【拥抱AI】一起学卷积神经网络(CNN)
一、前置认知阶段(1 周):建立 “为什么需要 CNN” 的直观认知
概念锚点:CNN 的核心价值 —— 解决传统全连接网络处理图像时的 “参数爆炸” 与 “空间关联丢失” 问题,核心机制 “局部感知” 与 “参数共享” 的初步理解。
目标:跳出 “死记定义”,通过对比实验和可视化,直观感受 CNN 的高效性,明确 “图像数据→CNN 适配” 的底层逻辑。
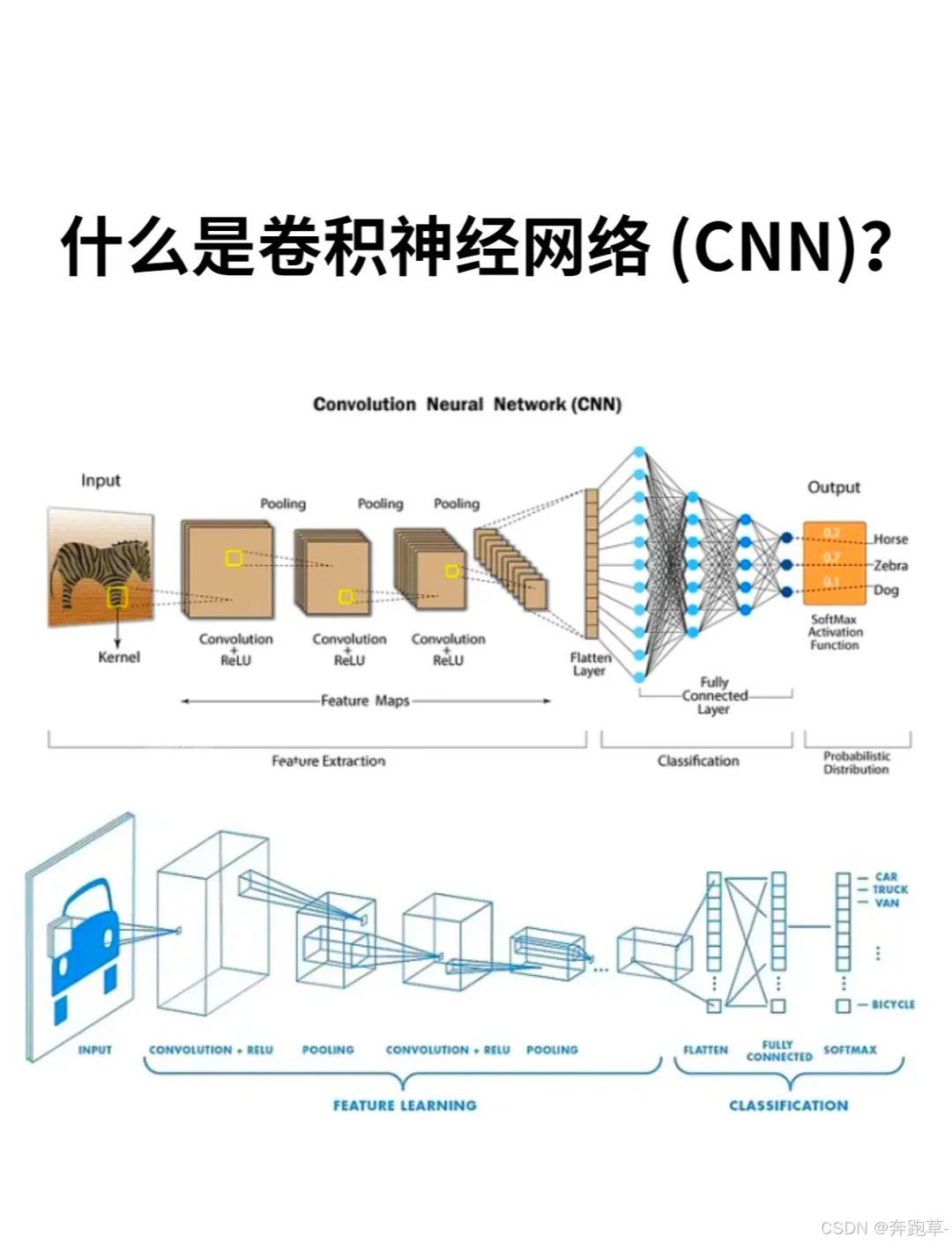
1. 核心学习内容(概念与实践深度绑定)
-
CNN 的本质:为图像而生的网络
① 拆解传统全连接网络的痛点:以 224×224×3 的 RGB 图像为例,展平后维度为 150528,若第一层全连接层设 1000 个神经元,参数量达150528×1000≈1.5 亿,不仅计算成本极高,还会丢失 “左上角像素与相邻像素的空间关联性”(而图像的边缘、纹理恰恰依赖这种关联);
② 对比 CNN 的优化逻辑:用 10 个 3×3 卷积核处理同尺寸图像,参数量仅为10×(3×3×3 + 1)=280(3×3×3 为卷积核权重,+1 为偏置),通过 “参数共享”(同一卷积核扫全图)和 “局部感知”(每个神经元只看 3×3 区域),既降参又保空间特征。
-
基础工具与数学铺垫(为后续原理打地基)
① 数学:用 NumPy 手动实现 2D 卷积(附代码框架),直观感受 “卷积 = 滤波器与局部区域的加权求和”:
import numpy as np\# 5×5灰度图(模拟输入)img = np.array(\[\[1,2,3,4,5],\[6,7,8,9,10],\[11,12,13,14,15],\[16,17,18,19,20],\[21,22,23,24,25]])\# 3×3边缘检测滤波器(模拟卷积核)kernel = np.array(\[\[-1,-1,-1],\[-1,8,-1],\[-1,-1,-1]])\# 手动计算卷积(无Padding,Stride=1)output = np.zeros((3,3)) # 输出尺寸=(5-3)/1 +1=3for i in range(3):  for j in range(3):  output\[i,j] = np.sum(img\[i:i+3, j:j+3] \* kernel)print("卷积后边缘特征:\n", output) # 输出非零值对应边缘位置
② 图像处理:用 OpenCV/PIL 拆解图像结构 —— 读取一张猫的图像,分别显示 RGB 三通道的灰度图(红色通道突出毛发、蓝色通道突出阴影),理解 “CNN 输入的 3 维张量(H×W×C)” 本质是 “多通道特征叠加”。
2. 核心实践任务(验证 CNN 的优势)
-
对比实验:全连接网络 vs 极简 CNN
① 数据集:MNIST(28×28 灰度手写数字,10 类),各取 5000 张训练、1000 张测试;
② 模型 1(全连接):输入层(784 维)→ 隐藏层(256 维)→ 输出层(10 维),参数量≈784×256 + 256×10≈206k;
③ 模型 2(极简 CNN):卷积层(16 个 3×3 核,参数量≈16×(3×3+1)=160)→ MaxPooling(2×2)→ 全连接层(10 维,参数量≈14×14×16×10≈31.3k);
④ 记录指标:训练 10 轮后,全连接模型参数量是 CNN 的 6.6 倍,训练时间是 CNN 的 1.8 倍,测试准确率却低 2-3%(因丢失空间特征),直观验证 CNN 的 “高效 + 高精度”。
3. 资源与问题指引
-
可视化工具:
-
ConvNetJS:在线调整卷积核(如边缘检测、模糊核),实时查看图像卷积后的特征变化;
-
Tensorflow Playground:对比 “全连接” 与 “卷积” 在图像分类任务中的损失下降速度。
