UniVLA-香港大学-单系统带导航-2025.5.9-开源
使用以任务为中心的潜在动作,学会在任何地方行动
https://github.com/OpenDriveLab/UniVLA
这个VLA是和RoboDual一个实验室出的,并不是双系统,并没有显式地把“快速反应”与“深度规划”分成两条网络路径,而是通过潜在动作解码器来模拟「下一秒会看到什么」(world model),并用策略头去预测接下来的动作(chunk),想一步走一步。
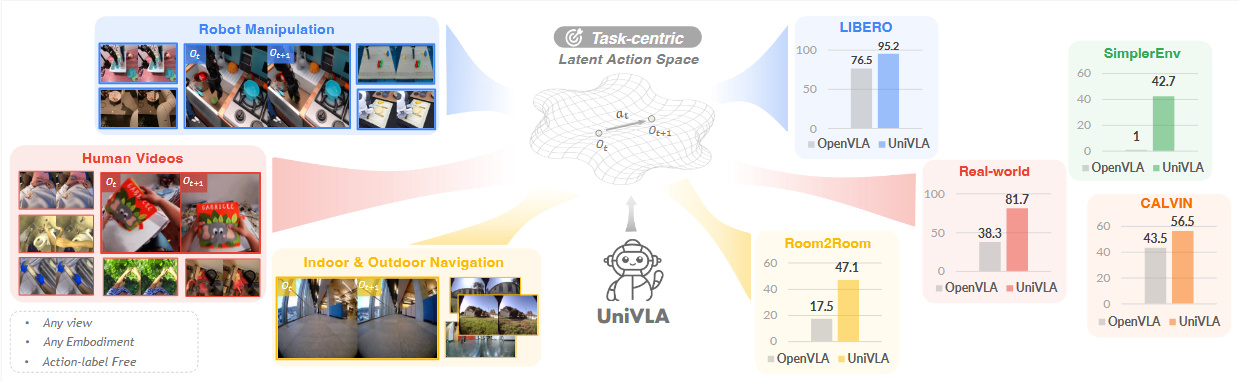
UniVLA 是一个统一 VLA 框架,使得策略能够跨越不同环境进行学习。
用 UniVLA,机器人在大棚里学会识别“成熟草莓”、“轻拿轻放”的动作后,也能直接搬到露天田地里用同一套策略去摘,不用从头再学?这个环境的跨度太大了,真能吗?
通过以任务为中心以无监督方式提取潜在动作,UniVLA 可利用任意载体和视角的数据,而无需动作标签。
可以用人演示的视频、架空臂的视角,甚至无人机俯拍,都能学?先质疑,是不是文字游戏
回答:大规模预训练时异构数据只是作为子集存在,其实用了很多Open-X等常规数据,Ego4D仅占3%;
预训练后进行的也是有监督微调,只是操控实验中有单独使用人类视频训练UniVLA,并非模型最终的主要训练途径。
在大规模视频预训练之后,UniVLA 形成了一种跨载体的通用策略,只需以极低的代价学习动作解码,就能在各种机器人上直接部署。
与 OpenVLA 相比,UniVLA 在多种操作和导航任务上均表现出一致的提升。
0. 摘要
海量有标注的数据不好搞,比如Helix用专家操作机器人录了500小时机器人自身相机的数据,而且现有方法难以跨越不同机器人形态和环境,这篇的关键创新是通过潜在动作模型,从视频中提取以任务为中心的动作表示。这使我们能够利用来自各种载体和视角的大量数据。
为了消除与任务无关的动态干扰,我们引入语言指令,并在 DINO 特征空间中构建潜在动作模型。在互联网级别的视频数据上学习得到的通用策略,可以通过高效的潜在动作解码部署到各种机器人上。
UniVLA 以不到 OpenVLA 1/20 的预训练计算量和 1/10 的后续数据量,实现了更优的性能。
随着将异构数据(甚至包括人类视频)纳入训练管道,我们观察到性能持续提升。
这是用什么类型数据训练差不多才加入其他来源的数据呢?
1. 介绍
得益于大规模机器人数据集的出现,基于VLA模型的机器人策略在最近取得了可喜的进展。然而,它们通常依赖真实动作标签进行监督,要标注海量网络视频几乎要耗费天文数字的人力和成本。
此外,不同载体(如 Franka 机械臂、WidowX 机械臂,甚至人手)以及不同任务(如操作与导航)在动作和观测空间上的多样性,对有效的知识迁移也构成了重大挑战。
这就提出了一个关键问题:我们能否学习一种统一的动作表示,让通用策略能够高效规划,从而释放互联网级视频的潜力,并促进不同载体和环境间的知识迁移?
