第6章 AB实验的SRM问题
目录
一、什么是SRM问题?
二、SRM的三大成因与典型案例
1️⃣ 部署阶段:残留效应
1. 残留效应:实验迭代
2. 触发前状态偏差:代码顺序
3. 动态定向目标:流动标签
防御措施
2️⃣ 执行阶段:策略下发时机偏差
3️⃣ 数据处理阶段:机器人过滤陷阱
三、SRM计算与问题定位四步法
1️⃣SRM指标计算
2️⃣SRM问题定位
1. 检查随机化点上游的一致性
2. 验证变量分配机制
3. 检查实验组/对照组的初始同步性
4. 细分市场与时间维度分析
5. 交叉实验影响评估
6. 判断是否可修复或需重跑实验
四、如何避免SRM问题?
附1:SRM计算工具(Python示例)
附2:残留效应典型案例解析——电商平台"个性化推荐"实验
一、实验背景
二、残留效应发生过程
三、具体异常表现
四、根本原因分析
五、解决方案与效果
六、经验总结
附3:触发前状态偏差案例与解析
一、概念本质
二、案例(信息流小部件实验)
三、错误代码逻辑分析
四、解决方案原理
五、业务影响模拟
六、通用检测方法
七、延伸思考
AB实验被视为产品迭代的黄金标准,但许多人忽略了一个关键陷阱——样本比例不匹配(SRM)。实际数据显示,超过30%的实验因SRM问题导致结论失效。
一、什么是SRM问题?
当实验组与对照组的用户比例偏离设计值时,即发生SRM问题。例如:
- 设计预期:实验组/对照组 = 50% : 50%(比例1.0)
- 实际结果:实验组用户821,588 vs 对照组815,482 → 实际比例0.993
计算验证:通过假设检验判断偏差是否显著
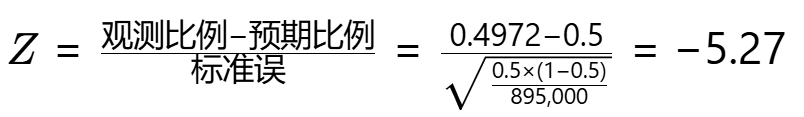
反查正态分布表得 P值=1.17×10⁻⁷(远小于0.001),表明该偏差随机发生的概率仅为百万分之0.117!此时必须怀疑实验流程存在系统性错误。
📌 核心结论:当P值<0.001且样本量足够大(why?)时,实验结果不可信!
大样本的敏感性
用户量小(如100人):50 vs 50 → 53 vs 47 可能是偶然
用户量大(160万):821k vs 815k → 即使差0.6%也绝不可能是偶然
为什么SRM会导致实验失效?
实验目的:测试「草莓蛋糕」和「巧克力蛋糕」哪种更受欢迎
SRM污染:分蛋糕时,A组(草莓)总是多分到0.6%。结果A组多吃到的部分并非因为草莓更好吃,而是分配机制倾斜。
最终结论:无法区分「口味差异」和「分配偏差」 → 实验无效。
注意:SRM问题只关注实验最初的分流比例(如进入实验的总用户量),不关心后续漏斗环节(如点击/转化的用户量差异)。
- 分流阶段(判断SRM)
- 计算依据:实验组 vs 对照组的初始用户分配量
- 示例:设计分流50%用户到实验组,实际只有45% → SRM警报
- 漏斗阶段(非SRM问题)
- 计算依据:实验组 vs 对照组的转化率/留存率等指标
- 示例:实验组点击率比对照组高20% → 这是实验效果,不是SRM
SRM是“分蛋糕”问题(是否公平分配),漏斗差异是“吃蛋糕”问题(谁吃得更多)。
二、SRM的三大成因与典型案例
1️⃣ 部署阶段:残留效应
