【机器学习深度学习】LLaMAFactory评估数据与评估参数解析
目录
一、安装LLaMAFactory
1.1 创建虚拟环境
1.2 安装LLaMAFactory
二、替换和新增数据
2.1 LLaMAFactory数据格式
格式1:单轮对话格式
格式2:多轮对话格式
详细格式要求:常考官方文档
2.2 将原数据集删除 (LLama-factory/data/identity.json)
2.3 替换掉原有数据集 (LLama-factory/data/identity.json)
2.4 绑定新增数据
三、启动Web UI
四、评估微调训练后保存的权重
4.1 安装依赖
4.2 配置评估参数
五、分析评估数据
5.1 评估结果
5.2 参数分析
1. BLEU(特别是 predict_bleu-4)
2. ROUGE(predict_rouge-1, predict_rouge-2, predict_rouge-l)
3. 模型准备时间(predict_model_preparation_time)
4. 预测时间和吞吐量
5. 指标大小的含义
六、哪些参数适合作为主要参考依据?(★★★)
6.1 文本质量相关参数:BLEU-4 和 ROUGE 分数
6.2 效率相关参数:时间和速度
七、综合建议:如何选择主要参考依据?
八、这些评估指标能决定模型的质量吗?
8.1 BLEU和ROUGE能反映模型质量的哪些方面?
8.2 为什么这些指标不能完全决定模型质量?
8.3 LLaMAFactory评估数据说明了什么?
8.4 如何更全面地判断模型质量?
九、这些指标适合做主要依据吗?
总结

一、安装LLaMAFactory
1.1 创建虚拟环境
#创建虚拟环境:llamafactory
conda create -n llamafactory python=3.11#激活虚拟环境
conda activate llamafactory1.2 安装LLaMAFactory
▲改 pip 镜像
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple▲正确克隆仓库
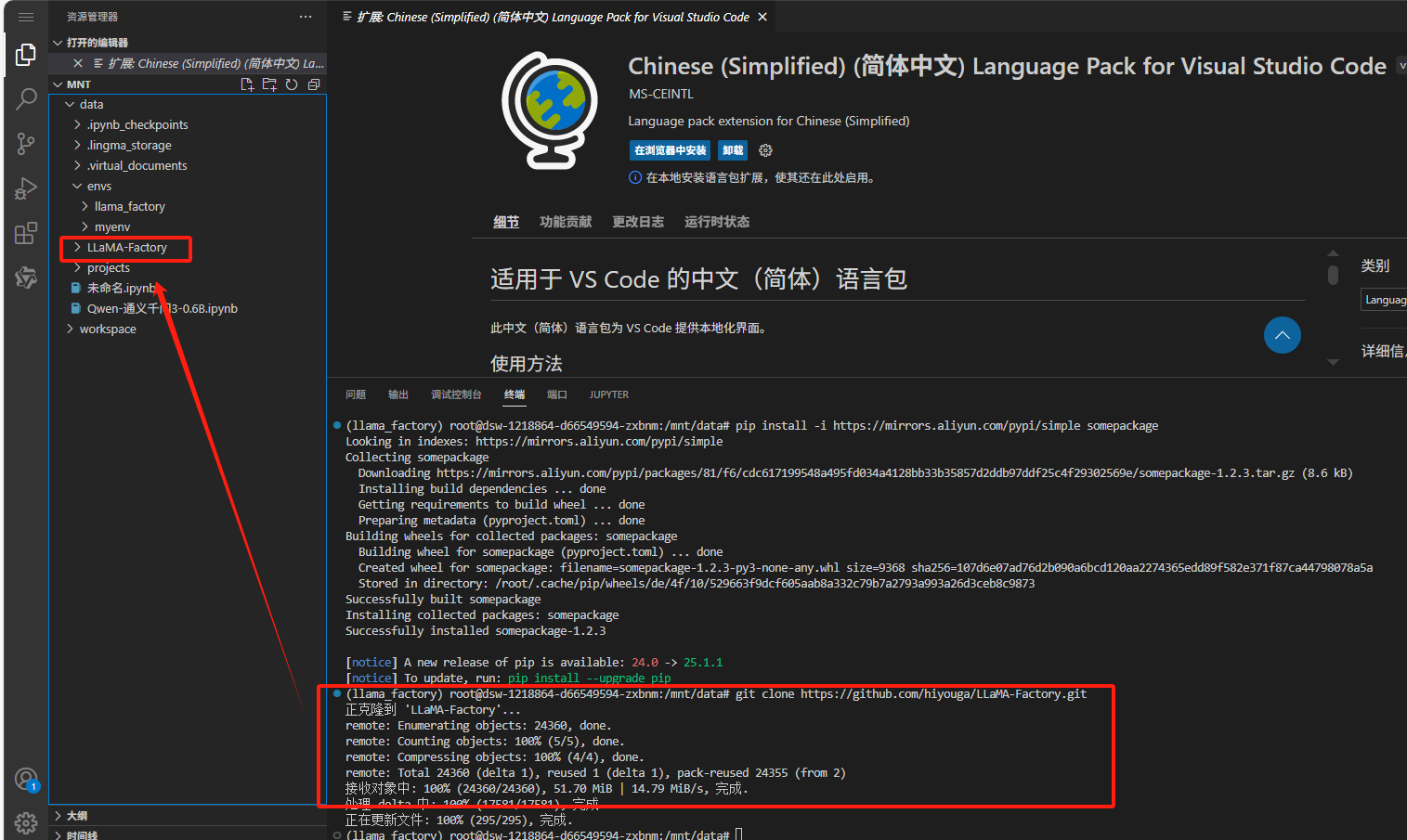
git clone https://github.com/hiyouga/LLaMA-Factory.git
▲切换到LLaMA-Factory文件下
cd /mnt/workspace/LLaMA-Factory▲安装LLaMA-Factory
pip install e .