就像大型语言模型(LLMs)能够学习跨语言的共享知识一样,我们的目标是构建一个统一的动作空间,以便在不同来源的视频数据——包括各种机器人演示和第一视角的人类视频之间——进行知识迁移。
我们的通用策略由三个关键阶段组成:
1)以任务为中心的潜在动作学习:通过无监督的方法,从大规模跨载体视频中提取与任务相关的动作表示。这一阶段我们借助 VQ-VAE,对成对帧的逆动力学进行离散化,得到潜在动作。
逆动力学的解释——“从相邻两帧预测出使它们连贯的动作”——正是 UniVLA 中 IDM的核心思路,只不过它预测的是一个潜在动作向量。
2)潜在动作预测:我们用这些离散化的潜在动作符号,训练一个自回归的VLM,模型不关心是具体什么机器人,只输出统一的潜在动作符号序列。
3)潜在动作解码:我们将潜在动作计划翻译为具体的物理动作,并对预训练的通用策略进行高效的专用化,以部署到未见过的任务中。
从网络级视频中学习潜在动作存在一个关键局限:简单的重建式目标往往会捕捉到与任务无关的动态行为,比如其他生物体的运动或不稳定的摄像机抖动,会被误学为潜在动作。
模型只是为了重现下一帧图像,而不区分这帧中哪些变化是“摘草莓”任务真正相关的。
为此,我们利用预训练的 DINOv2 特征从像素中提取 patch 级表,更好地捕捉与任务相关的信息。通过将现成的语言指令作为条件,我们进一步将运动拆分为两类互补的动作表示,其中一类明确对应任务中心的动作。
它的高效性源于其任务中心的潜在动作空间,它将与任务相关的动态与无关的视觉变化解耦开来,只关注“果实抓取”这条主线。
随着数据集规模增长,UniVLA 的性能不断提升,可高效利用跨硬件、跨视角的机器人数据集,甚至未标注的人类视频,来扩充预训练语料并提取可迁移知识。
当仅用 Bridge-V2 数据集进行预训练时,UniVLA 就能超越在更大规模 Open X-Embodiment 数据集上训练的 OpenVLA 和 LAPA,凸显了其从有限数据中提取可迁移知识的能力。
此外,我们使用了一个仅包含 1080 万参数的轻量级解码器,将潜在动作转换为可执行的轨迹,从而大幅减少了对大量微调工作的需求。这种设计利用了任务中心潜在动作空间的紧凑且富含信息的特点,使得 UniVLA 能在下游只需极少数据。
总而言之,主要贡献有三点:
- 提出了 UniVLA,使得通过网络级视频学习即可实现可扩展且高效的决策。
- 提出了一种从跨载体视频中提取与任务相关潜在动作的新方法,将任务中心的动态与无关的视觉变化解耦。定性和定量实验都凸显了其优于现有方法的优势。
- UniVLA 在多项基准与真实机器人测试中达到了最先进水平:在 LIBERO 基准上成功率较 OpenVLA 提升了 18.5%,在导航任务上提升了 29.6%,在真实部署中提升了 36.7%。
2. 相关技术工作
2.1 VLA模型
之前的一堆方法严重依赖带有真实动作标签的交互数据,这大大限制了 VLA 方法的可扩展性,要在更多场景或更多机器人上推广,就得重新采集、标注大量数据。
相比之下,我们的方法通过从视觉变化中学习统一的潜在动作表示,解放了对动作标签的依赖,从而能够利用互联网级别的无标注视频。
2.2 跨载体学习
由于不同机器人系统在摄像头视角、本体感知输入、关节结构、动作空间和控制频率上的差异,训练一套通用的机器人策略面临巨大挑战。现有方法需要大量且多样化的数据集来覆盖所有可能的状态转换模式,并且需要显式标注,导致数据利用效率低下。
我们的方法通过使用离散码本,以无监督方式对潜在动作进行编码,从而与众不同。通过向量量化有效滤除视觉噪声并实现高效的信息压缩,从而提升训练效率并减少对数据多样性的依赖。
2.3 潜在动作学习