1. 残留效应:实验迭代
文章末尾有案例
定义:前次实验改变用户行为,污染后续实验的分流比例
核心机制:
- 用户分组在多轮迭代中保持固定
- 实验效果改变用户活跃度 → 重新触发概率变化 → 用户计数失真
📌 典型案例:社交平台"可能认识的人"算法
| 阶段 | 现象 | 根本原因 |
|---|---|---|
| 第一轮迭代 | 实验组参与度提升30% | 算法效果优异 |
| 第二轮迭代 | SRM报警(P值<0.001) | 活跃用户更快进入冷却期 |
| 数据验证 | 首次触发用户比例正常 | 实验组回流用户减少23% |
解决方案:
# 修正计数逻辑:仅统计首次触发用户
user_count = count_users(first_trigger_time >= experiment_start_time)2. 触发前状态偏差:代码顺序
文章末尾有案例
定义:分流逻辑顺序不当,导致实验组用户被提前过滤
📌 典型案例:信息流交叉推广实验
错误代码逻辑:
if user in cool_off: # 先检查冷却状态no_widget()
elif user in control: # 后检查分组no_widget()
else:show_widget() # 实验组展示后果:
- 实验组活跃用户更快进入冷却期 → 不再触发跟踪事件
- 实验组有效用户数减少18% → SRM报警
✅ 修复方案
if user in control: # 先检查分组no_widget()
elif user in cool_off: # 后检查冷却状态no_widget()
else:show_widget()效果:实验组用户计数恢复预期比例
3. 动态定向目标:流动标签
定义:基于实时变化的用户属性(如活跃度)分组
⚠️ 双重风险
| 风险类型 | 后果 | 发生概率 |
|---|---|---|
| 属性延迟更新 | 用户体验受损(如向活跃用户推拉活策略) | 高 |
| 属性实时更新 | 实验组用户数量波动 → SRM问题 | 极高 |
📌 典型案例:招聘平台"求职兴趣"算法
实验设计:
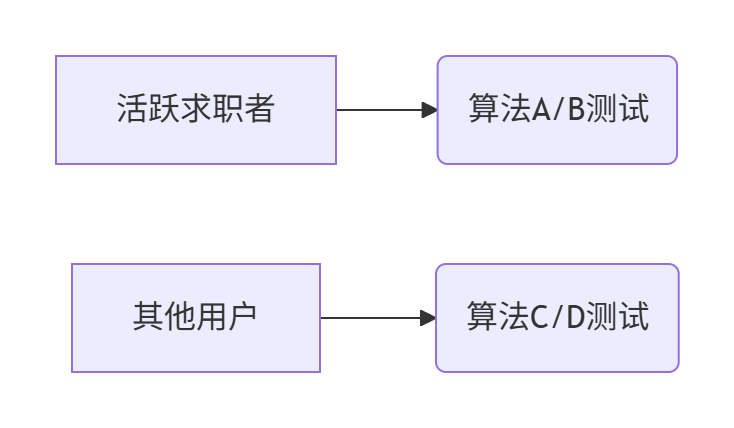
故障链:
- 算法C效果极佳 → 提升用户活跃度
- 部分用户被重新分类为"活跃求职者"
- 这些用户落入算法A组 → A组用户超预期+15%
- 算法A/B组间SRM报警(P值=0.0002)
🔥 连锁反应:
- 算法C/D组被污染(部分C组用户实际接受A组服务)
- 全实验结果失效
解决方案
"属性快照冻结"原则:在实验开始时固定用户属性状态
SELECT user_id FROM experiment_group WHERE user_status = 'dormant' AND snapshot_time = '2023-01-01 00:00:00' -- 实验启动时刻
防御措施
- 残留效应 → 采用首次触发计数法
- 状态偏差 → 遵守分组优先逻辑原则
- 动态属性 → 执行实验启动时属性冻结
💡 经验启示:SRM问题像"实验癌症",早期诊断(SRM测试)可避免90%的分析灾难!
