoop3/bin/start-hbase.sh
3.相关资源
百度网盘:https://pan.baidu.com/s/1eaN_8YWIquJKESAmMxhtDg?pwd=vg5n