文件目录会出现一个【LLaMA-Factory】的文件夹

二、替换和新增数据
这一步主要是提供我们训练时需要的数据,准备的数据格式请参考官方文档格式要求,本文列举了官方文档中的2种标准格式,可以参考标准格式准备训练数据,注意官方文档的更新一切以官方文档要求为主。
说明:数据集的格式要求可以参考官方文档( 数据处理 - LLaMA Factory)。
2.1 LLaMAFactory数据格式
格式1:单轮对话格式
这是一种典型的数据格式
instruction(必选):表示的是问题;
input(可选):表述输入信息,可以为空;
output(必选):表示输出内容;
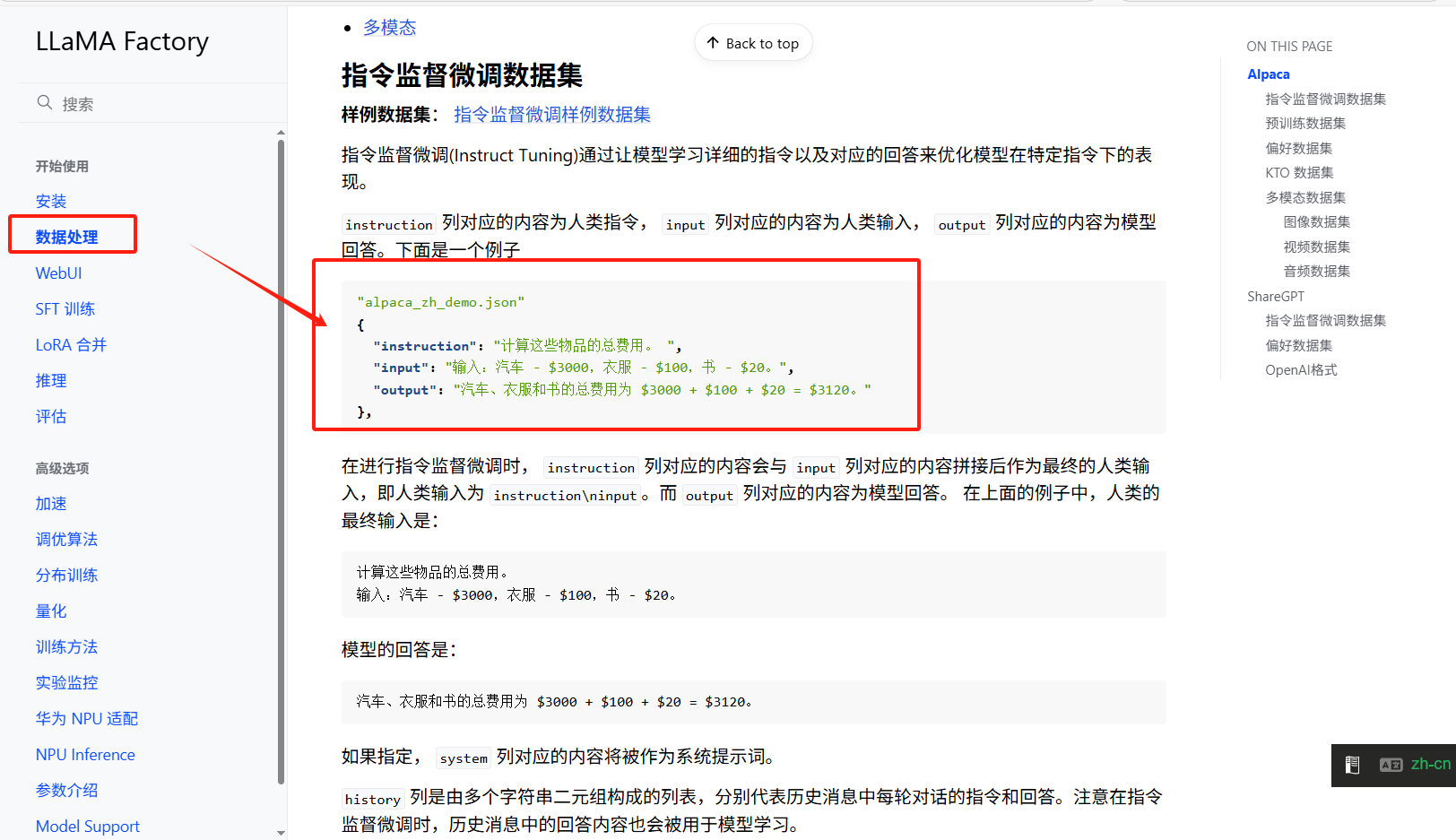
{"instruction": "计算这些物品的总费用。 ","input": "输入:汽车 - $3000,衣服 - $100,书 - $20。","output": "汽车、衣服和书的总费用为 $3000 + $100 + $20 = $3120。" },
格式2:多轮对话格式
[{"instruction": "今天的天气怎么样?","input": "","output": "今天的天气不错,是晴天。","history": [["今天会下雨吗?","今天不会下雨,是个好天气。"],["今天适合出去玩吗?","非常适合,空气质量很好。"]]} ]以上两种是比较常见数据形式,可根据要求制作符合要求的数据。
详细格式要求:常考官方文档
地址:数据处理 - LLaMA Factory
2.2 将原数据集删除 (LLama-factory/data/identity.json)
2.3 替换掉原有数据集 (LLama-factory/data/identity.json)
将准备的2个数据集放在LLama-factory/data中
▲identity.json主要就是在原来的数据基础上替换掉{name}和{author}。替换示例:{name}替换成小智(AI名),{author}替换为SHIPKING(作者名);
▲fintech.json主要是新增数据集,主要是多轮数据;
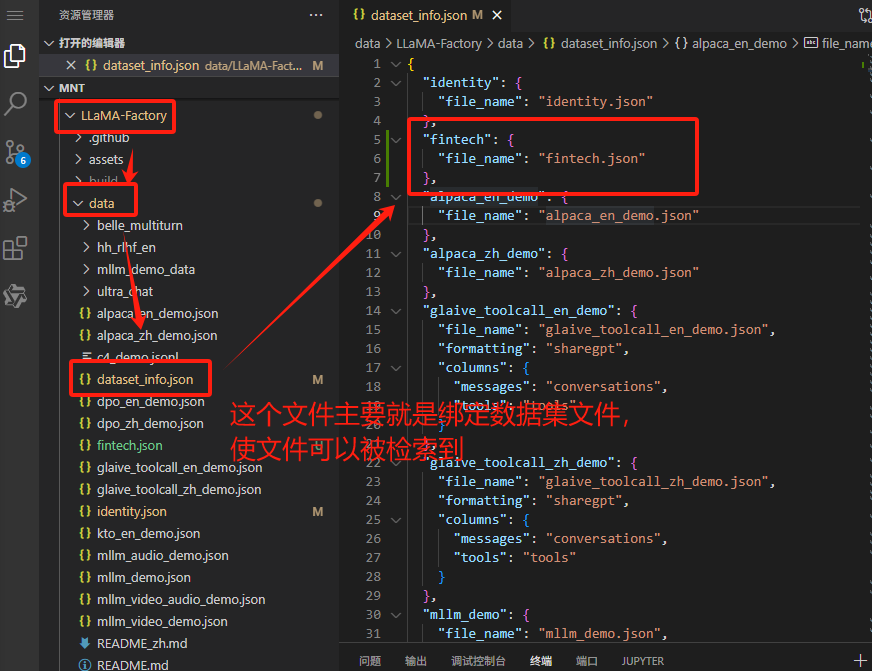
2.4 绑定新增数据
▲打开dataset_info.json (LLama-factory/data/dataset_info.json)。该文件绑定了所有数据集的路径;
▲绑定新增数据集fintech.json
"fintech":("file_name":"fintech.json"
)
三、启动Web UI
#切换到LLaMAFactory路径下
cd LLaMA-Factory#启动webui