2️⃣ 执行阶段:策略下发时机偏差
在执行AB实验时,策略下发方式会直接影响实验结果的可靠性。主要存在两类风险:
- 时序偏差:实验组和对照组策略不同步下发
- 过滤偏差:实验组存在隐性筛选条件而对照组无筛选
| 类型 | 典型场景 | 偏差方向 | 检测方法 | 解决方案 |
|---|---|---|---|---|
| 技术实现筛选 | 新功能需要高版本系统/特定硬件 | 实验组用户设备更新 | 设备类型分布对比 | 功能降级兼容 |
| 下发成功率筛选 | 实验组策略需成功加载,对照组无要求 | 保留高质量网络用户 | 下发成功率监控 | 对照组同步空载 |
| 行为路径筛选 | 实验组流程多出必要步骤(如必须查看说明) | 筛选特定行为模式用户 | 漏斗各环节流失率分析 | 路径步骤数量对齐 |
| 冷却机制筛选 | 实验组活跃用户更快进入冷却期(前文详述案例) | 流失高价值用户 | 新老用户分层验证 | 首次触发计数法 |
| 兼容性排除 | 实验组采用新技术(如WebGL)自动排除部分用户 | 年轻用户占比虚高 | 用户属性分布检验 | 技术方案兜底机制 |
| 时序性筛选 | 实验组先上线,对照组延迟部署 | 早期采纳者过度代表 | 每日新增用户比例监控 | 影子发布同步机制 |
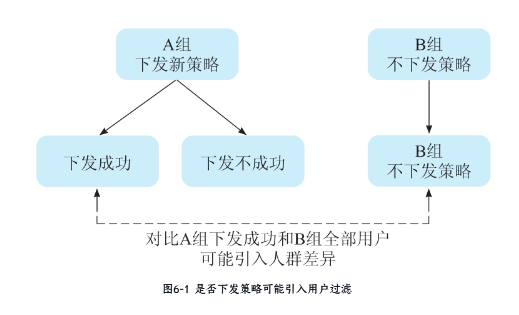
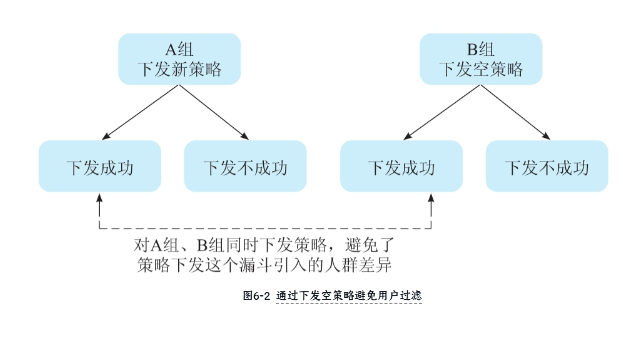
经典错误场景:
- A组(实验组)下发新策略,但仅用“下发成功”的用户对比B组(对照组)全部用户
- 结果:A组因下发失败损失部分用户→比例失衡
正确做法:对照组下发空策略,确保用户过滤条件一致
3️⃣ 数据处理阶段:机器人过滤陷阱
微软案例:
- 为降低噪声,过滤50%的机器人流量
- 副作用:误删高活跃用户→实验组用户分布失真
- 教训:过滤规则需谨慎验证,避免关联用户行为特征。
三、SRM计算与问题定位四步法
1️⃣SRM指标计算
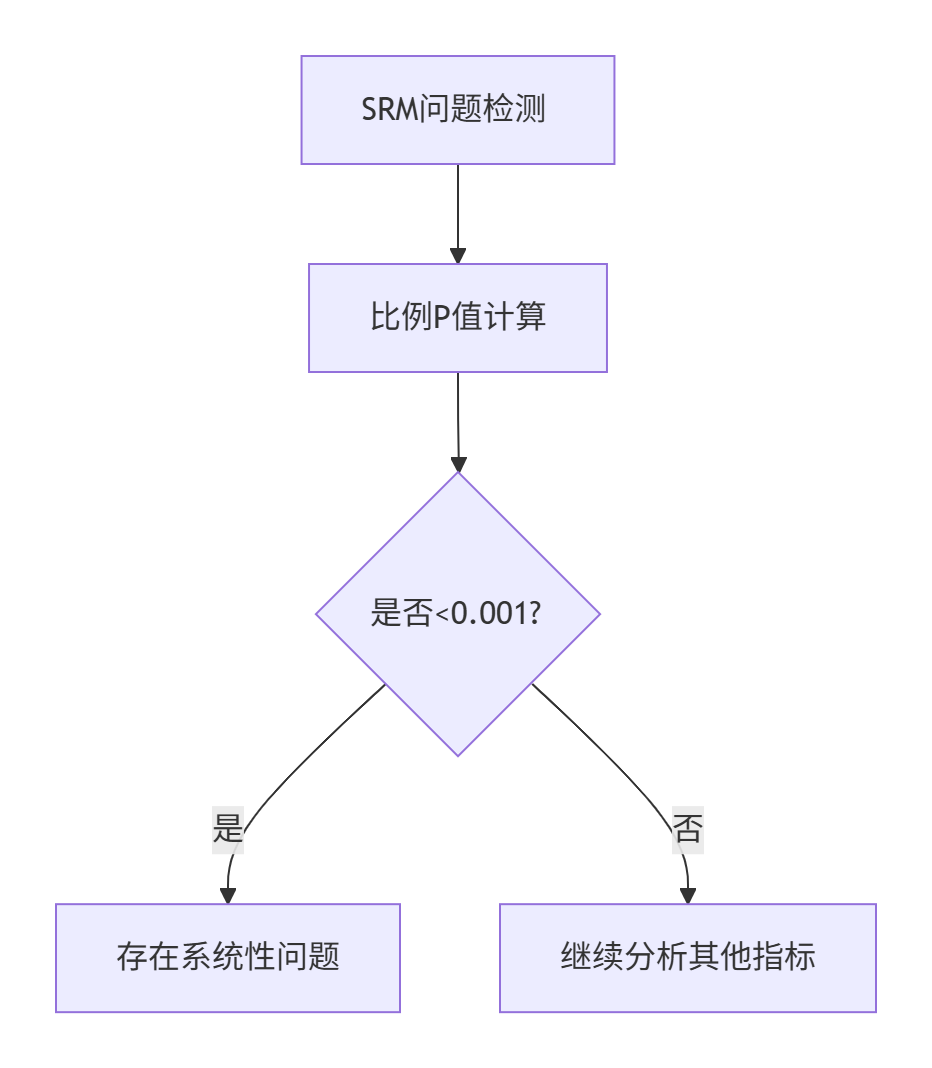
实验参数:
- 预期比例:实验组/对照组 = 50%:50%
- 实际观测:
- 实验组 = 445,000
- 对照组 = 450,000
- 总用户量 = 895,000
计算步骤:
-
实际比例计算。
实际比例 = 445,000 / 895,000 ≈ 0.4972 (49.72%) -
标准差计算。
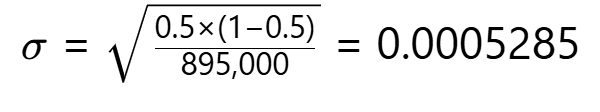
-
Z值计算。
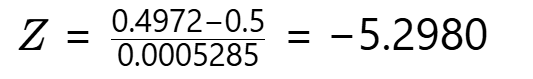
-
P值判定。查标准正态分布表:Z=-5.298 → P≈1.17×10⁻⁷,相当于百万分之0.117的概率
