[simdjson] 实现不同CPU调度 | 自动硬件适配的抽象
第八章:实现不同CPU调度
欢迎回来~
在前面的章节中,我们已经探索了如何使用simdjson的解析器、填充字符串、文档、值类型、对象与数组,学习了如何处理错误处理,甚至处理文档流。
我们已经看到simdjson的速度非常快。这种速度很大程度上源于现代CPU提供的高性能专用指令。但并非所有CPU都相同!在Intel芯片上可用的指令可能在ARM芯片或旧款Intel芯片上不存在。
这带来了一个挑战:如何让simdjson一次编译就能在不同CPU的计算机上实现最佳性能?这就是实现与CPU调度概念的由来。
挑战:不同CPU使用不同"语言"
将不同的CPU指令集(如SSE4.2、AVX2、AVX-512、ARM NEON等)视为不同的语言或方言。
为"AVX2语言"编译的程序在支持AVX2的CPU上运行很快,但在仅支持旧"SSE4.2语言"或完全不同语言(如ARM NEON)的CPU上根本无法运行。
如果simdjson仅提供最新CPU的优化代码,就无法在旧机器上运行;如果仅提供旧CPU的代码,在新机器上又无法发挥性能。
如何在不要求用户为每台机器单独编译的情况下实现最佳性能?
解决方案:编译多个版本,运行时选择
simdjson通过多个版本的核心解析逻辑解决这个问题。每个版本(即实现)都针对特定CPU家族的指令集进行了精心优化。
以下是simdjson可能包含的实现(取决于编译配置):
icelake:针对支持AVX-512指令的现代Intel/AMD CPU优化haswell:针对支持AVX2指令的CPU优化westmere:针对支持SSE4.2指令的旧款CPU优化arm64:针对使用NEON指令的64位ARM CPU优化ppc64:针对PowerPC CPU优化lsx/lasx:针对龙芯架构CPU优化fallback:不使用高级SIMD指令的基础版本,可在任何64位CPU上运行
默认编译时,simdjson会包含多个实现到最终库文件中。这会略微增加库体积,但提供了灵活性。
当程序首次使用需要特定实现的功能(如创建解析器或调用get_active_implementation())时,simdjson会执行快速检测:
- 检测当前CPU支持的指令集
- 检查库中编译的所有实现
- 选择当前CPU支持的最佳可用实现
这个过程称为CPU调度。simdjson会根据当前运行的CPU将核心解析任务分派给最适合的实现。
对于初级用户,这个过程是全自动的。我们只需包含<simdjson.h>,创建解析器,simdjson会自动为当前机器选择最快的代码路径。
查看当前激活的实现
虽然过程是自动的,但我们可以查看simdjson选择的实现。
#include <simdjson.h>
#include <iostream>int main() {// 创建解析器(若未检测则触发检测)simdjson::ondemand::parser parser;// 获取活动实现对象const simdjson::implementation* active_impl = simdjson::get_active_implementation();// 输出名称和描述std::cout << "Simdjson检测到并正在使用: " << active_impl->name();std::cout << " (" << active_impl->description() << ")" << std::endl;return 0;
}
运行

simdjson::get_active_implementation()返回指向当前选择的simdjson::implementation对象的指针,该对象提供name()和description()等方法。
