详解开源关键信息提取方案PP-ChatOCRv4的设计与实现
一,问题背景与挑战
在数字化时代,文档依然是承载和传递信息的重要媒介。特别是在金融、法律、医疗等领域,从发票、合同、病历等复杂文档中精准提取关键信息,是自动化办公和智能决策的基础环节。
然而,关键信息提取在实际落地中面临多重挑战:
-
复杂文档结构理解:文档往往包含文本、表格、印章、图像等多种元素,传统 OCR 难以完整解析复杂布局
-
语义理解与推理:不仅要识别文本,还需结合上下文和领域知识进行语义推理
-
多模态信息融合:需要将视觉信息与文本语义有效结合,实现跨模态理解
-
模型效率与部署:大型模型效果好但部署成本高,轻量模型部署容易但精度不足
为应对这些问题,PP-ChatOCRv4应需而生,融合了 OCR、计算机视觉与大语言模型技术,实现了复杂文档的高效智能解析与关键信息抽取。

二,PP-ChatOCRv4 解决方案概述
PP-ChatOCRv4 是一个开源的端到端关键信息抽取与智能问答系统,面向复杂文档的解析与交互场景。它结合 OCR 技术、结构化解析、向量检索 与 大语言模型(LLM),构建了从文档图像到结构化结果的完整处理链路 → PP-ChatOCRv4快速体验。
大模型社区-飞桨星河AI Studio大模型社区
1,核心设计理念
-
模块化架构:组件松耦合,便于替换、扩展和二次开发
-
多模态融合:结合视觉特征与文本语义,提高理解准确度
-
检索增强:向量检索为 LLM 提供精准上下文,提升回答质量
-
轻量高效:支持轻量化部署,适配资源受限环境
-
开源共建:完全开源,与 PaddlePaddle 生态深度集成
2,技术架构
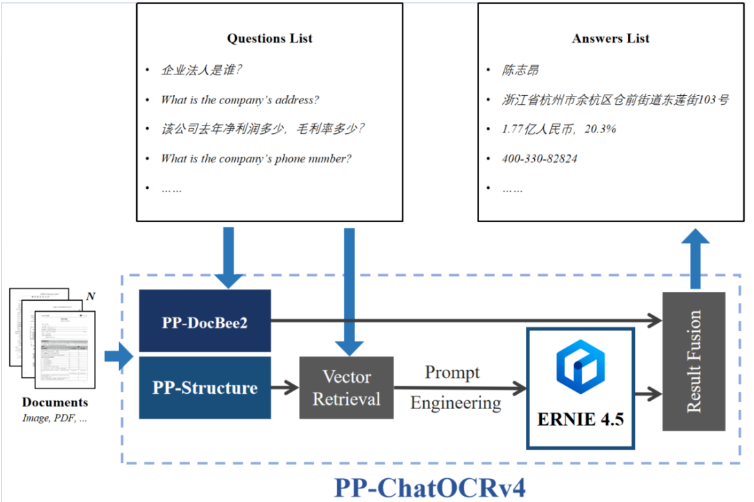
主要模块说明:
-
PP-DocBee2
对文档进行全文解析与语义理解,直接产出关键信息候选
-
PP-StructureV3
执行表格解析、版面分析、字段定位等结构化处理
-
Vector Retrieval(向量检索)
将结构化结果转为向量并检索,为推理提供精准上下文
-
Prompt Engineering(提示词工程)
将检索结果与用户问题结合,生成优化后的 LLM 输入
-
大语言模型
支持 ERNIE、GPT 等模型,完成跨领域语义推理与生成
-
Result Fusion(结果融合)
融合 LLM 输出与 PP-DocBee2 结果,提升最终结果的准确性与置信度
这种架构既保留了传统 OCR 的高精度识别优势,又结合检索增强的多模态推理,使其能够胜任复杂、多变的文档解析任务。
三,环境准备与快速体验
1,安装依赖
PP-ChatOCRv4 基于 PaddleOCR 3.0 开发,使用前需安装必要依赖:
# 安装 PaddlePaddle (GPU版本)
python -m pip install paddlepaddle-gpu==3.1.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/
# 安装 PaddleOCR
pip install paddleocr
# 安装 ERNIE-4.5-0.3B 依赖
git clone https://github.com/PaddlePaddle/ERNIE.git
cd ERNIE
pip install -r requirements.txt
pip install -e .
pip install --upgrade opencv-python opencv-python-headless2,快速上手示例
以下是一个简单的PP-ChatOCRv4使用示例,展示如何从合同文档中提取关键信息:
from paddleocr import PPChatOCRv4Doc
# 配置ERNIE服务
chat_bot_config = {"module_name": "chat_bot","model_name": "ernie-4.5-0.3b","base_url": "http://0.0.0.0:8178/v1","api_type": "openai","api_key": "sk-xxxxxx...", # 替换为你的API密钥
}
# 初始化PP-ChatOCRv4
pipeline = PPChatOCRv4Doc()
# 文档视觉分析
image_path = "./contract_sample.jpg"
visual_predict_res = pipeline.visual_predict(input=image_path,use_doc_orientation_classify=False,use_doc_unwarping=False,use_common_ocr=True,use_seal_recognition=True,use_table_recognition=True,
)
# 提取视觉信息
visual_info_list = []
for res in visual_predict_res:visual_info_list.append(res["visual_info"])
# 关键信息提取
question = "合同中的甲方名称是什么?"