近期研究将向量量化作为动作空间适配器,以便更好地将动作嵌入大型语言模型中。然而,这些方法的关键局限在于依赖真实动作标签,难以规模化扩展。
这三个的关键既然都是数据,那么把数据解决了,理论上确实迎刃而解。
为了利用更广泛的视频数据,Genie 通过因果潜在动作模型在预测下一帧的条件下提取潜在动作。类似地,LAPO 和 DynaMo 直接从视觉数据中学习潜在动作,无需在特定操控任务中使用显式动作标签。
模型根据当前帧和下一帧之间的变化,自动推断“是什么动作导致了画面变化”。
然而,这些方法会对所有像素变化进行编码,也会把与任务无关的动态(如摄像机抖动、他人活动或新物体出现)纳入表示,最终损害策略性能。
我们提出了一种新训练框架,将任务中心的动态与无关视觉变化解耦,构建更高效的潜在动作空间,以支持鲁棒的策略规划。
首先是没有大量专业的有标注的数据集,但是有互联网级别的无标注多载体的视频数据集,想要利用这部分数据集就得直接让模型学到潜在动作,但是因为有各种各样的干扰动作,所以需要一个主线任务去“解耦”,这样的逻辑应该是比较通顺的。
3. 方法论
3.1节,我们利用自然语言的任务描述,从大规模视频数据中以无监督方式提取逆动力学,并得到一组离散化的、以任务为中心的潜在动作,这些动作能够在多种机器人形态和应用场景下通用。
3.2节,在此基础上,我们训练了一个自回归的 Transformer 型 VLA,该模型以视觉观测和任务指令为输入,预测一系列在统一潜在空间中的动作符号。
3.3节,为了让模型能高效适配不同的机器人控制系统,我们为其引入了专门的策略解码头,将潜在动作符号解码为可执行的控制指令。
3.1 以任务为中心的潜在动作学习
第一步是为我们的方法框架奠定基础,通过生成伪动作标签(即潜在动作 token),为后续阶段训练通用策略提供依据。
潜在动作量化
图二展示了潜在动作模型两阶段的训练流程和整体架构。
第一阶段:利用预训练的 T5 文本编码器提取的任务指令嵌入,将其作为编码器和解码器的输入。这些嵌入提供了与任务相关的语义信息,以增强预测的准确性。
第二阶段:引入了一组新的潜在动作,专门设计用于替代语言的作用,并从 DINOv2 编码的视频帧特征中捕捉任务中心的动态。
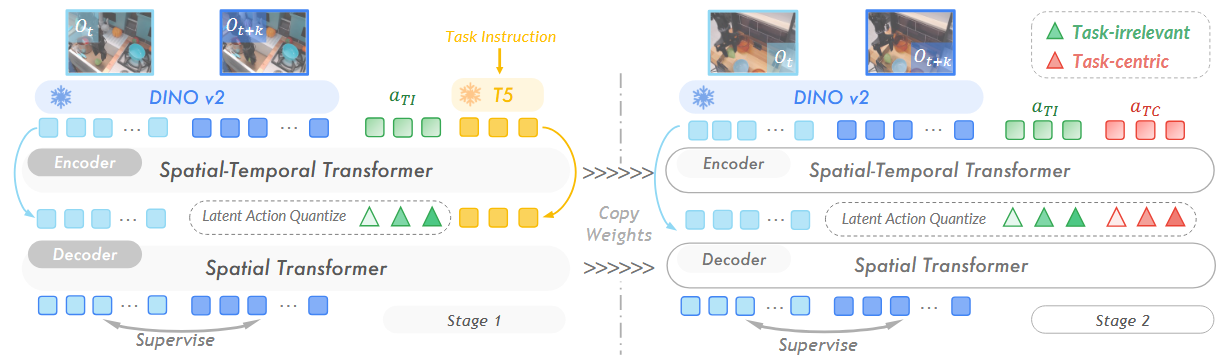
以两帧 {oₜ, oₜ₊ₖ}作为输入,相隔k帧,为了使不同视频源之间的时间间隔大致都为 1 秒,我们会根据各数据集的帧率来校准 k 值。
为了从视频中提取潜在动作,我们的模型由一个基于逆动力学的编码器 I(aₜ | oₜ, oₜ₊ₖ) 和一个基于正向动力学的解码器 F(oₜ₊ₖ | oₜ, aₜ) 共同构成。
编码器在给定相邻观测下推断潜在动作,解码器则在给定潜在动作后预测未来画面。将编码器实现为空间-时间 Transformer,并加入因果时间掩码。
并通过离散化和特征空间自监督预测,构建一个紧凑、去噪的动作表示,为后续通用策略学习提供坚实基础。
潜在动作解耦
如前所述,机器人动作在网络级视频中常常与无关的环境变化纠缠在一起。为了削弱这些与任务无关动态的负面影响,我们在潜在动作模型的第一阶段训练中引入了现成的语言指令(见图 2 左侧)。
这些语言输入由预训练的 T5 文本编码器处理,并作为条件信号同时作用于编码器和解码器的上下文中,为潜在动作提供了高级别的语义指引。
因此,离散后的潜在动作能够专注于记忆环境变化和视觉细节,而由于码本容量有限,它们不会重复编码由语言指令已覆盖的高级任务信息。
这一阶段生成了一套捕捉任务无关信息的潜在动作,与任务目标本身并行,并非核心。随后,我们保留第一阶段训练出的“任务无关”码本与参数,并在下一阶段利用它们,重点学习一套新的“任务中心”潜在动作。
基于已学得的任务无关表示,我们冻结对应的旧码本,只优化新码本,使模型专注于提炼并精化“任务中心”动作。
