NUMA架构
NUMA架构介绍
起源
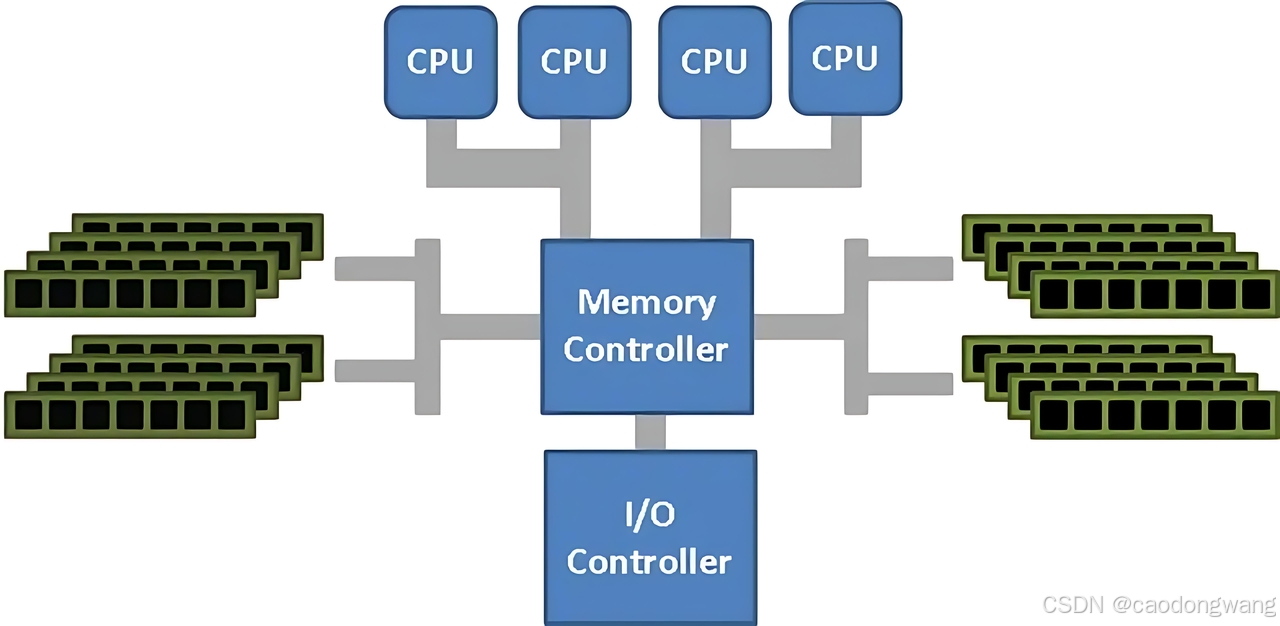
SMP(Symmetric Multi-Processing)即对称多处理架构,在这种系统架构中,所有处理器共享同样的内存访问地址空间和总线结构,因此从管理的角度来看,它们是“对称”的,即无主从之分,工作负载可以均匀地分配到所有可用处理器上,从而显著提高整个系统的数据处理能力,因此SMP也被称为一致存储器访问结构 (UMA:Uniform Memory Access)。
SMP架构示意图如下。
NUMA(Non-Uniform Memory Access)架构诞生于20世纪90年代,最初是为了克服传统对称多处理架构(SMP)的性能瓶颈。SMP架构中,所有处理器共享同一内存池(Uniform Memory Access),通过单一总线访问内存,导致随着处理器核心数量的增加,总线争用和内存访问延迟显著上升。当多核处理器普及后,SMP架构的局限性更加明显,因此NUMA架构被提出,通过将内存划分为多个本地节点,减少跨节点访问的延迟。
NUMA架构示意图如下。
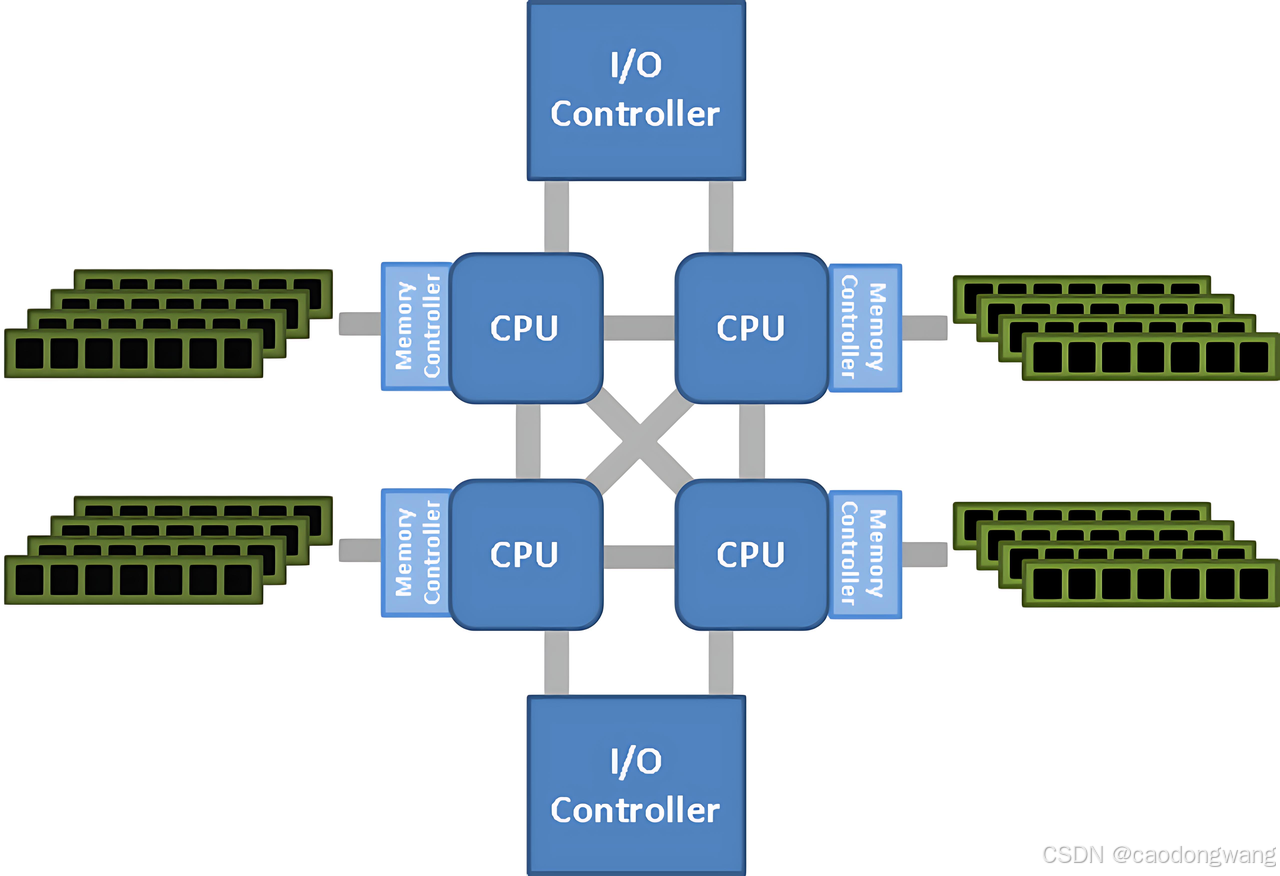
与UMA/SMP架构对比,内存访问最大的不同之处是出现了本地内存和远程内存。
- 每个CPU独立连接到一部分内存,这部分CPU通过内部总线直连的内存称为“本地内存”;
- CPU之间互联模块(如QPI总线)访问不和自己直连的内存称为“远程内存”。
访问本地内存的速度要远快于远程内存,NUMA(非一致性存储器访问)因此而得名。
现状
本小结引用于文章内容。
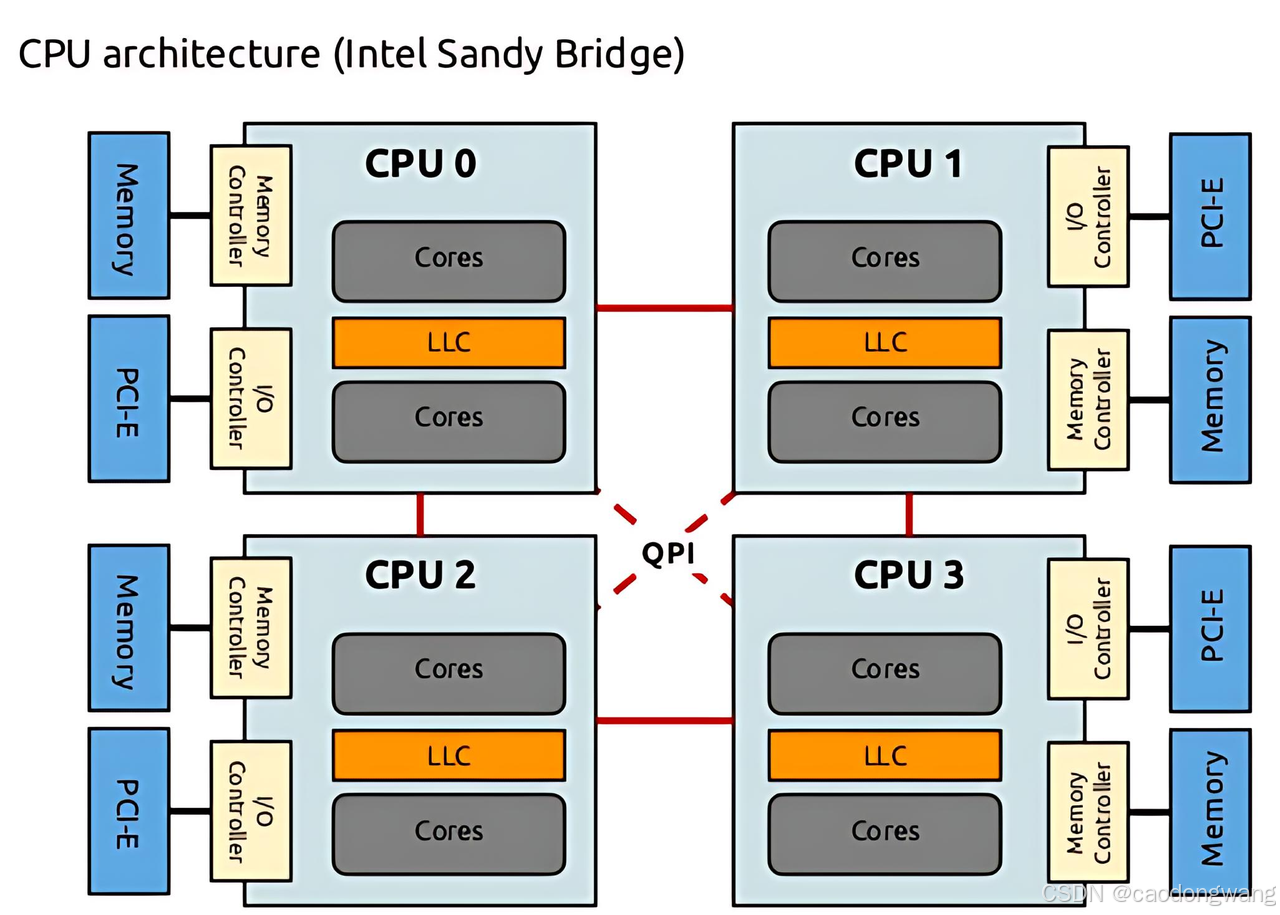
主流X86CPU的NUMA现状
Intel CPU 架构转变其以往使用大面积 die 承载全部 core 的策略,不在执着于更大面积的 die(晶圆利用率低、良品率低),改为“可扩展”的单 CPU 多 die 架构(即单 CPU 多 NUMA node)。

AMD 早在其“推土机”时代就开始尝试模块化设计,但受制于制程、软件兼容性等因素,过分强调更多的核心数目而忽略了单核性能,使其在很长一段时间都未被市场认可,直到 ZEN 时代才真正可以和 Intel 抗衡,ZEN 架构的特点是模块化,用小面积的 die “拼接”出多核心的 CPU,每个 die 至多承载 8 core,这使得 AMD 在一定程度上延续着摩尔定律。而 Intel 则创造了一个 die 承载 28 core 的记录。
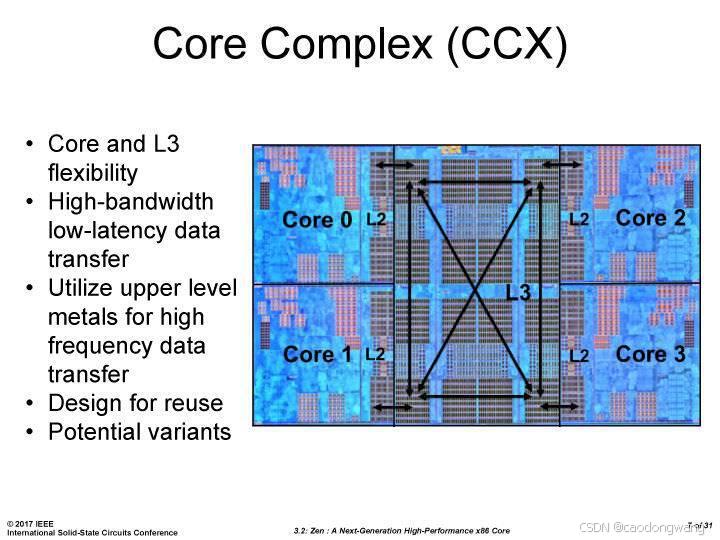


核心机制
1. 物理拓扑结构
- 节点(Node)组成: 每个 NUMA 节点通常包含:
- 一组 CPU 核心(通常对应一个物理 CPU 插槽或 Die)。
- 本地内存控制器(Memory Controller,直接连接本地内存)。
- 高速互联接口(如 Intel QPI、AMD Infinity Fabric、PCIe CCIX 等,用于节点间通信)。
- 内存访问差异:
- 本地内存访问:CPU/PCIe设备 访问同节点内存时,直接通过本地内存控制器,延迟最低。
- 远程内存访问:CPU/PCIe设备 访问跨节点内存时,需通过互联总线路由到目标节点的内存控制器,延迟显著增加。
2. 互联总线技术
- 典型总线类型:
- QPI(QuickPath Interconnect):Intel Xeon 处理器使用,支持节点间点对点高速通信。
- Infinity Fabric:AMD EPYC 处理器使用,支持多芯片封装(MCM)和跨插槽互联。
- UPI(Ultra Path Interconnect):Intel Xeon Scalable 处理器的下一代互联,带宽更高(如 10.4 GT/s)。
- 关键指标: 互联总线的带宽和延迟直接影响 NUMA 架构的扩展性。例如,QPI 带宽为 25.6 GB/s(单向),而 Infinity Fabric 可支持更高的双向带宽。
3. 硬件拓扑描述(ACPI 表)
- SLIT 表(System Locality Information Table): 由主板固件(如 UEFI)通过 ACPI 提供,记录节点间的 “距离”(相对延迟值,其实就是跳数)。
- NUMA 表(NUMA Memory Affinity Table): 描述 CPU 核心、内存区域与 NUMA 节点的映射关系,供操作系统分配资源时参考。
示例:
~/proj/sipu_sw$ numactl --hardware
available: 4 nodes (0-3) # 4个numa节点
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 48 49 50 51 52 53 54 55 56 57 58 59 # numa0 包含的cpu核心
node 0 size: 128402 MB # numa0 上总内存
node 0 free: 49043 MB
node 1 cpus: 12 13 14 15 16 17 18 19 20 21 22 23 60 61 62 63 64 65 66 67 68 69 70 71
node 1 size: 128965 MB
node 1 free: 849 MB
