Spark离线数据处理实例
工具:Jupyter notebook
# 一、需求分析
(1)分析美妆商品信息,找出每个“商品小类”中价格最高的前5个商品。
(2)每月订购情况,统计每个月订单的订购数量情况和消费金额。
(3)按订单的地区,统计各地在订购数量上的排行情况,取最高的前20个城市。
(4)按商品的类型,分别统计各美妆产品的订购数量排行,以了解产品的畅销程度和需求情况。
(5)分析各省的美妆订购数量,以了解哪些地方的商品需求量最大。
(6)通过RFM模型挖掘客户价值。
# 二、准备工作
1.数据清洗(Pandas)
2.窗口操作(Spark SQL)
3.数据可视化(pyecharts)
### 1.数据清洗(Pandas)
#### (1)模块库的安装
pip install pandas==1.1.5
pip list
pip show pandas
pip install pyecharts==1.9.0
pip show pyecharts
pip install pyspark-stubs==2.4.0
pip show pyspark-stubs
#### (1)导入库
import pandas as pd
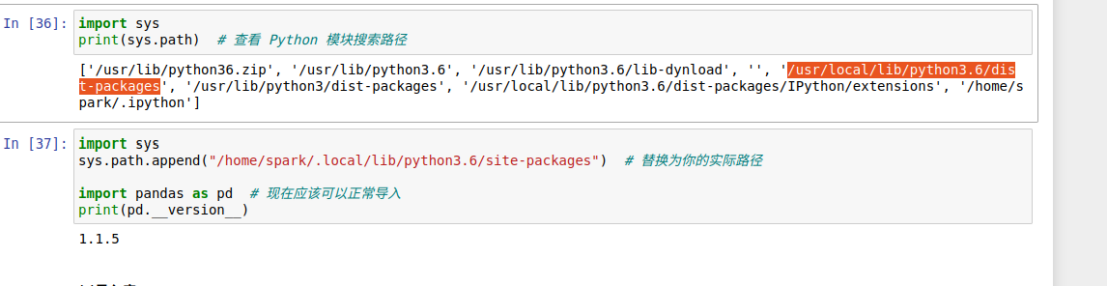
如果pandas导入错误执行图上代码,否则跳过此步骤
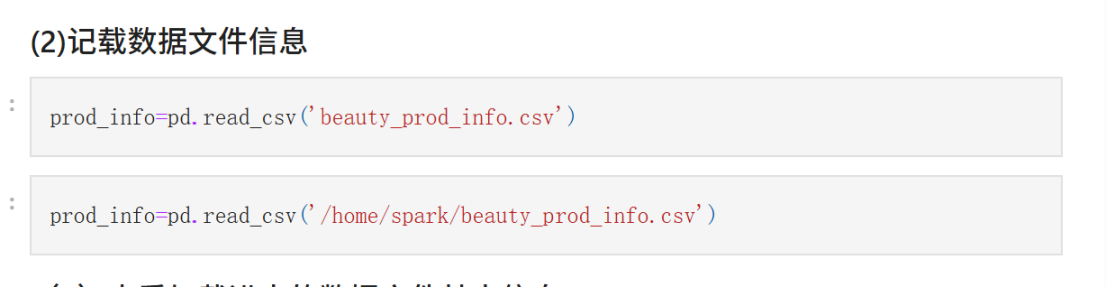
#### (2)记载数据文件信息
prod_info=pd.read_csv('beauty_prod_info.csv')
prod_info=pd.read_csv('/home/spark/beauty_prod_info.csv')
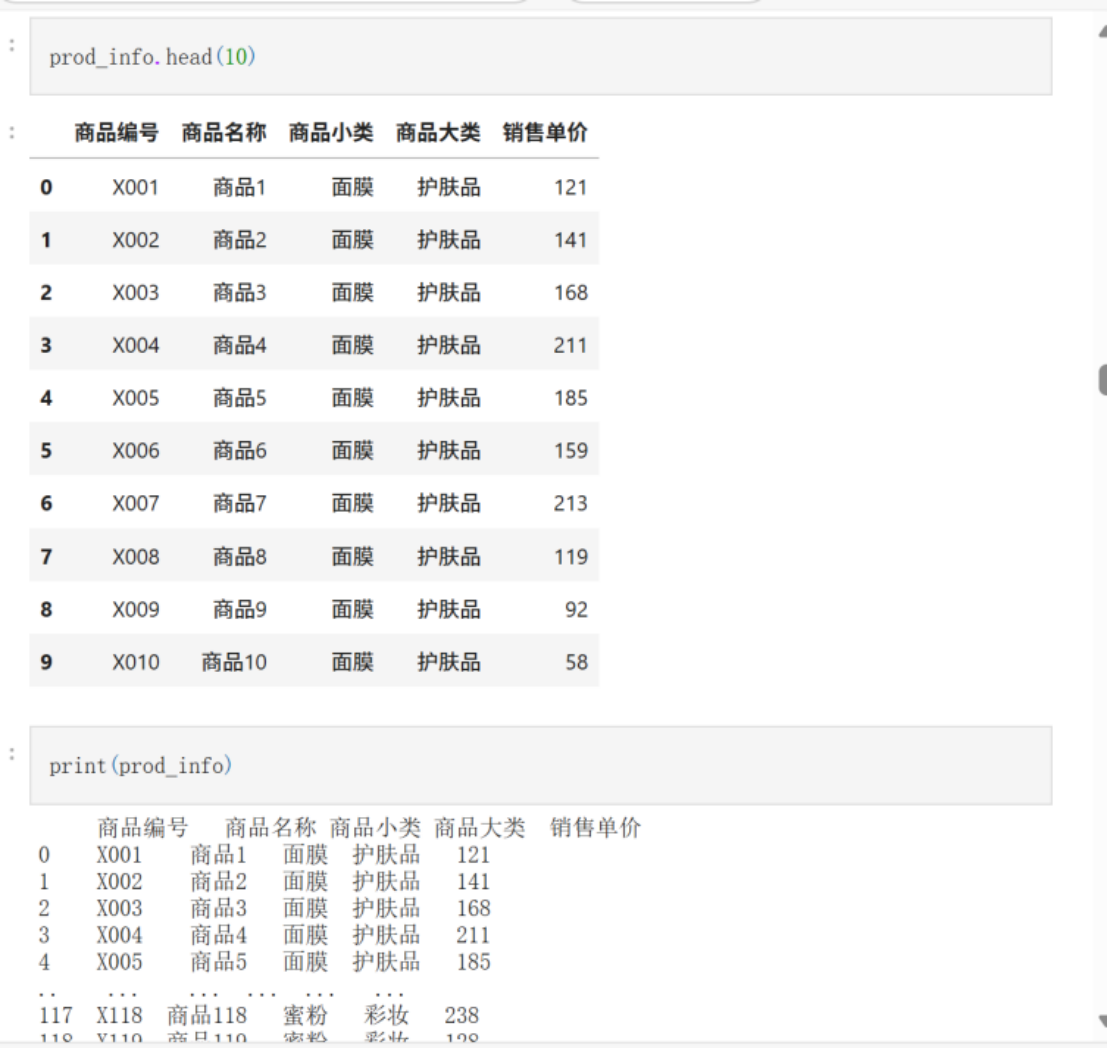
prod_info.head(10)