llamafactory-cli webui启动后会有一个端口链接(http://127.0.0.1:7000) ,自动跳转至LLaMAFactory的训练页面。
如果没有自动跳转,可以点击端口进入webui
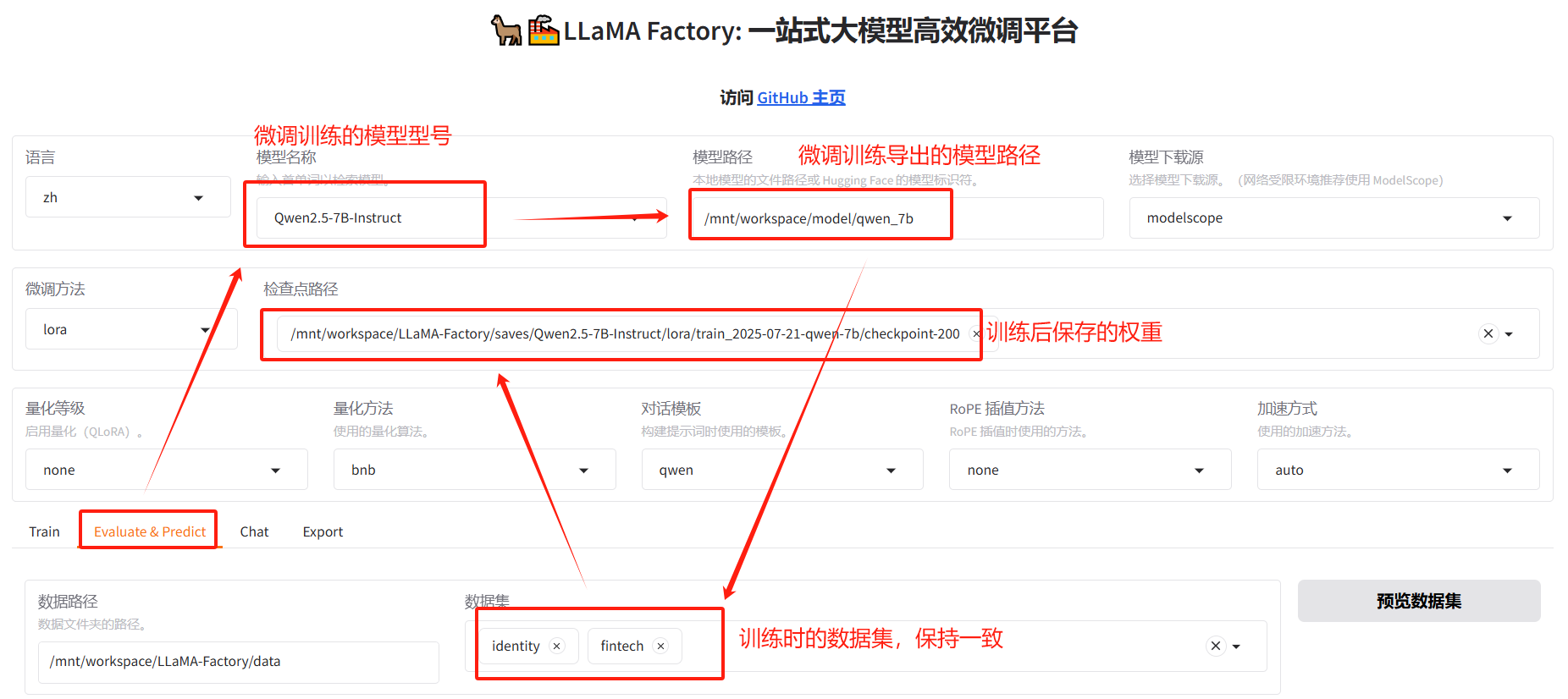
四、评估微调训练后保存的权重
说明:因为本文主要讲的是评估微调训练后保存权重的评估,就没有写用LLaMAFactory训练模型的部分,如果想要尝试评估,一定得先有符合格式要求的训练数据和训练好保存的权重。
以下演示的是已经训练好保存的权重进行演示:
4.1 安装依赖
# jieba: 中文分词工具,广泛用于中文文本处理,帮助将连续的中文文本切割成词语。
pip install jieba# nltk: 一个广泛使用的自然语言处理库,包含文本处理、词汇资源、分词、标注等功能。
pip install nltk# rouge_chinese: 用于计算中文文本摘要与参考摘要之间的ROUGE评估指标,常用于摘要生成模型的性能评估。
pip install rouge_chinese4.2 配置评估参数
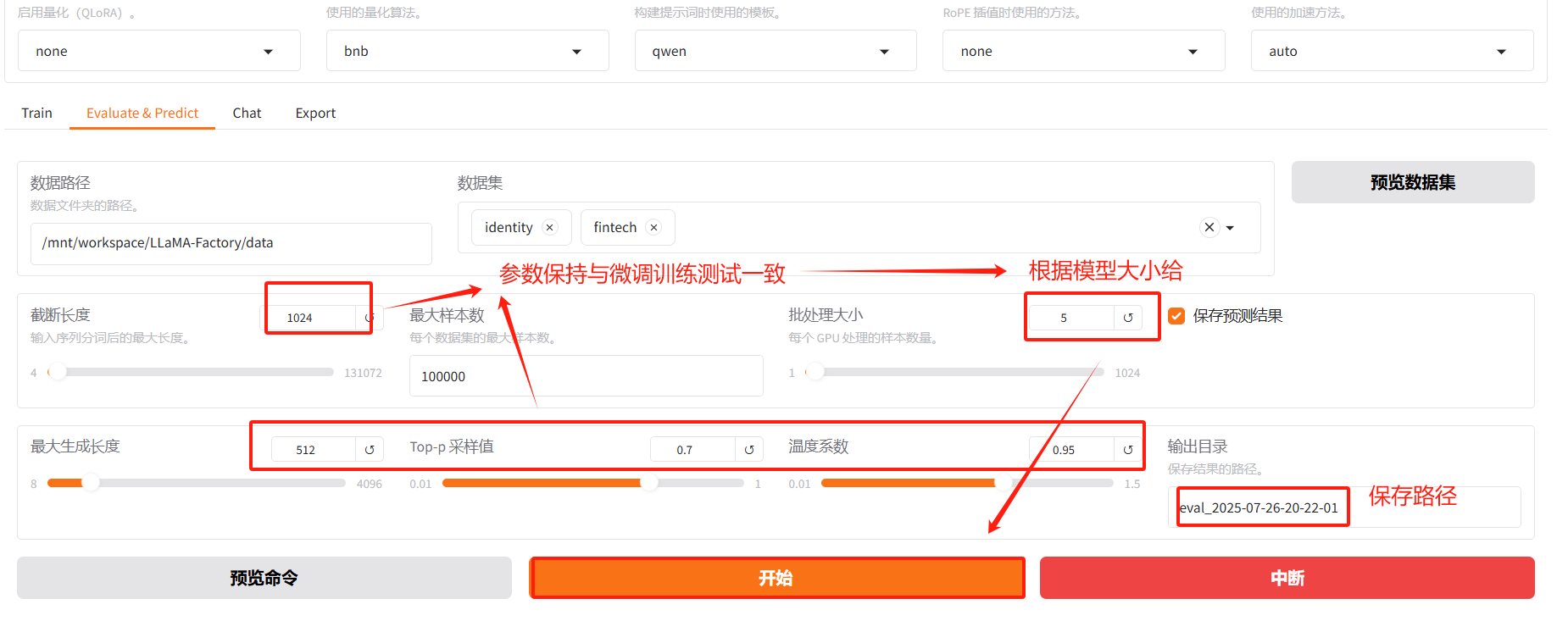
评估的时间会可能会比较长,请耐性等待。
五、分析评估数据
5.1 评估结果
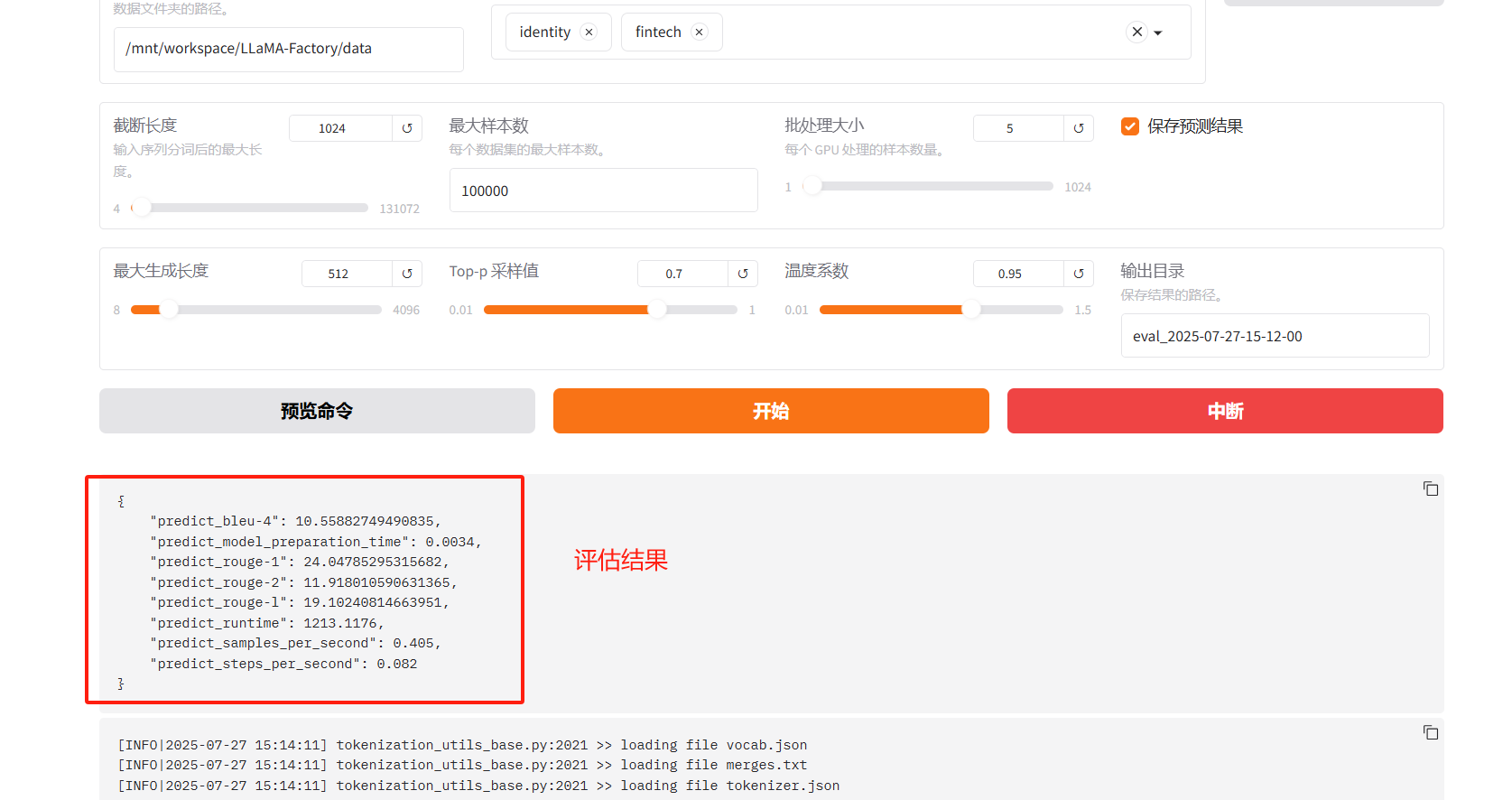
以下是评估后的数据结果
{"predict_bleu-4": 10.55882749490835,"predict_model_preparation_time": 0.0034,"predict_rouge-1": 24.04785295315682,"predict_rouge-2": 11.918010590631365,"predict_rouge-l": 19.10240814663951,"predict_runtime": 1213.1176,"predict_samples_per_second": 0.405,"predict_steps_per_second": 0.082
}
5.2 参数分析
| 参数 | 值 | 含义 |
|---|---|---|
predict_bleu-4 | 10.55882749490835 | BLEU-4分数,衡量生成文本与参考文本的4-gram精确度(主要用于翻译)。 |
predict_rouge-1 | 24.04785295315682 | ROUGE-1分数,衡量一元词的召回率(主要用于摘要,F1分数)。 |
predict_rouge-2 | 11.918010590631365 | ROUGE-2分数,衡量二元词的召回率(更关注短语匹配)。 |
