深入探讨redis:哨兵模式
目录
前言
手动恢复主从复制
自动恢复主从复制
使用docker搭建哨兵环境
编排主从节点
搭建哨兵节点
测试功能
哨兵重新选举主节点流程
前言
主从复制会出现一个问题就是,如果主节点和从节点主动断开,此时从节点可以自动变成主节点,如果主节点挂了那么从节点就无法实现数据同步了,虽然可以提供读操作,但是不能代替主节点的功能,需要手动恢复。哨兵机制就会对挂了的主节点进行替换。
哨兵节点就是一个监控redis数据节点(主节点和从节点)的节点,是一个独立的redis-sentinel进程。redis-sentinel进程并不负责存储数据,只是对其他redis-server进程起到监视作用。一般为了防止哨兵节点也挂了,会使用多个哨兵节点构成哨兵节点集合。
手动恢复主从复制
如果主节点发生故障,需要手动恢复,先看看原来的主节点是否可以快速恢复正常工作,如果可以就优先恢复原来的主节点。如果原来的主节点一时半会无法恢复正常工作,此时就需要程序员选择一个从节点手动将其变为主节点
- 首先通过slaveof no one断开这个从节点的主从连接,接着修改其他从节点的配置
- 修改其他从节点的slaveof主节点ip和port,连接上新的主节点
- 告知客户端(修改客户端的配置),让客户端能够连接主节点
- 之前的主节点恢复正常后可以作为从节点,连接上现在的主节点。
虽然可以手动恢复主从复制,但是在恢复期间服务器都不能进行写操作,会大大影响当前业务的正常运行。
自动恢复主从复制
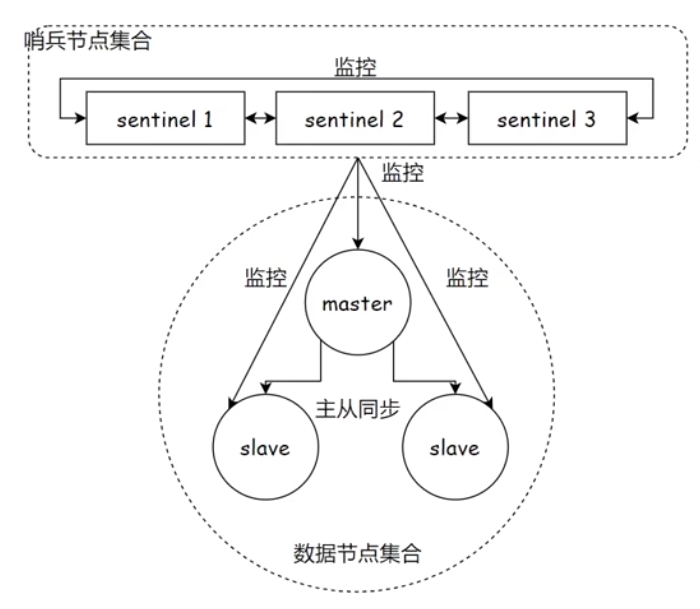
哨兵节点集合会自动对数据节点进行监控,哨兵节点会和数据节点建立tcp连接每隔一段时间就发送一个心跳包,如果能正常回复就认为数据节点运行正常。
- 如果主节点挂了,通过心跳机制就能及时发现,但是如果只是一个哨兵节点发现问题并不能触发自动恢复主从复制,因为有可能这个哨兵节点是因为自己的网络问题没能接收到数据节点的回应,所以只有当多个哨兵节点都发现异常才会认为,是真的出现问题
- 确定主节点挂了后,这些哨兵节点会选择一个代表,这个代表会从剩下的从节点中选出一个作为新的主节点
- 挑选完主节点后,哨兵节点就会自动控制新的主节点执行slaveof no one并且控制其他从节点修改配置,连接到新的主节点上。
- 哨兵节点会自动通知客户端新的主节点是哪个,后续客户端的写请求就会发送给这个新的主节点。
使用docker搭建哨兵环境
安装docker和docker-compose
#安装docker-compose
apt install docker-compose停止之前的redis服务
service redis-server stop停止redis-sentinel
service redis-sentinel stop先然后在使用docker获取redis的镜像