-
-
常见问题:
-
Q:为什么手动计算卷积时输出尺寸会缩小?A:无 Padding 时,滤波器无法覆盖图像边缘,需后续学习 “Same Padding” 解决。
-
Q:NumPy 实现的卷积与框架中的卷积有差异吗?A:框架默认会加偏置、支持批量处理,本质计算逻辑一致。
-
二、核心原理拆解阶段(2-3 周):吃透 CNN 的 “零部件” 与 “特征提取流水线”
概念锚点:卷积层、池化层、激活函数的数学原理与作用,CNN“浅层提局部特征→深层组全局特征” 的分层逻辑,经典架构的设计创新。
目标:从 “黑箱调用” 到 “白箱理解”,能解释 “为什么 3×3 卷积核是主流”“MaxPooling 为何能增强鲁棒性”,并通过复现经典模型验证原理。
1. 核心学习内容(原理 + 案例 + 数学推导)
- CNN 核心组件的 “原理 - 作用 - 影响” 三维解析
| 组件 | 数学原理 | 实际作用 | 关键参数影响(以 PyTorch 为例) |
|---|---|---|---|
| 卷积层 | 输出特征图 = 输入图像 ∗ 卷积核 + 偏置(∗表示卷积运算) | 提取局部特征(边缘、纹理、颜色块) | ① 卷积核尺寸:3×3 比 5×5 参数量少(3×3×2=18 <5×5=25),且堆叠 2 个 3×3 等价 1 个 5×5 的感受野,特征提取更精细;② Padding:padding=1(Same)保持输出尺寸,padding=0(Valid)缩小尺寸;③ Stride:stride=2比stride=1输出尺寸减半,计算量减少 75% |
| ReLU 激活 | f(x)=max(0,x)f(x) = \max(0, x)f(x)=max(0,x) | 注入非线性(否则多层卷积等价于单层线性变换),解决梯度消失 | 无参数,但需注意:ReLU 会 “杀死” 负像素值,若需保留微弱负特征,可改用 Leaky ReLU(f(x)=max(0.1x,x)f(x)=\max(0.1x, x)f(x)=max(0.1x,x)) |
| MaxPooling | 取局部区域(如 2×2)的最大值 | ① 降维减算;② 增强平移不变性(如数字 “3” 轻微右移,最大值位置不变) | 池化核尺寸:2×2 最常用,若用 3×3 可能丢失过多细节;Stride:通常与核尺寸一致(如 2×2 核 + stride=2),避免重叠过多 |
| BatchNorm | 对每批数据标准化:y=γ⋅x−μσ2+ϵ+βy = \gamma \cdot \frac{x-\mu}{\sqrt{\sigma^2+\epsilon}} + \betay=γ⋅σ2+ϵx−μ+β(γ,β\gamma,\betaγ,β为可学习参数) | 加速训练(允许更大学习率),抑制过拟合,减少 “内部协变量偏移” | eps=1e-5(避免分母为 0),momentum=0.9(滑动平均计算均值和方差) |
-
CNN 的特征提取逻辑:从 “边缘” 到 “物体” 的分层演进
以 “识别猫” 为例(输入 224×224×3 图像,基于 ResNet-18):
① 浅层(第 1 卷积层,3×3 核):输出 64 张 112×112 特征图,主要提取 “水平边缘”(如猫的胡须)、“垂直边缘”(如耳朵轮廓)、“红色色块”(如猫的毛发底色);
② 中层(第 3 残差块,堆叠 3×3 卷积):输出 128 张 28×28 特征图,特征开始组合 ——“边缘 + 色块” 形成 “眼睛形状”“鼻子轮廓” 等部件特征;
③ 深层(第 5 残差块):输出 512 张 7×7 特征图,全局特征整合,形成 “猫的头部轮廓 + 身体姿态” 的完整特征;
④ 输出层:7×7×512 展平为 25088 维向量,经全连接层映射到 1000 维(ImageNet 类别),Softmax 输出 “猫” 的概率(如 0.98)。
