秋招笔记-8.12
我决定从今天开始,在每天的学习内容中加入算法的内容,大致分布时间的话,假设我一天可以学习八个小时,那算法两个小时,八股三个小时,项目三个小时这样的分布差不多吧。之所以还是需要做做笔试一是为了应对面试时一些基本的可能需要写的东西,二是太久没写了感觉算法思想这一块有点遗失了啊。
算法
我们大体上分为两个部分吧,一部分当然是去做新题,另一部分则是去回顾一下以前写的老题。
新题的话,我们就按照灵茶山题单的内容来:
今天我们来做常用数据结构这个部分的题,这里介绍了这些数据结构:
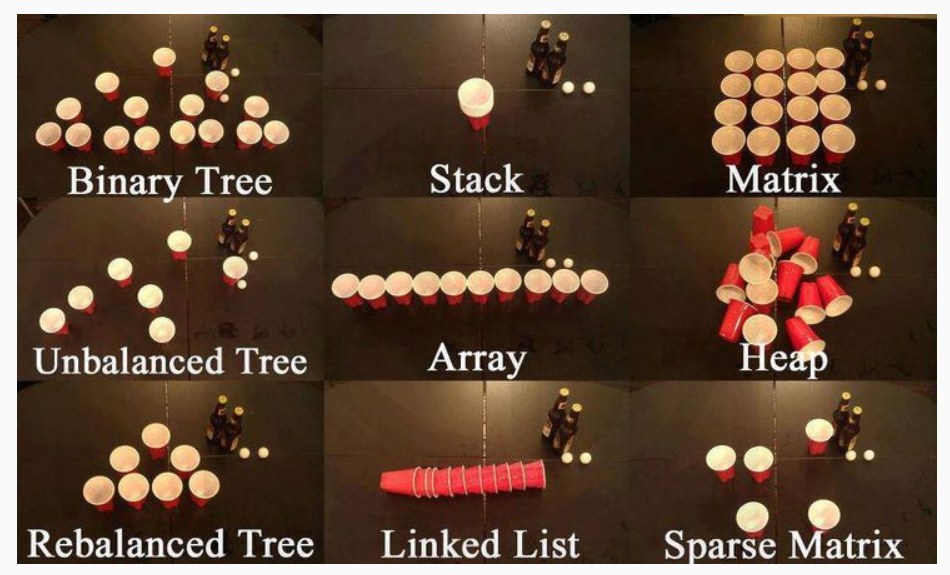
分别是二叉树,栈,矩阵,不平衡树,数组,堆,平衡树,链表和稀疏矩阵。
大家可能不太熟悉的就是我们的稀疏矩阵的概念,大体上来说其实就是矩阵中的元素大多数是0的矩阵就可以称为稀疏矩阵。
然后我们开始学习枚举的使用方法:
第一种是针对双变量问题,我们可以把其中一个变量用枚举变量表示来将双变量问题转换成单变量问题。
我们拿最经典的两数之和来介绍:
1. 两数之和 - 力扣(LeetCode)
class Solution {
public:vector<int> twoSum(vector<int>& nums, int target) {for (int i = 0; ; i++) { // 枚举 ifor (int j = i + 1; j < nums.size(); j++) { // 枚举 i 右边的 jif (nums[i] + nums[j] == target) { // 满足要求return {i, j}; // 返回两个数的下标}}}// 题目保证有解,循环中一定会 return// 所以这里无需 return,毕竟代码不会执行到这里}
};这其实就是一种利用枚举将双变量问题转成单变量问题的思路体现。
2001. 可互换矩形的组数 - 力扣(LeetCode)

class Solution {
public:long long interchangeableRectangles(vector<vector<int>>& rectangles) {int size = rectangles.size();long long ans = 0;map<double,int>cnt;for(int i = 0; i < size; i++){double ratio = 1.0 * rectangles[i][0] / rectangles[i][1];cnt[ratio]++;} for(map<double,int>::iterator it = cnt.begin(); it != cnt.end(); it++){ans += 1LL * (it -> second) * (it -> second - 1) / 2;}return ans;}
};
两个要注意的点是,一是要用double存宽高比不然值是错误的,而是直接利用组合数公式能够快速从哈希表中得到每个宽高比的组合数总和。
1128. 等价多米诺骨牌对的数量 - 力扣(LeetCode)

class Solution {
public:int numEquivDominoPairs(vector<vector<int>>& dominoes) {int ans = 0;int cnt[10][10]{};for (auto& d : dominoes) {auto [a, b] = minmax(d[0], d[1]); // 保证 a <= bans += cnt[a][b]++;}return ans;}
};这个题解最大的特点就是使用了minmax这个函数,其核心作用是同时返回两个值中的最小值和最大值,并以 std::pair形式返回结果,其中 first为最小值,second为最大值,这样我们可以直接获取到最小值和最大值之后进行比对即可。
3623. 统计梯形的数目 I - 力扣(LeetCode)

class Solution {
