Druid学习笔记 02、快速使用Druid的SqlParser解析
文章目录
- 前言
- 本章节源码
- 描述
- 认识作者
- 官方文档
- 快速入门demo案例
- 引入依赖
- 获取到SQL的AST(抽象语法树)
- 使用visitor完成表、字段、表达式解析
- 汇总总结
- 一、简介
- 1.1、和Antlr生成Parser的区别
- 1.2、Druid SQL Parser的使用场景
- 二、各种语法支持
- 三、性能
- 四、Druid SQL Parser的代码结构
- 4.1、parser
- 4.2、AST
- 4.3、Visitor
- 4.4、自定义Visitor
- 4.5、方言
- 五、SchemaRepository
- 参考文章
- 资料获取

前言
博主介绍:✌目前全网粉丝4W+,csdn博客专家、Java领域优质创作者,博客之星、阿里云平台优质作者、专注于Java后端技术领域。
涵盖技术内容:Java后端、大数据、算法、分布式微服务、中间件、前端、运维等。
博主所有博客文件目录索引:博客目录索引(持续更新)
CSDN搜索:长路
视频平台:b站-Coder长路
本章节源码
当前文档配套相关源码地址:
- gitee:https://gitee.com/changluJava/demo-exer/tree/master/java-sqlparser/demo-druid/demo-druid-simpledemo
- github:https://github.com/changluya/Java-Demos/tree/master/java-sqlparser/demo-druid/demo-druid/demo-druid-simpledemo
描述
Druid 本身并没有直接内置完善的血缘解析功能,但我们可以结合 Druid 的数据查询和元数据管理机制,配合一些外部手段实现基本的血缘解析。
认识作者
温绍锦:初心不改的阿里初代开源人:https://gitee.com/gitee-stars/18
官方文档
开源地址:https://github.com/alibaba/druid
学习文档:https://github.com/alibaba/druid/wiki/SQL-Parser
快速入门demo案例
引入依赖
<dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.2.0</version>
</dependency>
获取到SQL的AST(抽象语法树)
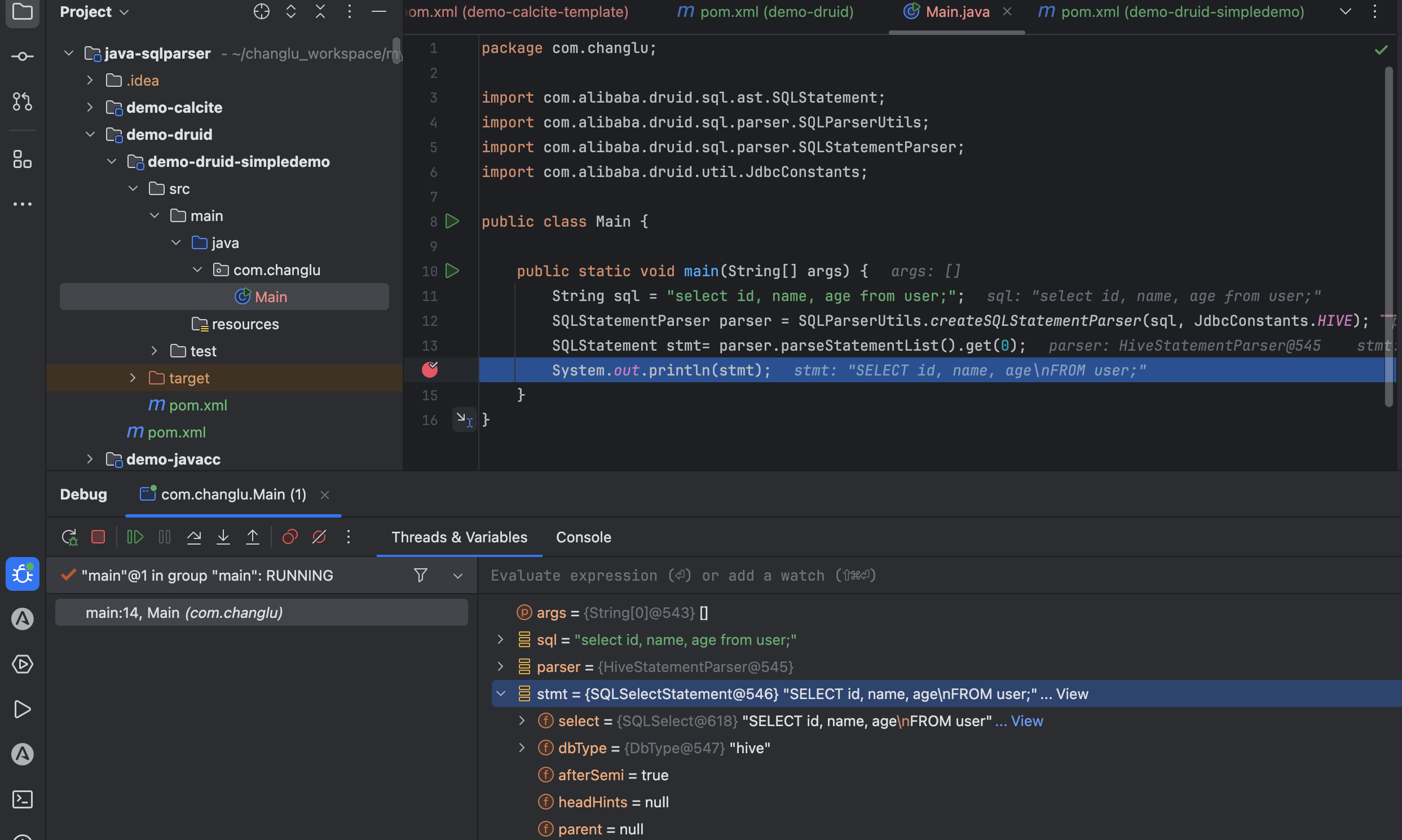
import com.alibaba.druid.sql.ast.SQLStatement;
import com.alibaba.druid.sql.parser.SQLParserUtils;
import com.alibaba.druid.sql.parser.SQLStatementParser;
import com.alibaba.druid.util.JdbcConstants;public class Main {public static void main(String[] args) {String sql = "select id, name, age from user;";SQLStatementParser parser = SQLParserUtils.createSQLStatementParser(sql, JdbcConstants.HIVE);SQLStatement stmt= parser.parseStatementList().get(0);System.out.println(stmt);}
