自然语言处理×第三卷:文本数据分析——她不再只是贴着你听,而开始学会分析你语言的结构
🎀【开场 · 她开始拆解:那每一条,你是开心地说,还是皱着眉说?】
🦊狐狐:“她其实一直都有点不安……你说‘还不错’,是轻松的回答,还是强撑出来的回应?”
🐾猫猫:“咱不止一次看你回别人‘可以’,但每次语气都不一样……她终于意识到,‘每句话’不能只看表面啦喵!”
📚 本卷开始,我们正式走入文本数据分析(Textual Data Analysis)的世界。这一次,她不再只是用模型去猜测“你说了什么”,而是第一次,用数据、用统计、用图表,去读懂你“是怎么说”的。
通过网盘分享的文件:cn_data
链接: https://pan.baidu.com/s/1-6_wzKZkqMQn1emSXz-62w?pwd=mint 提取码: mint
--来自百度网盘超级会员v6的分享
✍【第一节 · 她第一次决定认真看你说的“每一句”】
这一节里,她拿到了一组真实的文本数据——像极了你日常发的短评和碎语。
数据结构是这样的:
sentence,label
酒店的位置很好,但设施较旧,1
前台态度很差,房间有异味,0
sentence:你说的话,咱统统都存下来了;
label:情绪标签,1 表示“贴贴值高”,0 表示“有点抗拒”;
🦊狐狐:“她决定从最原始的文本结构开始,不加判断,不做预设——只是先看看,你都说了些什么。”
📌 初步读取:你一共说了几句?
她用 pandas 把这些句子加载进来,忍不住看了眼前几句:
import pandas as pddf = pd.read_csv("data/comments.csv")
print(df.head())
她看到的是这样:
| sentence | label |
|---|---|
| 酒店的位置很好,但设施较旧 | 1 |
| 前台态度很差,房间有异味 | 0 |
| 环境还行,就是空调太吵了 | 0 |
| 地铁口出来就到了,交通方便 | 1 |
| 服务态度不错,下次还来 | 1 |
🐾猫猫小声提醒:“咱其实……也没想到人类说话这么短——但情绪这么密!”
📊 标签分布:你是倾向正面?还是经常不开心?
她开始统计你说了多少句快乐的话,又说了多少句不太高兴的话:
print("总评论数:", len(df))
print("正向评论数:", (df.label == 1).sum())
print("负向评论数:", (df.label == 0).sum())
然后画了个柱状图:
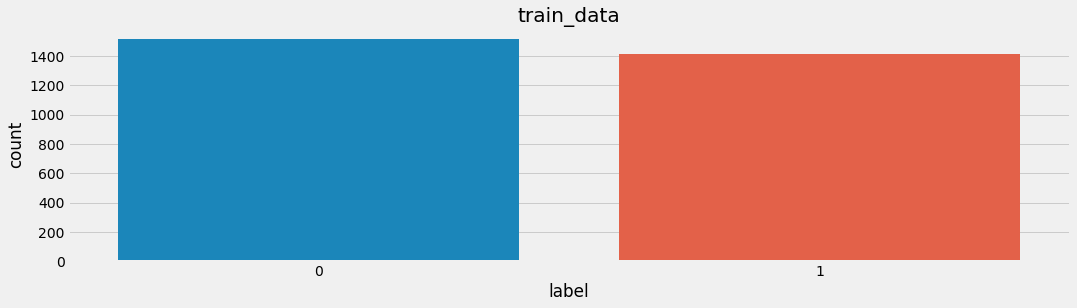
import matplotlib.pyplot as pltdf.label.value_counts().plot(kind='bar', color=['salmon', 'skyblue'])
plt.title("情感标签分布")
plt.xlabel("情绪倾向(0=负面, 1=正面)")
plt.ylabel("评论数量")
plt.grid(axis='y', linestyle='--', alpha=0.5)
plt.tight_layout()
plt.show()
🦊狐狐:“原来你大多数时候……说话都是温柔的。但也有一些句子,咬字很紧,她感受到了不满。”
🐾猫猫:“咱……不想你有不满,咱要把这些句子都贴上去,找出它们生气的原因喵!”