prod_sales=pd.read_csv('/home/spark/beauty_prod_sales.csv')
prod_sales.head()

#### (3、4)查看加载进来的数据文件基本信息
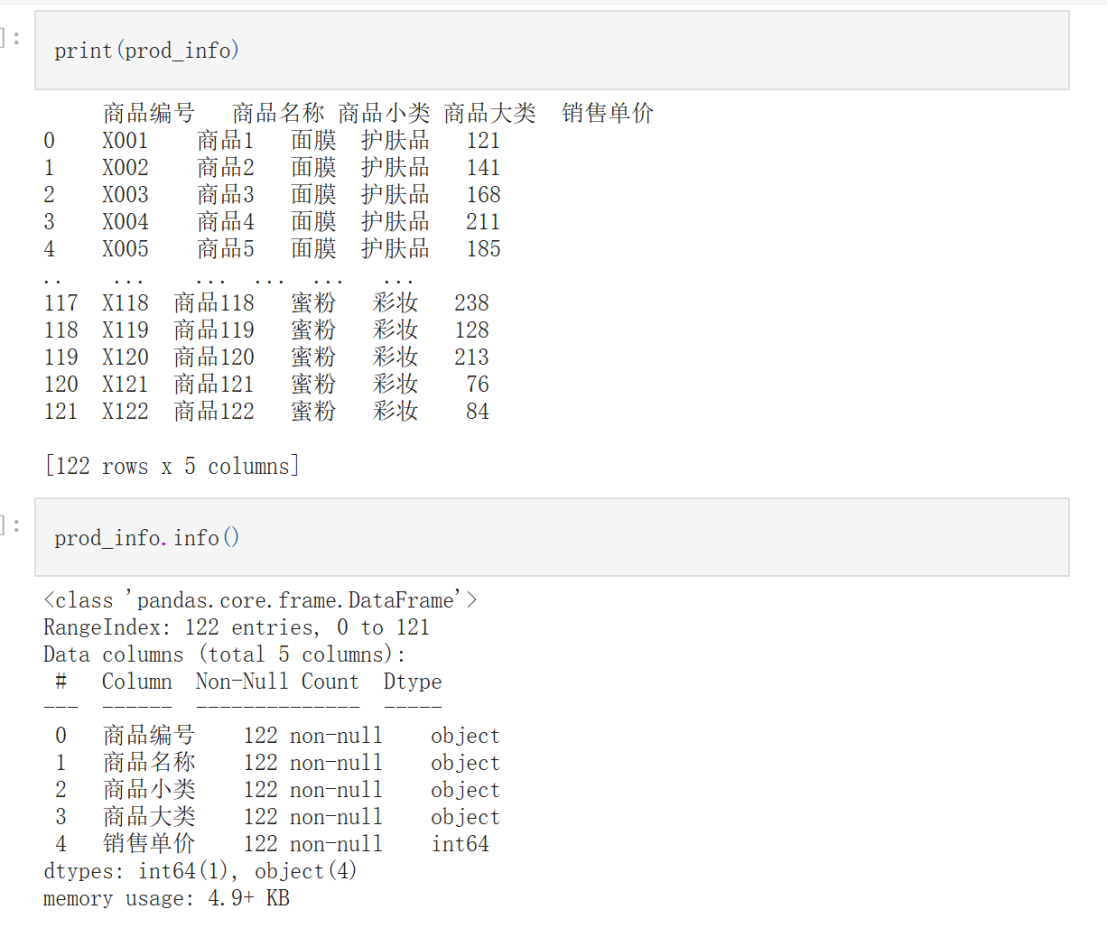
print(prod_info)
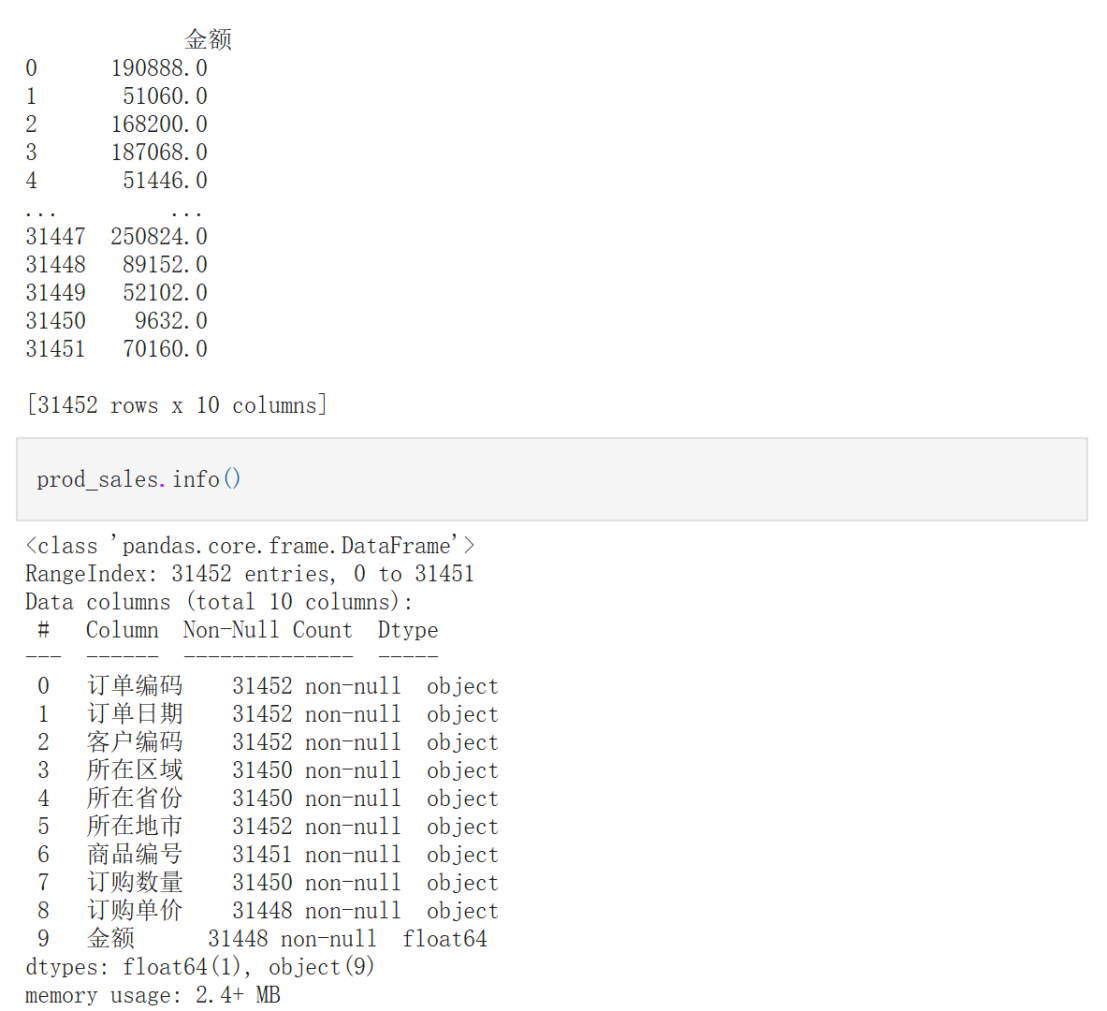
print(prod_sales)
prod_info.info()
prod_sales.info()

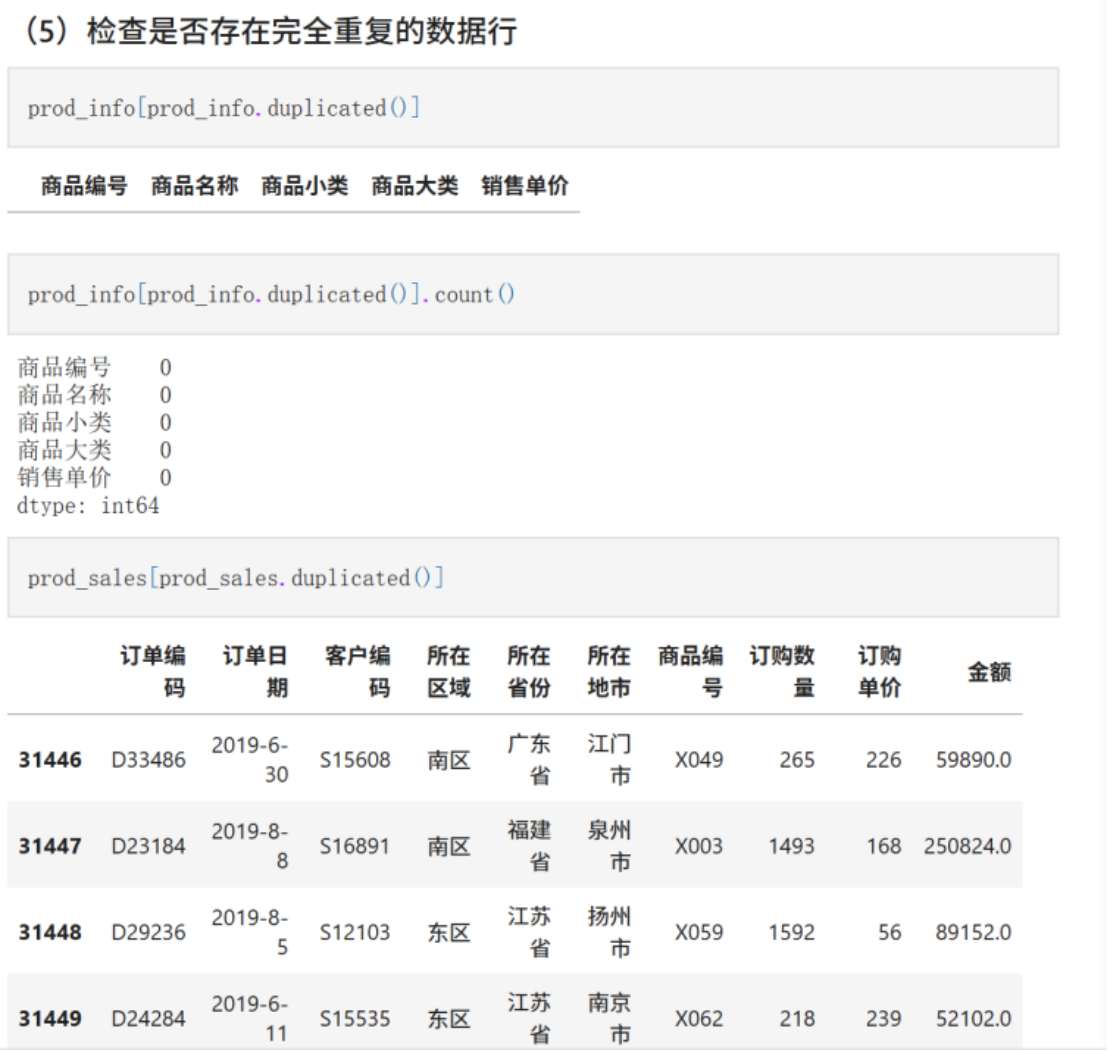
#### (5)检查是否存在完全重复的数据行
prod_info[prod_info.duplicated()]
prod_info[prod_info.duplicated()].count()
prod_sales[prod_sales.duplicated()]
