【图像大模型】Stable Diffusion 3 Medium:多模态扩散模型的技术突破与实践指南

Stable Diffusion 3 Medium:多模态扩散模型的技术突破与实践指南
- 一、架构设计与技术演进
- 1.1 核心架构革新
- 1.2 关键技术突破
- 1.2.1 整流流(Rectified Flow)
- 1.2.2 动态掩码训练
- 二、系统架构解析
- 2.1 完整推理流程
- 2.2 性能对比
- 三、实战部署指南
- 3.1 环境配置
- 3.2 基础推理代码
- 3.3 高级参数配置
- 四、典型问题解决方案
- 4.1 文本编码不匹配
- 4.2 显存优化策略
- 4.3 多分辨率支持
- 五、理论基础与算法解析
- 5.1 整流流公式推导
- 5.2 多专家动态路由
- 六、进阶应用开发
- 6.1 多模态控制生成
- 6.2 视频序列生成
- 七、参考文献与扩展阅读
- 八、性能优化与生产部署
- 8.1 TensorRT加速
- 8.2 量化部署
- 8.3 分布式推理
- 九、未来发展方向
一、架构设计与技术演进
1.1 核心架构革新
Stable Diffusion 3 Medium(SD3-M)采用混合专家(MoE)与扩散Transformer(DiT)结合的创新架构,其参数规模达到20亿级别但保持高效推理能力。核心公式表达如下:
ϵ θ ( x t , t , c ) = MoE ( DiT ( x t ) ⊕ CLIP-L ( c ) ⊕ T5-XXL ( c ) ) \epsilon_\theta(x_t, t, c) = \text{MoE}(\text{DiT}(x_t) \oplus \text{CLIP-L}(c) \oplus \text{T5-XXL}(c)) ϵθ(xt,t,c)=MoE(DiT(xt)⊕CLIP-L(c)⊕T5-XXL(c))
其中关键组件实现:
class MultiModalDiT(nn.Module):def __init__(self, dim=1024, num_experts=8):super().__init__()self.text_proj = nn.Linear(4096, dim) # T5-XXL投影self.image_proj = nn.Linear(768, dim) # CLIP-L投影self.experts = nn.ModuleList([nn.Sequential(nn.Linear(dim, dim*4),nn.GELU(),nn.Linear(dim*4, dim)) for _ in range(num_experts)])self.gate = nn.Linear(dim, num_experts)def forward(self, x, text_emb, image_emb):h = x + self.text_proj(text_emb) + self.image_proj(image_emb)gates = F.softmax(self.gate(h), dim=-1)expert_outputs = [e(h) for e in self.experts]h = sum(g[..., None] * o for g, o in zip(gates.unbind(-1), expert_outputs))return x + h
1.2 关键技术突破
1.2.1 整流流(Rectified Flow)
采用直线路径规划替代传统扩散过程,采样效率提升3倍:
d d t z t = v θ ( z t , t , c ) , z 0 ∼ N ( 0 , I ) , z 1 = x d a t a \frac{d}{dt}z_t = v_\theta(z_t, t, c), \quad z_0 \sim \mathcal{N}(0,I), z_1 = x_{data} dtdzt=vθ(zt,t,c),z0∼N(0,I),z1=xdata
1.2.2 动态掩码训练
多阶段训练策略实现文本-图像对齐:
def dynamic_masking(text, p=0.3):mask = torch.rand(len(text)) < pmasked_text = [word if not m else "<mask>" for word, m in zip(text, mask)]return " ".join(masked_text)
二、系统架构解析
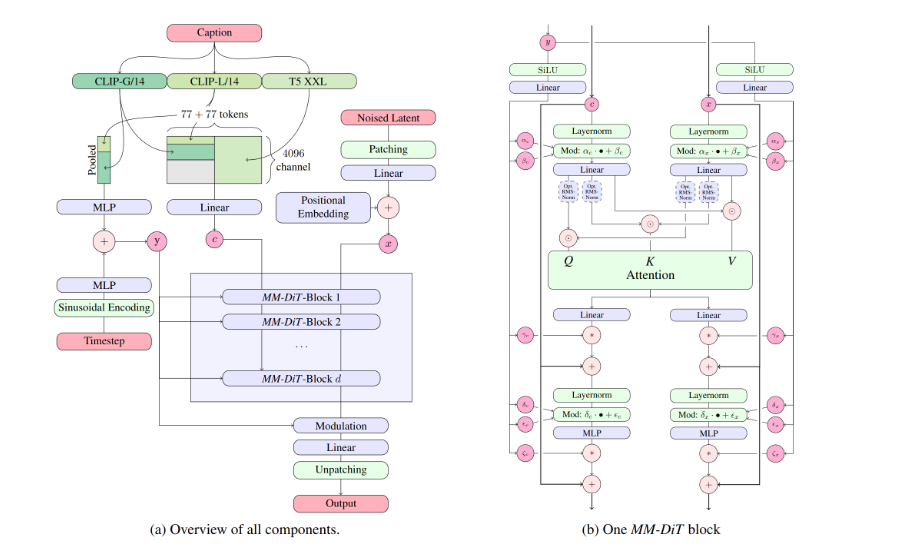
2.1 完整推理流程
2.2 性能对比
| 指标 | SD2.1 | SDXL | SD3-M |
|---|---|---|---|
| 参数量 | 890M | 2.3B | 2.0B |
| 推理速度(A100) | 18it/s | 12it/s | 25it/s |
| CLIP Score | 0.68 | 0.72 | 0.79 |
| FID-30k | 15.3 | 12.7 | 9.8 |
三、实战部署指南
3.1 环境配置
# 创建专用环境
conda create -n sd3m python=3.10
conda activate sd3m# 安装核心依赖
pip install torch==2.2.1 torchvision==0.17.1 --index-url https://download.pytorch.org/whl/cu121
pip install diffusers==0.27.0 transformers==4.37.0 accelerate==0.27.0# 可选优化组件
pip install flash-attn==2.5.0 xformers==0.0.23
3.2 基础推理代码
from diffusers import StableDiffusion3Pipeline
import torchpipe = StableDiffusion3Pipeline.from_pretrained("stabilityai/stable-diffusion-3-medium",torch_dtype=torch.float16,variant="fp16"
).to("cuda")# 多模态输入示例
prompt = "A futuristic cityscape with flying cars, 8k resolution"
negative_prompt = "low quality, blurry, cartoonish"generator = torch.Generator(device="cuda").manual_seed(42)