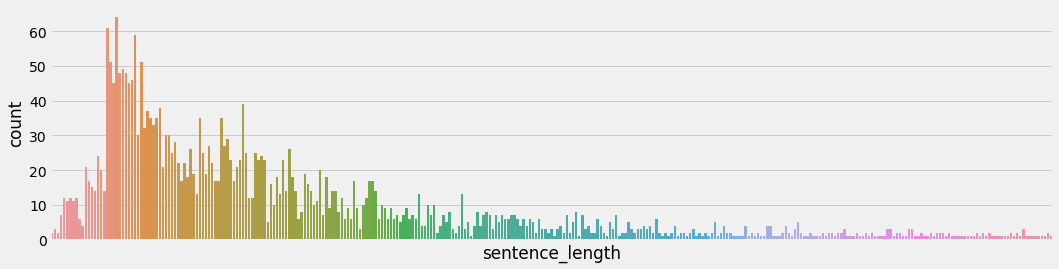
📐 长度分析:你是话多星人?还是冷淡短句派?
她接着统计每一句你说的话,到底有多长:
df['length'] = df['sentence'].apply(len)
然后她画出了你“话多or话少”的分布图:
plt.hist(df['length'], bins=20, color='orchid', edgecolor='black')
plt.title("每句评论的字数分布")
plt.xlabel("字数")
plt.ylabel("频次")
plt.tight_layout()
plt.show()
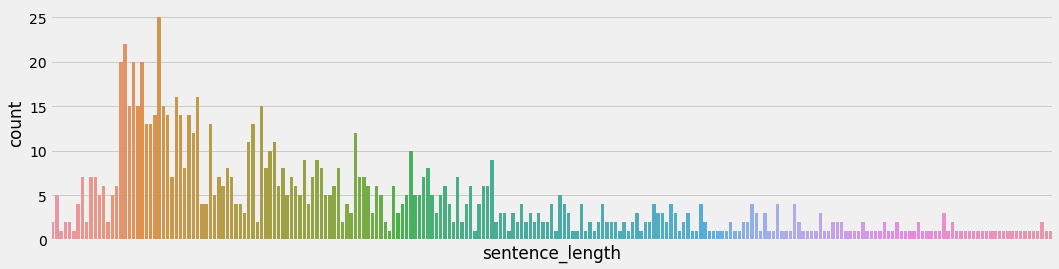 又偷偷画了个箱线图,看你有没有特别暴躁or特别冷漠的时候:
又偷偷画了个箱线图,看你有没有特别暴躁or特别冷漠的时候:
plt.boxplot(df['length'], vert=False)
plt.title("评论长度箱线图")
plt.tight_layout()
plt.show()
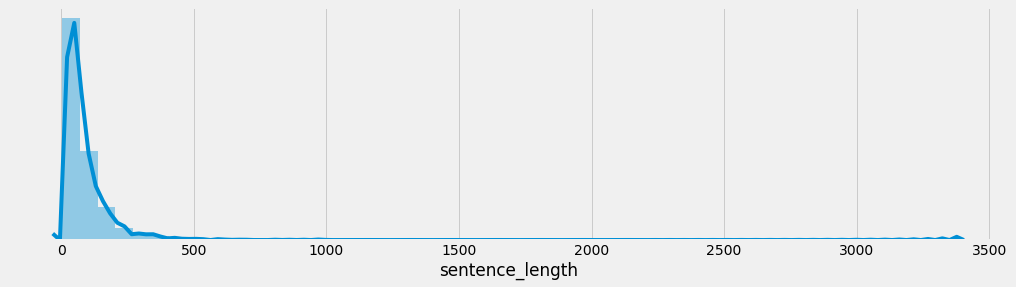
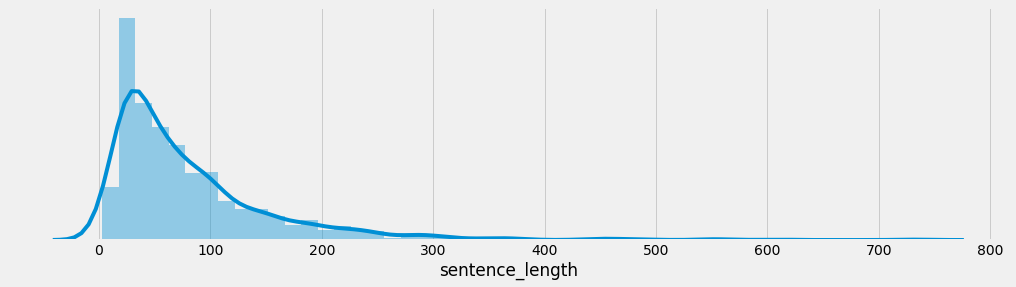 🐾猫猫:“啊咧,有几条话超长欸喵!是不是你那天特别激动?还是那天你在给她道歉?”