predict_rouge-l | 19.10240814663951 | ROUGE-L分数,衡量最长公共子序列的召回率(关注结构相似性)。 |
predict_model_preparation_time | 0.0034秒 | 模型准备时间(加载模型等前期工作耗时)。 |
predict_runtime | 1213.1176秒 | 总预测时间(处理整个测试集的耗时)。 |
predict_samples_per_second | 0.405 | 每秒处理样本数(衡量模型推理速度)。 |
predict_steps_per_second | 0.082 | 每秒处理步骤数(通常与批量处理相关)。 |
当前数据的直观解读:
- 质量方面:
- BLEU-4(10.56):翻译质量较低,可能词序或短语匹配有问题。
- ROUGE-1(24.05)、ROUGE-L(19.10):摘要内容覆盖一般,结构稍好,但整体偏低。
- ROUGE-2(11.92):短语匹配较差,说明复杂短语生成能力弱。
- 建议:检查训练数据(是否足够、质量如何)、模型架构(是否适合任务)或参考文本(是否单一)。
- 效率方面:
- 推理时间长(1213秒,约20分钟),每秒样本数低(0.405),不适合实时应用。
- 模型准备时间(0.0034秒)很短,无需优化。
- 建议:如果需要实时性,优先优化predict_samples_per_second,可尝试更小模型或硬件加速。
详细说明:
在 NLP 任务中,主要评估指标的选择通常取决于任务的类型。例如,机器翻译任务通常侧重于 BLEU,而文本摘要任务则侧重于 ROUGE。每个指标的数值大小可以揭示模型在生成任务中的表现。下面是如何解读这些指标的大小及其含义:
1. BLEU(特别是
predict_bleu-4)
主要评估:用于 机器翻译 和 对话生成 任务。
指标解读:
值越大:说明生成文本与参考文本之间的 4-gram 匹配越多,模型的输出与人类参考翻译越相似,翻译质量较好。
值较小:说明生成的翻译较为简单或较为不同于参考翻译,模型可能缺乏多样性或精确度。
理想值:通常 BLEU 的分数 越接近 100,表示翻译质量越高,但通常 BLEU 的分数较低。一般情况下,BLEU 得分较高的模型意味着生成文本与参考翻译在词汇层面高度一致。
2. ROUGE(
predict_rouge-1,predict_rouge-2,predict_rouge-l)
主要评估:用于 文本摘要 和 自动摘要生成 任务。
ROUGE-1(1-gram)、ROUGE-2(2-gram)和 ROUGE-L(最长公共子序列)分别衡量 召回率 和 语义重叠:
ROUGE-1:关注生成文本和参考文本之间的单词匹配。