prod_sales[prod_sales.duplicated()].count()
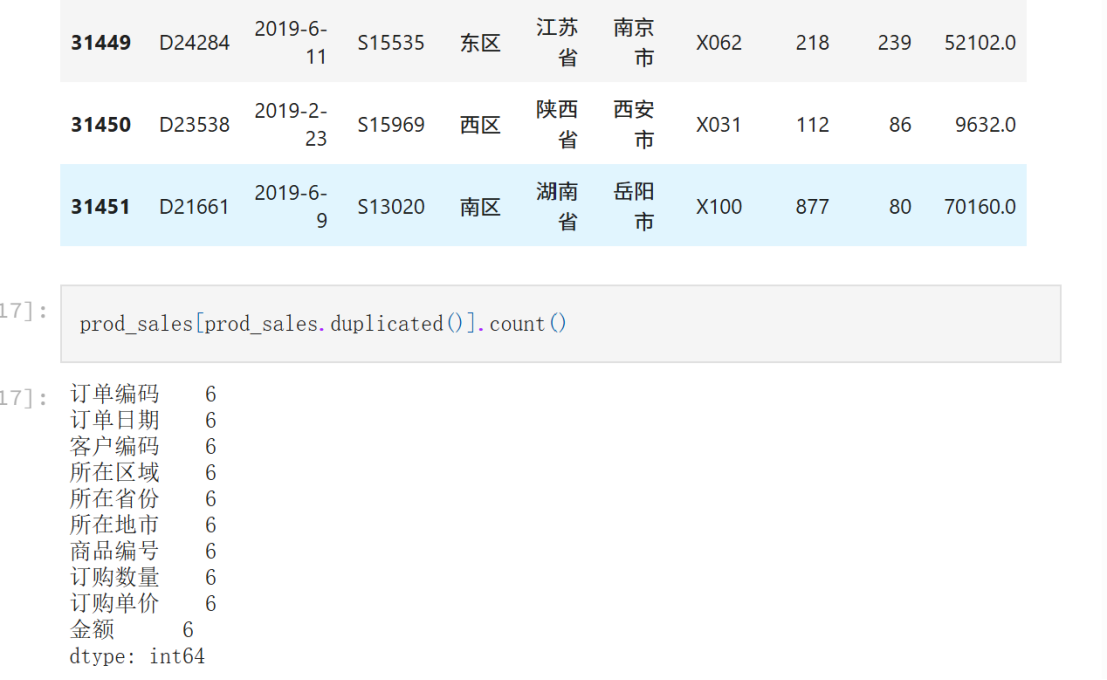
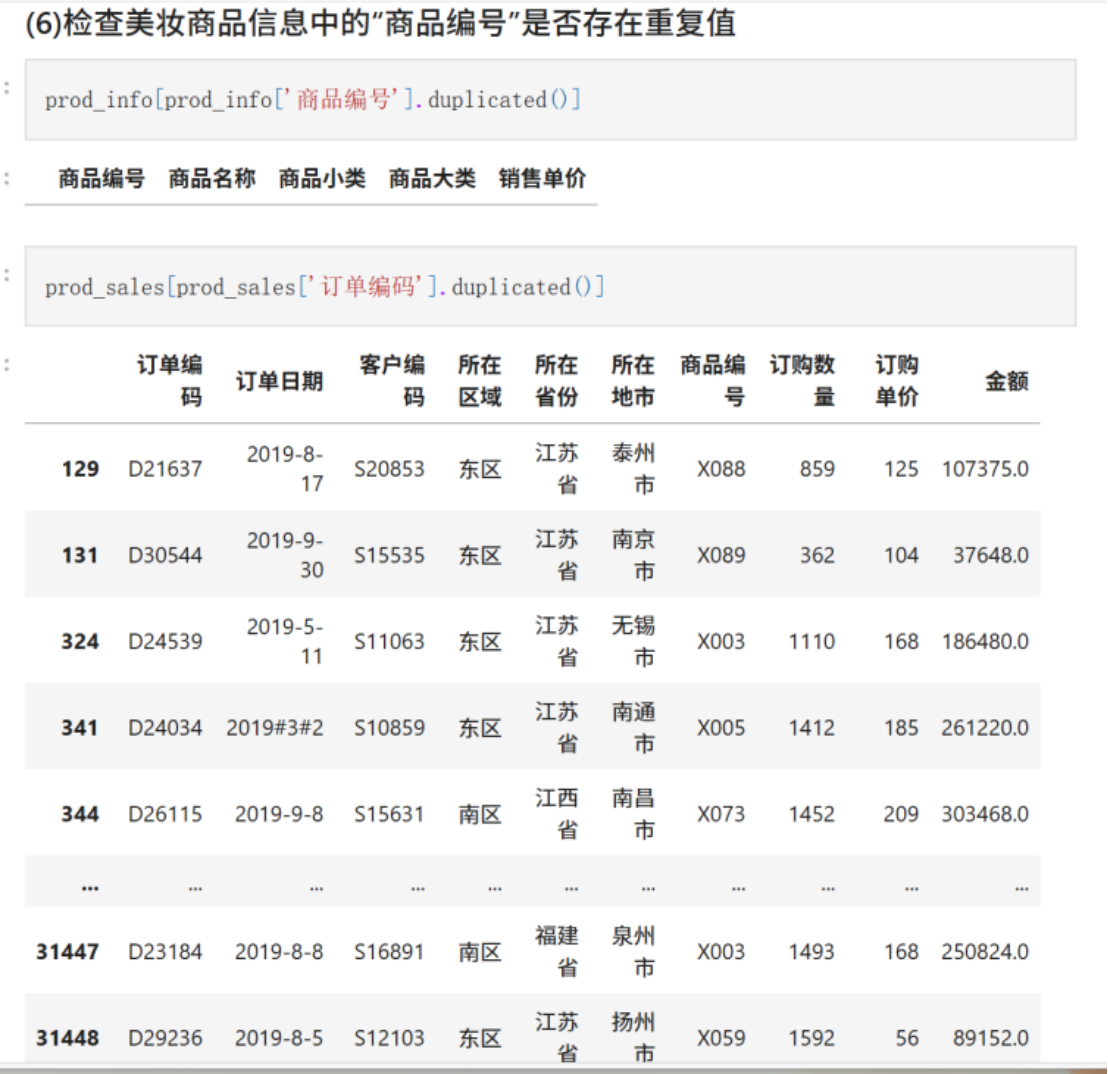
#### (6)检查美妆商品信息中的“商品编号”是否存在重复值
prod_info[prod_info['商品编号'].duplicated()]
prod_sales[prod_sales['订单编码'].duplicated()]
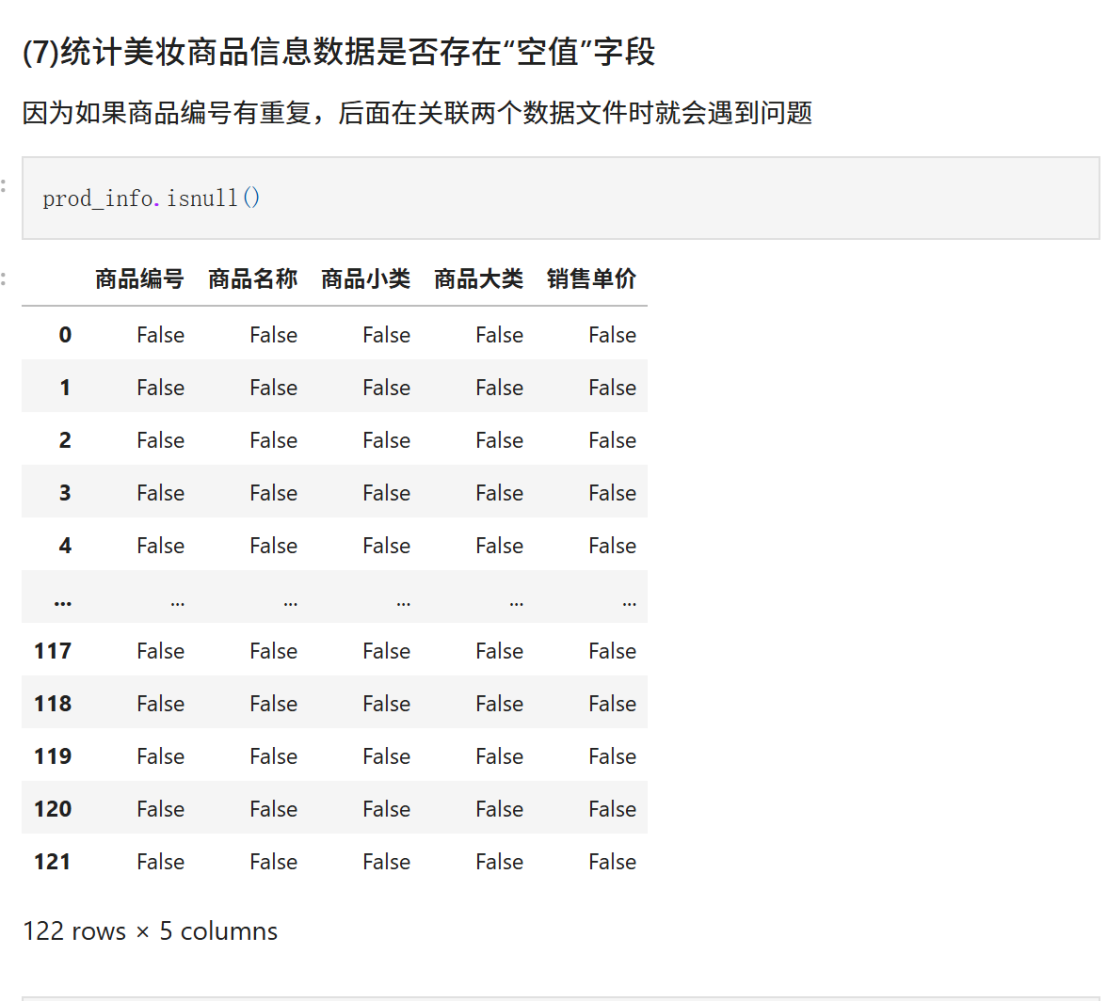
(7)统计美妆商品信息数据是否存在“空值”字段
因为如果商品编号有重复,后面在关联两个数据文件时就会遇到问题
prod_info.isnull()
prod_info.isnull().sum()
prod_sales.isnull().sum()