关键结论
-
判断标准:P值 < 0.001 → 存在SRM问题(系统错误);P值 ≥ 0.001 → 比例差异可接受。
-
案例解读:观测P值=1.17×10⁻⁷ << 0.001,结论:实验存在严重分流异常
2️⃣SRM问题定位
核心思路:从随机化流程、时间同步性、细分维度、外部干扰等多角度排查,优先解决根本性分配问题,必要时重启实验。
1. 检查随机化点上游的一致性
确保实验变量(如促销方案)在随机化点之前未被提前暴露(例如,若在结账页测试优惠,主页不得提前提及相关选项)。
若上游存在差异,需从更早的用户接触点开始分析。
核心原则:确保用户接触实验策略前无差异
典型案例:电商结账页实验
- 错误做法:在结账页展示"五折VS买二送一"选项 → 但首页已展示促销广告
- 后果:用户提前被广告影响 → 实验组涌入更多价格敏感用户
- 数据表现:P值=0.00003 → SRM报警
组别 用户量 优惠敏感用户占比 实验组 51,000 68% 对照组 49,800 52%
✅ 修正方案:从首页开始分流,保证所有用户首次接触信息的时机一致
2. 验证变量分配机制
确认用户是否在数据流水线顶端正确随机化(如基于用户ID)。
检查系统是否因并发实验或隔离组导致分配逻辑复杂化(如不同实验流量冲突)。
常见陷阱:动态标签更新导致组间泄漏
案例:招聘平台沉睡用户召回实验
- 实验设计:对"求职信息不全"用户推送激励
- 错误机制:用户补齐信息后自动移除"沉睡用户"标签
- 污染路径:

- 数据异常:第1周组间比例正常(50.1%:49.9%),第2周比例失衡(45.3%:54.7%)
🔥 解决方案:实验启动时冻结用户标签状态
-- 分析时使用快照数据
SELECT *
FROM experiment_data
WHERE snapshot_time = '2023-06-01 00:00'3. 检查实验组/对照组的初始同步性
确保所有组同时启动,避免因延迟(如缓存预热、网络延迟、分批推送)导致样本比例失衡。
特别注意追加实验组的情况(易与原有组别产生SRM问题)。
典型问题:实验组延迟启动导致样本偏移
案例:外卖APP会员涨价实验
- 执行过程:
组别 启动时间 当日时段 对照组 8:00 AM 早高峰(白领为主) 实验组 2:00 PM 下午茶(学生为主) - 用户差异:
用户类型 对照组占比 实验组占比 白领 72% 38% 学生 18% 55% - 后果:付费率差异被错误归因 → 实验结论失效
✅ 规避方案:采用影子发布机制(两组同时部署策略,但实验组暂不生效)
4. 细分市场与时间维度分析
按天检查:是否存在某天流量比例异常(如人为调整实验流量、其他实验干扰)。