public:int countTrapezoids(vector<vector<int>>& points) {const int MOD = 1e9+7;unordered_map<int, int> cnt;for (auto& p : points) {cnt[p[1]]++; // 统计每一行(水平线)有多少个点}long long ans = 0, s = 0;for (auto& [_, c] : cnt) {long long k = 1LL * c * (c - 1) / 2;ans += s * k;s += k;}return ans % MOD;}
};利用哈希表统计每条水平线(相同 y 坐标)上的点数,计算每条水平线上可形成的点对组合数,随后遍历所有水平线,将当前水平线的组合数与此前所有水平线的组合数累积总和相乘,得到当前水平线与历史水平线组合形成的梯形数量,并累加到结果中。
3371. 识别数组中的最大异常值 - 力扣(LeetCode)

class Solution {
public:int getLargestOutlier(vector<int>& nums) {unordered_map<int, int> cnt;int total = 0;for (int x : nums) {cnt[x]++;total += x;}int ans = INT_MIN;for (int x : nums) {cnt[x]--;if ((total - x) % 2 == 0 && cnt[(total - x) / 2] > 0) {ans = max(ans, x);}cnt[x]++;}return ans;}
};这个题的本质其实也是两数之和,我们把数组分成三部分,一部分是异常值,一部分是其他数的总和,一部分是特殊数字,我们获取一个总和,然后在哈希表中假设每个值都是异常值,总和去掉这个值的总和可以整除以2并且在哈希表中存在这样的值就满足条件。
1010. 总持续时间可被 60 整除的歌曲 - 力扣(LeetCode)

class Solution {
public:int numPairsDivisibleBy60(vector<int> &time) {int ans = 0, cnt[60]{};for (int t : time) {ans += cnt[(60 - t % 60) % 60];cnt[t % 60]++;}return ans;}
};看起来似乎有些抽象,但其实就是假如time[i]对60取余之后假如是1的话,就去找数组中对60取余后值为59的值的个数即可。
八股
这个部分我们主要针对的内容就是语言(C++,C#)计算机基础(计网,操作系统)游戏引擎(Unity和UE)以及渲染和物理引擎,看起来量确实很大,但其实我们在项目中花费的时间本身也是在补习相关的八股,比如当我们回顾Unity的项目时实际上也是在复习Unity的八股,所以这里我决定把游戏引擎、渲染和物理的部分去除掉,也就是这三个小时只看语言和计算机基础相关的知识。
很多知识都是翻来覆去地看的,重复性很高。
C++:
在main函数之前执行的内容有哪些?
在进入 main 之前,系统/加载器先创建进程、映射可执行文件与依赖库、设置栈指针和初始栈(含 argc/argv/environ),并完成动态链接重定位;随后由 C 运行时入口(如 _start/CRT)接管,依次把 .bss 清零、把 .data 初值从镜像拷贝到内存(而编译期常量通常直接放在 .rodata,无需运行时代码初始化),初始化运行库与线程/TLS 等环境,然后按顺序调用预初始化与初始化数组中的函数(其中包含用 __attribute__((constructor)) 标记的构造器);上述步骤完成后才跳转进入 main。
更直白的话语是:在进入 main 之前,系统先把程序装进内存并把栈支好;接着把全局/静态变量就位:没写初值的清零,带初值的从镜像拷到内存,而编译期常量直接放在只读区不用再跑代码;然后把运行库等环境准备好,按顺序调用你标了 constructor 的初始化函数,做完这些才开始执行 main。
结构体内存?