列出可用实现
我们还可以查看编译进库的所有实现,即使当前CPU不支持。
#include <simdjson.h>
#include <iostream>int main() {std::cout << "Simdjson编译包含以下实现:" << std::endl;for (auto implementation : simdjson::get_available_implementations()) {std::cout << "- " << implementation->name();std::cout << ": " << implementation->description();if (implementation->supported_by_runtime_system()) {std::cout << " (当前CPU支持)";} else {std::cout << " (当前CPU不支持)";}std::cout << std::endl;}// 按名称查找特定实现(不存在返回nullptr)const simdjson::implementation* fallback_impl = simdjson::get_available_implementations()["fallback"];if (fallback_impl) {std::cout << "\nFallback实现可用。" << std::endl;}return 0;
}
示例输出(因编译而异):

(用到云服务器…)
simdjson::get_available_implementations()提供所有实现的列表,可通过名称访问。supported_by_runtime_system()检查当前CPU是否支持该实现。
手动选择(不建议初学者使用)
出于测试或特殊部署需求,可以手动指定实现,但通常不建议这样做,因为:
- 失去跨机器的自动优化
- 选择不支持的实现可能导致崩溃
如需手动设置,必须检查实现是否存在且被当前CPU支持:
#include <simdjson.h>
#include <iostream>int main() {const simdjson::implementation* chosen_impl = simdjson::get_available_implementations()["westmere"];if (!chosen_impl) {std::cerr << "错误: 当前构建未包含westmere实现。" << std::endl;return EXIT_FAILURE;}if (!chosen_impl->supported_by_runtime_system()) {std::cerr << "错误: 当前CPU不支持westmere实现。" << std::endl;return EXIT_FAILURE;}// 手动设置 - 风险操作!simdjson::get_active_implementation() = chosen_impl;// 新创建的解析器将使用'westmere'实现simdjson::ondemand::parser parser;const simdjson::implementation* active_impl = simdjson::get_active_implementation();std::cout << "手动设置活动实现为: " << active_impl->name() << std::endl;return EXIT_SUCCESS;