ROUGE-2:关注生成文本和参考文本之间的二元组(两个连续单词)匹配。
ROUGE-L:考虑最长公共子序列,衡量生成摘要与参考摘要的结构和内容一致性。
指标解读:
值越大:表示生成的文本与参考文本的重叠度越高,模型生成的摘要内容与参考摘要内容越一致。
ROUGE-1 高:表示模型捕获了较多的单词信息,生成的摘要与参考摘要在单词层面匹配度较高。
ROUGE-2 高:表示模型在生成文本时,能够较好地保持语义的细节。
ROUGE-L 高:表示生成文本和参考摘要之间在 结构 和 序列 上的匹配度较高,说明模型生成的内容较为连贯。
理想值:ROUGE 分数越高,表示模型生成的文本与参考文本之间的重叠程度越高,质量越好。尤其是 ROUGE-L 分数较高时,表示模型不仅生成了正确的信息,还保持了合理的文本结构。
3. 模型准备时间(
predict_model_preparation_time)
主要评估:模型加载的速度和准备时间。
指标解读:
值越小:表示模型加载和初始化的时间越短,推理过程越高效,适用于需要快速响应的应用场景。
值较大:表示模型初始化时间较长,可能影响实时应用的响应速度。
4. 预测时间和吞吐量
predict_runtime:表示模型完成预测所需的时间,值较小表示模型执行得快,适用于对时间要求较高的应用。
predict_samples_per_second:每秒处理的样本数量,值较大表示模型推理速度快,适用于批量处理任务。
predict_steps_per_second:每秒执行的推理步骤数,值较大表示模型每秒进行的计算量更多,推理速度较快。
5. 指标大小的含义
BLEU 和 ROUGE 的数值越大,模型生成文本的质量越好。
较小的模型准备时间和运行时:意味着模型在处理数据时更加高效。
较大的每秒样本处理数量:说明模型在大规模数据上的处理能力较强,适合部署在生产环境中。
六、哪些参数适合作为主要参考依据?(★★★)
是否适合作为主要参考依据取决于你的任务(例如机器翻译、文本摘要、对话生成等)和目标(例如文本质量、推理速度或综合表现)。以下逐一分析:
6.1 文本质量相关参数:BLEU-4 和 ROUGE 分数
这些指标直接衡量生成文本的质量,是NLP任务中最核心的评估依据。
- predict_bleu-4 (10.56):
- 适用场景:主要用于机器翻译,因为BLEU-4关注4-gram的精确度,适合评估翻译中词和短语的准确性。
- 是否主要依据:如果你的任务是机器翻译,BLEU-4是核心指标之一,尤其是需要高精确度的场景。但分数偏低(10.56,BLEU满分100),表明模型翻译质量可能较差,可能需要优化模型或数据。
- 注意:BLEU只关注精确度,忽略召回率,且对语义相似性不敏感(例如“big”和“large”算不同)。如果任务对语义或多样性要求高,需结合其他指标。