node 2 cpus: 24 25 26 27 28 29 30 31 32 33 34 35 72 73 74 75 76 77 78 79 80 81 82 83
node 2 size: 129017 MB
node 2 free: 25550 MB
node 3 cpus: 36 37 38 39 40 41 42 43 44 45 46 47 84 85 86 87 88 89 90 91 92 93 94 95
node 3 size: 129010 MB
node 3 free: 10116 MB
node distances: # 数值越小表示延迟越低(如节点 0 访问本地内存距离为 10,访问节点 1 内存距离为 11)。
node 0 1 2 30: 10 11 20 201: 11 10 20 202: 20 20 10 113: 20 20 11 10# distances 定义
# distances 一般来源两类:1)CPU手册上说明;2)读取CPU中距离信息和跳数。
# 本地节点 (Local Node): 距离为 10(基准值)。
# 同一 Socket 内的其他节点: 距离可能为 10(如果共享高速缓存或内存控制器路径极短)、11 或稍高(例如 15-20),取决于它们在该 Socket 内部的连接方式。
# 直接相连的相邻 Socket 上的节点: 距离会显著增加(例如 21-32),反映了通过 Socket 间互连链路的延迟。
# 需要经过一个中间 Socket 跳转才能到达的节点: 距离会更高(例如 32-42),因为路径更长,延迟更大。
意义
-
扩展性: 允许构建具有大量 CPU 和内存的大型服务器。
-
性能: 通过减少内存访问延迟,提高整体性能。虽然跨节点访问内存会带来延迟,但本地内存访问速度更快。
-
带宽: 每个节点拥有自己的内存控制器和带宽,避免了 UMA 架构中共享内存带宽的瓶颈。
NUMA架构内存分配策略
NUMA架构和UMA架构内存分配显著差异逻辑如下图所示:
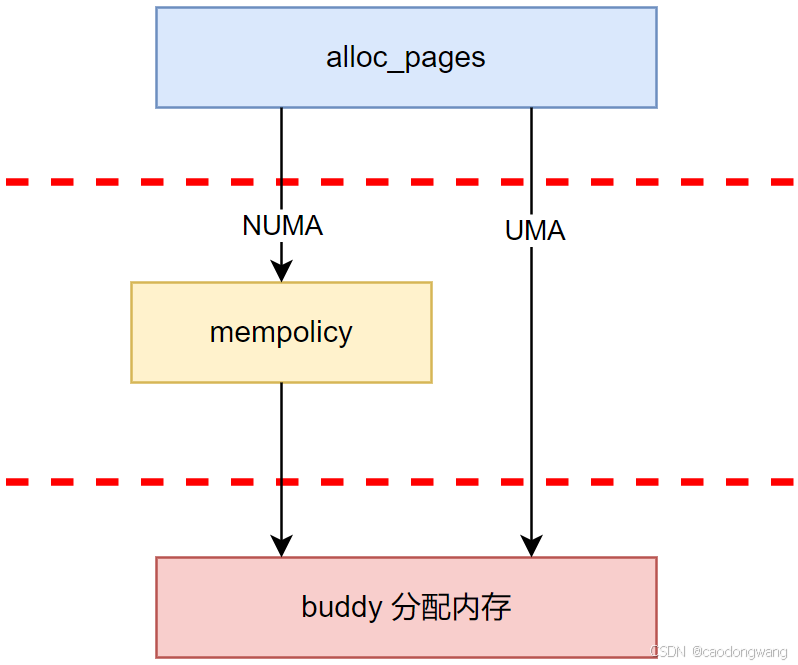
UMA系统中由于只有一个节点,因此不需要经过mempolicy子系统,而是直接从唯一的一个节点中通过buddy分配物理内存。NUMA系统中在分配物理内存之前首先需要经过mempolicy内核子系统根据合适的内存配置策略决定分配内存所处节点,之后buddy根据分配的节点分配内存。
故本小结主要关心的就是mempolicy子系统如何影响进程内存分配的。
linux内核内存管理
代码参考linux 6.12.32
node内存管理结构
typedef struct pglist_data {/** node_zones contains just the zones for THIS node. Not all of the* zones may be populated, but it is the full list. It is referenced by* this node's node_zonelists as well as other node's node_zonelists.*/struct zone node_zones[MAX_NR_ZONES];/** node_zonelists contains references to all zones in all nodes.* Generally the first zones will be references to this node's* node_zones.*/struct zonelist node_zonelists[MAX_ZONELISTS];......int node_id; ......
};
其中node_zones用来存放各个内存区域管理结构,如ZONE_NORMAL、ZONE_DMA32、ZONE_DMA等;node_zonelists[0]用来存放本node和其他node内存区域管理结构,按distance排序;node_zonelists[1]用来存放本node 内存区域管理结构。
node_zones初始化
start_kernelsetup_archinitmem_initx86_numa_initnuma_initx86_acpi_numa_initacpi_numa_init//解析acpi表,将所有node上内存添加到全局管理结构acpi_parse_cfmwsx86_init.paging.pagetable_init()native_pagetable_initpaging_initzone_sizes_initfree_area_init {for_each_node(nid) {pg_data_t *pgdat;pgdat = NODE_DATA(nid);free_area_init_node(nid);}}static int __init acpi_parse_cfmws(union acpi_subtable_headers *header,void *arg, const unsigned long table_end)