这个模块的设计灵感来自于现实世界中各种视频(农业监控、示范实录、人手采摘)所携带的海量非任务信息。UniVLA通过引入语言指令作为“关注键”,并分阶段学习,使得模型能够显式分离这两类信息:
先捕捉无关动态,再专注任务核心
3.2 通用策略的预训练
在前一步训练好潜在动作模型后,我们在已知后续帧 oₜ₊ₖ 的条件下,为任意视频帧 oₜ 打上潜在动作标签 a_z。
当摄像头拍到“果实在枝头”这一帧,并且后续一秒后的视频帧显示“果实离枝”时,模型就为第一帧打上“摘取”这一潜在动作标签。
通用策略以 Prismatic-7B 视觉-语言模型为基础,和OpenVLA一样的。
与之前那些直接用 LLaMA 罕用词映射到 [−1, 1] 连续动作区间的通用策略不同,我们在词表里新增了 |C| 个专用动作词元 {ACT_1, ACT_2, …, ACT_C}。潜在动作根据它们在码本中的索引,被映射到这些新加的动作词元上。
这种做法保留了原来 VLM 的模型结构和训练目标,能够充分利用其预训练知识来迁移到机器人控制任务。
此外,实验证明,将动作空间压缩(比如把 OpenVLA 的 2567 个词元缩到 |C|=16 时的 164 种组合)能够显著加快模型收敛速度。
我们的方法仅用 960 A100-小时预训练,就达到了可比性能,相比之下 OpenVLA 需要 21,500 A100-小时。
通过在统一的潜在动作空间里训练策略,模型能够利用从跨领域数据集中获得的可转移知识。因此,UniVLA 扩大了可用数据集的范围并提升了整体性能。
对草莓采摘机器人而言,这意味着它能高速吸收各类摘果示范,从而快速构建一套在多场景、多硬件平台上均鲁棒高效的“摘草莓”策略。
3.3 部署前的后训练
潜在动作解码
在下游适配阶段,预训练的通用策略依然保持与硬件无关,通过预测下一个潜在动作来驱动执行。为了将潜在动作与可执行行为衔接起来,我们引入了专门的动作解码器。
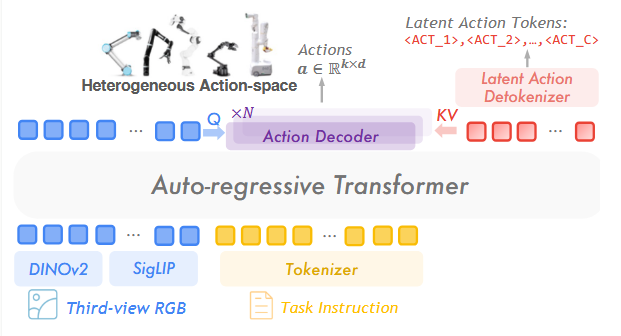
由于潜在动作是以约 1 秒为粒度设计的,它们可以自然地解码为一段段连续的动作块。可以根据不同机器人平台灵活调整动作块的步长,以实现更平滑、更精准的控制。
实际中,我们使用 LoRA 进行参数高效微调,以实现快速适配。整个模型端到端训练,即让模型学会“下一个应该是 ACT_4”,又让解码器保证“ACT_4”对应的关节角度能逼真还原实测动作。
从历史输出中学习
已有研究表明,历史观测对于提升机器人连续决策非常关键。然而,直接给大型 VLA 模型输入多帧历史观测,会带来推理延迟并产生大量冗余视觉信息。
借鉴 LLM 中“链式思考”(CoT)范式,我们提出利用历史潜在动作输出来辅助机器人决策。就像 LLM 一步步解决问题一样,我们在每个时间步将过去的动作 token 作为提示输入,形成机器人策略的反馈回路,让它能从自己的决策中学习并适应动态环境。
为了实现该方法,我们使用潜在动作模型为历史帧提取的动作打标签,然后将这些标签映射到 LLaMA 词表,并附加到任务指令中。
在后训练阶段,我们将历史动作 token 作为输入,使模型具备“上下文学习”能力。在推理时,每个时间步都会加入一段历史动作(N=4 个 token),但第一步除外。
4. 评估
在一系列多样的基准测试任务中评估了 UniVLA 的能力(包括操作任务的基准测试:LIBERO 、CALVIN 、SimplerEnv ,以及一个导航任务的基准:R2R ),同时也涵盖了现实世界的场景。此外,还进行了潜在动作分析,以量化其“以任务为中心”的特性,并进行了消融实验。
主要调查了三个方面:
- 性能与适应性