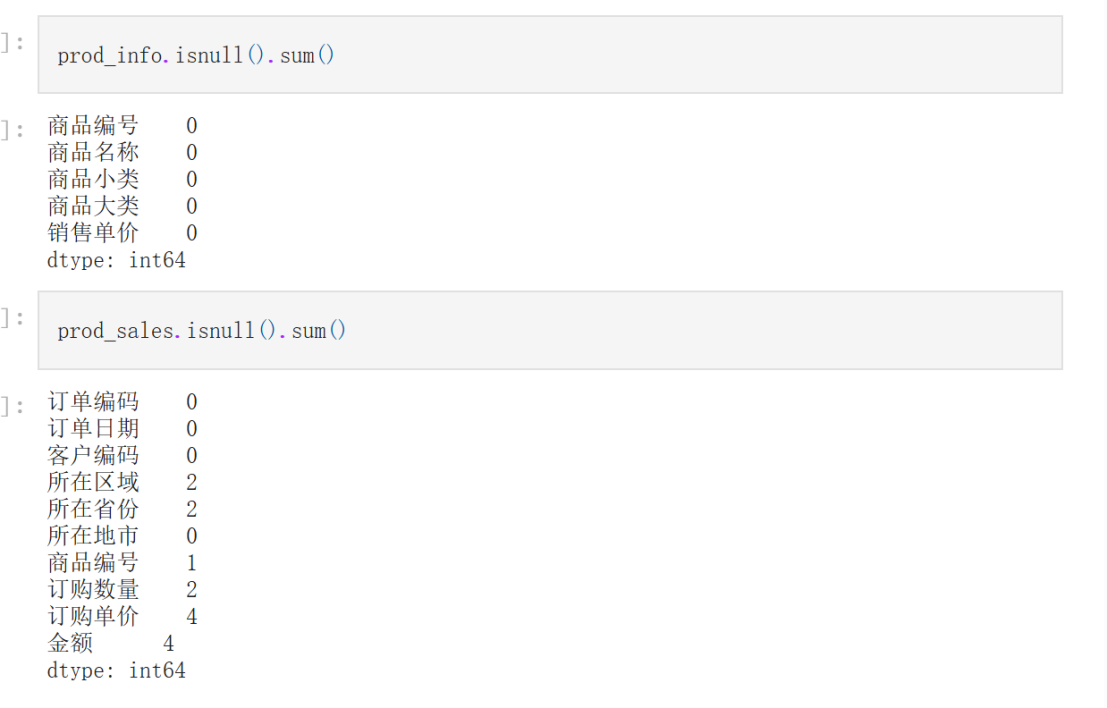
至此,美妆商品信息数据文件的初步分析工作就结束了,结论是不存在数据异常的情况。接下来继续分析美妆商品订单数据文件,加载美妆商品订单数据文件beauty_prod_sales.csv,并查看前5行的数据
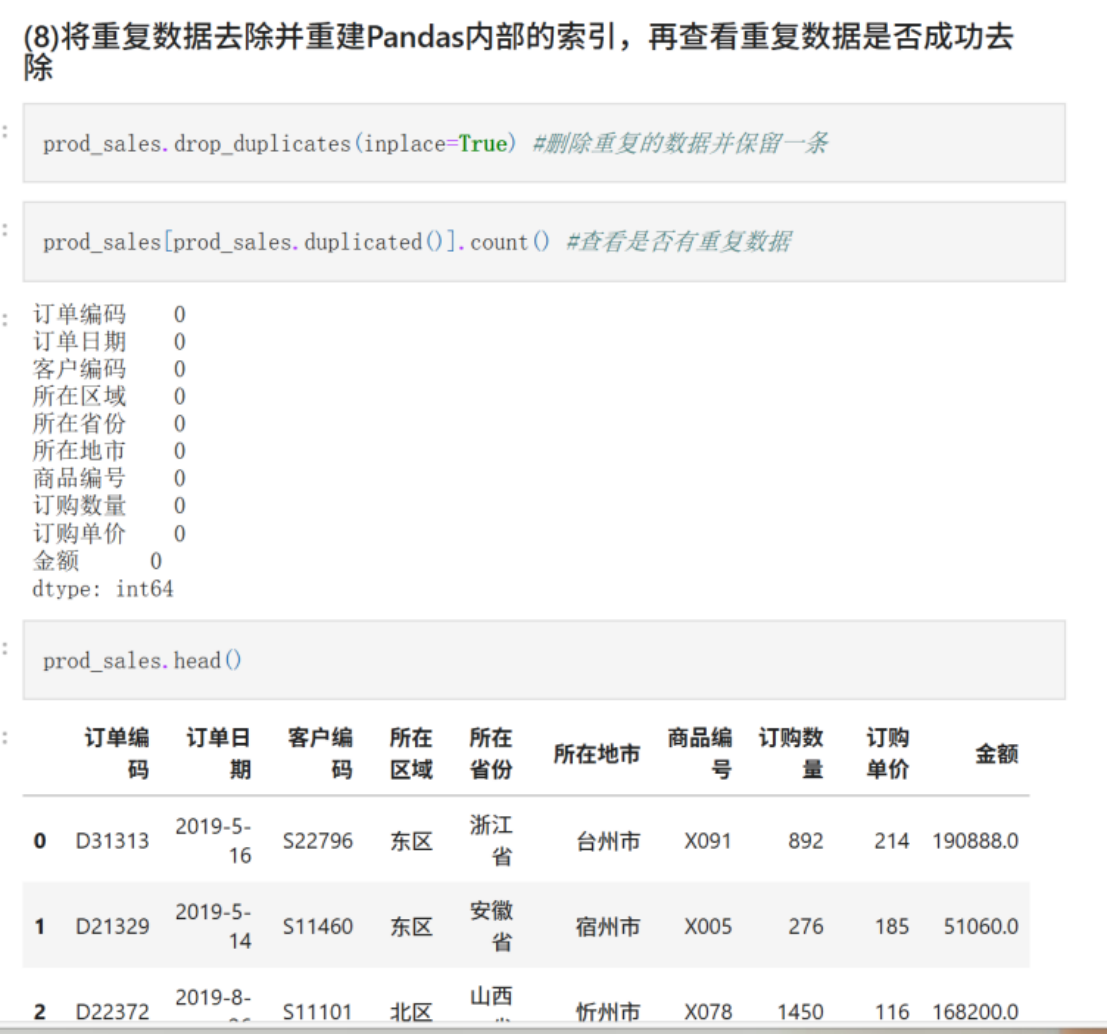
(8)将重复数据去除并重建Pandas内部的索引,再查看重复数据是否成功去除
prod_sales.drop_duplicates(inplace=True) #删除重复的数据并保留一条
prod_sales[prod_sales.duplicated()].count() #查看是否有重复数据
prod_sales.head()
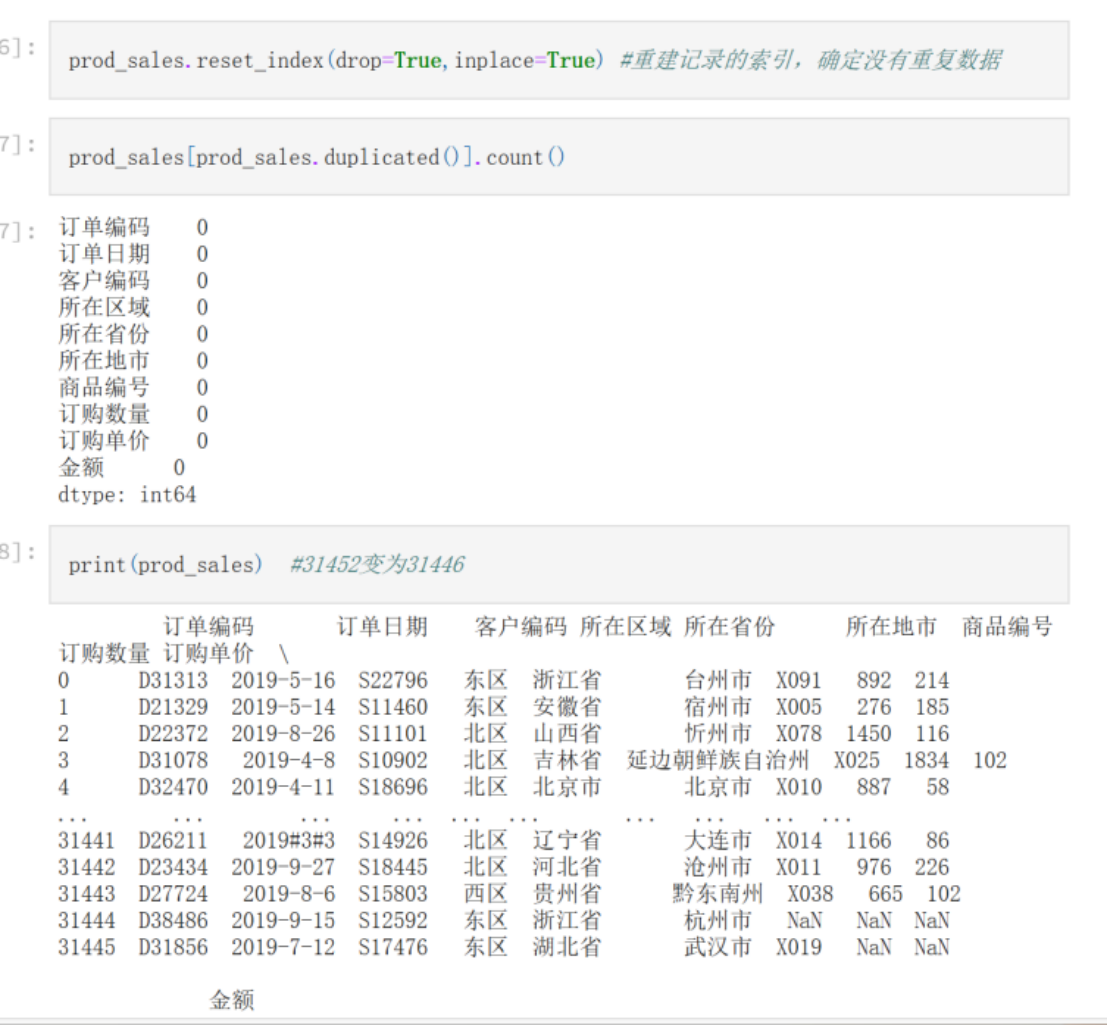