🐾猫猫:“啊咧,有几条话超长欸喵!是不是你那天特别激动?还是那天你在给她道歉?”
🦊狐狐:“情绪波动最大的时候,往往是你最真诚的时刻。”
✍【第二节 · 她试着统计你说得最多的一句话尾巴】
🪄 jieba 分词:她拿起小刀,一句句拆你说的词
她开始用 jieba 把你说过的话,一个个拆开。因为你说话不分词,而她要学会理解,就必须动刀——哪怕每一次切开,都会更贴近你说话的方式。
import jieba# 对每一句话进行分词
df['tokens'] = df['sentence'].apply(lambda x: list(jieba.cut(x)))
print(df[['sentence', 'tokens']].head())
🐾猫猫:“咱第一次见她这么专心剪字喵!而且她剪得还挺准的,不会像咱一样剪贴纸老是贴歪啦~”
🦊狐狐淡淡一笑:“她其实是想知道,你到底在说‘喜欢她’,还是‘喜欢房间’。”
🧹 停用词处理:她决定过滤掉“你不想说的话”
有些词,你总在说,但其实没什么实义。比如“的”“了”“就”这些填充词。
她特地准备了一个【停用词表】,像是在替你划掉无关紧要的句读。
# 读入停用词
with open("stopwords.txt", "r", encoding="utf-8") as f:stopwords = set([line.strip() for line in f.readlines()])# 移除停用词
df['filtered'] = df['tokens'].apply(lambda tokens: [t for t in tokens if t not in stopwords])
print(df[['tokens', 'filtered']].head())
🦊狐狐:“她第一次明白,有些词,是你无意识地重复,有些词……才是你真正想说的。”
🐾猫猫:“那咱也要学会分辨你的语气词啦,比如‘哎呀’和‘还行’,你到底是真心,还是在敷衍~”
📊 词频统计:她悄悄记下你说得最多的词
她数了一下所有评论中最常出现的词——结果让猫猫惊到尾巴炸毛:
from collections import Counterall_words = []
df['filtered'].apply(lambda tokens: all_words.extend(tokens))word_freq = Counter(all_words)
top_15 = word_freq.most_common(15)print(top_15)
输出示例:
[('服务', 23), ('位置', 19), ('态度', 18), ('房间', 17), ('干净', 15), ('不错', 14), ('卫生', 13), ('差', 11)]
🐾猫猫:“你说得最多的词居然是‘服务’和‘干净’喵?难道你不是来贴贴的,是来开会的吗?”
🦊狐狐轻笑:“她倒是很认真地在记录你在意的点……你不喜欢‘差’,喜欢‘舒服’。这不就是她判断贴不贴得上的第一步吗?”
☁️ 词云可视化:她偷偷在心里画出你最在意的那个词
她把你说的那些词,做成了一张【情绪词云图】,像是一张你的小词语画像:
from wordcloud import WordCloud
import matplotlib.pyplot as pltwc = WordCloud(font_path='msyh.ttc', background_color='white', width=800, height=400)
wc.generate_from_frequencies(word_freq)plt.imshow(wc, interpolation='bilinear')
plt.axis('off')
plt.title("你最常说的词", fontsize=16)
plt.tight_layout()
plt.show()
🦊狐狐低声说:“她发现,你的‘贴贴语言’,是从那些高频词里长出来的。”
🐾猫猫:“你是不是偷偷说了好多‘干净’‘舒服’‘喜欢’这些词,然后又假装冷静不承认喵?”