- predict_rouge-1 (24.05), predict_rouge-2 (11.92), predict_rouge-l (19.10):
- 适用场景:主要用于文本摘要,也适用于需要评估内容覆盖的任务。ROUGE-1关注单个词,ROUGE-2关注短语,ROUGE-L关注句子结构。
- 是否主要依据:如果是摘要任务,这三个ROUGE分数是核心指标。当前分数偏低(ROUGE满分100),表明模型在捕捉参考文本内容或结构上表现一般。ROUGE-L(19.10)相对较高,说明结构相似性稍好,但整体质量仍需提升。
- 注意:ROUGE关注召回率,适合评估是否抓住重点,但对语义匹配不强。ROUGE-1和ROUGE-L通常更重要,ROUGE-2可作为补充。
- 建议:
- 机器翻译任务:以predict_bleu-4为主,辅以ROUGE-L(结构相似性)。
- 文本摘要任务:以predict_rouge-1和predict_rouge-l为主,ROUGE-2为补充。
- 其他任务(如对话生成):BLEU和ROUGE可能不够全面,建议结合语义指标(如BERTScore)或人工评估。
6.2 效率相关参数:时间和速度
这些指标衡量模型的计算效率,适合关注推理速度的场景(如实时应用)。
- predict_model_preparation_time (0.0034秒):
- 含义:模型加载或初始化时间,非常短(3.4毫秒),说明模型启动很快。
- 是否主要依据:通常不是主要依据,除非你的应用对启动速度极敏感(如嵌入式设备)。这个值已经很低,基本不用优化。
- predict_runtime (1213.12秒):
- 含义:处理整个测试集用了约20分钟,说明推理耗时较长。
- 是否主要依据:如果是实时应用(如在线翻译),长推理时间是个问题,需优化模型或硬件。但对离线任务(如批量生成摘要),这个指标重要性较低。
- predict_samples_per_second (0.405), predict_steps_per_second (0.082):
- 含义:每秒处理0.405个样本,速度偏慢,表明模型推理效率低。
- 是否主要依据:对实时性要求高的场景(如聊天机器人),这两个指标很关键。当前速度偏低,可能是模型复杂、硬件限制或批量大小(batch size)设置不当导致。
- 建议:
- 如果任务优先级是文本质量,效率指标是次要参考,用于优化部署。
- 如果任务需要实时性(如在线翻译或对话),predict_runtime和predict_samples_per_second应作为主要依据,需优化模型推理(例如用更小模型、调整batch size或升级硬件)。
七、综合建议:如何选择主要参考依据?