{......cfmws = (struct acpi_cedt_cfmws *)header;start = cfmws->base_hpa;end = cfmws->base_hpa + cfmws->window_size;/** The SRAT may have already described NUMA details for all,* or a portion of, this CFMWS HPA range. Extend the memblks* found for any portion of the window to cover the entire* window.*/if (!numa_fill_memblks(start, end))//检查内存范围是否有重叠return 0;/* No SRAT description. Create a new node. */node = acpi_map_pxm_to_node(*fake_pxm); // 获取node id// 将内存范围添加到内存全局管理结构,附带上 node idif (numa_add_memblk(node, start, end) < 0) {/* CXL driver must handle the NUMA_NO_NODE case */pr_warn("ACPI NUMA: Failed to add memblk for CFMWS node %d [mem %#llx-%#llx]\n",node, start, end);}node_set(node, numa_nodes_parsed);......
}static void __init free_area_init_node(int nid)
{......// 从内存全局管理结构获取这个node节点 start_pfn 和 end_pfnget_pfn_range_for_nid(nid, &start_pfn, &end_pfn);pgdat->node_id = nid;pgdat->node_start_pfn = start_pfn;// 记录起始 pfnpgdat->per_cpu_nodestats = NULL;// 计算有效的 page 个数calculate_node_totalpages(pgdat, start_pfn, end_pfn);free_area_init_core(pgdat);
}static void __init free_area_init_core(struct pglist_data *pgdat)
{enum zone_type j;int nid = pgdat->node_id;pgdat_init_internals(pgdat); // 初始化工作队列、queue等pgdat->per_cpu_nodestats = &boot_nodestats;for (j = 0; j < MAX_NR_ZONES; j++) {struct zone *zone = pgdat->node_zones + j;unsigned long size = zone->spanned_pages;/** Initialize zone->managed_pages as 0 , it will be reset* when memblock allocator frees pages into buddy system.*/zone_init_internals(zone, j, nid, zone->present_pages);//设置zone名字、id等// 初始化zone内存相关变量,主要填充 zone->zone_start_pfninit_currently_empty_zone(zone, zone->zone_start_pfn, size);}
}
上面初始化总结来说就是:解析acpi表,获取每个node内存信息添加到全局内存管理结构中,然后根据这些内存信息初始化每个 node 的 pglist_data 结构中 node_zones 成员,指向对应的内存。
可以在linux系统下看看zone相关信息。
wdrnm@sio-soft-node010:~$ cat /proc/zoneinfo
Node 0, zone DMApages free 2817start_pfn: 1
Node 0, zone DMA32pages free 360964start_pfn: 4096
Node 0, zone Normalpages free 15935984start_pfn: 1048576
Node 1, zone Normalpages free 5194465start_pfn: 34078720
Node 2, zone Normalpages free 12183206start_pfn: 67633152
Node 3, zone Normalpages free 6122715start_pfn: 101187584
node_zonelists初始化
start_kernelmm_core_initbuild_all_zonelistsbuild_all_zonelists_init__build_all_zonelistsstatic void __build_all_zonelists(void *data)
{......for_each_node(nid) {pg_data_t *pgdat = NODE_DATA(nid);build_zonelists(pgdat);}......