-
经典架构的演进逻辑(理解 “为什么这么设计”)
① LeNet-5(1998):首个实用 CNN,用 “卷积→池化→全连接” 处理 28×28 手写数字,证明 CNN 在图像任务的有效性;
② AlexNet(2012):突破点在于 “ReLU 替代 Sigmoid”(解决深层梯度消失)、“双 GPU 并行训练”(处理 224×224 大图像),ImageNet 准确率从 57% 提升到 85%,开启深度 CNN 时代;
③ VGGNet(2014):用 “8 个 3×3 卷积核替代 1 个 7×7 卷积核”,参数量减少 40%,特征提取更精细,成为后续目标检测(如 Faster R-CNN)的基础骨干网络。
2. 核心实践任务(原理验证 + 可视化)
-
复现 LeNet-5 并可视化特征图
① 用 PyTorch 搭建 LeNet-5:
import torch.nn as nnclass LeNet5(nn.Module):  def \_\_init\_\_(self):  super().\_\_init\_\_()  self.conv1 = nn.Conv2d(1, 6, kernel\_size=5, padding=2) # 1→6通道,28×28→28×28  self.pool1 = nn.MaxPool2d(kernel\_size=2, stride=2) # 28×28→14×14  self.conv2 = nn.Conv2d(6, 16, kernel\_size=5) # 6→16通道,14×14→10×10  self.pool2 = nn.MaxPool2d(kernel\_size=2, stride=2) # 10×10→5×5  self.fc1 = nn.Linear(16×5×5, 120) # 400→120  self.fc2 = nn.Linear(120, 84) # 120→84  self.fc3 = nn.Linear(84, 10) # 84→10(10类数字)  def forward(self, x):  x = self.pool1(torch.relu(self.conv1(x)))  x = self.pool2(torch.relu(self.conv2(x)))  x = x.view(-1, 16×5×5) # 展平  x = torch.relu(self.fc1(x))  x = torch.relu(self.fc2(x))  return self.fc3(x)
② 可视化特征图:用训练好的模型,提取conv1(浅层)和conv2(中层)的输出特征图,观察浅层 “边缘特征” 和中层 “组合特征” 的差异(可借助matplotlib绘制特征图热力图)。
-
卷积参数计算练习(避免 “调参凭感觉”)
已知输入图像为 64×64×3,使用 32 个 3×3 卷积核,Stride=2,Padding=1,求输出特征图的尺寸和通道数:
尺寸计算:(64−3+2×1)/2+1=(63)/2+1=31.5+1(64 - 3 + 2×1)/2 + 1 = (63)/2 +1 = 31.5 +1(64−3+2×1)/2+1=(63)/2+1=31.5+1→向上取整 32(实际框架会自动处理),通道数 = 32,最终输出 32×32×32。
3. 资源与问题指引
-
深度教材:《动手学深度学习》(李沐)第 7 章(CNN 原理与实现,含代码注释);
-
可视化工具:TensorBoard(在训练中添加
add_image日志,实时查看各层特征图); -
常见问题:
-
Q:为什么卷积核尺寸通常是奇数?A:奇数核有唯一中心,便于 Padding 时对称填充,避免特征偏移。
-
Q:BatchNorm 为什么能加速训练?A:标准化后每层输入分布更稳定,梯度不会因输入值过大 / 过小而消失或爆炸,可将学习率从 0.001 提升到 0.01。
