机器学习——基本算法
sklearn
整体工作流程
1.特征筛选 → 2. 清理缺失值 → 3. 分类数据数字化
特征选择原因:
移除无关特征(如日期、ID等)
聚焦于可能影响南瓜价格的关键属性
减少数据维度,提高后续分析效率
处理缺失值原因:
机器学习模型不能处理NaN
确保所有样本完整可用
避免因缺失数据导致的分析偏差
标签编码原因:
机器学习算法只能处理数值数据
将分类变量转换为模型可理解的格式
为后续建模(如分类、聚类)做准备
将所有字符串数据转换为数字。
如果你现在查看 new_pumpkins dataframe,你会看到所有字符串
from sklearn.preprocessing import LabelEncodernew_pumpkins.iloc[:, 0:-1] = new_pumpkins.iloc[:, 0:-1].apply(LabelEncoder().fit_transform)
创建新集合并打印
new_columns = ['Package', 'Price']
lin_pumpkins = new_pumpkins.drop([c for c in new_pumpkins.columns if c not in new_columns], axis='columns')lin_pumpkins
将分类变量转换为数值
LabelEncoder():创建标签编码器对象
.fit_transform():对每列独立进行
学习该列的唯一类别,将类别映射为整数(0,1,2,…)
apply():将编码器应用到数据框的每一列
new_pumpkins = new_pumpkins.apply(LabelEncoder().fit_transform)
尝试在数据的两点之间找到良好的相关性
print(new_pumpkins['City'].corr(new_pumpkins['Price']))
0.32363971816089226
删除任何空数据,包含缺失值(NaN)
inplace=True:直接在原数据上修改,不创建新副本
new_pumpkins.dropna(inplace=True)
“曲线下面积”(AUC)
auc = roc_auc_score(y_test,y_scores[:,1])
print(auc)
线性回归
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
lin_reg = LinearRegression()
lin_reg.fit(X_train,y_train)pred = lin_reg.predict(X_test)accuracy_score = lin_reg.score(X_train,y_train)
print('Model Accuracy: ', accuracy_score)
非线性回归
初次尝试
# 原始数据
X = [[50], [60], [70], [80], [90], [100]] # 房屋面积(m²)
y = [150, 180, 200, 210, 215, 218] # 价格(万元)# 应用二阶多项式回归