docker pull redis5.0.9这个就相当于是从github上拉取项目,docker pull使用的是docker的中央仓库,默认就是从docker hub上拉取镜像。(注意docker hub是国外的数据源,所以在拉取时很有可能会出现连接异常,从而无法获取,需要配置国内源)
拉取到的镜像,里面包含了一个精简的linux操作系统,并且上面会安装redis,只要直接基于这个镜像创建一个容器跑起来,此时redis服务器就搭建到了。
编排主从节点
我们使用docker来搭建哨兵环境,docker-compose来进行容器的编排(每一个redis server或者每一个哨兵节点都是一个容器),我们通过一个配置文件,把具体要创建哪些容器,每个容器运行的各种参数,描述清楚,最后通过一个简单的命令就能批量启动和停止这些容器了。
我们创建三个容器作为数据节点,另外三个容器作为redis哨兵节点,配置通过两个yml的格式的配置文件。其实也可以用一个yml文件直接启动6个容器,但是这样的话就有可能是哨兵节点先启动,数据节点后启动,在数据节点还没启动时,哨兵节点发出的心跳包没有回应就可能认为数据节点挂了,虽然这样影响不是很大,但是可能会对日志内容产生影响。
先创建一个文件夹
mkdir redis
cd redis
mkdir redis-data
mkdir redis-sentinel
cd redis-data然后创建和配置yml文件
vim docker-compose.yml配置yml
version: '3.7'
services:master:image: 'redis:5.0.9'container_name: redis-masterrestart: alwayscommand: redis-server --appendonly yesports: - 6379:6379slave1:image: 'redis:5.0.9'container_name: redis-slave1restart: alwayscommand: redis-server --appendonly yes --slaveof redis-master 6379ports:- 6380:6379slave2:image: 'redis:5.0.9'container_name: redis-slave2restart: alwayscommand: redis-server --appendonly yes --slaveof redis-master 6379ports:- 6381:6379
- services:表示有几个容器
- master/slave1/slave2:表示容器的名字
- image:表示基于哪个镜像创建
- container_name:表示容器名字
- restart:是否自动重启
- command:是对该容器redis执行的命令(修改配置),在配置主从节点时,不必写主节点ip直接写容器名就行,因为可能主节点ip会发生修改之类的,容器名就相当于域名,docker会自动对容器名进行解析,得到对应ip
