vivado IP核High speed/Low latency设置对系统性能的影响
vivado IP核High speed/Low latency设置对性能的影响
IP核不同的设置选择下对系统性能的影响
目录
前言
一、High Speed full DSP
二、High Speed no DSP
三、Low Latency no DSP
总结
前言
在使用 Vivado 设计时,IP 核配置是影响综合结果和时序性能的关键因素之一。特别是在涉及高速数据处理或对延迟敏感的应用场景中,Vivado IP 核常常提供 “High Speed” 与 “Low Latency” 两种优化选项。这两个选项分别针对吞吐率最大化与延迟最小化进行了架构级的调整,直接影响逻辑资源使用、寄存器分布、流水线深度及时序路径的分布。很多开发者在配置 IP 核时往往忽略了这些选项对实际时序性能的深远影响,甚至可能在满足功能的前提下埋下时序违例的隐患。本文将以实际示例出发,对比分析 Vivado 中Accumulator Floating Point IP在不同配置下的资源消耗和时序表现,帮助开发者在设计早期做出更合理的架构权衡,为实现更可靠的时序收敛提供参考。
提示:文章系笔者原创,侵权必究!
一、High Speed full DSP
本文以浮点累加器IP核为例,说明 “High Speed” 与 “Low Latency”两种优化选项对资源和时序性能的影响。
首先出场的是高速满DSP设置,性能拉满。其消耗的资源如下图所示。
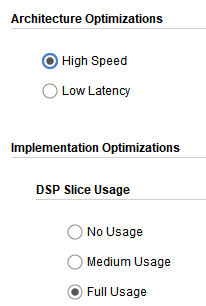
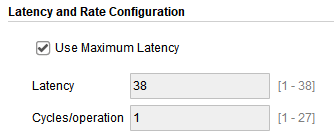
延时为38个CLK。

将该IP添加到笔者的设计中,工程主时钟约束为250MHz,综合出来效果如下,还不错,对于250MHz来说,裕量还比较多。

二、High Speed no DSP
接下来出场的是,累加器IP核设置为高速无需DSP,看其对资源消耗和时序性能的影响。由于不用DSP,逻辑资源的使用显然增加了。
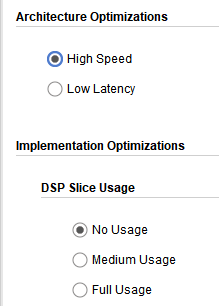
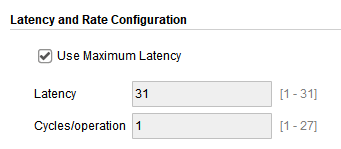
其延时比full DSP小了些,从38个CLK降为31个CLK,说明使用DSP会增加IP核的延迟。

对时序性能的影响,裕量减少了,但没有报时序违例,也还行。

三、Low Latency no DSP
最后出场的是低延时不使用DSP,可见延时确实相对于高速来说小了很多,资源的消耗也小了些,可是其出现时序违例了,违例还比较大。
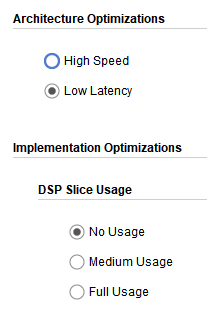
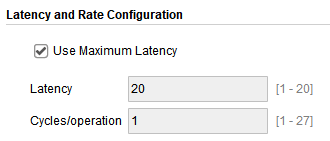
延时用高速的30多个CLK降为20个CLK,延时大大减少。

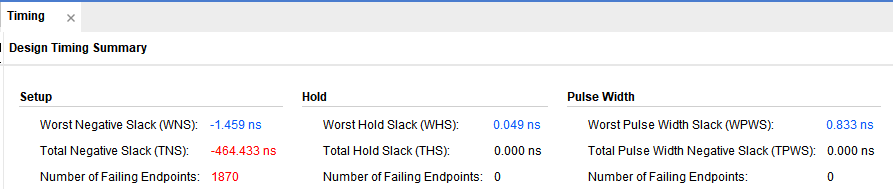
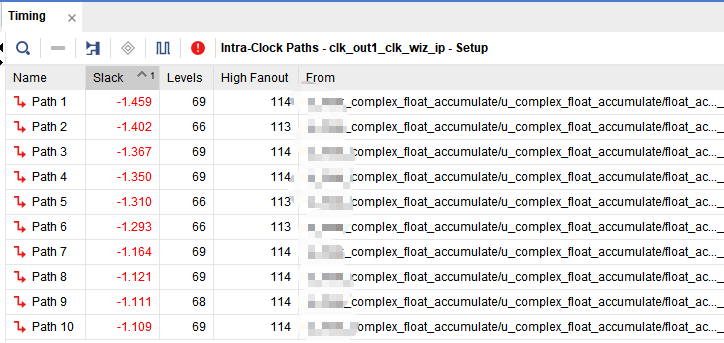
可见违例全是浮点累加器IP核产生的,这就是低延时的代价,虽然延时小了,但是系统可跑的主频降低了。
总结
本文以实际的例子介绍了IP核不同设置对系统的影响,一般来说,建议就是在资源充足的情况下尽量使用IP核中的高速设计,这样系统主频可以最大化,也能最小化系统延迟。