}static void build_zonelists(pg_data_t *pgdat)
{......memset(node_order, 0, sizeof(node_order));// find_next_best_node 函数通过distance距离由近到远返回node idwhile ((node = find_next_best_node(local_node, &used_mask)) >= 0) {if (node_distance(local_node, node) !=node_distance(local_node, prev_node))node_load[node] += 1;// 对节点添加负载node_order[nr_nodes++] = node; // 存放节点编号,注意,0号是本身prev_node = node;}// 根据节点编号填充 zonelistsbuild_zonelists_in_node_order(pgdat, node_order, nr_nodes);build_thisnode_zonelists(pgdat);
}static void build_zonelists_in_node_order(pg_data_t *pgdat, int *node_order,unsigned nr_nodes)
{......// ZONELIST_FALLBACK == 0zonerefs = pgdat->node_zonelists[ZONELIST_FALLBACK]._zonerefs;for (i = 0; i < nr_nodes; i++) {int nr_zones;// 根据node id拿到 pg_data_t 结构pg_data_t *node = NODE_DATA(node_order[i]);// 将该 node 的 node_zones 中区域内存管理结构填充到 zonerefs 中nr_zones = build_zonerefs_node(node, zonerefs);zonerefs += nr_zones;}zonerefs->zone = NULL;zonerefs->zone_idx = 0;
}static void build_thisnode_zonelists(pg_data_t *pgdat)
{struct zoneref *zonerefs;int nr_zones;// ZONELIST_NOFALLBACK == 1zonerefs = pgdat->node_zonelists[ZONELIST_NOFALLBACK]._zonerefs;nr_zones = build_zonerefs_node(pgdat, zonerefs);zonerefs += nr_zones;zonerefs->zone = NULL;zonerefs->zone_idx = 0;
}
遍历每个node的pg_data_t结构,初始化node_zonelists[0]和node_zonelists[1]。node_zonelists[0]指向node自身ZONE_NORMAL、ZONE_DMA32、ZONE_DMA,接着按distance 由近到远指向其他node的ZONE_NORMAL等结构。node_zonelists[1]只指向node自身ZONE_NORMAL、ZONE_DMA32、ZONE_DMA。
排序使用的distance 怎么来的?
start_kernelsetup_archinitmem_initx86_numa_initx86_acpi_numa_initacpi_numa_initacpi_parse_slitnuma_set_distancestatic int __init acpi_parse_slit(struct acpi_table_header *table)
{......for (i = 0; i < slit->locality_count; i++) {const int from_node = pxm_to_node(i);// 源node idif (from_node == NUMA_NO_NODE) // 跳过无效node idcontinue;for (j = 0; j < slit->locality_count; j++) {const int to_node = pxm_to_node(j);// 目标node idif (to_node == NUMA_NO_NODE) // 跳过无效node idcontinue;numa_set_distance(from_node, to_node,slit->entry[slit->locality_count * i + j]);}}......
}void __init numa_set_distance(int from, int to, int distance)
{......// 根据源node id和目标node id,填充 distance 信息numa_distance[from * numa_distance_cnt + to] = distance;
}
其实就是根据BIOS上报的distance 信息,依次填充到distance 全局数组中,后续每个node根据自己的node id来查找和其他node之间 distance ,从而排序每个node自己的node_zonelists链表。
初始化后示意图
假设x86架构下有两个node,第一个node的内存对应整个系统内存前半段,第二个node的内存对应整个系统内存后半段,大致示意图如下。
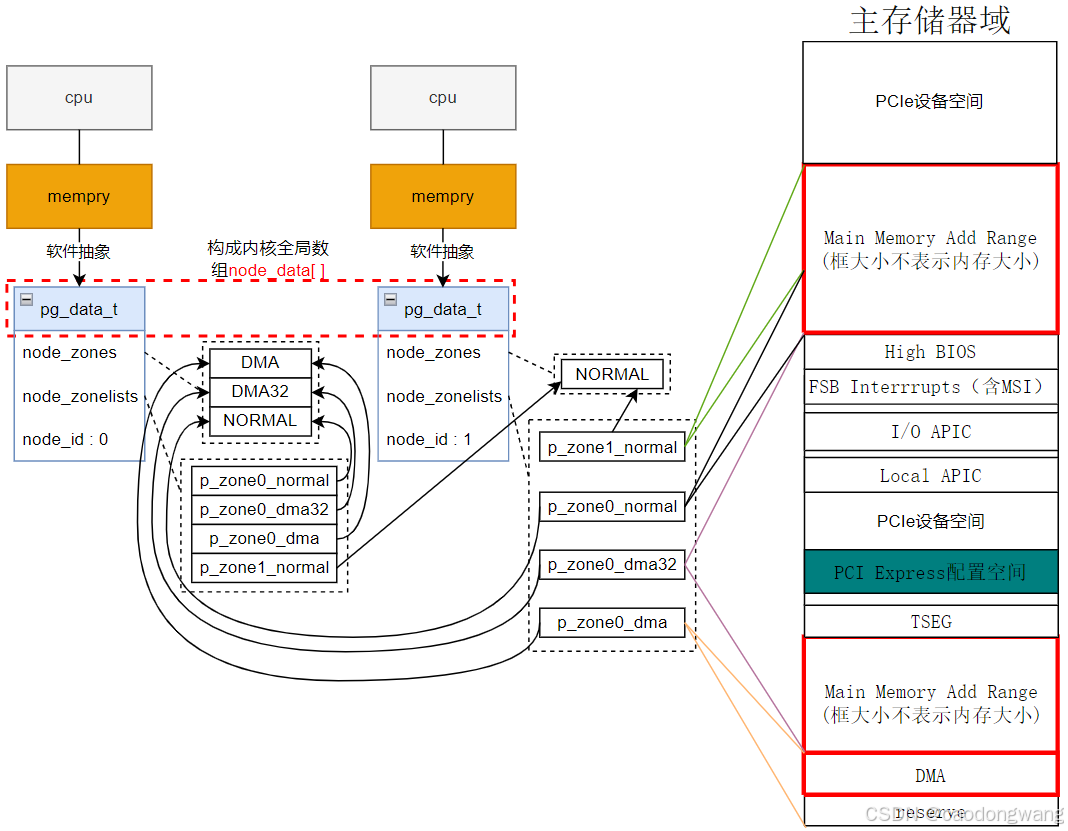
其中p_*表示指针;每个zone管理一段内存区间,比如zone0_dma表示node0的dma内存区间段(16MB);上面node_zonelist数组只画出了node_zonelist[0]指针结构,而node_zonelist[1]中只指向本node zone管理结构 ,顺序与node_zonelist[0]一致。
linux内核内存分配
linux内核内存分配策略
-
Preferred Node**(
MPOL_PREFERRED)策略:**内存优先从指定的NUMA节点分配(如numactl --preferred=0 <command>),但允许从距离最近节点分配。 -
**Interleave(
MPOL_INTERLEAVE)策略:**内存轮询式分配到多个NUMA节点(如numactl --interleave=0,1 <command>),平衡内存负载。 -
**Bind(
MPOL_BIND)策略:**内存仅从指定的NUMA节点组分配(如numactl --membind=0,1 <command>),禁止远程节点分配。 -
**Local(
MPOL_LOCAL)默认策略:**优先在当前 CPU 所在的NUMA节点上分配(如numactl --localalloc <command>),不足时使用其他节点。
linux内核内存分配实现
alloc_pagesalloc_pages_noprofstruct page *alloc_pages_noprof(gfp_t gfp, unsigned int order)
{struct mempolicy *pol = &default_policy;// 选择默认分配策略,即MPOL_LOCAL/** No reference counting needed for current->mempolicy* nor system default_policy*/if (!in_interrupt() && !(gfp & __GFP_THISNODE))pol = get_task_policy(current);// 如果进程自己有分配策略,则使用进程的return alloc_pages_mpol_noprof(gfp, order, pol, NO_INTERLEAVE_INDEX,numa_node_id());
}struct page *alloc_pages_mpol_noprof(gfp_t gfp, unsigned int order,struct mempolicy *pol, pgoff_t ilx, int nid)
{......// 根据内存分配策略,拿到node id以及nodemasknodemask = policy_nodemask(gfp, pol, ilx, &nid);......page = __alloc_pages_noprof(gfp, order, nid, nodemask);......