- ports:表示端口映射,前面是我们自己主机的端口,后面是容器端口,每一个容器都相当于是一个小型的虚拟机,都有自己的6379端口,所以容器外面使用6379并不影响容器里面,各个容器之间也互相独立,如果在容器外想访问容器里的端口,就可以把容器内部端口映射成宿主机的端口。
yml配置好了之后就可以启动容器了
docker-compose up -d接着查看信息
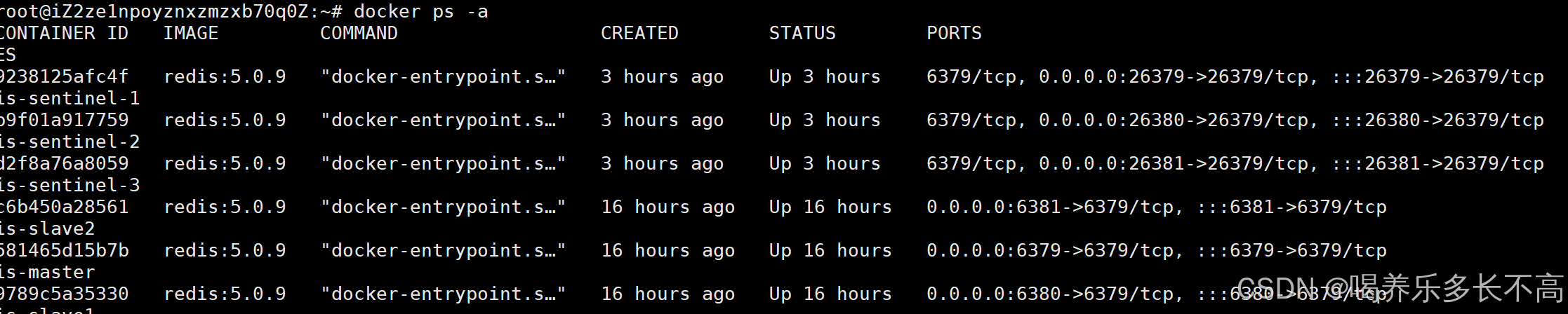
docker ps -a
也可以查看日志信息
docker-compose logs紧接着我们看看redis服务有没有启动成功
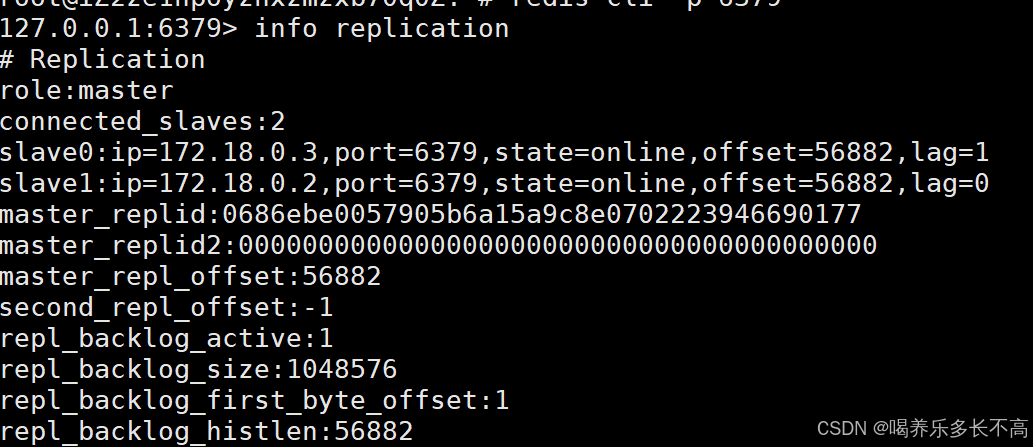
看以看到成功建立了主从结构
这两个从节点的ip都是由docker分配,其实装了dockers之后我们的机器上就会有一个单独的网卡来管理这些IP,这个分配的ip和宿主机是没有关系的。
搭建哨兵节点
搭建方式和刚刚的方法差不多,先进入刚刚创建的redis-sentinel目录创建创建yml文件
vim docker-compose.yml接着配置yml
version: '3.7'
services:sentinel1:image: 'redis:5.0.9'container_name: redis-sentinel-1restart: alwayscommand: redis-sentinel /etc/redis/sentinel.confvolumes:- ./sentinel1.conf:/etc/redis/sentinel.confports:- 26379:26379sentinel2:image: 'redis:5.0.9'container_name: redis-sentinel-2restart: alwayscommand: redis-sentinel /etc/redis/sentinel.confvolumes:- ./sentinel2.conf:/etc/redis/sentinel.confports:- 26380:26379sentinel3:image: 'redis:5.0.9'container_name: redis-sentinel-3restart: alwayscommand: redis-sentinel /etc/redis/sentinel.confvolumes:- ./sentinel3.conf:/etc/redis/sentinel.confports:- 26381:26379
这里内容大致和刚刚的差不多,不过有几处不同
volumes:进行配置文件的映射,但是因为哨兵节点在运行中可能会自动修改配置,使用不能共用一个配置文件,需要三个。
但是如果直接这样启动查看日志文件会发现报错
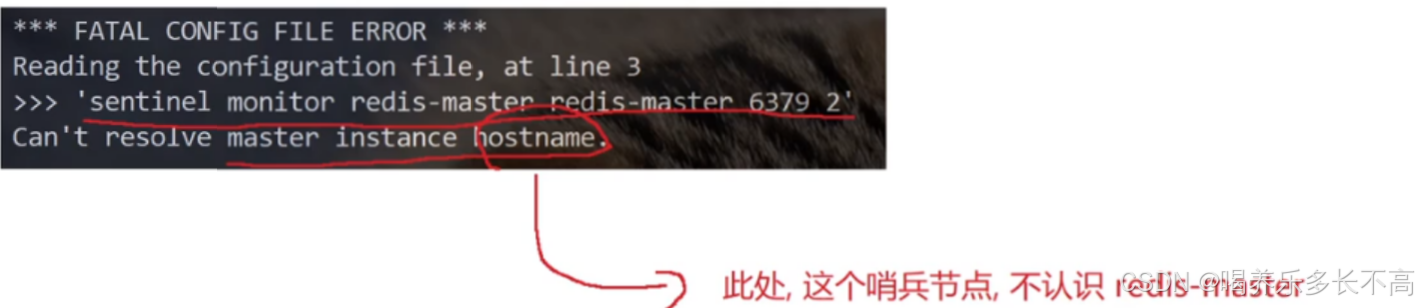
刚刚不是说docker会自动解析容器名获得对应ip吗,这里为什么又不认识了?