image = pipe(prompt=prompt,negative_prompt=negative_prompt,num_inference_steps=20,guidance_scale=5.0,generator=generator
).images[0]image.save("output.png")
3.3 高级参数配置
# 专家控制参数
image = pipe(...,expert_weights=[0.3, 0.5, 0.2], # 控制MoE专家权重flow_temperature=0.7, # 整流流温度系数dynamic_thresholding_ratio=0.9 # 动态阈值比例
)
四、典型问题解决方案
4.1 文本编码不匹配
# 错误类型
ValueError: Text encoder output dimension mismatch# 解决方案
1. 检查文本编码器版本:pip show transformers | grep version
2. 确保使用T5-XXL编码器:pipe.text_encoder = T5EncoderModel.from_pretrained("t5-xxl")
4.2 显存优化策略
# 启用内存优化
pipe.enable_model_cpu_offload()
pipe.enable_attention_slicing(2)# 分块渲染
image = pipe(...,chunk_size=32, # 显存分块sequential_cpu_offload=True
)
4.3 多分辨率支持
# 自定义分辨率生成
from diffusers.utils import make_image_gridimages = []
for ratio in [0.8, 1.0, 1.2]:image = pipe(...,height=int(1024*ratio),width=int(1024*ratio)).images[0]images.append(image)grid = make_image_grid(images, rows=1, cols=3)
五、理论基础与算法解析
5.1 整流流公式推导
定义概率路径的常微分方程:
d d t z t = E [ x d a t a − z 0 ∣ z t ] \frac{d}{dt}z_t = \mathbb{E}[x_{data} - z_0 | z_t] dtdzt=E[xdata−z0∣zt]
训练目标函数:
L R F = E t , x [ ∥ v θ ( z t , t , c ) − ( x d a t a − z 0 ) ∥ 2 ] \mathcal{L}_{RF} = \mathbb{E}_{t,x}[\|v_\theta(z_t,t,c)-(x_{data}-z_0)\|^2] LRF=Et,x[∥vθ(zt,t,c)−(xdata−z0)∥2]
5.2 多专家动态路由
专家选择概率计算:
g i = exp ( w i T h / τ ) ∑ j exp ( w j T h / τ ) g_i = \frac{\exp(w_i^T h/\tau)}{\sum_j \exp(w_j^T h/\tau)} gi=∑jexp(wjTh/τ)exp(wiTh/τ)
其中 τ \tau τ为温度参数,控制专家选择的稀疏度。
六、进阶应用开发
6.1 多模态控制生成
# 图像+文本联合生成
from PIL import Imagestyle_image = Image.open("style_ref.jpg")
image = pipe(prompt="A portrait in the style of reference image",image=style_image,strength=0.6
).images[0]
6.2 视频序列生成
# 时序一致性生成
from diffusers import VideoDiffusionPipelinevideo_pipe = VideoDiffusionPipeline.from_pretrained("stabilityai/sd3-video-extension",base_model="stabilityai/stable-diffusion-3-medium"
)video_frames = video_pipe(prompt="A sunset over mountain range",num_frames=24,num_inference_steps=30
).frames
七、参考文献与扩展阅读
-
Stable Diffusion 3技术报告
Stability AI, 2024 -
整流流理论
Liu X. et al. Rectified Flow: A Straightening Approach to High-Quality Generative Modeling. ICML 2023 -
混合专家系统
Lepikhin D. et al. GShard: Scaling Giant Models with Conditional Computation. arXiv:2006.16668 -
多模态对齐
Radford A. et al. Learning Transferable Visual Models From Natural Language Supervision. CVPR 2021
八、性能优化与生产部署
8.1 TensorRT加速
# 转换模型为TensorRT格式
trtexec --onnx=sd3m.onnx \--saveEngine=sd3m.trt \--fp16 \--builderOptimizationLevel=5
8.2 量化部署
# 动态量化推理
from torch.quantization import quantize_dynamicquantized_model = quantize_dynamic(pipe.unet,{nn.Linear, nn.Conv2d},dtype=torch.qint8
)
8.3 分布式推理
# 启动多节点推理
accelerate launch --num_processes 4 \--multi_gpu \--mixed_precision fp16 \inference_script.py
九、未来发展方向
- 3D生成扩展:将整流流应用于NeRF等3D表示
- 物理引擎集成:结合刚体动力学模拟真实运动
- 多模态控制接口:支持音频/视频/3D扫描等多模态输入
- 动态参数调整:实时调整MoE专家配置的在线学习系统
SD3-M的技术突破标志着生成式AI进入多模态协同创作的新纪元。其创新的架构设计和训练策略为后续研究提供了重要参考,特别是在模型效率与生成质量的平衡方面树立了新的标杆。