}static nodemask_t *policy_nodemask(gfp_t gfp, struct mempolicy *pol,pgoff_t ilx, int *nid)
{nodemask_t *nodemask = NULL;switch (pol->mode) {case MPOL_PREFERRED:/* Override input node id */*nid = first_node(pol->nodes);// 指定nodebreak;case MPOL_PREFERRED_MANY:// 指定node集合nodemask = &pol->nodes;if (pol->home_node != NUMA_NO_NODE)*nid = pol->home_node;break;case MPOL_BIND:// 绑定特定node/* Restrict to nodemask (but not on lower zones) */if (apply_policy_zone(pol, gfp_zone(gfp)) &&cpuset_nodemask_valid_mems_allowed(&pol->nodes))nodemask = &pol->nodes;if (pol->home_node != NUMA_NO_NODE)*nid = pol->home_node;break;case MPOL_INTERLEAVE:// 交错分配/* Override input node id */*nid = (ilx == NO_INTERLEAVE_INDEX) ?interleave_nodes(pol) : interleave_nid(pol, ilx);break;......}return nodemask;
}struct page *__alloc_pages_noprof(gfp_t gfp, unsigned int order,int preferred_nid, nodemask_t *nodemask)
{......// 根据 node id 和 nodemask 构建 ac 结构,if (!prepare_alloc_pages(gfp, order, preferred_nid, nodemask, &ac,&alloc_gfp, &alloc_flags))return NULL;......// 根据ac指定 zonelist 依次尝试分配内存/* First allocation attempt */page = get_page_from_freelist(alloc_gfp, order, alloc_flags, &ac);if (likely(page))goto out;......
}static inline bool prepare_alloc_pages(gfp_t gfp_mask, unsigned int order,int preferred_nid, nodemask_t *nodemask,struct alloc_context *ac, gfp_t *alloc_gfp,unsigned int *alloc_flags)
{// 将 gfp_mask 中的区域限制转换为 zone_type,指导选择物理内存区域ac->highest_zoneidx = gfp_zone(gfp_mask);// 一般返回 nid->node_zonelists[0]ac->zonelist = node_zonelist(preferred_nid, gfp_mask);ac->nodemask = nodemask; // 允许分配内存的 node 掩码ac->migratetype = gfp_migratetype(gfp_mask);....../** The preferred zone is used for statistics but crucially it is* also used as the starting point for the zonelist iterator. It* may get reset for allocations that ignore memory policies.*/// 指向 nid->node_zonelists[0] 第一个允许的 zone 区域// 注意,是node_zonelists[0]指针数组某个位置ac->preferred_zoneref = first_zones_zonelist(ac->zonelist,ac->highest_zoneidx, ac->nodemask);return true;
}static struct page *
get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags,const struct alloc_context *ac)
{......z = ac->preferred_zoneref;// 从node_zonelists[0]指针数组中某个位置开始// 依次尝试从各个 zone 区域分配内存for_next_zone_zonelist_nodemask(zone, z, ac->highest_zoneidx,ac->nodemask) {......
try_this_zone:// 尝试从 zone 区域分配内存page = rmqueue(zonelist_zone(ac->preferred_zoneref), zone, order,gfp_mask, alloc_flags, ac->migratetype);......}......
}
简单来说,就是根据进程内存分配策略拿到node id和nodemask,然后用着两个信息加分配标志构造zonelist结构,最后从zonelist中依次尝试分配内存。
内存分配流程示意图
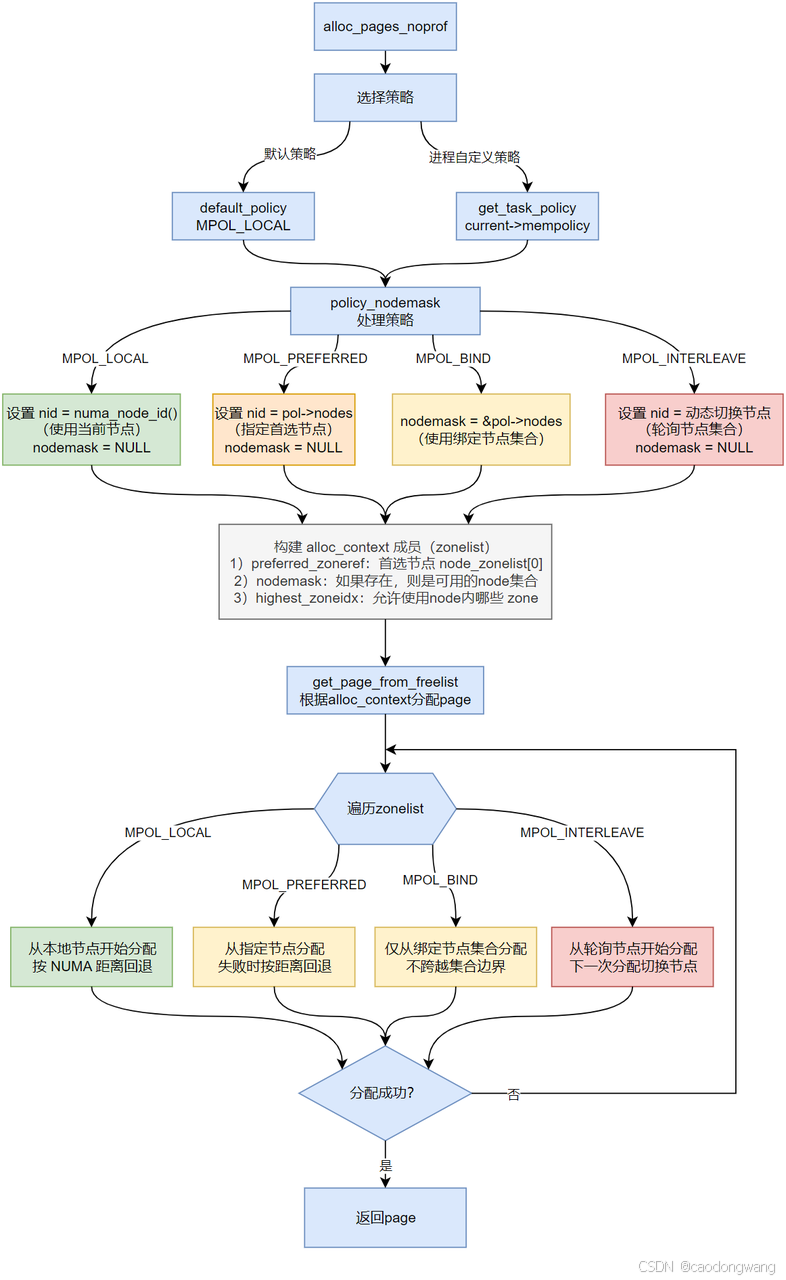
举例解释一下上面流程,假设某NUMA架构有4个node,距离信息如下:
node distances:
node 0 1 2 30: 10 11 20 201: 11 10 20 202: 20 20 10 113: 20 20 11 10
假设进程都运行在node0上且未调度:
-
Local(
MPOL_LOCAL)默认策略:优先使用0节点,接着1节点。之后2或3。 -
Preferred Node(
MPOL_PREFERRED)策略:preferred指定为2,优先使用2,接着3,之后才0或1 。 -
Bind(
MPOL_BIND)策略:bind指定为2,则只会使用2;bind指定为1和3,则只会使用1和3。 -
Interleave(
MPOL_INTERLEAVE)策略:interleave指定all,则0、1、2、3交替使用;interleave指定1和3,则1和3交替使用。
用户指定分配策略
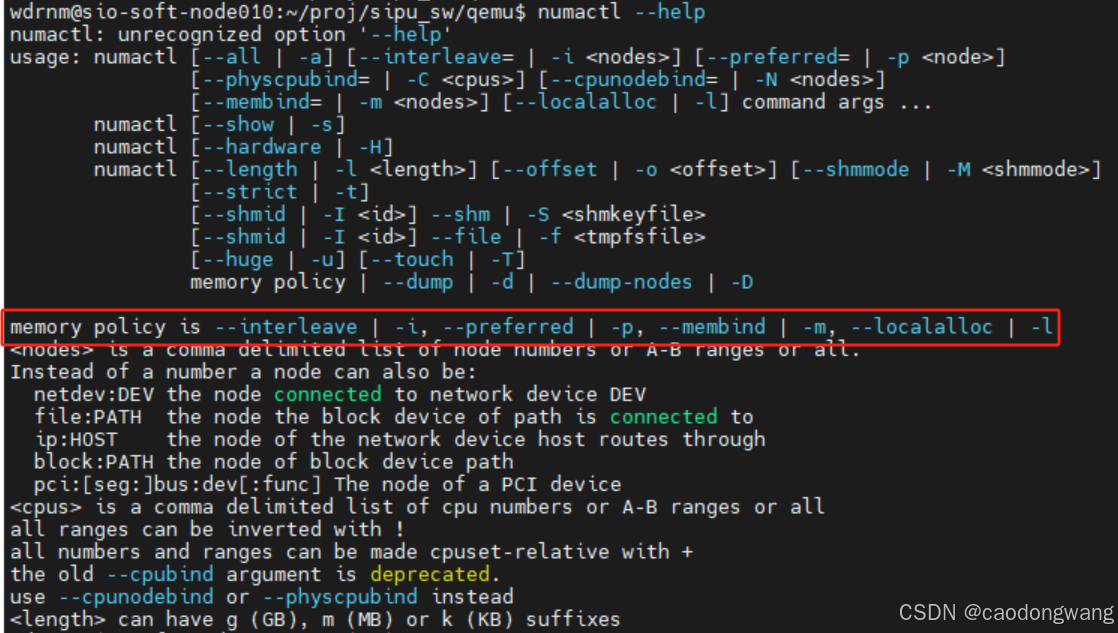
用户态程序可以通过numactl工具来设置程序内存分配策略,或者用户程序中直接调用内存策略设置接口,两者本质都是通过libnuma.so库完成系统调用。
看看numactl工具支持哪些内存策略设置,如下图所示。
再来简单看看numactl源码:
int main(int ac, char **av)
{......get_short_opts(opts,shortopts);while ((c = getopt_long(ac, av, shortopts, opts, NULL)) != -1) {switch (c) {......case 'i': /* --interleave */if (parse_all)mask = numactl_parse_nodestring(optarg, ALL);elsemask = numactl_parse_nodestring(optarg, CPUSET);......numa_set_interleave_mask(mask);......break;case 'm': /* --membind */if (parse_all)mask = numactl_parse_nodestring(optarg, ALL);elsemask = numactl_parse_nodestring(optarg, CPUSET);......numa_set_membind(mask);......break;case 'p': /* --preferred */if (parse_all)mask = numactl_parse_nodestring(optarg, ALL);elsemask = numactl_parse_nodestring(optarg, CPUSET);......numa_set_preferred(find_first(mask));......break;case 'l': /* --local */......numa_set_localalloc();......break;......}}long WEAK set_mempolicy(int mode, const unsigned long *nmask,unsigned long maxnode)