因为使用docker-compose一次性启动N个容器,这N个容器相当于处在一个局域网内,可以互相访问,但是我们创建的数据节点和哨兵节点是互相分开的,也就不在一个局域网内,所以无法访问。
解决方法就是使用docker-compose把这两组服务器放到一个局域网中
#列出当前docker中的局域网
docker network ls![]()
这就是刚刚创建的两个局域网,中间的是各自的网络名字
此时我们只需要给刚刚的docker-compose.yml添加配置,让新的局域网不自己创建而是加入到刚刚的数据节点的局域网中
networks:default:external:name: redis-data_defaul//注意这里的网络名字redis-data_defaul要和刚刚创建数据节点的网络名字一样
#如果docker已经启动可以使用这个命令停止
docker-compose down编写配置文件
vim sentinel1.confbind 0.0.0.0
port 26379
sentinel monitor redis-master redis-master 6379 2
sentinel down-after-milliseconds redis-master 1000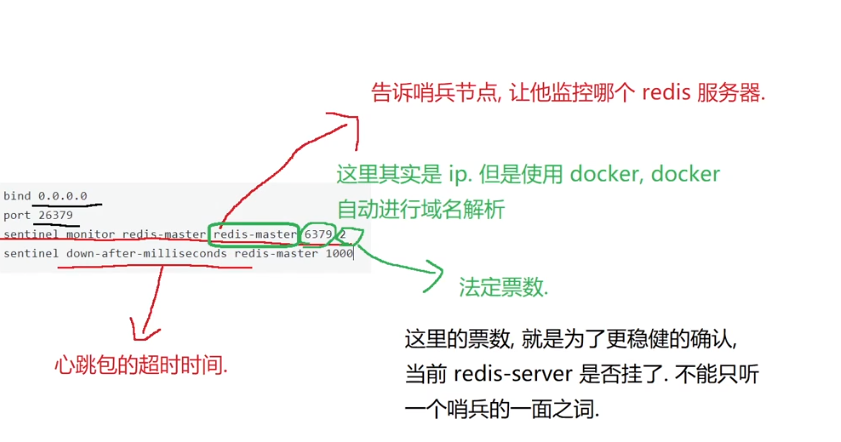
初始配置文件三个哨兵节点可以一致
cp sentinel1.conf sentinel2.conf
cp sentinel1.conf sentinel3.conf最后启动docker就行
查看容器状态如果是这样则说明启动成功
测试功能
我们搭建哨兵节点是为了随时检测主节点状态,以便在主节点挂了的时候,哨兵节点可以帮我们重新选则一个主节点出来,代替之前的主节点。
现在我们来手动关闭redis主节点服务