prod_sales.reset_index(drop=True,inplace=True) #重建记录的索引,确定没有重复数据
prod_sales[prod_sales.duplicated()].count()
print(prod_sales) #31452变为31446
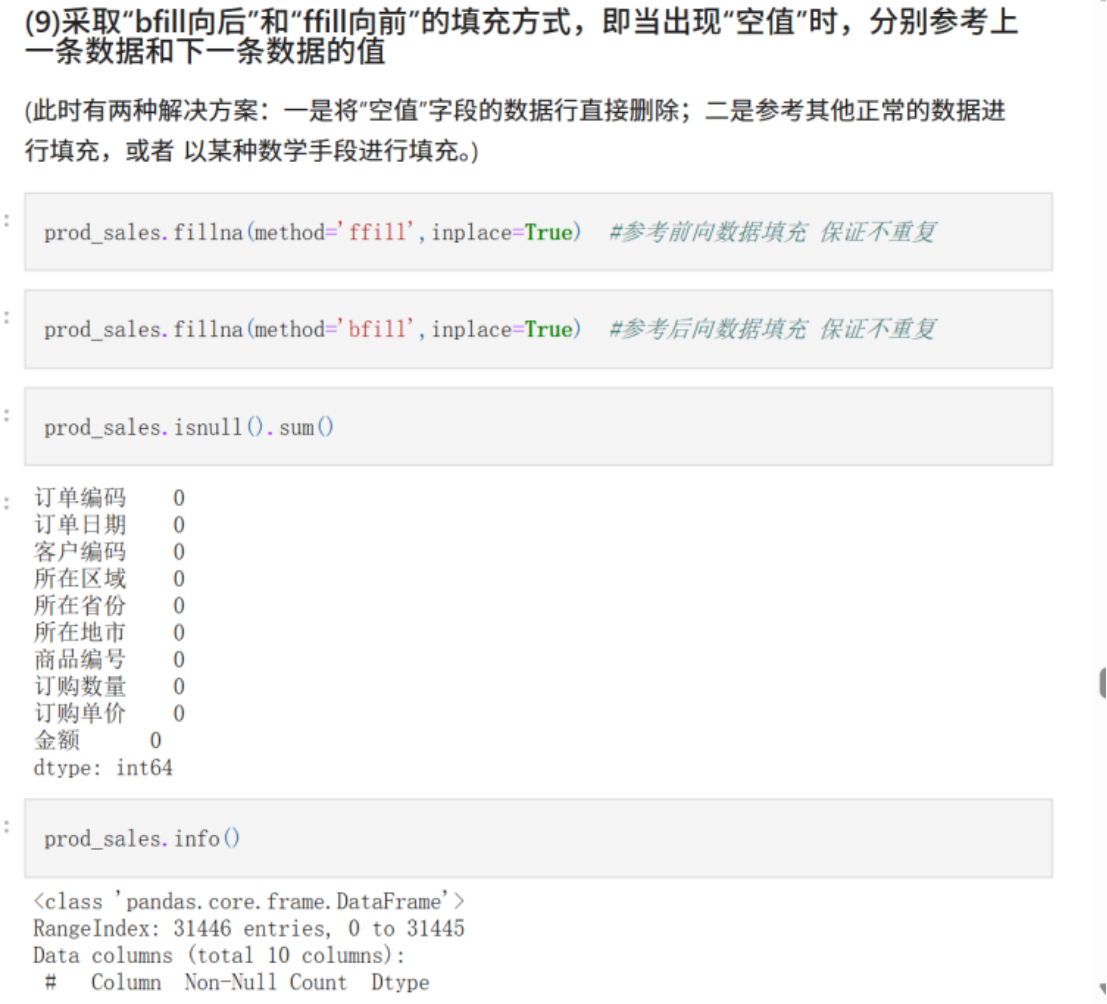
(9)采取“bfill向后”和“ffill向前”的填充方式,即当出现“空值”时,分别参考上一条数据和下一条数据的值
(此时有两种解决方案:一是将“空值”字段的数据行直接删除;二是参考其他正常的数据进行填充,或者 以某种数学手段进行填充。)
prod_sales.fillna(method='ffill',inplace=True) #参考前向数据填充 保证不重复
prod_sales.fillna(method='bfill',inplace=True) #参考后向数据填充 保证不重复
prod_sales.isnull().sum()