UniVLA 能否成功地将预训练过程中获得的知识迁移到新的实体和任务中,并高效地进行适应?操作适应性4.1;导航适应性4.1.2 - 泛化能力
UniVLA 如何在未见过的场景中进行泛化?(有关其在新环境中泛化能力的分析4.1.3) - 可扩展性
UniVLA 能否有效利用多样的数据源,甚至包括人类视频,并从不断扩展的数据集中获得可扩展的收益?(有关数据可扩展性的分析4.3节)
4.1 主要结果
4.1.1 LIBERO操控基准测试
实验设置
在以下三类数据上对完整的潜在动作模型进行预训练:操控数据、导航数据和人类视频数据,它们分别来自 Open X-Embodiment (OpenX) 数据集、GNM 数据集和人类视频(Ego4D) 的子集。具体细节见附录 A1。
LIBERO 基准测试包含四个任务集,专门用于推动机器人操控中“终生学习”研究。
我们的实验专注于在目标任务集上进行有监督微调,通过“行为克隆”——即模仿成功示范——来训练多种策略,并评估它们的表现。
如图 4 所示,我们的实验设置包括以下四个任务集,每个任务集包含 10 个子任务,每个子任务配有 50 次人类遥控示范。

- LIBERO-Spatial
需要模型推断空间关系,草莓机器人要根据果架高度和倾斜角度,将采下的草莓轻放到集果篮里的指定隔层,用来评估其几何推理能力。 - LIBERO-Object
保持场景布局不变,但改变物体类型,用来评估模型在不同物体(怪状草莓)实例上的泛化能力。 - LIBERO-Goal
保持物体和布局不变,但赋予不同的任务目标,同样是在草莓采摘场景,有时目标是“采摘最成熟的草莓”,有时是“只采摘指定编号的植株”,考察机器人能否快速切换目标。 - LIBERO-Long
专注于长时序的操控任务,包含多个子目标,涉及不同物体、布局和任务顺序,草莓机器人要先在果园中导航到指定行,然后判断果实成熟度→摘取→放入篮中→移动到下一个点,整个流程连续拍板,多步执行。
遵循 OpenVLA 中提出的数据处理流程,将失败示范剔除,不用于训练。UniVLA 在 LIBERO-Long 上训练 40,000 步,其它任务集上训练 30,000 步,整体批量大小为 128。我们仅使用第三人称视角图像和语言指令作为输入。
值得注意的是,LIBERO 里的示例未出现在策略的预训练数据中,也未出现在我们潜在动作模型的训练数据中,因此模型需要具备强泛化能力。
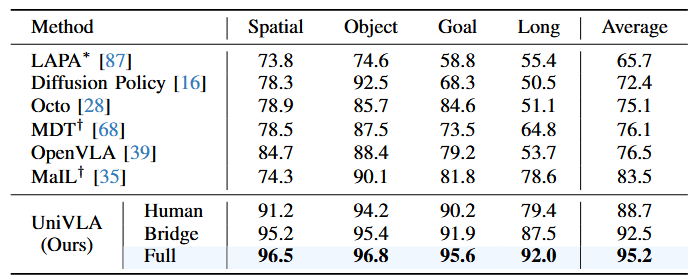
除了展示在全量数据上预训练的最佳模型结果外,我们还给出了仅在 Bridge-V2 数据上预训练的“Bridge”模型,以及仅在“Human”(人类视频)数据上预训练的“Human”模型在表 I 中的表现。
为了减少结果波动,所有方法在每个任务集上均运行 500 次试验(即每个子任务 50 次),报告的性能为三个随机初始化的平均成功率。
对比基线模型
- LAPA
LAPA 提出了一种从未标注的人类视频中无监督学习潜在动作的框架。 - Octo
Octo 是一种基于 Transformer 的策略,在多种机器人数据集上训练,使用统一的动作表示来处理异构动作空间。 - MDT
MDT 利用扩散模型生成灵活的动作序列,并根据多模态目标进行条件生成。 - OpenVLA
通过在包括 OpenX 在内的大规模多样数据上预训练,实现通用机器人策略。 - MaIL
MaIL 通过引入选择性状态空间模型来增强模仿学习(动态挑选对“摘草莓”关键的状态信息(果实位置、成熟度)),提高策略学习的效率和可扩展性。
实验结果
表 I 中的结果显示,UniVLA 在所有四个评估任务集上表现非常出色,显著优于 OpenVLA、LAPA 和 Octo 等先前的通用策略。即使只看一种数据,效果也能高一点。总之,UniVLA 展现了无与伦比的知识迁移能力,在 LIBERO 基准上创下了新纪录。