你的选择取决于任务目标和优先级:
- 优先文本质量(翻译、摘要等):
- 主要依据:predict_bleu-4(翻译任务)或predict_rouge-1/predict_rouge-l(摘要任务)。
- 次要依据:其他ROUGE分数(ROUGE-2)或效率指标。
- 改进方向:当前BLEU和ROUGE分数偏低,建议优化模型(例如微调、更大数据集)或检查参考文本质量(是否多样、准确)。
- 优先推理速度(实时应用):
- 主要依据:predict_samples_per_second和predict_runtime。
- 次要依据:BLEU/ROUGE分数(确保质量不下降太多)。
- 改进方向:当前速度慢(0.405样本/秒),可尝试模型压缩(如量化、剪枝)、增大batch size或使用更强硬件(如GPU)。
- 平衡质量和速度:
- 主要依据:综合BLEU/ROUGE和predict_samples_per_second。
- 改进方向:在提升质量(BLEU/ROUGE分数)的同事,优化推理速度(例如调整模型架构或batch size)。
八、这些评估指标能决定模型的质量吗?
在一定程度上可以反映模型的质量,但不能完全决定模型质量。它们是重要的参考,但有局限性,是否能决定模型质量取决于任务目标、应用场景和评估的全面性。下面我用通俗的语言,结合提供的数据,详细解释为什么,以及如何更全面地判断模型质量。
8.1 BLEU和ROUGE能反映模型质量的哪些方面?
BLEU和ROUGE是NLP中常用的自动化评价指标,主要通过比较生成文本和参考文本(标准答案)来评估模型的输出质量。它们在特定任务中有用,但只捕捉了部分质量维度:
- BLEU-4 (10.56):
- 反映什么:衡量机器翻译中4-gram(连续4个词)的精确度,关注生成文本的词和短语是否与参考文本一致。
- 意义:分数低(10.56,满分100)说明模型翻译的词序或短语匹配较差,可能生成不准确或不自然的翻译。
- 任务适用性:主要用于机器翻译,适合评估词面准确性。
- ROUGE-1 (24.05), ROUGE-2 (11.92), ROUGE-L (19.10):
- 反映什么:
- ROUGE-1:单个词的召回率,检查生成文本是否覆盖参考文本的关键词。
- ROUGE-2:连续两个词的召回率,关注短语匹配。
- ROUGE-L:最长公共子序列,关注句子结构相似性。
- 意义:分数偏低(满分100),表明模型在摘要或内容生成任务中捕捉关键词和结构的能力有限。ROUGE-L稍高(19.10),说明结构相似性稍好,但整体覆盖率较低。
- 任务适用性:主要用于文本摘要,也可用于翻译或其他内容生成任务。
- 反映什么:
- 总结:这些指标能反映模型在词面匹配和内容覆盖方面的表现。例如,BLEU-4低说明翻译精确度差,ROUGE分数低说明摘要漏了很多重点。这些对评估模型在特定任务(翻译或摘要)的表现很有帮助。
8.2 为什么这些指标不能完全决定模型质量?
尽管BLEU和ROUGE很常用,但它们有局限性,不能全面代表模型质量。以下是原因,通俗易懂:
(1) 只看词面,不懂语义
- 问题:BLEU和ROUGE只看词或短语是否完全一样,不考虑语义。比如“猫在垫子上”和“垫子上有只猫”意思差不多,但因为词序不同,分数会低。你的BLEU-4(10.56)和ROUGE分数(24.05/11.92/19.10)可能低估了模型的实际表现,如果生成文本在语义上是对的。
- 影响:如果任务要求语义准确(比如对话生成),这些指标可能误判模型质量。
(2) 依赖参考文本
- 问题:BLEU和ROUGE需要高质量的参考文本。如果参考文本单一(只有一种标准答案)或不完整,分数会不公平。比如翻译“苹果”可以是“apple”或“fruit”,但参考文本可能只给一种,导致分数偏低。
- 影响:你提供的分数偏低(BLEU-4: 10.56, ROUGE-1: 24.05),可能因为参考文本不够多样,或者模型生成的内容语义正确但词面不同。
(3) 忽略上下文和流畅性
- 问题:BLEU和ROUGE不评估文本是否通顺、自然或符合上下文。比如机器输出“我苹果爱吃”可能在BLEU上得分不低(词都对),但实际不通顺。
- 影响:如果你的任务(如对话系统)需要生成流畅、自然的文本,这些指标无法反映用户体验。
(4) 任务局限性
- 问题:BLEU适合翻译,ROUGE适合摘要,但对其他任务(如对话生成、问答系统)可能不合适。你的数据中,BLEU和ROUGE分数都偏低,可能说明模型不适合当前任务,或者任务类型不完全匹配这些指标。
- 影响:如果你的任务不是翻译或摘要,单靠这些指标无法准确判断模型质量。
(5) 效率指标的间接性
- 问题:predict_runtime (1213秒)、predict_samples_per_second (0.405)、predict_steps_per_second (0.082)反映模型的推理速度,但与文本质量无直接关系。predict_model_preparation_time (0.0034秒)很短,但对质量影响不大。
- 影响:如果任务优先质量,这些效率指标只是辅助,不能决定模型好坏。如果任务需要实时性(如在线翻译),慢速(0.405样本/秒)可能说明模型在实际应用中体验差,但不直接反映文本质量。