按用户分层:对比新用户/老用户、不同渠道等细分市场的样本比例是否均衡。
三步分析法:
def diagnose_srm(data):# 1. 日期维度date_check = data.groupby('date')['group_ratio'].std() > 0.02# 2. 用户维度user_check = data.groupby('user_segment')['group_ratio'].apply(lambda x: abs(x.mean()-0.5)>0.05)# 3. 实验交叉exp_check = data.groupby('other_exp_id')['group_ratio'].var() > 0.01return date_check, user_check, exp_check实战案例:社交平台推荐算法实验
- 全局数据:SRM报警(P=0.0004)
- 细分排查:
维度 实验组比例 问题定位 新用户 49.8% ✓ 老用户 46.1% → 老用户显著失衡 结合实验B 61.2% → 交叉实验流量抢夺 - 根因:同时运行的实验B对老用户定向引流 → 实验样本被劫持
5. 交叉实验影响评估
实验组与对照组在其他实验中的流量占比应相似,若差异显著,可能存在流量争夺或分配冲突。
6. 判断是否可修复或需重跑实验
可修复情况:如数据污染(机器人流量)可通过清洗调整。
需重跑实验:若SRM源于流量分配等系统性问题,需重新设计实验。
四、如何避免SRM问题?
- 必做SRM测试:每次实验首看用户比例P值
- 关键防护措施:
- 对照组下发空策略而非无策略
- 动态属性(如用户状态)需在实验开始前快照固定
- 定期审计:实验平台升级后,需重新验证分流稳定性
💡 最后忠告:SRM是实验的“心电图”,P值异常=实验“心肌梗塞”!不解决SRM,所有指标都是空中楼阁。
附1:SRM计算工具(Python示例)
from scipy import stats
def check_srm(control_count, treatment_count, expected_ratio=0.5):total = control_count + treatment_countobs_ratio = treatment_count / totalstd_error = (expected_ratio*(1-expected_ratio)/total)**0.5z_score = (obs_ratio - expected_ratio)/std_errorp_value = stats.norm.sf(abs(z_score))*2 # 双侧检验return p_value# 示例:对照组445,000 vs 实验组450,000