libero更适合知识迁移的这种场景,至于clavin目前他们还没进行实验,但在它们的list中
4.1.2 在 Room2Room 上导航标准测试
实验设置
在本实验中,我们在 VLN-CE 基准上评估 UniVLA,以考察其导航任务性能。
VLN-CE 是一套“视觉+语言导航”测试集,就像让草莓机器人一边接收“去那片草莓区”的口头指令,一边根据摄像机图像自主规划行走路线。VLN-CE 是对 R2R 的扩展。
这些基准提供了多个语言引导的导航任务,以及在重建的真实室内场景中执行低级动作的连续环境。
我们特别聚焦于 VLN-CE 中的 Room2Room(R2R)任务,该任务是视觉—语言导航领域最具影响力的基准之一。所有方法都在 R2R 训练集的 10,819 条示例上训练,并在 val-unseen(未见)集的 1,839 条示例上评估。使用“Oracle 成功率”来评估导航性能。如果智能体最终距离目标点 3 米内,即判为一次成功。
Oracle 成功率是只要机器人最终抵达目标(在给定容差范围内),就算成功;不考虑路径是否最优。
在草莓采摘中3M太远了吧,要求离得更近的话成功率应该还会下降不少,后面可以测试一下
对比基线
所有方法均只能使用“RGB 图像”输入,不得借助深度或里程计数据,只在 VLN-CE 环境中直接预测低级移动动作:
- Seq2Seq
基于循环神经网络的“从图像到动作”序列到序列策略。 - CMA
交叉模态注意力(Cross-Modal Attention)将语言指令与 RGB 图像融合,用于动作预测。 - LLaVA-Nav
将 LLaVA 微调用于导航,借助 NaVid 提供的数据,并参考之前的轨迹记忆。 - OpenVLA
我们为导航动作设计了特殊 Token,在 R2R 训练集上对其进行了微调。 - NaVid
大型视频导向视觉-语言模型,编码所有历史 RGB 观察,用预训练视觉编码器和 LLM 预测动作。
在下图 6 中,我们展示了各方法的 Oracle 成功率。仅使用单帧 RGB 图像作为输入,UniVLA 显著优于 Seq2Seq 和 CMA,将成功率从 8.10% 提升至 47.1%。鉴于 LLaVA-Nav 在调用历史信息时计算开销过大,我们参考 NaVid,并在 100 条 R2R val-unseen 子集上给出其结果。
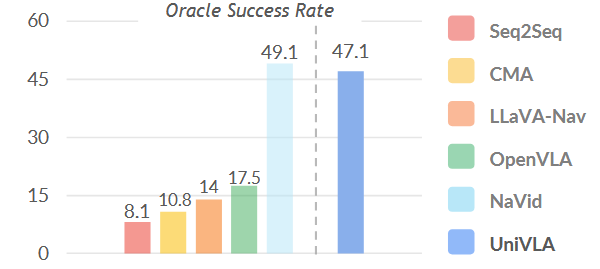
此外,UniVLA 的成功率已可与 NaVid(需编码所有历史画面)相媲美,而 UniVLA 仅依赖当前画面与历史“潜在动作”信息。
4.1.3 真实机器人部署
实验设置
所有真实机器人实验均使用 AgileX Robotics 生产的 Piper 机械臂(具有 7 自由度动作空间)和第三视角的 Orbecc DABAI RGB-D 相机,但我们只使用相机的 RGB 图像作为输入。
为了评估各种策略的能力,我们设计了一套全面的任务,涵盖不同维度的技能,包括:
- 空间感知
拿起螺丝刀放进柜子里并关上柜门 - 工具使用与非抓持操作
拿起扫帚,将切菜板上的东西扫入簸箕(“清理切菜板”)。 - 可变形物体操作
将毛巾对折两次(“折叠毛巾两次”)。 - 语义理解
先把中等大小的塔块放到大块塔上,再把小的放到中块塔上。
每个任务收集 20 到 80 条示范轨迹,数量依据任务难度调整,用于微调模型。为了全面评估泛化能力,我们设计了多维度的未见情景测试,包括光照变化、视觉干扰物以及物体泛化(见图 7)。
单一“成功率”难以全面衡量策略性能,我们引入了一种分步骤评分体系。对以上四个任务,各设 3 分满分,对应任务执行中不同阶段的完成情况。详细评分标准、任务设置和实验结果见附录 C。