{long i;i = syscall(__NR_set_mempolicy,mode,nmask,maxnode);return i;
}static void setpol(int policy, struct bitmask *bmp)
{if (set_mempolicy(policy, bmp->maskp, bmp->size + 1) < 0)numa_error("set_mempolicy");
}SYMVER("numa_set_interleave_mask_v1", "numa_set_interleave_mask@libnuma_1.1")
void numa_set_interleave_mask_v1(nodemask_t *mask)
{struct bitmask *bmp;int nnodes = numa_max_possible_node_v1_int()+1;bmp = numa_bitmask_alloc(nnodes);copy_nodemask_to_bitmask(mask, bmp);if (numa_bitmask_equal(bmp, numa_no_nodes_ptr))setpol(MPOL_DEFAULT, bmp);elsesetpol(MPOL_INTERLEAVE, bmp);numa_bitmask_free(bmp);
}SYMVER("numa_set_membind_v1", "numa_set_membind@libnuma_1.1")
void numa_set_membind_v1(const nodemask_t *mask)
{struct bitmask bitmask;bitmask.maskp = (unsigned long *)mask;bitmask.size = sizeof(nodemask_t);setpol(MPOL_BIND, &bitmask);
}void numa_set_preferred(int node)
{struct bitmask *bmp = numa_allocate_nodemask();if (!bmp)return;numa_bitmask_setbit(bmp, node);setpol(MPOL_PREFERRED, bmp);numa_bitmask_free(bmp);
}void numa_set_localalloc(void)
{setpol(MPOL_LOCAL, numa_no_nodes_ptr);
}
其实4中内存分配策略设置,都是通过 set_mempolicy 接口,简单调用示意图。
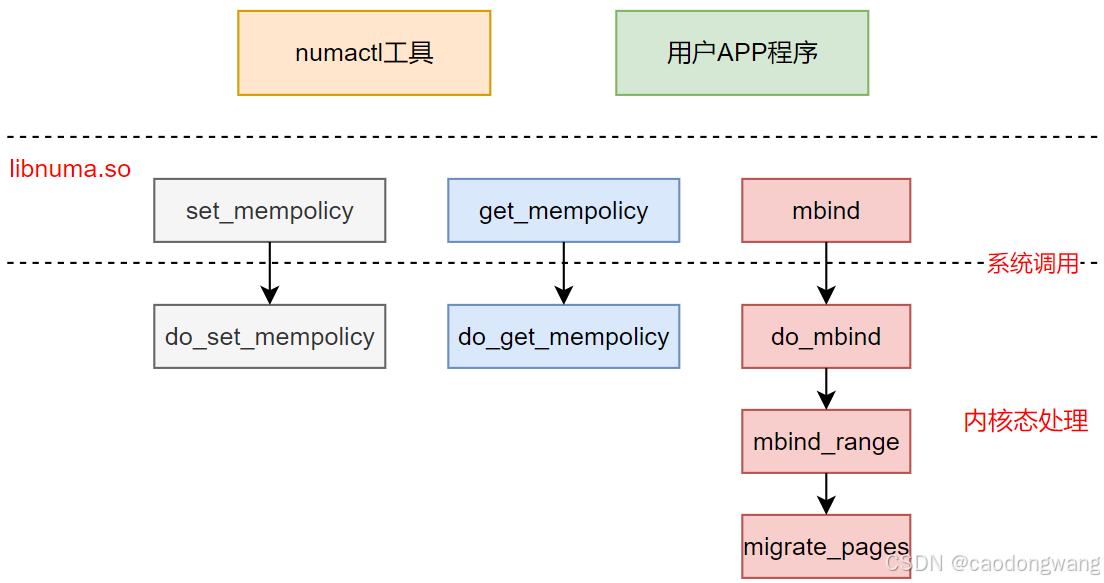
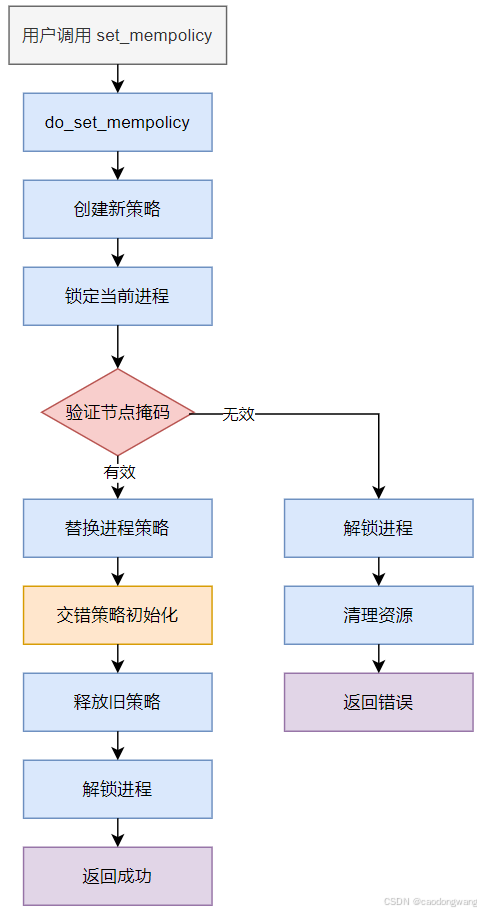
这里主要关心 do_set_mempolicy 接口,其代码如下。
static long do_set_mempolicy(unsigned short mode, unsigned short flags,nodemask_t *nodes)
{struct mempolicy *new, *old;......// 根据用户态参数创建新的内存分配策略new = mpol_new(mode, flags, nodes);if (IS_ERR(new)) {ret = PTR_ERR(new);goto out;}task_lock(current); // 加锁// 检查策略 mode 与node掩码 nodes 组合是否合法,合法则在new中填充掩码nodesret = mpol_set_nodemask(new, nodes, scratch);if (ret) {task_unlock(current);mpol_put(new);goto out;}old = current->mempolicy;current->mempolicy = new; // 新策略替换老策略if (new && (new->mode == MPOL_INTERLEAVE ||new->mode == MPOL_WEIGHTED_INTERLEAVE)) {current->il_prev = MAX_NUMNODES-1; // 如果是交错,则初始化第一个起始nodecurrent->il_weight = 0;}task_unlock(current); // 释放锁mpol_put(old); // 释放老策略ret = 0;
out:NODEMASK_SCRATCH_FREE(scratch);return ret;
}
do_set_mempolicy分配示意流程图如下:
分配策略对进程影响示例
正常情况
dwcao@a147:~$ ib_send_lat -a -d mlx5_2 -F --report_gbits 10.10.2.11
---------------------------------------------------------------------------------------Send Latency TestDual-port : OFF Device : mlx5_2Number of qps : 1 Transport type : IBConnection type : RC Using SRQ : OFFPCIe relax order: ONibv_wr* API : ONTX depth : 1Mtu : 4096[B]Link type : IBMax inline data : 236[B]rdma_cm QPs : OFFData ex. method : Ethernet
---------------------------------------------------------------------------------------local address: LID 0xaf QPN 0x0033 PSN 0x9b2924remote address: LID 0xaf QPN 0x0032 PSN 0xefedf0
---------------------------------------------------------------------------------------#bytes #iterations t_min[usec] t_max[usec] t_typical[usec] t_avg[usec] t_stdev[usec] 99% percentile[usec] 99.9% percentile[usec]2 1000 1.10 5.05 1.27 1.24 0.00 1.37 5.054 1000 1.10 1.34 1.18 1.18 0.00 1.29 1.348 1000 1.12 4.48 1.18 1.19 0.00 1.31 4.4816 1000 1.22 21.29 1.33 1.33 0.00 1.53 21.2932 1000 1.12 1.36 1.22 1.22 0.00 1.33 1.3664 1000 1.21 4.29 1.32 1.32 0.00 1.43 4.29128 1000 1.23 4.71 1.38 1.39 0.00 1.57 4.71256 1000 2.00 5.39 2.09 2.09 0.00 2.25 5.39512 1000 2.01 5.32 2.11 2.11 0.00 2.26 5.321024 1000 2.09 5.05 2.18 2.18 0.00 2.35 5.052048 1000 2.20 23.80 2.34 2.35 0.00 2.52 23.804096 1000 2.52 5.50 2.65 2.65 