print(check_srm(445000, 450000)) # 输出1.17e-07 → SRM警报!附2:残留效应典型案例解析——电商平台"个性化推荐"实验
一、实验背景
某头部电商平台进行为期3个月的推荐算法迭代实验:
- 实验组A:新神经网络推荐算法
- 对照组B:原协同过滤算法
- 分流比例:50%:50%(各500万用户)
二、残留效应发生过程
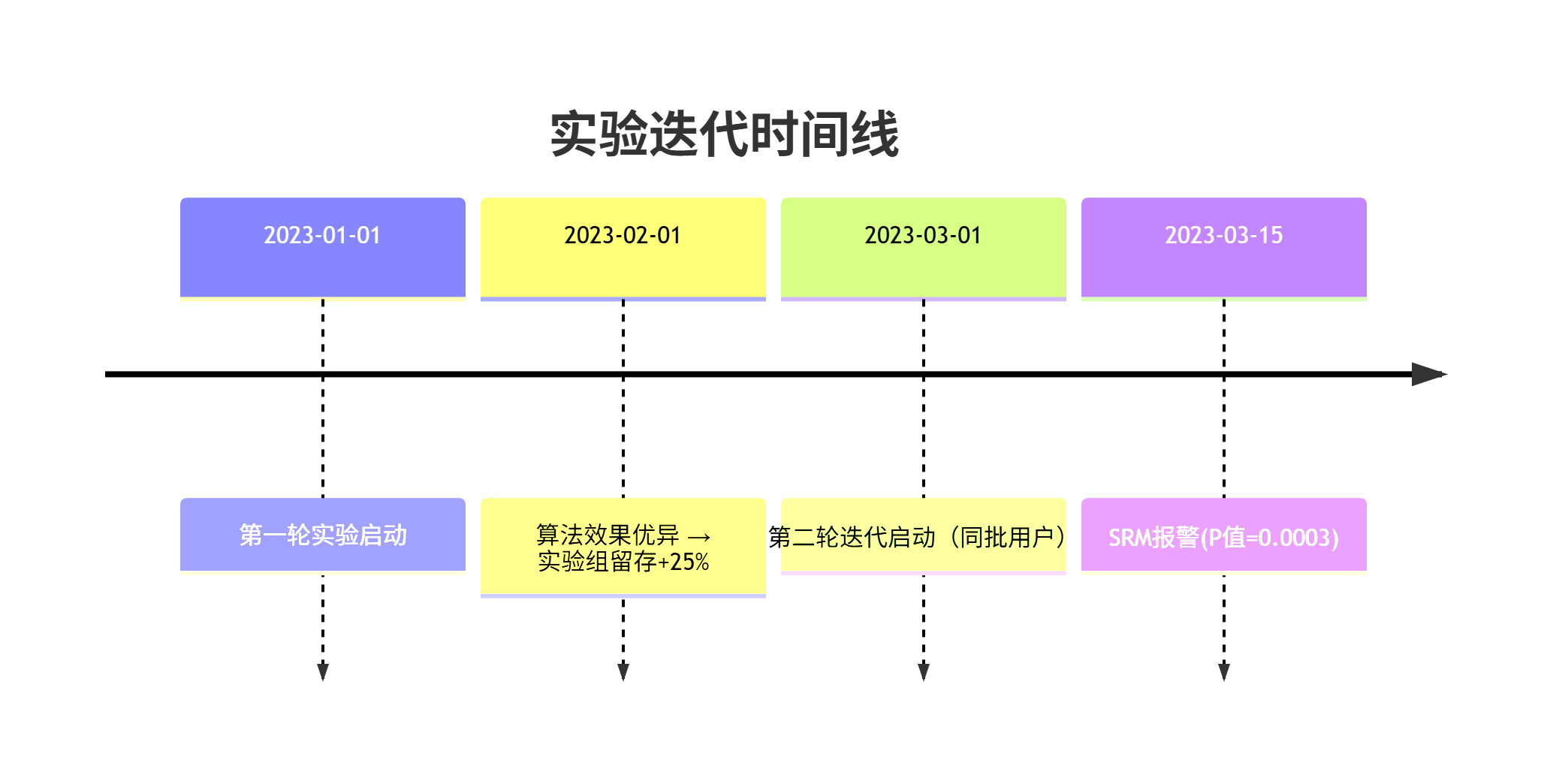
三、具体异常表现
| 指标 | 预期值 | 实际观测值 |
|---|---|---|
| 实验组用户量 | 500万 | 487万 |
| 对照组用户量 | 500万 | 513万 |
| 日活用户比例偏差 | 0% | +6.2% |
四、根本原因分析
-
行为改变链:
- 实验组用户因推荐更精准 → 购买频次提高 → 更快达到"高价值用户"阈值
- 系统自动将高频用户移出实验池(防过度营销策略)
-
数据污染路径:
# 平台用户分层逻辑(问题代码) if user.total_orders > 10: # 月订单>10即被标记为高价值remove_from_experiment() # 退出AB实验# 实验组用户因算法优秀,平均23天达到阈值 # 对照组用户平均需57天达到阈值 -
残留效应验证:
- 对比首次参与实验的新用户:组间比例保持50.1%:49.9%
- 老用户:实验组比例降至48.3% → 证实为行为改变导致
五、解决方案与效果
-
临时措施:
-- 分析时排除高价值用户影响 SELECT * FROM experiment_data WHERE user_value_tier != 'high'效果:SRM报警解除(P值回升至0.12)
-
永久修复:
- 实验期间冻结用户分层规则
- 建立实验专用用户池隔离机制
-
业务影响:
指标 修复前结论 修复后真实结论 留存率提升 +18% +22% GMV贡献 +14% +19%
六、经验总结
-
残留效应三特征:
- 多轮实验叠加时出现
- 前序实验改变用户行为轨迹
- 表现为实验组用户"异常消失"
-
检查清单:
- ✅ 实验间用户流向监控
- ✅ 关键行为阈值冻结
- ✅ 新旧用户分层分析
💡 这个案例告诉我们:实验效果太好也可能是灾难的开始。就像给运动员服用特效药后,如果不调整测试标准,会误判其真实体能水平。
附3:触发前状态偏差案例与解析
一、概念本质
触发前状态偏差是指因代码执行顺序不合理,导致系统在判断用户是否属于实验组之前,就因其他条件排除了部分用户,从而造成实验组和对照组比例失衡的现象。
二、案例(信息流小部件实验)
实验设计目标:
- 测试交叉推广小部件对用户行为的影响
- 实验组:展示小部件