对比基线
- Diffusion Policy
单任务扩散模型,专门优化单一路径精度和低延迟控制。 - OpenVLA 与 LAPA
两个通用策略,OpenVLA 在大规模机器人数据上预训练;LAPA 利用人类视频无监督学习潜在动作。为了公平对比,把 LAPA 用与我们相似的 Prismatic-7B 模型和动作解码头重现一遍。
实验结果
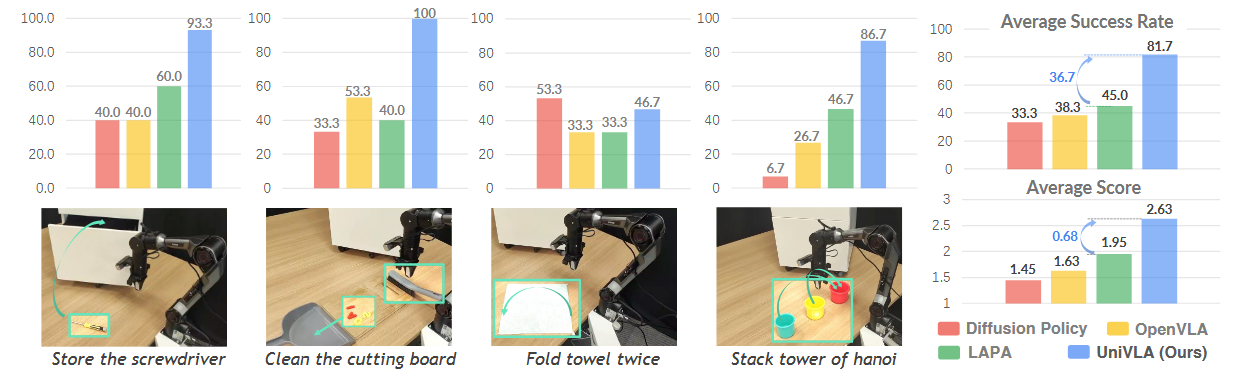
单任务 Diffusion Policy(DP)因对特定路径的精确优化,在“折叠毛巾”这种一旦边缘选定就按固定轨迹执行的任务中表现最佳。在该任务上,DP 成功率为 53.3%,高于 UniVLA 的 46.7%。
然而,UniVLA 在分步评分上得分更高(2.47 对比 DP 的 2.33,详见附录 C),说明即使最终没完全成功,它依然能稳健地完成中间步骤(如边缘对齐、部分折叠),这在动态真实环境中尤为重要,因为阶段性进展也很有价值。
DP 的单任务训练最大化了特定流程的轨迹精度,但在需要语义推理的任务上表现欠佳(如汉诺塔任务,DP 仅 6.7% 成功率)。相对地,UniVLA 展现出优异的泛化和语义理解能力,成功率达到 86.7%。
在“收纳螺丝刀”这类对物体操作和空间推理要求极高的场景中,UniVLA 的成功率高达 93.3%,进一步证明了其能力。
此外,我们的方法在 NVIDIA RTX 4090 GPU 上以紧凑的潜在动作空间进行规划,并支持高效的动作批量预测(实际中使用批量大小 12),实现了10Hz的闭环推理频率。
总之,UniVLA 在成功率上比第二名 LAPA 高出 36.7%,在平均评分上高出 0.68 分。
泛化能力分析
从三个方面研究了策略的泛化能力,具体实验设置见图 7。表 II 的结果凸显了 UniVLA 卓越的泛化能力,在成功率和分步评分上显著优于各对照方法。可以在github看视频演示。
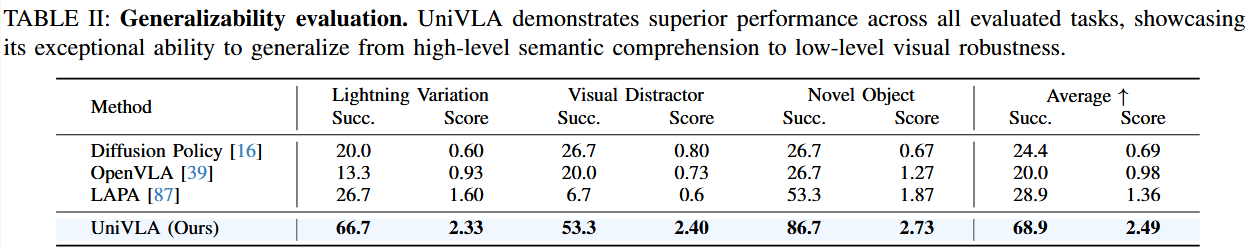
在不同光照条件下,UniVLA 成功率达 66.7%,显示其对环境变化的鲁棒性。
在有视觉干扰物的场景中,依赖语义信息较多的策略(如 LAPA 和 UniVLA)表现会有所下降。
在新物体测试中,我们将螺丝刀换成了马克笔,并相应修改了语言指令。对此,UniVLA 仅下降 6.6%,影响极小。
4.2 讨论潜在动作
4.2.1 定性分析
我们通过图 8 中不同数据源但相同潜在动作的图像对,研究潜在动作在跨领域间的迁移能力。

每一行都是相同的潜在动作,比如捡起东西,放下东西,前进,每组都有不同的数据来源,包括最后一列的人手操作视角。
值得注意的是,我们的潜在动作模型在训练时没有使用任何 LIBERO 数据,却能对该数据集中从未见过的示范进行准确标注。
此外,如 C 组所示,LAM(潜在动作模型)学会将操控中的“腕部视角”画面,与导航中的“第一人称视角”动作对齐,突显了它在不同模态与主体之间搭桥的能力。
4.2.2 定量分析
为了评估我们提出的“任务中心动力学分解”方法在潜在动作学习中的有效性,我们比较了使用不同潜在动作标签训练出的策略的部署表现。LIBERO 上的结果见下表表 III。我们仅用包含大量不可预测运动的人类视频来预训练策略,以更突出本方法的优势。
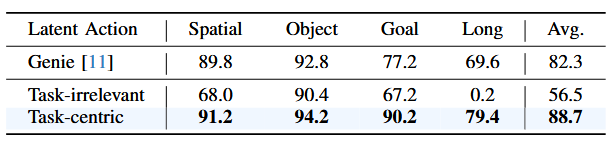
与 Genie 中提出的对所有视觉变化都捕捉潜在动作的方法相比,我们的方法优势明显。
草莓机器人如果用 Genie 方法,可能把“光线闪烁”“叶子飘动”也当成动作,训练时干扰多