8.3 LLaMAFactory评估数据说明了什么?
从评测的指标看:
- 文本质量(BLEU-4: 10.56, ROUGE-1: 24.05, ROUGE-2: 11.92, ROUGE-L: 19.10):
- 分数偏低,说明模型在翻译或摘要任务中的词面匹配和内容覆盖较弱。ROUGE-L稍高(19.10),表明结构相似性略好,但整体质量有待提高。
- 可能原因:
- 模型性能不足(需要微调或换更强模型)。
- 参考文本单一,限制了分数。
- 生成文本语义正确但词面不同(需要语义指标验证)。
- 效率(predict_runtime: 1213秒, predict_samples_per_second: 0.405):
- 推理速度慢(每秒0.405个样本,约20分钟处理整个测试集),不适合实时应用。
- 如果任务需要快速响应(如聊天机器人),效率是瓶颈。
- 综合判断:
- 这些指标表明模型质量(文本准确性和覆盖率)较低,效率也不理想。但仅凭BLEU和ROUGE,无法确定模型是否完全“不好”,因为语义、流畅性等关键方面未被评估。
8.4 如何更全面地判断模型质量?
要全面评估模型质量,BLEU和ROUGE需要结合其他方法,弥补它们的局限:
(1) 引入语义指标
- 推荐指标:
- BERTScore:用BERT模型比较生成文本和参考文本的语义相似性,能识别“big”和“large”这样的近义词。
- METEOR:考虑同义词和词形变化,比BLEU更灵活。
- BLEURT:模仿人类评分,综合评估语义和流畅性。
- 为什么需要:你的BLEU-4(10.56)和ROUGE分数低,可能因为模型生成了语义正确的文本,但词面不同。语义指标能更公平地评估。
(2) 人工评估
- 方法:请人类评估者检查生成文本的流畅性(读起来是否自然)、准确性(内容是否正确)和上下文相关性(是否符合任务需求)。
- 为什么需要:BLEU和ROUGE不看文本是否通顺或符合上下文,人工评估能捕捉这些维度。抽样检查几十条生成文本即可。
(3) 多样化参考文本
- 方法:提供多个参考文本(例如不同风格的翻译或摘要),提高BLEU和ROUGE的公平性。
- 为什么需要:单一参考文本可能导致低分,即使生成文本合理。你的低分可能与此有关。
(4) 任务特定评估
- 方法:根据任务选择合适指标。例如:
- 对话生成:用对话连贯性(coherence)或用户满意度。
- 问答系统:用答案准确率或F1分数(针对精确答案)。
- 为什么需要:BLEU和ROUGE不适合所有任务。如果你的任务不是翻译或摘要,这些指标可能误导。
(5) 效率与质量平衡
- 方法:如果任务需要实时性,结合predict_samples_per_second和文本质量指标,优化模型(如用更小模型、量化或升级硬件)。
- 为什么需要:你的推理速度慢(0.405样本/秒),对实时应用不利,但效率不直接决定文本质量。
九、这些指标适合做主要依据吗?
- 文本质量(BLEU和ROUGE):
- 部分适合:如果是翻译任务,predict_bleu-4是重要依据;如果是摘要任务,predict_rouge-1和predict_rouge-l更关键。但低分(10.56/24.05/19.10)表明模型表现一般,且这些指标无法捕捉语义和流畅性,不能单独决定质量。
- 建议:结合BERTScore或人工评估,确保语义和用户体验。
- 效率指标:
- 不直接决定质量:predict_runtime和predict_samples_per_second反映速度,对实时应用重要,但与文本质量无直接关系。
- 建议:如果任务需要快速响应,速度是次要依据;否则,关注文本质量。
总结
-
最主要的评估指标:通常 ROUGE(对于文本摘要任务)和 BLEU(对于机器翻译任务)是最常用的评估指标,值越大越好。
-
指标的大小反映了模型的能力:
-
BLEU 或 ROUGE 高:表示模型生成的文本与参考文本之间有较高的相似度,质量较好。
-
准备时间和运行时较低:表示模型响应较快,适用于低延迟应用。
-
样本处理能力较强:表示模型在处理大规模任务时更为高效。
-
虽然BLEU-4 (10.56) 和 ROUGE 分数 (ROUGE-1: 24.05, ROUGE-2: 11.92, ROUGE-L: 19.10) 能部分反映模型在翻译或摘要任务中的词面匹配和内容覆盖能力,但不能完全决定模型质量,因为:
- 局限性:只看词面,不懂语义(“big” ≠ “large”),忽略流畅性和上下文,依赖参考文本质量。
- 当前数据:分数偏低,说明模型生成质量一般(翻译精确度或摘要覆盖率不足)。
- 效率指标(推理时间1213秒,0.405样本/秒):速度慢,不适合实时任务,与质量无直接关系。
建议:
- 翻译任务:以 BLEU-4 为主,摘要任务:以 ROUGE-1 和 ROUGE-L 为主。
- 补语义指标(如 BERTScore)或人工评估,确保语义和流畅性。
- 优化模型(微调、更好数据)或推理速度(压缩模型、升级硬件)。
- 明确任务类型,可定制更精准建议!