每个成员的起始偏移必须是其类型对齐要求(由平台/ABI规定,通常为2的幂,可能小于、等于或大于成员大小)的整数倍;结构体自身的对齐要求等于其所有成员对齐要求的最大值,结构体的起始地址也要满足这个对齐;为保证结构体数组元素都正确对齐,sizeof(struct) 会向上补齐到该最大对齐的整数倍(因此成员间或末尾可能有填充);编译器/ABI设置如 #pragma pack、__attribute__((packed))、alignas(N) 可降低或提高对齐,从而改变布局与大小。
为什么需要内存对齐?
内存对齐的本质是让CPU“对得上口径、一次拿全、少出事”:很多硬件规定数据要放在某个边界上,不对齐可能直接报错;即便能访问,也常要拆成两次读写、可能跨缓存行/页,变慢还更耗能;按对齐放可以让CPU一次就把需要的字节整块取到,速度更稳、开销更小。
指针和引用的区别?
这个已经说了很多次了,但这里我补充一下就是sizeof的用法:sizeof(指针变量)得到的是指针本身的大小(与指向什么无关,大小随平台如32位4字节、64位多为8字节);而sizeof(引用)得到的是被引用类型的大小,因为引用只是别名没有“自身大小”;若想得到指针所指对象的大小应写sizeof(*p)(不会真的解引用);另外通过引用不会发生数组衰减,所以对“数组的引用”做sizeof会得到整个数组的大小。
那我们再详细地介绍一下sizeof的用法:
sizeof 可用于类型或表达式,返回字节数且不求值表达式;对指针得到指针本身大小(与指向类型无关,想要对象大小用 sizeof(p));对引用得到被引用类型大小;对“真数组对象”(局部/全局、结构体成员、数组引用)得到整个数组的字节数,但函数形参写成 T a[] 会退化为 T,在函数体内 sizeof(a) 仅是指针大小;字符串字面量包含结尾 '\0',如 sizeof "abc" 为 4;动态分配得到的是指针,sizeof 也只给指针大小。
传递函数参数时传指针和传引用有何区别?
在 C++ 里,传引用像给形参起“别名”:语法自然(无需取址/解引用)、不能为 null、绑定后不可改绑(不能指向别处),可用 const 控制只读,且 const 引用能绑定临时对象;传指针则要取址调用、函数内需解引用,指针可为 null(需判空)、可改指向别的对象,适合表示“可选/输出参数”、与数组迭代和指针运算相关的场景;语义上引用用于“必须存在的别名”,指针用于“可空/可重绑定/数组”;性能通常等价,涉及所有权请用智能指针表达。
具体传参的时候怎么传呢?对小而可拷贝的标量(如 int、double、指针)直接按值传;想只读大对象且避免拷贝用 const T&;需要修改且参数“必须存在”用 T&;参数是“可选的/可能为 null”或需要能改指向时用 T(只读则 const T);输出参数优先用返回值,确需多输出时:必定产出用 T&,可选产出用 T;要转移/表达所有权用 std::unique_ptr 按值传(或 std::shared_ptr 表示共享);需利用移动语义接收右值用 T&&;简单记忆:引用表示“非空别名、不可改绑”,指针表示“可空、可改绑、也常用于数组/迭代”。
new的几种用法?