chat_result = pipeline.chat(key_list=[question],visual_info=visual_info_list,chat_bot_config=chat_bot_config,
)
print(chat_result['chat_res'])
# 预期输出: {'合同中的甲方名称是什么?': '北京科技有限公司'}项目完整代码,请参见:Practice of Key Information Extraction in Contract Scenarios Based on ERNIE-4.5-0.3B and PaddleOCR
链接:https://github.com/PaddlePaddle/ERNIE/blob/develop/cookbook/notebook/key_information_extraction_tutorial_en.ipynb
四,性能评估与优化
1,基准测试
我们在公开数据集和实际业务场景中对PP-ChatOCRv4进行了全面评估,以下是在合同关键信息提取任务上的性能表现:
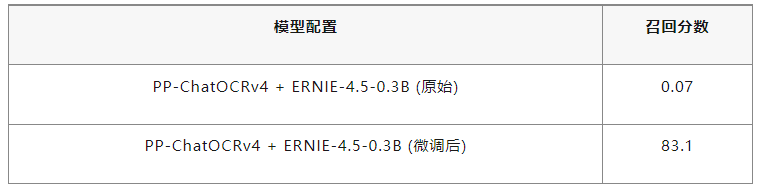
测试环境:A100 GPU, batch size=1, 输入文本长度平均512 tokens
2,优化策略
PP-ChatOCRv4的性能优化主要体现在以下几个方面:
-
模型压缩:采用知识蒸馏、量化等技术,减小模型体积
-
推理加速:使用Paddle Inference优化推理性能
-
并行计算:支持多GPU并行处理,提高吞吐量
-
自适应batch size:根据输入文档复杂度动态调整batch size
# 启用INT8量化优化
from paddle.quantization.quantize import quantize_model
quantized_model = quantize_model(model, quantize_type='INT8')
# 使用Paddle Inference加速推理
from paddle.inference import Config, create_predictor
config = Config(model_path)
config.enable_memory_optim()
config.set_cpu_math_library_num_threads(10)
predictor = create_predictor(config)五,实际应用案例
以下是使用PP-ChatOCRv4处理合同文档的实际案例:
案例:从房屋租赁合同中提取面积误差比例
from paddleocr import PPChatOCRv4Doc
# 配置ERNIE服务
chat_bot_config = {"module_name": "chat_bot","model_name": "xxx","base_url": "http://10.214.40.13:8170/v1","api_type": "openai","api_key": "sk-xxxxxx...", # your api_key
}
# 初始化模型
pipeline = PPChatOCRv4Doc()
# 处理文档
image_path = "./housing_contract.jpg"
question = "合同中的面积误差比例是多少?"
visual_predict_res = pipeline.visual_predict(input=image_path,use_doc_orientation_classify=False,use_doc_unwarping=False,use_common_ocr=True,use_seal_recognition=True,use_table_recognition=True,
)
visual_info_list = []
for res in visual_predict_res:visual_info_list.append(res["visual_info"])layout_parsing_result = res["layout_parsing_result"]
# 提取面积误差比例
chat_result = pipeline.chat(key_list=[question],visual_info=visual_info_list,vector_info=None,mllm_predict_info=None,chat_bot_config=chat_bot_config,retriever_config=None,
)
print(chat_result['chat_res'])
# 输出: {'合同中的面积误差比例是多少?': '面积误差比绝对值在5%以内(含5%)'}实际应用中,PP-ChatOCRv4展现出了良好的鲁棒性和准确性,能够有效处理各种复杂合同文档。

六 总结与展望
PP-ChatOCRv4作为开源关键信息提取解决方案,通过融合OCR、计算机视觉和大语言模型技术,有效解决了复杂文档解析的难题。其模块化设计、多模态融合能力和轻量级部署特性,使其在金融、法律、医疗等多个领域具有广泛的应用前景。
下一步与资源
📚 查阅完整文档:PaddleOCR官方文档
https://github.com/PaddlePaddle/PaddleOCR
💻 运行示例代码:Practice of Key Information Extraction in Contract Scenarios Based on ERNIE-4.5-0.3B and PaddleOCR
https://github.com/PaddlePaddle/ERNIE/blob/develop/cookbook/notebook/key_information_extraction_tutorial_en.ipynb
🐞 报告问题或提出建议:PaddleOCR GitHub Issues
https://github.com/PaddlePaddle/PaddleOCR/issues
🤝 欢迎贡献代码:PaddleOCR贡献指南
https://github.com/PaddlePaddle/PaddleOCR/blob/main/docs/community/community_contribution.md
如果你有更好的文章,欢迎投稿!
稿件接收邮箱:nami.liu@pasuntech.com
更多精彩内容请关注“算力魔方®”!