docker stop redis-master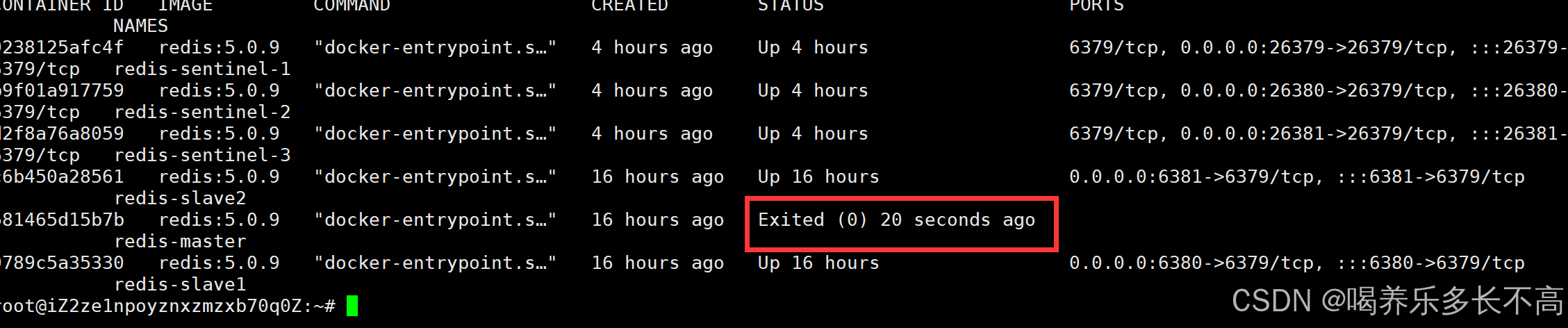
此时已经成功停止主节点服务
来查看哨兵节点日志
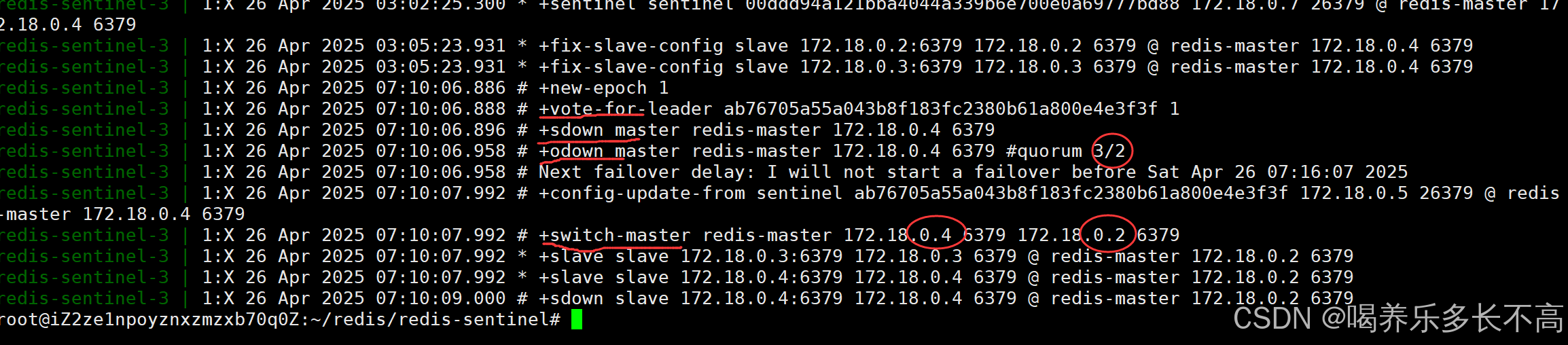
- sdown:主观下线,表示该哨兵节点认为主节点挂了
- vote:哨兵节点投票选出leader
- odown:客观下线,说明有好几个哨兵都认为主节点挂了,并且认为挂了的哨兵节点数达到了法定票数(就是之前配置文件里设置的)3/2,此时就说明主节点确实挂了
- switch:更换主节点,从0.4换为0.2

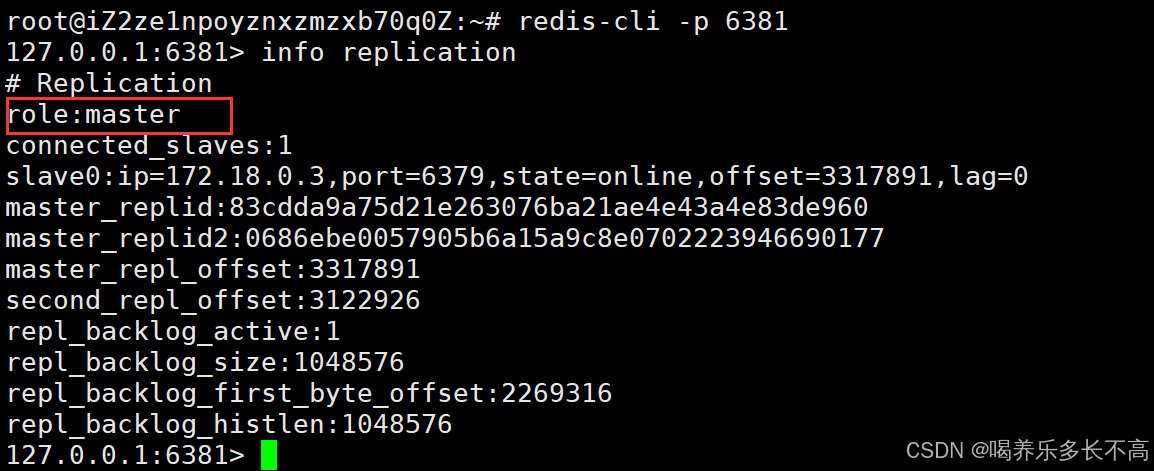 这时主节点已经成功更换为6381
这时主节点已经成功更换为6381
然后我们再重启之前的主节点看看是否可以连上
docker start redis-master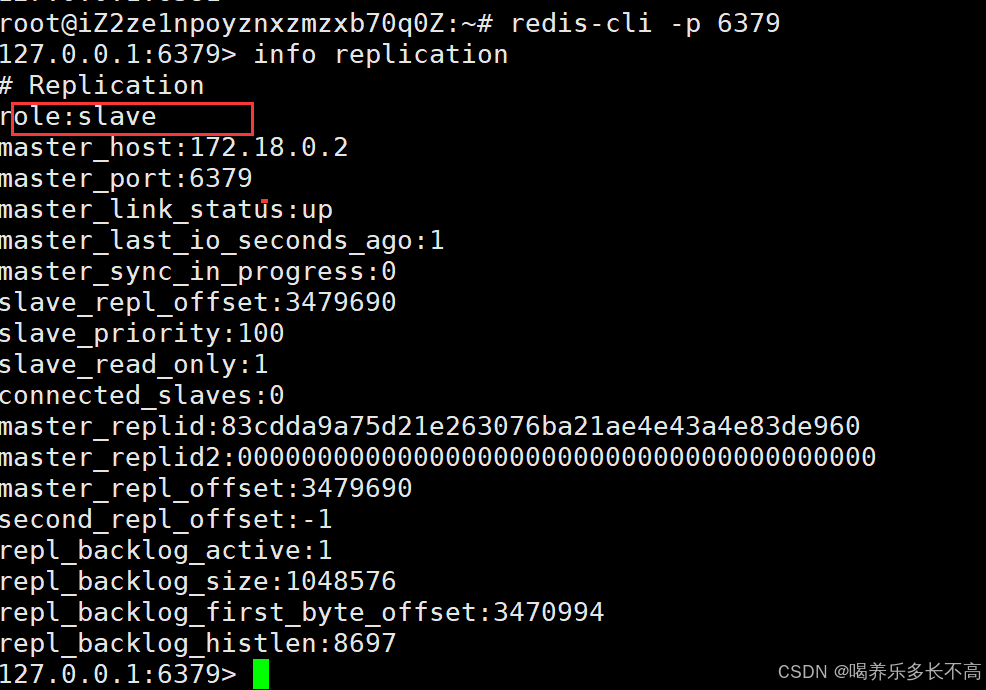
看以看到重新启动的6379只能作为从节点和现在的主节点6381连接, 说明我们的哨兵节点有在正常工作。
哨兵重新选举主节点流程
- 主观下线
哨兵节点通过心跳包判定redis服务器是否正常工作,如果没有收到回应,就认为redis服务挂了,但是也可能是因为网络问题没有收到,所以一个哨兵节点认为redis挂了还不行需要多个一起
- 客观下线
多个哨兵都认为主节点挂了,当这个数量达到法定票数,那么就一致认为主节点真的挂了
- 选出leader
确定主节点挂了之后,哨兵们会投票选出一个leader,由leader负责决定谁是下一个主节点
![]()
![]()

日志里可以看到每个哨兵节点的投票情况,而这个ab76705
而这个节点就是2号哨兵节点