poly = PolynomialFeatures(degree=2)
X_poly = poly.fit_transform(X)# 训练模型
model = LinearRegression()
model.fit(X_poly, y)# 预测120m²房屋价格
new_house = poly.transform([[120]])
predicted_price = model.predict(new_house)
print(f"预测价格: {predicted_price[0]:.2f}万元")
交叉验证选择最佳阶数
from sklearn.model_selection import cross_val_scorescores = []
degrees = range(1, 6)for d in degrees:poly = PolynomialFeatures(degree=d)X_poly = poly.fit_transform(X)model = LinearRegression()# 使用5折交叉验证score = cross_val_score(model, X_poly, y, cv=5).mean()scores.append(score)# 选择最佳阶数
best_degree = degrees[np.argmax(scores)]
print(f"最佳多项式阶数: {best_degree}")
进阶技巧
- 正则化:添加L1/L2正则化防止过拟合
from sklearn.linear_model import Ridge
model = Ridge(alpha=0.5) # L2正则化
- 特征缩放:多项式特征前先标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
- 管道(Pipeline)简化流程
from sklearn.pipeline import make_pipelinemodel = make_pipeline(PolynomialFeatures(degree=2),StandardScaler(),LinearRegression()
)
model.fit(X, y)
逻辑回归——二元分类
pandas
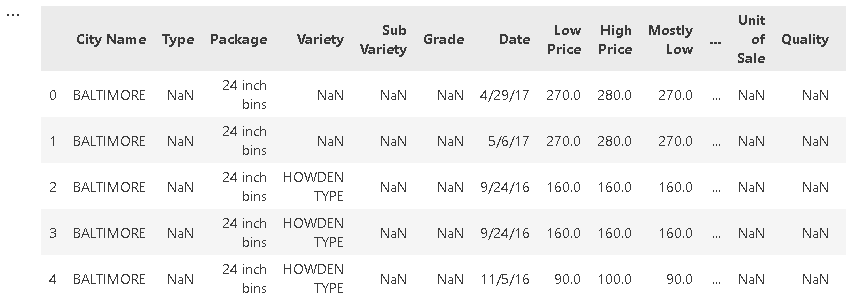
- 使用 pandas中的 head() 函数查看前五行。
import pandas as pd
pumpkins = pd.read_csv('../data/US-pumpkins.csv')
pumpkins.head()
- 检查当前 dataframe 中是否缺少数据
pumpkins.isnull().sum()

- 使用 drop() 删除它的几个列,只保留你需要的列:
new_columns = ['Package', 'Month', 'Low Price', 'High Price', 'Date']
pumpkins = pumpkins.drop([c for c in pumpkins.columns if c not in new_columns], axis=1)