}

使用visitor完成表、字段、表达式解析
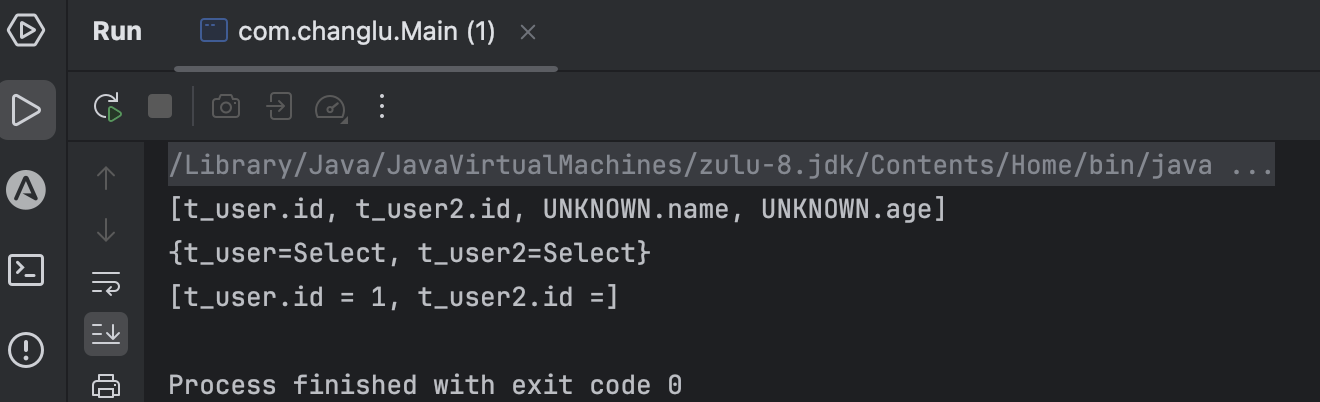
public static void main(String[] args) throws Exception{String sql = "select name, age from t_user left join t_user2 on t_user.id = t_user2.id where t_user.id = 1;";List<SQLStatement> stmtList = SQLUtils.parseStatements(sql, JdbcConstants.HIVE);SQLStatement stmt = stmtList.get(0);// 构建visitorSchemaStatVisitor statVisitor = SQLUtils.createSchemaStatVisitor(JdbcConstants.HIVE);stmt.accept(statVisitor);System.out.println(statVisitor.getColumns()); // [t_user.name, t_user.age, t_user.id]System.out.println(statVisitor.getTables()); // {t_user=Select}System.out.println(statVisitor.getConditions()); // [t_user.id = 1]
}
汇总总结
下面内容主要参考Druid的学习wiki:https://github.com/alibaba/druid/wiki/SQL-Parser
一、简介
SQL Parser是Druid的一个重要组成部分,Druid内置使用SQL Parser来实现防御SQL注入(WallFilter)、合并统计没有参数化的SQL(StatFilter的mergeSql)、SQL格式化、分库分表。
1.1、和Antlr生成Parser的区别
和Antlr生成的SQL有很大不同的是,Druid SQL Parser性能非常好,可以用于生产环境直接对SQL进行分析处理。
1.2、Druid SQL Parser的使用场景
- MySql SQL全量统计
- Hive/ODPS SQL执行安全审计
- 分库分表SQL解析引擎
- 数据库引擎的SQL Parser
二、各种语法支持
Druid的sql parser是目前支持各种数据语法最完备的SQL Parser。目前对各种数据库的支持如下:
| 数据库 | DML | DDL |
|---|---|---|
| odps | 完全支持 | 完全支持 |
| mysql | 完全支持 | 完全支持 |
| postgresql | 完全支持 | 完全支持 |
| oracle | 支持大部分 | 支持大部分 |
| sql server | 支持常用的 | 支持常用的ddl |
| db2 | 支持常用的 | 支持常用的ddl |
| hive | 支持常用的 | 支持常用的ddl |
druid还缺省支持sql-92标准的语法,所以也部分支持其他数据库的sql语法。
三、性能
Druid的SQL Parser是手工编写,性能非常好,目标就是在生产环境运行时使用的SQL Parser,性能比antlr、javacc之类工具生成的Parser快10倍甚至100倍以上。
SELECT ID, NAME, AGE FROM USER WHERE ID = ?