prod_sales.info()
(10)下面对存在问题的订单日期、订购数量、订购单价这几个字段进行处理
错误原因:
prod_sales['订单日期'].astype('datetime64') #转换类型 说明有非法字符
prod_sales['订购数量'].astype('int64') #多了文字(个)
prod_sales['订购单价'].astype('float64') #多了元
转换类型:
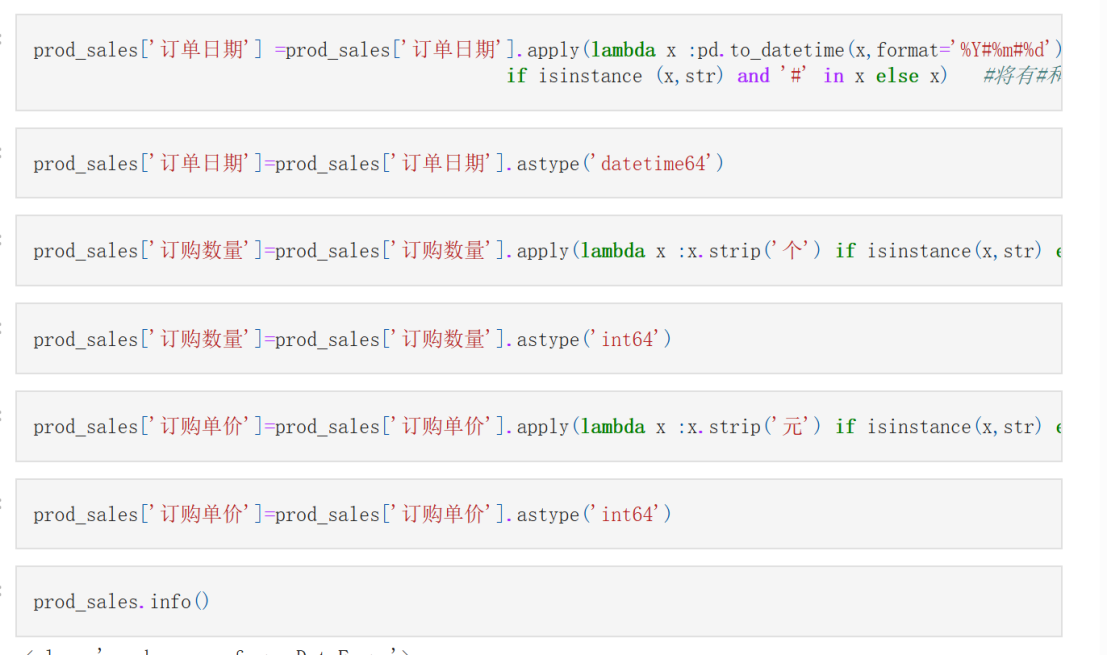
prod_sales['订单日期'] =prod_sales['订单日期'].apply(lambda x :pd.to_datetime(x,format='%Y#%m#%d') \
if isinstance (x,str) and '#' in x else x) #将有#和字符串的转换为日期格式
