windows单机单卡+CIFAR-10数据集+Docker模拟训练
一:基础环境介绍
系统版本:windows11 x64
GPU:NVIDIA GeForce RTX 4050
GPU_DRIVE:572.40
CUDA:未安装
Docker:28.3.2
二:使用的镜像的Dockerfile(按需修改)
备注:rdma-ofed驱动安装部分可以去掉,单机单卡场景不使用roce和ib,并且非H系列和A系列机器不需要安装,这里windows电脑更不需要安装。
FROM nvidia/cuda:12.4.1-cudnn-runtime-ubuntu22.04 ## 基础镜像# 环境变量 ENV DEBIAN_FRONTEND="noninteractive" \TZ="Asia/Shanghai" \PYTHON_VERSION="3.10.18" \OFED_VERSION="5.8-7.0.6.1" \OFED_SHA256="5c584ec09ca991e2c17aacd73a8a6d9db83f83873575ae49008bb2876e3bc2f8"# 添加编码环境变量LANG="C.UTF-8" \LC_ALL="C.UTF-8" \PYTHONIOENCODING="utf-8"# 安装系统依赖包和工具 RUN set -eux; \apt-get update && \apt-get install -y --no-install-recommends \# 基础工具jq tar zip unzip gzip vim curl wget tree \debconf-utils tzdata ca-certificates \# 编译工具链gcc-11 g++-11 make build-essential \# 网络和安全工具openssl openssh-server \# Python 环境(保留 2.7 用于 OFED 安装)python3.10 python3.10-dev python3.10-venv \python3-pip python3-wheel libpython3.10-dev \python2.7 python2.7-dev && \# 创建 SSH 运行目录mkdir -p /var/run/sshd && \# 配置编译器符号链接rm -rf /usr/bin/gcc /usr/bin/g++ && \ln -sf /usr/bin/gcc-11 /usr/bin/gcc && \ln -sf /usr/bin/g++-11 /usr/bin/g++ && \# 配置 Python 符号链接ln -sf /usr/bin/python2.7 /usr/bin/python2 && \ln -sf /usr/bin/python3.10 /usr/bin/python3 && \ln -sf /usr/bin/python3.10 /usr/bin/python && \# 配置时区ln -fs /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && \dpkg-reconfigure --frontend noninteractive tzdata && \echo "Asia/Shanghai" > /etc/timezone && \# 清理 APT 缓存apt-get clean && \rm -rf /var/lib/apt/lists/*# 安装 PyTorch(CUDA 12.4 兼容版本) RUN pip3 install --no-cache-dir \torch==2.6.0 \torchvision==0.21.0 \torchaudio==2.6.0 \tensorboard \matplotlib \--index-url https://download.pytorch.org/whl/cu124# 安装 Mellanox OFED 网络驱动(用于 RDMA 高速通信) RUN set -eux; \# 下载并验证 OFED 安装包wget --tries=3 -O /usr/local/src/MLNX_OFED_LINUX-${OFED_VERSION}-ubuntu22.04-x86_64.tgz \"https://www.mellanox.com/downloads/ofed/MLNX_OFED-5.8-7.0.6.1/MLNX_OFED_LINUX-${OFED_VERSION}-ubuntu22.04-x86_64.tgz" && \echo "${OFED_SHA256} /usr/local/src/MLNX_OFED_LINUX-${OFED_VERSION}-ubuntu22.04-x86_64.tgz" | sha256sum -c - && \# 解压安装包tar -xzf /usr/local/src/MLNX_OFED_LINUX-${OFED_VERSION}-ubuntu22.04-x86_64.tgz -C /usr/local/src && \rm -f /usr/local/src/MLNX_OFED_LINUX-${OFED_VERSION}-ubuntu22.04-x86_64.tgz && \# 安装 OFED 依赖包apt-get update && \apt-get install -y --no-install-recommends \# 核心依赖perl ethtool lsof udev pciutils kmod \libnuma1 libusb-1.0-0 libpci3 \# 网络库libmnl0 libnl-3-dev libnl-3-200 \libnl-route-3-200 libnl-route-3-dev \# 构建工具autoconf automake m4 bison flex \pkg-config libltdl-dev chrpath libelf1 \# Fortran 支持gfortran libgfortran5 \# 其他工具libfuse2 debhelper graphviz tcl tk swig dpatch \# NVIDIA 计算库libnvidia-compute-515 && \# 临时切换到 Python 2(OFED 安装器要求)rm -f /usr/bin/python && \ln -sf /usr/bin/python2.7 /usr/bin/python && \# 安装 OFED(仅用户空间,不更新固件)cd /usr/local/src/MLNX_OFED_LINUX-${OFED_VERSION}-ubuntu22.04-x86_64 && \./mlnxofedinstall --user-space-only --without-fw-update --force && \# 恢复 Python 3 为默认rm -f /usr/bin/python && \ln -sf /usr/bin/python3.10 /usr/bin/python && \# 清理安装文件和缓存cd / && \rm -rf /usr/local/src/MLNX_OFED_LINUX-* && \apt-get clean && \rm -rf /var/lib/apt/lists/*# 设置工作目录 WORKDIR /workspace# 暴露 SSH 端口 EXPOSE 22# 默认启动 bash CMD ["/bin/bash"]## 构建镜像 docker build -f Dockerfile.ubuntu22.04-cuda12.4.1-python3.10.18-pytorch2.6-gpu -t training_test:ubuntu22.04-cuda12.4.1-python3.10.18-pytorch2.6-gpu ## 镜像推送(可选,有harbor的话,后续使用的话) docker tag training_test:ubuntu22.04-cuda12.4.1-python3.10.18-pytorch2.6-gpu prod.harbor.com/ops/training_test:ubuntu22.04-cuda12.4.1-python3.10.18-pytorch2.6-gpu4docker push prod.harbor.com/ops/training_test:ubuntu22.04-cuda12.4.1-python3.10.18-pytorch2.6-gpu4三:训练相关代码
CIFAR-10数据集详细解释
CIFAR-10是计算机视觉领域最经典的图像分类基准数据集之一,由多伦多大学的Alex Krizhevsky、Vinod Nair和Geoffrey Hinton创建。
📊 数据集基本信息
数据规模
- 总图像数量:60,000张
- 图像尺寸:32×32像素(彩色图像)
- 类别数量:10个类别
- 每类图像数:6,000张
数据分割
- 训练集:50,000张图像
- 测试集:10,000张图像
- 训练集分布:分为5个batch,每个batch包含10,000张图像
- 测试集分布:每个类别正好1,000张图像
🏷️ 十个类别
类别编号 英文名称 中文名称 说明 0 airplane 飞机 各种类型的飞机 1 automobile 汽车 轿车、SUV等 2 bird 鸟类 各种鸟类 3 cat 猫 家猫、野猫等 4 deer 鹿 各种鹿类 5 dog 狗 各种犬类 6 frog 青蛙 青蛙和蟾蜍 7 horse 马 马匹 8 ship 船舶 各种船只 9 truck 卡车 大型卡车(不包括皮卡) 💡 数据集特点