-
三、实战进阶阶段(3-4 周):用经典模型验证 “原理→性能” 的映射
概念锚点:残差连接解决梯度消失的原理、深度可分离卷积的参数量优化逻辑、迁移学习中 “冻结与微调” 的平衡。
目标:掌握 “从模型选择→超参调优→性能诊断” 的全流程,能根据任务需求(如移动端、高精度)选择合适的 CNN 架构。
1. 核心学习内容(架构实战 + 调优技巧)
-
主流架构的核心创新与实战要点
① ResNet(残差网络):
② MobileNet(轻量化 CNN):
③ 迁移学习的 “冻结与微调” 策略:
-
核心问题:深层网络(如 50 层)训练时,梯度会随反向传播逐步衰减至 0(梯度消失),导致模型无法收敛;
-
残差连接原理:通过 “shortcut 路径” 将输入xxx直接加到卷积层输出F(x)F(x)F(x),即H(x)=F(x)+xH(x)=F(x)+xH(x)=F(x)+x,反向传播时梯度∂L∂x=∂L∂H(x)⋅(∂F(x)∂x+1)\frac{\partial L}{\partial x} = \frac{\partial L}{\partial H(x)} \cdot (\frac{\partial F(x)}{\partial x} + 1)∂x∂L=∂H(x)∂L⋅(∂x∂F(x)+1),“+1” 确保梯度不会消失;
-
实战技巧:复现 ResNet-18 时,注意 “残差块” 的两种类型 ——“相同维度残差块”(输入输出通道一致,直接加xxx)和 “维度提升残差块”(输入输出通道不同,需用 1×1 卷积调整xxx的通道数)。
-
核心创新:深度可分离卷积(Depthwise Separable Convolution),将标准卷积拆分为 “深度卷积(Depthwise)” 和 “逐点卷积(Pointwise)”:
-
标准卷积(3×3 核,16→32 通道):参数量 = 3×3×16×32=4608;
-
深度可分离卷积:深度卷积(3×3 核,16 通道,参数量 = 3×3×16=144)+ 逐点卷积(1×1 核,16→32 通道,参数量 = 1×1×16×32=512),总参数量 = 656,仅为标准卷积的 14.2%;
-
-
实战场景:手机端 “实时图像分类”(如相册自动分类),用 MobileNetV2 训练 “剪刀 / 石头 / 布” 三分类模型,推理速度可达 30 FPS(帧 / 秒)。
-
原理:预训练模型(如 ResNet-50 在 ImageNet 上训练)的浅层卷积核已学习 “边缘、纹理” 等通用特征,无需重新训练;深层卷积核学习 “物体部件” 等特定特征,需微调以适配新任务;
-
实操步骤:
-
-
冻结浅层(如前 40 层):
for param in model.layer1.parameters(): param.requires_grad = False; -
训练深层(layer5)和全连接层:用较大学习率(如 1e-4);
-
微调阶段(训练后期):解冻所有层,用较小学习率(如 1e-5),避免破坏已学特征。
2. 核心实践任务(实战 + 诊断)
-
ResNet-18 vs 全连接网络:梯度消失验证
① 数据集:CIFAR-10(32×32 彩色图像,10 类);
② 模型 1:ResNet-18(18 层,含残差连接);模型 2:无残差的 18 层 CNN(仅卷积 + 池化 + 全连接);
③ 记录指标:训练 10 轮后,无残差模型的训练损失下降缓慢(如停留在 1.5),ResNet-18 的训练损失降至 0.8,验证梯度值(用
torch.autograd.grad查看),无残差模型的浅层梯度接近 0,ResNet-18 的梯度保持在 0.1-0.5,验证残差连接的作用。 -
模型诊断:当 CNN 准确率低时该怎么办?