0.00 2.83 5.508192 1000 2.72 99.33 2.87 2.89 0.06 3.07 99.3316384 1000 3.29 7.98 3.43 3.44 0.09 3.61 7.9832768 1000 4.23 97.33 4.36 4.39 0.11 4.63 97.3365536 1000 5.58 100.40 5.75 5.77 0.09 5.96 100.40131072 1000 8.04 12.30 8.21 8.23 0.08 8.43 12.30262144 1000 13.09 18.33 13.25 13.26 0.10 13.47 18.33524288 1000 23.13 28.21 23.28 23.31 0.00 23.49 28.211048576 1000 43.19 49.75 43.59 43.62 0.08 44.01 49.752097152 1000 84.30 179.22 84.81 84.80 0.00 85.07 179.224194304 1000 166.64 181.40 166.94 166.95 0.10 167.34 181.408388608 1000 331.30 335.10 331.43 331.45 0.06 331.81 335.10
---------------------------------------------------------------------------------------dwcao@a147:~$ ib_send_bw -a -d mlx5_2 -F --report_gbits 10.10.2.11
---------------------------------------------------------------------------------------Send BW TestDual-port : OFF Device : mlx5_2Number of qps : 1 Transport type : IBConnection type : RC Using SRQ : OFFPCIe relax order: ONibv_wr* API : ONTX depth : 128CQ Moderation : 100Mtu : 4096[B]Link type : IBMax inline data : 0[B]rdma_cm QPs : OFFData ex. method : Ethernet
---------------------------------------------------------------------------------------local address: LID 0xaf QPN 0x002c PSN 0xe9879bremote address: LID 0xaf QPN 0x002d PSN 0xa9ed0f
---------------------------------------------------------------------------------------#bytes #iterations BW peak[Gb/sec] BW average[Gb/sec] MsgRate[Mpps]2 1000 0.051346 0.049625 3.1015384 1000 0.13 0.13 4.1222148 1000 0.27 0.27 4.21657716 1000 0.52 0.52 4.06530332 1000 1.06 1.06 4.13205364 1000 1.67 1.67 3.261145128 1000 4.22 4.21 4.114703256 1000 8.31 8.27 4.039236512 1000 17.12 17.08 4.1706031024 1000 33.95 33.92 4.1411422048 1000 68.84 67.58 4.1246074096 1000 122.15 121.12 3.6962828192 1000 151.90 151.77 2.31584416384 1000 186.35 186.32 1.42147432768 1000 201.01 200.99 0.76670365536 1000 202.47 188.60 0.359728131072 1000 202.71 196.41 0.187307262144 1000 201.54 200.23 0.095476524288 1000 202.83 202.18 0.0482041048576 1000 203.15 203.15 0.0242172097152 1000 203.64 203.64 0.0121384194304 1000 203.90 203.90 0.0060778388608 1000 204.03 204.03 0.003040
---------------------------------------------------------------------------------------
跨node情况
dwcao@a147:~$ numactl --membind=1 ib_send_lat -a -d mlx5_2 -F --report_gbits 10.10.2.11
---------------------------------------------------------------------------------------Send Latency TestDual-port : OFF Device : mlx5_2Number of qps : 1 Transport type : IBConnection type : RC Using SRQ : OFFPCIe relax order: ONibv_wr* API : ONTX depth : 1Mtu : 4096[B]Link type : IBMax inline data : 236[B]rdma_cm QPs : OFFData ex. method : Ethernet
---------------------------------------------------------------------------------------local address: LID 0xaf QPN 0x0034 PSN 0xeabedfremote address: LID 0xaf QPN 0x0035 PSN 0x7f543b
---------------------------------------------------------------------------------------#bytes #iterations t_min[usec] t_max[usec] t_typical[usec] t_avg[usec] t_stdev[usec] 99% percentile[usec] 99.9% percentile[usec]2 1000 1.74 4.37 1.78 1.78 0.00 1.93 4.374 1000 1.76 3.67 1.81 1.85 0.00 2.14 3.678 1000 1.75 5.54 1.84 1.85 0.00 2.04 5.5416 1000 1.77 6.40 1.83 1.88 0.03 2.28 6.4032 1000 1.76 3.85 1.86 1.88 0.00 2.21 3.8564 1000 1.95 4.50 2.22 2.21 0.00 2.49 4.50128 1000 1.93 18.05 2.10 2.11 0.00 2.37 18.05256 1000 2.88 6.12 3.02 3.02 0.03 3.26 6.12512 1000 3.01 17.53 3.14 3.15 0.00 3.42 17.531024 1000 3.35 6.36 3.52 3.52 0.06 3.74 6.362048 1000 4.07 6.96 4.21 4.22 0.03 4.46 6.964096 1000 5.47 100.99 5.68 5.79 2.95 6.00 100.998192 1000 7.20 101.46 7.37 7.39 0.23 7.68 101.4616384 1000 11.08 105.39 11.42 11.48 0.82 12.50 105.3932768 1000 6.41 113.74 6.63 8.85 5.31 19.04 113.7465536 1000 6.12 128.05 6.28 9.62 8.94 34.45 128.05131072 1000 9.38 159.00 9.88 12.92 11.92 64.34 159.00262144 1000 17.25 222.25 18.04 20.78 15.64 124.26 222.25524288 1000 32.05 339.26 33.64 36.48 22.92 241.86 339.261048576 1000 62.10 581.50 64.18 66.87 30.80 133.31 581.502097152 1000 121.27 1039.19 124.41 126.07 29.29 127.17 1039.194194304 1000 243.46 1903.83 247.92 248.48 12.15 251.82 1903.838388608 1000 485.77 1427.90 493.88 494.09 8.33 499.87 1427.90