1. 小尺寸图像
- 32×32像素,相对较小
- 适合快速实验和原型开发
- 对计算资源要求不高
2. 平衡数据集
- 每个类别的图像数量相等
- 避免了类别不平衡问题
3. 真实世界图像
- 图像来自80 million tiny images数据集
- 包含真实世界的复杂性和变化
4. 标准化基准
- 业界公认的测试标准
- 便于不同算法间的性能比较
🎯 为什么选择CIFAR-10?
1. 入门友好
- 数据量适中,训练时间可控
- 图像尺寸小,便于理解和可视化
- 类别清晰易懂
2. 挑战性适中
- 比MNIST复杂,但比ImageNet简单
- 适合测试各种深度学习技术
- 经典的基准测试
3. 研究价值
- 广泛用于学术研究
- 大量已发表的baseline结果
- 便于复现和比较
📈 性能基准
经典结果
- 无数据增强:18%错误率(卷积神经网络)
- 有数据增强:11%错误率
- 超参数优化:15%错误率(贝叶斯优化)
现代结果
- ResNet:~6%错误率
- 现代架构:<3%错误率
- 人类表现:约5-10%错误率
🔧 数据格式
# 数据结构 {'data': numpy.array, # 10000x3072的数组'labels': list, # 10000个标签(0-9)'batch_label': str, # batch名称'filenames': list # 文件名列表 }# 图像数据排列: # - 前1024个值:红色通道 # - 中1024个值:绿色通道 # - 后1024个值:蓝色通道🚀 在深度学习中的应用
1. 算法验证
- 新架构的初步测试
- 优化算法的效果验证
- 正则化技术的评估
2. 教学用途
- 深度学习课程的经典案例
- 从简单到复杂的过渡
- 理解卷积神经网络
3. 研究基础
- 许多重要论文都基于CIFAR-10
- 架构搜索的标准数据集
- 迁移学习的源域
🎓 学习价值
对于初学者来说,CIFAR-10是理想的选择因为:
- 快速反馈:训练时间短,可以快速看到结果
- 直观理解:图像小,容易可视化和理解
- 丰富资源:大量教程、代码和论文可参考
- 渐进学习:从CIFAR-10到ImageNet的自然进阶
🔄 与其他数据集的关系
- MNIST → CIFAR-10 → ImageNet:难度递增的学习路径
- CIFAR-100:100个类别的扩展版本
- SVHN:类似复杂度的街景数字识别
CIFAR-10就像是深度学习领域的"Hello World",既简单易懂,又具有足够的挑战性,是学习和研究计算机视觉的好起点。
(1)先在本地C盘直接创建目录training_test:
以下是目录层级:
training_test/ ├── code/ │ └── train.py 训练代码 ├── datasets/ │ └── cifar10/ 数据集 ├── logs/ │ ├── tensorboard/ 看板日志 │ └── training_logs/ 训练日志 └── output/├── checkpoints/├── models/└── results/ 训练结果(2)train.py训练用代码内容:
备注:训练用数据集会直接下载到datasets目录,也可以自己手动下载放到放到这个目录下
# -*- coding: utf-8 -*- import torch import torch.nn as nn import torch.optim as optim import torchvision import torchvision.transforms as transforms from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter import time import os import json from datetime import datetime import matplotlib.pyplot as plt# =================== 路径配置 =================== class PathConfig:# Windows路径(容器内会映射到/workspace)BASE_DIR = "/workspace"# 训练前:数据集路径DATASET_DIR = os.path.join(BASE_DIR, "datasets", "cifar10")# 训练前:代码路径CODE_DIR = os.path.join(BASE_DIR, "code")# 训练中:日志路径LOG_DIR = os.path.join(BASE_DIR, "logs", "training_logs")TENSORBOARD_DIR = os.path.join(BASE_DIR, "logs", "tensorboard")# 训练后:输出路径MODEL_DIR = os.path.join(BASE_DIR, "output", "models")CHECKPOINT_DIR = os.path.join(BASE_DIR, "output", "checkpoints")RESULT_DIR = os.path.join(BASE_DIR, "output", "results")# 确保所有目录存在 for path in [PathConfig.DATASET_DIR, PathConfig.LOG_DIR, PathConfig.TENSORBOARD_DIR, PathConfig.MODEL_DIR, PathConfig.CHECKPOINT_DIR, PathConfig.RESULT_DIR]:os.makedirs(path, exist_ok=True)# =================== 简化的ResNet模型 =================== class BasicBlock(nn.Module):def __init__(self, in_channels, out_channels, stride=1):super(BasicBlock, self).__init__()self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)self.bn1 = nn.BatchNorm2d(out_channels)self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(out_channels)self.shortcut = nn.Sequential()if stride != 1 or in_channels != out_channels:self.shortcut = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(out_channels))def forward(self, x):out = torch.relu(self.bn1(self.conv1(x)))out = self.bn2(self.conv2(out))out += self.shortcut(x)out = torch.relu(out)return outclass SimpleResNet(nn.Module):def __init__(self, num_classes=10):super(SimpleResNet, self).__init__()self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)self.bn1 = nn.BatchNorm2d(64)self.layer1 = self._make_layer(64, 64, 2, stride=1)self.layer2 = self._make_layer(64, 128, 2, stride=2)self.layer3 = self._make_layer(128, 256, 2, stride=2)self.avgpool = nn.AdaptiveAvgPool2d((1, 1))self.fc = nn.Linear(256, num_classes)def _make_layer(self, in_channels, out_channels, blocks, stride):layers = []layers.append(BasicBlock(in_channels, out_channels, stride))for _ in range(1, blocks):layers.append(BasicBlock(out_channels, out_channels))return nn.Sequential(*layers)def forward(self, x):x = torch.relu(self.bn1(self.conv1(x)))x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.avgpool(x)x = x.view(x.size(0), -1)x = self.fc(x)return x# =================== 训练管理类 =================== class TrainingManager:def __init__(self):self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")self.log_file = os.path.join(PathConfig.LOG_DIR, f"training_{datetime.now().strftime('%Y%m%d_%H%M%S')}.log")self.writer = SummaryWriter(PathConfig.TENSORBOARD_DIR)# 训练指标self.metrics = {"train_loss": [], "train_acc": [],"test_loss": [], "test_acc": [],"epochs": [], "learning_rates": []}def log(self, message):"""记录训练日志"""timestamp = datetime.now().strftime("%Y-%m-%d %H:%M:%S")log_message = f"[{timestamp}] {message}"print(log_message)# 写入日志文件with open(self.log_file, 'a', encoding='utf-8') as f:f.write(log_message + "\n")def load_data(self):"""加载CIFAR-10数据集"""self.log("Loading CIFAR-10 dataset...")self.log(f"Dataset path: {PathConfig.DATASET_DIR}")# 数据预处理transform_train = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),])transform_test = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),])# 下载并加载数据集(自动下载到指定目录)trainset = torchvision.datasets.CIFAR10(root=PathConfig.DATASET_DIR, train=True, download=True, transform=transform_train)self.trainloader = DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)testset = torchvision.datasets.CIFAR10(root=PathConfig.DATASET_DIR, train=False, download=True, transform=transform_test)self.testloader = DataLoader(testset, batch_size=100, shuffle=False, num_workers=2)self.log(f"Training samples: {len(trainset)}")self.log(f"Test samples: {len(testset)}")self.log("Dataset loaded successfully!")def create_model(self):"""创建模型"""self.log("Creating model...")self.model = SimpleResNet().to(self.device)self.criterion = nn.CrossEntropyLoss()self.optimizer = optim.SGD(self.model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)self.scheduler = optim.lr_scheduler.StepLR(self.optimizer, step_size=20, gamma=0.1)# 计算参数数量total_params = sum(p.numel() for p in self.model.parameters())trainable_params = sum(p.numel() for p in self.model.parameters() if p.requires_grad)self.log(f"Total parameters: {total_params:,}")self.log(f"Trainable parameters: {trainable_params:,}")def train_epoch(self, epoch):"""训练一个epoch"""self.model.train()train_loss = 0correct = 0total = 0start_time = time.time()for batch_idx, (inputs, targets) in enumerate(self.trainloader):inputs, targets = inputs.to(self.device), targets.to(self.device)self.optimizer.zero_grad()outputs = self.model(inputs)loss = self.criterion(outputs, targets)loss.backward()self.optimizer.step()train_loss += loss.item()_, predicted = outputs.max(1)total += targets.size(0)correct += predicted.eq(targets).sum().item()if batch_idx % 50 == 0:self.log(f'Epoch {epoch}, Batch {batch_idx}/{len(self.trainloader)}, 'f'Loss: {loss.item():.3f}, Acc: {100.*correct/total:.2f}%')epoch_time = time.time() - start_timetrain_acc = 100. * correct / totalavg_loss = train_loss / len(self.trainloader)self.log(f'Epoch {epoch} Training - Loss: {avg_loss:.3f}, Acc: {train_acc:.2f}%, Time: {epoch_time:.1f}s')return train_acc, avg_lossdef test_epoch(self, epoch):"""测试一个epoch"""self.model.eval()test_loss = 0correct = 0total = 0with torch.no_grad():for inputs, targets in self.testloader:inputs, targets = inputs.to(self.device), targets.to(self.device)outputs = self.model(inputs)loss = self.criterion(outputs, targets)test_loss += loss.item()_, predicted = outputs.max(1)total += targets.size(0)correct += predicted.eq(targets).sum().item()test_acc = 100. * correct / totalavg_loss = test_loss / len(self.testloader)self.log(f'Epoch {epoch} Testing - Loss: {avg_loss:.3f}, Acc: {test_acc:.2f}%')return test_acc, avg_lossdef save_checkpoint(self, epoch, train_acc, test_acc, is_best=False):"""保存检查点"""checkpoint = {'epoch': epoch,'model_state_dict': self.model.state_dict(),'optimizer_state_dict': self.optimizer.state_dict(),'scheduler_state_dict': self.scheduler.state_dict(),'train_acc': train_acc,'test_acc': test_acc,'metrics': self.metrics}# 保存到checkpoints目录checkpoint_path = os.path.join(PathConfig.CHECKPOINT_DIR, f'checkpoint_epoch_{epoch}.pth')torch.save(checkpoint, checkpoint_path)# 如果是最佳模型,保存到models目录if is_best:best_model_path = os.path.join(PathConfig.MODEL_DIR, 'best_model.pth')torch.save(checkpoint, best_model_path)self.log(f'Best model saved! Test Acc: {test_acc:.2f}%')def