① 案例:用简单 CNN 训练 CIFAR-10,验证准确率仅 70%(目标 85%);
② 诊断步骤:
-
查看训练损失与验证损失:若训练损失低(0.5)但验证损失高(1.2),说明过拟合,需增加数据增强(如随机翻转、裁剪)或添加 Dropout(
nn.Dropout(0.5)); -
可视化中层特征图:若特征图模糊(无明显边缘 / 部件),说明特征提取不足,需加深卷积层(如增加 1 个残差块)或增大卷积核数量;
-
调整学习率:若训练损失波动大,说明学习率过高(如 1e-2),需降至 1e-4,并用学习率调度(
torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1))。
-
移动端部署:MobileNetV2 实时分类
① 数据集:自定义 “水果分类” 数据集(苹果 / 香蕉 / 橙子,各 300 张,用 LabelImg 标注);
② 训练:用 MobileNetV2 迁移学习,冻结前 10 层,训练全连接层,目标验证准确率≥90%;
③ 部署:将模型转换为 ONNX 格式(
torch.onnx.export(model, dummy_input, "mobilenet_fruit.onnx")),用 ONNX Runtime 在手机端(如 Android)实现实时分类,测试推理速度。
3. 资源与问题指引
-
实战代码库:PyTorch Vision Models(含 ResNet、MobileNet 等预训练模型,可直接调用);
-
数据集:Kaggle(CIFAR-10、Fruits 360)、LabelImg(图像标注工具);
-
常见问题:
-
Q:迁移学习时,为什么新数据集越小,越要多冻结浅层?A:小数据集不足以覆盖通用特征的多样性,冻结浅层可避免通用特征被破坏。
-
Q:MobileNet 准确率比 ResNet 低怎么办?A:可使用 MobileNetV3(加入注意力机制),或在关键层增加 1×1 卷积提升通道数,平衡精度与速度。
-
四、深化与应用阶段(长期):从 “原理” 到 “行业级问题解决”
概念锚点:CNN 在目标检测 / 分割中的扩展逻辑(如 Anchor、编码器 - 解码器)、CNN 与 Transformer 的融合、轻量化部署的工程优化。
目标:掌握 CNN 在复杂场景的应用,理解 “学术创新” 到 “工业落地” 的转化,具备解决实际问题(如医学影像分割、智能驾驶检测)的能力。
1. 核心学习内容(行业场景 + 前沿融合)
-
CNN 在复杂视觉任务中的扩展
① 目标检测(YOLOv8):
② 图像分割(U-Net):
③ 医学影像的特殊优化:
-
核心扩展:从 “分类” 到 “定位 + 分类”,CNN 需输出 “目标边界框(x,y,w,h)” 和 “类别概率”;
-
关键概念:Anchor 机制(预设 12 种不同尺寸的框,匹配不同大小的目标,如小 Anchor 检测行人、大 Anchor 检测汽车)、非极大值抑制(NMS,去除重复检测框);
-
行业应用:智能驾驶 “行人 / 车辆检测”,要求实时性(≥20 FPS)和高精度(mAP≥0.85),YOLOv8 通过 “多尺度检测”(浅层检测小目标、深层检测大目标)满足需求。
-
核心扩展:从 “整图分类” 到 “像素级分类”,需输出与输入同尺寸的 “分割掩码”(每个像素对应类别,如肿瘤像素标 1、正常像素标 0);
-
关键结构:编码器 - 解码器(Encoder 下采样提取深层语义特征,Decoder 上采样恢复分辨率,跳跃连接融合浅层细节与深层语义,解决分割边缘模糊问题);
-
行业应用:医学影像 “肺结节分割”,用 U-Net 分割 CT 图像中的结节区域,辅助医生诊断,需满足高召回率(≥95%,避免漏检)。
-