}
底层原理(简化版)
当创建解析器时,全局active_implementation指针初始为nullptr。
首次使用时触发检测流程:
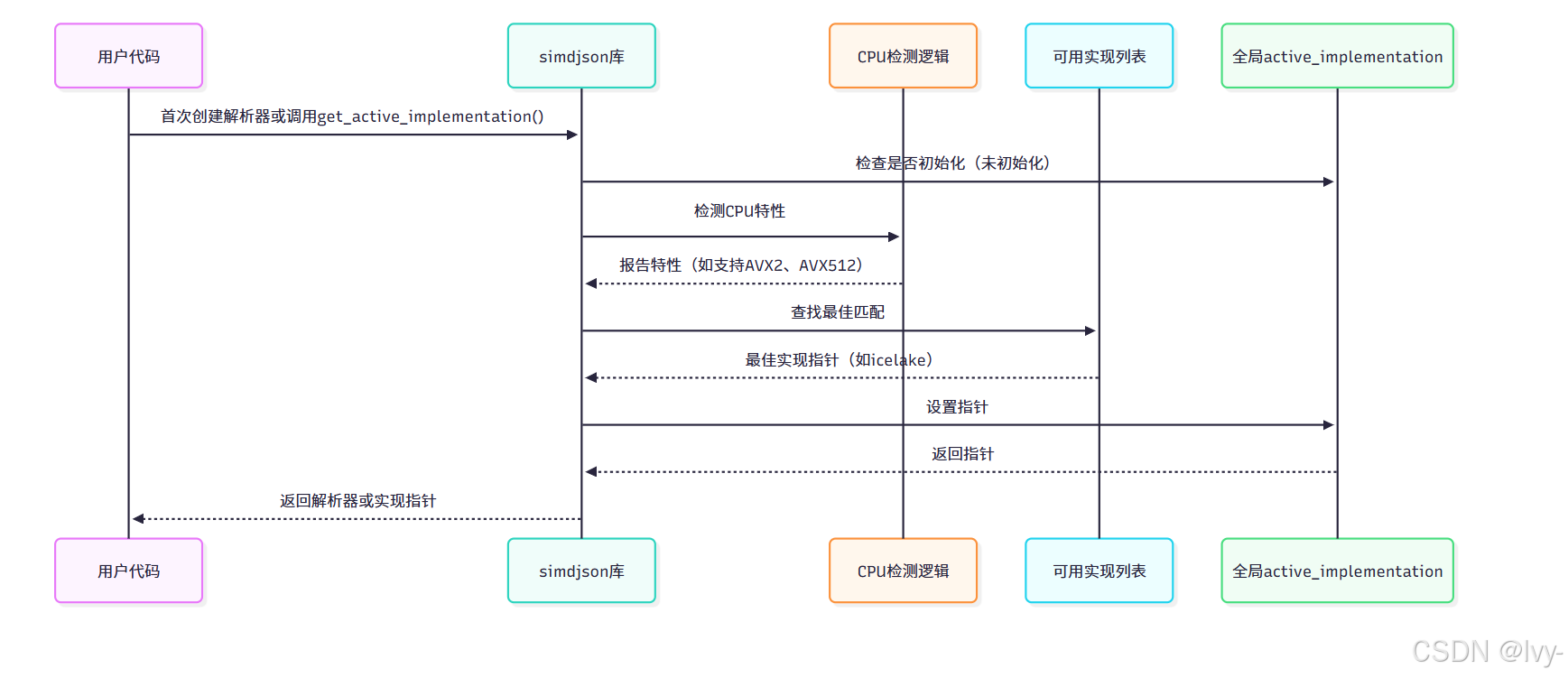
- 检测CPU支持的最高指令集
- 选择当前CPU支持的最快实现
- 设置全局指针指向该实现
- 后续解析操作委托给该实现
核心解析操作(parse、iterate等)最终委托给simdjson::implementation的虚方法。DOM解析通过internal::dom_parser_implementation实例执行架构特定的操作。
(多态 实现多设备兼容)
相关传送:
vela系统对于设备兼容的设计思想:[vale os_3] 文件系统/VFS | 网络协议栈
相关源码文件:
implementation.h:定义实现基类和全局访问函数implementation_detection.h:编译时预处理逻辑simdjson.cpp:运行时CPU检测逻辑- 各架构实现文件(如
haswell/implementation.cpp)
自动硬件适配的设计思想👆
通过分层抽象将硬件适配逻辑与业务逻辑解耦,利用多态和模板技术在编译期和运行期动态选择最优实现。
接口抽象层
implementation.h定义抽象基类implementation,声明所有硬件平台必须实现的统一接口方法。全局函数active_implementation作为访问入口,返回当前最优实现的引用。
检测机制分层
-
编译期检测通过
implementation_detection.h中的预处理器宏实现,根据__AVX2__等编译器定义宏筛选可用实现。 -
运行时检测在
simdjson.cpp中通过cpuid指令查询CPU特性,构建实现列表并按优先级排序。
自动化配置流程
架构实现文件(如haswell/implementation.cpp)注册到全局工厂。运行时首先执行detect_best_supported_implementation(),遍历所有已注册实现,通过supported_by_runtime_system()验证CPU支持性,最终选择最高instruction_set优先级的可用实现。
关键数据结构
// 实现描述符结构
struct implementation {const std::string name;const instruction_set instruction_set;virtual bool supported_by_runtime_system() const;virtual simdjson_result<element> parse(...) const = 0;// 其他统一接口...
};
性能优化点
- 实现选择仅在初始化时执行一次
- 通过虚函数表实现多态调用
- 各架构实现文件独立编译,避免条件分支影响性能
(异步架构和池化技术,也是为了实现解耦)
总结
simdjson通过编译多个优化版本和运行时自动选择实现跨CPU的高性能:
- 包含针对不同指令集的优化实现
- 首次使用时自动检测并设置最佳实现
- 所有解析操作委托给选定实现
- 支持查看活动/可用实现
- 手动选择存在风险,不建议常规使用
本系列教程到此结束,现在我们已经掌握:
- simdjson基础用法
- 按需API解析和导航JSON
- 错误处理和文档流处理
- 理解自动硬件优化机制
如需进阶功能和性能调优,请参考官方文档:https://github.com/simdjson/simdjson/tree/master/doc
END ★,°:.☆( ̄▽ ̄):.°★ 。