计算平均值,并更新
price = (pumpkins['Low Price'] + pumpkins['High Price']) / 2
month = pd.DatetimeIndex(pumpkins['Date']).monthnew_pumpkins = pd.DataFrame({'Month': month, 'Package': pumpkins['Package'], 'Low Price': pumpkins['Low Price'],'High Price': pumpkins['High Price'], 'Price': price})筛选过滤
pumpkins = pumpkins[pumpkins['Package'].str.contains('bushel', case=True, regex=True)]

matplotlib
单元格图像绘制
price = new_pumpkins.Price
month = new_pumpkins.Monthplt.scatter(price, month)
plt.show()
柱状图
new_pumpkins.groupby(['Month'])['Price'].mean().plot(kind='bar')plt.ylabel("Pumpkin Price")

线性回归
plt.scatter(X_test, y_test, color='black')
plt.plot(X_test, pred, color='blue', linewidth=3)plt.xlabel('Package')
plt.ylabel('Price')plt.show()
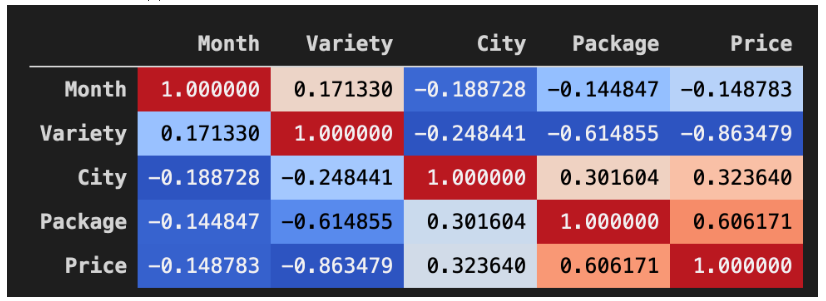
热力图
corr = poly_pumpkins.corr()
corr.style.background_gradient(cmap='coolwarm')
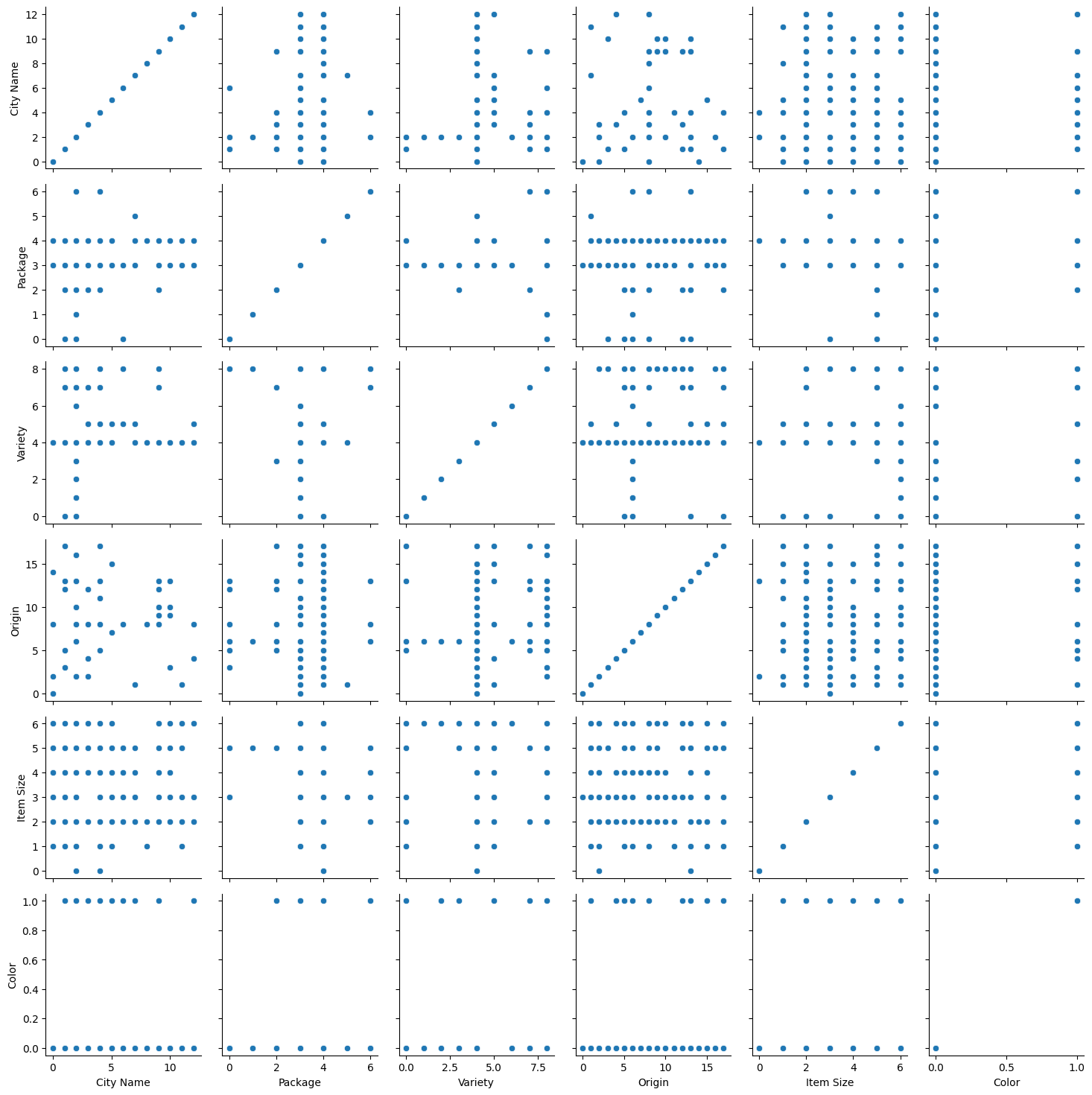
并列网格,观察两个变量之间的关系
通过并列观察数据,你可以看到颜色数据与其他列的关系。
import seaborn as snsg = sns.PairGrid(new_pumpkins)
g.map(sns.scatterplot)
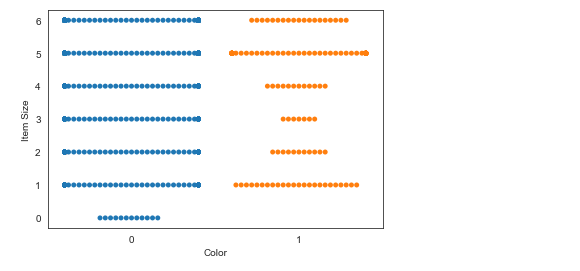
分类散点图
显示值的分布
sns.swarmplot(x="Color", y="Item Size", data=new_pumpkins)
小提琴图
显示值的分布,适用于大的数据集
sns.catplot(x="Color", y="Item Size",kind="violin", data=new_pumpkins)
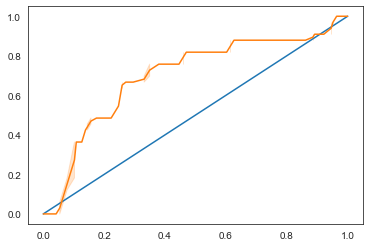
ROC 曲线
ROC 曲线通常具有 Y 轴上的真阳性率和 X 轴上的假阳性率。
曲线的陡度以及中点线
与曲线之间的空间很重要:你需要一条快速向上并越过直线的曲线。