所以是2号节点自投一票,然后1号,3号哨兵节点立马跟票最后由2号哨兵担任leader选出新的主节点。
会不会出现抢票?
每个哨兵手里只有一票,当哨兵2发现主节点下线后,就会自己投自己一票,并且立马给1和3发送消息,表示我来负责这个事,之后1和3就会把票都投给2,2发送消息的这个行为就类似于拉票,让1和3都来投自己,1和3收到拉票请求且手里有票就会毫不犹豫的把票投出去。其实这就是一个手慢无的过程哪个哨兵先发现主节点挂了并发起拉票请求,哪个哨兵就是leader。
当最后得票数超过总哨兵数得一般时,这个哨兵就是leader,为了方便投票一般会把哨兵节点设置为奇数
- 选取新的主节点
- 根据优先级:每个redis节点再配置文件中都会有一个优先级设置slave-priority,优先级高的节点就会被选上
- offset:当优先级一样时就会根据offet来决定,offet表示从主节点那边同步数据得进度,offset越大说明和主节点数据越接近,也就优先选举。
- run id:当前两个都一样时,就会根据redis得名字来决定,名字数值大的胜出(其实前两个都一样得话选哪个节点都一样了)
新的主节点选好后,leader就会控制这个节点执行slave no one,让其成为新的master,然后再控制其他节点,执行slave of,让这些节点以新的master为主节点。
⼀些注意事项:
- 哨兵节点不能只有⼀个.否则哨兵节点挂了也会影响系统可用性.
- 哨兵节点最好是奇数个.方便选举leader,得票更容易超过半数.
- 哨兵节点不负责存储数据.仍然是redis主从节点负责存储.
- 哨兵+主从复制解决的问题是"提高可用性",不能解决"数据极端情况下写丢失"的问题.
- 哨兵+主从复制不能提高数据的存储容量.当我们需要存的数据接近或者超过机器的物理内存,这样的结构就难以胜任了.