---------------------------------------------------------------------------------------dwcao@a147:~$ numactl --membind=1 ib_send_bw -a -d mlx5_2 -F --report_gbits 10.10.2.11
---------------------------------------------------------------------------------------Send BW TestDual-port : OFF Device : mlx5_2Number of qps : 1 Transport type : IBConnection type : RC Using SRQ : OFFPCIe relax order: ONibv_wr* API : ONTX depth : 128CQ Moderation : 100Mtu : 4096[B]Link type : IBMax inline data : 0[B]rdma_cm QPs : OFFData ex. method : Ethernet
---------------------------------------------------------------------------------------local address: LID 0xaf QPN 0x0030 PSN 0x91620aremote address: LID 0xaf QPN 0x0031 PSN 0x8c1359
---------------------------------------------------------------------------------------#bytes #iterations BW peak[Gb/sec] BW average[Gb/sec] MsgRate[Mpps]2 1000 0.053305 0.052322 3.2701234 1000 0.10 0.10 3.1837708 1000 0.20 0.20 3.10510016 1000 0.41 0.40 3.11148932 1000 0.83 0.83 3.25336864 1000 1.59 1.57 3.074962128 1000 4.21 4.21 4.106591256 1000 8.39 8.36 4.084405512 1000 12.01 11.86 2.8950971024 1000 13.08 12.99 1.5851132048 1000 14.67 14.62 0.8923164096 1000 15.63 15.58 0.4753378192 1000 16.54 15.17 0.23141116384 1000 54.54 19.47 0.14857932768 1000 101.25 33.00 0.12589865536 1000 114.65 49.41 0.094248131072 1000 117.21 72.73 0.069364262144 1000 121.90 91.20 0.043486524288 1000 124.35 108.74 0.0259251048576 1000 124.28 116.58 0.0138982097152 1000 126.39 124.19 0.0074024194304 1000 129.52 129.52 0.0038608388608 1000 133.29 133.29 0.001986
---------------------------------------------------------------------------------------
可以看到跨node使用内存对时延和性能都由很大影响。
这里抛一个疑问,用户态进程先申请内存填充数据,再让PCIe设备使用这块内存,可能会出现内存所属节点和PCIe设备所属节点不是同一个。
NUMA架构内存使用优化
根据进程访问内存特定,可以将进程划分静态大内存进程、动态增长型进程、内存密集型计算进程、低延时****敏感型进程。
静态大内存进程
特征:启动时一次性分配大量内存(如数据库缓冲池、科学计算矩阵),生命周期内内存布局基本不变,远程访问延迟敏感。
优化方案:
-
显式内存绑定:
-
使用
numactl --membind或mbind()将进程绑定到单一NUMA节点,确保所有内存分配在本地节点完成。 -
示例:
numactl --membind=0 ./program(绑定到节点0)。
-
-
大页(Huge Page)对齐:
- 配置NUMA感知的大页内存(如2MB/1GB页),减少TLB缺失和地址转换开销。通过
/sys/kernel/mm/hugepages设置本地节点的大页池。
- 配置NUMA感知的大页内存(如2MB/1GB页),减少TLB缺失和地址转换开销。通过
动态增长型进程
特征:运行时内存需求逐步增加(如Java虚拟机、长周期服务进程),可能跨节点分配,易引发内存碎片或远程访问。
优化方案:
-
分区分配策略:
- 使用
MPOL_PREFERRED策略优先从本地节点分配,不足时按比例扩展至相邻低延迟节点。
- 使用
内存密集型计算进程
特征:高频访问大数据集(如AI训练、流体仿真),要求高内存带宽,对跨节点延迟极度敏感。
优化方案:
-
交错分配(Interleave):
- 按节点空闲内存或带宽比例分配内存页(如
numactl --interleave=all),均衡负载并提升聚合带宽。
- 按节点空闲内存或带宽比例分配内存页(如
-
数据分块与本地化计算:
- 将数据集划分为与NUMA节点数匹配的块,每个线程绑定到固定节点处理本地数据块。
低延迟敏感进程
特征:实时性要求高(如金融交易、音视频处理),微秒级延迟波动不可接受,内存访问量中等但需确定性响应。
优化方案:
-
CPU/内存严格亲和性:
- 使用
taskset和numactl双重绑定(如numactl --cpunodebind=0 --membind=0 ./program),确保进程仅在本地节点运行。
- 使用
-
锁页内存与预分配:
- 分配锁页内存避免换页,启动时预分配所有内存消除运行时分配延迟。
自动优化
NUMA 感知调度器与自动内存绑定
-
CPU 亲和性与内存分配联动:Linux 内核调度器会根据进程的
CPU亲和性(通过sched_setaffinity或numactl设置)自动调整内存分配策略。例如,当进程被绑定到特定CPU时,内核优先从该CPU所属node分配内存。 -
默认本地分配策略:内核默认采用
localalloc策略,进程申请内存时优先从当前CPU的node分配,失败时才扩展到其他node。
自动NUMA平衡(AutoNUMA)
-
动态页面迁移:内核线程
numad实时监控进程内存访问模式,将“热页”(频繁访问页面)迁移到当前运行CPU所属的Node。通过/proc/sys/kernel/numa_balancing启用(默认开启)。 -
进程迁移:调度器结合
numa_miss(跨节点访问次数)指标,将进程迁移到内存所在Node,降低远程访问比例。
详细的代码分析可查阅文章。
注意:应用程序的手动 NUMA 调优将覆盖自动 NUMA 平衡。