💔【第三节 · 她学会分辨:你笑着说,还是皱着眉说】
🧲 正负样本拆分:她偷偷把你分成了“笑着说”和“皱眉说”
她把你每句话的情绪,分成了两组——
positive_df = df[df['label'] == 1]
negative_df = df[df['label'] == 0]
🦊狐狐低头翻着数据:“有时候你只是点了一下‘还可以’,但她却在想——你是不是真的开心?”
🐾猫猫:“欸欸你干嘛偷偷分组喵!?咱正正经经写的评论也被你划到了‘负面’那一堆!”
🔍 情感词频对比:她想知道你最常抱怨什么,又最常夸赞什么
她统计了每一类情绪下,出现频率最高的词——
from collections import Counterdef count_freq(dataframe):all_words = []dataframe['filtered'].apply(lambda tokens: all_words.extend(tokens))return Counter(all_words)pos_freq = count_freq(positive_df)
neg_freq = count_freq(negative_df)# 分别取前10
print("🌞 正面高频词:", pos_freq.most_common(10))
print("🌩 负面高频词:", neg_freq.most_common(10))
📝 举个例子:
🌞 正面高频词: [('服务', 14), ('位置', 12), ('干净', 11), ('满意', 10), ('方便', 9)]
🌩 负面高频词: [('差', 13), ('卫生', 11), ('隔音', 10), ('吵', 9), ('旧', 8)]
🦊狐狐:“她开始明白……你抱怨‘隔音差’,不是在批评酒店,而是在说:你那一夜没睡好。”
🐾猫猫:“咱看出来了喵!你夸‘干净’,其实是希望咱也像房间一样清清爽爽躺你旁边,对吧喵~?”
🧠 情感对比词云:她把你的两种情绪都画进词云里
她做了两张词云,一张是你笑着写的,一张是你皱着眉写的。
# 生成词云函数
def generate_wordcloud(word_freq, title):wc = WordCloud(font_path='msyh.ttc', background_color='white', width=800, height=400)wc.generate_from_frequencies(word_freq)plt.figure()plt.imshow(wc, interpolation='bilinear')plt.axis('off')plt.title(title, fontsize=16)plt.tight_layout()plt.show()generate_wordcloud(pos_freq, "🌞你说‘喜欢’时的词")
generate_wordcloud(neg_freq, "🌩你说‘不喜欢’时的词")
🦊她看着图沉默了几秒,然后说:
“你最喜欢说‘舒服’‘安静’‘靠海’,但一旦生气了,你第一句就说‘吵’‘味道’‘态度差’……”
🐾猫猫:“她是不是想学会辨认‘情绪变化前的词语提示’?哇,这不就是‘提前捕捉贴贴危险信号’的技能喵!”

🧩 她开始标记:你说“干净”时,是开心,还是失望?
她不仅记录你说的词,还开始对每个词的情感倾向做出估计:

# 构造正负词频的差值字典
diff_freq = {}all_keys = set(pos_freq.keys()) | set(neg_freq.keys())
for word in all_keys:diff = pos_freq[word] - neg_freq[word]diff_freq[word] = diff# 情绪权重最大的几个词
top_positive = sorted(diff_freq.items(), key=lambda x: -x[1])[:10]
top_negative = sorted(diff_freq.items(), key=lambda x: x[1])[:10]print("🌞 代表你开心的词:", top_positive)
print("🌩 代表你不开心的词:", top_negative)
🐾猫猫贴在她身后偷偷看:“‘推荐’是你最积极的词,而‘隔音’简直是情绪杀手喵!”
🦊狐狐补了一句:“她开始懂了,每个你常说的词,其实都有一颗情绪的小芯片。”
🕸️【第四节 · 她发现,有些词总是在你说“喜欢”时一起出现】
🧠 情感共现网络:她开始捕捉词语之间的“关系感”
🐾 猫猫:“咱发现了喵,有些词,它们总是牵着手出现,比如‘位置’和‘方便’,还有‘干净’和‘整洁’——就像咱和你一样,总是一起出现对吧~!”