这样的SQL,druid parser处理大约是600纳秒,也就是说单线程每秒可以处理1500万次以上。在1.1.3~1.1.4版本中,SQL Parser的性能有极大提升,完全可以适用于生产环境中对SQL进行处理。
四、Druid SQL Parser的代码结构
Druid SQL Parser分三个模块:
- Parser
- AST
- Visitor
4.1、parser
parser是将输入文本转换为ast(抽象语法树),parser有包括两个部分,Parser和Lexer,其中Lexer实现词法分析,Parser实现语法分析。
4.2、AST
AST是Abstract Syntax Tree的缩写,也就是抽象语法树。AST是parser输出的结果。下面是获得抽象语法树的一个例子:
final String dbType = JdbcConstants.MYSQL; // 可以是ORACLE、POSTGRESQL、SQLSERVER、ODPS等
String sql = "select * from t";
List<SQLStatement> stmtList = SQLUtils.parseStatements(sql, dbType);
- Druid SQL AST介绍 https://github.com/alibaba/druid/wiki/Druid_SQL_AST
4.3、Visitor
Visitor是遍历AST的手段,是处理AST最方便的模式,Visitor是一个接口,有缺省什么都没做的实现VistorAdapter。
我们可以实现不同的Visitor来满足不同的需求,Druid内置提供了如下Visitor:
- OutputVisitor用来把AST输出为字符串
- WallVisitor 来分析SQL语意来防御SQL注入攻击
- ParameterizedOutputVisitor用来合并未参数化的SQL进行统计
- EvalVisitor 用来对SQL表达式求值
- ExportParameterVisitor用来提取SQL中的变量参数
- SchemaStatVisitor 用来统计SQL中使用的表、字段、过滤条件、排序表达式、分组表达式
- SQL格式化 Druid内置了基于语义的SQL格式化功能【字符串拼接模式完成sql格式化处理】
4.4、自定义Visitor
每种方言的Visitor都有一个缺省的VisitorAdapter,使得编写自定义的Visitor更方便。 https://github.com/alibaba/druid/wiki/SQL_Parser_Demo_visitor
4.5、方言
SQL-92、SQL-99等都是标准SQL,mysql/oracle/pg/sqlserver/odps等都是方言,也就是dialect。parser/ast/visitor都需要针对不同的方言进行特别处理。
五、SchemaRepository
Druid SQL Parser内置了一个SchemaRepository,在内存中缓存SQL Schema信息,用于SQL语义解析中的ColumnResolve等操作。 https://github.com/alibaba/druid/wiki/SQL_Schema_Repository
可以基于Druid SQL Parser之上构造Oracle SQL到其他数据的SQL翻译。比如Aliyun提供的Oracle到MySql的SQL翻译功能,就是基于Druid基础上实现的。https://rainbow-expert.aliyun.com/sqltransform.htm
参考文章
[1]. Druid SQL解析原理以及使用(一):https://blog.csdn.net/qq_25104587/article/details/90577646
[2]. 使用Druid的sql parser做一个表数据血缘分析工具:https://www.cnblogs.com/enhe/p/12141686.html
资料获取
大家点赞、收藏、关注、评论啦~
精彩专栏推荐订阅:在下方专栏👇🏻
- 长路-文章目录汇总(算法、后端Java、前端、运维技术导航):博主所有博客导航索引汇总
- 开源项目Studio-Vue—校园工作室管理系统(含前后台,SpringBoot+Vue):博主个人独立项目,包含详细部署上线视频,已开源
- 学习与生活-专栏:可以了解博主的学习历程
- 算法专栏:算法收录
更多博客与资料可查看👇🏻获取联系方式👇🏻,🍅文末获取开发资源及更多资源博客获取🍅