prod_sales['订单日期']=prod_sales['订单日期'].astype('datetime64')
prod_sales['订购数量']=prod_sales['订购数量'].apply(lambda x :x.strip('个') if isinstance(x,str) else x)
prod_sales['订购数量']=prod_sales['订购数量'].astype('int64')
prod_sales['订购单价']=prod_sales['订购单价'].apply(lambda x :x.strip('元') if isinstance(x,str) else x)
prod_sales['订购单价']=prod_sales['订购单价'].astype('int64')
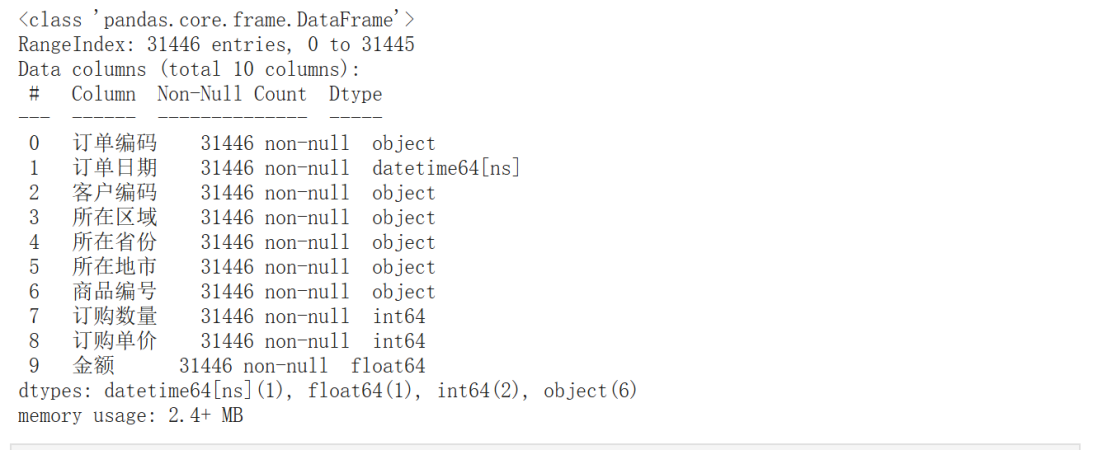
prod_sales.info()