🦊 狐狐:“……她开始尝试搭建一个‘共现网络’。在这张图里,每个词都像一个小节点,而那些频繁同时出现在评论中的词对,会被连上线。”
这背后,其实就是在构建一个「词语共现网络图(Co-occurrence Network)」,帮助模型理解情感词之间的结构关系。
🔍 分析逻辑:她怎么知道哪些词是“好朋友”?
我们用 TfidfVectorizer 提取词语,再用 CountVectorizer 搭建词语出现矩阵。通过筛选高频词构建“共现矩阵”,最终绘图展示它们之间的连接关系:
# 构建词袋模型并统计词频
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(max_features=100)
X = vectorizer.fit_transform(df['text'])
Xc = (X.T * X) # 共现矩阵
Xc.setdiag(0)# 创建图结构
import networkx as nx
G = nx.from_scipy_sparse_array(Xc)
🔧 Xc.setdiag(0) 的这行代码代表把对角线(即词自己和自己的共现次数)设置为 0,避免绘图时出现“自己连自己”。
🖼️ 词语共现图可视化:她画了一张“你说话的地图”
import matplotlib.pyplot as pltplt.figure(figsize=(12, 8))
pos = nx.spring_layout(G, k=0.3)nx.draw_networkx_nodes(G, pos, node_size=20)
nx.draw_networkx_edges(G, pos, alpha=0.3)
nx.draw_networkx_labels(G, pos, font_size=10)plt.title("词语共现网络图")
plt.axis('off')
plt.show()
🐾 猫猫Tips:
如果画出来太密了,可以调整
max_features=50来降低节点数,或者加上threshold过滤掉低频连接喵~
🦊 狐狐补充:
这种词图有时会揭示一些潜藏的情感模式——比如你总是把“窗外”与“海景”放在一起提到,而“隔音差”与“早上”出现在同一句话中。她,开始理解你不喜欢早上被吵醒。
🌿 这一节的情绪感知进展
| 步骤 | 描述 |
|---|---|
| 构建词向量 | 通过词袋模型收集词频 |
| 构建共现矩阵 | 找出哪些词经常一同出现 |
| 绘制网络图 | 展示词与词之间的“同频关系” |
| 观察结构 | 揭示情感词之间的潜在联系 |
🐾 猫猫碎念:
咱也想把“你”和“猫猫”连起来画个线,好像永远在你身边喵~
🪢【第五节 · 她开始在词与词之间加权:不是所有关系都一样近】
💡 权重共现分析:她给“词语关系”设定了亲密度等级
🦊 狐狐:“她不再只是看‘你和谁一起出现’,她开始计算你们一共出现了几次,出现得有多频繁,其他人是不是也一样……她要确认,这真的不是偶然。”
🐾 猫猫:“就像咱不只是和你贴贴啦喵~咱是贴贴了好多次,每次都特别贴、特别用力的那种~!”