是的,又是这个问题。
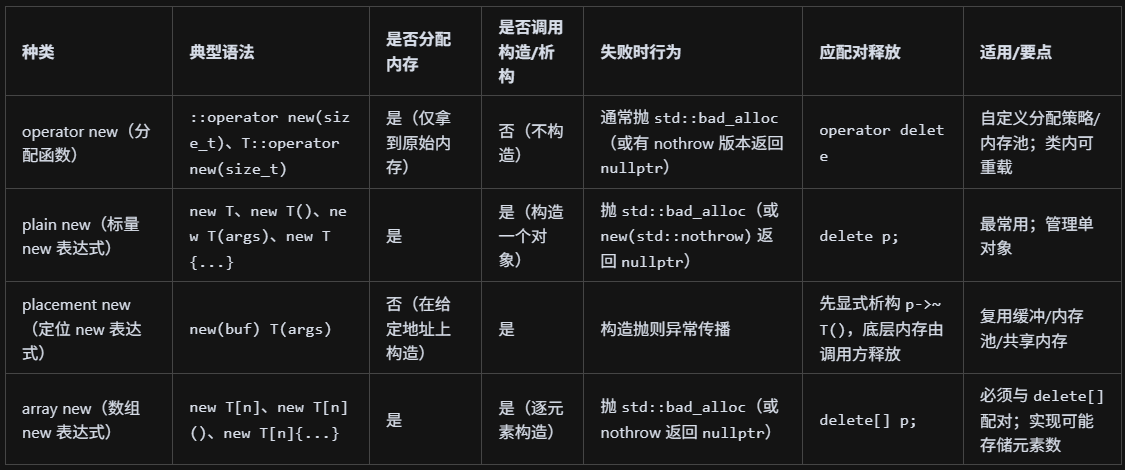
这里补充一下这个opertator new这个东西:operator new是“名为 operator new 的分配函数”,而不是你平常理解的“把某个运算符重载成自定义语义”的那个“新运算”;new 是一个“new 表达式”(关键字语法),它会先选择并调用相应的分配函数 operator new/operator new[](可能是全局的也可能是类内重载的)取得原始内存,然后在这块内存上调用构造函数。
变量的声明和定义的区别?
声明是“告诉编译器有个名字及其类型/链接”,通常不分配存储、可多次出现;定义是“真正落地创建实体”,会分配存储并可初始化,在给定链接下只能有一次(一次定义规则)。所有定义都是声明,但并非所有声明都是定义。块内的int x;既是声明也是定义;文件作用域下不带extern的一般是定义,带extern且无初始化的是声明,带初始化的不管是否写extern都是定义。
extern int g; // 声明(不分配存储)
int g; // 定义(分配存储)
int g2 = 0; // 定义(并初始化)
extern int g3 = 1; // 定义(有初始化即为定义)
static int s; // 定义(内部链接)
void f(int); // 函数声明
void f(int x) {} // 函数定义什么是顶层const和底层const?
顶层 const是修饰“对象本身”的不可变(如int const x;、T* const p),限制你不能通过这个名字改值或改指向,但按值拷贝/传参会丢弃顶层 const;底层 const是修饰“经由指针/引用所指向的对象”的不可变(如const T* p、const T& r),它参与类型系统与重载,禁止通过该指针/引用改内容,允许T* -> const T*的加 const 转换而不允许反向;快速判断:从右往左读,紧贴星号的 const 多为顶层(T* const),紧贴基本类型的 const 多为底层(const T*),两者可同时存在(const T* const p)。
数组名和指针的区别?
数组名不是指针:它是“数组类型的表达式名”,在大多数表达式中会自动衰减为指向首元素的指针(T),但在用作 sizeof、&(以及 _Alignof)操作数时不衰减;数组名不可赋值、不可自增自减,指针变量可以重指向和运算;sizeof(数组名)得到整个数组的字节数,而 sizeof(指针)只得指针大小;函数形参写成 T a[] 实际等同 T,在函数体内 sizeof(a)就是指针大小,所以只有在“真数组”仍未衰减的作用域里(如局部/全局数组、结构体里的数组成员,用作 sizeof 的操作数)才能用 sizeof(a)/sizeof(a[0])算元素个数;另需区分 &a 的类型是 “指向整个数组的指针”(T ()[N],步进按整块),而衰减后的 a 是 T(步进按单元素)。
final和override关键字的作用是什么?
override 用在派生类的虚函数上,声明“这是对基类同名虚函数的覆盖”,并让编译器强制校验签名完全匹配(否则报错);final 用来“封死扩展”,加在虚函数上表示此函数到本类为止不能再被重写,加在类上表示该类不能被继承;二者可组合写成 “override final”,既确认确实在重写,又禁止后续再重写;简言之:override是“意图校验”,final是“继承/重写限制”。
拷贝初始化和直接初始化有何区别?