- 对照组:不展示小部件
- 冷却规则:用户看到小部件≥2次或点击1次后进入冷却
三、错误代码逻辑分析
# 原始错误代码
if user in cool_off: # 第一层判断:冷却状态no_widget()
elif user in control: # 第二层判断:实验分组no_widget()
else:show_widget()问题发生机制:
-
活跃用户陷阱:
- 实验组活跃用户 → 更快触发冷却条件(看到2次/点击1次)
- 冷却后直接跳过后续所有判断 → 不再计入实验组用户统计
-
数据失真过程:
用户类型 实验组用户数 对照组用户数 初始分流 50,000 50,000 3天后活跃用户 12,000进入冷却 无变化 有效统计用户 38,000 50,000 比例偏差 43.2% 56.8% -
统计学影响:
- 计算得P值=0.00017(远小于0.001)
- 置信度>99.9%存在SRM问题
四、解决方案原理
# 修正后代码
if user in control: # 第一层判断:实验分组no_widget()
elif user in cool_off: # 第二层判断:冷却状态no_widget()
else:show_widget()-
保证用户计数:
- 先判断分组 → 所有实验组用户都被标记
- 冷却状态仅影响是否展示,不影响用户归属统计
-
数据对比:
指标 错误代码 修正代码 实验组统计完整性 76% 100% SRM P值 <0.001 0.412
五、业务影响模拟
假设小部件真实效果:
- 日活用户留存率提升:+15%
- 信息流浏览时长提升:+8%
错误分析结果:因活跃用户被过滤 → 测得留存率仅+9%,结论:低估真实效果40%。
六、通用检测方法
-
代码审查清单:
- ✅ 分组判断是否在最外层
- ✅ 状态判断是否影响用户计数
- ✅ 冷却/过滤条件是否独立统计
-
数据验证指标:
-- 检查实验组用户流失率 SELECT COUNT(DISTINCT CASE WHEN group='treatment' THEN user_id END) as treatment_total,COUNT(DISTINCT CASE WHEN group='treatment' AND is_cooled=1 THEN user_id END) as treatment_cooled FROM experiment_users
七、延伸思考
为什么开发者容易犯这个错误?
- 直觉认为"先过滤无效用户更高效"
- 忽视实验数据分析的特殊性(需要保证分母完整)
- 冷却机制与实验机制耦合过紧
💡 关键认知:在AB测试中,用户分组标记的优先级必须高于所有业务逻辑判断,这是与常规功能开发最本质的区别。