save_results(self):"""保存训练结果"""# 保存训练指标metrics_path = os.path.join(PathConfig.RESULT_DIR, 'training_metrics.json')with open(metrics_path, 'w') as f:json.dump(self.metrics, f, indent=2)# 绘制训练曲线plt.figure(figsize=(12, 4))plt.subplot(1, 2, 1)plt.plot(self.metrics['epochs'], self.metrics['train_loss'], 'b-', label='Train Loss')plt.plot(self.metrics['epochs'], self.metrics['test_loss'], 'r-', label='Test Loss')plt.xlabel('Epoch')plt.ylabel('Loss')plt.title('Training and Test Loss')plt.legend()plt.grid(True)plt.subplot(1, 2, 2)plt.plot(self.metrics['epochs'], self.metrics['train_acc'], 'b-', label='Train Acc')plt.plot(self.metrics['epochs'], self.metrics['test_acc'], 'r-', label='Test Acc')plt.xlabel('Epoch')plt.ylabel('Accuracy (%)')plt.title('Training and Test Accuracy')plt.legend()plt.grid(True)plt.tight_layout()curve_path = os.path.join(PathConfig.RESULT_DIR, 'training_curves.png')plt.savefig(curve_path, dpi=300, bbox_inches='tight')plt.close()self.log(f"Training results saved to {PathConfig.RESULT_DIR}")def train(self, num_epochs=30):"""主训练循环"""self.log("=== Training Started ===")self.log(f"Device: {self.device}")self.log(f"Epochs: {num_epochs}")best_acc = 0for epoch in range(1, num_epochs + 1):self.log(f"\n=== Epoch {epoch}/{num_epochs} ===")# 训练train_acc, train_loss = self.train_epoch(epoch)# 测试test_acc, test_loss = self.test_epoch(epoch)# 更新学习率self.scheduler.step()current_lr = self.optimizer.param_groups[0]['lr']# 记录指标self.metrics['epochs'].append(epoch)self.metrics['train_loss'].append(train_loss)self.metrics['train_acc'].append(train_acc)self.metrics['test_loss'].append(test_loss)self.metrics['test_acc'].append(test_acc)self.metrics['learning_rates'].append(current_lr)# TensorBoard记录self.writer.add_scalar('Loss/Train', train_loss, epoch)self.writer.add_scalar('Loss/Test', test_loss, epoch)self.writer.add_scalar('Accuracy/Train', train_acc, epoch)self.writer.add_scalar('Accuracy/Test', test_acc, epoch)self.writer.add_scalar('Learning_Rate', current_lr, epoch)# 保存检查点is_best = test_acc > best_accif is_best:best_acc = test_accself.save_checkpoint(epoch, train_acc, test_acc, is_best)# 每5个epoch保存一次结果if epoch % 5 == 0:self.save_results()self.log(f"\n=== Training Completed ===")self.log(f"Best Test Accuracy: {best_acc:.2f}%")# 保存最终结果self.save_results()self.writer.close()def main():print("=== CIFAR-10 Training with PyTorch ===")print(f"CUDA Available: {torch.cuda.is_available()}")if torch.cuda.is_available():print(f"GPU: {torch.cuda.get_device_name(0)}")# 创建训练管理器trainer = TrainingManager()# 加载数据trainer.load_data()# 创建模型trainer.create_model()# 开始训练trainer.train(num_epochs=30)print("\n=== Training Complete ===")print("Check the following directories for results:")print(f"- Models: {PathConfig.MODEL_DIR}")print(f"- Checkpoints: {PathConfig.CHECKPOINT_DIR}")print(f"- Results: {PathConfig.RESULT_DIR}")print(f"- Logs: {PathConfig.LOG_DIR}")if __name__ == "__main__":main()四:启动训练
## 打开cmd或者使用docker-desktop的terminal 预留6006端口给tensorboard看板页面使用docker run --gpus all -it --name pytorch-cifar10 -v C:/training_test:/workspace -p 6006:6006 training_test:ubuntu22.04-cuda12.4.1-python3.10.18-pytorch2.6-gpu bashdocker exec -it pytorch-cifar10 bash python code/train.py
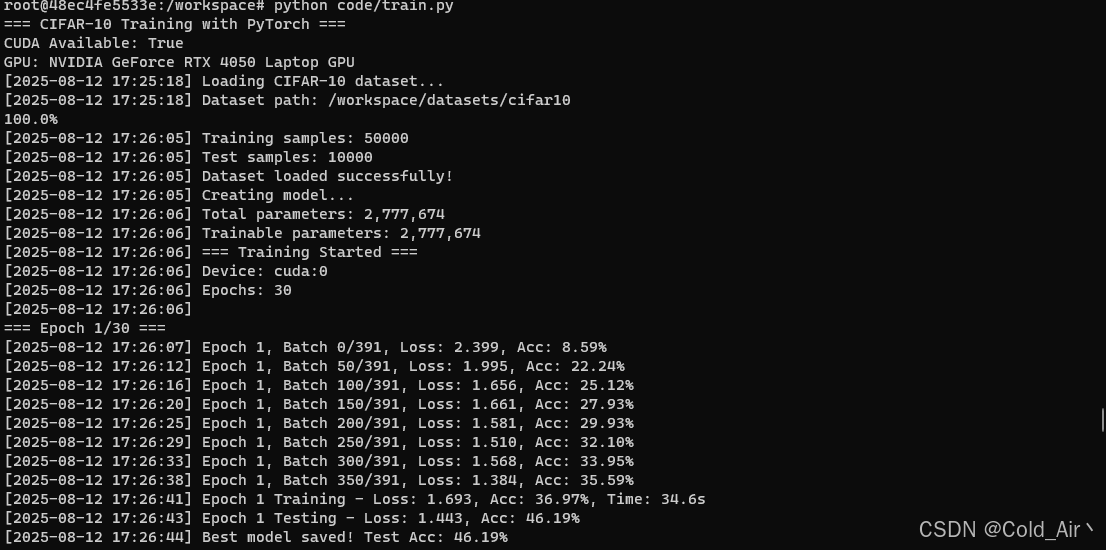
启动训练之后会先自动下载数据集,数据集下载完成之后开始训练
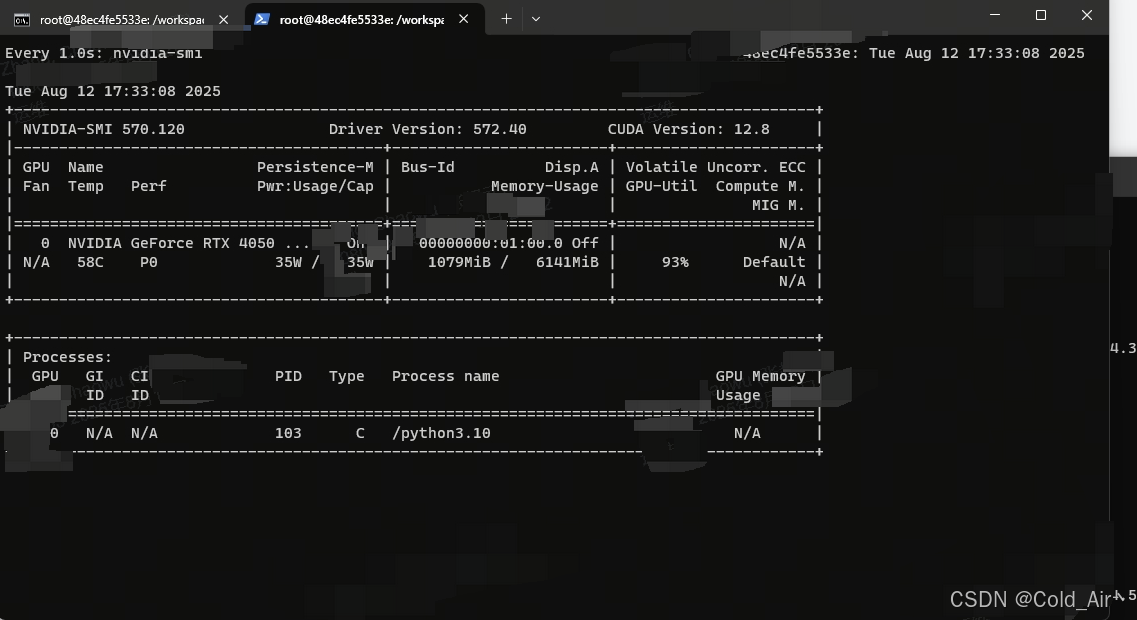
nvidia-smi查看下gpu显存和利用率
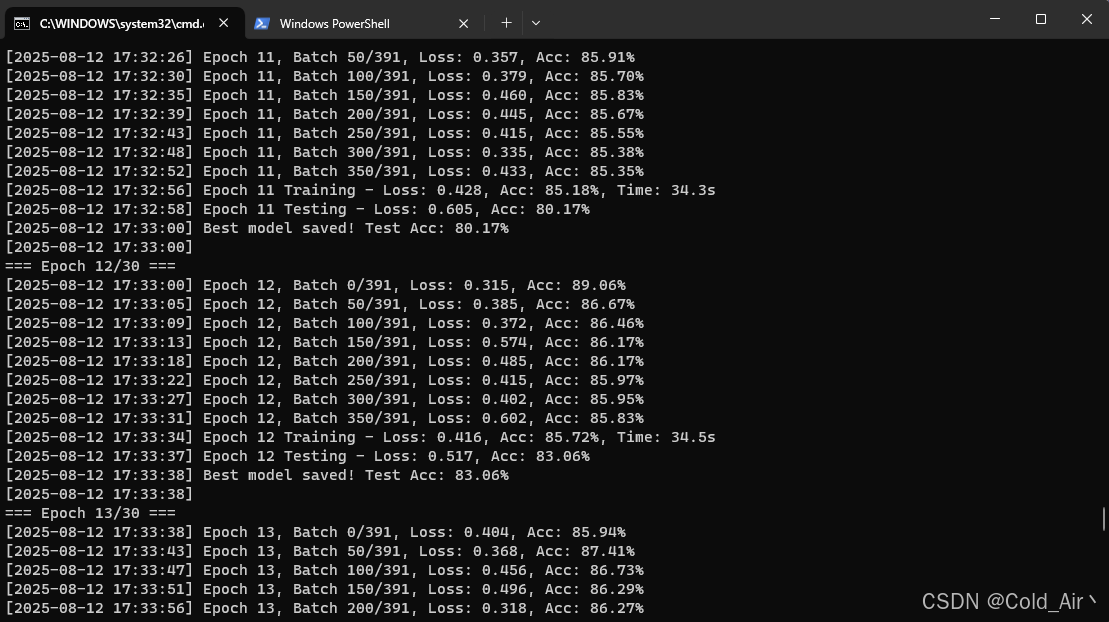
实时查看训练任务是否正常
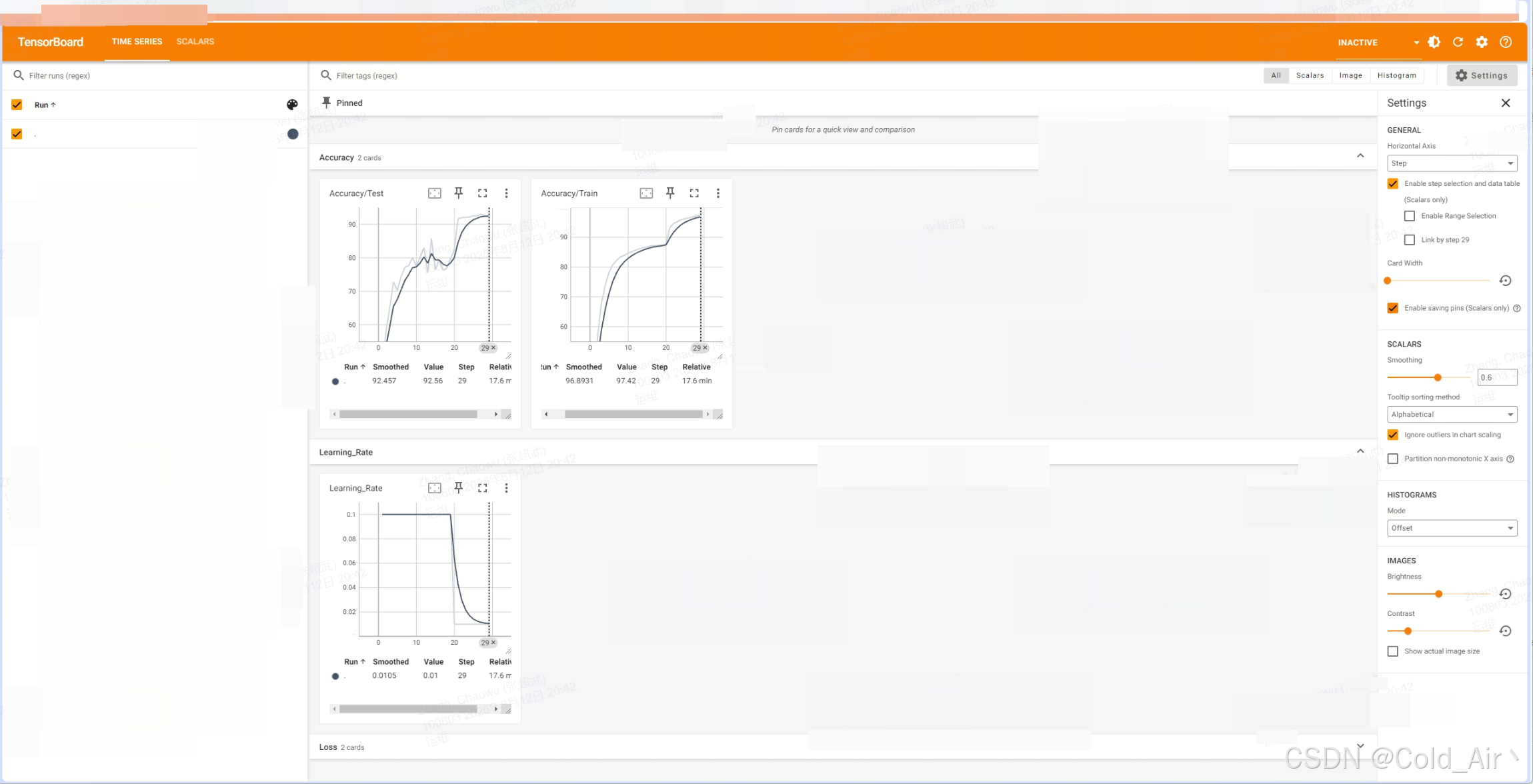
启动tensorboard查看训练看板:
# 在容器内启动TensorBoard tensorboard --logdir=/workspace/logs/tensorboard --host=0.0.0.0 --port=6006访问本机ip+6006端口:
关于tensorboard板的一些解释:
1. Scalars 标签页: Loss/Train_Loss - 训练损失曲线 Loss/Test_Loss - 测试损失曲线 Accuracy/Train_Accuracy - 训练准确率曲线 Accuracy/Test_Accuracy - 测试准确率曲线 Learning_Rate - 学习率变化2. Images 标签页: 可以看到一些样本图片3. Histograms 标签页: 模型参数分布训练完成
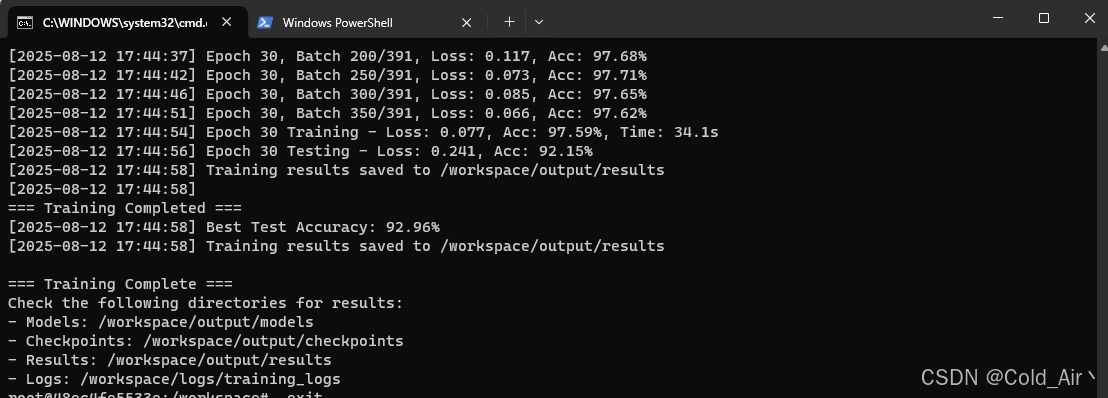
查看训练结果:
进到training_test/output/results目录:
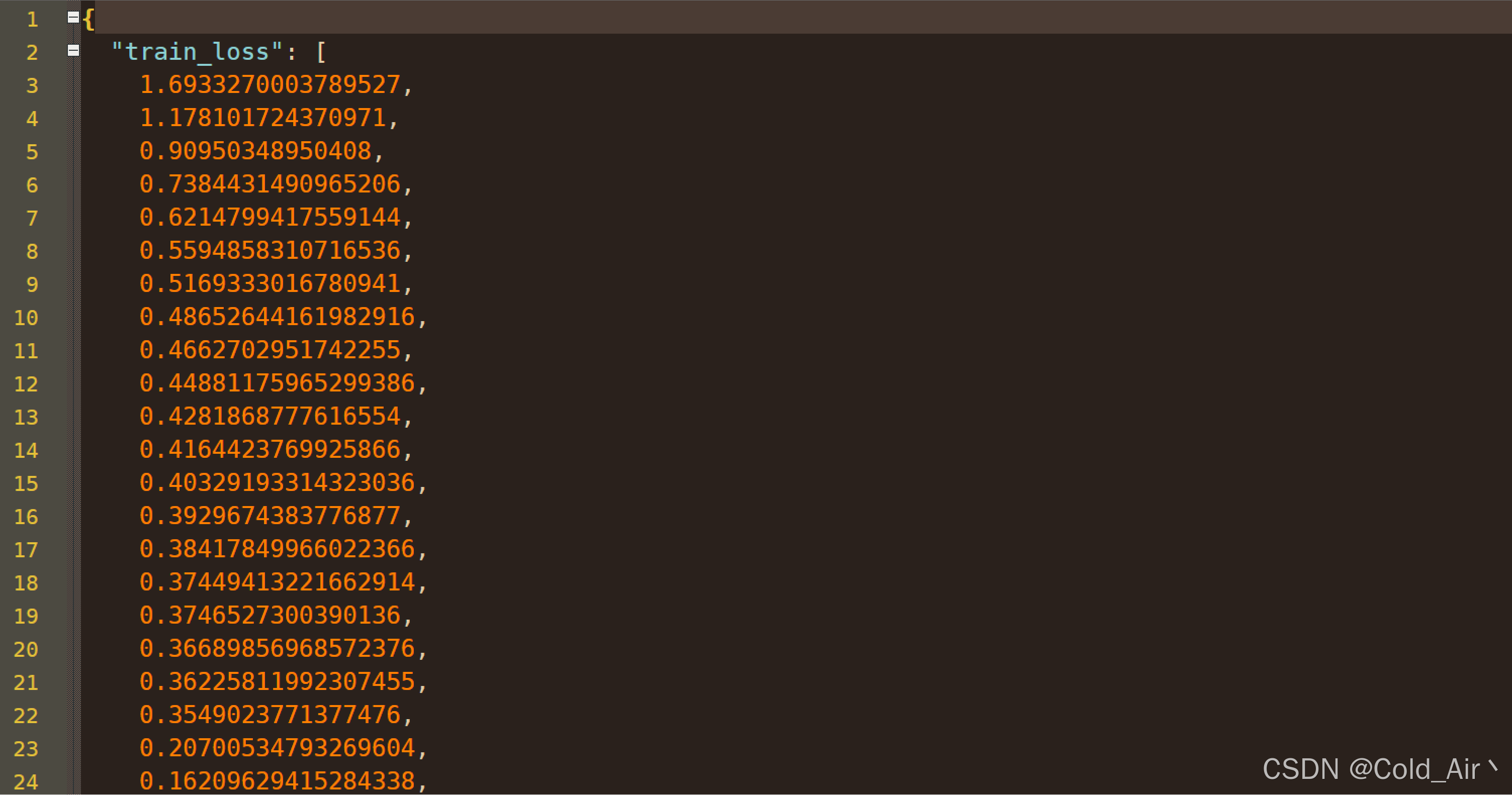
查看training_metrics.json内容,查看结果数据是否达到基准要求:
五:延伸
其实不管是在linux服务器上,还是在windows电脑/服务器上,使用docker镜像的原理是不变的,这一套单机单卡的训练场景是可以通用在linux的服务器上的,可能到时为了提高数据读写的性能使用的存储方式不同罢了,后续会不断更新如何在多机多卡场景去模拟推理或训练并加入rdma相关集合通信的概念。