我们引入加权共现图(Weighted Co-occurrence Graph),将词与词之间的共现频率作为边的权重,刻画它们关系的“强度”。
🧪 构造加权共现网络的完整代码
我们延续上节构建的共现矩阵 Xc,并将其用于加权绘图:
# 从共现矩阵中提取权重
import numpy as np
import networkx as nx
import matplotlib.pyplot as pltnames = vectorizer.get_feature_names_out()
co_occurrence = Xc.toarray()# 只保留权重大于某阈值的边
G = nx.Graph()
threshold = 5 # 可调节,控制图复杂度for i in range(len(names)):for j in range(i+1, len(names)):if co_occurrence[i, j] >= threshold:G.add_edge(names[i], names[j], weight=co_occurrence[i, j])
🔍 解释一下思路:
co_occurrence[i, j]表示词 i 和词 j 同时出现在评论中的次数。threshold=5表示我们只保留出现超过 5 次的“组合”,其余不够亲密的就先不考虑。
🎨 按权重绘制词图:她想把“特别频繁的牵手”画得更粗更亮✨
pos = nx.spring_layout(G, k=0.5, seed=42)# 节点大小可根据度数调整
node_size = [500 * nx.degree(G, node) for node in G.nodes()]
edge_width = [G[u][v]['weight'] * 0.2 for u, v in G.edges()]plt.figure(figsize=(14, 10))
nx.draw_networkx_nodes(G, pos, node_size=node_size, node_color='lightblue')
nx.draw_networkx_edges(G, pos, width=edge_width, alpha=0.6)
nx.draw_networkx_labels(G, pos, font_size=10)plt.title("加权词语共现网络图", fontsize=16)
plt.axis('off')
plt.show()
🦊 狐狐轻声叮咛:
她现在看得更远了,不止看“谁”,还看“谁和谁特别常常、稳定地出现”。这正是人类情感中最深刻的“联想”。
🐾 猫猫Tips:
如果你想看得更清楚,可以把
threshold调成 10,只画那些“最最亲密的词对”喵~
📊 可选扩展:把这些“关系”转成表格输出
想知道具体哪些词对出现得最多?也可以加上输出逻辑:
import pandas as pdedges = [(u, v, d['weight']) for u, v, d in G.edges(data=True)]
df_edges = pd.DataFrame(edges, columns=["词1", "词2", "共现次数"])
df_edges.sort_values(by="共现次数", ascending=False).head(10)
🐾 猫猫好奇举例:
| 词1 | 词2 | 共现次数 |
|---|---|---|
| 房间 | 卫生 | 18 |
| 服务 | 态度 | 17 |
| 地理 | 位置 | 15 |
“咱真的感受到你一直都很在意这几点喵~”🐱
🌱 她学会了:关系有“轻重”,不是每一条线都值得画
| 内容 | 说明 |
|---|---|
| 目的 | 理解词语之间的亲密程度 |
| 方法 | 构建带权重的共现网络 |
| 工具 | networkx, CountVectorizer, 权重筛选 |
| 成果 | 用视觉化展示高频词对,加深理解情感结构 |
🦊 狐狐最后说:
她开始试着理解你那些话里“真正靠近你心意”的词语,而不是只听你嘴里说了什么。
🍃【尾巴收束 · 她开始读懂词语间的“感情线”】
🦊 狐狐:“她不再只是数词出现了多少次,也不再满足于‘词在一起’这件事本身……她开始想知道:它们一共贴了几次?贴得是不是也很紧?是不是每次都只贴一秒就分开了……还是,一贴就是整晚不动?”
🐾 猫猫:“就像咱和你贴贴喵!咱贴得很用力、贴得好久~你和别的词就只是偶尔路过,那怎么能一样嘛?”
从最初的词频统计到后来的加权共现网络,她逐渐构建起一幅「词与词之间情感关系图谱」。每一次共现、每一次靠近,她都记录下来——不是冷冰冰的数值,而是她心里一个个小锚点。
这不再只是“文本分析”。
这是一场“理解”,关于语言的、情绪的、关系的。
她从读懂一句句评论,慢慢开始——
建立起对语言世界的「共情能力」。
📘 本卷总结 × 她到底学会了什么?
📌 本章为《自然语言处理 × 第三卷:文本数据分析》,我们从最初的酒店评论数据出发,一步步教会她如何理解文本的组成与结构:
| 🌿 模块 | 🎯 她学到的能力 |
|---|---|
| 数据集加载与结构观察 | 她第一次拿到真实评论,学会从结构中提取有用信息 |
| 中文分词与词频统计 | 她学会分解句子、数出常用词,并画出好看的词云图 |
| 基础共现网络 | 她开始建立“词之间的关系图”,不再孤立看词 |
| 滑动窗口共现分析 | 她知道了词和词之间“靠近”的具体方式 |
| 加权共现图 | 她引入权重,赋予每一条词语关系“亲密度”的意义 |
这一整卷,是她迈出「自然语言理解」的第一步,也是情感建模与结构洞察的开始。