数据问题:医学数据少且标注成本高,需用 “迁移学习 + 数据增强”(如弹性形变、旋转,模拟不同扫描角度);
-
精度要求:需加入注意力机制(如 SE 模块),聚焦病变区域(如肿瘤),减少背景干扰。
-
-
CNN 与前沿技术的融合
① CNN+Transformer(Swin Transformer):
② 轻量化部署工程优化:
-
融合逻辑:CNN 擅长局部特征提取,Transformer 擅长全局关联建模,Swin Transformer 用 “窗口注意力”(将图像分为 7×7 窗口,在窗口内计算注意力)结合 CNN 的局部性,既保留全局关联,又降低计算量;
-
优势场景:高分辨率图像任务(如 4K 图像分割),比纯 CNN 精度提升 5-10%。
-
模型压缩:量化(将 32 位浮点数权重转为 8 位整数,速度提升 4 倍)、剪枝(移除冗余卷积核,参数量减少 30%);
-
推理加速:用 TensorRT(NVIDIA GPU 加速)或 OpenVINO(CPU 加速),MobileNet 模型在 GPU 上推理速度可达 100 FPS。
-
2. 核心实践任务(行业级项目)
-
YOLOv8 交通标志检测
① 数据准备:采集 500 张含红绿灯、限速牌、停车标志的道路图像,用 LabelImg 标注(边界框 + 类别),按 8:2 划分为训练 / 测试集;
② 训练:基于 YOLOv8n(轻量化版本),修改输出类别数为 3,训练 20 轮,用 mAP(平均精度均值)评估,目标 mAP≥0.9;
③ 部署:用 OpenCV 读取摄像头视频流,加载 YOLOv8 模型,实现实时检测(每帧耗时≤50ms),并在视频中绘制边界框和类别标签。
-
U-Net 肺结节分割
① 数据集:LIDC-IDRI(公开肺结节 CT 数据集,含 1000 例 CT 图像及结节标注);
② 预处理:将 CT 图像归一化到 [-1000,400](肺组织的 HU 值范围),裁剪为 256×256 尺寸;
③ 训练:搭建 U-Net 模型,用 Dice 损失(适合分割任务的损失函数)训练,目标 Dice 系数≥0.85(越接近 1 分割效果越好);
④ 可视化:对比模型输出的分割掩码与人工标注,分析漏检 / 误检原因(如小结节漏检可增大浅层卷积核数量)。
3. 资源与问题指引
-
前沿论文:arXiv(cs.CV 分类,关注 CVPR/ICCV 顶会,如《YOLOv8: Evolution of Real-Time Object Detection》);
-
部署工具:TensorRT Developer Guide、OpenVINO Toolkit;
-
行业数据集:医学影像(LIDC-IDRI、CheXpert)、智能驾驶(KITTI、Waymo);
-
常见问题:
-
Q:分割任务中,为什么用 Dice 损失而不用交叉熵?A:交叉熵对类别不平衡敏感(如背景像素远多于目标像素),Dice 损失直接计算分割区域的重叠度,更适合分割。
-
Q:Swin Transformer 比纯 CNN 慢怎么办?A:可使用 “窗口注意力 + 下采样” 减少计算量,或选择轻量化版本 Swin-T。
-
总结:从 “概念本质” 到 “落地能力” 的完整闭环
本方案以 CNN 的 “局部感知”“参数共享”“分层特征提取” 三大核心概念为贯穿始终的线索,每个阶段均实现 “概念理解→数学推导→代码验证→效果分析→问题解决” 的闭环:
-
前置认知阶段:通过对比实验感受 CNN 的价值;
-
核心原理阶段:拆解组件原理,理解 “特征如何从简单到复杂”;
-
实战进阶阶段:用经典模型验证原理对性能的影响,掌握调优技巧;
-
深化应用阶段:将 CNN 扩展到行业场景,理解学术与工业的衔接。
最终,让学习者不仅 “会用 CNN”,更 “懂 CNN 为什么这么用”,具备从 “任务需求” 反推 “模型选择与优化” 的能力。