类对象的拷贝初始化(T x = expr)只使用“可隐式”的构造/转换把 expr 变成 T;若 expr 已是 T/派生则走拷贝/移动构造,explicit 在此不参与;直接初始化(T x(args) 或 T x{args})在构造函数中做重载决议,允许选择 explicit,花括号还优先匹配 initializer_list 并做窄化检查;T x = {…} 是“拷贝列表初始化”,沿用花括号规则但 explicit 仍不参与;因此 explicit 的作用就是禁止隐式转换与拷贝初始化,强制使用直接初始化或显式转换,避免意外转换与重载歧义。
explict关键字的作用?
explicit 用在“转换构造函数”和“类型转换运算符”上,用来禁止隐式转换和拷贝初始化(T x = a),从而只能通过直接初始化或显式转换(T x(a)/T x{a}/static_cast)调用;它主要用于防止单参(或等效单参)构造带来的意外自动转换与重载歧义;C++11 起可用于转换运算符,C++20 起支持 explicit(bool) 按条件禁用隐式转换。
如何理解转换构造函数?
转换构造函数指能用单个实参(含默认参数凑成单参)把“其他类型的值”直接构造成本类对象的构造函数,即定义“其他类型 → 本类”的转换;若未加 explicit,它可在赋值、传参、表达式中被隐式调用参与重载决议(如 T x = a、f(a) 自动把 a 转成 T),加了 explicit 则只能用于直接初始化或显式转换(如 T x(a)、static_cast<T>(a)),从而避免意外的自动转换;与之相对,“本类 → 其他类型”的转换由类型转换运算符 operator U() 实现。
如何理解命名遮蔽?
基类函数非虚时,派生类若声明同名同签名成员,只是“名字隐藏”并重新定义了一个新函数;对派生对象调用命中派生版本,经由基类指针/引用调用仍静态绑定到基类版本,需用限定名 Base::f() 指明基类;基类函数为虚时,派生类写出同名同签名成员(即使不写 override)就是“重写”,经由基类指针/引用会虚派发到派生,写 override 只是做匹配校验;一旦签名不完全相同,就不会重写而是触发“名字隐藏”,把基类该名字下的所有重载都遮蔽,需要 using Base::f; 把基类重载带回,或用 Base::f(args) 指名调用;若想禁止派生重写,则在基类虚函数上标注 final。
比如:
C++中的继承权限?
public 继承会把基类的 public 保持为 public、protected 保持为 protected(base 的 private 仍继承但不可直接访问);protected 继承会把基类的 public 和 protected 都变成派生类中的 protected;private 继承会把基类的 public 和 protected 都变成派生类中的 private(基类的 private 一直不可直接访问)。
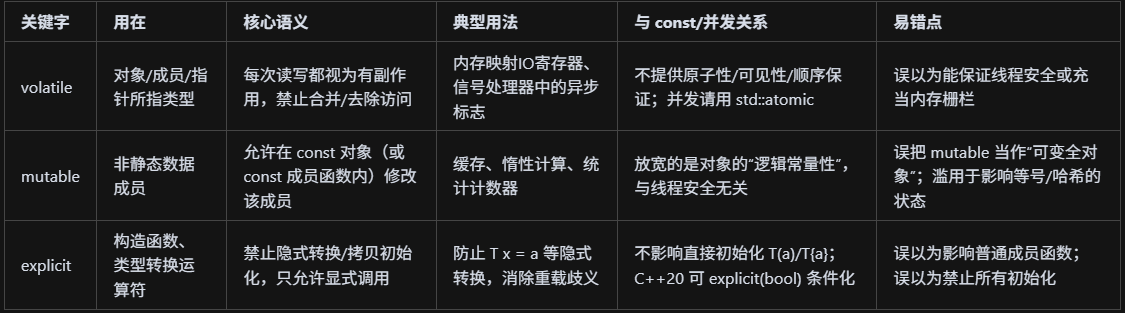
volatile、mutable和explicit关键字的用法?
volatile 是“别优化掉、每次都去真内存”的读写限定(用于硬件寄存器/异步修改,不是并发同步);mutable 是“即使对象是 const,这个成员也允许改”的成员修饰(常做缓存,不涉及线程安全);explicit 用在构造函数/转换运算符上,禁止隐式转换,只允许显式构造/转换,避免误用与歧义。
计算机网络:
DNS域名解析以什么协议为主?为什么?