使用与任务无关的潜在动作训练,在挑战性最大的 LIBERO-Long 上成功率几乎为零。其他情况也有一定成功率,说明以任务为中心还是很重要的。
4.3 更多消融研究
数据可扩展性
我们在图 9 中展示了随着预训练数据规模扩大以及跨领域数据加入,UniVLA 的性能如何演进。
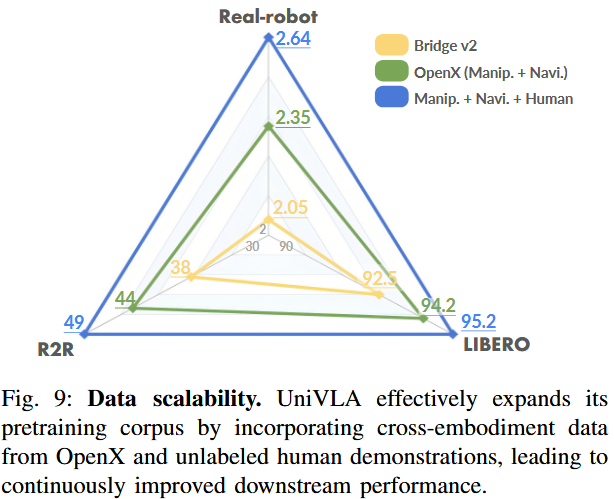
尽管仅用 Bridge-V2 预训练就已在 LIBERO 上创下新高,但加入 OpenX 和 Ego4D 中的跨主体数据后,平均成功率又提升了 2.0%。
在更具挑战的真实场景测试集上,与仅用 Bridge-V2 预训练相比,引入 OpenX 数据使平均得分提高 0.3;再加入人类视频数据,尽管缺少动作标签且跨主体差距更大,仍带来额外 0.28 的增益。
R2R 导航基准也呈现相似趋势。
数据使用效率
前面一节凸显了 UniVLA 在预训练数据规模上的可扩展性。接下来我们考察它在新环境下以最少数据高效适应的能力。
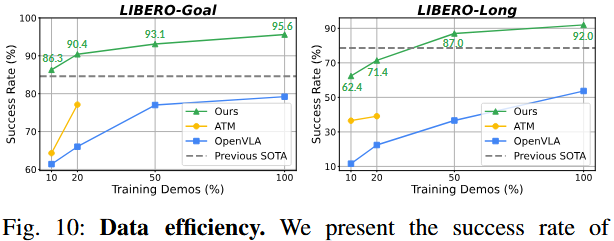
我们在 LIBERO-Goal 和 LIBERO-Long 两个子集上,分别仅用部分示范数据进行训练。
UniVLA 展现了更佳的数据效率。尤其是,当只使用 10% 的示范数据时,UniVLA 在 LIBERO-Goal 上取得 86.3% 的成功率,高于使用全部数据训练的 OpenVLA(79.2%)。并且,在 LIBERO-Goal 和 LIBERO-Long 上,仅用 10% 和 50% 的训练集就能达到新的基准水平。
潜在动作解码器
我们将所提出的动作解码方案,与 OpenVLA、LAPA 等常用的自回归离散动作生成方式进行了对比(见下表 IV)。
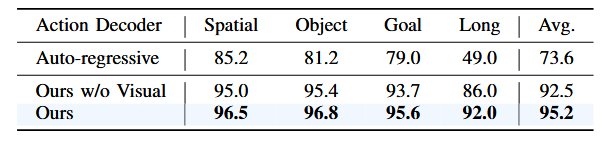
“w/o visual”表示在解码潜在动作时未使用视觉嵌入作为查询输入。本方法在所有测试集上均取得更高成功率,尤其在 LIBERO-Long 上提升了 42.1%。
历史潜在动作
如 3.3 节所述,我们在指令输入中加入了历史潜在动作,以增强连续决策能力。
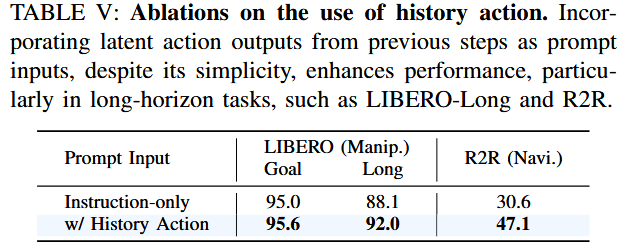
表 V 的定量结果显示,在长时序场景中效果尤为明显,仅用四个历史动作 token(即一个潜在动作分组)就能使 R2R 成功率提升 16.5%,在 LIBERO-Long 上提升 3.9%。
5. 结论
通过大量实验评估,我们证明了 UniVLA 在多个操控和导航基准测试中均达到了最新的最优水平。4090 ≥ 10Hz
该模型还展示了对多源预训练数据的良好可扩展性,从而提升下游任务性能;即便在示范数据极其有限的情况下,它依然保持高度的适应能力。
希望本工作能够为下一代通用策略铺路,使其能够利用网络规模的视频数据进行训练,而不受机器人形态差异或动作标签有无的限制。
6. 限制和未来工作
当前模型将“摘草莓”这样一秒内的动作都拆成同样长度的潜在动作单元,对某些需要更精细或更粗略控制的步骤(如“轻轻拨动叶片” )可能不够灵活。
未来可以让草莓机器人根据果实大小、果园通道宽度等环境变化,自动选择更细粒度或更粗粒度的动作单元。
大部分数据集使用的是对“短时动作”进行精细描述的指令,而非抽象的高层目标。示范里多是“请将手爪移到果实上并轻轻夹起”,而不是“请完成整片草莓田的采摘”。
未来方向可结合强化学习,用奖励机制不断优化选哪条路径才最省时、最不碰果枝。
“场景内学习”能力对提升视觉-语言-动作模型的上限至关重要。将人类示范视频编码为一系列紧凑的潜在动作嵌入,作为场景内示例(从概念上看,潜在动作模型像一个视频分词器)。这一方式可在不额外微调的情况下实现零样本技能获取。我们将在未来工作中探索这一方向。