DNS以UDP/53为主,因为无需建连、开销小、延迟低,且大多数查询/响应很小,单个往返包就能完成,便于高并发;但在响应过大被截断(TC 置位)、区域传送(AXFR/IXFR)或需更可靠传输时会改用TCP/53。(这里的53是端口号)
什么是区域传送?
区域传送就是权威DNS服务器之间同步同一域名“电话簿”的过程:主服务器把该域的所有记录一次性整本复制给从服务器(AXFR,全量),或只把最近改动的部分给它(IXFR,增量),通常用 TCP/53 传输以确保可靠;它只发生在授权的权威服务器之间。
DNS负载均衡是什么?
当客户端解析域名时,调度/权威 DNS 按策略(轮询、权重、就近、健康状况)从同一域名配置的多条 A/AAAA 记录里选择并返回一个或一组 IP,客户端据此直连其中一个 IP,从而把不同用户分散到不同服务器。
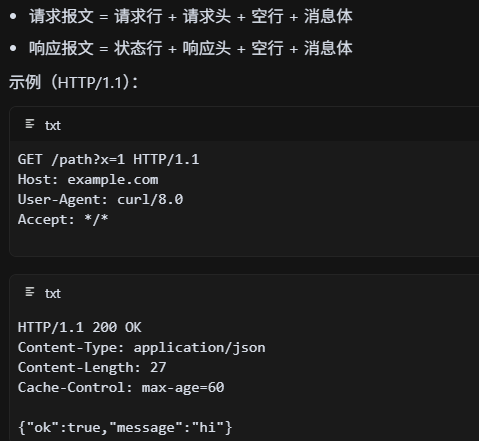
HTTP请求和响应报文的字段有哪些?
什么是ARP和RARP?
ARP 做 IP→MAC,RARP 做 MAC→IP地址的转换。
HTTP是安全的吗?
完全不是,HTTP协议的报文是明文传输,别人只要抓包后就能获取所有传输的数据,要安全性就使用HTTPS。
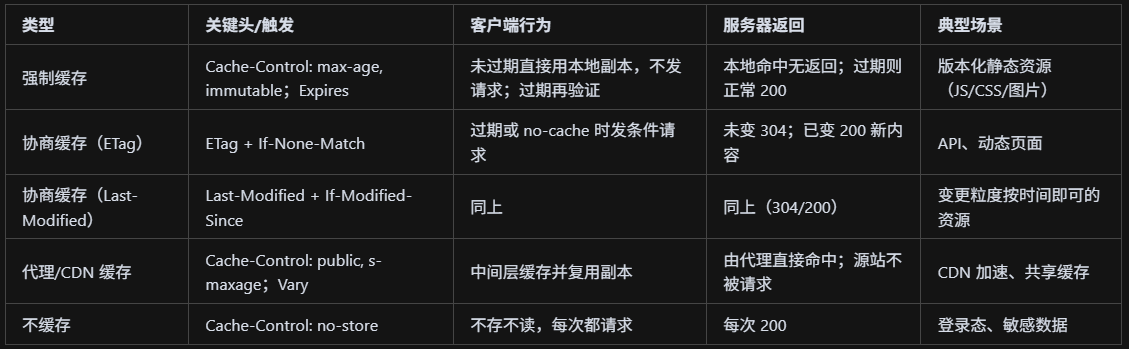
还记得HTTP中的缓存方案吗?
HTTP 缓存主要分两类:强制缓存(命中直接用本地,不发请求)和协商缓存(带条件请求,未变化返回 304);核心头包括 Cache-Control/Expires 控制时效,ETag/If-None-Match 与 Last-Modified/If-Modified-Since 判断是否变化,配合 Vary、public/private、s-maxage 等用于浏览器与代理/CDN。
TCP的封包和拆包是什么?
TCP 是字节流无消息边界的协议;“封包”是指应用层在发送前给每条消息加上可解析的边界(如固定长度、长度前缀、分隔符或帧/TLV),再写入 TCP;“拆包”是接收端从连续字节流中按这些边界还原出一条条完整消息,以处理粘包/半包(一次读到多条或不完整)的情况。